TL;DR#
Multi-modal 3D object understanding is promising, but existing methods often rely on complete datasets with rigid alignments across modalities. Current approaches struggle in real-world settings where data is incomplete, noisy, or modalities lack consistent correspondence. They also require semantic instance segmentation, a labor intensive task. Thus there is a need to improve scene-level understanding.
This paper introduces a flexible framework: CrossOver, for cross-modal 3D scene understanding via scene-level alignment without aligned modality data. It learns a unified, modality-agnostic embedding space for scenes using RGB images, point clouds, CAD models, floorplans, and text descriptions. By using dimensionality-specific encoders and multi-stage training, CrossOver achieves robust scene retrieval and object localization, adapting to missing modalities and emergent cross-modal behaviors.
Key Takeaways#
Why does it matter?#
This paper introduces a new paradigm for flexible scene understanding, breaking away from the constraints of aligned multi-modal data. It inspires new research directions in interactive mixed-reality experiences and dynamic scene reconstruction with its adaptable method.
Visual Insights#

🔼 CrossOver is a method for aligning different data modalities (images, point clouds, CAD models, floorplans, and text) representing the same 3D scene. It learns a shared embedding space where similar scenes are close together, regardless of the input modality. This allows for tasks like retrieving matching point clouds given a CAD model, or locating furniture in a point cloud based on its CAD model. The figure illustrates the overall process of CrossOver, showing how it takes various scene inputs, processes them through modality-specific encoders, merges the results into a unified representation, and enables scene and object retrieval.
read the caption
Figure 1: CrossOver is a cross-modal alignment method for 3D scenes that learns a unified, modality-agnostic embedding space, enabling a range of tasks. For example, given the 3D CAD model of a query scene and a database of reconstructed point clouds, CrossOver can retrieve the closest matching point cloud and, if object instances are known, it can identify the individual locations of furniture CAD models with matched instances in the retrieved point cloud, using brute-force alignment. This capability has direct applications in virtual and augmented reality.
| Scannet [11] | 3RScan [38] | |||||
| Scene-level Recall | R@25% | R@50% | R@75% | R@25% | R@50% | R@75% |
| ULIP-2 [43] | 1.28 | 0.64 | 0.24 | 1.91 | 0.40 | 0.28 |
| PointBind [18] | 6.73 | 0.96 | 0.32 | 3.18 | 0.64 | 0.01 |
| Inst. Baseline (Ours) | 88.46 | 37.82 | 1.92 | 93.63 | 35.03 | 3.82 |
| Ours | 98.08 | 76.92 | 23.40 | 99.36 | 79.62 | 22.93 |
| ULIP-2 [43] | 98.12 | 96.21 | 60.34 | 98.66 | 85.91 | 36.91 |
| PointBind [18] | 98.22 | 95.17 | 62.07 | 100 | 87.25 | 41.61 |
| Inst. Baseline (Ours) | 99.31 | 97.59 | 71.13 | 100 | 92.62 | 55.03 |
| Ours | 99.66 | 98.28 | 76.29 | 100 | 97.32 | 67.79 |
| ULIP-2 [43] | 37.24 | 16.90 | 8.62 | 16.78 | 6.04 | 1.34 |
| PointBind [18] | 54.83 | 27.93 | 11.72 | 21.48 | 6.04 | 2.01 |
| Inst. Baseline (Ours) | 98.63 | 83.85 | 46.74 | 92.62 | 60.40 | 20.81 |
| Ours | 99.31 | 96.56 | 70.10 | 100 | 89.26 | 50.34 |
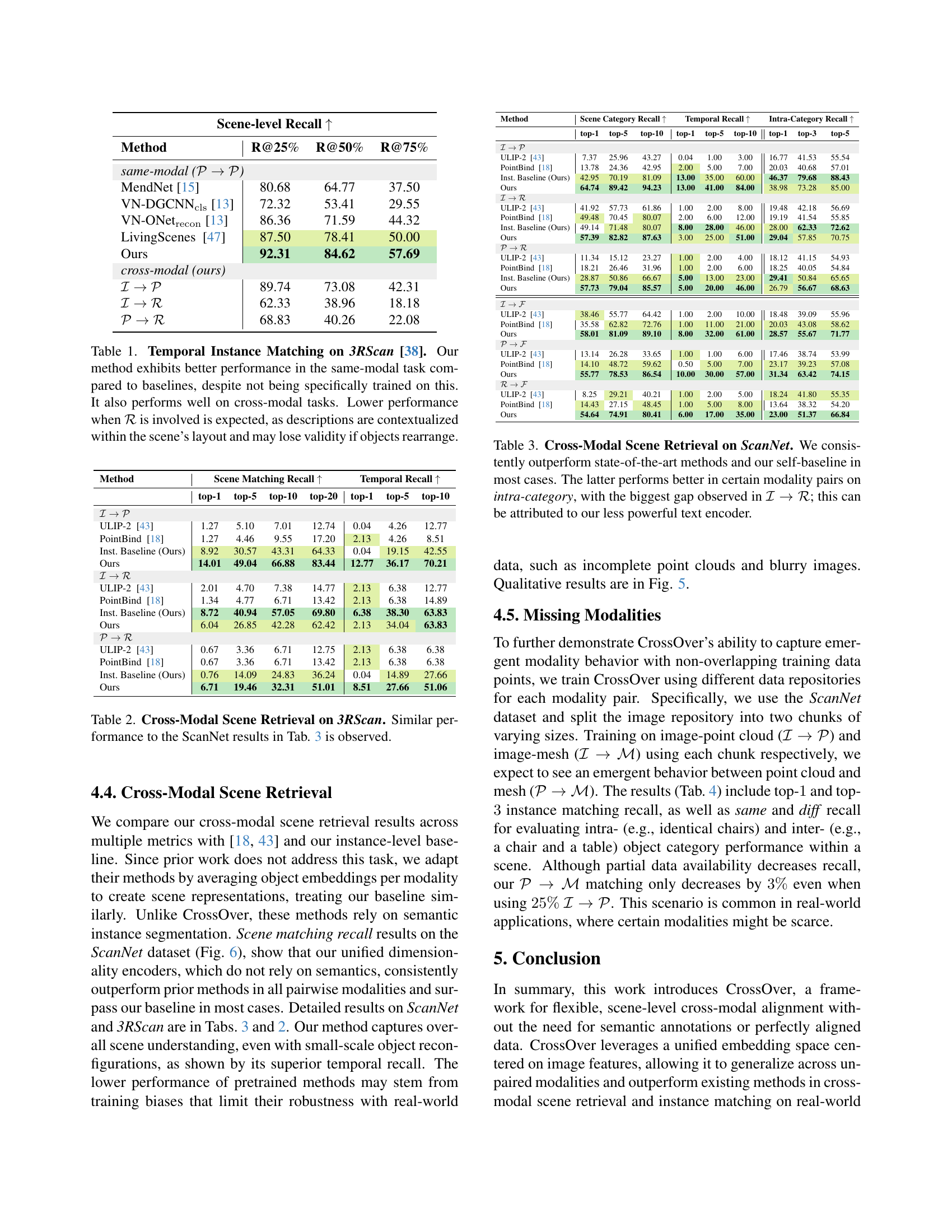
🔼 Table 1 presents a comprehensive evaluation of temporal instance matching performance on the 3RScan dataset. It compares the proposed method’s performance against several baselines across various metrics, including same-modal (where the query and retrieved instances are of the same modality) and cross-modal (where the query and retrieved instances are from different modalities) scenarios. The results demonstrate that the proposed approach achieves better performance than other baselines on same-modal tasks, even though it wasn’t explicitly trained on them. The table also highlights that the method performs well on cross-modal tasks, but shows decreased performance when textual descriptions (ℛ) are involved, suggesting that these descriptions’ contextual relevance to the scene may be impacted by changes in object arrangement or location.
read the caption
Table 1: Temporal Instance Matching on 3RScan [38]. Our method exhibits better performance in the same-modal task compared to baselines, despite not being specifically trained on this. It also performs well on cross-modal tasks. Lower performance when ℛℛ\mathcal{R}caligraphic_R is involved is expected, as descriptions are contextualized within the scene’s layout and may lose validity if objects rearrange.
