TL;DR#
Photo Doodling involves artists adding decorative elements to enhance photographs. However, automating this process is challenging due to the need for seamless integration of elements, preservation of background consistency, and efficient style acquisition from limited data. Prevailing image editing methods fall short due to their focus on global style transfer or pixel-perfect user-defined masks, creating a gap in addressing the challenges.
To address these issues, this paper introduces PhotoDoodle, an image editing framework designed to learn artistic image editing from few-shot examples. This method employs a two-stage training pipeline with EditLoRA and introduces a PE Cloning strategy to enforce strict background consistency through implicit feature alignment, facilitating precise and style-conscious decorative generation. Additionally, the authors provide a dedicated photo-doodle dataset.
Key Takeaways#
Why does it matter?#
PhotoDoodle enables artistic photo editing via few-shot learning, offering a new approach to personalized image manipulation and style transfer. It advances customized image creation and opens new avenues for artistic expression and automation.
Visual Insights#

🔼 Figure 1 showcases PhotoDoodle’s ability to generate artistic photo edits. It demonstrates the system’s capacity to add decorative elements to photographs, mimicking the styles and techniques of human artists. Crucially, the examples highlight PhotoDoodle’s capability to seamlessly integrate these additions into the original photo, maintaining a consistent appearance between the before and after images. The edits range in style from adding cartoon elements and magical effects to incorporating hand-drawn lines and star decorations, illustrating the system’s versatility.
read the caption
Figure 1: PhotoDoodle can mimic the styles and techniques of human artists in creating photo doodles, adding decorative elements to photos while maintaining perfect consistency between the pre- and post-edit states.
| Methods | ↑ | ↑ | ↑ |
|---|---|---|---|
| Instruct-Pix2Pix | 0.237 | 38.201 | 0.806 |
| Magic Brush | 0.234 | 36.555 | 0.811 |
| SDEdit(FLUX) | 0.230 | 34.329 | 0.704 |
| Ours | 0.261 | 51.159 | 0.871 |
🔼 This table presents a quantitative comparison of different methods for general image editing tasks. The metrics used are CLIP Score, GPT Score, and CLIPimg, which assess the quality and alignment between generated images and text instructions. The results are compared to several baseline methods, and the best performance for each metric is highlighted in bold, allowing for easy identification of the superior method among those tested.
read the caption
Table 1: Comparison Results in General Image Editing Tasks. The best results are denoted as Bold.
In-depth insights#
PhotoDoodle#
The “PhotoDoodle” research paper introduces a novel image editing framework, PhotoDoodle, designed for photo doodling. It allows artists to overlay decorative elements seamlessly onto photographs, maintaining background consistency. The approach uses a two-stage training strategy: first, pre-training a general-purpose image editing model (OmniEditor), and then fine-tuning it with EditLoRA using a small, artist-curated dataset. This process captures distinct editing styles and techniques. The paper focuses on maintaining clean latent conditioning and using position encoding cloning for consistency, aiming to balance artistic flexibility and strict background preservation. They also introduce a dataset with 300 high-quality pairs across 6 artistic styles. The framework can learn artistic image editing from few-shot examples, showing advanced performance and robustness. The problem is that the inserted elements must appear seamlessly integrated with the background, requiring realistic blending, perspective alignment, and contextual coherence.
Artistic Editing#
Artistic image editing is a nuanced field aiming to augment photographs with decorative elements while maintaining a seamless blend with the background. Challenges include perspective alignment, contextual coherence, and preserving the original content’s integrity. The goal is to capture an artist’s unique style efficiently, often from limited data, differentiating it from global style transfer or regional inpainting. This requires innovative approaches beyond traditional image editing paradigms to achieve realistic blending and harmonious integration of new elements, ultimately enabling personalized and expressive photo enhancements.
Few-shot Data#
The paper addresses the challenge of learning artistic image editing from limited data, a scenario often termed “few-shot.” This is crucial because acquiring extensive paired data for each artist’s unique style is difficult and expensive. The approach, PhotoDoodle, focuses on efficient style capture from minimal examples, achieved by fine-tuning a pre-trained model (OmniEditor) with EditLoRA using only a small, artist-curated dataset. Few-shot learning enables adapting the model to new artistic styles quickly without extensive retraining. The framework leverages pre-training to build a strong foundation and implicit alignment strategies, like PE Cloning, to extract spatial correspondences and ensure consistency without adding training parameters.
Style Transfer#
Style transfer, in the context of image editing, involves modifying an image to adopt the visual characteristics of another, be it another image or a particular artistic style, and plays a pivotal role in PhotoDoodle. The paper leverages EditLoRA module to efficiently capture and transfer unique artistic styles from few-shot examples by fine-tuning a pre-trained diffusion model on artist-curated before-and-after image pairs. This is achieved by training the EditLora steers the behaviour of the OmniEditor to the specified artist’s style by generating Itar that reflects both the previously learned editing capabilities and the distinctive stylistic effects from the artist. The technique ensures that transferred styles seamlessly integrate into the target image while preserving the structural and contextual integrity of the original content.
EditLoRA#
EditLoRA seems to be a crucial component for style transfer in the image editing framework, efficiently adapting the base model to specific artistic styles from limited data. It uses Low-Rank Adaptation (LoRA) to fine-tune a small subset of parameters, reducing overfitting risk while preserving the pre-trained model’s capabilities. The EditLoRA training set differs from standard image generation, utilizing before-and-after image pairs and text instructions. It guides the OmniEditor to generate images reflecting both learned editing capabilities and distinctive stylistic effects, tailoring the model’s behavior to the artist’s unique style.
More visual insights#
More on figures

