TL;DR#
Large language models (LLMs) struggle with proof-oriented programming due to limited datasets for such languages like F*, and lack of large-scale, project-level implementations. This severely restricts the model’s ability to learn the complex reasoning processes involved. The absence of sufficient training data hinders the development of LLMs capable of reliably generating and verifying formal proofs for software. This is a crucial limitation given the increasing importance of formal verification in software development for enhancing software safety and security.
This paper introduces PoPilot, the first project-level formal verification specialist LLM. It tackles data scarcity through three key strategies: synthesizing basic proof-oriented programming problems, incorporating diverse coding data, and generating new proofs and repair data. PoPilot achieves a 64% relative performance margin over GPT-40 in project-level proof-oriented programming and improves GPT-40’s performance by 54% by repairing its outputs. This demonstrates the effectiveness of the proposed data-centric approach for enhancing LLMs’ proficiency in proof-oriented programming.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) and formal verification. It presents a novel approach to addressing data scarcity in proof-oriented programming, a significant challenge in the field. The synthetic data generation techniques and the impressive performance gains achieved open up new avenues for research into improving LLM capabilities in this domain and are highly relevant to the increasing focus on software safety and security.
Visual Insights#

🔼 This figure illustrates the pipeline used to generate repository-level data for training the proof-oriented programming model. It starts with existing type declarations and proofs from repositories. A problem synthesis loop generates new problems by creating variations of existing proofs, using an LLM to generate solutions (new problem-solution pairs). A repair loop is also included. This loop takes existing proofs that are erroneous and uses an LLM to attempt repair. The verification step uses F*’s solver to check the correctness of both newly generated and repaired proofs. The process then augments the existing data with these verified new and repaired problem-solution pairs, resulting in a richer and more diverse training dataset.
read the caption
Figure 1: Illustration of repository-level data generation pipeline.
| Model | Pass@1 | +Repair |
|---|---|---|
| Qwen-2.5-coder-7B-instruct | 0.25 | 0.30 |
| Qwen-2.5-coder-14B-instruct | 0.50 | 0.55 |
| Qwen-2.5-coder-32B-instruct | 0.48 | 0.58 |
| Qwen-2-72B-instruct | 0.34 | 0.43 |
| DeepSeek-Coder-V2-Lite-Instruct | 0.43 | 0.53 |
| LLama-3.1-70B | 0.21 | 0.27 |
| GPT-4o | 0.60 | 0.70 |
| Fine-tune Data Mixture | ||
| 54K F* Only | 0.42 | 0.47 |
| + Evol | 0.52 | 0.56 |
| 93K F* Only | 0.48 | 0.52 |
| + DSP-V1 | 0.52 | 0.54 |
| + DSP-V1 + Evol + CodeAlpaca + RBR | 0.58 | 0.62 |
| - F* NL2Code | 0.48 (-) | 0.52(-) |
🔼 This table compares the performance of various large language models (LLMs) on function-level proof-oriented programming tasks in the F* language. It shows the accuracy (Pass@1) of each model in generating correct code, as well as its ability to repair incorrect code (Pass@1+Repair). The models are tested with different mixtures of training data, including purely synthetic F* data, and data from other programming languages and datasets. The different data mixtures used are also described to show the effect of data diversity on model performance.
read the caption
Table 1: Performance comparison across different models and fine-tuning data mixtures. F* only: synthetic F* data, Evol: 80K (54K F*) / 50K (93K F*) Magicoder-Evol-Instruct data, DSP-V1: 20K Deepseek-Prover-V1 data, CodeAlpaca: 15K CodeAlpaca data, RBR: 15K RunBugRun data
In-depth insights#
Proof-Oriented LLM#
A Proof-Oriented LLM represents a significant advancement in large language model (LLM) capabilities, moving beyond traditional code generation towards formal verification. This involves not just producing code, but also generating and verifying mathematical proofs of its correctness. The core challenge addressed is the scarcity of training data in formal verification languages like F*, limiting the performance of existing LLMs. The proposed solution often incorporates data augmentation techniques that synthetically generate proof-oriented programming problems, teaching the model complex reasoning skills. The effectiveness of this approach is demonstrated by surpassing existing LLMs in project-level proof-oriented programming tasks, achieving significant performance gains under data scarcity. Synthetic data generation, in particular, becomes a crucial tool for bridging the data gap and accelerating development in this area. This research showcases the potential of LLMs to assist in ensuring software reliability and safety, where correctness guarantees are paramount.
