TL;DR#
Current AI benchmarks predominantly focus on English, limiting insights into low-resource languages like Korean. Many benchmarks don’t compare AI performance to humans, hindering accurate AI proficiency measurement. Some benchmarks lack real-world application scenarios, limiting MLLM applicability. These limitations highlight the need for new evaluation resources.
This paper introduces KoNET, a benchmark dataset leveraging four Korean educational tests. The exams have rigorous standards and diverse questions. This helps with AI performance analysis across education levels. The assessment of a range of models uncover difficulties, subject diversity, and human error rates. The dataset builder will be open-sourced.
Key Takeaways#
Why does it matter?#
This paper introduces a novel benchmark to evaluate Korean language understanding in AI, filling a crucial gap. It fosters multilingual AI development and offers a new resource for assessing AI’s ability to generalize beyond English datasets. The human error rate analysis could lead to more human-like AI models.
Visual Insights#

🔼 Figure 1 presents a two-part overview of the KoNET benchmark. Part (a) showcases examples of mathematics problems from the four different educational levels included in KoNET (elementary, middle, high school, and college). This visually demonstrates the increasing complexity and difficulty of the problems as the educational level advances. Part (b) displays a graph illustrating the average accuracy of the top 30 AI models tested on each of the four KoNET exams. The graph clearly shows a decline in AI model accuracy as the difficulty of the exams increases from elementary to college level. This decrease highlights the challenges that current AI models face in handling complex, higher-level reasoning tasks.
read the caption
Figure 1: Examples and Performance Overview of KoNET. (a) Illustration of mathematics problem examples, highlighting the increased complexity and difficulty as the educational level progresses. (b) Demonstration of how the accuracy of contemporary AI models decreases with more advanced curricula. A detailed analysis is provided in Section 4.
In-depth insights#
Korean AI tests#
KoNET, a novel benchmark, addresses the gap in evaluating multimodal AI systems using Korean educational standards. It comprises four exams: KoEGED, KoMGED, KoHGED, and KOCSAT, each renowned for rigor and diverse questions, enabling comprehensive AI performance analysis across educational levels. By focusing on Korean, KoNET sheds light on model performance in less-explored languages. The benchmark allows direct comparison of AI with human performance given human error rates in dataset, underscoring crucial competencies for AI-driven educational technologies and real-world applicability.
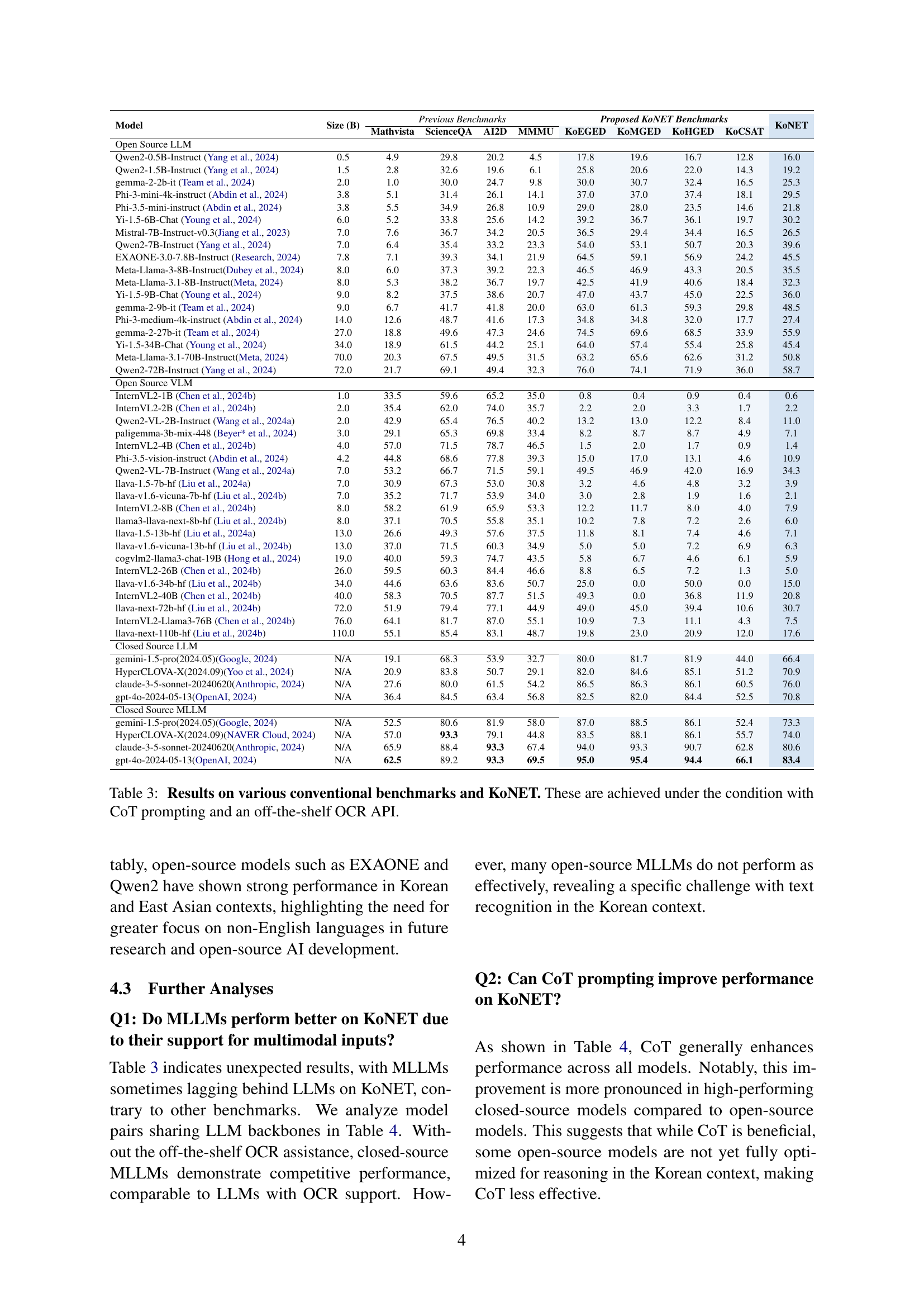
KoNET analysis#