🔼 PhotoDoodle’s architecture involves a two-stage training process. First, a high-rank LoRA (Low-Rank Adaptation) trains the OmniEditor on a large dataset for general image editing and text-to-image generation. Second, a low-rank LoRA fine-tunes the EditLoRA on a smaller dataset of artist-specific photo doodles (before-and-after pairs). This captures individual artists’ unique styles. During inference, the original image is encoded as a condition token and concatenated with a noisy latent token. MMAttention (Multi-Modal Attention) controls the generation based on these inputs.
read the caption
Figure 2: The overall architecture and training prodigim of photodoodle. The ominiEditor and EditLora all follow the lora training prodigm. We use a high rank lora for pre-training the OmniEditor on a large-scale dataset for general-purpose editing and text-following capabilities, and a low rank lora for fine-tuning EditLoRA on a small set of paired stylized images to capture individual artists’ specific styles and strategies for efficient customization. We encode the original image into a condition token and concatenate it with a noised latent token, controlling the generation outcome through MMAttention.

🔼 Figure 3 showcases the results of PhotoDoodle, demonstrating its ability to generate high-quality photo doodles that seamlessly blend artistic styles with original images. The examples show how PhotoDoodle can mimic diverse artistic techniques, including adding decorative elements, applying stylized modifications, and maintaining contextual coherence. The figure highlights PhotoDoodle’s capacity for instruction-driven image editing, where specific instructions guide the generation of personalized photo doodles, resulting in images consistent with both the user’s request and the artist’s style.
read the caption
Figure 3: The generated results of PhotoDoodle. PhotoDoodle can mimic the manner and style of artists creating photo doodles, enabling instruction-driven high-quality image editing.

