TL;DR#
Web crawl is key for pretraining LLMs, but much crawled data gets discarded due to low quality. Traditional web crawlers prioritize graph connectivity, favoring high inlink counts which does not align well with LLM pretraining needs and causing computational waste and website burden. To address this inefficiency, this paper introduces CRAW4LLM, a novel web crawling method designed to enhance the efficiency of collecting high-quality pretraining data for LLMs.
Instead of relying on traditional graph-based metrics, CRAW4LLM prioritizes webpages based on their influence on LLM pretraining. It leverages a pretraining influence scorer derived from data-filtering pipelines to assess and rank newly discovered documents during each crawling iteration. Experiment results show that CRAW4LLM significantly improves crawling efficiency and reduces data waste, outperforming traditional methods by achieving similar performance with substantially less data.
Key Takeaways#
Why does it matter?#
This research offers a significant advancement in web crawling for LLM pretraining, addressing the critical issue of data quality and efficiency. By prioritizing pretraining influence, it reduces data processing waste and alleviates website burdens. It paves the way for more sustainable data acquisition, offering a new direction for future research to explore advanced, targeted crawling strategies.
Visual Insights#

🔼 This figure illustrates the difference in web graph traversal between a traditional graph-connectivity-based crawler and the proposed CRAW4LLM method. Both crawlers begin from the same seed URL (represented by a star). The traditional crawler (green) explores the web graph by prioritizing pages based on graph connectivity metrics (such as PageRank or harmonic centrality). This leads to a broad, but potentially inefficient, search of the web. Conversely, CRAW4LLM (red) prioritizes pages based on their relevance to LLM pretraining, focusing its search on a more targeted subset of web pages relevant for training large language models. This targeted approach is visualized by the red path which focuses on a smaller set of interconnected nodes.
read the caption
Figure 1: Graph traverse process of a traditional graph-connectivity-based crawler (green) and Craw4LLM (red) starting from a same seed URL (star).
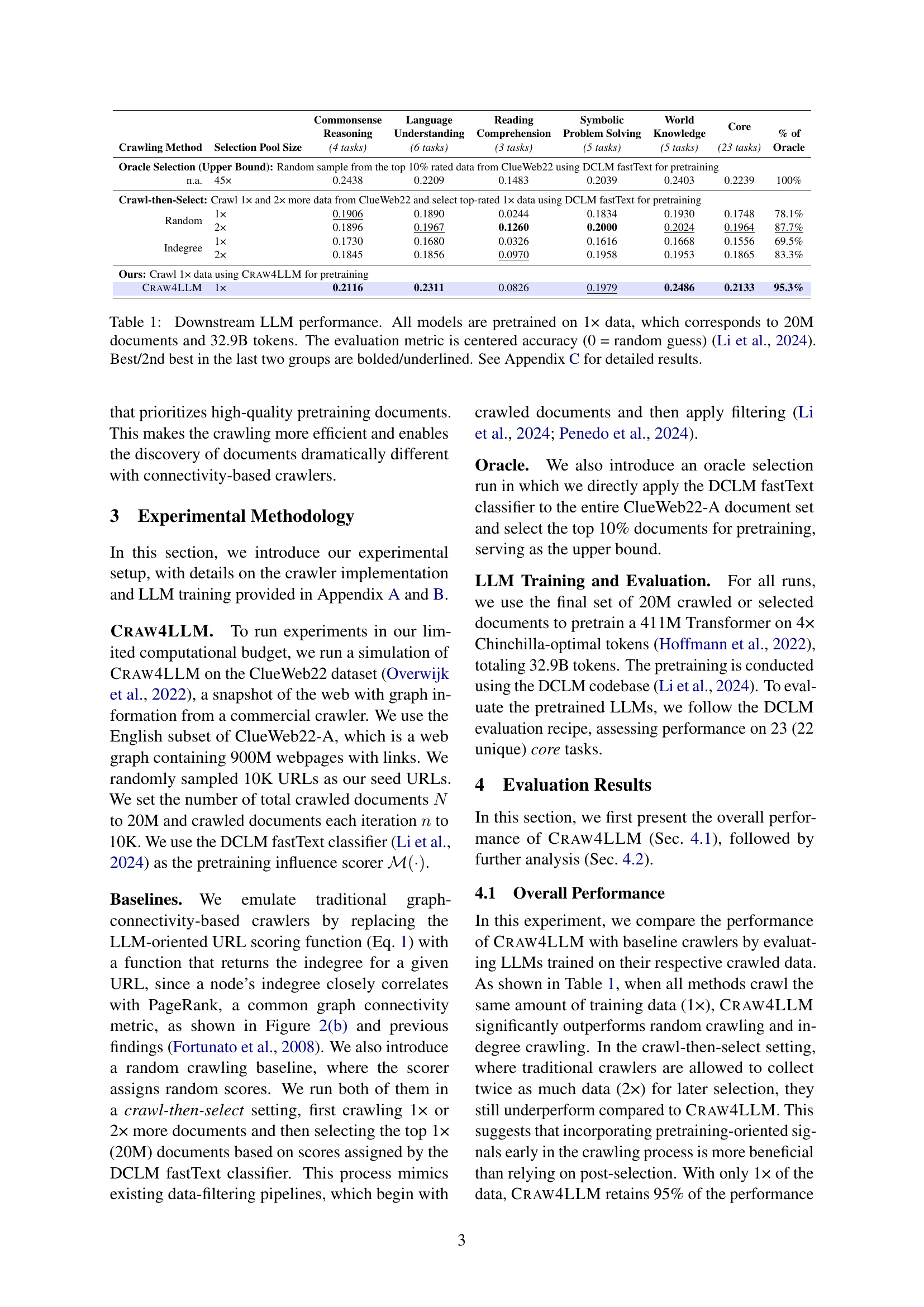
| Commonsense Reasoning | Language Understanding | Reading Comprehension | Symbolic Problem Solving | World Knowledge | Core | % of | ||
| Crawling Method | Selection Pool Size | (4 tasks) | (6 tasks) | (3 tasks) | (5 tasks) | (5 tasks) | (23 tasks) | Oracle |
| Oracle Selection (Upper Bound): Random sample from the top 10% rated data from ClueWeb22 using DCLM fastText for pretraining | ||||||||
