TL;DR#
Large Language Models (LLMs) have demonstrated great reasoning, but the generation of long tokens has caused efficiency concerns. This paper draws inspiration from human thought processes and introduces LightThinker, a novel method that allows LLMs to compress thought process during reasoning. By compressing verbose thought steps into compact representations and discarding the original reasoning chains, the approach aims to reduce the number of tokens stored in the context window. It dynamically adapts during reasoning, so the subsequent generation can be based on the new compressed version.
To enable this, the model is trained on how and when to perform the compression, in addition to creating specialized attention masks. A novel metric, called Dependency (Dep), quantifies the compression by measuring the reliance on historical tokens during generation. In experiments on datasets and models, LightThinker was found to reduce memory use and inference time, and maintained competitive accuracy. This research can improve LLM efficiency in reasoning tasks without sacrificing the performance.
Key Takeaways#
Why does it matter?#
This paper presents a new direction for future LLM inference acceleration. It can potentially lead to more efficient and cost-effective LLM usage, benefiting both researchers and practitioners working with these powerful models. The Dependency metric can also serve as a tool for analyzing and understanding the compression achieved by different methods.
Visual Insights#
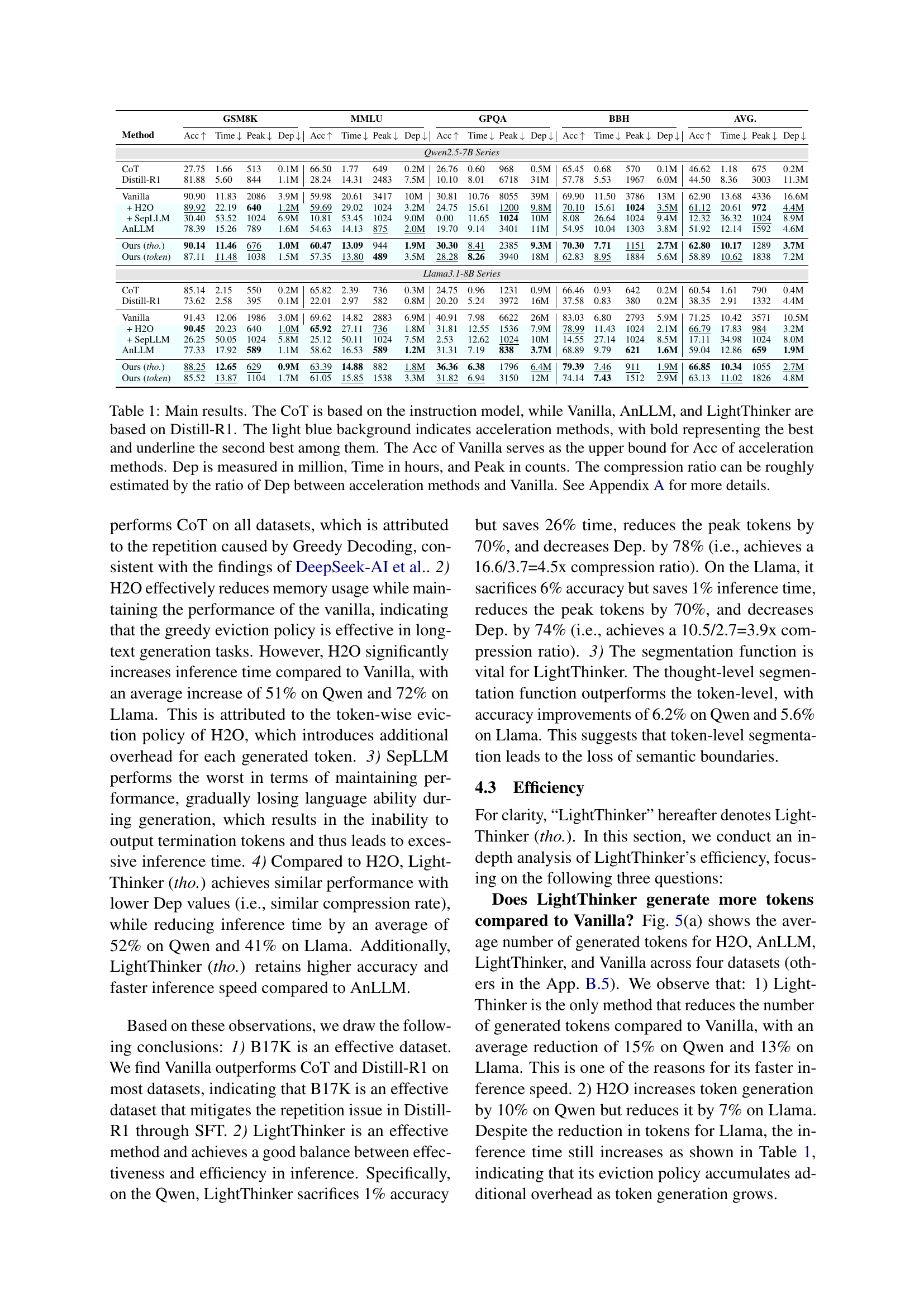
| Method | GSM8K | MMLU | GPQA | BBH | AVG. | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Time | Peak | Dep | Acc | Time | Peak | Dep | Acc | Time | Peak | Dep | Acc | Time | Peak | Dep | Acc | Time | Peak | Dep | |
| Qwen2.5-7B Series | ||||||||||||||||||||
| CoT | 27.75 | 1.66 | 513 | 0.1M | 66.50 | 1.77 | 649 | 0.2M | 26.76 | 0.60 | 968 | 0.5M | 65.45 | 0.68 | 570 | 0.1M | 46.62 | 1.18 | 675 | 0.2M |
| Distill-R1 | 81.88 | 5.60 | 844 | 1.1M | 28.24 | 14.31 | 2483 | 7.5M | 10.10 | 8.01 | 6718 | 31M | 57.78 | 5.53 | 1967 | 6.0M | 44.50 | 8.36 | 3003 | 11.3M |
| Vanilla | 90.90 | 11.83 | 2086 | 3.9M | 59.98 | 20.61 | 3417 | 10M | 30.81 | 10.76 | 8055 | 39M | 69.90 | 11.50 | 3786 | 13M | 62.90 | 13.68 | 4336 | 16.6M |