Synthetic Data Aug#
The concept of ‘Synthetic Data Augmentation’ in the context of proof-oriented programming is crucial due to the scarcity of real-world data. Synthetic data generation effectively addresses the data limitations by creating artificial yet valid proof-oriented programming problems and solutions. This allows the training of large language models (LLMs) to improve their performance on tasks such as proof generation and repair, overcoming the bottleneck of insufficient high-quality data. The approach likely involves generating diverse problem types, controlling complexity levels, and ensuring correctness guarantees. The efficacy of this approach is evidenced by the reported performance gains, which likely result from the LLM learning fundamental patterns and intricate reasoning processes within a controlled environment. The success hinges on the quality and diversity of synthetic data, which needs to closely resemble real-world scenarios to ensure effective generalization. Furthermore, evaluation metrics are important to gauge the model’s improvement and robustness across varying problem complexities.
PoPilot: Model Details#
A hypothetical section titled ‘PoPilot: Model Details’ in a research paper would delve into the specifics of the PoPilot model’s architecture, training, and capabilities. It would likely begin by specifying the base model used, perhaps a large language model (LLM) like GPT-40 or a similar architecture, and how it was pre-trained. Crucially, details of the fine-tuning process would be provided, including the datasets used (synthetic and real-world F* code, potentially augmented with data from other programming languages), the training methods employed (e.g., supervised learning, reinforcement learning), and any hyperparameters adjusted. The section should also address the model’s size (number of parameters) and its performance metrics on relevant benchmark tasks for F* code generation, repair, and verification. Finally, a discussion of the model’s limitations and potential biases stemming from data scarcity or specific training techniques would demonstrate a rigorous and comprehensive analysis. Computational resource requirements during training and inference would also be valuable details.
Project-Level Eval#
A hypothetical ‘Project-Level Eval’ section in a research paper evaluating proof-oriented programming models would delve into the performance of these models on complex, real-world coding projects. This is crucial because function-level evaluations, while useful for benchmarking basic capabilities, often fail to capture the intricacies of large-scale codebases. Project-level evaluation would involve assessing the models’ ability to synthesize and repair proofs within existing repositories, considering factors such as code complexity, interdependencies, and the scale of the project. Key metrics might include the accuracy of proof generation and repair, the efficiency of the process (e.g., time taken), and the model’s capacity to handle errors gracefully. The results would demonstrate the models’ practical applicability and highlight any limitations, particularly in managing the complexity of large, multi-file projects. This section would likely be supported by a detailed case study showcasing the model’s performance on a representative real-world project, directly comparing it to state-of-the-art models or even human programmers. Ultimately, strong performance in this section would provide compelling evidence of the model’s readiness for real-world deployment and its potential for transforming software development practices.
Future Work#
Future research directions stemming from this work could explore extending the approach to other proof-oriented programming languages beyond F*, evaluating the model’s performance on larger, more complex, real-world projects, and investigating the integration of PoPilot with existing IDEs and development workflows. Further investigation into the generalizability of the synthetic data generation techniques to other domains with data scarcity would be valuable. A key area would be improving the model’s ability to handle more intricate and nuanced reasoning tasks, especially those involving complex inter-dependencies between code components. Finally, research on how PoPilot could be incorporated into automated software verification systems and its potential for identifying and correcting subtle bugs would significantly enhance its practical value and relevance.
More visual insights#
More on figures

🔼 This figure shows an example of a function-level proof-oriented programming problem in the F* programming language. It presents a function,
list_with_length, which takes a list of integers as input and returns a tuple containing the original list and its length. The task is to write an F* program that proves a property: for any list of integers, the length of the list returned bylist_with_lengthis equal to the length of the original list. The figure illustrates the problem statement, including the function code and the property to be proved, showcasing the formal verification aspect of proof-oriented programming.read the caption
Figure 2: Function-level Proof-oriented programming example.

🔼 Figure 3 is a bar chart comparing the lengths of generated definitions (synthetically created for the F* programming language) with the lengths of definitions found in existing F* repositories. The x-axis represents the length of the definitions (likely measured in characters or tokens), and the y-axis shows the frequency of definitions of that particular length. The chart helps to visualize the distribution of definition lengths in both the generated and existing datasets, demonstrating whether the generated data accurately reflects the length characteristics of real-world F* code.
read the caption
Figure 3: Length Comparison between Generated Definitions vs Existing Definitions.

🔼 This figure shows the results of using PoPilot to repair incorrect outputs generated by several state-of-the-art large language models (LLMs). The x-axis represents different LLMs, and the y-axis represents the percentage of correctly repaired outputs. The bars show the success rates for three different approaches: (1) Generation with 5 attempts at generation followed by 5 repair attempts (Gen@5+Self Repair@5), (2) Generation with 5 attempts and the use of PoPilot for repair (Gen@5 + Ours Repair@5), and (3) Generation with only 10 attempts at generation (Gen@10). The figure highlights PoPilot’s ability to significantly improve the repair performance of other models.
read the caption
Figure 4: PoPilot repairing failed outputs for state-of-the-art models.

