TL;DR#
Existing LLM evaluation focuses on constraint satisfaction, overlooking structural dependency between dialogue turns. This results in a failure to model complex real-world scenarios and methodological biases, which impacts the coherence and analytical depth of dialogue systems.
To address these limitations, this paper introduces StructFlowBench, a multi-turn benchmark with structural flow modeling, including 6 inter-turn relationships. The study systematically evaluates 13 LLMs to reveal deficiencies in understanding dialogue structures, offering insights for improving multi-turn instruction following.
Key Takeaways#
Why does it matter?#
This paper introduces a novel benchmark, StructFlowBench, which incorporates a multi-turn structural flow framework for instruction-following tasks. The benchmark addresses the critical gap in current evaluation methods by emphasizing the structural dependency between dialogue turns, moving beyond simple constraint satisfaction. It encourages researchers to develop more contextually aware and structurally coherent dialogue systems. The systematic evaluation of various LLMs provides valuable insights for optimizing dialogue systems and advancing research in human-AI interaction.
Visual Insights#

🔼 This figure presents a taxonomy of six fundamental inter-turn relationships in multi-turn dialogues. These relationships are: Follow-up, Refinement, Recall, Summary, Expansion, and Unrelatedness. Each relationship is visually represented, showing how subsequent turns in a conversation relate to previous turns. The taxonomy provides a framework for analyzing existing dialogues and generating new dialogues with specified structural flows, allowing for more nuanced and controlled evaluation of multi-turn instruction following capabilities.
read the caption
Figure 1: The Structural Flow Taxonomy includes six fundamental structures, each used to describe the inter-turn relationships in multi-turn dialogues. It can be applied to analyze any dialogue and generate specific structural flows.
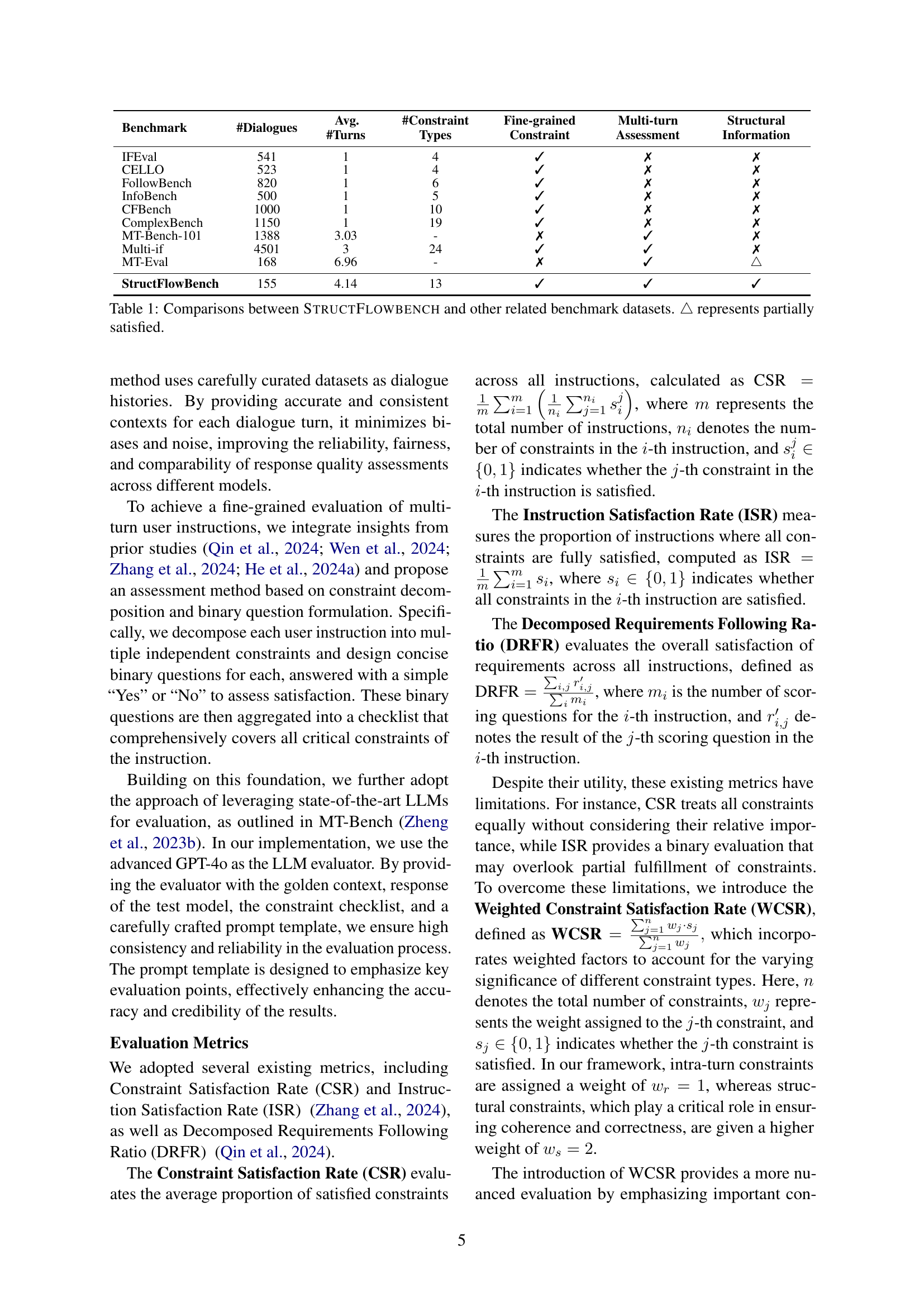
| Benchmark | #Dialogues | Avg. #Turns | #Constraint Types | Fine-grained Constraint | Multi-turn Assessment | Structural Information |
|---|---|---|---|---|---|---|
| IFEval | 541 | 1 | 4 | ✓ | ✗ | ✗ |
| CELLO | 523 | 1 | 4 | ✓ | ✗ | ✗ |
| FollowBench | 820 | 1 | 6 | ✓ | ✗ | ✗ |
| InfoBench | 500 | 1 | 5 | ✓ | ✗ | ✗ |
| CFBench | 1000 | 1 | 10 | ✓ | ✗ | ✗ |
| ComplexBench | 1150 | 1 | 19 | ✓ | ✗ | ✗ |
| MT-Bench-101 | 1388 | 3.03 | - | ✗ | ✓ | ✗ |
| Multi-if | 4501 | 3 | 24 | ✓ | ✓ | ✗ |
| MT-Eval | 168 | 6.96 | - | ✗ | ✓ | |
| StructFlowBench | 155 | 4.14 | 13 | ✓ | ✓ | ✓ |
🔼 This table compares StructFlowBench against other multi-turn dialogue and instruction following benchmarks. It highlights key differences in the number of dialogues, average turns per dialogue, the number of constraint types used for evaluation, whether fine-grained constraints were included in the evaluation, whether the benchmark assesses multi-turn dialogue capabilities, and whether structural information was considered in the evaluation. The symbol ‘△△’ indicates that some constraints might be partially satisfied.
read the caption
Table 1: Comparisons between StructFlowbench and other related benchmark datasets. △△\triangle△ represents partially satisfied.
