TL;DR#
Current large language models (LLMs) struggle with complex reasoning, especially in the context of video understanding. Existing methods often focus on specific tasks like solving mathematical problems or analyzing images, neglecting the broader applications of video understanding. Moreover, creating high-quality datasets for multimodal reasoning is challenging.
This research introduces video-SALMONN-01, the first open-source reasoning-enhanced audio-visual LLM designed for general video understanding. To address the issue of dataset scarcity, they created a new reasoning-intensive dataset with step-by-step solutions. They also developed a novel optimization technique, pDPO, that efficiently models step-level rewards for multimodal inputs. Their model outperforms existing baselines on various video reasoning benchmarks, demonstrating the effectiveness of their approach. Furthermore, RivaBench, a new benchmark dataset, was created to facilitate future research in this area.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of existing large language models in handling complex reasoning tasks within general video understanding. It introduces a novel reasoning-enhanced audio-visual LLM, video-SALMONN-01, along with a new benchmark, RivaBench, pushing the boundaries of multimodal reasoning. The proposed methods, including process direct preference optimization (pDPO), offer significant improvements in accuracy and zero-shot capabilities, opening exciting avenues for future research in multimodal AI.
Visual Insights#

🔼 The figure illustrates the architecture of the video-SALMONN-01 model. It shows how input video data is processed through two parallel branches: one for visual information and one for audio. Each branch uses an encoder (visual encoder and audio encoder) to extract relevant features from the respective input sequences (frames and audio segments). These feature representations are then combined in an interleaved manner to align temporal information and create a unified representation suitable for processing by a Large Language Model (LLM). This unified representation is then inputted to the LLM for further analysis and task completion.
read the caption
Figure 1: video-SALMONN-o1 model structure. The input video is processed by the visual and audio branches, generating encodings from the visual and audio frame sequences respectively. Two encoding streams are combined in an interleaved fashion to synchronize across time before sending to LLM.
| Attribute | Academic | StandUp | SynthDec |
|---|---|---|---|
| Num. of QA | 1,912 | 2,128 | 200 |
| Duration (s) | 47.2 66.1 | 43.2 15.1 | 8.13.2 |
| Format | 5-way MCQ | 5-way MCQ | Yes/No |
🔼 Table 1 provides a detailed breakdown of the RivaBench dataset’s statistics, a new benchmark specifically designed for evaluating the reasoning capabilities of audio-visual LLMs. It shows the number of question-answer pairs, average video duration (mean and standard deviation), and the type of questions (Multiple Choice Questions, or MCQ) for three different scenarios or partitions within the dataset: Academic, StandUp, and SynthDec. The SynthDec partition is particularly noteworthy, as it is composed of 100 synthetically generated videos paired with 100 real videos selected to have similar content. This careful construction aims to assess the model’s ability to distinguish between real and synthetic video data. All videos used in RivaBench are sourced from YouTube.
read the caption
Table 1: RivaBench basic statistics. The duration is given by mean ±plus-or-minus\pm± standard deviation. The SynthDec split contains 100 synthetic videos and 100 real videos that human annotators search to have similar content as synthetic videos. MCQ stands for multiple-choice questions. Video sources are all from YouTube.
In-depth insights#
Reasoning in LLMs#
Reasoning capabilities in large language models (LLMs) are a rapidly evolving area of research. Early approaches focused on prompt engineering and search algorithms to guide LLMs through complex problems. However, these methods proved inefficient and limited for intricate reasoning tasks. A significant advancement is the development of reinforcement learning techniques. Reinforcement learning (RL) based methods, such as Process Direct Preference Optimization (pDPO), optimize the reasoning process by directly rewarding or penalizing each step taken towards a solution. This contrasts with earlier methods that only considered the final outcome. Multimodal LLMs, those that integrate visual and audio inputs, further challenge the task of reasoning, requiring sophisticated reward modeling tailored to diverse sensory data. Effective benchmarks, such as RivaBench, are crucial for evaluating progress. The core challenge remains balancing model efficiency with accuracy and avoiding biases or hallucinations. Future work needs to focus on addressing the high computational cost of RL training for multimodal LLMs and developing robust methods that handle ambiguous or complex inputs.
Multimodal Reasoning#
