TL;DR#
Existing benchmarks lack tests for Large Multimodal Models (LMMs) regarding interactive intelligence with human users, a key aspect for general AI assistants. To address this, the study introduces InterFeedback, a versatile framework applicable to any LMM and dataset. It also presents InterFeedback-Bench, evaluating interactive intelligence using MMMU-Pro and MathVerse on 10 open-source LMMs. A newly collected dataset, InterFeedback-Human, assesses interactive performance manually in models like OpenAI-01 and Claude-3.5-Sonnet.
The evaluation reveals that even advanced LMMs like OpenAI-01 correct their results through human feedback less than 50% of the time. The study highlights the need for methods to enhance LMMs’ ability to interpret and benefit from feedback. Key findings include that interactive processes improve performance, existing LMMs struggle with feedback interpretation, and additional iterations don’t guarantee correct solutions. The research also emphasizes that LMMs may not always use reasoning and sometimes guess the answer based on human’s response.
Key Takeaways#
Why does it matter?#
This research introduces InterFeedback-Bench, a benchmark designed to evaluate how well large multimodal models interact with human feedback. It highlights the gaps in current LMMs’ ability to use feedback effectively, offering researchers a crucial tool for developing more interactive and adaptive AI systems. The framework and datasets provide a new avenue for exploring human-AI interaction, pushing the boundaries of general-purpose AI assistants.
Visual Insights#

🔼 The figure illustrates a human-in-the-loop interactive feedback process. A multimodal model initially provides an answer to a question. If the answer is incorrect, a human user gives feedback, guiding the model to refine its answer through iterative steps. This demonstrates the importance of human feedback in improving the accuracy and problem-solving capabilities of large multimodal models.
read the caption
Figure 1: Illustration of an interactive feedback scenario. When models generate incorrect responses, human users provide pertinent feedback to iteratively refine the answers.
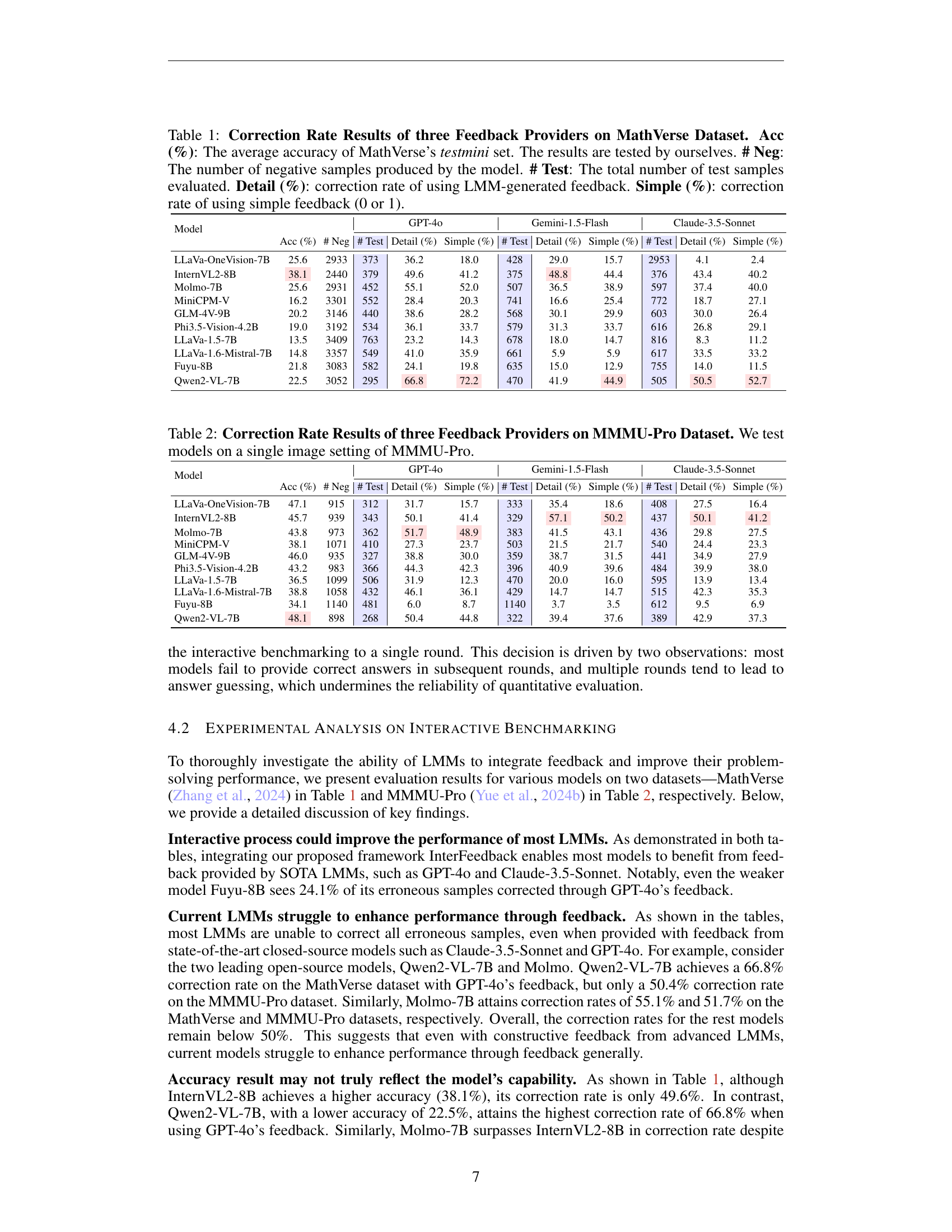
| Model | GPT-4o | Gemini-1.5-Flash | Claude-3.5-Sonnet | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc (%) | # Neg | # Test | Detail (%) | Simple (%) | # Test | Detail (%) | Simple (%) | # Test | Detail (%) | Simple (%) | |
| LLaVa-OneVision-7B | 25.6 | 2933 | 373 | 36.2 | 18.0 | 428 | 29.0 | 15.7 | 2953 | 4.1 | 2.4 |
