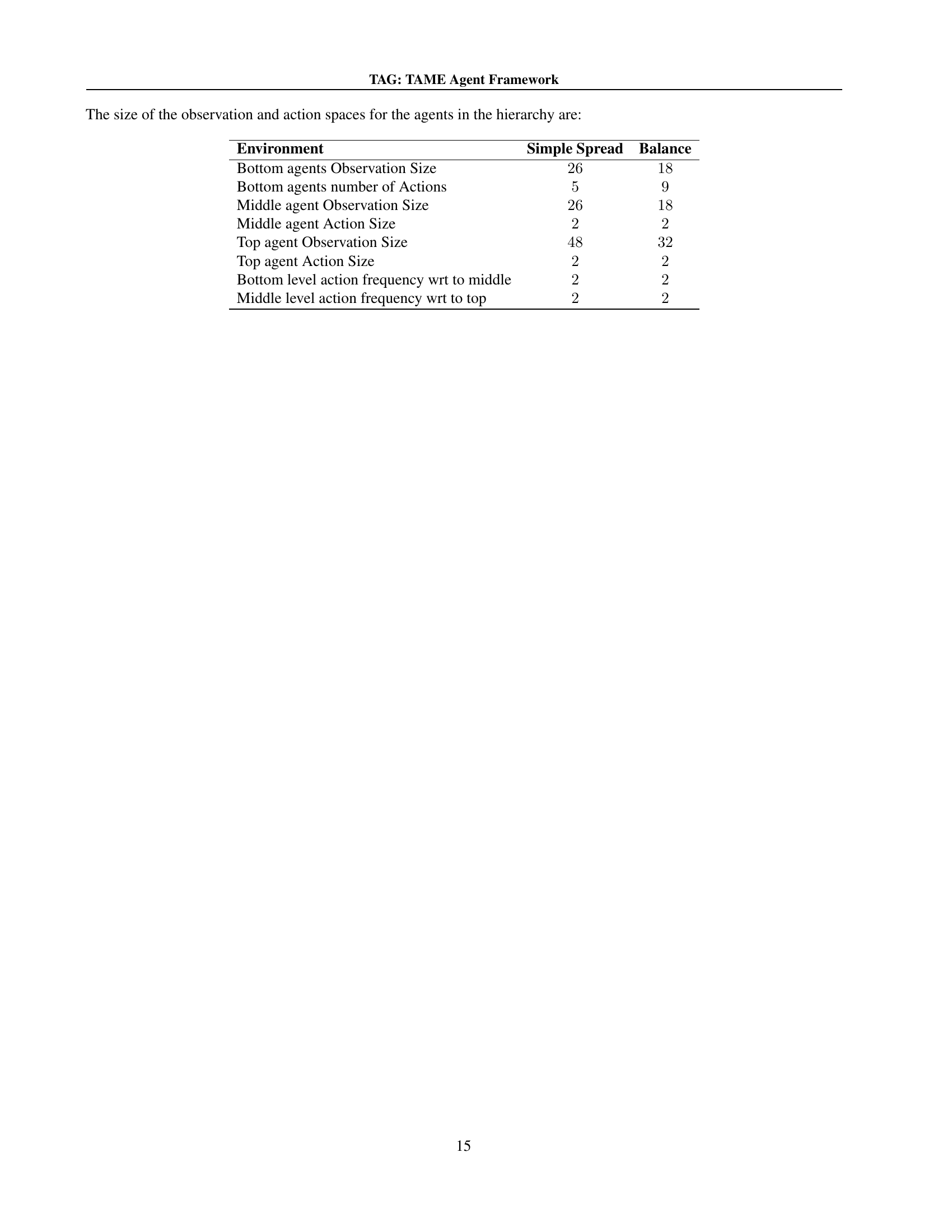
TL;DR#
Hierarchical organization enables efficiency. But current hierarchical reinforcement learning approaches often restrict hierarchies or require centralized training. This limits real-world use. Thus, the paper introduces the TAME Agent Framework, TAG, for fully decentralized hierarchical multi-agent systems.
TAG enables hierarchies through a LevelEnv concept, abstracting each level as an environment. This standardizes information flow while allowing seamless integration of diverse agents. Experiments show this improves over multi-agent RL baselines, enhancing learning speed and final performance.
Key Takeaways#
Why does it matter?#
This paper introduces the TAG framework, offering a promising direction for scalable multi-agent systems. Its decentralized hierarchical organization enhances learning speed and final performance. It holds the potential for creating more adaptive and efficient AI systems and opens new research avenues in MARL and HRL.