In-depth insights#
Scene-level align#
Scene-level alignment is crucial for holistic 3D scene understanding, moving beyond individual object alignments. It facilitates tasks like scene retrieval and object localization by learning relationships between different modalities, even when data is incomplete. Current methods often fall short by assuming perfect object-level alignment, limiting their real-world applicability. Approaches like CrossOver aim to learn a modality-agnostic embedding space where scenes from diverse modalities (RGB images, point clouds, CAD models, floorplans, text) can be aligned. This is achieved through techniques such as dimensionality-specific encoders and multi-stage training pipelines that do not rely on explicit object semantics during inference. The benefit of scene-level alignment is that it allows emergent cross-modal behaviors to be learned, such as recognizing that a ‘Scene’ in the image modality corresponds to the same ‘Scene’ in the text modality, thus promoting robust scene representation. Compared to object-level alignment, it focuses on holistic spatial relationships and the overall context of the environment, providing a more adaptable understanding of real-world scenes.
No prior info#
The research paper, titled CrossOver, strategically avoids reliance on prior semantic information or explicit 3D scene graphs, distinguishing it from existing methodologies. This is a significant departure because many current approaches depend on detailed annotations and consistent semantics, which are often challenging to obtain in real-world scenarios. By circumventing the need for prior information, CrossOver gains flexibility and can operate effectively in environments where data is incomplete or noisy. This design choice influences several aspects of CrossOver, including the development of dimensionality-specific encoders tailored to process raw data directly, and a multi-stage training pipeline designed to progressively learn modality-agnostic embeddings. The emergent cross-modal behavior is another notable outcome, enabling the system to recognize correlations between modalities without explicit training on all possible pairs, further enhancing its adaptability and practicality.
Emergent traits#
Emergent traits refer to the novel behaviors or functionalities that arise in a system due to the interactions between its individual components. In the context of cross-modal learning, it implies the model can perform tasks or exhibit abilities not explicitly programmed or trained for. This often arises from the complex interplay of information learned from different modalities, allowing the model to generalize and infer relationships beyond the training data. The model can perform tasks that were not explicitly trained for. For instance, a model trained to align images and text might be able to perform zero-shot object localization, identifying objects in images based on textual descriptions it has never seen before. This demonstrates a higher level of understanding and reasoning. A key challenge is understanding and controlling these emergent traits, ensuring they align with desired outcomes and don’t lead to unintended biases or behaviors. This emphasizes the black-box nature of such traits.
Flexible training#
Flexible training in multimodal learning is crucial for real-world applicability. It allows models to handle incomplete or noisy data by leveraging available information without strict modality alignment. Contrastive learning can be particularly effective, aligning modalities in a shared embedding space even with missing pairs. A well-designed training strategy should also consider the specific characteristics of each modality, using dimensionality-specific encoders to optimize feature extraction and avoid reliance on consistent semantics. Furthermore, a multi-stage training pipeline can progressively build a modality-agnostic embedding space, first capturing fine-grained relationships at the object level and then developing unified scene representations. Flexible training promotes emergent cross-modal behavior.
No perfect data#
The pursuit of ‘perfect data’ in multi-modal 3D scene understanding is often unrealistic. Real-world data inherently suffers from occlusions, sensor limitations, noise, and missing modalities. Relying solely on perfectly aligned and complete datasets limits the practical applicability of research. Methods should be robust to incomplete or noisy data, acknowledging that some modalities might be missing or poorly aligned. Flexibility in handling imperfect data is vital, as it mirrors the challenges encountered in real-world deployment scenarios, such as construction sites or robotic navigation, where data acquisition is rarely ideal and assumptions on data must be relaxed.
More visual insights#
More on figures

🔼 CrossOver is a multimodal scene understanding framework that aligns different modalities (RGB images, point clouds, CAD models, floor plans, and text descriptions) within a shared embedding space. It uses a two-stage approach: first, an Instance-Level Multimodal Interaction module captures interactions between modalities at the instance level; second, a Scene-Level Multimodal Interaction module combines instance-level information to generate a single scene-level feature vector. Finally, Unified Dimensionality Encoders process each modality independently, interacting with the scene-level feature vector, to eliminate the need for precise semantic instance information and enable cross-modal alignment at the scene level.
read the caption
Figure 2: Overview of CrossOver. Given a scene 𝒮𝒮\mathcal{S}caligraphic_S and its instances 𝒪isubscript𝒪𝑖\mathcal{O}_{i}caligraphic_O start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT represented across different modalities ℐ,𝒫,ℳ,ℛ,ℱℐ𝒫ℳℛℱ\mathcal{I},\mathcal{P},\mathcal{M},\mathcal{R},\mathcal{F}caligraphic_I , caligraphic_P , caligraphic_M , caligraphic_R , caligraphic_F, the goal is to align all modalities within a shared embedding space. The Instance-Level Multimodal Interaction module captures modality interactions at the instance level within the context of a scene. This is further enhanced by the Scene-Level Multimodal Interaction module, which jointly processes all instances to represent the scene with a single feature vector ℱ𝒮subscriptℱ𝒮\mathcal{F_{S}}caligraphic_F start_POSTSUBSCRIPT caligraphic_S end_POSTSUBSCRIPT. The Unified Dimensionality Encoders eliminate dependency on precise semantic instance information by learning to process each scene modality independently while interacting with ℱ𝒮subscriptℱ𝒮\mathcal{F_{S}}caligraphic_F start_POSTSUBSCRIPT caligraphic_S end_POSTSUBSCRIPT.

🔼 This figure illustrates the inference pipeline for cross-modal scene retrieval. It begins with a query scene represented by a specific modality (e.g., a point cloud). A dimensionality-specific encoder processes this query, generating a feature vector in a shared embedding space. This feature vector is then compared to feature vectors of scenes in the target modality (e.g., floorplans) stored in a database. The scene with the closest feature vector in the target modality is identified as the retrieved scene.
read the caption
Figure 3: Cross-modal Scene Retrieval Inference Pipeline. Given a query modality (𝒫𝒫\mathcal{P}caligraphic_P) that represents a scene, we obtain with the corresponding dimensionality encoder its feature vector (ℱ3Dsubscriptℱ3𝐷\mathcal{F}_{3D}caligraphic_F start_POSTSUBSCRIPT 3 italic_D end_POSTSUBSCRIPT) in the shared cross-modal embedding space. We identify the closest feature vector (ℱ2Dsubscriptℱ2𝐷\mathcal{F}_{2D}caligraphic_F start_POSTSUBSCRIPT 2 italic_D end_POSTSUBSCRIPT) in the target modality (ℱℱ\mathcal{F}caligraphic_F) and retrieve the corresponding scene from a database of scenes in ℱℱ\mathcal{F}caligraphic_F.