| n.a. | 45× | 0.2438 | 0.2209 | 0.1483 | 0.2039 | 0.2403 | 0.2239 | 100% |
| Crawl-then-Select: Crawl 1× and 2× more data from ClueWeb22 and select top-rated 1× data using DCLM fastText for pretraining | ||||||||
| Random | 1× | 0.1906 | 0.1890 | 0.0244 | 0.1834 | 0.1930 | 0.1748 | 78.1% |
| 2× | 0.1896 | 0.1967 | 0.1260 | 0.2000 | 0.2024 | 0.1964 | 87.7% | |
| Indegree | 1× | 0.1730 | 0.1680 | 0.0326 | 0.1616 | 0.1668 | 0.1556 | 69.5% |
| 2× | 0.1845 | 0.1856 | 0.0970 | 0.1958 | 0.1953 | 0.1865 | 83.3% | |
| Ours: Crawl 1× data using Craw4LLM for pretraining | ||||||||
| Craw4LLM | 1× | 0.2116 | 0.2311 | 0.0826 | 0.1979 | 0.2486 | 0.2133 | 95.3% |
🔼 This table presents the downstream performance of Large Language Models (LLMs) trained using different web crawling methods. All models were pretrained on the same amount of data (1x, corresponding to 20 million documents and 32.9 billion tokens). The performance is evaluated across 23 core tasks using centered accuracy as the metric (where 0 represents a random guess). The table compares the performance of CRAW4LLM against baselines that use different crawling strategies (random crawling, indegree-based crawling, and a crawl-then-select approach with random and indegree baselines), as well as an oracle selection method representing an upper bound. The best and second-best performing methods in each comparison group are highlighted.
read the caption
Table 1: Downstream LLM performance. All models are pretrained on 1× data, which corresponds to 20M documents and 32.9B tokens. The evaluation metric is centered accuracy (0 = random guess) (Li et al., 2024). Best/2nd best in the last two groups are bolded/underlined. See Appendix C for detailed results.
In-depth insights#
LLM-Driven Crawl#
The concept of an LLM-driven crawl represents a paradigm shift in web data acquisition. Instead of relying on traditional metrics, the crawler prioritizes pages deemed most valuable for LLM pretraining. This approach is revolutionary because it aligns crawling with the specific needs of modern AI models. Such a system would necessitate a dynamic scoring mechanism, where the crawler continuously evaluates webpage relevance based on pretraining objectives. This could involve analyzing text quality, topic diversity, or even the presence of specific linguistic patterns known to benefit LLMs. By intelligently selecting data, an LLM-driven crawl promises to improve the efficiency of pretraining, reducing both computational costs and the environmental impact associated with large-scale data processing, and also reduce legal risks. This type of crawl reduces website burden, and is more sustainable.