🔼 This figure shows the distribution of the top ten error types found in the model-generated repair data. The data consists of incorrect proofs generated by a language model, which were then used as input to train a model for repairing erroneous proofs in a proof-oriented programming language, F*. The chart visualizes the frequency of different error types, providing insights into the types of errors most frequently made by the model. This information is valuable for understanding the model’s weaknesses and for guiding future data augmentation and model training efforts.
read the caption
Figure 5: Distribution of Top 10 Error Types of Model-Generated Repair Data.
More on tables
| Baseline Models | Generate@5 | Repair@5 | Gen+Rep (Total 10) | Generate@10 |
|---|---|---|---|---|
| Qwen2.5-Coder-32B-Instruct | 23.5 | 0.8 | 24.3 | 27.1 |
| Deepseek-Coder-33B-Instruct | 22.3 | 4.6 | 26.9 | 28.8 |
| GPT-4o | 22.2 | 1.7 | 23.9 | 23.8 |
| Qwen2.5-72B-Instruct | 23.4 | 3.0 | 26.4 | 25.8 |
| Llama-3.3-70B-Instruct-Turbo | 19.6 | 3.9 | 23.5 | 21.6 |
| Data Mixture | ||||
| Existing Repos | 30.7 | 1.0 | 31.7 | 35.3 |
| + Syn. Project Proof | 32.2 | 2.2 | 34.4 | 36.2 |
| + Func + Syn. Project Proof | 32.8 | 2.7 | 35.5 | 37.8 |
| + Syn. Project Proof + Syn. Repair | 32.7 | 0.7 | 33.4 | 37.5 |
| + Syn. Project Proof + Model Repair | 33.1 | 4.2 | 37.3 | 37.2 |
| + Syn. Project Proof + All Repair | 34.0 | 4.7 | 38.7 | 38.0 |
| PoPilot | 33.0 | 6.4 | 39.4 | 38.5 |
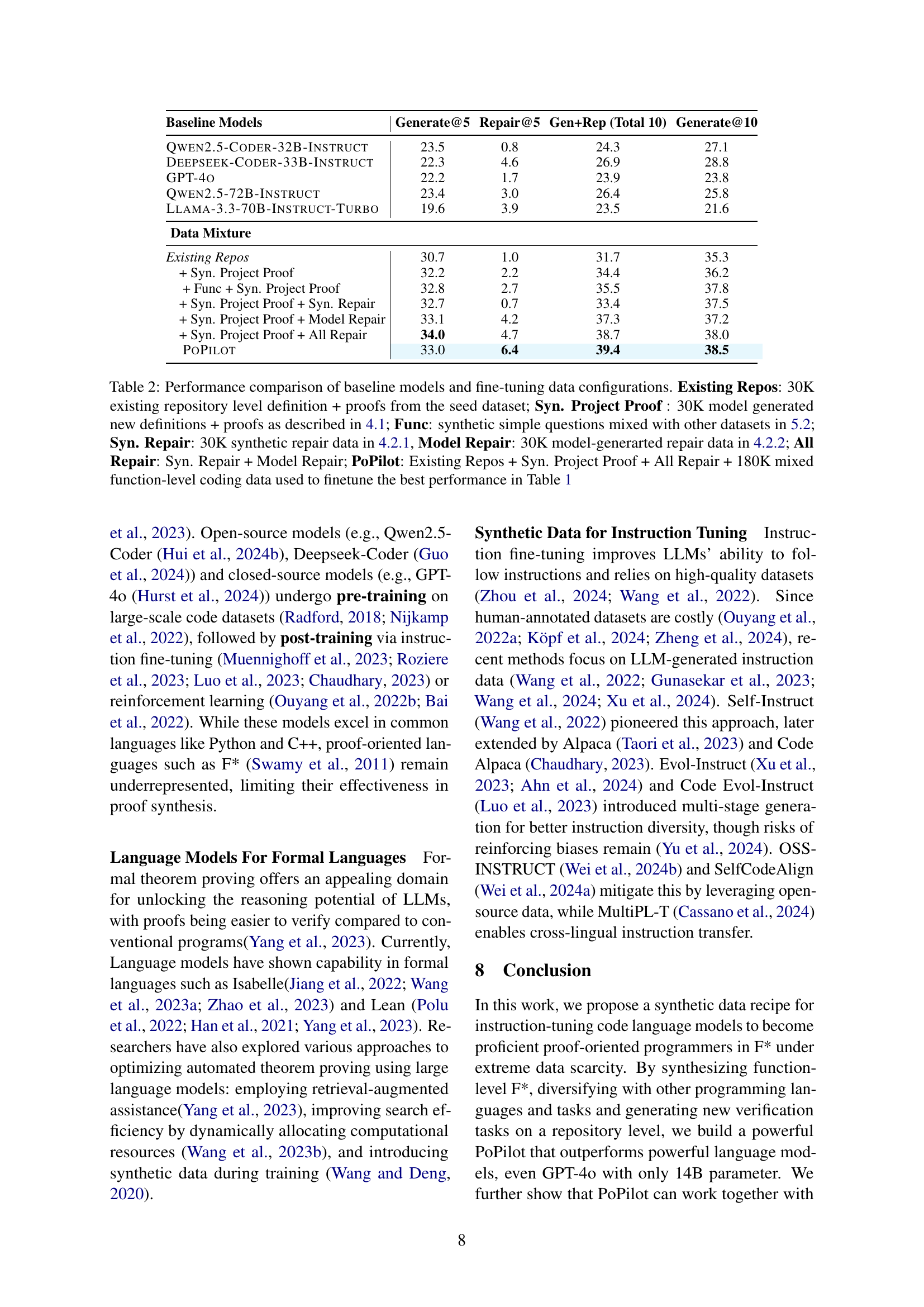
🔼 This table compares the performance of various large language models (LLMs) on proof generation and repair tasks, specifically focusing on the impact of different training data configurations. The baseline models are evaluated against a fine-tuned model (PoPilot). The training data configurations include: existing repository-level definitions and proofs (Existing Repos), synthetically generated project-level definitions and proofs (Syn. Project Proof), synthetic repair data (Syn. Repair), model-generated repair data (Model Repair), and a combination of all these data types (All Repair). PoPilot utilizes a combination of all data types, along with an additional 180K mixed function-level coding data. The metrics used are Generate@5 (successful generation within 5 attempts), Repair@5 (successful repair within 5 attempts), Gen+Rep (total of 10 attempts: 5 generation + 5 repair if needed), and Generate@10 (successful generation within 10 attempts).
read the caption