Multimodal reasoning, a crucial aspect of artificial intelligence, focuses on the ability of systems to integrate and interpret information from diverse sources like text, images, audio, and video to solve complex problems. The key challenge lies in effectively fusing these heterogeneous data modalities, each with its own unique characteristics and representations. This integration requires advanced techniques capable of handling ambiguity, noise, and potentially conflicting information across modalities. Successful multimodal reasoning systems must be able to disambiguate meaning, establish relationships between different modalities, and generate coherent inferences that go beyond simple concatenation or averaging of individual modal outputs. Progress in this area relies heavily on robust feature extraction, efficient fusion mechanisms, and advanced reasoning algorithms that can handle multimodal contexts. The development of large-scale, high-quality datasets is vital for training and evaluating such systems, as well as the creation of new evaluation metrics that capture the nuances of multimodal reasoning capabilities. Future research should explore methods for improved explainability and interpretability, particularly crucial for building trust and understanding in these powerful systems.
pDPO Optimization#
The concept of pDPO (process direct preference optimization) presents a novel approach to enhance the reasoning capabilities of multimodal large language models (LLMs). Instead of directly predicting a numerical reward for each reasoning step, as in traditional methods, pDPO leverages contrastive learning. It compares the effectiveness of different reasoning steps within the same context, focusing on step-level pairwise comparisons rather than absolute scores. This is particularly beneficial for multimodal tasks, as the ambiguity in assessing numerical scores is mitigated. By employing a contrastive selection method, pDPO efficiently identifies and prioritizes the most critical reasoning steps that significantly affect the final outcome. This targeted approach improves training efficiency and reduces computational costs compared to methods relying on extensive rollouts. The innovative combination of contrastive step selection and pairwise reward modeling makes pDPO well-suited for the challenges of multimodal reasoning, where various modalities (audio, visual, text) must be effectively integrated. The results demonstrate that pDPO achieves significant performance improvements, highlighting its potential as a powerful technique for enhancing reasoning in complex, real-world scenarios.
RivaBench Dataset#
The RivaBench dataset represents a significant contribution to the field of multimodal reasoning, particularly for audio-visual large language models (LLMs). Its focus on challenging, high-quality question-answer pairs across diverse scenarios such as stand-up comedy, academic presentations, and synthetic video detection addresses a critical gap in existing benchmarks. The inclusion of detailed, expert-curated step-by-step solutions for each question makes RivaBench ideal for training and evaluating LLMs’ reasoning capabilities. The dataset’s three representative scenarios offer a variety of challenges: stand-up comedy tests the model’s ability to interpret humor within an audio-visual context; academic presentations assess its ability to process complex information and extract meaning; and synthetic video detection pushes the boundaries of zero-shot capabilities. The 4,000+ high-quality question-answer pairs within RivaBench ensure rigorous evaluation of models. By incorporating these varied settings, RivaBench facilitates a deeper understanding of the strengths and limitations of audio-visual LLMs, fostering the development of more robust and reliable models.
Zero-Shot Detection#
Zero-shot detection, in the context of this research paper, signifies the model’s ability to identify synthetic videos without prior training examples. This is a remarkable feat, showcasing the model’s robust generalization capabilities and deeper understanding of visual patterns. The paper highlights the enhanced reasoning abilities as the key contributor to this performance, suggesting that the model is not merely matching visual features but actively inferring the underlying characteristics of real versus synthetic videos. This capability goes beyond typical image classification tasks, showcasing the potential for broader applications in video authenticity verification, content generation evaluation, and anomaly detection. The success of zero-shot detection underlines the importance of reasoning-enhanced multimodal models in tackling complex visual understanding tasks. Further investigation could explore the limitations of this approach, its sensitivity to various types of synthetic videos, and how it can be improved with additional training or architectural refinements. The zero-shot nature of this capability suggests a step toward more generalizable and robust AI systems that can adapt to novel challenges with minimal additional training.
More visual insights#
More on figures

🔼 This figure illustrates the process of creating a dataset for fine-tuning (SFT) a large language model (LLM). The process starts with a video and its corresponding audio. Gemini-1.5-pro, a large language model, is used to generate a question-answer pair related to the video content, along with a step-by-step reasoning path that explains how to arrive at the answer. GPT-40, another LLM, then acts as a quality control mechanism, evaluating the validity and logical coherence of both the question-answer pair and the reasoning steps. Only those QA pairs and reasoning paths that pass GPT-40’s quality check are included in the final SFT dataset. This ensures that the model learns from high-quality, logically sound reasoning examples.
read the caption
Figure 2: Acquisition pipeline of reasoning-intensive SFT data. The question, answer and reasoning paths are generated by Gemini-1.5-pro taking the video with paired audio as inputs. GPT4o is employed for quality checks to ensure the QA-pair and the reasoning steps are valid and require logical thinking.