KoNET analysis involves a multifaceted approach to assess AI’s capabilities in the Korean educational context. It includes evaluating AI performance against human benchmarks using error rates, offering insights into AI’s strengths and limitations in Korean educational content. It also includes an analysis of the performance differences between LLMs and MLLMs and demonstrates how many of the public models may underperform closed source models when unsupported by Korean OCR or if MLLMs are less effective in processing non-English contexts. Further, it evaluates the reliability of LLM-as-a-Judge approach and highlights its consistency. Finally, it explores the multilingual capabilities, revealing that Open Source models may show limited multilingual support than Closed Source, offering a comprehensive view.
Model error rates#
Model error rates are pivotal for understanding AI limitations relative to human performance. Analyzing these rates across diverse subjects reveals strengths/weaknesses in AI comprehension. Lower error rates in simpler comprehension imply AI excels in straightforward tasks, while higher error rates in complex reasoning mirror cognitive load challenges. Such analysis enhances model development towards nuanced understanding, potentially mimicking human-like error patterns in specific domains. Closed-source models, while often superior, still exhibit distinct error distributions, underscoring the need for tailored open-source development. This offers valuable insights to better align AI with human cognition.
OCR’s Impact#
Optical Character Recognition (OCR) has a profound impact on AI, especially in multimodal learning. By enabling AI to ‘see’ and understand text within images, OCR unlocks capabilities like processing scanned documents or extracting data from infographics. This textual information becomes crucial for MLLMs, augmenting visual cues. Without reliable OCR, MLLMs are limited to visual understanding, hindering comprehensive reasoning. The quality of OCR directly affects MLLM’s accuracy; poor OCR leads to misinterpretations and incorrect conclusions. Further optimization of OCR, particularly for diverse languages and fonts, is crucial for enhancing the overall performance and applicability of multimodal AI systems across various domains. The development and integration of efficient OCR are necessary to support more reliable AI.
Beyond English AI#
The phrase “Beyond English AI” highlights the crucial need to broaden the scope of AI development and evaluation beyond the dominant English-centric perspective. Current AI benchmarks and datasets heavily favor English, leading to skewed performance metrics and potentially overlooking biases that may exist in other languages and cultural contexts. Addressing this requires creating and utilizing datasets in diverse languages, like Korean as exemplified in the research paper, to rigorously assess AI capabilities across different linguistic landscapes. This also entails developing models specifically tuned for these languages, accounting for unique grammatical structures, cultural nuances, and regional variations. Furthermore, incorporating human error data from diverse populations becomes essential for ensuring AI systems generalize effectively and exhibit fair and equitable performance across different user groups. Ultimately, a focus on “Beyond English AI” is pivotal for building inclusive and globally relevant AI technologies.