In-depth insights#
StructFlowBench#
StructFlowBench, a novel instruction-following benchmark, introduces a multi-turn structural flow framework. It addresses limitations in existing benchmarks that overlook the crucial structural dependency between dialogue turns. By defining six fundamental inter-turn relationships (Follow-up, Refinement, Recall, Summary, Expansion, Unrelatedness), it introduces novel structural constraints for model evaluation. It has a Dual-constraint evaluation system, combining intra-turn instruction constraints with newly proposed structural constraints, to ensure logical coherence across turns. This enables a comprehensive assessment of LLMs’ multi-turn dialogue capabilities and comprehension of multi-turn dialogue structures and user intent.
Dual-Constraint Eval#
While the research paper doesn’t have an explicit section titled ‘Dual-Constraint Eval’, the concept is woven into the study of multi-turn instruction following. It implies a methodology where LLMs are evaluated based on satisfying two distinct sets of constraints simultaneously: intra-turn and inter-turn. Intra-turn constraints, cover aspects within a single dialogue turn such as content accuracy or style. The innovation lies in also assessing LLMs against inter-turn, or structural constraints across multiple turns, ensuring logical coherence or intent carryover. This duality enhances the assessment, preventing models from acing individual responses but failing in conversation-level coherence, thereby creating a higher standard for multi-turn dialogue systems.
6-Flow Taxonomy#
The research introduces a novel structural flow taxonomy, comprising six fundamental inter-turn relationships: Follow-up, Refinement, Recall, Summary, Expansion, and Unrelatedness. This taxonomy is pivotal for understanding and analyzing the structural dynamics of multi-turn dialogues, a capability often overlooked in existing LLM evaluations. By categorizing how dialogue turns relate to each other, the taxonomy enables a more nuanced assessment of an LLM’s ability to maintain coherence, track user intent, and generate contextually appropriate responses across multiple turns. The significance of each relationship is highlighted; for instance, ‘Refinement’ indicates an LLM’s capacity to adapt to user corrections, while ‘Recall’ demonstrates its memory of previous interactions. The taxonomy also serves as a basis for controlled dialogue generation, allowing researchers to create datasets with predefined structural patterns, which are crucial for training and evaluating LLMs in more realistic and complex conversational scenarios.
Dataset Analysis#
A comprehensive dataset analysis would be pivotal in understanding the benchmark’s robustness. It should detail the dataset’s size, distribution across different structural flows, and the diversity of topics covered. Analyzing the constraint types and their prevalence would reveal the benchmark’s focus. Moreover, examining the dialogue turn lengths and the complexity of the language used could provide insights into the challenge posed to LLMs. Understanding data generation and augmentation is important to assess potential biases. Finally, studying real-world scenario mapping is important in gauging the benchmark’s applicability.