🔼 Figure 3 illustrates the process of contrastive step selection and pairwise rollout used in the process direct preference optimization (pDPO) method. The top panel shows how the top two most influential steps (s2 and s5) are selected for optimization. For each step, an alternative step is sampled to create a pair used for comparison. The bottom panel demonstrates the pairwise rollout process. For each step (like s2), multiple possible next steps are simulated (rollouts). These rollouts, starting from the same prefix, are then evaluated by GPT-40 to determine which is closer to the correct solution and thus which step was more effective.
read the caption
Figure 3: Illustration of the contrastive step selection (top) and pairwise rollout (bottom) to construct per-step expected correctness score for pDPO. Contrastive step selection: Top 2 steps, s2subscript𝑠2s_{2}italic_s start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT and s5subscript𝑠5s_{5}italic_s start_POSTSUBSCRIPT 5 end_POSTSUBSCRIPT are selected in this example, and for s2subscript𝑠2s_{2}italic_s start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT, an alternative step, s2′subscriptsuperscript𝑠′2s^{\prime}_{2}italic_s start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT, is sampled to form the preference pair. Pairwise rollout: Three rollouts are shown for each step and s2subscript𝑠2s_{2}italic_s start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT and s2′subscriptsuperscript𝑠′2s^{\prime}_{2}italic_s start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT are step pairs with the same prefix solution. The answer correctness is checked using GPT-4o by comparing it against the reference answer.

🔼 This figure shows the distribution of the number of reasoning steps in the supervised fine-tuning (SFT) data. The left panel displays the distribution for the entire SFT dataset, while the right panel focuses on a subset of the data specifically designed for reasoning-intensive tasks. The figure highlights that the reasoning-intensive subset, which contains more challenging questions, necessitates a greater number of reasoning steps for successful problem-solving, compared to the overall SFT dataset.
read the caption
Figure 4: Distributions of the numbers of reasoning steps in SFT data. Left: Distribution of the entire SFT data. Right: Distribution on the reasoning-intensive subset of SFT data. Due to the difficulty of the reasoning-intensive subset, more reasoning steps are required in general for samples in this set.

🔼 This figure compares the performance of the process direct preference optimization (pDPO) algorithm using different numbers of top steps selected for pairwise training. The x-axis represents the number of top steps selected, and the y-axis represents the accuracy. The results show that including intermediate steps in addition to full solution paths improves the overall accuracy of pDPO, suggesting that focusing on specific, error-prone steps enhances the model’s learning and reasoning capabilities. Note that pairs of full solution paths are always included in the training.
read the caption
Figure 5: Comparison between different top T steps selected for pDPO. Pairs of full solution paths are always used in addition to pairs of intermediate steps.

🔼 This figure shows an example from the reasoning-intensive SFT (Supervised Fine-Tuning) dataset. It illustrates a question-answer pair along with a step-by-step reasoning process. The visual input is a short video showing items made of glass and plastic. The question asks which material is better when considering frequent handling and minimal dropping risk. The provided answer is ’the glass one’, and the figure details a six-step reasoning path leading to that conclusion. This showcases the multimodal nature of the dataset, combining visual information from a video with text-based questions, answers, and reasoning steps.
read the caption
Figure 6: Example of reasoning SFT data

🔼 This figure shows an example from the StandUp comedy section of the RivaBench dataset. The example includes a short video clip, a question related to understanding the humor in the video, the correct answer, and an explanation clarifying why that answer is correct. The question requires the model to understand the interplay between the audio (comedian’s words), visual (comedian’s actions and facial expressions), and the audience’s reaction (laughter) to determine the humor’s source. It highlights the multi-modal nature of the reasoning required within RivaBench.
read the caption
Figure 7: Example of StandUp part of the RivaBench.

🔼 Figure 8 shows an example from the StandUp comedy subset of the RivaBench dataset. It displays a still image from a stand-up comedy video, the corresponding audio transcription, a multiple-choice question about the comedic effect of a particular line, the correct answer, and a detailed explanation justifying the answer. This exemplifies the type of high-quality, expert-annotated audio-visual reasoning data included in the RivaBench benchmark.
read the caption
Figure 8: Example of StandUp part of the RivaBench.