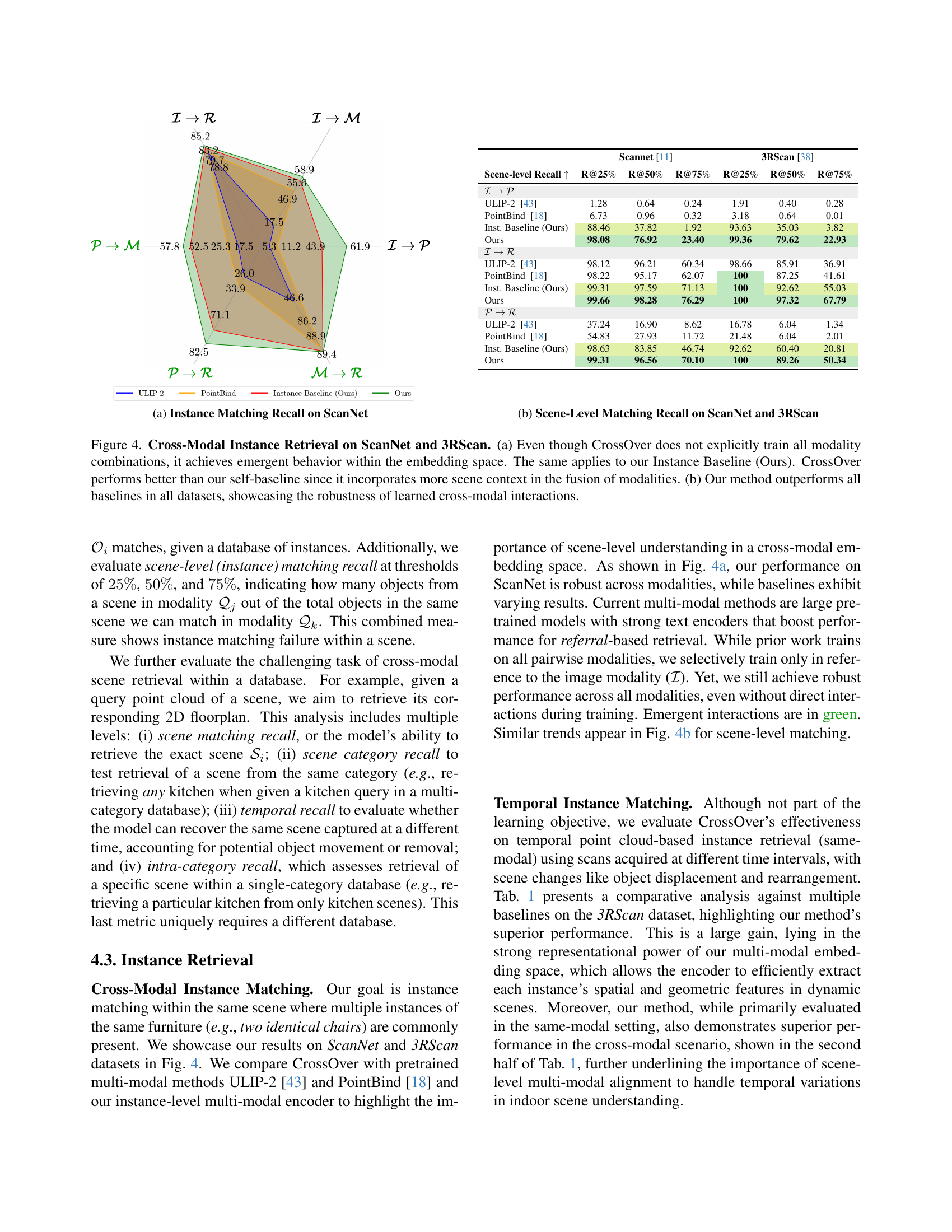
🔼 This figure shows the performance of CrossOver and other multi-modal methods on instance-level retrieval tasks using the ScanNet dataset. Specifically, it displays the recall (the percentage of correctly identified instances) for various modality pairs (e.g., image to text, point cloud to mesh). Each bar represents a different modality pair, and the height of the bar indicates the recall rate. The results showcase CrossOver’s ability to achieve high recall across diverse modality combinations, demonstrating its effectiveness in cross-modal instance retrieval. The chart visually compares CrossOver’s performance against other state-of-the-art multi-modal methods, highlighting CrossOver’s superior performance.
read the caption
(a) Instance Matching Recall on ScanNet

🔼 This figure presents a comparison of scene-level matching recall achieved by different methods on the ScanNet and 3RScan datasets. Scene-level matching recall assesses the ability of a method to retrieve the correct scene from a database given a query scene represented by a specific modality (e.g., RGB images or point clouds). The figure illustrates the superior performance of the proposed CrossOver method compared to several baselines, highlighting its robustness across different datasets and modalities.
read the caption
(b) Scene-Level Matching Recall on ScanNet and 3RScan

🔼 Figure 4 presents the results of cross-modal instance retrieval experiments conducted on the ScanNet and 3RScan datasets. Part (a) compares the performance of CrossOver to a simpler ‘Instance Baseline’ which doesn’t leverage scene-level context. This demonstrates that CrossOver’s superior performance stems from its ability to learn relationships between modalities at the scene level, not just the object level. Although CrossOver doesn’t explicitly train on every possible modality combination, it shows emergent cross-modal behavior. Part (b) shows that CrossOver significantly outperforms other existing multi-modal methods (ULIP-2 and PointBind) on both datasets, highlighting the robustness and effectiveness of its learned cross-modal interactions.
read the caption
Figure 4: Cross-Modal Instance Retrieval on ScanNet and 3RScan. (a) Even though CrossOver does not explicitly train all modality combinations, it achieves emergent behavior within the embedding space. The same applies to our Instance Baseline (Ours). CrossOver performs better than our self-baseline since it incorporates more scene context in the fusion of modalities. (b) Our method outperforms all baselines in all datasets, showcasing the robustness of learned cross-modal interactions.

🔼 This figure demonstrates the effectiveness of the CrossOver model in cross-modal scene retrieval. Using a floorplan as input (query modality ℱ), the model successfully retrieves the corresponding point cloud scene (target modality 𝒫) as the top match. In contrast, PointBind and a simpler baseline model fail to identify the correct scene among the top four results. The visualization also highlights a noteworthy characteristic of the CrossOver embedding space: temporal scenes (i.e., the same scene captured at different times) cluster closely together. This is evident in the examples where similar scene layouts are retrieved with slightly different viewpoints (k=2 and k=3), demonstrating the model’s ability to capture and maintain scene-level consistency across time.
read the caption
Figure 5: Cross-Modal Scene Retrieval Qualitative Results on ScanNet. Given a scene in query modality ℱℱ\mathcal{F}caligraphic_F, we aim to retrieve the same scene in target modality 𝒫𝒫\mathcal{P}caligraphic_P. While PointBind and the Instance Baseline do not retrieve the correct scene within the top-4 matches, CrossOver identifies it as the top-1 match. Notably, temporal scenes appear close together in CrossOver’s embedding space (e.g., k=2𝑘2k=2italic_k = 2, k=3𝑘3k=3italic_k = 3), with retrieved scenes featuring similar object layouts to the query scene, such as the red couch in k=4𝑘4k=4italic_k = 4.

🔼 Figure 6 presents a comparative analysis of cross-modal scene retrieval performance using different methods. The results are shown in plots for top 1, 5, 10, and 20 scene matching recall. Three modality pairs are compared: images to point clouds (I→P), images to text descriptions (I→R), and point clouds to text descriptions (P→R). The ‘Ours’ and ‘Instance Baseline’ methods were not explicitly trained on the P→R pair. The experiment used a database of 306 scenes. The plots demonstrate that the ‘Ours’ method significantly outperforms other methods, particularly the ‘Instance Baseline’, highlighting the improved cross-modal scene interactions enabled by the unified encoders used in the ‘Ours’ approach.
read the caption
Figure 6: Cross-Modal Scene Retrieval on ScanNet (Scene Matching Recall). Plots showcase the top 1, 5, 10, 20 scene matching recall of different methods on three modality pairs: ℐ→𝒫→ℐ𝒫\mathcal{I}\rightarrow\mathcal{P}caligraphic_I → caligraphic_P, ℐ→ℛ→ℐℛ\mathcal{I}\rightarrow\mathcal{R}caligraphic_I → caligraphic_R, 𝒫→ℛ→𝒫ℛ\mathcal{P}\rightarrow\mathcal{R}caligraphic_P → caligraphic_R. Ours and the Instance Baseline have not been explicitly trained on 𝒫→ℛ→𝒫ℛ\mathcal{P}\rightarrow\mathcal{R}caligraphic_P → caligraphic_R. Results are computed on a database of 306 scenes and showcase the superior performance of our approach. Once again, the difference between Ours and our self-baseline is attributed to the enhanced cross-modal scene-level interactions achieved with the unified encoders.