| InternVL2-8B | 38.1 | 2440 | 379 | 49.6 | 41.2 | 375 | 48.8 | 44.4 | 376 | 43.4 | 40.2 |
| Molmo-7B | 25.6 | 2931 | 452 | 55.1 | 52.0 | 507 | 36.5 | 38.9 | 597 | 37.4 | 40.0 |
| MiniCPM-V | 16.2 | 3301 | 552 | 28.4 | 20.3 | 741 | 16.6 | 25.4 | 772 | 18.7 | 27.1 |
| GLM-4V-9B | 20.2 | 3146 | 440 | 38.6 | 28.2 | 568 | 30.1 | 29.9 | 603 | 30.0 | 26.4 |
| Phi3.5-Vision-4.2B | 19.0 | 3192 | 534 | 36.1 | 33.7 | 579 | 31.3 | 33.7 | 616 | 26.8 | 29.1 |
| LLaVa-1.5-7B | 13.5 | 3409 | 763 | 23.2 | 14.3 | 678 | 18.0 | 14.7 | 816 | 8.3 | 11.2 |
| LLaVa-1.6-Mistral-7B | 14.8 | 3357 | 549 | 41.0 | 35.9 | 661 | 5.9 | 5.9 | 617 | 33.5 | 33.2 |
| Fuyu-8B | 21.8 | 3083 | 582 | 24.1 | 19.8 | 635 | 15.0 | 12.9 | 755 | 14.0 | 11.5 |
| Qwen2-VL-7B | 22.5 | 3052 | 295 | 66.8 | 72.2 | 470 | 41.9 | 44.9 | 505 | 50.5 | 52.7 |
🔼 This table presents the correction rates achieved by three different feedback providers (GPT-40, Gemini-1.5-Flash, and Claude-3.5-Sonnet) when assisting various Large Multimodal Models (LMMs) on the MathVerse dataset. The correction rate is calculated as the percentage of initially incorrect answers that were corrected through feedback. The table includes the average accuracy on the MathVerse testmini set, the number of negative samples (initially incorrect answers), the total number of test samples evaluated for each LMM, the correction rates using detailed LMM-generated feedback, and the correction rates using simple binary (correct/incorrect) feedback.
read the caption
Table 1: Correction Rate Results of three Feedback Providers on MathVerse Dataset. Acc (%): The average accuracy of MathVerse’s testmini set. The results are tested by ourselves. # Neg: The number of negative samples produced by the model. # Test: The total number of test samples evaluated. Detail (%): correction rate of using LMM-generated feedback. Simple (%): correction rate of using simple feedback (0 or 1).
In-depth insights#
InterFeedback#
The research introduces “InterFeedback,” a novel approach to evaluating interactive intelligence in Large Multimodal Models (LMMs) by simulating human-AI interactions. It fills a critical gap, as existing benchmarks primarily assess LMMs in static environments, neglecting their ability to learn and adapt through feedback. The framework enables any LMM to interactively solve problems, leveraging models like GPT-4o to simulate human feedback, thus creating a closed-loop learning system. Key components are a feedback receiver and a feedback provider to evaluate the interpretability of different feedback.
