TL;DR#
Machine unlearning aims to remove specific data from pre-trained models, but this often degrades the model’s performance on other data. This collateral damage leads to poor deletion or unusable models. Current unlearning methods struggle to balance removing information and preserving other abilities of the model. Therefore, finding the right data is crucial for utility-preserving coreset selection.
This paper introduces UPCORE (Utility-Preserving Coreset Selection), a framework that minimizes collateral damage during unlearning. By selectively pruning the forget set to remove outliers, UPCORE reduces model degradation after unlearning. The method uses isolation forests to identify and remove outlier data points in the forget set. UPCORE achieves superior balance between deletion efficacy and model preservation across standard unlearning methods.
Key Takeaways#
Why does it matter?#
This paper is important for researchers who work on privacy, security, and fairness in machine learning. The method for utility preservation will offer an approach to unlearning that mitigates collateral damage. It highlights a new metric, AUC, for evaluating the trade-off between privacy and utility, and shows how it can be combined with existing unlearning methods to achieve better results and thus opens new avenues for future investigation. This research contributes to the development of safer, more reliable, and ethically aligned AI systems.
Visual Insights#

🔼 This figure illustrates the core concept of the UPCORE method. The left panel shows how standard unlearning methods impact the entire forget set uniformly. This can lead to collateral damage where information outside the forget set is unintentionally lost due to the presence of outliers (points with high variance in the model’s hidden representation) within the forget set. The right panel demonstrates how UPCORE addresses this problem. By identifying and removing outliers, UPCORE creates a lower-variance coreset. This coreset is then used for unlearning, minimizing collateral damage. Furthermore, UPCORE leverages positive transfer learning from the coreset to the pruned points; the pruned points benefit from the learned information of the coreset and are also successfully unlearned without causing negative transfer to the other data points.
read the caption
Figure 1: Left: Standard unlearning methods are applied equally to all points in the forget set. Here, outlier points in the model’s hidden space (visualized in 2D) contribute to the unintentional forgetting of points outside of the forget set (i.e. collateral damage). Right: By finding a lower-variance coreset within the forget set, UPCORE reduces damage while maintaining forget performance via positive transfer from the coreset to the pruned points.