Influence Scoring#
Influence scoring in web crawling for LLM pretraining prioritizes webpages based on their potential impact on the learning process. It replaces traditional methods reliant on graph connectivity metrics like PageRank, which often favor high-inlink documents, not necessarily aligned with high-quality pretraining data. This approach aims to address the inefficiency of conventional web crawlers, where a significant portion of collected data is discarded due to low quality. By scoring URLs using a pretraining-oriented function, the crawler can strategically explore the web graph, focusing on documents deemed more valuable for LLM pretraining. This enhances efficiency, reduces computational waste, and mitigates risks of over-crawling. Influence is often derived from data classification models trained to discern useful documents, allowing for a targeted and effective web crawling strategy.
Web Graph Traversal#
Web graph traversal is crucial for effective web crawling. Traditional methods often rely on graph connectivity metrics, such as PageRank and indegree, but may not align with the needs of LLM pretraining. Prioritizing webpages based on their influence on LLM pretraining, as proposed by CRAW4LLM, represents a significant shift. Efficient traversal strategies are essential to alleviate computational burdens, reduce website traffic, and address ethical and legal concerns related to data usage. By carefully selecting and prioritizing high-quality data sources, web graph traversal can be optimized to enhance the performance of LLMs while promoting responsible web crawling practices.
Ethical Crawling#
Ethical web crawling is a multifaceted challenge, balancing the need for data to train large language models (LLMs) with respecting website owners’ rights and resource limitations. Efficient crawling techniques are paramount, minimizing server load and reducing the risk of denial-of-service. Crawlers should adhere to robots.txt directives, respect crawl delays, and identify themselves clearly. Transparency is key; crawlers should disclose their purpose and contact information. Data usage also requires ethical consideration, focusing on fair use and mitigating potential biases. A crucial aspect involves obtaining consent where possible and respecting copyright laws to prevent misuse of copyrighted material. Regular audits and updates to crawling practices are essential to adapt to evolving web standards and ethical considerations. Furthermore, responsible data handling, including anonymization and secure storage, is crucial to protect user privacy. Ethical crawling is an ongoing process of refinement to ensure a sustainable and respectful relationship with the online ecosystem.
Dataset Efficiency#
From the perspective of dataset efficiency for LLM pretraining, the paper highlights the significance of prioritizing high-quality data. Traditional web crawling methods, often relying on graph-connectivity metrics, prove inefficient as much of the crawled data is discarded due to low quality. The introduction of CRAW4LLM addresses this by incorporating an LLM pretraining preference into the crawling process. By scoring webpages based on their pretraining influence, CRAW4LLM achieves superior performance with significantly less data. This targeted approach contrasts with indiscriminate crawling followed by data filtering, demonstrating the value of intelligent data acquisition. The reduction in crawling waste not only saves computational resources but also alleviates the burden on websites, promoting ethical and sustainable data collection.
More visual insights#
More on figures

🔼 The figure shows the correlation between pretraining influence scores and indegrees on randomly sampled ClueWeb22-B documents. Specifically, subplot (a) displays a weak negative correlation between pretraining influence scores and indegrees, indicating that documents with many incoming links are not necessarily the most influential for pretraining. The Spearman correlation coefficient is reported as -0.11, suggesting that a higher indegree does not strongly imply higher pretraining influence.
read the caption
(a) Pretraining (-0.11).