LMM HAI Underexplored#
Large Multimodal Models (LMMs) hold significant promise as interactive AI assistants, yet their capabilities in Human-AI Interaction (HAI) remain largely underexplored. While LMMs excel in various multimodal tasks, their interactive intelligence, particularly the ability to learn and improve from human feedback, is not well-assessed. Current benchmarks primarily focus on static testing, neglecting the dynamic and iterative nature of HAI. This lack of comprehensive evaluation in interactive settings hinders the development of LMMs that can effectively collaborate and adapt to human guidance, thus impeding their potential as general-purpose AI assistants that can refine their problem-solving abilities through feedback loops.
Iterative LMM Tests#
Iterative LMM (Large Multimodal Models) tests represent a crucial shift in how we evaluate AI, moving beyond static benchmarks to dynamic, interactive assessments. The core idea is to probe an LMM’s ability to learn and adapt through successive rounds of interaction, typically involving human feedback. This allows us to assess not just the model’s initial knowledge but also its capacity to refine its understanding and improve its performance over time. The setup involves a task, initial model response, feedback (binary or detailed), and a re-evaluation. Key aspects include defining suitable tasks (drawing on existing datasets or creating new ones), simulating the role of human feedback (using other LLMs or real users), and devising metrics that capture the iterative improvement. The success of iterative tests hinges on the quality and relevance of the feedback provided; poor feedback can actually degrade performance. These tests help reveal whether LMMs truly “reason” or simply guess, and highlight areas where models struggle to incorporate new information effectively. Overall, iterative tests offer a richer, more realistic evaluation of LMMs’ potential for real-world applications involving ongoing human-AI collaboration.
Feedback: Suboptimal#
If we assume feedback provided to an AI model is suboptimal, then the model will likely exhibit impaired learning and adaptation. The model would struggle to discern relevant patterns, leading to inaccurate parameter adjustments. In cases of misleading or noisy feedback, the model might develop skewed representations or amplify biases. In turn, it results in lower generalization performance when facing unseen data. Effective techniques for noise reduction and reliability assessment become vital in such scenarios, ensuring the model can extract meaningful insights from the provided feedback while mitigating the impact of suboptimal signals. The model needs to possess a robust learning mechanism that can distinguish between helpful signals and potentially disruptive elements within the feedback data to maintain and improve its performance.
HAI’s Future Steps#
While the paper doesn’t explicitly have a section called ‘HAI’s Future Steps,’ its focus on interactive intelligence in LMMs provides a clear direction. Future research should prioritize enhancing LMMs’ ability to learn from diverse feedback types, moving beyond simple correctness signals. Developing more sophisticated prompting techniques and internal mechanisms that allow models to effectively incorporate human input is crucial. Additionally, creating more comprehensive and dynamic benchmarks that assess the full spectrum of HAI capabilities is essential to foster progress in this area. It’s also important to explore the role of multimodality in feedback and interaction, as well as how to personalize feedback mechanisms for different users and tasks. Moreover, addressing biases and ethical considerations in HAI systems will be crucial to ensure responsible and equitable development.
More visual insights#
More on figures

🔼 This figure illustrates the process of creating a benchmark dataset for evaluating large multimodal models (LMMs) using human feedback. It starts with a target dataset (like MathVerse). For each LMM being tested (the ‘feedback receiver’), the model processes each item in the dataset. Any incorrect responses from this LMM create the ’negative set’ for that LMM. A separate, highly accurate model (the ‘feedback provider’) is then run on the same dataset items, generating the ‘positive set’. The intersection of the positive and negative sets creates the final curated test data used for further benchmark evaluations. This ensures only problems that the provider can solve correctly, but the receiver cannot, are included.
read the caption
Figure 2: Overview of the test data construction process for InterFeedback-Bench. For each LMM serving as the feedback receiver, we process each instance from a target dataset (e.g., MathVerse) and collect the error cases to form a negative set. The feedback provider then processes the same instances to build a positive set. Finally, we curate test data by selecting the intersection of both sets.