| + H2O | 89.92 | 22.19 | 640 | 1.2M | 59.69 | 29.02 | 1024 | 3.2M | 24.75 | 15.61 | 1200 | 9.8M | 70.10 | 15.61 | 1024 | 3.5M | 61.12 | 20.61 | 972 | 4.4M |
| + SepLLM | 30.40 | 53.52 | 1024 | 6.9M | 10.81 | 53.45 | 1024 | 9.0M | 0.00 | 11.65 | 1024 | 10M | 8.08 | 26.64 | 1024 | 9.4M | 12.32 | 36.32 | 1024 | 8.9M |
| AnLLM | 78.39 | 15.26 | 789 | 1.6M | 54.63 | 14.13 | 875 | 2.0M | 19.70 | 9.14 | 3401 | 11M | 54.95 | 10.04 | 1303 | 3.8M | 51.92 | 12.14 | 1592 | 4.6M |
| Ours (tho.) | 90.14 | 11.46 | 676 | 1.0M | 60.47 | 13.09 | 944 | 1.9M | 30.30 | 8.41 | 2385 | 9.3M | 70.30 | 7.71 | 1151 | 2.7M | 62.80 | 10.17 | 1289 | 3.7M |
| Ours (token) | 87.11 | 11.48 | 1038 | 1.5M | 57.35 | 13.80 | 489 | 3.5M | 28.28 | 8.26 | 3940 | 18M | 62.83 | 8.95 | 1884 | 5.6M | 58.89 | 10.62 | 1838 | 7.2M |
| Llama3.1-8B Series | ||||||||||||||||||||
| CoT | 85.14 | 2.15 | 550 | 0.2M | 65.82 | 2.39 | 736 | 0.3M | 24.75 | 0.96 | 1231 | 0.9M | 66.46 | 0.93 | 642 | 0.2M | 60.54 | 1.61 | 790 | 0.4M |
| Distill-R1 | 73.62 | 2.58 | 395 | 0.1M | 22.01 | 2.97 | 582 | 0.8M | 20.20 | 5.24 | 3972 | 16M | 37.58 | 0.83 | 380 | 0.2M | 38.35 | 2.91 | 1332 | 4.4M |
| Vanilla | 91.43 | 12.06 | 1986 | 3.0M | 69.62 | 14.82 | 2883 | 6.9M | 40.91 | 7.98 | 6622 | 26M | 83.03 | 6.80 | 2793 | 5.9M | 71.25 | 10.42 | 3571 | 10.5M |
| + H2O | 90.45 | 20.23 | 640 | 1.0M | 65.92 | 27.11 | 736 | 1.8M | 31.81 | 12.55 | 1536 | 7.9M | 78.99 | 11.43 | 1024 | 2.1M | 66.79 | 17.83 | 984 | 3.2M |
| + SepLLM | 26.25 | 50.05 | 1024 | 5.8M | 25.12 | 50.11 | 1024 | 7.5M | 2.53 | 12.62 | 1024 | 10M | 14.55 | 27.14 | 1024 | 8.5M | 17.11 | 34.98 | 1024 | 8.0M |
| AnLLM | 77.33 | 17.92 | 589 | 1.1M | 58.62 | 16.53 | 589 | 1.2M | 31.31 | 7.19 | 838 | 3.7M | 68.89 | 9.79 | 621 | 1.6M | 59.04 | 12.86 | 659 | 1.9M |
| Ours (tho.) | 88.25 | 12.65 | 629 | 0.9M | 63.39 | 14.88 | 882 | 1.8M | 36.36 | 6.38 | 1796 | 6.4M | 79.39 | 7.46 | 911 | 1.9M | 66.85 | 10.34 | 1055 | 2.7M |
| Ours (token) | 85.52 | 13.87 | 1104 | 1.7M | 61.05 | 15.85 | 1538 | 3.3M | 31.82 | 6.94 | 3150 | 12M | 74.14 | 7.43 | 1512 | 2.9M | 63.13 | 11.02 | 1826 | 4.8M |