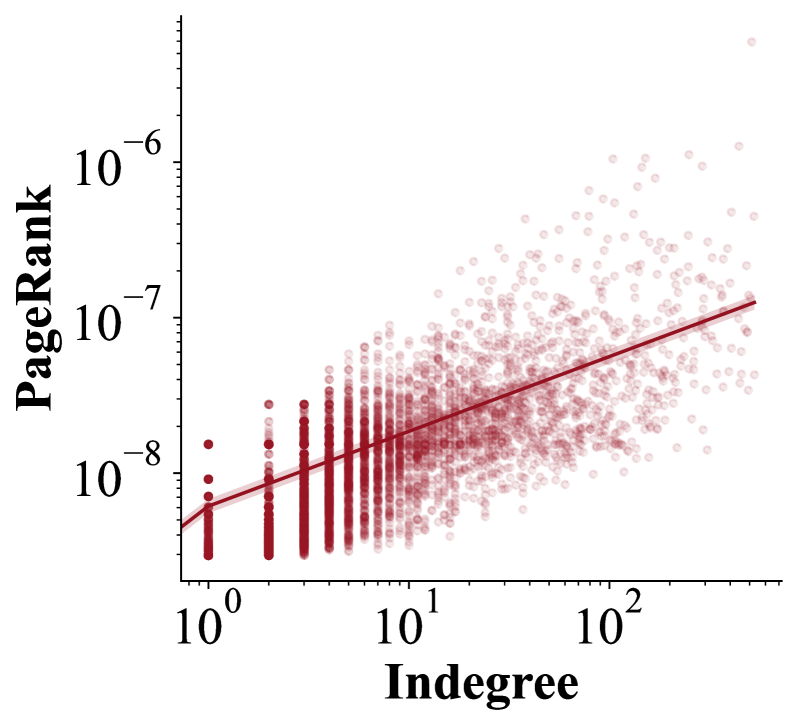
🔼 The figure shows the correlation between the pretraining influence scores and PageRank scores. The scatter plot visually represents the relationship between these two metrics, calculated on a randomly sampled subset of documents from the ClueWeb22-B dataset. The Spearman correlation coefficient (0.88) indicates a strong positive correlation, suggesting that documents with high PageRank scores tend to also have high pretraining influence scores.
read the caption
(b) PageRank (0.88).

🔼 This figure displays scatter plots illustrating the correlation between pretraining influence scores and other metrics on a subset of documents from the ClueWeb22-B dataset. The pretraining influence scores are derived from the DCLM fastText model. The plots visually compare the relationships between these scores and PageRank, as well as the relationship between PageRank and the number of inlinks (indegree). Spearman correlation coefficients are provided to quantify the strength of each correlation.
read the caption
Figure 2: Correlations between pretraining influence scores from DCLM fastText (Li et al., 2024) and PageRank to indegrees, on randomly sampled ClueWeb22-B documents (Overwijk et al., 2022). Spearman correlation coefficients are reported in parentheses.

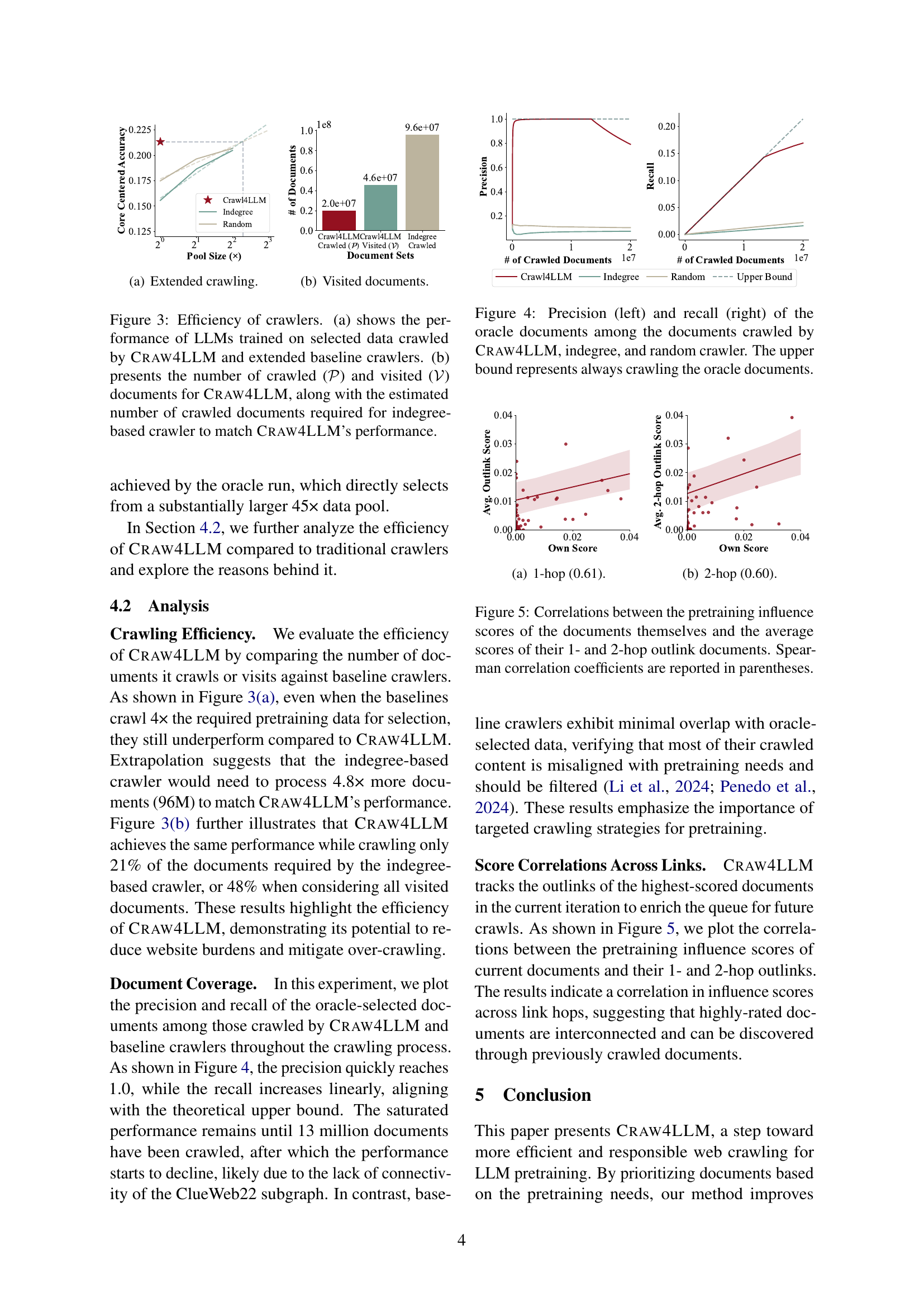
🔼 This figure shows the efficiency of different crawling methods in achieving comparable performance to the oracle method. The x-axis represents the pool size (relative to the oracle), indicating how much more data the crawlers processed than the oracle. The y-axis shows the performance of the LLMs trained on the data collected by each crawler. CRAW4LLM achieves nearly the same performance as the oracle by crawling significantly less data, while the other methods, including extended indegree and random crawling, require much larger amounts of data to reach comparable performance.