Table 2: Performance comparison of baseline models and fine-tuning data configurations. Existing Repos: 30K existing repository level definition + proofs from the seed dataset; Syn. Project Proof : 30K model generated new definitions + proofs as described in 4.1; Func: synthetic simple questions mixed with other datasets in 5.2; Syn. Repair: 30K synthetic repair data in 4.2.1, Model Repair: 30K model-generarted repair data in 4.2.2; All Repair: Syn. Repair + Model Repair; PoPilot: Existing Repos + Syn. Project Proof + All Repair + 180K mixed function-level coding data used to finetune the best performance in Table 1
| Model | Gen@5 | sample1-on-5 | sample5-on-1 |
|---|---|---|---|
| Our Best Model | 34 | +1.7 | +4.7 |
| Qwen2.5-Coder-32B | 23.5 | +0.8 | +7.8 |
| DS-Coder-33B | 22.3 | +4.6 | +9.8 |
🔼 This table compares two different strategies for repairing incorrect program proofs generated by a language model. The ‘sample1-on-5’ strategy attempts to repair each incorrect solution only once. In contrast, the ‘sample5-on-1’ strategy attempts to repair the same incorrect solution five times. The table shows the success rates (Generate@5 and Repair@5) for both methods across three different models, highlighting the impact of multiple repair attempts on overall accuracy.
read the caption
Table 3: Comparison of repair sampling strategies: sample1-on-5 repairs each incorrect solution once, while sample5-on-1 repairs the same incorrect solution multiple times.
| Baseline Models | Generate@5 | Repair@5 | Gen+Rep (Total 10) | Generate@10 |
|---|---|---|---|---|
| Qwen2.5-Coder-32B-Instruct | 23.5 | 0.8 | 24.3 | 27.1 |
| Deepseek-Coder-33B-Instruct | 22.3 | 4.6 | 26.9 | 28.8 |
| GPT-4o | 22.2 | 1.7 | 23.9 | 23.8 |
| Qwen2.5-72B-Instruct | 23.4 | 3.0 | 26.4 | 25.8 |
| Llama-3.3-70B-Instruct-Turbo | 19.6 | 3.9 | 23.5 | 21.6 |
| Fine-tuned model | ||||
| PoPilot-small | 21.9 | 3.9 | 25.8 | 29.2 |
| PoPilot | 33.0 | 6.4 | 39.4 | 38.5 |
🔼 Table 4 presents a performance comparison of a smaller language model (PoPilot-Small) fine-tuned using the same data as the larger PoPilot model. It contrasts the smaller model’s performance on proof generation and repair tasks with that of several baseline models including Qwen2.5-Coder-32B-INSTRUCT, DeepSeek-Coder-33B-INSTRUCT, GPT-40, Qwen2.5-72B-INSTRUCT, and Llama-3.3-70B-INSTRUCT-TURBO. The metrics used for comparison are Generate@5, Repair@5, Gen+Rep (Total 10), and Generate@10. The table highlights the smaller model’s performance relative to the larger model and the baseline models.
read the caption
Table 4: Performance comparison of the small model
Full paper#