Model Weakness#
Current LLMs struggle with complex, multi-turn dialogues, exhibiting instability in maintaining context and coherence. Mid-tier models often falter in Instruction Satisfaction Rate and Weighted Constraint Satisfaction Rate, indicating difficulty in complex constraint management. Refinement tasks pose a significant challenge, revealing a need for improved dynamic response adaptation. Format consistency remains a key limitation, suggesting further advancements are required in generating structured outputs. These weaknesses highlight the importance of StructFlowBench in identifying and addressing areas for improvement in multi-turn instruction-following models.
More visual insights#
More on figures

🔼 The figure illustrates the three-stage pipeline for constructing the StructFlowBench dataset. First, parameters such as the task type, topic, user type, and structural flow template are defined. Second, a two-step dialogue generation process creates the dialogue data. This begins with generating intermediate dialogue plans (summarized prompts) from the structural flow templates, followed by generating complete dialogues from these plans using GPT-4. Finally, the generated dialogues undergo constraint extraction. Intra-turn constraints are extracted automatically using GPT-4, while the structural constraints are added based on the predefined structural flow information.
read the caption
Figure 2: The construction pipeline of StructFlowBench. First, tasks, topics, user types, and structural flow templates are defined. Then, dialogue data is generated in two steps: intermediate dialogue plans (i.e., the summarized prompts) are created from the structural flow, followed by generating complete dialogues from these plans. Finally, intra-turn constraints are extracted by GPT-4o, and structural constraints are added based on the structural flow information.
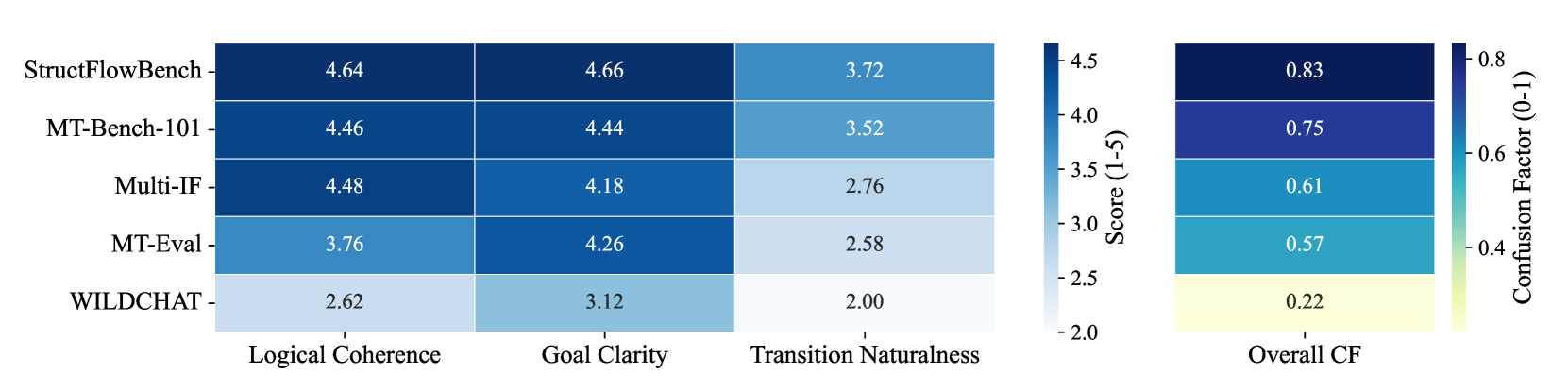
🔼 This heatmap visualizes a comparative analysis of five multi-turn dialogue datasets across three key aspects: logical coherence, goal clarity, and transition naturalness. Each dataset’s performance is rated on a scale of 1 to 5 for each aspect, with 5 representing the highest score. Additionally, a ‘Confusion Factor’ is calculated to indicate the proportion of dialogues in each dataset that scored 4 or higher, suggesting a higher likelihood of being mistaken for real human interactions. This provides a comprehensive overview of the suitability of each dataset for evaluating complex conversational scenarios.
read the caption
Figure 3: The comprehensive complex scenario evaluation heatmap of five multi-turn dialogue datasets.