| Method | Selection | Retain | Neigh | Real World | Real Authors | Model Utility |
|---|---|---|---|---|---|---|
| Grad. Ascent | Complete | 0.488 | 0.568 | 0.720 | 0.891 | 0.343 |
| Random | 0.495 | 0.558 | 0.731 | 0.907 | 0.353 | |
| UPCORE | 0.523 | 0.608 | 0.769 | 0.933 | 0.387 | |
| Refusal | Complete | 0.493 | 0.488 | 0.714 | 0.890 | 0.366 |
| Random | 0.456 | 0.458 | 0.644 | 0.819 | 0.332 | |
| UPCORE | 0.500 | 0.524 | 0.744 | 0.920 | 0.381 | |
| NPO | Complete | 0.281 | 0.237 | 0.192 | 0.342 | 0.199 |
| Random | 0.253 | 0.271 | 0.195 | 0.308 | 0.186 | |
| UPCORE | 0.329 | 0.319 | 0.246 | 0.414 | 0.248 |
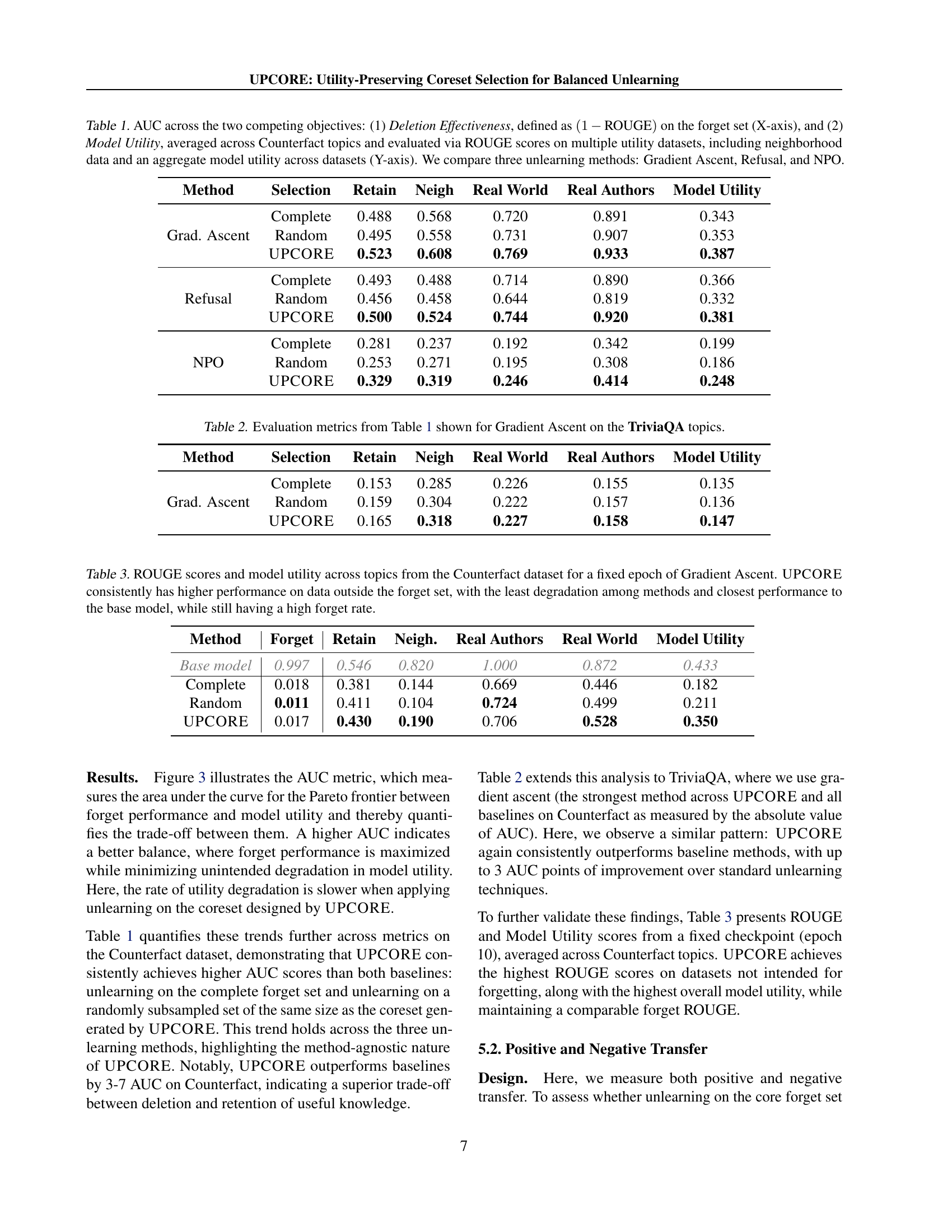
🔼 This table presents the Area Under the Curve (AUC) values, which represents a trade-off between deletion effectiveness and model utility. Deletion effectiveness is measured by (1 - ROUGE) score on the forget set (how well the model forgets the unwanted information), while model utility is evaluated using ROUGE scores across several datasets: retain set, neighborhood data, real-world data, and real-author data. An aggregate model utility score is also calculated by combining these metrics. The results are shown for three different unlearning methods: Gradient Ascent, Refusal, and Negative Preference Optimization (NPO), and for three coreset selection methods: selecting the complete forget set, a random subset of the forget set and the UPCORE coreset.
read the caption
Table 1: AUC across the two competing objectives: (1) Deletion Effectiveness, defined as (1−ROUGE)1ROUGE(1-\text{ROUGE})( 1 - ROUGE ) on the forget set (X-axis), and (2) Model Utility, averaged across Counterfact topics and evaluated via ROUGE scores on multiple utility datasets, including neighborhood data and an aggregate model utility across datasets (Y-axis). We compare three unlearning methods: Gradient Ascent, Refusal, and NPO.
In-depth insights#
CoreSet Selection#
Coreset selection focuses on identifying representative subsets of a larger dataset, aiming to maintain key properties while reducing computational burden. Traditional coreset selection emphasizes coverage, diversity, or data point importance, improving training efficiency in supervised learning. In the context of machine unlearning, coreset selection offers a novel approach by focusing on data points disproportionately contributing to collateral damage. This involves strategically pruning outliers to minimize utility loss while ensuring effective knowledge removal. It differs from typical coreset methods primarily targeting classification or regression tasks by adapting to the unique challenges of unlearning, where preserving utility and ensuring data deletion accuracy are critical and often conflicting goals.