🔼 This figure presents a comparison of instance matching recall across different modalities. The results are shown for various modality pairs, including image-to-point cloud, image-to-mesh, point cloud-to-mesh, and image-to-text. The figure showcases the relative performance of the proposed CrossOver model compared to several baseline methods, highlighting its ability to achieve robust performance across various modality combinations even without explicit object-level alignment.
read the caption
(a) Instance Matching Recall

🔼 This figure shows the scene-level matching recall results on the ScanNet and 3RScan datasets. It compares the performance of the proposed CrossOver method with several baselines, including ULIP-2, PointBind, and an instance baseline. The results are presented for different recall thresholds (R@25%, R@50%, R@75%), which represent the percentage of correctly retrieved scenes among the top 25%, 50%, and 75% of retrieved results. The figure visually demonstrates the superior performance of CrossOver across all datasets and metrics.
read the caption
(b) Scene-Level Matching Recall

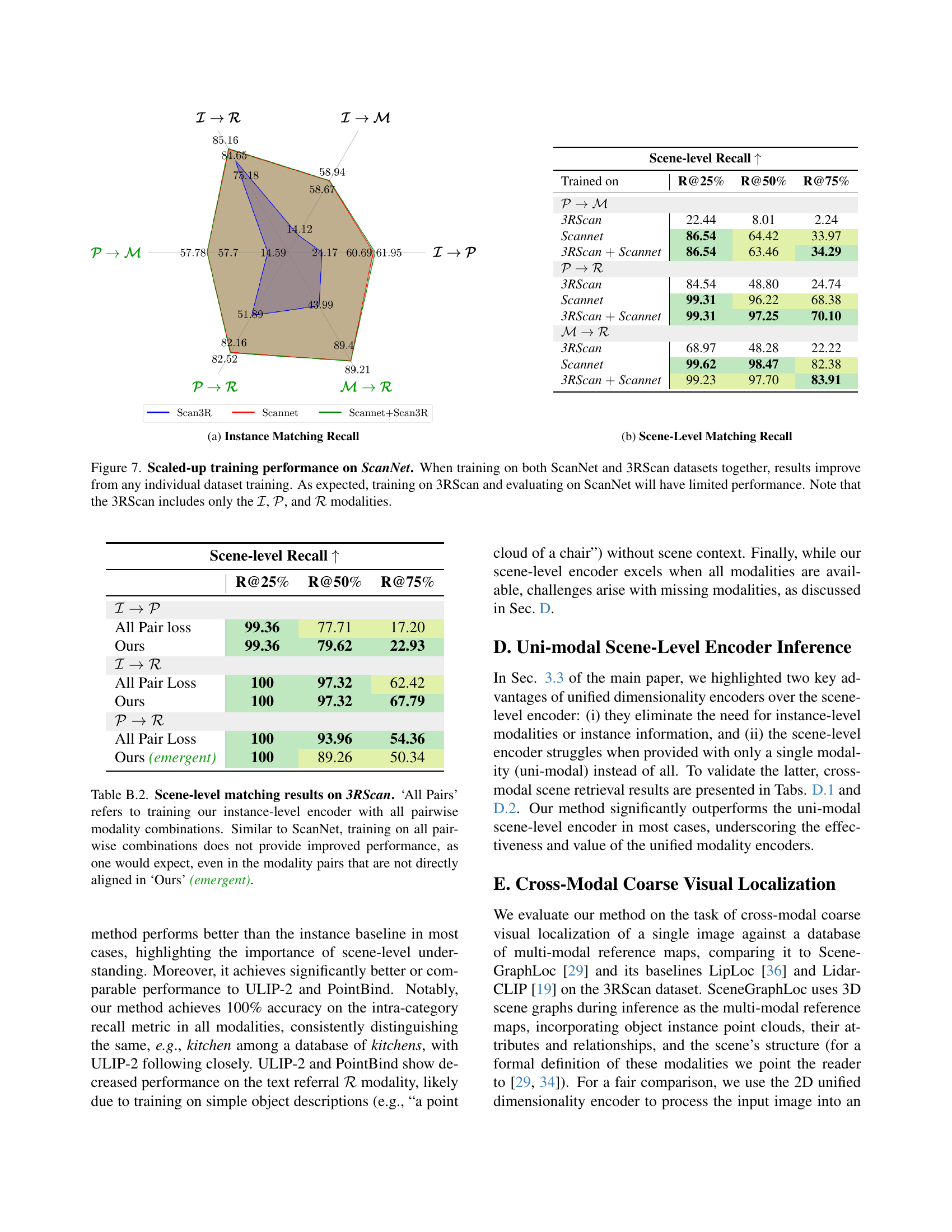
🔼 Figure 7 shows the results of training the CrossOver model on different combinations of the ScanNet and 3RScan datasets. The graph displays the improvement in both instance-level and scene-level matching recall when training on both datasets compared to training on only one. The improvement highlights the benefit of using a larger and more diverse dataset for training. It also shows that training only on the 3RScan dataset and testing on ScanNet results in significantly lower performance, as expected, since 3RScan has different modalities (RGB images, point clouds, and text descriptions) than ScanNet. This demonstrates the model’s ability to leverage data from multiple sources to improve overall performance.
read the caption
Figure 7: Scaled-up training performance on ScanNet. When training on both ScanNet and 3RScan datasets together, results improve from any individual dataset training. As expected, training on 3RScan and evaluating on ScanNet will have limited performance. Note that the 3RScan includes only the ℐℐ\mathcal{I}caligraphic_I, 𝒫𝒫\mathcal{P}caligraphic_P, and ℛℛ\mathcal{R}caligraphic_R modalities.

🔼 Figure 8 shows the performance of CrossOver on cross-modal scene retrieval using ScanNet. The model retrieves scenes from point cloud data (P) given an image query (I). The plots illustrate different performance metrics: scene matching recall (overall accuracy), category recall (retrieving scenes of the same type), temporal recall (retrieving the same scene across different time points), and intra-category recall (retrieving a specific scene instance from a set of similar scenes). The analysis is conducted for varying numbers of camera views (1, 5, 10, 15, 20) used during training to assess impact on retrieval performance, across multiple top-k results (k=1, 5, 10, 20). The maximum k value varies depending on the metric because the number of eligible matches differs based on the criteria for each metric (scene similarity, category, temporal changes).
read the caption
Figure 8: Cross-Modal ℐ→𝒫→ℐ𝒫\mathcal{I}\rightarrow\mathcal{P}caligraphic_I → caligraphic_P Scene Retrieval on ScanNet. Plots showcase scene matching recall (Recall), category recall, temporal recall, and intra-category recall for different number of camera views evaluated on several Top-k𝑘kitalic_k matches. Note that maximum k𝑘kitalic_k differs per recall since the amount of eligible matches depends on the criteria for each recall type: scene similarity, category, temporal changes.

🔼 Figure 9 shows the results of cross-modal scene retrieval experiments on the 3RScan dataset. Specifically, it examines how well the model can retrieve a scene represented by point clouds (𝒫) given a query scene represented by images (ℐ). The experiments vary the number of camera views used to generate the image representation of the query scene. The plots in the figure show both the scene matching recall and the temporal recall for different numbers of camera views. Scene matching recall measures the accuracy of retrieving the correct scene, while temporal recall measures the accuracy of retrieving the correct scene across different time points (i.e., capturing the same scene at different times).
read the caption
Figure 9: Cross-Modal ℐ→𝒫→ℐ𝒫\mathcal{I}\rightarrow\mathcal{P}caligraphic_I → caligraphic_P Scene Retrieval on 3RScan. Plots showcase scene matching recall (Recall) and temporal recall for different number of camera views.
More on tables
| Scene-level Recall | |||
| Method | R@25% | R@50% | R@75% |
| same-modal () | |||
| MendNet [15] | 80.68 | 64.77 | 37.50 |
| VN-DGCNNcls [13] | 72.32 | 53.41 | 29.55 |
| VN-ONetrecon [13] | 86.36 | 71.59 | 44.32 |
| LivingScenes [47] | 87.50 | 78.41 | 50.00 |
| Ours | 92.31 | 84.62 | 57.69 |
| cross-modal (ours) | |||
| 89.74 | 73.08 | 42.31 | |
| 62.33 | 38.96 | 18.18 | |
| 68.83 | 40.26 | 22.08 | |
🔼 Table 2 presents the results of cross-modal scene retrieval experiments conducted on the 3RScan dataset. It shows the performance of the CrossOver model in retrieving scenes across different modalities (image, point cloud, text description). The table likely compares CrossOver’s performance to other baselines or previous methods. The caption indicates that the results are similar to those obtained on the ScanNet dataset (reported in Table 3), suggesting consistent performance across different datasets.
read the caption
Table 2: Cross-Modal Scene Retrieval on 3RScan. Similar performance to the ScanNet results in Tab. 3 is observed.