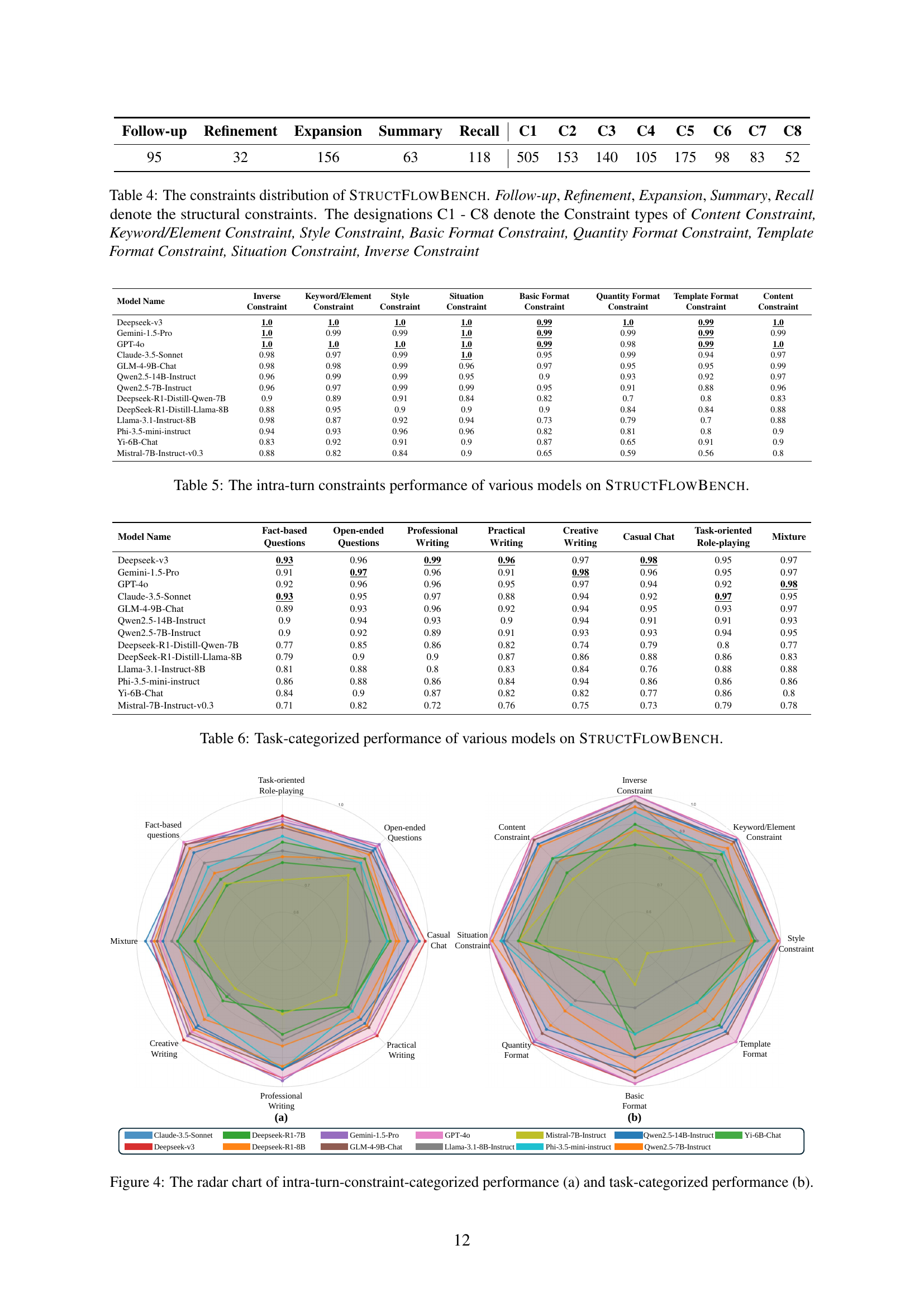
🔼 Figure 4 presents a comparative analysis of the performance of various LLMs across two different categorization schemes. Panel (a) shows the models’ performance across various intra-turn constraints, such as content, style, format, keyword, and inverse constraints. Each axis represents a constraint type, and the distance from the center indicates the model’s proficiency in that constraint. Panel (b) displays the models’ performance across seven different task categories, including fact-based questions, open-ended questions, practical writing, creative writing, professional writing, casual chat, and task-oriented role-playing. This allows for a comprehensive view of the strengths and weaknesses of each model across both constraint types and task types.
read the caption
Figure 4: The radar chart of intra-turn-constraint-categorized performance (a) and task-categorized performance (b).

🔼 This template guides the generation of intermediate dialogue plans. It structures the process by first requiring understanding of background knowledge and a dialogue structure template. Then, it specifies setting a user purpose (topic and type) and defining the overall user goal. Finally, it details generating summarized user prompts for each turn in the dialogue, ensuring they align naturally with the overall dialogue structure and user goals. The output format is specified to ensure consistency and usability.
read the caption
Figure 5: Intermediate Dialogue Plan Generation Template

🔼 This figure displays the prompt template used to generate complete dialogues from the intermediate dialogue plans. The prompt instructs the model to expand the summarized user prompts into realistic and detailed user prompts, incorporating various constraints from the ‘Constraint Guideline.’ These constraints ensure the expanded prompts align with the summarized prompts, reflecting genuine user inquiries and adhering to specified user characteristics. The output should follow a JSON format. The template includes sections for background information and specific instructions to guide the model’s response generation.