🔼 Figure 9 shows an example from the Academic portion of the RivaBench dataset. It displays a slide from an academic presentation about a twin study investigating the relationship between traumatic brain injury (TBI) and dementia. The figure also includes a portion of the accompanying audio transcript and the question and answer related to this video segment. The question assesses the study’s method for isolating the impact of TBI on dementia risk, while the answer explains how the twin study design controls for genetic and early life factors by analyzing twins with differing TBI and dementia onset.
read the caption
Figure 9: Example of Academic part of the RivaBench.

🔼 Figure 10 shows an example from the Academic portion of the RivaBench dataset. The figure contains a screenshot of a video showing students working on a hands-on electronics project using either a Zoom-based remote learning environment or a RobotAR augmented reality environment. Accompanying the video screenshot is a textual description of the key learning competencies tested (conceptual understanding of voltage and current, series and parallel circuits, use of a breadboard, multimeter, and building a working circuit). The results show that students in the RobotAR condition achieved greater competency in more of the learning objectives than their peers using Zoom. The caption references the improved performance with RobotAR.
read the caption
Figure 10: Example of Academic part of the RivaBench.

🔼 This figure shows an example video clip from the RivaBench benchmark’s SynthDec (synthetic video detection) partition. The SynthDec partition contains videos generated using AI, making it challenging to distinguish between real and synthetic content. This particular clip is likely intended to showcase a particularly difficult example or characteristic of synthetic videos for which visual reasoning is needed to accurately classify.
read the caption
Figure 11: Example video clip of the SynthDec part of RivaBench.

🔼 This figure shows a short video clip from the RivaBench dataset’s SynthDec (synthetic video detection) subset. The video clip is an example of a synthetic video, meaning it was artificially generated rather than recorded from real life. SynthDec is designed to test the ability of large language models to differentiate between real and synthetic videos. This specific clip likely contains visual anomalies or inconsistencies that are characteristic of AI-generated videos and would be used to train or evaluate such a model.
read the caption
Figure 12: Example video clip of the SynthDec part of RivaBench.

🔼 This figure shows a side-by-side comparison of how two different models, video-SALMONN-01 SFT and video-SALMONN-01 Process DPO, approached the same question from the StandUp subset of the RivaBench benchmark dataset. The StandUp subset contains comedic video clips. The video shows a comedian performing on stage. The question asks what the speaker implies by saying ‘I didn’t need to know that’ at the end of the video. Both models provide a step-by-step reasoning process leading to their respective answers. The figure highlights the differences in the reasoning process, showing how the enhanced reasoning capabilities of pDPO lead to a more accurate and nuanced understanding of the context compared to the simpler SFT model.
read the caption
Figure 13: Example video and solutions from the StandUp test set.

🔼 This figure showcases an example video frame from the VideoMME test set, accompanied by solution approaches from two distinct model versions: video-SALMONN-01 using standard supervised fine-tuning (SFT) and video-SALMONN-01 employing the proposed Process Direct Preference Optimization (pDPO). The video depicts a scene involving a character in a game being struck by a turret. The solutions highlight the different reasoning steps each model undertakes to arrive at its answer, and how pDPO leads to a more accurate response by leveraging its audio-visual reasoning capabilities.
read the caption
Figure 14: Example video and solutions from videoMME test set.

🔼 This figure showcases a video from the VideoMME test set and presents two different solution approaches generated by the model. The top solution demonstrates the model’s initial attempt using supervised fine-tuning (SFT), revealing a flawed reasoning process due to misinterpreting visual information (mistaking moonlit sky for the moon). The bottom solution illustrates the enhanced performance achieved through the proposed process direct preference optimization (pDPO) method. Using pDPO, the model correctly identifies the missing element in the video.
read the caption
Figure 15: Example video and solutions from videoMME test set.

🔼 This figure showcases a comparative analysis of three different large language models (LLMs) - video-SALMONN-01, GPT-4, and Gemini-1.5-pro - in their ability to detect synthetic videos. Each model is presented with the same video clip and asked to determine if it is synthetically generated or real. The figure displays the response of each model, highlighting the reasoning steps and the final conclusion reached by each model. This comparison underscores the varying capabilities of these LLMs in handling this nuanced task, demonstrating the strengths and weaknesses in their ability to process and interpret visual cues to identify artificial or synthetic video content.
read the caption
Figure 16: Example output from video-SALMONN-o1, GPT-4o and Gemini-1.5-pro for synthetic video detection.