| Method | Scene Matching Recall | Temporal Recall | |||||
| top-1 | top-5 | top-10 | top-20 | top-1 | top-5 | top-10 | |
| ULIP-2 [43] | 1.27 | 5.10 | 7.01 | 12.74 | 0.04 | 4.26 | 12.77 |
| PointBind [18] | 1.27 | 4.46 | 9.55 | 17.20 | 2.13 | 4.26 | 8.51 |
| Inst. Baseline (Ours) | 8.92 | 30.57 | 43.31 | 64.33 | 0.04 | 19.15 | 42.55 |
| Ours | 14.01 | 49.04 | 66.88 | 83.44 | 12.77 | 36.17 | 70.21 |
| ULIP-2 [43] | 2.01 | 4.70 | 7.38 | 14.77 | 2.13 | 6.38 | 12.77 |
| PointBind [18] | 1.34 | 4.77 | 6.71 | 13.42 | 2.13 | 6.38 | 14.89 |
| Inst. Baseline (Ours) | 8.72 | 40.94 | 57.05 | 69.80 | 6.38 | 38.30 | 63.83 |
| Ours | 6.04 | 26.85 | 42.28 | 62.42 | 2.13 | 34.04 | 63.83 |
| ULIP-2 [43] | 0.67 | 3.36 | 6.71 | 12.75 | 2.13 | 6.38 | 6.38 |
| PointBind [18] | 0.67 | 3.36 | 6.71 | 13.42 | 2.13 | 6.38 | 6.38 |
| Inst. Baseline (Ours) | 0.76 | 14.09 | 24.83 | 36.24 | 0.04 | 14.89 | 27.66 |
| Ours | 6.71 | 19.46 | 32.31 | 51.01 | 8.51 | 27.66 | 51.06 |
🔼 Table 3 presents the results of cross-modal scene retrieval experiments conducted on the ScanNet dataset. The table compares the performance of the proposed CrossOver model against several state-of-the-art baselines across various metrics, including scene matching recall at different thresholds (R@25%, R@50%, R@75%), scene category recall, temporal recall, and intra-category recall. The results demonstrate that CrossOver consistently outperforms the baselines in most scenarios, showcasing its ability to effectively retrieve scenes across different modalities. However, the self-baseline (a simpler version of the CrossOver model) shows slightly better performance in some intra-category retrieval tasks, particularly for the image to text modality pair (I→R). This difference is attributed to the limitations of the text encoder used in CrossOver, suggesting an area for future improvement.
read the caption
Table 3: Cross-Modal Scene Retrieval on ScanNet. We consistently outperform state-of-the-art methods and our self-baseline in most cases. The latter performs better in certain modality pairs on intra-category, with the biggest gap observed in ℐ→ℛ→ℐℛ\mathcal{I}\rightarrow\mathcal{R}caligraphic_I → caligraphic_R; this can be attributed to our less powerful text encoder.
| Method | Scene Category Recall | Temporal Recall | Intra-Category Recall | ||||||
| top-1 | top-5 | top-10 | top-1 | top-5 | top-10 | top-1 | top-3 | top-5 | |
| ULIP-2 [43] | 7.37 | 25.96 | 43.27 | 0.04 | 1.00 | 3.00 | 16.77 | 41.53 | 55.54 |
| PointBind [18] | 13.78 | 24.36 | 42.95 | 2.00 | 5.00 | 7.00 | 20.03 | 40.68 | 57.01 |
| Inst. Baseline (Ours) | 42.95 | 70.19 | 81.09 | 13.00 | 35.00 | 60.00 | 46.37 | 79.68 | 88.43 |
| Ours | 64.74 | 89.42 | 94.23 | 13.00 | 41.00 | 84.00 | 38.98 | 73.28 | 85.00 |
| ULIP-2 [43] | 41.92 | 57.73 | 61.86 | 1.00 | 2.00 | 8.00 | 19.48 | 42.18 | 56.69 |
| PointBind [18] | 49.48 | 70.45 | 80.07 | 2.00 | 6.00 | 12.00 | 19.19 | 41.54 | 55.85 |
| Inst. Baseline (Ours) | 49.14 | 71.48 | 80.07 | 8.00 | 28.00 | 46.00 | 28.00 | 62.33 | 72.62 |
| Ours | 57.39 | 82.82 | 87.63 | 3.00 | 25.00 | 51.00 | 29.04 | 57.85 | 70.75 |
| ULIP-2 [43] | 11.34 | 15.12 | 23.27 | 1.00 | 2.00 | 4.00 | 18.12 | 41.15 | 54.93 |
| PointBind [18] | 18.21 | 26.46 | 31.96 | 1.00 | 2.00 | 6.00 | 18.25 | 40.05 | 54.84 |
| Inst. Baseline (Ours) | 28.87 | 50.86 | 66.67 | 5.00 | 13.00 | 23.00 | 29.41 | 50.84 | 65.65 |
| Ours | 57.73 | 79.04 | 85.57 | 5.00 | 20.00 | 46.00 | 26.79 | 56.67 | 68.63 |
| ULIP-2 [43] | 38.46 | 55.77 | 64.42 | 1.00 | 2.00 | 10.00 | 18.48 | 39.09 | 55.96 |
| PointBind [18] | 35.58 | 62.82 | 72.76 | 1.00 | 11.00 | 21.00 | 20.03 | 43.08 | 58.62 |
| Ours | 58.01 | 81.09 | 89.10 | 8.00 | 32.00 | 61.00 | 28.57 | 55.67 | 71.77 |
| ULIP-2 [43] | 13.14 | 26.28 | 33.65 | 1.00 | 1.00 | 6.00 | 17.46 | 38.74 | 53.99 |
| PointBind [18] | 14.10 | 48.72 | 59.62 | 0.50 | 5.00 | 7.00 | 23.17 | 39.23 | 57.08 |
| Ours | 55.77 | 78.53 | 86.54 | 10.00 | 30.00 | 57.00 | 31.34 | 63.42 | 74.15 |
| ULIP-2 [43] | 8.25 | 29.21 | 40.21 | 1.00 | 2.00 | 5.00 | 18.24 | 41.80 | 55.35 |
| PointBind [18] | 14.43 | 27.15 | 48.45 | 1.00 | 5.00 | 8.00 | 13.64 | 38.32 | 54.20 |
| Ours | 54.64 | 74.91 | 80.41 | 6.00 | 17.00 | 35.00 | 23.00 | 51.37 | 66.84 |
🔼 This ablation study investigates the robustness of CrossOver’s instance matching performance when training data for different modalities are sourced from separate repositories, resulting in non-overlapping data. The table shows that even with significantly less data in one or both modality pairs, the model maintains high performance, demonstrating its ability to generalize and leverage relationships between modalities even when training data is limited or incomplete.
read the caption
Table 4: Ablation on 𝒫→ℳ→𝒫ℳ\mathcal{P}\rightarrow\mathcal{M}caligraphic_P → caligraphic_M instance matching on ScanNet with non-overlapping data per modality pair. Despite modality pairs not sharing the same image repository, our method retains high performance even when a pair is underrepresented in the data.
| Available Data | Instance Matching Recall | ||||
| (%) | (%) | same | diff | top-1 | top-3 |
| 25 | 75 | 86.32 | 73.38 | 55.46 | 79.73 |
| 50 | 50 | 87.46 | 70.02 | 57.49 | 79.94 |
| 75 | 25 | 87.35 | 67.65 | 54.99 | 79.45 |
| 100 | 100 | 87.44 | 72.46 | 59.88 | 80.81 |
🔼 This table presents the results of scene-level matching on the ScanNet dataset. Two sets of results are shown: one where the instance-level encoder was trained using all pairwise combinations of modalities (‘All Pairs’) and one using the method described in the paper (‘Ours’). The results show that training with all pairwise modalities does not lead to a significant improvement in performance compared to the proposed method. This is true even for modality pairs that are not directly aligned in the ‘Ours’ (emergent) results. This suggests that the proposed method’s approach of focused modality alignment is more effective.
read the caption
Table B.1: Scene-level matching results on ScanNet. ‘All Pairs’ refers to training our instance-level encoder with all pairwise modality combinations. As shown, training on all pairwise combinations does not provide drastically improved performance, as one would expect, even in the modality pairs that are not directly aligned in ‘Ours’ (emergent).