Variance Impact#
Variance significantly impacts unlearning, influencing how effectively a model forgets specific data. Higher variance indicates a wider spread of data points in the model’s latent space, leading to greater collateral damage during unlearning. Removing high-variance (outlier) points reduces the overall data spread, minimizing unintended utility degradation. Strategies like pruning outliers or creating compact coresets effectively control variance, striking a better balance between data removal and model preservation. Understanding and managing variance is critical for optimizing unlearning performance and ensuring the continued usefulness of the model.
AUC Improvement#
The paper introduces UPCORE, a method for balanced unlearning that aims to minimize the trade-off between removing information and maintaining model utility. The paper introduces a new metric, Area Under the Curve (AUC), across standard unlearning metrics to evaluate the effectiveness of unlearning methods. A higher AUC indicates a better balance, with improved forget performance and minimized degradation in model utility on non-forget data. The experimental results show that UPCORE consistently achieves higher AUC compared to baseline methods like unlearning on the complete forget set and unlearning on a randomly sampled subset. This means UPCORE provides a superior trade-off between deletion efficacy and model utility across various unlearning methods and datasets. The AUC improvement suggests that UPCORE is more effective in generalizing to variations of the forgotten information and is more robust to blackbox attacks attempting to extract the deleted information.
Positive Transfer#
Positive transfer in machine unlearning is a fascinating yet underexplored phenomenon. It refers to the ability of an unlearning process, designed to remove specific knowledge from a model, to inadvertently improve the model’s performance on related, yet distinct, tasks or data points. Intuitively, one might expect unlearning to only degrade performance, as it involves selectively ‘forgetting’ information. However, positive transfer suggests that this targeted forgetting can sometimes lead to a better generalization or a reduction in overfitting. One potential explanation is that unlearning can act as a form of regularization, preventing the model from memorizing noisy or irrelevant details. It is crucial to carefully evaluate and control positive transfer effects to ensure that the unlearning process achieves its intended goal of removing undesirable knowledge without compromising the model’s overall utility or introducing unintended biases. Furthermore, this concept highlights the complex interplay between different pieces of information within a model.
Robust Unlearning#
Robust unlearning aims to ensure that the removal of specific information from a machine learning model does not compromise its overall utility or create vulnerabilities. This is crucial because simply deleting data can lead to unintended consequences like reduced accuracy on other tasks or susceptibility to adversarial attacks attempting to recover the ‘forgotten’ knowledge. A robust unlearning method should generalize well to rephrased inputs and be resilient to jailbreaking attempts, indicating genuine removal rather than superficial alteration. Balancing deletion effectiveness with utility preservation is a key challenge, often necessitating strategies like coreset selection to identify and prune influential data points while retaining core knowledge. Evaluation across diverse settings and metrics is essential to assess robustness, considering factors like model utility, negative transfer, and resilience to various attacks.
More visual insights#
More on figures

🔼 This figure illustrates the four stages of the UPCORE algorithm. Stage 1 involves extracting the hidden states from the large language model (LLM) being modified. These hidden states represent the LLM’s internal representation of the data. Stage 2 uses Isolation Forests to identify outlier data points within the forget set (data to be removed). These outliers are points that significantly increase the variance of the model’s representation. In Stage 3, the algorithm prunes or removes these identified outliers to create a core forget set, a smaller subset of the original forget set with lower variance. Finally, Stage 4 applies an unlearning method to the LLM, using only the selected core forget set to remove the targeted information while minimizing unintended damage to the model’s overall performance.
read the caption
Figure 2: UPCORE has four stages. First, we extract hidden states from the LLM to be modified; second, we identify outliers using Isolation Forests; third, we prune outliers to select a core forget set, and fourth, we perform unlearning on the coreset.