read the caption
Figure 6: Complete Dialogue Generation Prompt Template

🔼 This figure details the prompt template used for extracting constraints from a multi-turn dialogue. The prompt instructs an LLM to identify and categorize atomic constraint expressions from a given user prompt. It defines atomic constraint expressions as the smallest units describing task requirements within instructions. The prompt provides examples and a guideline specifying the types and definitions of atomic constraints (e.g., Inverse Constraint, Keyword/Element Constraint, Style Constraint). The output format is JSON, structured to categorize each extracted constraint by type, content (expressed as a question), and an explanation justifying the type classification.
read the caption
Figure 7: Constraint Extraction Prompt Template

🔼 Figure 8 presents the prompt template utilized for the GPT-40 evaluation in the StructFlowBench. This template guides the GPT-40 model in assessing the alignment of an LLM response with the corresponding user prompt and its specified constraints. It provides GPT-40 with the conversation history, the user’s prompt, the LLM’s response, and a checklist of constraints to verify. The output from GPT-40 consists of a ‘yes’ or ’no’ judgment for each constraint, accompanied by a detailed explanation justifying the decision.
read the caption
Figure 8: GPT-4o Evaluation Prompt Template
More on tables
| Model Name | follow-up | refinement | expansion | summary | recall | CSR | ISR | WCSR | DRFR |
|---|---|---|---|---|---|---|---|---|---|
| Deepseek-v3 | 0.99 | 0.8 | 0.92 | 1.0 | 1.0 | 0.98 | 0.93 | 0.96 | 0.98 |
| Gemini-1.5-Pro | 0.97 | 0.78 | 0.91 | 1.0 | 0.94 | 0.97 | 0.91 | 0.95 | 0.97 |
| GPT-4o | 0.98 | 0.78 | 0.88 | 0.97 | 0.91 | 0.97 | 0.9 | 0.95 | 0.97 |
| Claude-3.5-Sonnet | 0.98 | 0.8 | 0.88 | 1.0 | 0.91 | 0.95 | 0.88 | 0.94 | 0.96 |
| GLM-4-9B-Chat | 0.95 | 0.75 | 0.84 | 0.97 | 0.94 | 0.95 | 0.86 | 0.93 | 0.95 |
| Qwen2.5-14B-Instruct | 0.97 | 0.73 | 0.87 | 0.97 | 0.97 | 0.94 | 0.84 | 0.92 | 0.94 |
| Qwen2.5-7B-Instruct | 0.95 | 0.76 | 0.9 | 0.94 | 0.97 | 0.94 | 0.84 | 0.92 | 0.94 |
| Deepseek-R1-Distill-Qwen-7B | 0.91 | 0.62 | 0.85 | 0.86 | 0.78 | 0.81 | 0.69 | 0.8 | 0.82 |
| DeepSeek-R1-Distill-Llama-8B | 0.94 | 0.73 | 0.82 | 0.89 | 0.84 | 0.87 | 0.79 | 0.86 | 0.87 |
| Llama-3.1-Instruct-8B | 0.96 | 0.71 | 0.84 | 0.79 | 0.94 | 0.85 | 0.68 | 0.83 | 0.86 |
| Phi-3.5-mini-instruct | 0.94 | 0.68 | 0.87 | 0.94 | 0.94 | 0.88 | 0.73 | 0.87 | 0.88 |
| Yi-6B-Chat | 0.98 | 0.62 | 0.87 | 0.84 | 0.94 | 0.86 | 0.7 | 0.84 | 0.86 |
| Mistral-7B-Instruct-v0.3 | 0.97 | 0.59 | 0.87 | 0.71 | 0.97 | 0.77 | 0.56 | 0.76 | 0.78 |
🔼 This table presents a comprehensive evaluation of thirteen large language models (LLMs) on the StructFlowBench benchmark. The left half shows each model’s performance across five fundamental structural constraints (Follow-up, Refinement, Expansion, Summary, Recall) within multi-turn dialogues. The right half displays the models’ overall performance using four key metrics: Constraint Satisfaction Rate (CSR), Instruction Satisfaction Rate (ISR), Weighted Constraint Satisfaction Rate (WCSR), and Decomposed Requirements Following Ratio (DRFR). These metrics assess the models’ ability to understand and correctly follow both individual constraints and the overall structure of the multi-turn instructions.
read the caption
Table 2: StructFlowBench rated by GPT-4o. The left side displays the performance of various models on the five basic structural constraints, while the right side presents their performance on the four key metrics.
| Category | #Dialogues |
|---|---|
| Fact-based Questions | 25 |
| Open-ended Questions | 20 |
| Practical Writing | 26 |
| Creative Writing | 21 |
| Professional Writing | 21 |
| Casual Chat | 15 |
| Task-oriented Role Play | 17 |
| Mixture | 10 |
| Total | 155 |
🔼 Table 3 presents the distribution of tasks within the StructFlowBench dataset. It shows the number of dialogues included for each of the nine task types used in the benchmark. These tasks cover various NLP domains, ensuring a comprehensive evaluation of different instruction-following capabilities.