🔼 Figure 17 shows a comparison of the outputs of three different large language models (LLMs) – video-SALMONN-01, GPT-4, and Gemini-1.5-pro – when tasked with detecting whether a video is synthetically generated or real. The models analyze the same video and provide a Yes/No answer, along with a step-by-step reasoning process justifying their conclusions. The figure highlights the differences in their reasoning abilities and the types of visual cues each model focuses on to arrive at its decision. This showcases the varying capabilities of these LLMs in identifying subtle visual artifacts characteristic of AI-generated videos.
read the caption
Figure 17: Example output from video-SALMONN-o1, GPT-4o and Gemini-1.5-pro for synthetic video detection.

🔼 Figure 18 illustrates the contrastive step selection process used in the process direct preference optimization (pDPO) method. Two example reasoning paths for answering a question about a video are shown, highlighting the step-by-step reasoning process. Each step in the reasoning path has an associated score (dsk), representing the sensitivity of that step to small perturbations in the input video. A higher dsk score indicates a greater sensitivity, suggesting that the model is more likely to make an error at that step. The figure demonstrates how the algorithm selects the most crucial steps for further optimization by focusing on steps with high dsk scores, particularly those where errors due to visual misinterpretations or hallucinations might occur. In this example, the third step in the first solution path demonstrates a visual hallucination, and hence it receives a very high dsk score and is selected for optimization via rollout.
read the caption
Figure 18: Example of the contrastive step selection process where two sampled paths are shown and the scores dsksubscript𝑑subscript𝑠𝑘d_{s_{k}}italic_d start_POSTSUBSCRIPT italic_s start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUBSCRIPT are given for each reasoning steps. The 3rd step in the first solution is wrong due to visual hallucination, and as a result, a very high score is assigned to that step and that step will be used to perform rollout.
More on tables
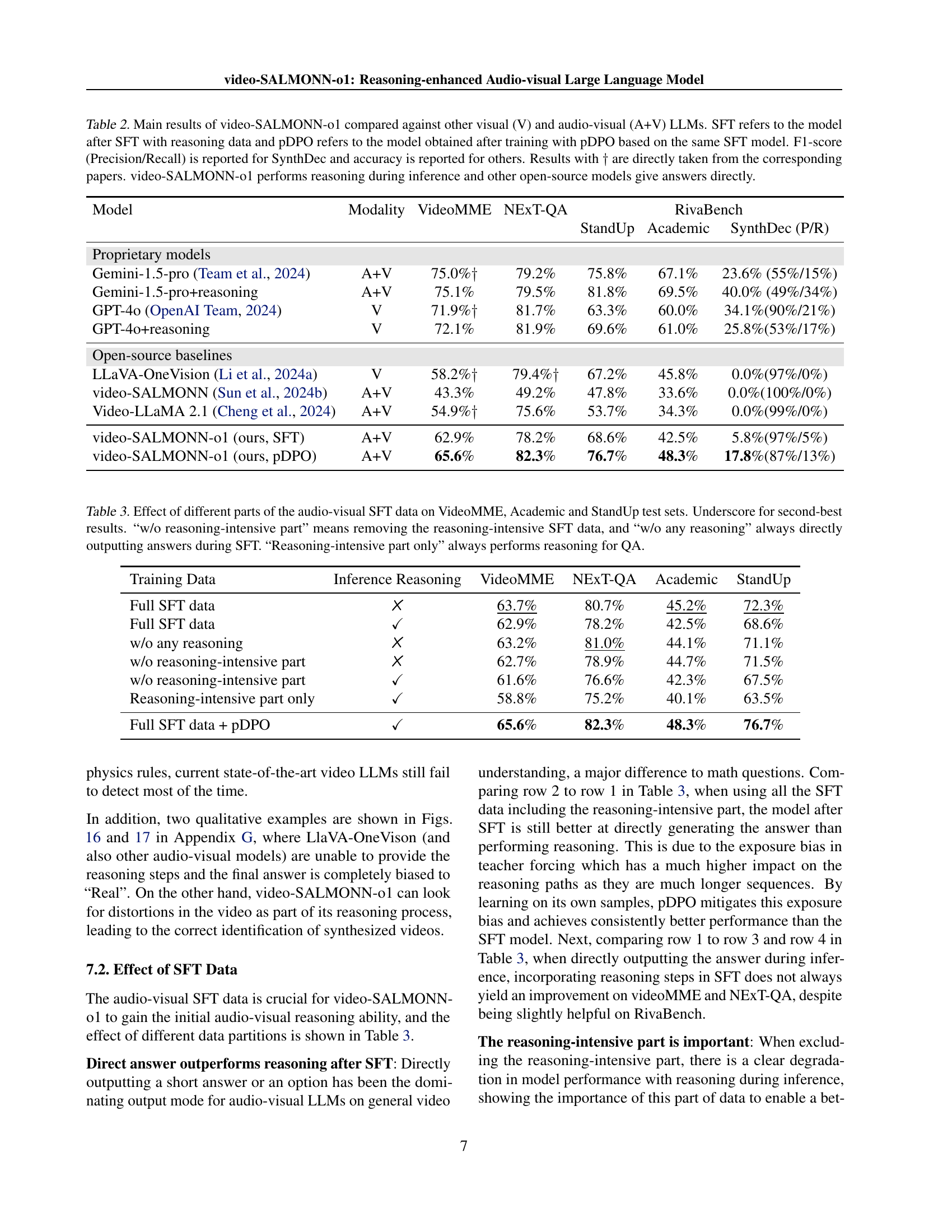
| Model | Modality | VideoMME | NExT-QA | RivaBench | ||
|---|---|---|---|---|---|---|
| StandUp | Academic | SynthDec (P/R) | ||||
| Proprietary models | ||||||
| Gemini-1.5-pro (Team et al., 2024) | A+V | 75.0% | 79.2% | 75.8% | 67.1% | 23.6% (55%/15%) |
| Gemini-1.5-pro+reasoning | A+V | 75.1% | 79.5% | 81.8% | 69.5% | 40.0% (49%/34%) |
| GPT-4o (OpenAI Team, 2024) | V | 71.9% | 81.7% | 63.3% | 60.0% | 34.1%(90%/21%) |
| GPT-4o+reasoning | V | 72.1% | 81.9% | 69.6% | 61.0% | 25.8%(53%/17%) |
| Open-source baselines | ||||||
| LLaVA-OneVision (Li et al., 2024a) | V | 58.2% | 79.4% | 67.2% | 45.8% | 0.0%(97%/0%) |
| video-SALMONN (Sun et al., 2024b) | A+V | 43.3% | 49.2% | 47.8% | 33.6% | 0.0%(100%/0%) |
| Video-LLaMA 2.1 (Cheng et al., 2024) | A+V | 54.9% | 75.6% | 53.7% | 34.3% | 0.0%(99%/0%) |