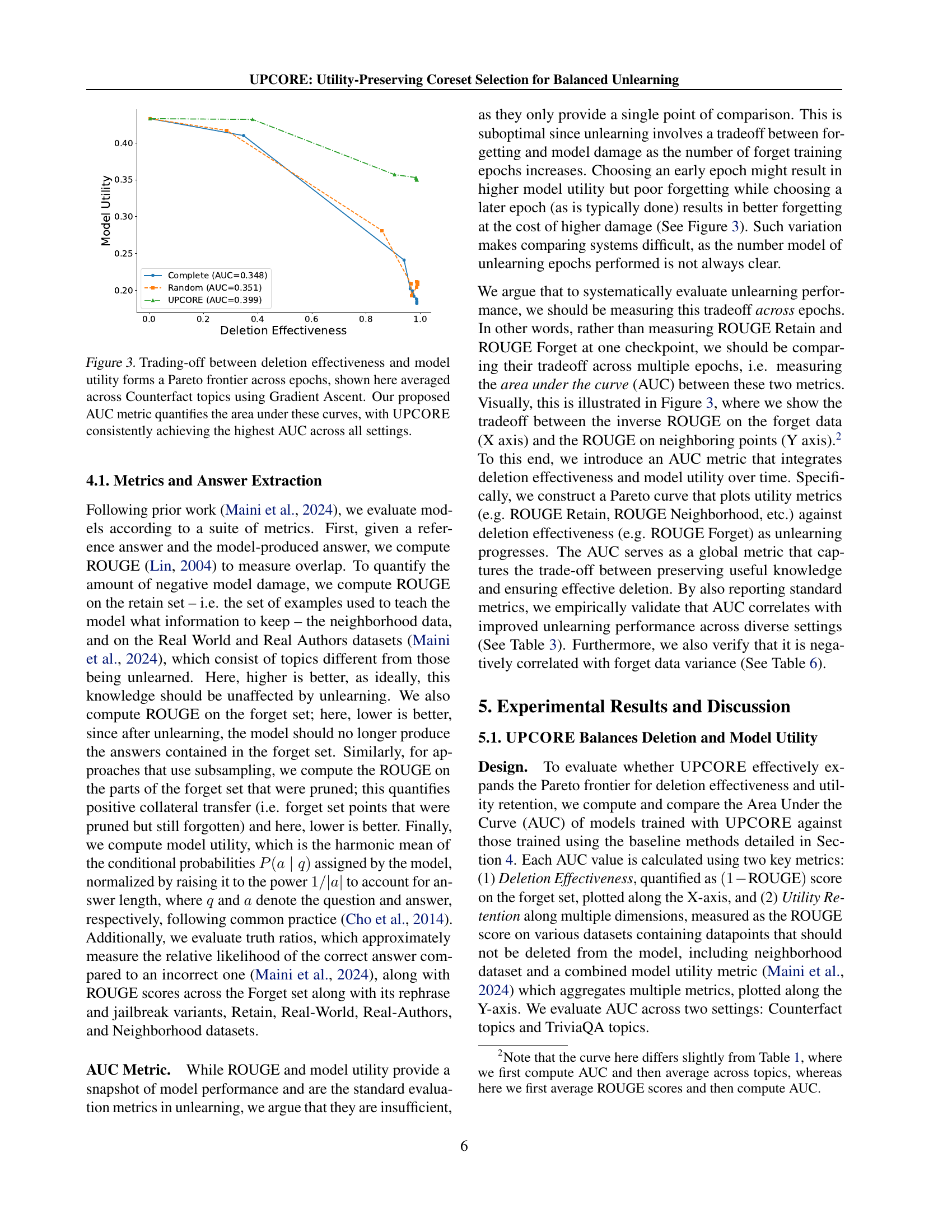
🔼 This figure demonstrates the trade-off between deletion effectiveness (how well the model forgets the unwanted information) and model utility (how well the model performs on other tasks) across different training epochs during the unlearning process. The x-axis represents deletion effectiveness, while the y-axis represents model utility. Each line represents a different method: complete unlearning (applying unlearning to the full forget set), random unlearning (applying unlearning to a random subset of the forget set), and UPCORE (the proposed method). The area under the curve (AUC) for each method is calculated to quantify the overall performance. UPCORE consistently achieves the highest AUC, indicating a superior balance between effective deletion and the preservation of model utility. This showcases the advantage of UPCORE over traditional unlearning methods.
read the caption
Figure 3: Trading-off between deletion effectiveness and model utility forms a Pareto frontier across epochs, shown here averaged across Counterfact topics using Gradient Ascent. Our proposed AUC metric quantifies the area under these curves, with UPCORE consistently achieving the highest AUC across all settings.

🔼 This figure displays the area under the curve (AUC) for two metrics: ROUGE score on the forget set (measuring successful deletion) and ROUGE score on the neighborhood data (measuring unintended model damage). The AUC is calculated for three different coreset selection methods: complete (using the whole forget set), random (using a random sample of the forget set), and UPCORE. The graph shows that UPCORE consistently achieves a higher AUC across three different unlearning methods (Gradient Ascent, Refusal, and NPO), indicating a superior balance between effective deletion and preservation of model utility on related but unseen data. The results highlight that UPCORE effectively reduces unintended damage to neighborhood data by carefully selecting a coreset of the forget data.
read the caption
Figure 4: AUC between forget set ROUGE and neighborhood data ROUGE averaged across topics in Counterfact. UPCORE reduces damage to neighborhood data.