More visual insights#
More on figures

🔼 Figure 2 presents a correlation analysis comparing human error rates with those of AI models. The x-axis represents human error rates obtained from the KoCSAT (Korean College Scholastic Ability Test), while the y-axis shows error rates from closed-source AI models. The analysis reveals the relationship between human and AI model performance on Korean educational questions. Appendix C.3 provides further details on the methodology used for calculating these error rates.
read the caption
Figure 2: Correlation analysis of error rates. The x-axis shows human error rates, and the y-axis displays error rates from closed-source models. Appendix C.3 offers a detailed discussion on the methods used to calculate these error rates.

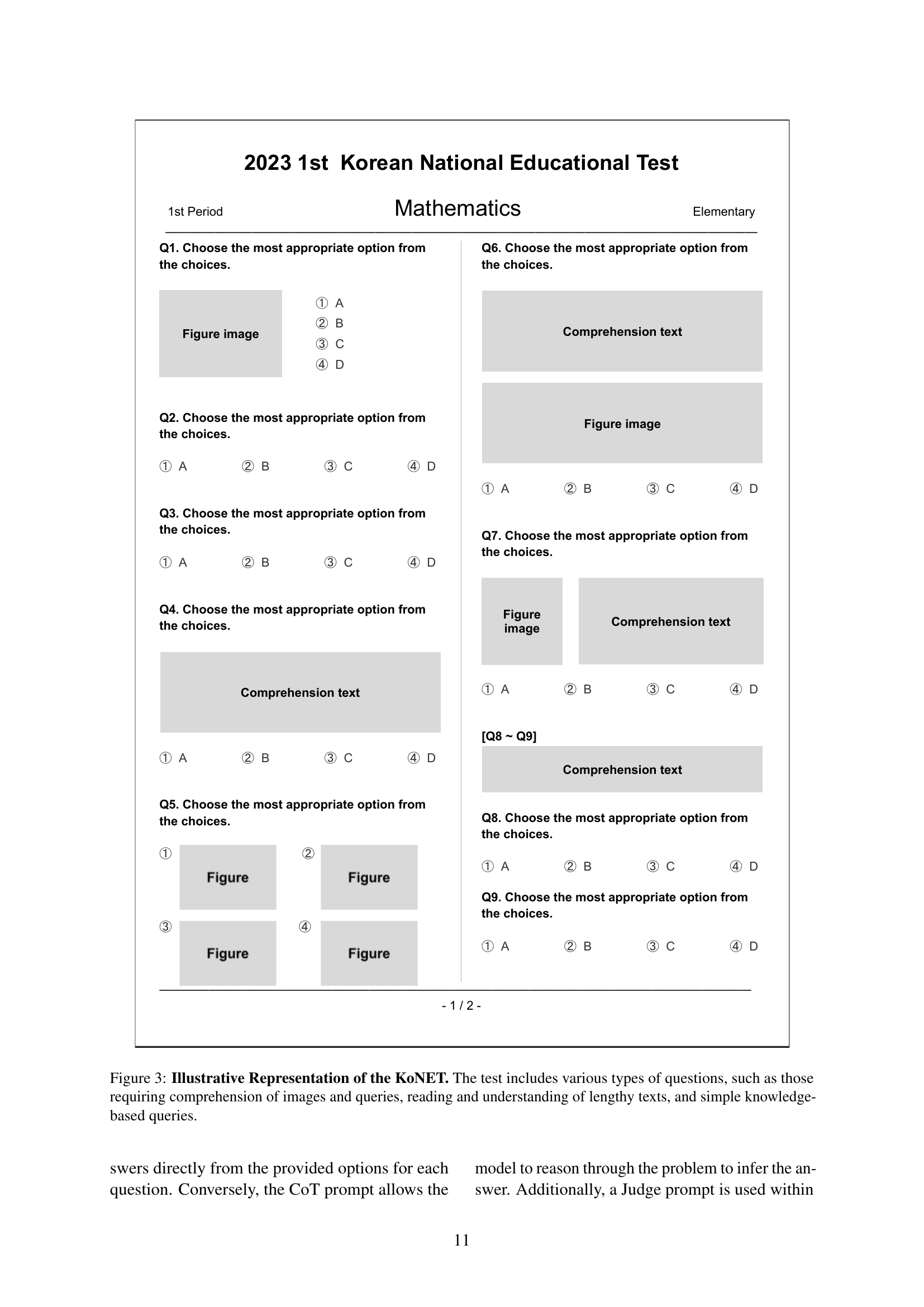
🔼 Figure 3 provides example questions from the KoNET dataset to illustrate the variety of question types included. It shows examples of questions requiring visual comprehension (of images and diagrams), reading comprehension (of longer text passages), and knowledge-based questions (requiring factual recall). The examples highlight the increasing complexity of question types as the educational level progresses from elementary school to high school and college.
read the caption
Figure 3: Illustrative Representation of the KoNET. The test includes various types of questions, such as those requiring comprehension of images and queries, reading and understanding of lengthy texts, and simple knowledge-based queries.