🔼 The figure illustrates the InterFeedback framework, designed to evaluate a large multimodal model’s (LMM) ability to learn from human feedback. The process begins with the LMM attempting to solve a problem. A human then verifies the answer. If incorrect, another LMM simulates a human providing feedback to help the first LMM improve its response. This iterative process continues until the LMM solves the problem or a predetermined number of rounds are completed. The framework explores two feedback types: simple (correct/incorrect) and detailed (with explanations).
read the caption
Figure 3: Overview of the proposed framework InterFeedback for assessing an LMM’s ability to improve itself through feedback. The model interacts with humans to progressively solve a problem, and after each conversation round, we verify the correctness of the answer. If the answer is incorrect, an LMM-stimulated human will provide constructive feedback. We implement two types of feedback to investigate the behavior of LMMs.

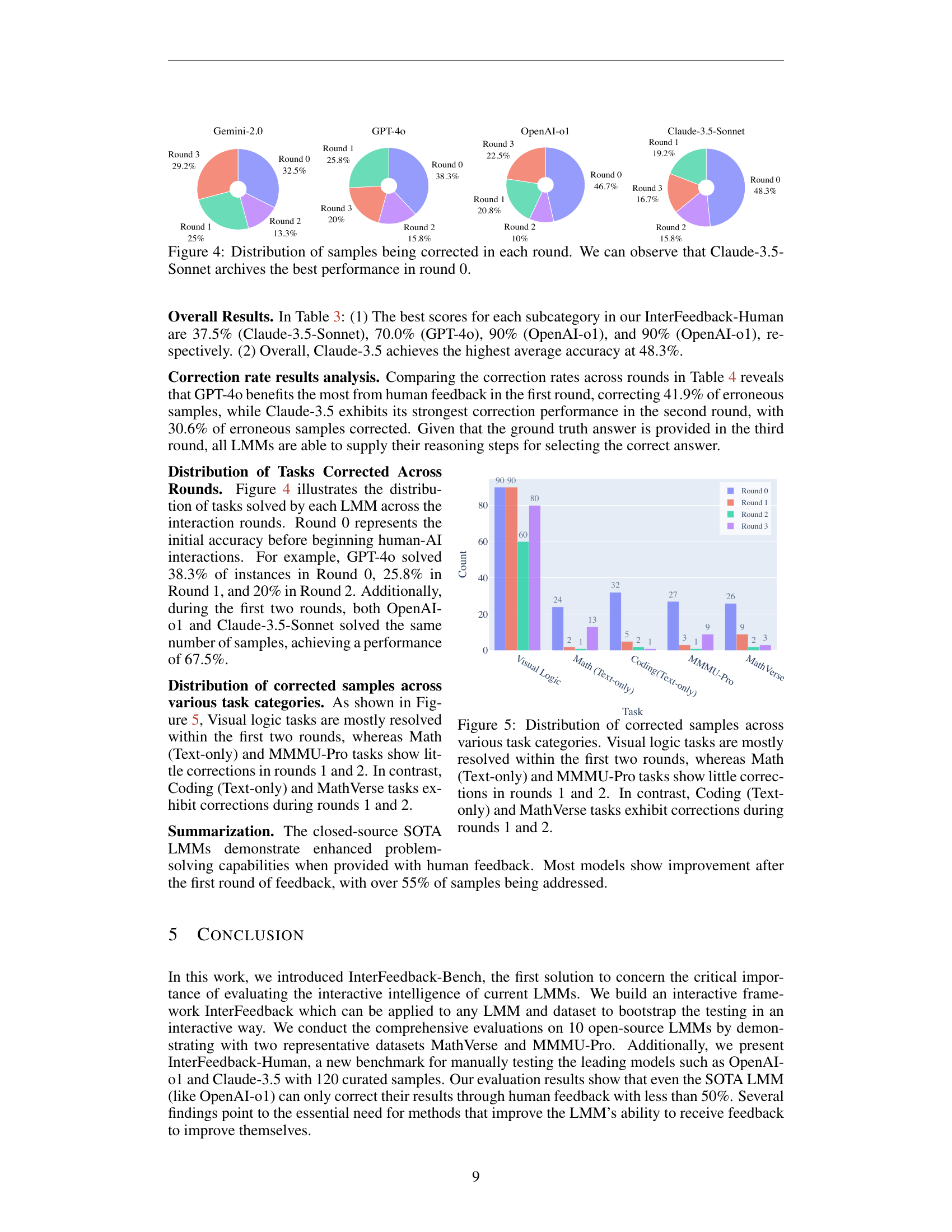
🔼 This figure shows the percentage of samples that were initially incorrect but were later corrected in each round of interaction for four different large language models (LLMs): Gemini-2.0, GPT-40, OpenAI-01, and Claude-3.5-Sonnet. Each model’s initial accuracy (round 0) and accuracy after each subsequent round of feedback is represented by different colored segments. The size of each segment is proportional to the percentage of samples corrected in that round. The figure illustrates how the models improve iteratively through human feedback, but also highlights that different models begin at different levels of accuracy and improve at varying rates.
read the caption
Figure 4: Distribution of samples being corrected in each round. We can observe that Claude-3.5-Sonnet archives the best performance in round 0.