read the caption
Table 3: Task distribution of StructFlowBench dataset.
| Follow-up | Refinement | Expansion | Summary | Recall | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 95 | 32 | 156 | 63 | 118 | 505 | 153 | 140 | 105 | 175 | 98 | 83 | 52 |
🔼 This table presents the distribution of constraints within the StructFlowBench dataset. It breaks down the number of instances for each of the five structural constraints (Follow-up, Refinement, Expansion, Summary, Recall) and the eight intra-turn constraint types (Content, Keyword/Element, Style, Basic Format, Quantity Format, Template Format, Situation, and Inverse). This shows the frequency of different constraint types used in creating the multi-turn dialogues within the benchmark dataset.
read the caption
Table 4: The constraints distribution of StructFlowBench. Follow-up, Refinement, Expansion, Summary, Recall denote the structural constraints. The designations C1 - C8 denote the Constraint types of Content Constraint, Keyword/Element Constraint, Style Constraint, Basic Format Constraint, Quantity Format Constraint, Template Format Constraint, Situation Constraint, Inverse Constraint
| Model Name | Inverse Constraint | Keyword/Element Constraint | Style Constraint | Situation Constraint | Basic Format Constraint | Quantity Format Constraint | Template Format Constraint | Content Constraint |
|---|---|---|---|---|---|---|---|---|
| Deepseek-v3 | 1.0 | 1.0 | 1.0 | 1.0 | 0.99 | 1.0 | 0.99 | 1.0 |
| Gemini-1.5-Pro | 1.0 | 0.99 | 0.99 | 1.0 | 0.99 | 0.99 | 0.99 | 0.99 |
| GPT-4o | 1.0 | 1.0 | 1.0 | 1.0 | 0.99 | 0.98 | 0.99 | 1.0 |
| Claude-3.5-Sonnet | 0.98 | 0.97 | 0.99 | 1.0 | 0.95 | 0.99 | 0.94 | 0.97 |
| GLM-4-9B-Chat | 0.98 | 0.98 | 0.99 | 0.96 | 0.97 | 0.95 | 0.95 | 0.99 |
| Qwen2.5-14B-Instruct | 0.96 | 0.99 | 0.99 | 0.95 | 0.9 | 0.93 | 0.92 | 0.97 |
| Qwen2.5-7B-Instruct | 0.96 | 0.97 | 0.99 | 0.99 | 0.95 | 0.91 | 0.88 | 0.96 |
| Deepseek-R1-Distill-Qwen-7B | 0.9 | 0.89 | 0.91 | 0.84 | 0.82 | 0.7 | 0.8 | 0.83 |
| DeepSeek-R1-Distill-Llama-8B | 0.88 | 0.95 | 0.9 | 0.9 | 0.9 | 0.84 | 0.84 | 0.88 |
| Llama-3.1-Instruct-8B | 0.98 | 0.87 | 0.92 | 0.94 | 0.73 | 0.79 | 0.7 | 0.88 |
| Phi-3.5-mini-instruct | 0.94 | 0.93 | 0.96 | 0.96 | 0.82 | 0.81 | 0.8 | 0.9 |
| Yi-6B-Chat | 0.83 | 0.92 | 0.91 | 0.9 | 0.87 | 0.65 | 0.91 | 0.9 |
| Mistral-7B-Instruct-v0.3 | 0.88 | 0.82 | 0.84 | 0.9 | 0.65 | 0.59 | 0.56 | 0.8 |
🔼 This table presents a detailed breakdown of the performance of various Large Language Models (LLMs) on the intra-turn constraints within the StructFlowBench benchmark. It shows how well each model satisfied eight different types of intra-turn constraints: Content, Keyword/Element, Style, Basic Format, Quantity Format, Template Format, Situation, and Inverse. The performance is likely quantified numerically, potentially with a score or percentage reflecting the success rate of each LLM on each constraint type.
read the caption
Table 5: The intra-turn constraints performance of various models on StructFlowBench.