read the caption
(a) Extended crawling.

🔼 Figure 3(b) shows the number of documents visited and crawled by the CRAW4LLM crawler and baseline crawlers (Indegree and Random). It compares the number of documents crawled (P) to achieve a certain performance level against the number of documents visited (V) during the crawling process. This visualization highlights the efficiency of CRAW4LLM in achieving comparable performance with significantly fewer crawled and visited documents than traditional methods.
read the caption
(b) Visited documents.
🔼 Figure 3 delves into the efficiency of different web crawling methods. Subfigure (a) compares the performance of Large Language Models (LLMs) trained using data collected by Craw4LLM and traditional crawlers (extended baselines). The traditional crawlers are extended to crawl more data in an attempt to match Craw4LLM’s results. Subfigure (b) shows a quantitative comparison of the number of web pages crawled and visited by Craw4LLM versus the estimated number a traditional, indegree-based crawler would need to crawl to achieve similar LLM performance. This demonstrates Craw4LLM’s effectiveness in selecting high-quality data with far fewer crawls.
read the caption
Figure 3: Efficiency of crawlers. (a) shows the performance of LLMs trained on selected data crawled by Craw4LLM and extended baseline crawlers. (b) presents the number of crawled (𝒫𝒫\mathcal{P}caligraphic_P) and visited (𝒱𝒱\mathcal{V}caligraphic_V) documents for Craw4LLM, along with the estimated number of crawled documents required for indegree-based crawler to match Craw4LLM’s performance.