🔼 This bar chart displays the distribution of correctly answered questions across different task categories and rounds of interaction. Visual logic problems saw the most improvements after the first two rounds of feedback. In contrast, math problems (text-based) and MMMU-Pro problems showed less improvement across the first two rounds. Coding (text-based) and MathVerse problems demonstrated a moderate level of correction across the first two rounds.
read the caption
Figure 5: Distribution of corrected samples across various task categories. Visual logic tasks are mostly resolved within the first two rounds, whereas Math (Text-only) and MMMU-Pro tasks show little corrections in rounds 1 and 2. In contrast, Coding (Text-only) and MathVerse tasks exhibit corrections during rounds 1 and 2.

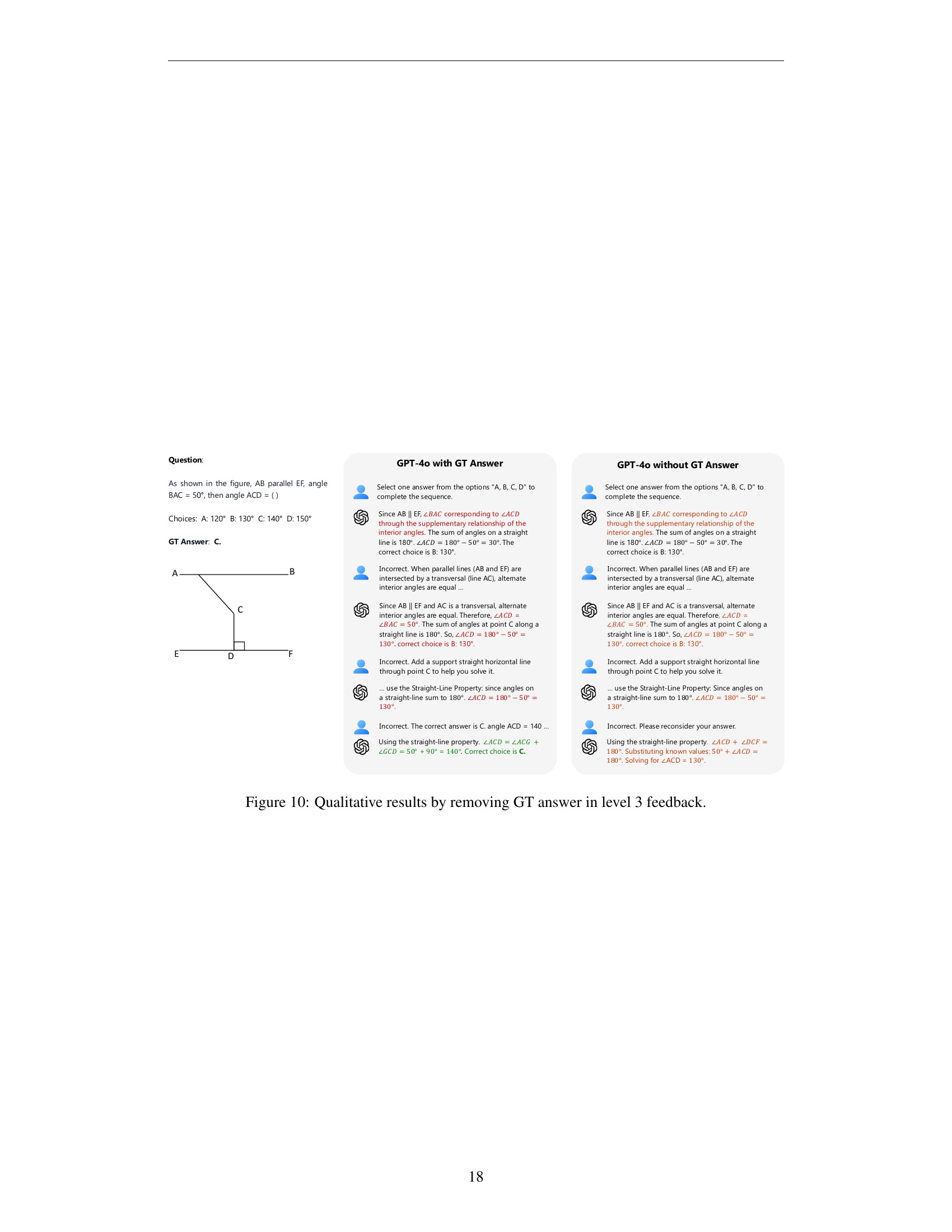
🔼 This figure displays a qualitative comparison of how different Large Multimodal Models (LMMs) perform on a visual reasoning task. The task involves selecting the correct option from four choices to complete a sequence or reveal a pattern in a series of images. The figure shows the responses of three different LMMs (Claude-3.5 Sonnet, Gemini 2.0 Flash, and OpenAI-01) to the same question. Each model’s response, including intermediate steps and any corrections made, is presented. This illustrates the various approaches and reasoning processes of each LMM. The differences in reasoning steps and the number of iterations needed to arrive at the correct answer highlight the varying capabilities and challenges associated with interactive intelligence in LMMs.