Visual Insights#

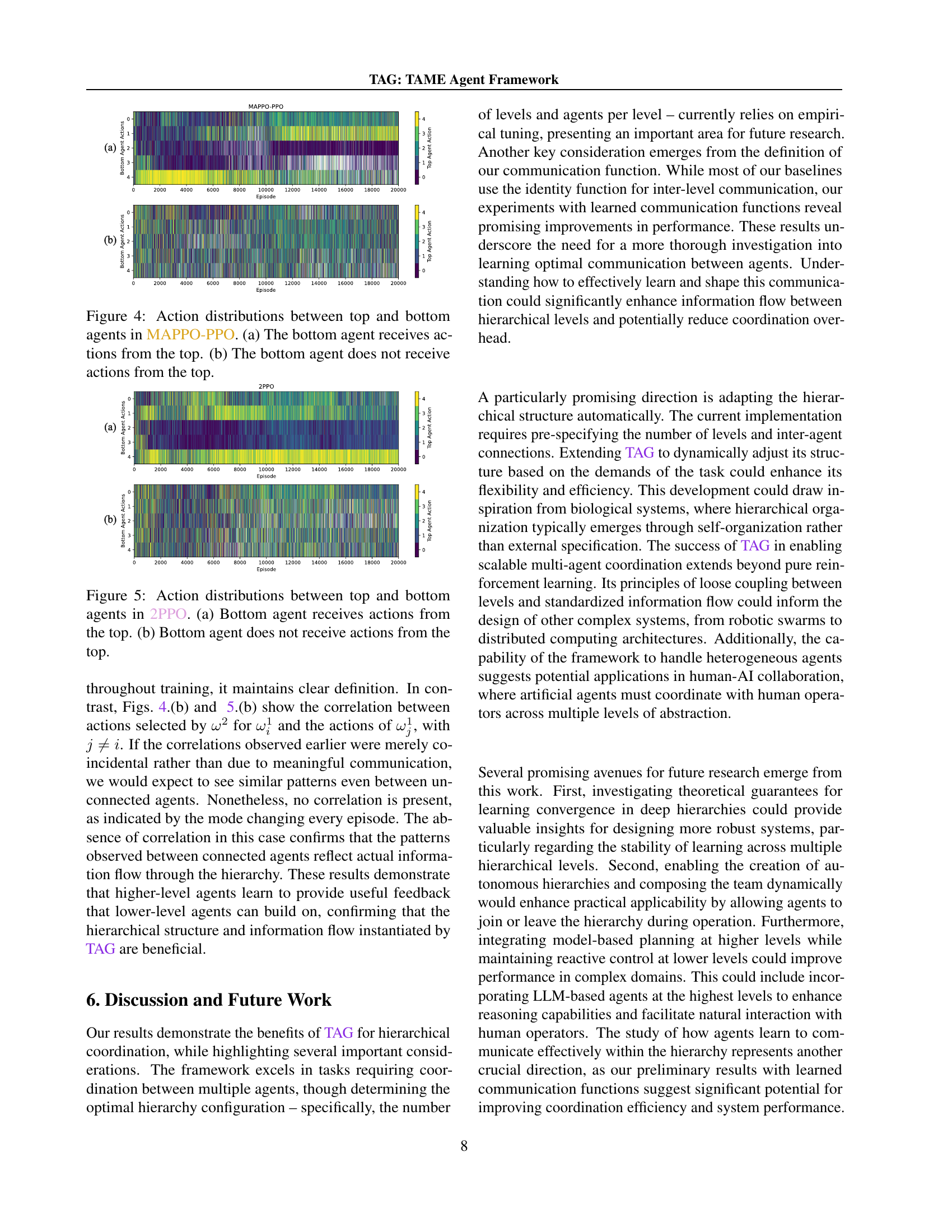
🔼 This figure illustrates the hierarchical agent structures used in the four-agent Multi-Agent Particle World (MAPW) Spread environment. Two different hierarchies are shown: one with three levels and another with two levels. Yellow boxes depict the hierarchical levels, with the top-level agent coordinating lower levels. Blue lines show the information flow from each level to the next higher level. Red lines illustrate how each agent controls its corresponding agent in the environment. Green boxes represent the goals that the agents must reach.
read the caption
Figure 1: Three- and two-level hierarchical agents used in the four-agent MPE-Spread environment. Yellow boxes represent the hierarchy levels, while blue connections indicate what each agent perceives as its environment. Red connections illustrate how the agents in the real environment are controlled, and green boxes represent the goals that the agents must reach.