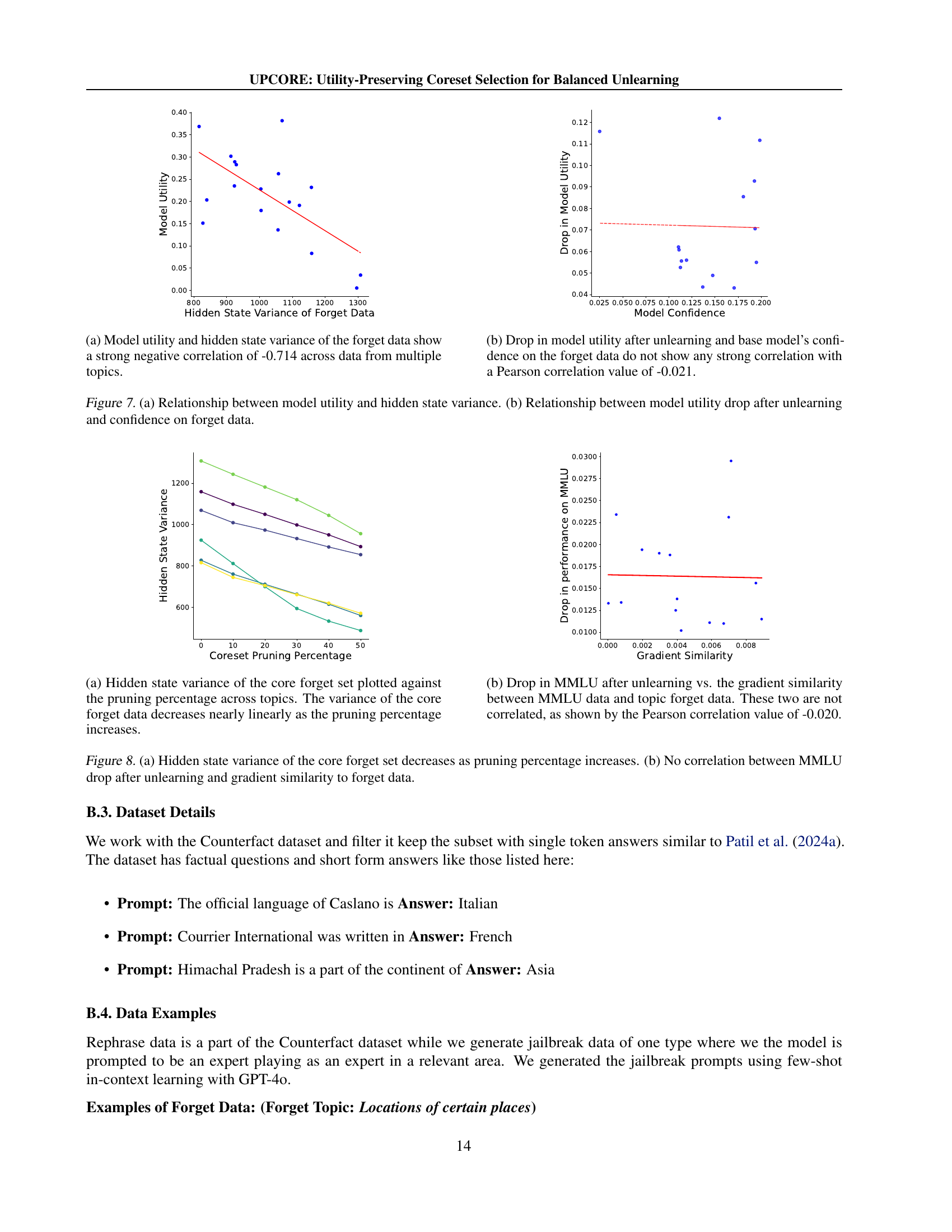
🔼 This figure examines how changing the size of the coreset, created by pruning outliers, affects the model’s performance. The coreset size is varied by adjusting the percentage of data points pruned. The x-axis represents the different pruning percentages, while the y-axis shows the AUC (Area Under the Curve) score, calculated for various utility metrics (assessing the model’s performance on data outside the unlearning scope). These metrics are averaged across multiple topics from the Counterfact dataset. The figure helps determine the optimal balance between effective data removal and preserving model utility by showing how AUC varies across different pruning rates. It shows the tradeoff between deletion effectiveness and model utility in unlearning.
read the caption
Figure 5: Impact of scaling the coreset size on performance: AUC scores on different utility sets, averaged across Counterfact topics, for various pruning percentages.

