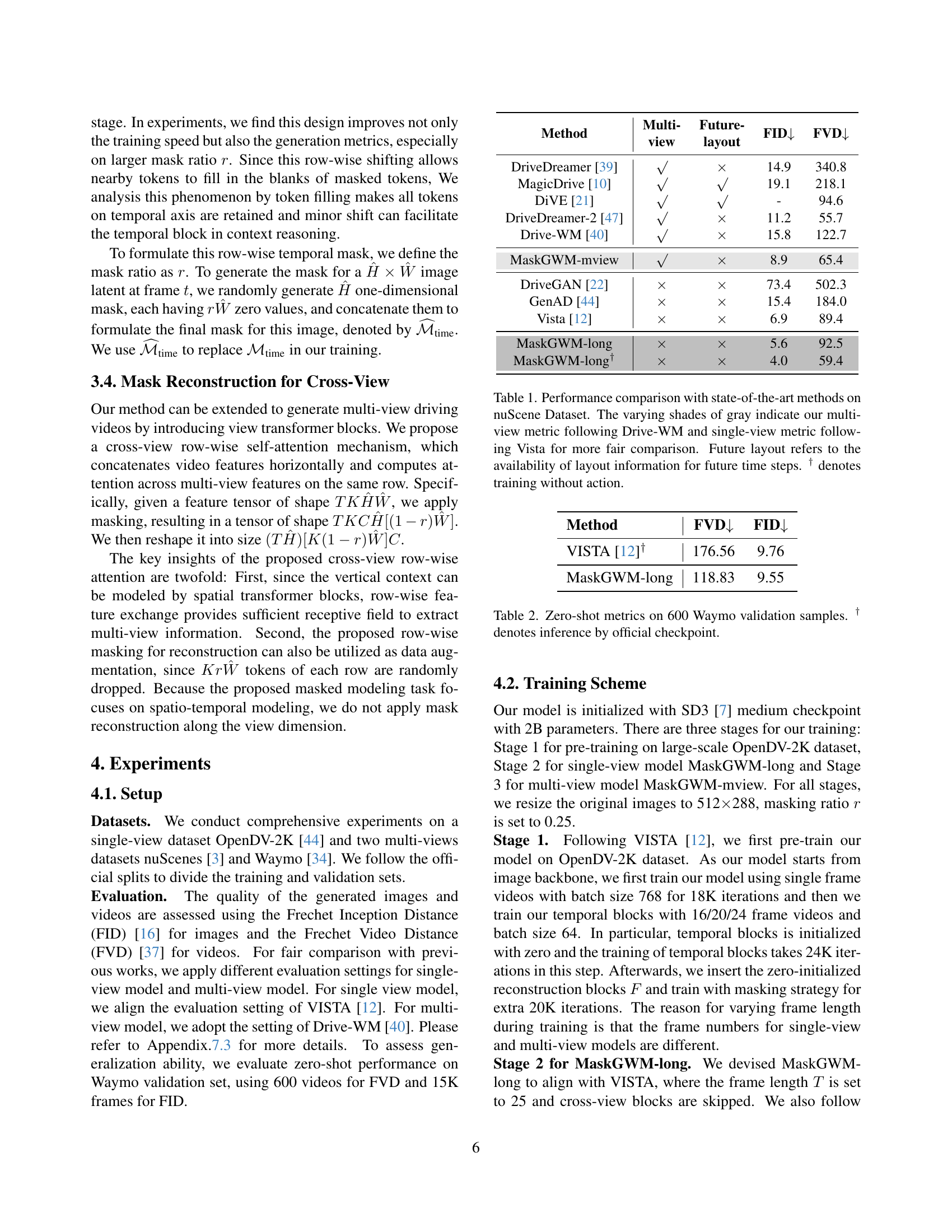
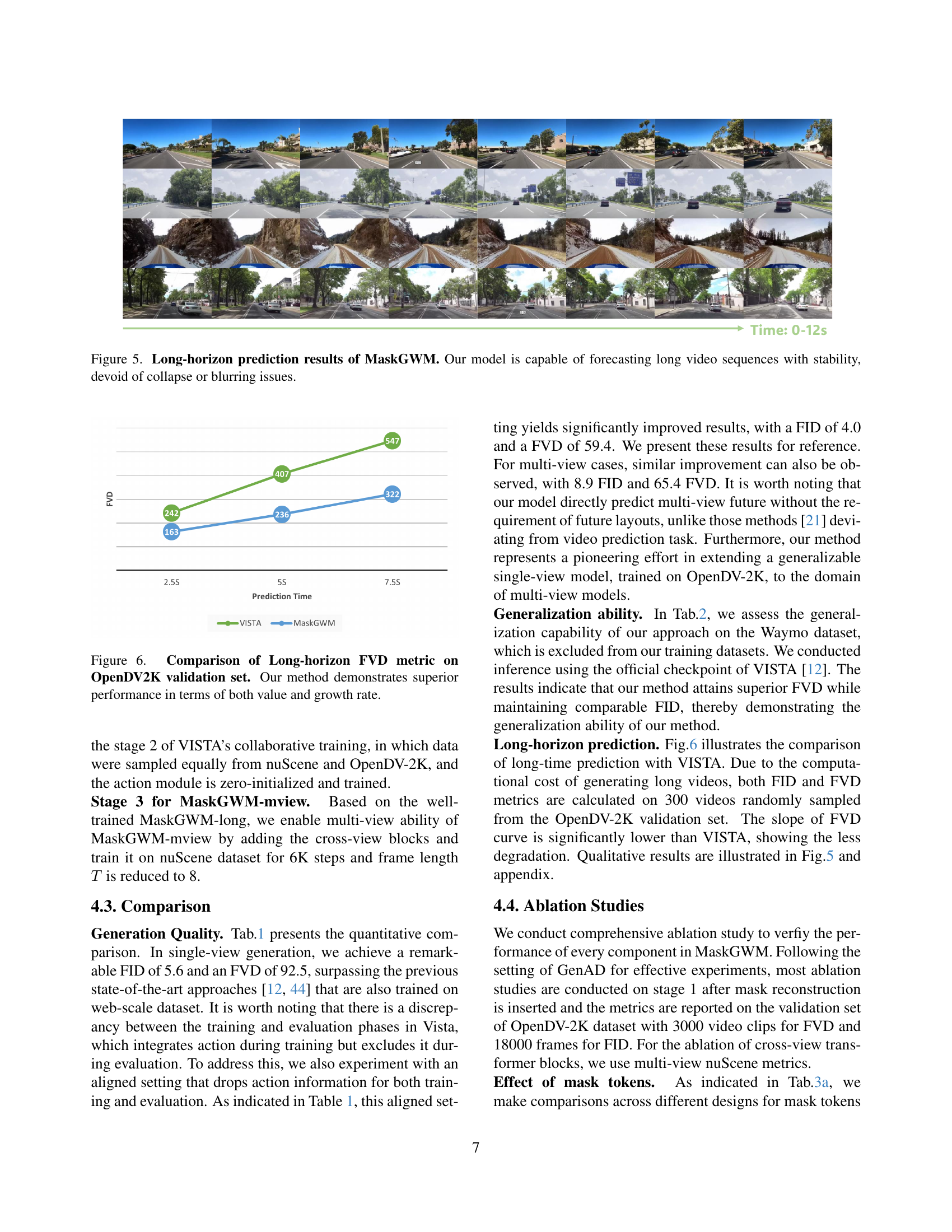
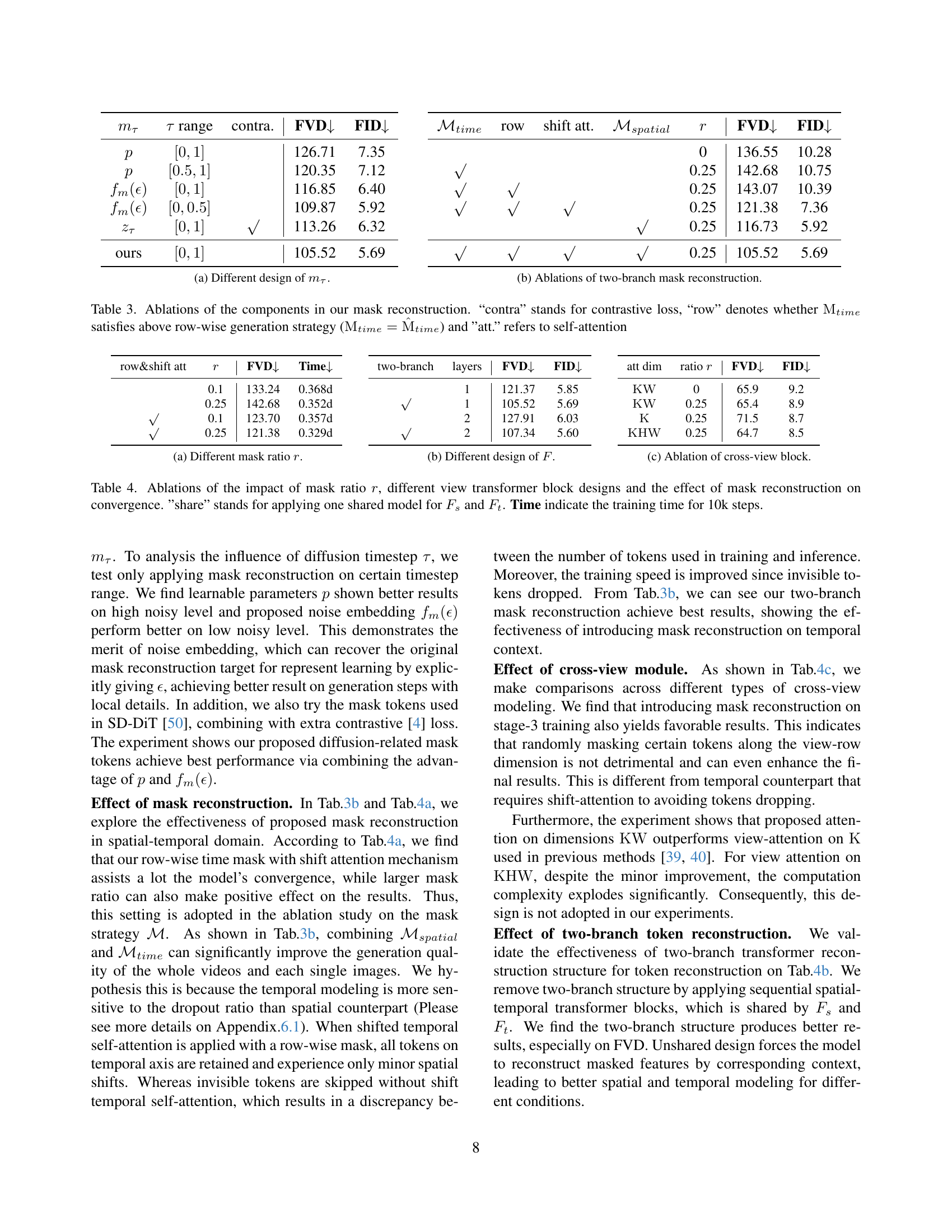
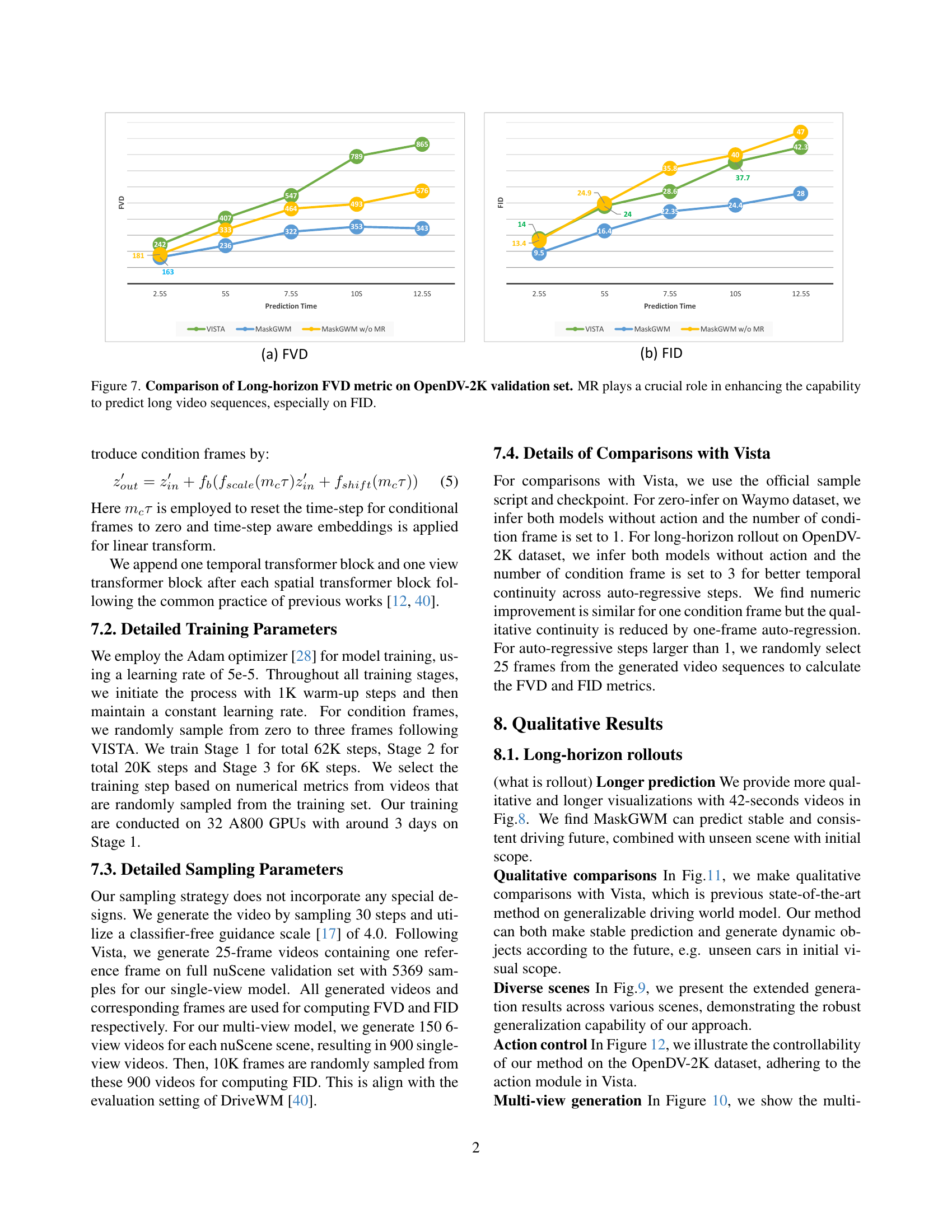
TL;DR#
Autonomous driving models need to accurately forecast environmental changes, but current driving world models struggle with predictive duration and generalization. These models, which rely on video prediction, are limited in complex scenarios like weather changes and scene variations. To tackle these issues, a new model design is needed, that combines generation loss with feature-level context learning to improve fidelity, generalizability, and long-time series prediction.
This paper introduces MaskGWM, a Generalizable driving World Model that utilizes video mask reconstruction. It employs a Diffusion Transformer structure trained with extra mask construction, diffusion-related mask tokens, and extends mask construction to spatial-temporal domains using row-wise masking. Comprehensive evaluations on multiple datasets confirm that MaskGWM significantly improves upon existing driving world models, demonstrating enhanced video quality, zero-shot performance, and long-term prediction.
Key Takeaways#
Why does it matter?#
This paper introduces a novel approach for enhancing driving world models. The MaskGWM enhances realism, generalizability, and forecast accuracy in autonomous driving simulations. It presents new avenues for research on improving the reliability and adaptability of autonomous systems in diverse and complex real-world conditions.
Visual Insights#
Full paper#