🔼 This table presents the main results of the experiments, comparing the performance of different methods for accelerating large language models (LLMs) in complex reasoning tasks. The methods include Chain-of-Thought (CoT), two training-free acceleration methods (H2O and SepLLM), one training-based method (AnLLM), and the proposed method, LightThinker. The evaluation is performed on four datasets using two different LLM models (Qwen and Llama). Metrics include accuracy (Acc), inference time (Time), peak token usage (Peak), and a novel dependency metric (Dep) which measures the amount of information used during reasoning. Light blue highlighting indicates acceleration methods, with the best performing methods shown in bold and the second-best underlined. Vanilla serves as the baseline, establishing the upper accuracy bound for comparison. Dep is expressed in millions, Time in hours, and Peak in counts. A rough estimate of the compression ratio for each method is determined by comparing the Dep values against that of Vanilla. More details on the dependency metric are available in Appendix A.
read the caption
Table 1: Main results. The CoT is based on the instruction model, while Vanilla, AnLLM, and LightThinker are based on Distill-R1. The light blue background indicates acceleration methods, with bold representing the best and underline the second best among them. The Acc of Vanilla serves as the upper bound for Acc of acceleration methods. Dep is measured in million, Time in hours, and Peak in counts. The compression ratio can be roughly estimated by the ratio of Dep between acceleration methods and Vanilla. See Appendix A for more details.
In-depth insights#
CoT Compression#
While the paper focuses on compressing intermediate reasoning steps in LLMs, the concept of “CoT Compression” could refer to techniques that specifically aim to reduce the token length of Chain-of-Thought (CoT) prompts or generated reasoning chains. This could involve distilling knowledge from verbose CoT examples into shorter, more efficient prompts. Another approach might involve training models to generate more concise and relevant reasoning steps, avoiding unnecessary or redundant information. The LightThinker architecture could be adapted where gist tokens are used to compress CoT examples. Furthermore, exploring methods to identify and retain only the most crucial reasoning steps while discarding less informative ones. Finally, using summarization techniques to condense lengthy CoT explanations into more compact representations. It’s essential to balance compression with maintaining the accuracy and coherence of the reasoning process. This is the core target in compressing CoT.