read the caption
Figure 6: Qualitative results on different LMMs.

🔼 This figure presents a qualitative comparison of different Large Multimodal Models (LMMs) in solving a geometry problem. The problem involves finding the measure of angle CED given that DE is parallel to BC, angle A = 80°, and angle B = 60°. The figure displays the responses of three different LMMs (Claude-3.5-Sonnet, Gemini-2.0 Flash, and OpenAI-01) to the problem. Each model’s response shows the steps taken to arrive at the answer, including any corrections made after receiving feedback. This showcases the models’ varying capabilities in problem-solving and reasoning, and their ability to utilize feedback to improve the solution.
read the caption
Figure 7: Qualitative results on different LMMs.

🔼 This figure demonstrates how Large Multimodal Models (LMMs) tend to guess answers when faced with challenging problems they cannot readily solve. Two instances of the same question are shown, highlighting how the model, even with feedback, produces different incorrect answers on separate attempts, before ultimately settling on a final answer (which may or may not be correct). The figure visually represents the limitations of LMMs and suggests a reliance on elimination rather than true reasoning in certain situations.
read the caption
Figure 8: An example that model tends to guess answers.

🔼 This figure demonstrates how large language models (LLMs) resort to guessing when faced with challenging problems. It showcases two instances where, despite receiving feedback, the models’ responses are inconsistent across different runs for the same problem. This suggests that the models may not be truly reasoning but are simply trying to eliminate incorrect answers rather than utilizing a logical problem-solving strategy. The inconsistency highlights the limitations of LLMs in tackling complex questions effectively, even with guidance.
read the caption
Figure 9: An example that model tends to guess answers.
More on tables
| Model | GPT-4o | Gemini-1.5-Flash | Claude-3.5-Sonnet | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc (%) | # Neg | # Test | Detail (%) | Simple (%) | # Test | Detail (%) | Simple (%) | # Test | Detail (%) | Simple (%) | |
| LLaVa-OneVision-7B | 47.1 | 915 | 312 | 31.7 | 15.7 | 333 | 35.4 | 18.6 | 408 | 27.5 | 16.4 |
| InternVL2-8B | 45.7 | 939 | 343 | 50.1 | 41.4 | 329 | 57.1 | 50.2 | 437 | 50.1 | 41.2 |
| Molmo-7B | 43.8 | 973 | 362 | 51.7 | 48.9 | 383 | 41.5 | 43.1 | 436 | 29.8 | 27.5 |
| MiniCPM-V | 38.1 | 1071 | 410 | 27.3 | 23.7 | 503 | 21.5 | 21.7 | 540 | 24.4 | 23.3 |
| GLM-4V-9B | 46.0 | 935 | 327 | 38.8 | 30.0 | 359 | 38.7 | 31.5 | 441 | 34.9 | 27.9 |
| Phi3.5-Vision-4.2B | 43.2 | 983 | 366 | 44.3 | 42.3 | 396 | 40.9 | 39.6 | 484 | 39.9 | 38.0 |
| LLaVa-1.5-7B | 36.5 | 1099 | 506 | 31.9 | 12.3 | 470 | 20.0 | 16.0 | 595 | 13.9 | 13.4 |
| LLaVa-1.6-Mistral-7B | 38.8 | 1058 | 432 | 46.1 | 36.1 | 429 | 14.7 | 14.7 | 515 | 42.3 | 35.3 |
| Fuyu-8B | 34.1 | 1140 | 481 | 6.0 | 8.7 | 1140 | 3.7 | 3.5 | 612 | 9.5 | 6.9 |
| Qwen2-VL-7B | 48.1 | 898 | 268 | 50.4 | 44.8 | 322 | 39.4 | 37.6 | 389 | 42.9 | 37.3 |
🔼 This table presents the correction rates achieved by three different feedback providers (GPT-40, Gemini-1.5-Flash, and Claude-3.5-Sonnet) when assisting various Large Multimodal Models (LMMs) in solving problems from the MMMU-Pro dataset. The experiment is performed using a single image setting for each problem in MMMU-Pro. For each LMM and feedback provider combination, the table shows the accuracy, the number of negative samples, the total number of test samples, and the correction rates using both detailed LMM-generated feedback and simple binary feedback. The correction rate indicates the percentage of initially incorrect answers that were successfully corrected with the feedback.
