TL;DR#
Large Language Models (LLMs) have achieved great results, but their internal mechanisms are unclear. Researchers still don’t understand how LLMs handle reasoning and long-range dependencies. This paper introduces methods to quantify how LLMs encode contextual information. The results show that tokens often seen as minor (like determiners and punctuation) surprisingly carry high context. Removing these tokens degrades performance, even if removing only irrelevant ones.
To address this understanding gap, the authors introduce LLM-Microscope, a framework to analyze LLMs’ internal behaviors. The toolkit assesses token-level nonlinearity, evaluates contextual memory, visualizes layer contributions, and measures representation dimensionality. Analysis reveals that filler tokens act as key aggregators in language understanding and there is a correlation between contextualization and linearity.
Key Takeaways#
Why does it matter?#
This work is significant for researchers because it sheds light on the role of seemingly trivial tokens in LLMs, potentially revolutionizing how we approach model design and optimization. Also, LLM-Microscope toolkit enables thorough model analysis with key methods like context memory & nonlinearity assessments, logit lens and dimensionality measuring. These findings and tools open new research avenues in understanding & improving contextual understanding in LLMs.
Visual Insights#

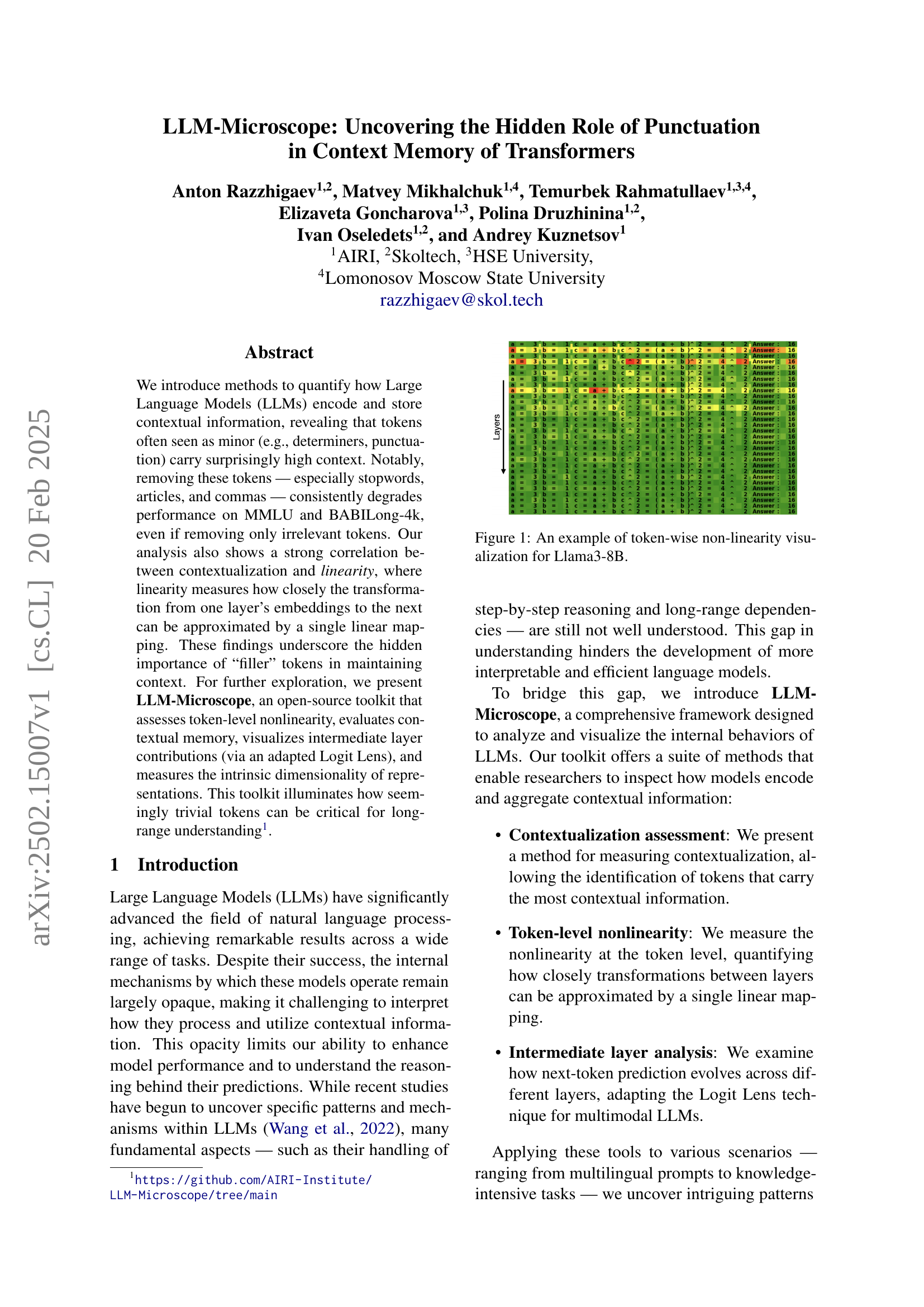
🔼 This figure displays a visualization of token-wise non-linearity for the Llama3-8B language model. It shows how the transformation of token embeddings changes across different layers of the model, illustrating the degree of non-linearity for each token at each layer. This helps to understand how the model processes and transforms contextual information. The visualization likely uses color or other visual cues to represent the level of nonlinearity, with darker shades representing higher nonlinearity.