LLM Efficiency#
LLM efficiency is a critical area, given the resource demands of large models. Research focuses on reducing computational and memory footprints. Techniques include quantization, which reduces the precision of model weights, and pruning, which removes less important connections. Knowledge distillation transfers knowledge from a large model to a smaller one, retaining performance while improving efficiency. Innovative architectures and training strategies also play a role, aiming to optimize resource utilization during both training and inference, thus leading to smaller model sizes and faster processing.
Dynamic Thinking#
Dynamic Thinking in LLMs involves adapting internal processes during reasoning, mirroring human cognition. LightThinker embodies this by compressing thoughts, reducing token load, and saving memory. Such models learn when and how to compress, optimizing resource use without sacrificing accuracy. This shift enables LLMs to handle complex tasks more efficiently, balancing performance with computational cost. This idea promotes further study in adaptive AI systems for better resource management and scalable reasoning.
Data Dependency#
Data dependency, especially within the realm of language models, highlights the crucial relationships between generated tokens and the preceding context. Analyzing these dependencies is vital for understanding how effectively a model uses prior information for reasoning and generation. A lower data dependency indicates the model relies less on the original context, signifying more efficient compression or abstraction. This concept is useful for assessing the quality of information retention during reasoning. Metrics quantifying this dependency are essential for fairly comparing different memory optimization techniques, especially in scenarios with dynamically changing context lengths and complex interactions between input prompts and generated outputs. Analyzing data dependency is essential to optimize model architectures and training methodologies for efficient information processing.
Inference Speed#