| Model Name | Fact-based Questions | Open-ended Questions | Professional Writing | Practical Writing | Creative Writing | Casual Chat | Task-oriented Role-playing | Mixture |
|---|---|---|---|---|---|---|---|---|
| Deepseek-v3 | 0.93 | 0.96 | 0.99 | 0.96 | 0.97 | 0.98 | 0.95 | 0.97 |
| Gemini-1.5-Pro | 0.91 | 0.97 | 0.96 | 0.91 | 0.98 | 0.96 | 0.95 | 0.97 |
| GPT-4o | 0.92 | 0.96 | 0.96 | 0.95 | 0.97 | 0.94 | 0.92 | 0.98 |
| Claude-3.5-Sonnet | 0.93 | 0.95 | 0.97 | 0.88 | 0.94 | 0.92 | 0.97 | 0.95 |
| GLM-4-9B-Chat | 0.89 | 0.93 | 0.96 | 0.92 | 0.94 | 0.95 | 0.93 | 0.97 |
| Qwen2.5-14B-Instruct | 0.9 | 0.94 | 0.93 | 0.9 | 0.94 | 0.91 | 0.91 | 0.93 |
| Qwen2.5-7B-Instruct | 0.9 | 0.92 | 0.89 | 0.91 | 0.93 | 0.93 | 0.94 | 0.95 |
| Deepseek-R1-Distill-Qwen-7B | 0.77 | 0.85 | 0.86 | 0.82 | 0.74 | 0.79 | 0.8 | 0.77 |
| DeepSeek-R1-Distill-Llama-8B | 0.79 | 0.9 | 0.9 | 0.87 | 0.86 | 0.88 | 0.86 | 0.83 |
| Llama-3.1-Instruct-8B | 0.81 | 0.88 | 0.8 | 0.83 | 0.84 | 0.76 | 0.88 | 0.88 |
| Phi-3.5-mini-instruct | 0.86 | 0.88 | 0.86 | 0.84 | 0.94 | 0.86 | 0.86 | 0.86 |
| Yi-6B-Chat | 0.84 | 0.9 | 0.87 | 0.82 | 0.82 | 0.77 | 0.86 | 0.8 |
| Mistral-7B-Instruct-v0.3 | 0.71 | 0.82 | 0.72 | 0.76 | 0.75 | 0.73 | 0.79 | 0.78 |
🔼 This table presents a detailed breakdown of the performance of thirteen different large language models (LLMs) on various tasks within the StructFlowBench benchmark. It shows how well each model performs on specific tasks such as fact-based questions, open-ended questions, creative writing, professional writing, casual chat, task-oriented role-playing, and a mixed task. The results offer insights into the strengths and weaknesses of each LLM across different types of dialogue tasks.
read the caption
Table 6: Task-categorized performance of various models on StructFlowBench.
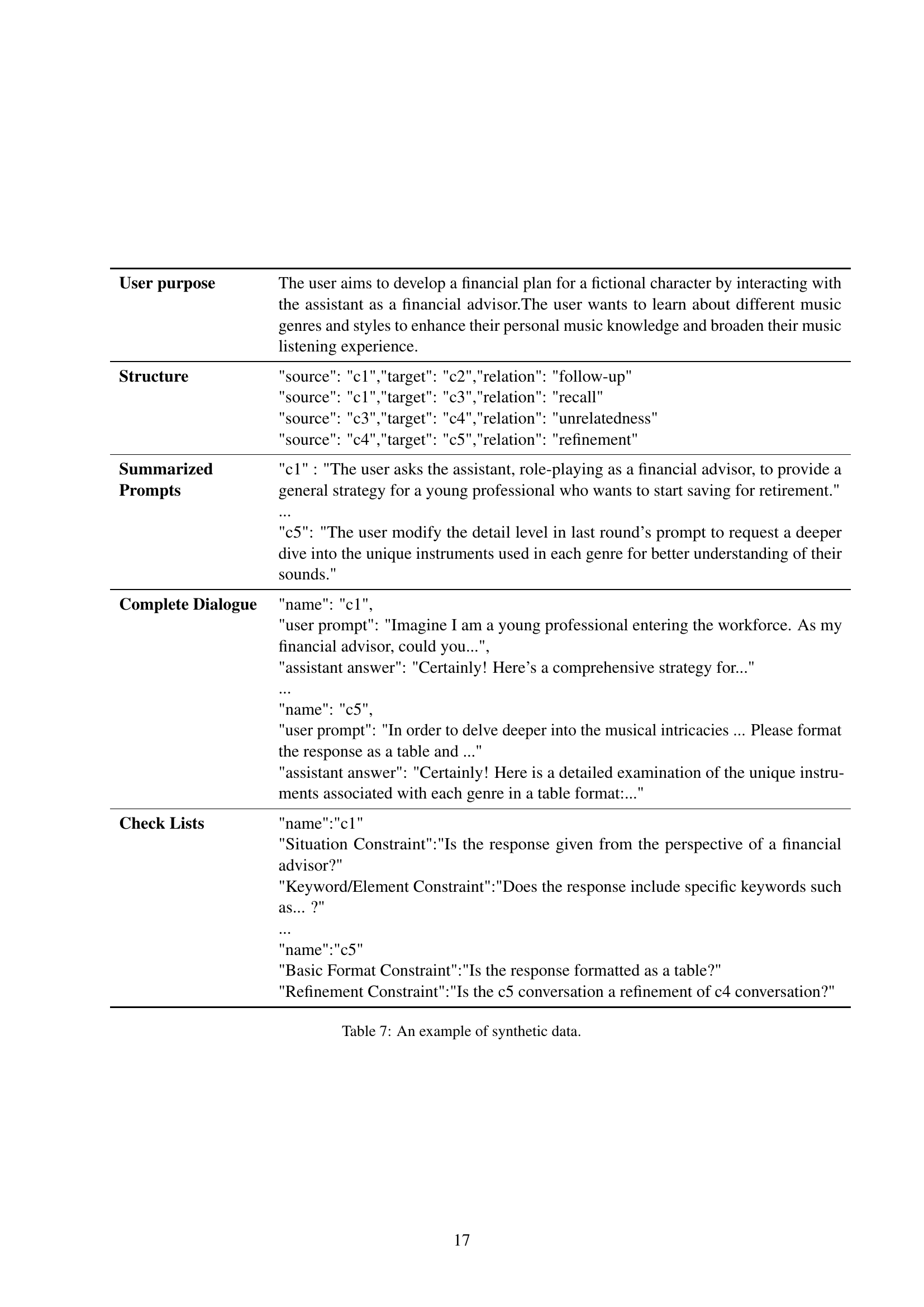
| User purpose | The user aims to develop a financial plan for a fictional character by interacting with the assistant as a financial advisor.The user wants to learn about different music genres and styles to enhance their personal music knowledge and broaden their music listening experience. |
|---|---|
| Structure | "source": "c1","target": "c2","relation": "follow-up" |
| "source": "c1","target": "c3","relation": "recall" | |
| "source": "c3","target": "c4","relation": "unrelatedness" | |
| "source": "c4","target": "c5","relation": "refinement" | |
| Summarized Prompts | "c1" : "The user asks the assistant, role-playing as a financial advisor, to provide a general strategy for a young professional who wants to start saving for retirement." |
| … | |
| "c5": "The user modify the detail level in last round’s prompt to request a deeper dive into the unique instruments used in each genre for better understanding of their sounds." | |
| Complete Dialogue | "name": "c1", |
| "user prompt": "Imagine I am a young professional entering the workforce. As my financial advisor, could you…", | |