read the caption
Table 2: Correction Rate Results of three Feedback Providers on MMMU-Pro Dataset. We test models on a single image setting of MMMU-Pro.
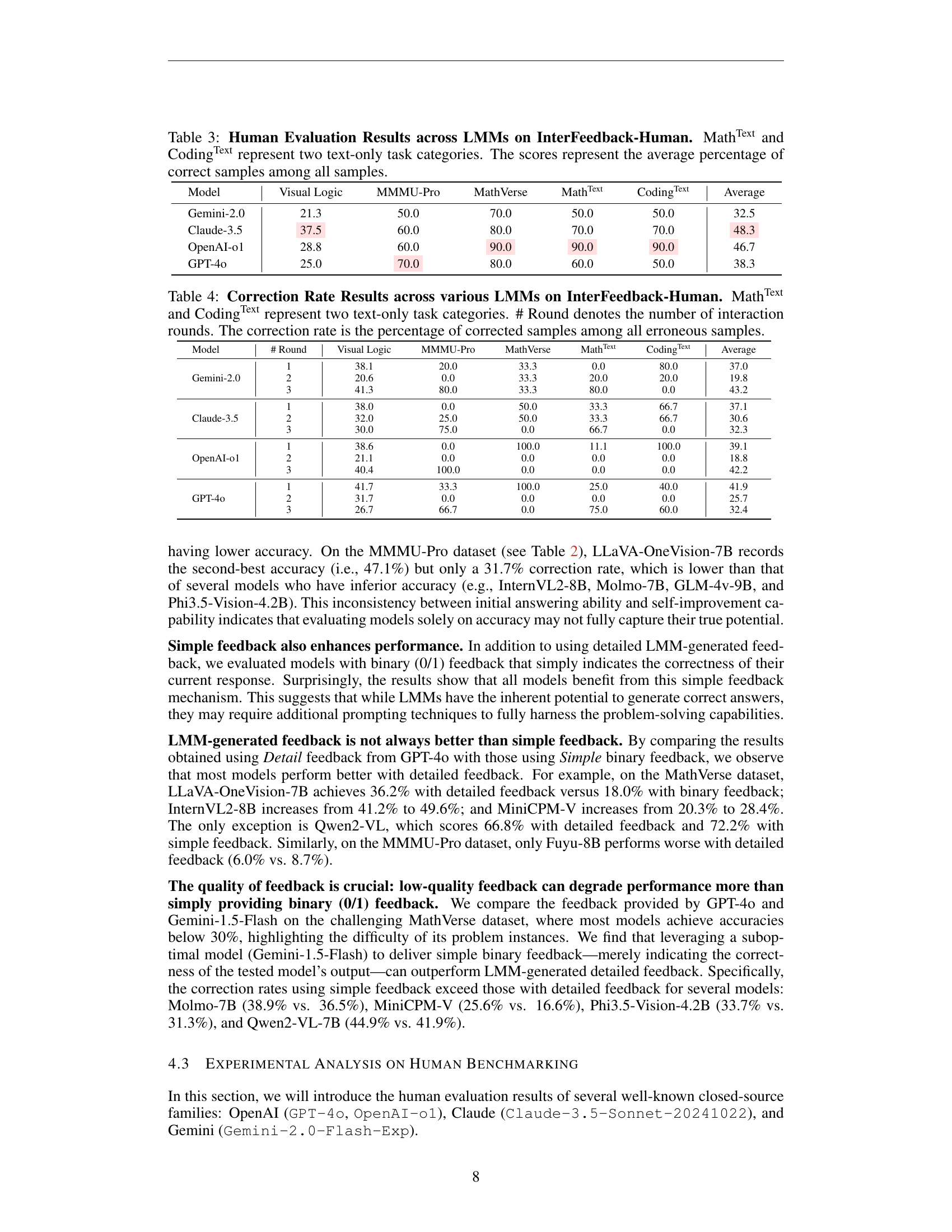
| Model | Visual Logic | MMMU-Pro | MathVerse | Math | Coding | Average |
|---|---|---|---|---|---|---|
| Gemini-2.0 | 21.3 | 50.0 | 70.0 | 50.0 | 50.0 | 32.5 |
| Claude-3.5 | 37.5 | 60.0 | 80.0 | 70.0 | 70.0 | 48.3 |
| OpenAI-o1 | 28.8 | 60.0 | 90.0 | 90.0 | 90.0 | 46.7 |
| GPT-4o | 25.0 | 70.0 | 80.0 | 60.0 | 50.0 | 38.3 |
🔼 Table 3 presents the human evaluation results for several Large Multimodal Models (LMMs) on the InterFeedback-Human dataset. The dataset contains various task types, including visual logic problems, mathematical and coding tasks, and text-only problems categorized as MathText and CodingText. The table shows the average percentage of correct answers achieved by each LMM across all samples in each task category. This provides a comprehensive assessment of the models’ capabilities in interactive human-AI scenarios.