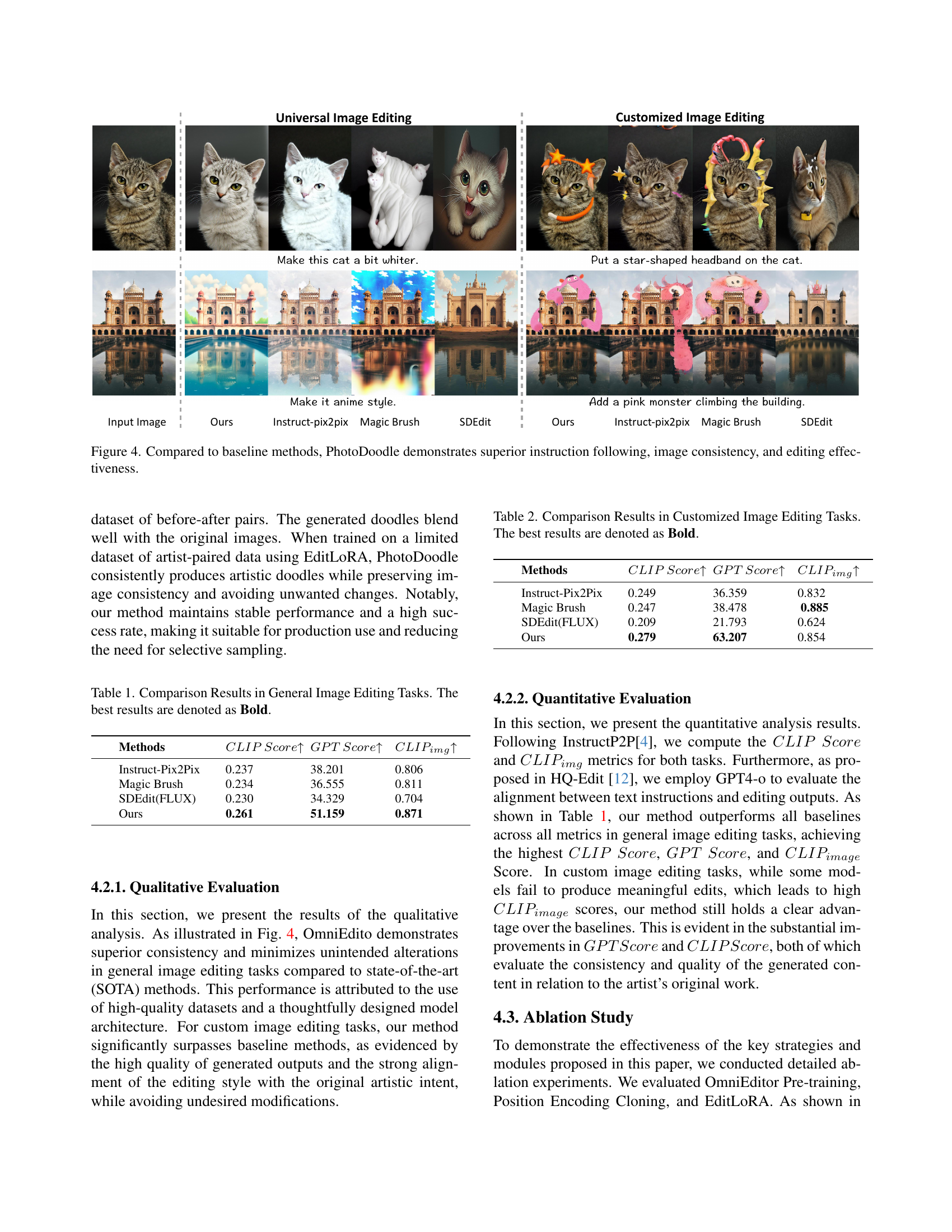
🔼 Figure 4 presents a qualitative comparison of PhotoDoodle against three baseline methods (InstructPix2Pix, MagicBrush, and SDEdit) in both universal and customized image editing tasks. The top row showcases universal image editing, where the instruction is relatively simple and general. The bottom row depicts customized image editing with more complex and specific directives. For each task and method, the input image, the result from each method, and the instruction are shown. The figure highlights PhotoDoodle’s superior performance in accurately following instructions (instruction following), maintaining the original image’s consistency (image consistency), and producing effective and high-quality edits (editing effectiveness). PhotoDoodle produces results that are visually more pleasing and closely adhere to the instructions given, compared to the noticeably inferior results of the baselines.
read the caption
Figure 4: Compared to baseline methods, PhotoDoodle demonstrates superior instruction following, image consistency, and editing effectiveness.

🔼 This ablation study analyzes the impact of different components of the PhotoDoodle model on its performance. The figure shows that removing any key component significantly degrades the results. Specifically: * No OmniEditor Pre-training: Training EditLoRA alone significantly reduces the harmony between sketches and photos and impairs the model’s ability to follow text instructions accurately. This highlights the importance of the OmniEditor’s general-purpose image editing capabilities as a foundation. * No Position Encoding Cloning: Removing this mechanism reduces output consistency and introduces unwanted background modifications. This demonstrates the crucial role of maintaining background consistency during the editing process. * Only Pre-trained OmniEditor (No EditLoRA): Using only the pre-trained model without fine-tuning it with EditLoRA significantly reduces the degree of stylization. This shows that EditLoRA is essential for learning and applying the unique editing styles of individual artists.
read the caption
Figure 5: Ablation study results. Without OmniEditor pre-training, training EditLoRA directly reduces the harmony between sketches and photos and weakens text-following capabilities; removing Position Encoding Cloning decreases output consistency and introduces unwanted background changes; using only pre-trained OmniEditor without EditLoRA significantly reduces the degree of stylization.
Full paper#