read the caption
Figure 1: An example of token-wise non-linearity visualization for Llama3-8B.
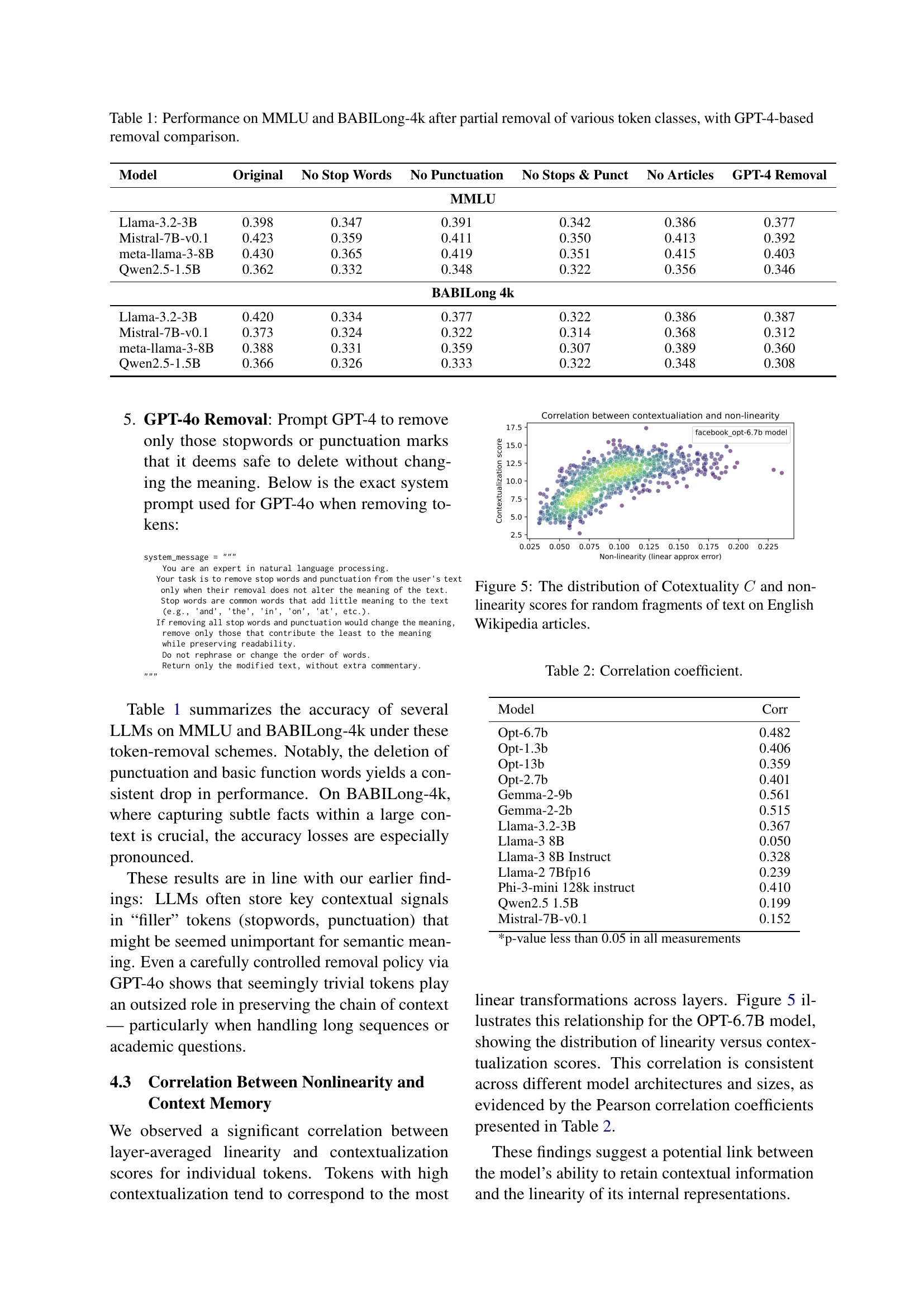
| Model | Original | No Stop Words | No Punctuation | No Stops & Punct | No Articles | GPT-4 Removal |
|---|---|---|---|---|---|---|
| MMLU | ||||||
| Llama-3.2-3B | 0.398 | 0.347 | 0.391 | 0.342 | 0.386 | 0.377 |
| Mistral-7B-v0.1 | 0.423 | 0.359 | 0.411 | 0.350 | 0.413 | 0.392 |
| meta-llama-3-8B | 0.430 | 0.365 | 0.419 | 0.351 | 0.415 | 0.403 |
| Qwen2.5-1.5B | 0.362 | 0.332 | 0.348 | 0.322 | 0.356 | 0.346 |
| BABILong 4k | ||||||
| Llama-3.2-3B | 0.420 | 0.334 | 0.377 | 0.322 | 0.386 | 0.387 |
| Mistral-7B-v0.1 | 0.373 | 0.324 | 0.322 | 0.314 | 0.368 | 0.312 |
| meta-llama-3-8B | 0.388 | 0.331 | 0.359 | 0.307 | 0.389 | 0.360 |
| Qwen2.5-1.5B | 0.366 | 0.326 | 0.333 | 0.322 | 0.348 | 0.308 |
🔼 This table presents the performance of several large language models (LLMs) on two benchmark tasks, MMLU and BABILong-4k, after removing different types of tokens (stopwords, punctuation, articles). It compares the results of three removal methods: a simple rule-based removal, GPT-4 guided removal, and removal of only specific token classes. The table shows how the removal of seemingly insignificant tokens impacts the models’ ability to solve problems across various domains and with different levels of contextual complexity.
read the caption
Table 1: Performance on MMLU and BABILong-4k after partial removal of various token classes, with GPT-4-based removal comparison.
In-depth insights#
Punc’s Hidden Role#
While the paper doesn’t explicitly have a section titled “Punc’s Hidden Role”, its core findings strongly suggest the underappreciated importance of punctuation within Large Language Models (LLMs). The research reveals that punctuation marks, often considered minor tokens, play a significant role in encoding and storing contextual information. The study demonstrates that removing punctuation consistently degrades performance on tasks requiring specialized knowledge and long-context reasoning, indicating that these seemingly trivial tokens are critical for maintaining coherent context. This challenges the conventional view of punctuation as merely grammatical