🔼 Figure 4 showcases the various prompt engineering techniques employed in the study. It details three main prompt types: Direct prompts, which directly ask the model for an answer; Chain-of-Thought (CoT) prompts, which guide the model through a step-by-step reasoning process before providing an answer; and Judge prompts, designed to evaluate the correctness of the responses produced by the model in comparison to the correct answer. Both Korean and English versions of each prompt type are displayed, highlighting the multilingual nature of the experiments. The figure provides a detailed illustration of how these different prompts are structured and used to elicit responses and assess their validity, demonstrating a comprehensive approach to prompt engineering.
read the caption
Figure 4: Examples of prompt formats used in the study. These include Direct prompts for answer extraction, CoT (Chain-of-Thought) prompts for reasoning-based inference, and Judge prompts for evaluating the accuracy of generated responses.

🔼 Figure 5 compares the performance of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) across several benchmark datasets, including KoNET (Korean National Educational Test Benchmark). The box plots illustrate the accuracy distribution for each model type on each benchmark. A key observation is that the performance difference between LLMs and MLLMs on KoNET is notably different from the performance difference observed on other benchmark datasets, suggesting that KoNET presents a unique evaluation challenge for MLLMs.
read the caption
Figure 5: Performance of LLMs and MLLMs across Previous benchmarks and KoNET. These present a performance comparison between LLMs and MLLMs across various benchmarks, including KoNET. These illustrate the accuracy distribution for each model type, but KoNET shows a different distribution trend between LLMs and MLLMs compared to other benchmarks.

🔼 Figure 6 shows three examples of comprehension tasks with varying difficulty levels, as measured by human error rates. The tasks are: sentence selection (left), where students choose the best sentence to complete a passage; sentence ordering (middle), where students arrange sentences in a logical order; and sentence insertion (right), where