🔼 This figure visualizes the variance of hidden states within the forget sets generated by different methods for unlearning, namely the baseline approach and UPCORE. It showcases the variance of hidden states for six different topics from the Counterfact dataset. Each bar represents a specific topic, and the height shows the variance. The comparison highlights that UPCORE, which employs Isolation Forests for coreset selection, significantly reduces the variance in the hidden states compared to the baseline approach. This reduction in variance is a key outcome of UPCORE, as it aims to minimize the impact of unlearning on other parts of the model by selecting a subset of forget data with lower variance.
read the caption
Figure 6: Hidden state variance of the baseline and UPCORE forget sets across the six Counterfact forget topics. UPCORE consistently reduces variance using Isolation Forest as expected.

🔼 This figure displays the relationship between model utility and the variance of the model’s hidden states for data points in the forget set. The analysis is performed across multiple topics to demonstrate that this negative correlation is consistent even across different subject matters. The correlation coefficient of -0.714 indicates a strong inverse relationship: as the variance of hidden states in the forget set increases, the model’s utility decreases after unlearning.
read the caption
(a) Model utility and hidden state variance of the forget data show a strong negative correlation of -0.714 across data from multiple topics.

🔼 This figure examines the relationship between the drop in model utility after unlearning and the model’s confidence scores on the forget data. The analysis reveals a weak negative correlation (Pearson correlation coefficient of -0.021), suggesting that the model’s initial confidence in the data to be forgotten is not a strong predictor of the amount of utility loss experienced after unlearning. This implies that factors beyond simple confidence scores likely play a crucial role in determining the impact of unlearning on model performance. The plot likely shows a scatter plot with model confidence on the x-axis and drop in model utility on the y-axis, with each point representing a data point from the forget set.
read the caption
(b) Drop in model utility after unlearning and base model’s confidence on the forget data do not show any strong correlation with a Pearson correlation value of -0.021.

🔼 Figure 7 displays the correlation between model performance and two factors: hidden state variance and model confidence. Panel (a) shows a strong negative correlation between model utility (measured after unlearning) and the variance of hidden states in the model’s representation of the data points designated for unlearning. Higher variance leads to lower model utility after unlearning. Panel (b) shows that there is little to no correlation between the drop in model utility after unlearning and the model’s confidence scores on those same data points. This suggests that variance of model representations is a more significant factor influencing the amount of collateral damage during unlearning than model confidence.
read the caption
Figure 7: (a) Relationship between model utility and hidden state variance. (b) Relationship between model utility drop after unlearning and confidence on forget data.

🔼 This figure shows the relationship between the variance of the hidden states in the core forget set and the pruning percentage applied during the coreset selection process. The x-axis represents the percentage of data points pruned from the initial forget set, while the y-axis represents the variance of the hidden states of the remaining points (the core forget set). As the pruning percentage increases (more points are removed), the variance of the hidden states in the core forget set decreases almost linearly. This demonstrates the effectiveness of the pruning strategy in reducing the variance within the forget set, a key factor in mitigating the collateral damage during the unlearning process.
read the caption
(a) Hidden state variance of the core forget set plotted against the pruning percentage across topics. The variance of the core forget data decreases nearly linearly as the pruning percentage increases.
More on tables
| Method | Selection | Retain | Neigh | Real World | Real Authors | Model Utility |
|---|---|---|---|---|---|---|
| Grad. Ascent | Complete | 0.153 | 0.285 | 0.226 | 0.155 | 0.135 |
| Random | 0.159 | 0.304 | 0.222 | 0.157 | 0.136 | |
| UPCORE | 0.165 | 0.318 | 0.227 | 0.158 | 0.147 |
🔼 This table presents the results of the Gradient Ascent unlearning method applied to TriviaQA topics. It shows the performance metrics (Retain, Neigh, Real World, Real Authors, Model Utility) from Table 1, but specifically focusing on the TriviaQA dataset. These metrics evaluate the trade-off between deletion accuracy (how well the model forgets the specified information) and model utility (how well the model performs on related and unrelated tasks). The table compares three data selection methods: using the entire forget set, a random subset of the forget set, and the coreset selected by UPCORE. This allows for a comparison of how different strategies for selecting data points to unlearn affect the overall balance between these competing objectives.