markers, highlighting their function as key aggregators of memory and overall meaning within the model’s internal representations. Further analysis shows a correlation between linearity and contextualization scores in token representations, suggesting that punctuation contributes to the model’s ability to retain contextual information through linear transformations across layers.
LLM Internals#
While the paper doesn’t explicitly have a section titled “LLM Internals,” its core focus deeply explores this area. It meticulously investigates how Large Language Models (LLMs) encode, store, and process contextual information. The research reveals that tokens often dismissed as minor, like punctuation and determiners, surprisingly carry significant contextual weight. This underscores the LLMs might leverage such tokens for broader memory and comprehension tasks, acting as key aggregators of meaning. The presented LLM-Microscope toolkit allows researchers to investigate the inner workings of LLMs such as token-level nonlinearity and visualizing the contribution to final token prediction. Ultimately, it aims to illuminate how seemingly trivial components play pivotal roles in long-range understanding, pushing forward refined interpretability methods.
Token Linearity#
Token linearity plays a crucial role in LLMs, influencing how effectively models process and retain contextual information. Research reveals a strong correlation between token linearity and contextualization scores, suggesting that tokens exhibiting high linearity are more likely to be significant for maintaining context. This implies that models with more linear transformations between layers may be better at preserving contextual information across long sequences. Analyzing token-level nonlinearity helps to uncover the importance of seemingly trivial tokens, such as punctuation marks and stopwords, which often carry surprisingly high contextual information. By quantifying the degree of nonlinearity at the token level, researchers can assess how closely transformations between layers can be approximated by a single linear mapping, providing insights into the internal mechanisms of LLMs and their ability to understand and process language effectively.