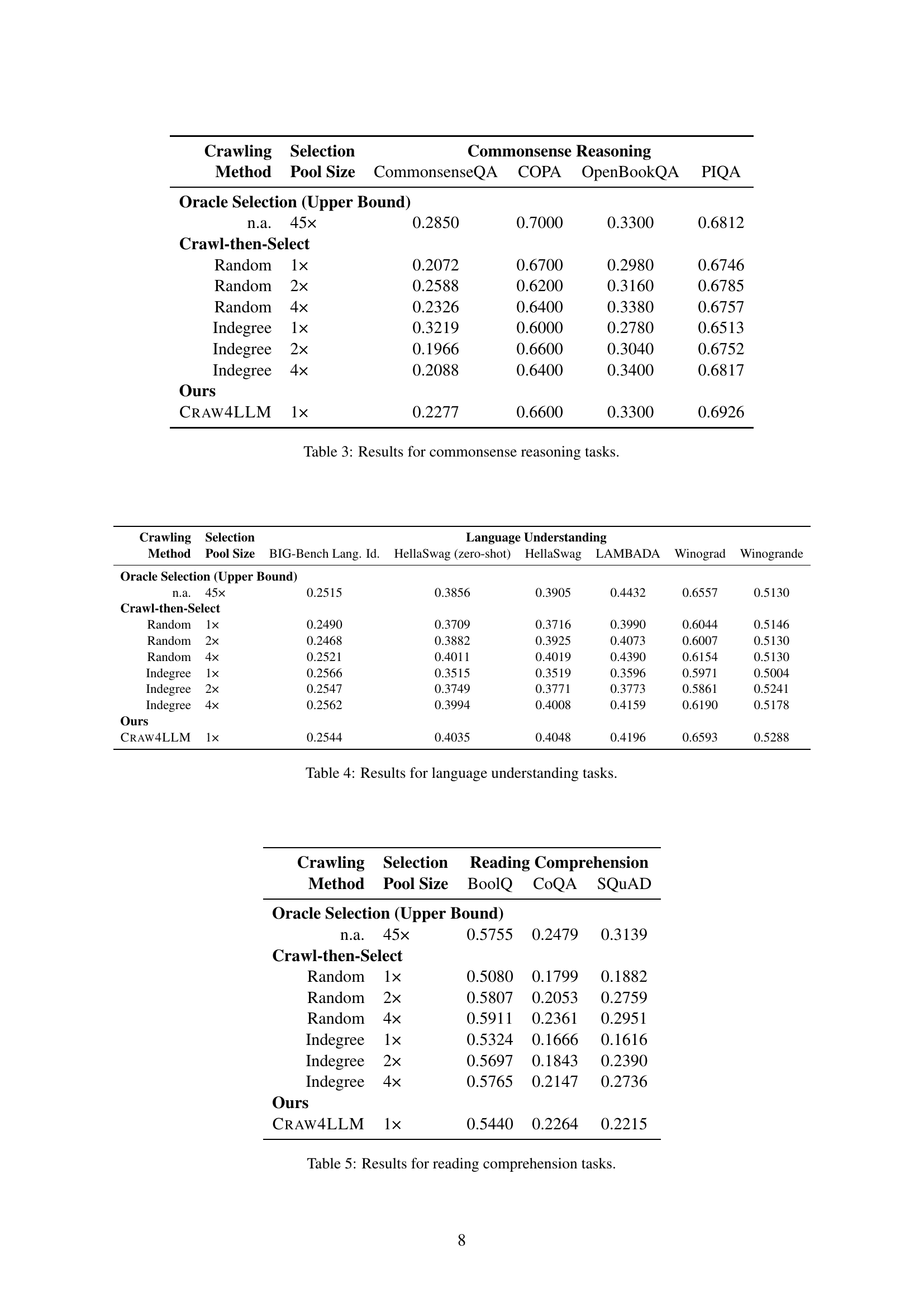
🔼 Figure 4 illustrates the effectiveness of CRAW4LLM in identifying high-quality documents for LLM pretraining. The left panel shows the precision (the percentage of truly valuable documents among those identified by each method) while the right panel shows the recall (the percentage of valuable documents found by each method). CRAW4LLM demonstrates high precision, quickly identifying nearly all the best documents. In contrast, the indegree-based and random crawling methods perform significantly worse. The upper bound line represents a hypothetical ideal scenario where only the best documents are collected.
read the caption
Figure 4: Precision (left) and recall (right) of the oracle documents among the documents crawled by Craw4LLM, indegree, and random crawler. The upper bound represents always crawling the oracle documents.
More on tables
| Hyper-parameter | Value |
| 24 | |
| 8 | |
| 1,024 | |
| 128 | |
| Warmup | 2,000 |
| Learning Rate | 3e-3 |
| Weight Decay | 0.033 |
| z-loss | 1e-4 |
| Global Batch Size | 512 |
| Sequence Length | 2048 |
🔼 This table lists the hyperparameters used for training the language model. It details the architecture of the model, including the number of layers, attention heads, the width of the model’s hidden layers (dmodel), and the width of each attention head (dhead). These parameters significantly influence the model’s capacity and performance.
read the caption
Table 2: Model and training hyper-parameters. nlayerssubscript𝑛layersn_{\text{layers}}italic_n start_POSTSUBSCRIPT layers end_POSTSUBSCRIPT, nlayerssubscript𝑛layersn_{\text{layers}}italic_n start_POSTSUBSCRIPT layers end_POSTSUBSCRIPT, dmodelsubscript𝑑modeld_{\text{model}}italic_d start_POSTSUBSCRIPT model end_POSTSUBSCRIPT, and dheadsubscript𝑑headd_{\text{head}}italic_d start_POSTSUBSCRIPT head end_POSTSUBSCRIPT denote the number of layers, attention heads, width, and width per attention head, respectively.