| Scene-level Recall | |||
| Trained on | R@25% | R@50% | R@75% |
| 3RScan | 22.44 | 8.01 | 2.24 |
| Scannet | 86.54 | 64.42 | 33.97 |
| 3RScan Scannet | 86.54 | 63.46 | 34.29 |
| 3RScan | 84.54 | 48.80 | 24.74 |
| Scannet | 99.31 | 96.22 | 68.38 |
| 3RScan Scannet | 99.31 | 97.25 | 70.10 |
| 3RScan | 68.97 | 48.28 | 22.22 |
| Scannet | 99.62 | 98.47 | 82.38 |
| 3RScan Scannet | 99.23 | 97.70 | 83.91 |
🔼 This table presents a comparison of scene-level matching recall results on the 3RScan dataset between two training methods: one using all pairwise modality combinations during instance-level encoder training, and the other (‘Ours’) using a more selective approach. The results are reported for various combinations of modalities (I-P, I-R, P-R), showing recall rates at 25%, 50%, and 75% thresholds. The comparison highlights that training with all pairwise combinations does not consistently improve performance compared to the selective approach, even for modality pairs where direct alignment wasn’t explicitly performed during training. The ’emergent’ performance of the selective method suggests a capability to learn cross-modal relationships implicitly.
read the caption
Table B.2: Scene-level matching results on 3RScan. ‘All Pairs’ refers to training our instance-level encoder with all pairwise modality combinations. Similar to ScanNet, training on all pairwise combinations does not provide improved performance, as one would expect, even in the modality pairs that are not directly aligned in ‘Ours’ (emergent).
| Scene-level Recall | |||
| R@25% | R@50% | R@75% | |
| All Pairs | 97.12 | 75.00 | 15.06 |
| Ours | 98.08 | 76.92 | 23.40 |
| All Pairs | 100 | 98.08 | 75.95 |
| Ours | 99.66 | 98.28 | 76.29 |
| All Pairs | 87.82 | 63.14 | 33.97 |
| Ours | 86.54 | 63.46 | 34.29 |
| All Pairs | 99.66 | 97.25 | 75.26 |
| Ours (emergent) | 99.31 | 96.56 | 70.10 |
| All Pairs | 89.42 | 65.71 | 35.26 |
| Ours (emergent) | 87.50 | 61.54 | 30.77 |
| All Pairs | 100 | 98.08 | 83.52 |
| Ours (emergent) | 99.23 | 97.70 | 83.91 |
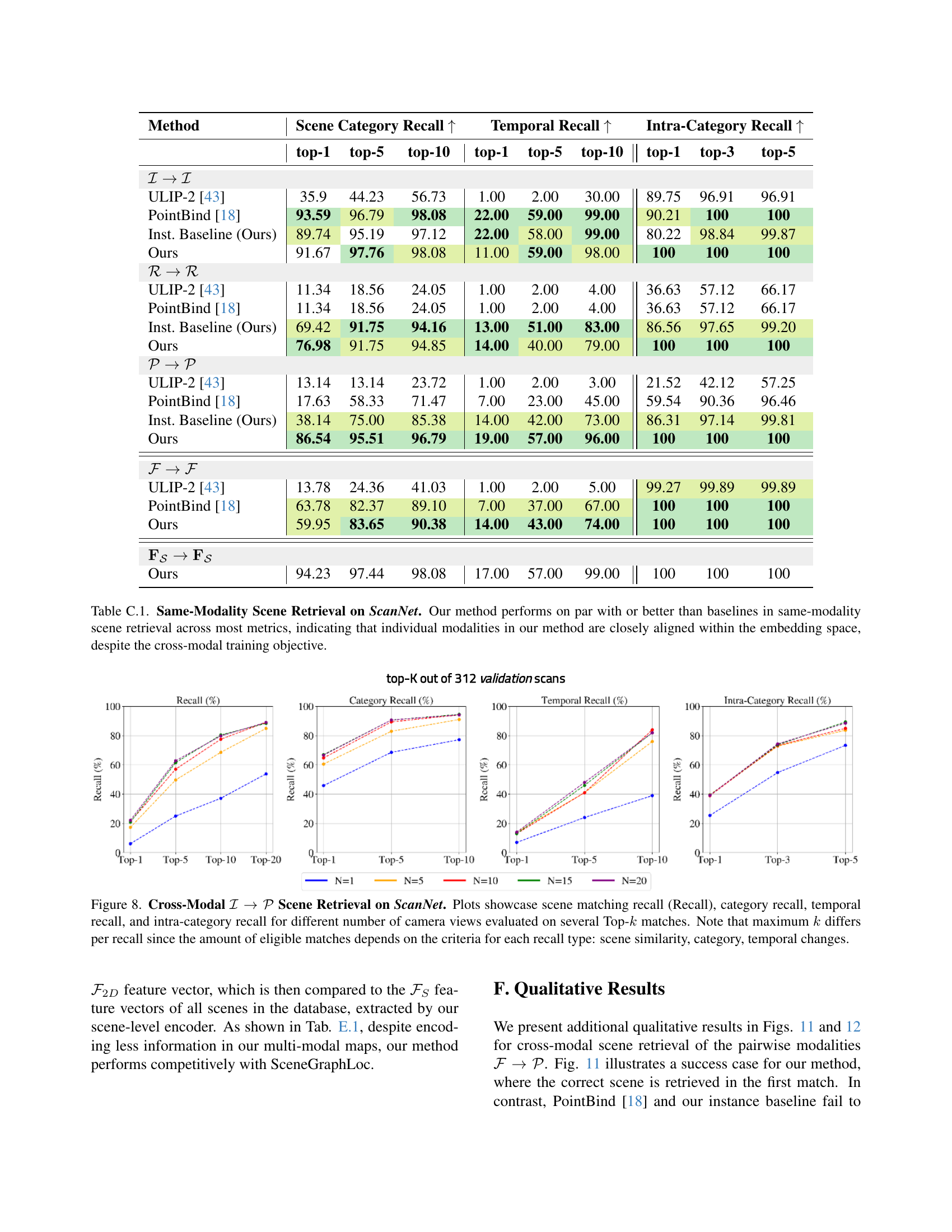
🔼 Table C.1 presents the results of same-modality scene retrieval experiments conducted on the ScanNet dataset. The table compares the performance of the proposed CrossOver method against several baseline methods (ULIP-2, PointBind, and an instance-level baseline) across various metrics, including top-k scene matching recall, scene category recall, temporal recall, and intra-category recall. The results demonstrate that CrossOver achieves comparable or superior performance to the baselines across all metrics. This finding supports the claim that the individual modalities within CrossOver’s learned embedding space are well-aligned, even though the model was primarily trained with a cross-modal objective.
read the caption
Table C.1: Same-Modality Scene Retrieval on ScanNet. Our method performs on par with or better than baselines in same-modality scene retrieval across most metrics, indicating that individual modalities in our method are closely aligned within the embedding space, despite the cross-modal training objective.
| Scene-level Recall | |||
| R@25% | R@50% | R@75% | |
| All Pair loss | 99.36 | 77.71 | 17.20 |
| Ours | 99.36 | 79.62 | 22.93 |
| All Pair Loss | 100 | 97.32 | 62.42 |
| Ours | 100 | 97.32 | 67.79 |
| All Pair Loss | 100 | 93.96 | 54.36 |
| Ours (emergent) | 100 | 89.26 | 50.34 |
🔼 Table C.2 presents the results of same-modality scene retrieval experiments conducted on the 3RScan dataset. It compares the performance of the proposed CrossOver method against several established baselines (ULIP-2, PointBind, and an instance-level baseline) across various metrics including top-k scene retrieval recall (top-1, top-5, top-10), scene category recall, temporal recall, and intra-category recall. The results show that CrossOver achieves comparable or better performance than the baselines, despite the limited training data available for the 3RScan dataset, which likely accounts for the slightly lower overall performance compared to the ScanNet results presented in Table C.1.
read the caption
Table C.2: Same-Modality Scene Retrieval on 3RScan. Our method performs on par with or better than baselines in same-modality scene retrieval across most metrics. The lower performance on this dataset is likely due to limited training data availability.