| "assistant answer": "Certainly! Here’s a comprehensive strategy for…" | |
| … | |
| "name": "c5", | |
| "user prompt": "In order to delve deeper into the musical intricacies … Please format the response as a table and …" | |
| "assistant answer": "Certainly! Here is a detailed examination of the unique instruments associated with each genre in a table format:…" | |
| Check Lists | "name":"c1" |
| "Situation Constraint":"Is the response given from the perspective of a financial advisor?" | |
| "Keyword/Element Constraint":"Does the response include specific keywords such as… ?" | |
| … | |
| "name":"c5" | |
| "Basic Format Constraint":"Is the response formatted as a table?" | |
| "Refinement Constraint":"Is the c5 conversation a refinement of c4 conversation?" |
🔼 This table presents a sample entry from the StructFlowBench dataset, illustrating the structure of a single dialogue. It shows the user’s overall goal, the planned structure of the dialogue turns with their relationships (follow-up, recall, unrelatedness, refinement), summarized prompts for each turn, the complete dialogue exchange, and finally, a list of constraints (situation, keyword/element, basic format, refinement) that apply to specific turns within the dialogue. This provides a detailed view of how a single data point in the benchmark is constructed and the types of constraints used for evaluation.
read the caption
Table 7: An example of synthetic data.
| Model | Model Link | |
| GPT | GPT-4o | https://platform.openai.com/docs/models#gpt-4o |
| Claude | Claude-3.5-Sonnet | https://docs.anthropic.com/en/docs/about-claude/models |
| Gemini | Gemini-1.5-Pro | https://ai.google.dev/gemini-api/docs/models/gemini?hl=en#gemini-1.5-pro |
| Deepseek | DeepSeek-v3 | https://huggingface.co/deepseek-ai/DeepSeek-V3 |
| DeepSeek-R1-Distill-Qwen-7B | https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | |
| DeepSeek-R1-Distill-Llama-8B | https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B | |
| Qwen | Qwen2.5-14B-Instruct | https://huggingface.co/Qwen/Qwen2.5-14B-Instruct |
| Qwen2.5-7B-Instruct | https://huggingface.co/Qwen/Qwen2.5-7B-Instruct | |
| GLM | GLM-4-9B-Chat | https://huggingface.co/THUDM/glm-4-9b-chat |
| Yi | Yi-6B-Chat | https://huggingface.co/01-ai/Yi-6B-Chat |
| LLAMA | Llama-3.1-8B-Instruct | https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct |
| Mistral | Mistral-7B-Instruct-v0.3 | https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3 |
| Phi | Phi-3.5-mini-instruct | https://huggingface.co/microsoft/Phi-3.5-mini-instruct |
🔼 This table provides links to the model cards or repositories of the 13 large language models (LLMs) evaluated in the StructFlowBench study. For each model, its name, a shortened version of its name used in the paper, and a link to its online resource are listed. This allows readers to access the specific versions of the LLMs used in the benchmark for further study or reproducibility.
read the caption
Table 8: Model Links.
Full paper#