| Crawling | Selection | Commonsense Reasoning | |||
| Method | Pool Size | CommonsenseQA | COPA | OpenBookQA | PIQA |
| Oracle Selection (Upper Bound) | |||||
| n.a. | 45× | 0.2850 | 0.7000 | 0.3300 | 0.6812 |
| Crawl-then-Select | |||||
| Random | 1× | 0.2072 | 0.6700 | 0.2980 | 0.6746 |
| Random | 2× | 0.2588 | 0.6200 | 0.3160 | 0.6785 |
| Random | 4× | 0.2326 | 0.6400 | 0.3380 | 0.6757 |
| Indegree | 1× | 0.3219 | 0.6000 | 0.2780 | 0.6513 |
| Indegree | 2× | 0.1966 | 0.6600 | 0.3040 | 0.6752 |
| Indegree | 4× | 0.2088 | 0.6400 | 0.3400 | 0.6817 |
| Ours | |||||
| Craw4LLM | 1× | 0.2277 | 0.6600 | 0.3300 | 0.6926 |
🔼 This table presents the performance of different web crawling methods on commonsense reasoning tasks. It compares the performance of a baseline method (crawling a large amount of data and then selecting the top-performing subset) using random selection and indegree-based selection with the proposed CRAW4LLM method. The results are shown for different amounts of crawled data (1x, 2x, 4x) relative to the amount used in the CRAW4LLM method (1x). An oracle selection result (selecting the best 10% of data from the entire dataset) serves as an upper bound performance measure. The commonsense reasoning tasks evaluated are CommonsenseQA, COPA, OpenBookQA, and PIQA.
read the caption
Table 3: Results for commonsense reasoning tasks.
| Crawling | Selection | Language Understanding | |||||
| Method | Pool Size | BIG-Bench Lang. Id. | HellaSwag (zero-shot) | HellaSwag | LAMBADA | Winograd | Winogrande |
| Oracle Selection (Upper Bound) | |||||||
| n.a. | 45× | 0.2515 | 0.3856 | 0.3905 | 0.4432 | 0.6557 | 0.5130 |
| Crawl-then-Select | |||||||
| Random | 1× | 0.2490 | 0.3709 | 0.3716 | 0.3990 | 0.6044 | 0.5146 |
| Random | 2× | 0.2468 | 0.3882 | 0.3925 | 0.4073 | 0.6007 | 0.5130 |
| Random | 4× | 0.2521 | 0.4011 | 0.4019 | 0.4390 | 0.6154 | 0.5130 |
| Indegree | 1× | 0.2566 | 0.3515 | 0.3519 | 0.3596 | 0.5971 | 0.5004 |
| Indegree | 2× | 0.2547 | 0.3749 | 0.3771 | 0.3773 | 0.5861 | 0.5241 |
| Indegree | 4× | 0.2562 | 0.3994 | 0.4008 | 0.4159 | 0.6190 | 0.5178 |
| Ours | |||||||
| Craw4LLM | 1× | 0.2544 | 0.4035 | 0.4048 | 0.4196 | 0.6593 | 0.5288 |
🔼 This table presents the performance of different Language Models (LMs) on various language understanding tasks. The models were pre-trained using data obtained from different crawling methods: a baseline crawler using indegree as a priority metric, a random crawler, and the proposed CRAW4LLM method. The table shows the performance (accuracy) of each model across several benchmarks, including BIG-Bench, HellaSwag, LAMBADA, Winograd, and Winogrande. The ‘Pool Size’ column indicates how many times more data was crawled compared to the target training dataset size of 1x. The ‘Oracle Selection (Upper Bound)’ row shows the best possible result achievable by selecting the top 10% of data, based on the DCLM fastText classifier.
read the caption
Table 4: Results for language understanding tasks.
| Crawling | Selection | Reading Comprehension | ||
| Method | Pool Size | BoolQ | CoQA | SQuAD |
| Oracle Selection (Upper Bound) | ||||
| n.a. | 45× | 0.5755 | 0.2479 | 0.3139 |
| Crawl-then-Select | ||||
| Random | 1× | 0.5080 | 0.1799 | 0.1882 |
| Random | 2× | 0.5807 | 0.2053 | 0.2759 |
| Random | 4× | 0.5911 | 0.2361 | 0.2951 |
| Indegree | 1× | 0.5324 | 0.1666 | 0.1616 |
| Indegree | 2× | 0.5697 | 0.1843 | 0.2390 |
| Indegree | 4× | 0.5765 | 0.2147 | 0.2736 |
| Ours | ||||
| Craw4LLM | 1× | 0.5440 | 0.2264 | 0.2215 |
🔼 This table presents the results of the reading comprehension tasks, evaluated using three metrics: BoolQ, CoQA, and SQUAD. It compares the performance of Language Models (LLMs) trained on data obtained through different crawling methods and data selection strategies. The methods include a baseline using random selection, indegree-based crawling, and the proposed CRAW4LLM method, each with varying amounts of crawled data (1x, 2x, and 4x the size of the target dataset). An oracle selection represents the upper bound performance. The table shows the performance (accuracy) achieved by each method for each reading comprehension metric.