Inference speed is critical for deploying LLMs, especially in real-time applications. Reducing the computational cost per token accelerates inference, making models more responsive. Techniques that compress intermediate steps or selectively attend to key information enhance speed. However, maintaining accuracy while optimizing for speed is a key challenge. Methods like quantization and pruning can accelerate inference but may reduce performance if not done carefully. Striking a balance between efficiency and accuracy is paramount. It is important to consider trade-offs, since aggressively optimizing speed will impact accuracy. Furthermore, it is also important to maintain a good compression ratio to accelerate speed effectively. A well-engineered approach will deliver the best user experience. The goal is to accelerate the inference speed with minimal losses.
More visual insights#
More on tables
| GSM8K | MMLU | GPQA | BBH | |
|---|---|---|---|---|
| Qwen | 20 | 37 | 115 | 48 |
| Llama | 26 | 47 | 139 | 55 |
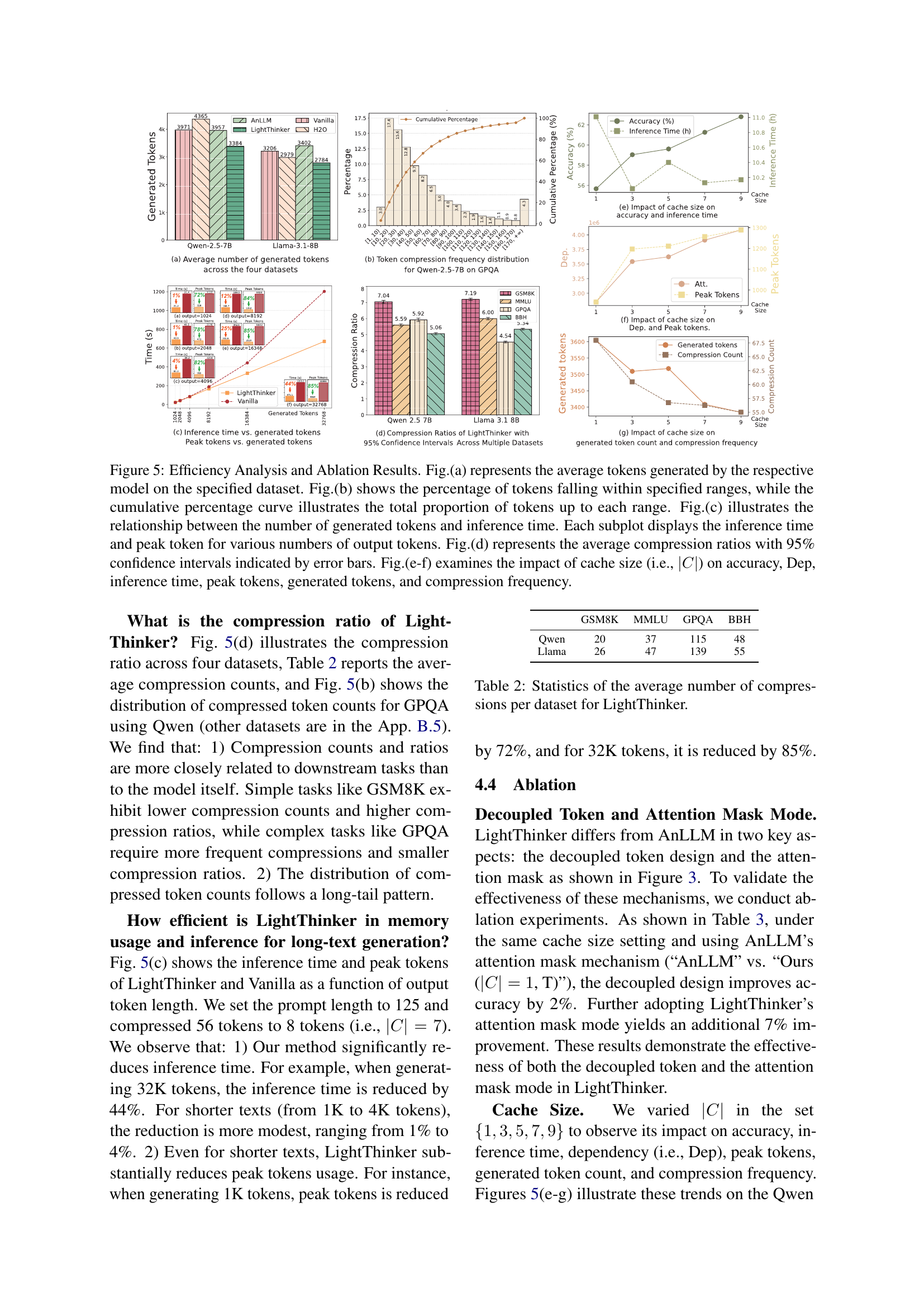
🔼 This table presents the average number of times the LightThinker model performed compression during inference on four different datasets (GSM8K, MMLU, GPQA, and BBH). It shows how frequently the model utilized its compression mechanism across various reasoning tasks and dataset complexities.
read the caption
Table 2: Statistics of the average number of compressions per dataset for LightThinker.
| GSM8K | MMLU | GPQA | BBH | AVG | |
|---|---|---|---|---|---|
| AnLLM | 78.39 | 54.63 | 19.70 | 54.95 | 51.92 |
| Ours (|C|=1, T) | 78.32 | 58.23 | 20.71 | 55.35 | 53.15 |
| Ours (|C|=1, F) | 80.21 | 58.23 | 22.22 | 62.02 | 55.67 |
🔼 This ablation study on the Qwen model investigates the impact of two key design choices in LightThinker: the decoupled token design and the attention mask mechanism. It compares LightThinker’s performance against AnLLM, using AnLLM’s attention mask (‘T’) and LightThinker’s attention mask (‘F’). Accuracy results across four datasets (GSM8K, MMLU, GPQA, BBH) are reported to demonstrate the individual and combined effects of these design choices on model accuracy.
read the caption
Table 3: Ablation results on the Qwen, reporting accuracy on four datasets. “T” denotes the use of AnLLM’s attention mask mechanism, while “F” indicates the use of LightThinker’s attention mask mechanism.
Full paper#