In-depth insights#
Decentralization#
The core idea revolves around shifting away from monolithic, centralized architectures, characteristic of many current AI systems, towards more distributed and modular designs inspired by biological and social systems. This decentralization aims to improve adaptability, scalability, and robustness. The paper likely explores how tasks can be decomposed across multiple agents at different levels of a hierarchy, enabling localized decision-making and reducing reliance on central control. A key aspect is maintaining coordination and coherence among these decentralized agents, potentially through communication protocols or shared objectives. The focus is on achieving efficient learning and adaptation in a dynamic environment where agents are simultaneously learning and adapting at different levels. The hierarchical structure allows for higher-level agents to maintain strategic oversight without needing to manage every detail of the lower-level behaviors, while lower-level agents can operate with greater autonomy and adapt to local conditions. Therefore, decentralization in this context means distributing control and decision-making authority across a network of agents, rather than relying on a central controller, thus fostering more resilient and scalable systems.
LevelEnv#
The LevelEnv abstraction, central to the framework, presents each level of the multi-agent hierarchy as an environment to the level above, standardizing information flow and preserving agent autonomy. This is done by representing state, actions, and rewards in a way that abstracts away the complexities of lower levels. This standardization facilitates the loose coupling of agents. This modularity allows for heterogeneous agents to be integrated across various hierarchy levels. This allows for specialized learning algorithms at each level, improving learning efficiency. LevelEnv facilitates bidirectional information flow. This design allows lower levels to influence the behavior of higher levels, thus promoting complex coordination while preserving each agent’s independence. The level acts as a structured message passing layer, ensuring smooth communication across hierarchical tiers.
TAG framework#
The TAG framework introduces a decentralized approach to multi-agent hierarchical reinforcement learning, addressing limitations of monolithic architectures. Its key innovation, the LevelEnv abstraction, standardizes information flow between levels while preserving agent autonomy. This framework facilitates both horizontal and vertical coordination, enabling higher-level agents to maintain strategic oversight. Bidirectional information flow enhances adaptability. The design promotes modularity and integrates heterogeneous agents, improving scalability by allowing layers to operate at different temporal scales. The framework supports various learning algorithms, offering flexibility in adapting to specific agent roles, which enhances sample efficiency and final performance compared to flat architectures. Empirical validation demonstrates the effectiveness of this framework.
Hierarchical RL#
Hierarchical Reinforcement Learning (HRL) offers a structured approach to complex tasks by decomposing them into sub-goals and actions across multiple levels. This facilitates temporal abstraction, enabling agents to plan over longer horizons and tackle challenges with sparse rewards. HRL methods often employ options, which are temporally extended actions, or a manager-worker framework where a high-level policy guides lower-level policies. A key benefit is improved exploration and credit assignment, as higher levels learn abstract representations, simplifying the learning process for lower levels. Challenges include ensuring stability during learning due to the non-stationary nature of lower levels and designing effective communication protocols between levels. HRL’s potential lies in enhancing sample efficiency and scalability in complex, multi-agent environments.
Agent autonomy#
The concept of agent autonomy is paramount in decentralized hierarchical reinforcement learning. True autonomy implies that agents at each level of a hierarchy retain decision-making power, avoiding the pitfalls of centralized control where higher-level directives become prescriptive. A key challenge lies in balancing this autonomy with the need for effective coordination. Agents must be able to adapt to local conditions and leverage their specific capabilities, while also aligning their actions with the overarching goals of the system. This can be achieved through mechanisms that subtly influence lower-level behaviors without dictating exact actions, fostering a collaborative environment where agents contribute their unique intelligence to the collective effort. Preserving autonomy also promotes robustness. If one agent fails, the system degrades gracefully, relying on the decentralized nature of the architecture.
More visual insights#
More on figures

🔼 Figure 2 illustrates the information flow within a hierarchical multi-agent system using the TAG framework. It focuses on a single level (level 𝑙) containing two agents. Blue arrows depict the top-down flow of actions from level 𝑙+1 to level 𝑙. Red and green arrows show the bottom-up flow of messages and rewards, respectively, from level 𝑙-1 to level 𝑙. This diagram helps visualize how TAG facilitates communication and coordination between adjacent levels in a hierarchy, while maintaining agent autonomy.
read the caption
Figure 2: Representation of the information flows between a level l𝑙litalic_l with two agents and the levels above and below. The top-down flow of actions is shown in blue. The bottom-up flux of messages and rewards is shown in red and green, respectively.