| Method | Scene Category Recall | Temporal Recall | Intra-Category Recall | ||||||
| top-1 | top-5 | top-10 | top-1 | top-5 | top-10 | top-1 | top-3 | top-5 | |
| ULIP-2 [43] | 35.9 | 44.23 | 56.73 | 1.00 | 2.00 | 30.00 | 89.75 | 96.91 | 96.91 |
| PointBind [18] | 93.59 | 96.79 | 98.08 | 22.00 | 59.00 | 99.00 | 90.21 | 100 | 100 |
| Inst. Baseline (Ours) | 89.74 | 95.19 | 97.12 | 22.00 | 58.00 | 99.00 | 80.22 | 98.84 | 99.87 |
| Ours | 91.67 | 97.76 | 98.08 | 11.00 | 59.00 | 98.00 | 100 | 100 | 100 |
| ULIP-2 [43] | 11.34 | 18.56 | 24.05 | 1.00 | 2.00 | 4.00 | 36.63 | 57.12 | 66.17 |
| PointBind [18] | 11.34 | 18.56 | 24.05 | 1.00 | 2.00 | 4.00 | 36.63 | 57.12 | 66.17 |
| Inst. Baseline (Ours) | 69.42 | 91.75 | 94.16 | 13.00 | 51.00 | 83.00 | 86.56 | 97.65 | 99.20 |
| Ours | 76.98 | 91.75 | 94.85 | 14.00 | 40.00 | 79.00 | 100 | 100 | 100 |
| ULIP-2 [43] | 13.14 | 13.14 | 23.72 | 1.00 | 2.00 | 3.00 | 21.52 | 42.12 | 57.25 |
| PointBind [18] | 17.63 | 58.33 | 71.47 | 7.00 | 23.00 | 45.00 | 59.54 | 90.36 | 96.46 |
| Inst. Baseline (Ours) | 38.14 | 75.00 | 85.38 | 14.00 | 42.00 | 73.00 | 86.31 | 97.14 | 99.81 |
| Ours | 86.54 | 95.51 | 96.79 | 19.00 | 57.00 | 96.00 | 100 | 100 | 100 |
| ULIP-2 [43] | 13.78 | 24.36 | 41.03 | 1.00 | 2.00 | 5.00 | 99.27 | 99.89 | 99.89 |
| PointBind [18] | 63.78 | 82.37 | 89.10 | 7.00 | 37.00 | 67.00 | 100 | 100 | 100 |
| Ours | 59.95 | 83.65 | 90.38 | 14.00 | 43.00 | 74.00 | 100 | 100 | 100 |
| Ours | 94.23 | 97.44 | 98.08 | 17.00 | 57.00 | 99.00 | 100 | 100 | 100 |
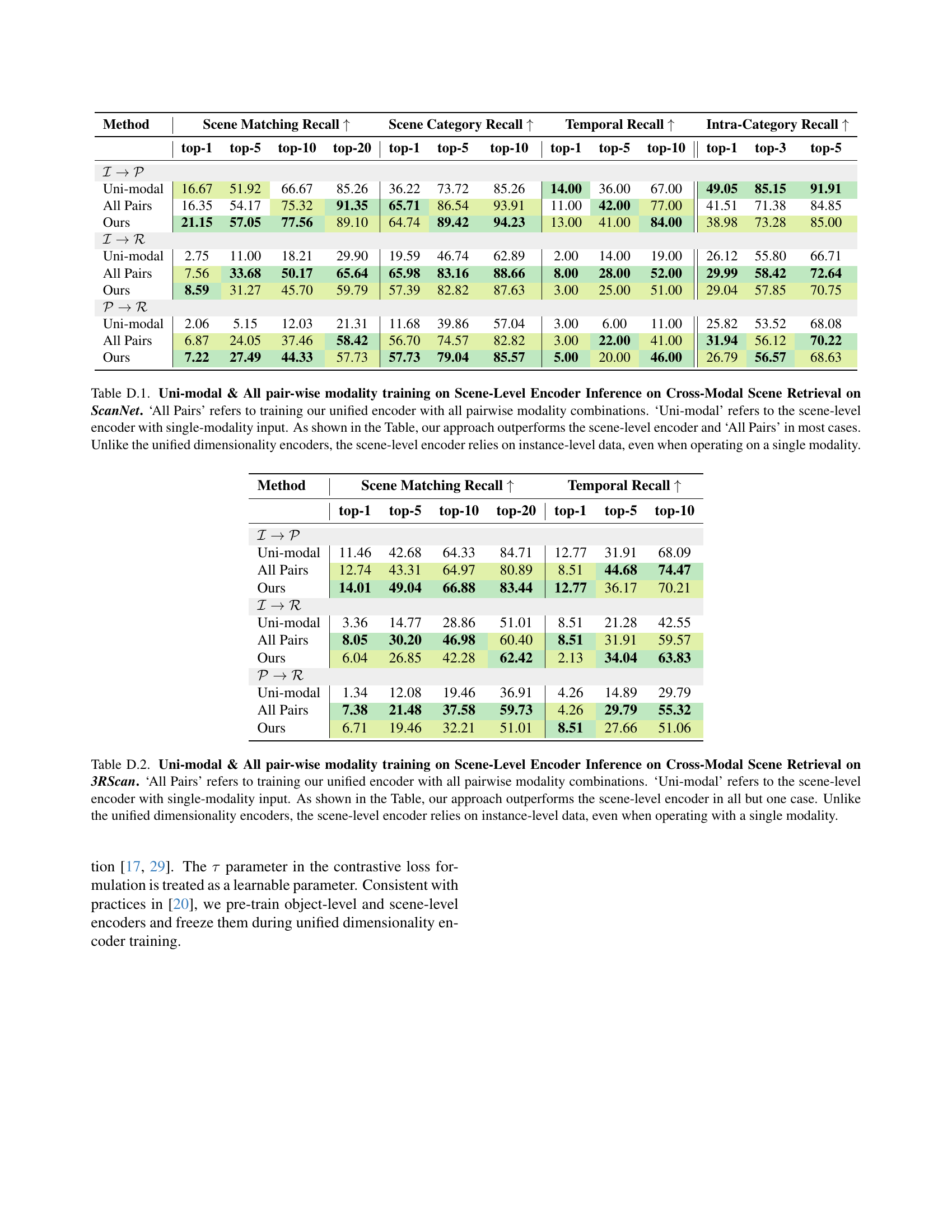
🔼 This table compares the performance of three different approaches for cross-modal scene retrieval on the ScanNet dataset. The methods compared are: 1) a unified encoder trained using all pairwise modality combinations, 2) a scene-level encoder using a single modality input, and 3) the proposed CrossOver model. The table shows that the CrossOver model generally outperforms both the all-pairs method and the uni-modal scene-level approach in terms of scene matching recall, scene category recall, temporal recall, and intra-category recall. A key finding is that the scene-level encoder’s performance is significantly affected by its dependence on instance-level data, whereas the CrossOver model’s unified dimensionality encoders are more robust to the absence of specific modalities.
read the caption
Table D.1: Uni-modal & All pair-wise modality training on Scene-Level Encoder Inference on Cross-Modal Scene Retrieval on ScanNet. ‘All Pairs’ refers to training our unified encoder with all pairwise modality combinations. ‘Uni-modal’ refers to the scene-level encoder with single-modality input. As shown in the Table, our approach outperforms the scene-level encoder and ‘All Pairs’ in most cases. Unlike the unified dimensionality encoders, the scene-level encoder relies on instance-level data, even when operating on a single modality.