Contextual Memory#
Contextual memory in LLMs is a critical area. The paper introduces a method leveraging the model’s ability to reconstruct prefixes from individual token representations to assess contextual information. This approach sheds light on how different tokens encode and preserve context. It involves processing input sequences, collecting hidden states, using a trainable linear pooling layer and MLP, and using resulting embedding to train a copy of original model to reconstruct the prefix. The effectiveness is evaluated by calculating perplexity, with lower loss indicating richer contextual information. It aids in identifying key tokens for contextual information, analyze contextualization across token types, explore the relationship between contextualization and other properties, and compare across model architectures. Thus providing more detailed analysis about each tokens.
LLM-Microscope#
The LLM-Microscope framework is presented as a tool to analyze the internal workings of Large Language Models (LLMs). It offers a way to explore how these models encode and utilize contextual information. The toolkit includes methods for assessing contextualization by identifying tokens that carry significant contextual information. It also measures token-level nonlinearity to quantify how transformations occur between layers. The tool includes visualizing intermediate layer contributions, adopting the Logit Lens technique, and assessing intrinsic dimensionality. By providing these tools, LLM-Microscope helps to uncover patterns in how LLMs handle tasks, ranging from multilingual prompts to knowledge-intensive tasks. It aims to make LLM analysis more accessible to researchers by providing both an open-source Python package and an interactive demo hosted on Hugging Face, to provide an intuitive interface for in-depth model analysis and the exploration of the internal representations, while the toolkit focuses on addressing the opacity of LLMs.
More visual insights#
More on figures

🔼 The LLM-Microscope demo system interface allows users to select a language model, input text, and visualize the results of the analysis. The visualization dashboard displays heatmaps of token-level nonlinearity and layer-wise contribution to prediction, line graphs showing average linearity scores per layer, and a heatmap showing the contextualization level of each token. A Logit Lens visualization also displays the model’s prediction evolution across layers. The interface provides an interactive way for researchers and practitioners to explore how LLMs process and transform information.
read the caption
Figure 2: Interface LLM-Microscope demo system.