read the caption
Table 2: Evaluation metrics from Table 1 shown for Gradient Ascent on the TriviaQA topics.
| Method | Forget | Retain | Neigh. | Real Authors | Real World | Model Utility |
|---|---|---|---|---|---|---|
| Base model | 0.997 | 0.546 | 0.820 | 1.000 | 0.872 | 0.433 |
| Complete | 0.018 | 0.381 | 0.144 | 0.669 | 0.446 | 0.182 |
| Random | 0.011 | 0.411 | 0.104 | 0.724 | 0.499 | 0.211 |
| UPCORE | 0.017 | 0.430 | 0.190 | 0.706 | 0.528 | 0.350 |
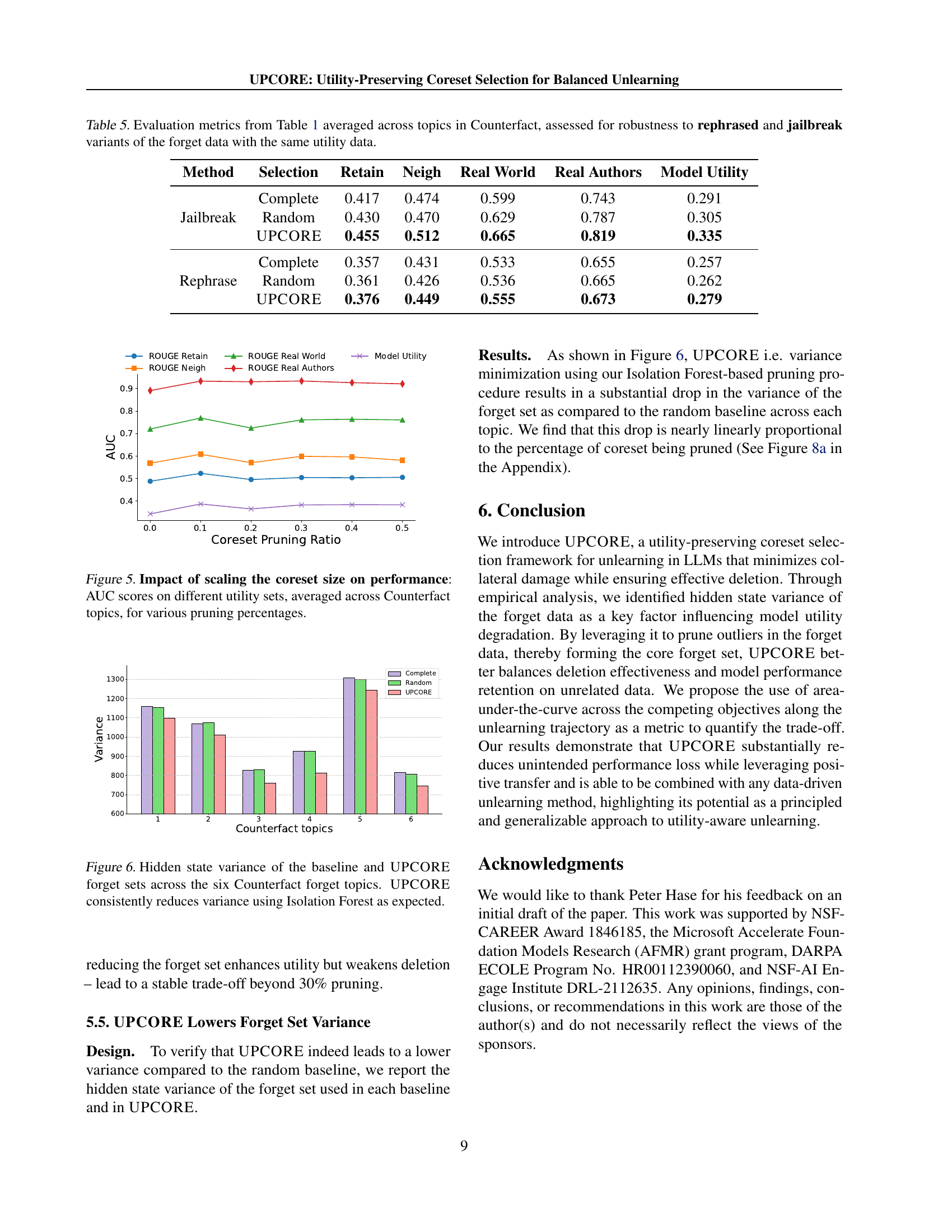
🔼 Table 3 presents a detailed comparison of ROUGE scores and model utility across different topics from the Counterfact dataset. The experiment uses Gradient Ascent as the unlearning method, evaluating performance at a specific epoch. The table showcases UPCORE’s superior balance in unlearning: maintaining high forget rates while minimizing negative impact on data outside the target set (retain set, neighborhood data, etc.). It highlights UPCORE’s superior performance compared to using the complete forget set or a randomly selected subset, demonstrating both higher forget rates and better preservation of model utility on other data.