| Method | Temporal Recall | ||
| top-1 | top-5 | top-10 | |
| ULIP-2 [43] | 2.13 | 8.51 | 29.79 |
| PointBind [18] | 10.64 | 51.06 | 93.62 |
| Inst. Baseline (Ours) | 4.26 | 65.96 | 100 |
| Ours | 17.02 | 61.70 | 100 |
| ULIP-2 [43] | 2.13 | 6.38 | 8.51 |
| PointBind [18] | 2.13 | 6.38 | 8.51 |
| Inst. Baseline (Ours) | 19.15 | 46.81 | 91.49 |
| Ours | 12.77 | 51.06 | 87.23 |
| ULIP-2 [43] | 0.04 | 4.26 | 6.38 |
| PointBind [18] | 2.13 | 17.02 | 36.17 |
| Inst. Baseline (Ours) | 6.38 | 29.79 | 3.83 |
| Ours | 19.15 | 65.96 | 97.87 |
| Ours | 17.02 | 59.57 | 97.87 |
🔼 This table presents a comparison of cross-modal scene retrieval performance on the 3RScan dataset using different training methods for the scene-level encoder. The methods compared are: using all pairwise modality combinations during training (‘All Pairs’), using only a single input modality (‘Uni-modal’), and the proposed CrossOver method (‘Ours’). The metrics used are scene matching recall (top-1, top-5, top-10, top-20) and temporal recall (top-1, top-5, top-10). The results show that CrossOver significantly outperforms the uni-modal scene-level encoder in most cases and generally performs better than the ‘All Pairs’ training approach. The superior performance of CrossOver is attributed to its use of unified dimensionality encoders that do not rely on instance-level data, unlike the scene-level encoder.
read the caption
Table D.2: Uni-modal & All pair-wise modality training on Scene-Level Encoder Inference on Cross-Modal Scene Retrieval on 3RScan. ‘All Pairs’ refers to training our unified encoder with all pairwise modality combinations. ‘Uni-modal’ refers to the scene-level encoder with single-modality input. As shown in the Table, our approach outperforms the scene-level encoder in all but one case. Unlike the unified dimensionality encoders, the scene-level encoder relies on instance-level data, even when operating with a single modality.
| Method | Scene Matching Recall | Scene Category Recall | Temporal Recall | Intra-Category Recall | |||||||||
| top-1 | top-5 | top-10 | top-20 | top-1 | top-5 | top-10 | top-1 | top-5 | top-10 | top-1 | top-3 | top-5 | |
| Uni-modal | 16.67 | 51.92 | 66.67 | 85.26 | 36.22 | 73.72 | 85.26 | 14.00 | 36.00 | 67.00 | 49.05 | 85.15 | 91.91 |
| All Pairs | 16.35 | 54.17 | 75.32 | 91.35 | 65.71 | 86.54 | 93.91 | 11.00 | 42.00 | 77.00 | 41.51 | 71.38 | 84.85 |
| Ours | 21.15 | 57.05 | 77.56 | 89.10 | 64.74 | 89.42 | 94.23 | 13.00 | 41.00 | 84.00 | 38.98 | 73.28 | 85.00 |
| Uni-modal | 2.75 | 11.00 | 18.21 | 29.90 | 19.59 | 46.74 | 62.89 | 2.00 | 14.00 | 19.00 | 26.12 | 55.80 | 66.71 |
| All Pairs | 7.56 | 33.68 | 50.17 | 65.64 | 65.98 | 83.16 | 88.66 | 8.00 | 28.00 | 52.00 | 29.99 | 58.42 | 72.64 |
| Ours | 8.59 | 31.27 | 45.70 | 59.79 | 57.39 | 82.82 | 87.63 | 3.00 | 25.00 | 51.00 | 29.04 | 57.85 | 70.75 |
| Uni-modal | 2.06 | 5.15 | 12.03 | 21.31 | 11.68 | 39.86 | 57.04 | 3.00 | 6.00 | 11.00 | 25.82 | 53.52 | 68.08 |
| All Pairs | 6.87 | 24.05 | 37.46 | 58.42 | 56.70 | 74.57 | 82.82 | 3.00 | 22.00 | 41.00 | 31.94 | 56.12 | 70.22 |
| Ours | 7.22 | 27.49 | 44.33 | 57.73 | 57.73 | 79.04 | 85.57 | 5.00 | 20.00 | 46.00 | 26.79 | 56.57 | 68.63 |
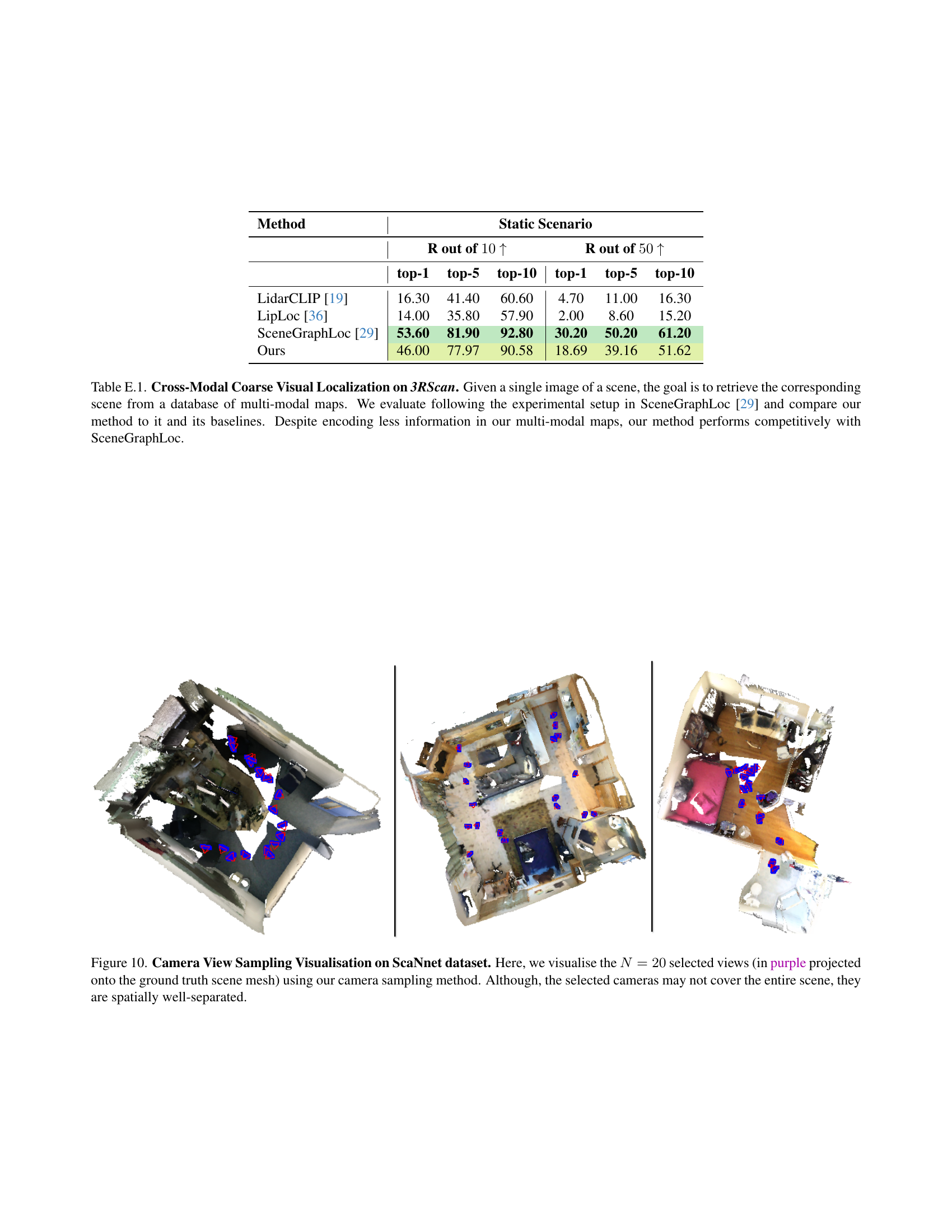
🔼 Table E.1 presents the results of cross-modal coarse visual localization experiments conducted on the 3RScan dataset. The task is to retrieve a scene’s corresponding multi-modal map given a single image of that scene. The evaluation uses the experimental setup from SceneGraphLoc [29]. The table compares the performance of the proposed method to SceneGraphLoc and its baselines (LidarCLIP [19] and LipLoc [36]). Despite utilizing less information within its multi-modal maps, the proposed method demonstrates competitive performance with SceneGraphLoc.
read the caption
Table E.1: Cross-Modal Coarse Visual Localization on 3RScan. Given a single image of a scene, the goal is to retrieve the corresponding scene from a database of multi-modal maps. We evaluate following the experimental setup in SceneGraphLoc [29] and compare our method to it and its baselines. Despite encoding less information in our multi-modal maps, our method performs competitively with SceneGraphLoc.
Full paper#