🔼 This figure illustrates the process used to assess contextual memory in LLMs. It shows how a model’s ability to reconstruct a text prefix is used to quantify how much contextual information is encoded in individual tokens. The pipeline involves encoding a sequence, pooling layer-wise embeddings, and using a trainable copy of the original model to attempt reconstruction. The cross-entropy loss of the reconstruction process is used to measure the contextualization score. Lower scores indicate more information retained about the context.
read the caption
Figure 3: Prefix decoding pipeline as a contextualization assessment.

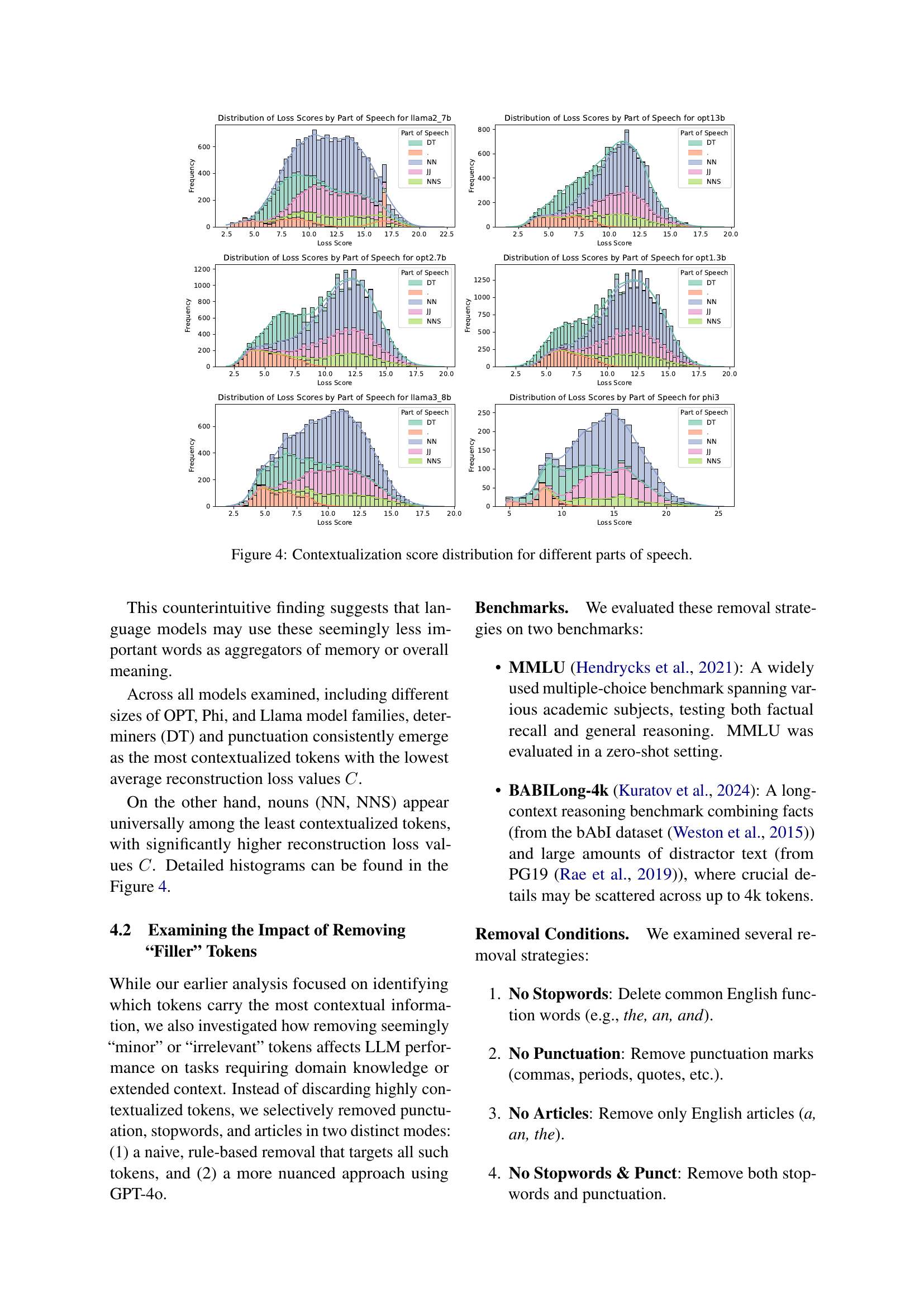
🔼 This figure displays the distribution of contextualization scores for different parts of speech across several large language models. The contextualization score reflects how well a model can reconstruct the preceding text using only a token’s representation. Lower scores indicate the token is more central to preserving the context. The figure shows that determiners (DT) and punctuation consistently have the lowest average reconstruction loss values, suggesting they are highly contextual and important for maintaining coherent context within the models. Conversely, nouns (NN, NNS) generally show higher reconstruction loss values, indicating they are less crucial for preserving the complete context.
read the caption
Figure 4: Contextualization score distribution for different parts of speech.

🔼 Figure 5 is a scatter plot illustrating the relationship between contextualization (C) and non-linearity scores for tokens in English Wikipedia text. Each point represents a token, with its horizontal position indicating the non-linearity score (representing the deviation from a linear transformation between layers) and its vertical position representing the contextualization score (C) (measuring how well the model can reconstruct the preceding text using only the token’s representation). The plot shows the distribution of these scores across many tokens, revealing a correlation between contextual importance and the linearity of a token’s representation within the language model.
read the caption
Figure 5: The distribution of Cotextuality C𝐶Citalic_C and non-linearity scores for random fragments of text on English Wikipedia articles.

🔼 This figure visualizes the ‘Logit Lens’ analysis for the Llama3-8B language model. The input is a German sentence: ’eins zwei drei vier fünf sechs sieben.’ The heatmap shows the model’s predicted probabilities for each word token across different layers of the model’s processing. Each row represents a layer in the model and each column represents a token position. The color intensity reflects the confidence of the model’s prediction for that token at that layer. The analysis reveals that the model initially predicts mainly English tokens, even though the input was German, before converging to the correct German translations in later layers.
read the caption
Figure 6: Logit lens visualisation for Llama3-8B. Input text in German: “eins zwei drei vier fünf sechs sieben,” which translates into English: “one two three four five six seven.”
Full paper#