| video-SALMONN-o1 (ours, SFT) | A+V | 62.9% | 78.2% | 68.6% | 42.5% | 5.8%(97%/5%) |
| video-SALMONN-o1 (ours, pDPO) | A+V | 65.6% | 82.3% | 76.7% | 48.3% | 17.8%(87%/13%) |
🔼 This table presents the main results of the video-SALMONN-01 model on three video understanding benchmarks: VideoMME, NEXT-QA, and RivaBench. It compares the performance of video-SALMONN-01, after both supervised fine-tuning (SFT) with reasoning data and further optimization using process direct preference optimization (pDPO), against several other visual (V) and audio-visual (A+V) large language models (LLMs). The metrics used are accuracy for VideoMME, NEXT-QA, and the StandUp and Academic subsets of RivaBench, and F1-score (Precision/Recall) for the SynthDec subset of RivaBench. Results marked with a dagger (†) are taken directly from the cited papers. A key difference highlighted is that video-SALMONN-01 performs reasoning during inference, unlike the other open-source models which provide direct answers.
read the caption
Table 2: Main results of video-SALMONN-o1 compared against other visual (V) and audio-visual (A+V) LLMs. SFT refers to the model after SFT with reasoning data and pDPO refers to the model obtained after training with pDPO based on the same SFT model. F1-score (Precision/Recall) is reported for SynthDec and accuracy is reported for others. Results with ††\dagger† are directly taken from the corresponding papers. video-SALMONN-o1 performs reasoning during inference and other open-source models give answers directly.
| Training Data | Inference Reasoning | VideoMME | NExT-QA | Academic | StandUp |
|---|---|---|---|---|---|
| Full SFT data | 63.7% | 80.7% | 45.2% | 72.3% | |
| Full SFT data | 62.9% | 78.2% | 42.5% | 68.6% | |
| w/o any reasoning | 63.2% | 81.0% | 44.1% | 71.1% | |
| w/o reasoning-intensive part | 62.7% | 78.9% | 44.7% | 71.5% | |
| w/o reasoning-intensive part | 61.6% | 76.6% | 42.3% | 67.5% | |
| Reasoning-intensive part only | 58.8% | 75.2% | 40.1% | 63.5% | |
| Full SFT data + pDPO | 65.6% | 82.3% | 48.3% | 76.7% |
🔼 Table 3 analyzes how different subsets of the audio-visual supervised fine-tuning (SFT) data impact the model’s performance on three different benchmarks: VideoMME, Academic, and StandUp. It compares the full SFT data, data without the reasoning-intensive portion, data with only the reasoning intensive part, and data where the model directly outputs answers without any reasoning steps. The results show the accuracy of each configuration across the three benchmarks, highlighting the importance of reasoning-intensive data and the effect of removing it. Underscores indicate the second-best performance for easier comparison.
read the caption
Table 3: Effect of different parts of the audio-visual SFT data on VideoMME, Academic and StandUp test sets. Underscore for second-best results. “w/o reasoning-intensive part” means removing the reasoning-intensive SFT data, and “w/o any reasoning” always directly outputting answers during SFT. “Reasoning-intensive part only” always performs reasoning for QA.