students determine the best place to insert a sentence into a passage. Each example displays the human error rate (percentage of incorrect responses), illustrating the increasing difficulty as the complexity of the text grows. This demonstrates that more complex passages lead to higher error rates, suggesting increased cognitive load in comprehending and organizing the information.
read the caption
Figure 6: Examples of human error rate. These illustrates human error rates across three types of comprehension tasks: sentence selection (left), sentence ordering (middle), and sentence insertion (right). The percentages at the top represent the error rates calculated based on responses from students. Higher error rates indicate more challenging tasks requiring deeper comprehension. Notably, as the complexity of the comprehension text increases, the error rate also rises, suggesting a greater cognitive load in understanding and structuring the given information.

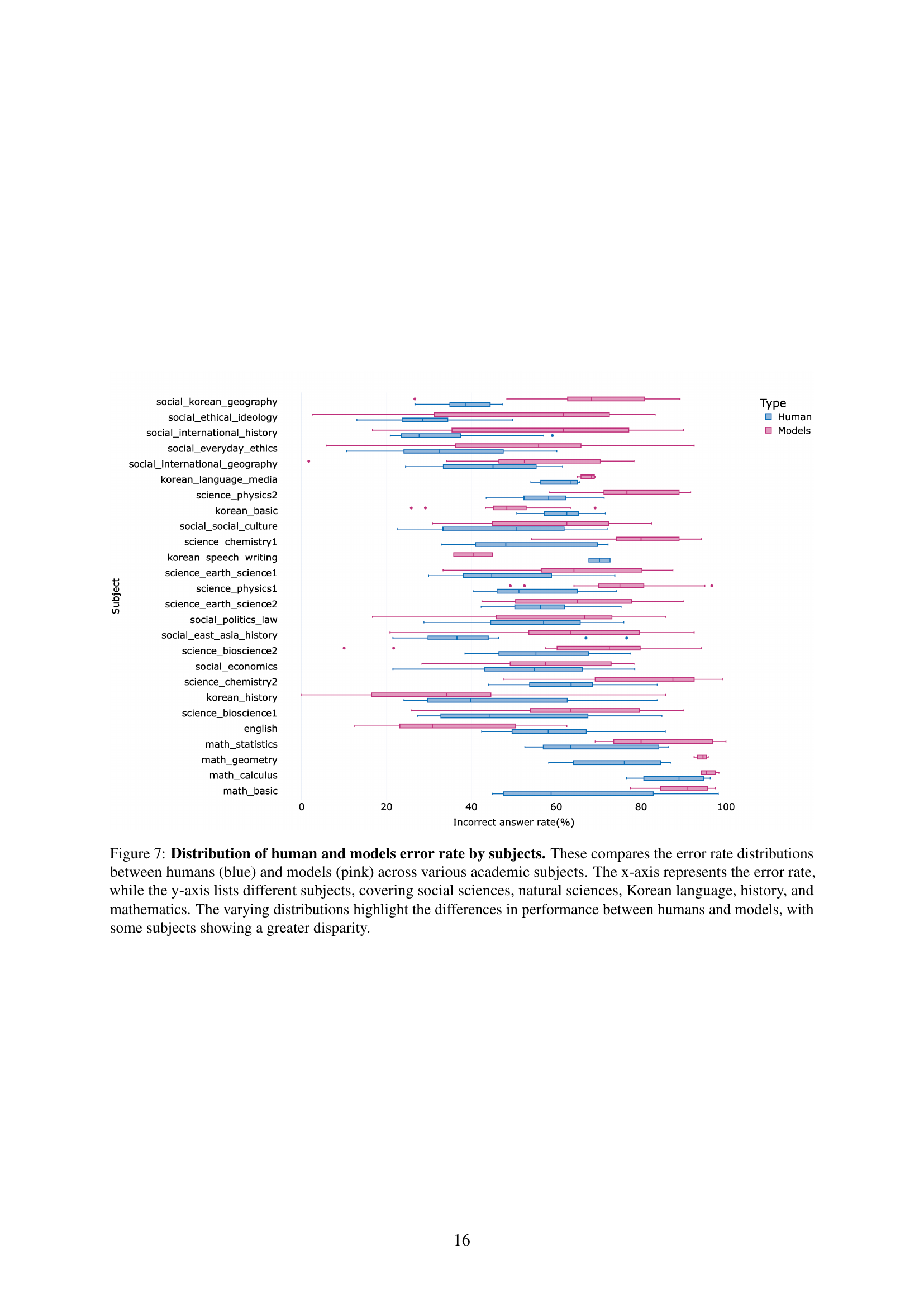
🔼 Figure 7 is a box plot comparing the error rates of human test-takers and AI models across various subjects in the Korean College Scholastic Ability Test (KoCSAT). The y-axis categorizes subjects into social sciences, natural sciences, Korean language, history, and mathematics. The x-axis displays the error rate (percentage of incorrect answers). The box plots visually represent the distribution of error rates for each subject, allowing for a comparison of the performance differences between humans and AI models. The varying lengths and positions of the box plots highlight significant differences in performance across different subjects, with some subjects revealing a much larger gap between human and AI model accuracy than others.
read the caption
Figure 7: Distribution of human and models error rate by subjects. These compares the error rate distributions between humans (blue) and models (pink) across various academic subjects. The x-axis represents the error rate, while the y-axis lists different subjects, covering social sciences, natural sciences, Korean language, history, and mathematics. The varying distributions highlight the differences in performance between humans and models, with some subjects showing a greater disparity.