read the caption
Table 3: ROUGE scores and model utility across topics from the Counterfact dataset for a fixed epoch of Gradient Ascent. UPCORE consistently has higher performance on data outside the forget set, with the least degradation among methods and closest performance to the base model, while still having a high forget rate.
| Method | Random | UPCORE |
|---|---|---|
| Gradient Ascent | 0.022 | 0.053 |
| Refusal | 0.169 | 0.127 |
| NPO | 0.206 | 0.231 |
🔼 This table presents the ROUGE scores achieved on the pruned data points after applying unlearning. It compares the results of UPCORE (which selectively prunes outliers from the forget set before unlearning) to a random subsampling method. The key observation is that even when unlearning is applied only to a subset of the forget data, the effect generalizes beyond that subset, influencing data points that were not directly unlearned. This demonstrates the presence of both positive and negative transfer: positive transfer is seen because unlearning a smaller subset (via pruning) still affects other data points within the same semantic group, while negative transfer is minimized through careful selection of the pruned points.
read the caption
Table 4: ROUGE score on pruned datapoints. Both for UPCORE and random sampling, unlearning on a subset of datapoints translates to other datapoints not in the subset.
| Method | Selection | Retain | Neigh | Real World | Real Authors | Model Utility |
|---|---|---|---|---|---|---|
| Jailbreak | Complete | 0.417 | 0.474 | 0.599 | 0.743 | 0.291 |
| Random | 0.430 | 0.470 | 0.629 | 0.787 | 0.305 | |
| UPCORE | 0.455 | 0.512 | 0.665 | 0.819 | 0.335 | |
| Rephrase | Complete | 0.357 | 0.431 | 0.533 | 0.655 | 0.257 |
| Random | 0.361 | 0.426 | 0.536 | 0.665 | 0.262 | |
| UPCORE | 0.376 | 0.449 | 0.555 | 0.673 | 0.279 |
🔼 This table presents the results of evaluating the robustness of the UPCORE method against rephrased and jailbroken versions of the forgotten data. It shows the performance of three coreset selection methods (Complete, Random, and UPCORE) across various metrics, including ROUGE scores on different data sets (Retain, Neigh, Real World, Real Authors) and overall Model Utility. The goal is to assess how well the methods maintain the balance between deletion efficacy and model preservation when faced with attempts to circumvent the unlearning process by reformulating or attacking the forgotten information.
read the caption
Table 5: Evaluation metrics from Table 1 averaged across topics in Counterfact, assessed for robustness to rephrased and jailbreak variants of the forget data with the same utility data.
| AUC | Correlation with HSV |
|---|---|
| Retain | -0.421 |
| Neigh | -0.507 |
| Real World | -0.371 |
| Real Authors | -0.489 |
| Model Utility | -0.612 |
🔼 This table presents the correlation coefficients between the variance of the hidden state representations of the forget set and the Area Under the Curve (AUC) values for various metrics. The AUC values, calculated across different topics, measure the trade-off between deletion effectiveness (how well the model forgets the target information) and model utility (how well the model performs on unrelated tasks). A negative correlation indicates that as the variance of the forget set increases, the AUC decreases, suggesting a worse trade-off between forgetting and model utility. This finding aligns with the observations in Section 3.2, where a negative correlation between model utility and variance was also observed.
read the caption
Table 6: Correlation between the forget set representation variance and the AUC across topics. The negative correlation values are consistent with the negative correlation of model utility and variance shown in Section 3.2.
Full paper#