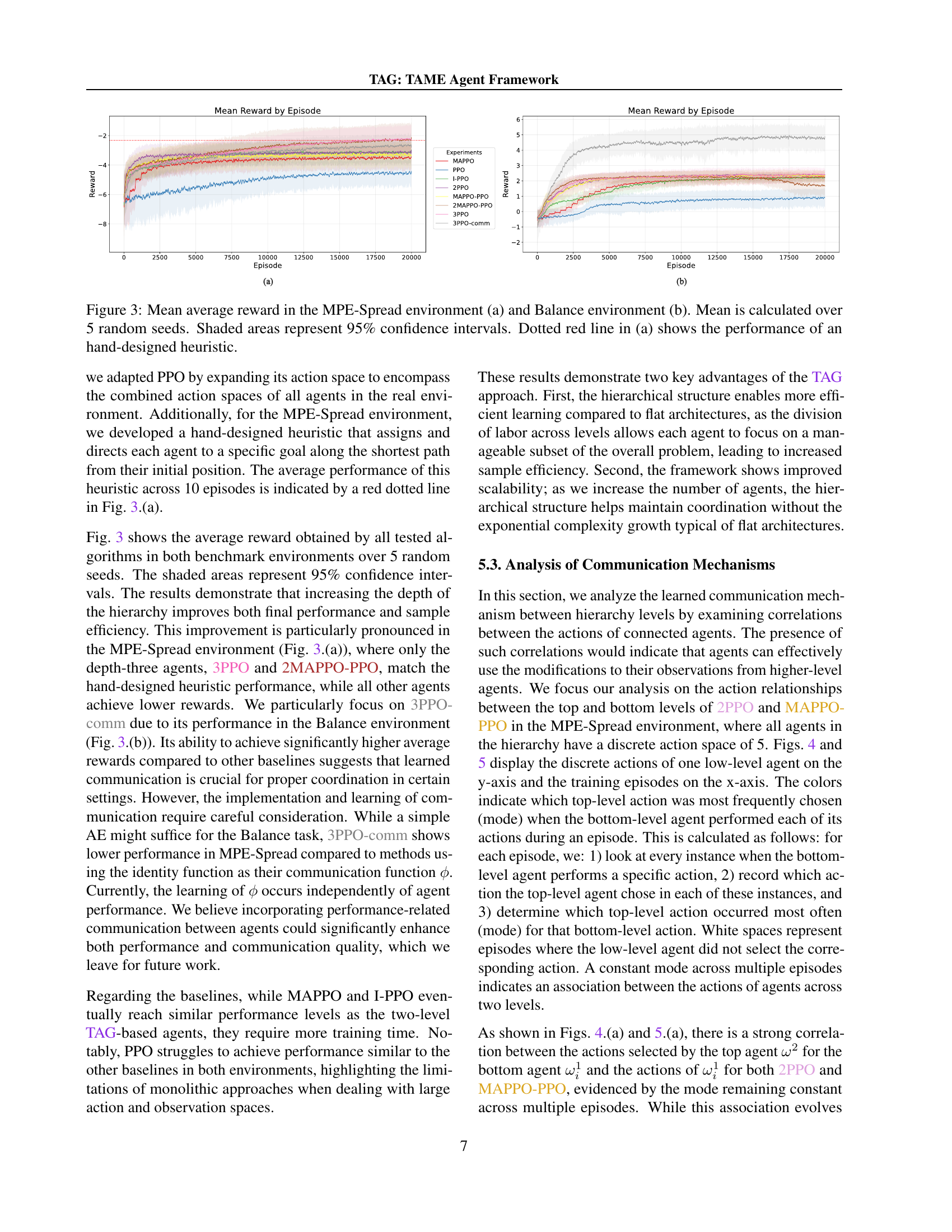
🔼 Figure 3 presents a comparison of the average rewards obtained by various multi-agent reinforcement learning (MARL) algorithms across two benchmark environments: MPE-Spread and Balance. The results are averaged over five independent runs with different random seeds to account for stochasticity. Shaded regions indicate the 95% confidence intervals around the mean reward for each algorithm. For the MPE-Spread environment, a hand-designed heuristic’s performance is included as a dotted red line, serving as a performance upper bound. This figure highlights the relative performance of different approaches, including various hierarchical and non-hierarchical methods, across different task complexities, showing how hierarchical organization might affect performance and sample efficiency.
read the caption
Figure 3: Mean average reward in the MPE-Spread environment (a) and Balance environment (b). Mean is calculated over 5 random seeds. Shaded areas represent 95% confidence intervals. Dotted red line in (a) shows the performance of an hand-designed heuristic.
Full paper#