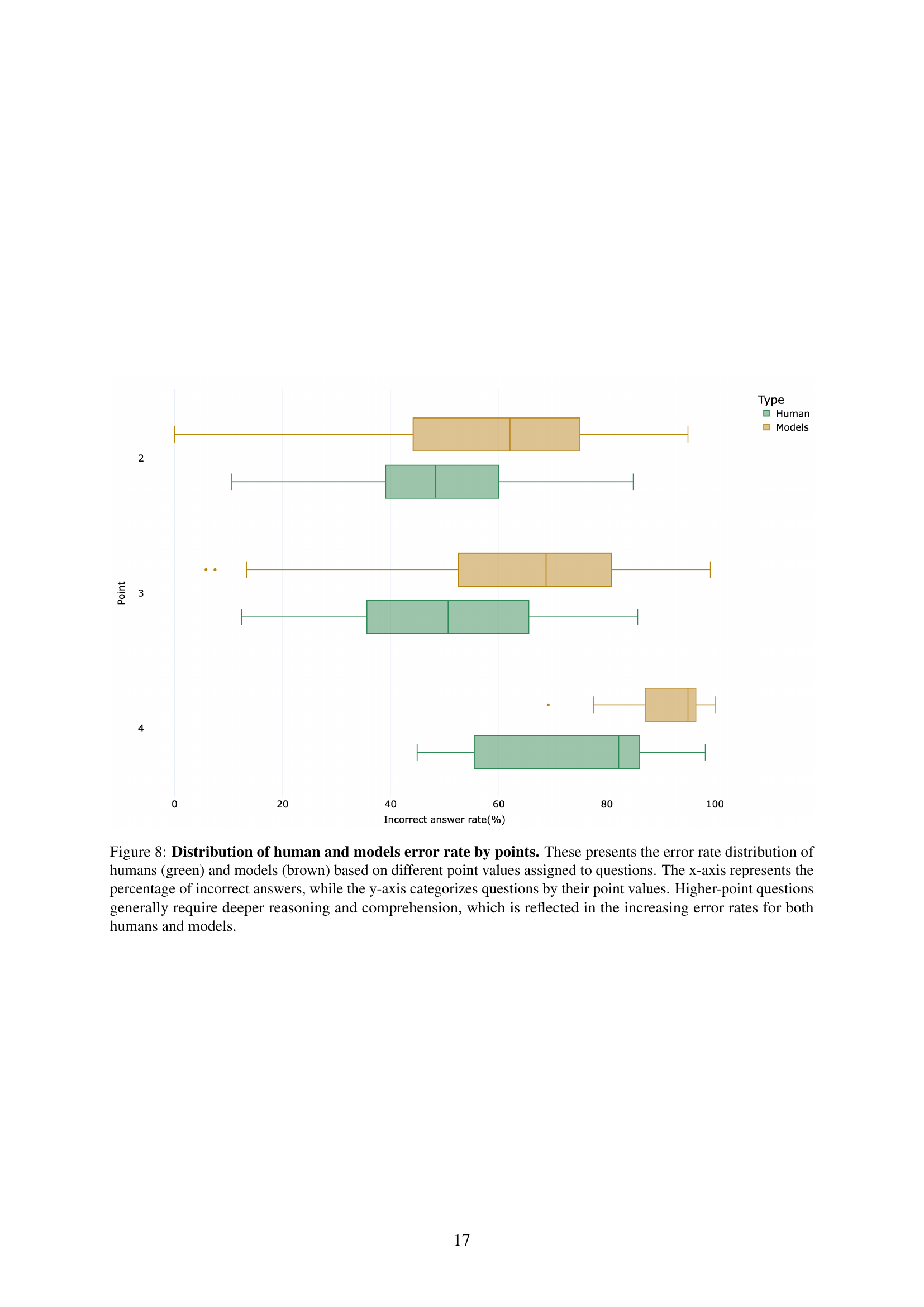
🔼 Figure 8 is a box plot showing the distribution of error rates for both humans and AI models across questions with varying point values (difficulty). The x-axis displays the percentage of incorrect answers, and the y-axis shows the point value of each question. Higher point values indicate more complex questions demanding greater reasoning and comprehension. The plot reveals that as question difficulty increases (higher point values), the error rate for both humans and AI models increases, demonstrating the expected relationship between difficulty and accuracy.
read the caption
Figure 8: Distribution of human and models error rate by points. These presents the error rate distribution of humans (green) and models (brown) based on different point values assigned to questions. The x-axis represents the percentage of incorrect answers, while the y-axis categorizes questions by their point values. Higher-point questions generally require deeper reasoning and comprehension, which is reflected in the increasing error rates for both humans and models.

🔼 Figure 9 presents a comparison of the performance of various LLMs and MLLMs across multiple languages, showcasing their multilingual capabilities. The x-axis displays accuracy percentages, and the y-axis lists the different languages evaluated. The figure highlights that closed-source models generally exhibit better performance and wider language support than their open-source counterparts. However, even closed-source models show performance degradation on certain languages (e.g., Arabic, due to its right-to-left writing direction). This analysis reveals the disparities in multilingual capabilities between different model types and emphasizes the challenges posed by low-resource languages.
read the caption
Figure 9: Performance of multilingual ability. These illustrations depict the accuracy distribution of various models across multiple languages, highlighting their multilingual capabilities. The x-axis represents accuracy percentages, while the y-axis lists different languages. In general, Open Source models tend to support a narrower range of languages fluently compared to Closed Source models. However, even among Closed Source LLMs, performance tends to decline for certain languages; for instance, Arabic differs from English in writing direction, which can impact model performance.
Full paper#