read the caption
Table 5: Results for reading comprehension tasks.
| Crawling | Selection | Symbolic Problem Solving | ||||
| Method | Pool Size | AGI Eval LSAT-AR | BIG-Bench CS Algorithms | BIG-Bench Dyck Lang. | BIG-Bench Operators | BIG-Bench Repeat Copy Logic |
| Oracle Selection (Upper Bound) | ||||||
| n.a. | 45× | 0.2739 | 0.4341 | 0.2160 | 0.2143 | 0.0625 |
| Crawl-then-Select | ||||||
| Random | 1× | 0.2391 | 0.4568 | 0.1970 | 0.2143 | 0.0000 |
| Random | 2× | 0.2696 | 0.4538 | 0.2520 | 0.1762 | 0.0313 |
| Random | 4× | 0.1957 | 0.4568 | 0.2600 | 0.1857 | 0.0625 |
| Indegree | 1× | 0.2304 | 0.4371 | 0.1900 | 0.1429 | 0.0000 |
| Indegree | 2× | 0.2609 | 0.4235 | 0.2340 | 0.2143 | 0.0313 |
| Indegree | 4× | 0.2174 | 0.4538 | 0.2530 | 0.1667 | 0.0938 |
| Ours | ||||||
| Craw4LLM | 1× | 0.2696 | 0.4371 | 0.1620 | 0.2095 | 0.0938 |
🔼 This table presents the performance of different web crawling methods on symbolic problem-solving tasks. It compares the results of using an oracle selection (the upper bound of performance), random crawling, indegree-based crawling (representing traditional graph-connectivity methods), and the proposed CRAW4LLM method. The table shows the performance across several different datasets and tasks, indicating how each crawling strategy impacts the downstream performance of LLMs trained on the data collected.
read the caption
Table 6: Results for symbolic problem solving tasks.
| Crawling | Selection | World Knowledge | ||||
| Method | Pool Size | ARC Easy | ARC Challenge | BIG-Bench-Bench QA Wikidata | Jeopardy | MMLU |
| Oracle Selection (Upper Bound) | ||||||
| n.a. | 45× | 0.5951 | 0.3166 | 0.4945 | 0.1176 | 0.2805 |
| Crawl-then-Select | ||||||
| Random | 1× | 0.5152 | 0.2799 | 0.5186 | 0.0461 | 0.2552 |
| Random | 2× | 0.5425 | 0.2807 | 0.5081 | 0.0648 | 0.2561 |
| Random | 4× | 0.5577 | 0.2867 | 0.5126 | 0.0970 | 0.2543 |
| Indegree | 1× | 0.4857 | 0.2509 | 0.4888 | 0.0138 | 0.2618 |
| Indegree | 2× | 0.5248 | 0.2790 | 0.5205 | 0.0555 | 0.2464 |
| Indegree | 4× | 0.5749 | 0.2935 | 0.5084 | 0.0959 | 0.2430 |
| Ours | ||||||
| Craw4LLM | 1× | 0.6103 | 0.3208 | 0.5143 | 0.1323 | 0.2661 |
🔼 This table presents the results of evaluating Large Language Models (LLMs) on world knowledge tasks. Different crawling methods (random, indegree-based, and CRAW4LLM) were used to gather data for LLM pretraining, with varying amounts of data collected (1x, 2x, and 4x the target dataset size for crawl-then-select methods). The ‘Oracle Selection’ row represents an upper bound, using the top-performing 10% of data. The table shows performance metrics for each method across several world knowledge benchmarks: ARC Easy, ARC Challenge, BIG-Bench QA, Wikidata, Jeopardy, and MMLU. This allows comparison of the efficiency of different crawling strategies in obtaining high-quality pretraining data that results in strong LLM performance on world knowledge tasks.
read the caption
Table 7: Results for world knowledge tasks.
Full paper#