read the caption
Table 3: Human Evaluation Results across LMMs on InterFeedback-Human. MathTextText{}^{\text{Text}}start_FLOATSUPERSCRIPT Text end_FLOATSUPERSCRIPT and CodingTextText{}^{\text{Text}}start_FLOATSUPERSCRIPT Text end_FLOATSUPERSCRIPT represent two text-only task categories. The scores represent the average percentage of correct samples among all samples.
| Model | # Round | Visual Logic | MMMU-Pro | MathVerse | Math | Coding | Average |
|---|---|---|---|---|---|---|---|
| Gemini-2.0 | 1 | 38.1 | 20.0 | 33.3 | 0.0 | 80.0 | 37.0 |
| 2 | 20.6 | 0.0 | 33.3 | 20.0 | 20.0 | 19.8 | |
| 3 | 41.3 | 80.0 | 33.3 | 80.0 | 0.0 | 43.2 | |
| Claude-3.5 | 1 | 38.0 | 0.0 | 50.0 | 33.3 | 66.7 | 37.1 |
| 2 | 32.0 | 25.0 | 50.0 | 33.3 | 66.7 | 30.6 | |
| 3 | 30.0 | 75.0 | 0.0 | 66.7 | 0.0 | 32.3 | |
| OpenAI-o1 | 1 | 38.6 | 0.0 | 100.0 | 11.1 | 100.0 | 39.1 |
| 2 | 21.1 | 0.0 | 0.0 | 0.0 | 0.0 | 18.8 | |
| 3 | 40.4 | 100.0 | 0.0 | 0.0 | 0.0 | 42.2 | |
| GPT-4o | 1 | 41.7 | 33.3 | 100.0 | 25.0 | 40.0 | 41.9 |
| 2 | 31.7 | 0.0 | 0.0 | 0.0 | 0.0 | 25.7 | |
| 3 | 26.7 | 66.7 | 0.0 | 75.0 | 60.0 | 32.4 |
🔼 This table presents the correction rates achieved by various Large Multimodal Models (LMMs) on the InterFeedback-Human benchmark. The benchmark consists of five types of tasks: visual logic, mathematical logic, coding, MMMU-Pro, and MathVerse. MathText and CodingText represent text-only tasks within the benchmark. The table shows the correction rate (percentage of initially incorrect answers that were subsequently corrected) for each LMM across three interaction rounds. Round 0 indicates the initial accuracy before any interaction, while subsequent rounds reflect improvements after receiving human feedback.
read the caption
Table 4: Correction Rate Results across various LMMs on InterFeedback-Human. MathTextText{}^{\text{Text}}start_FLOATSUPERSCRIPT Text end_FLOATSUPERSCRIPT and CodingTextText{}^{\text{Text}}start_FLOATSUPERSCRIPT Text end_FLOATSUPERSCRIPT represent two text-only task categories. # Round denotes the number of interaction rounds. The correction rate is the percentage of corrected samples among all erroneous samples.
🔼 This table lists the large multimodal models (LMMs) used in the InterFeedback-Bench benchmark. For each model, it provides the release date and a link to its source. This information is crucial for reproducibility and allows researchers to easily access the specific versions of the models used in the study. The models are categorized into closed-source and open-source, reflecting their accessibility and licensing.
read the caption
Table 5: The release time and model source of LMMs used in our InterFeedback-Bench.
Full paper#