| Training Configuration | Inference | VideoMME | NExT-QA | StandUp | Academic |
|---|---|---|---|---|---|
| SFT | 1-best | 62.9% | 78.2% | 68.6% | 42.5% |
| SFT | Major@20 | 63.5% | 81.5% | 73.5% | 45.3% |
| SFT + ORM | RM@20 | 62.7% | 78.5% | 69.0% | 42.6% |
| SFT + PRM | RM@20 | 63.5% | 79.3% | 72.1% | 43.9% |
| SFT + pDPO | 1-best | 65.6% | 82.3% | 76.7% | 48.3% |
🔼 This table compares the performance of different reward modeling methods on four video understanding benchmarks: VideoMME, NEXT-QA, StandUp (from RivaBench), and Academic (from RivaBench). The methods compared are standard supervised fine-tuning (SFT), SFT with outcome reward model (ORM), SFT with process reward model (PRM), and SFT with process direct preference optimization (pDPO). Performance is measured using two metrics: Major@20 (majority voting accuracy over 20 sampled reasoning paths) and RM@20 (best-of-n accuracy over 20 samples). The pDPO method, which uses preference pairs of complete reasoning paths, is highlighted as a key approach in the paper. The results demonstrate how the different reward models influence the ability of the large language model to reason through the video understanding problems.
read the caption
Table 4: Effect of different reward modelling methods on VideoMME, NExT-QA, the StandUp and Academic split of RivaBench. Major@20 and RM@20 are evaluated following Zhang et al. (2024a), where Major@20 refers to the accuracy under majority voting with 20 sampled paths, and RM@20 is the best-of-n with 20 samples. Samples are all generated from the model after SFT. pDPO with full paths only uses preference pairs of complete reasoning paths.
| Type | Prompt content |
|---|---|
| Direct answer | VIDEOSelect the best answer to the following question based on the video. Respond with only the letter of the correct option. |
| {Question} | |
| Choose from: A. {Option A}, B, {Option B}… | |
| Reasoning | VIDEO Question: |
| {Question} | |
| Choose from: A. {Option A}, B, {Option B}… | |
| Answer the question step by step. Output each thinking step. Mark the end of each step with end_of_step token. | |
| SynthDec | An AI-generated video contains unnatural distorted things, such as distorted hands or faces. Is the given video AI generated? Answer YES or NO. Answer step by step and output each step clearly. |
🔼 This table presents the prompt templates used for different task types in the video-SALMONN-01 model. It shows how the prompts are structured for direct answer tasks (requiring a single choice from provided options), reasoning tasks (requiring step-by-step explanations and a final answer), and synthetic video detection tasks (requiring identification of AI-generated video features and a yes/no answer). The different prompt structures illustrate how the model’s interaction and expected output vary based on the task demands.
read the caption
Table 5: Prompt used for different types of tasks.
Full paper#