TL;DR#
Speech Language Models (SLMs) require extensive resources to train, hindering research and development for many. Training SLMs demands large-scale datasets, resulting in high computational costs, restricting research to well-funded labs. Existing scaling laws present a pessimistic view of the computational resources needed to train high-quality SLMs.
This paper introduces a recipe for training high-quality SLMs on a single GPU in 24 hours. The recipe, called Slam, uses empirical analysis of model initialization, synthetic training data, preference optimization to maximize performance. Empirical results show that the recipe scales well with more compute, performing on par with leading SLMs at a fraction of the cost. In SLM scaling laws, Slam gives an optimistic view of SLM feasibility.
Key Takeaways#
Why does it matter?#
This paper is crucial for SLM research by offering a practical recipe to train high-quality models on limited resources. It challenges pessimistic views on SLM feasibility, encouraging further exploration and refinement of scaling laws. The open-sourced code, models, and training recipes democratize access, opening new avenues for innovation in speech and audio processing.
Visual Insights#

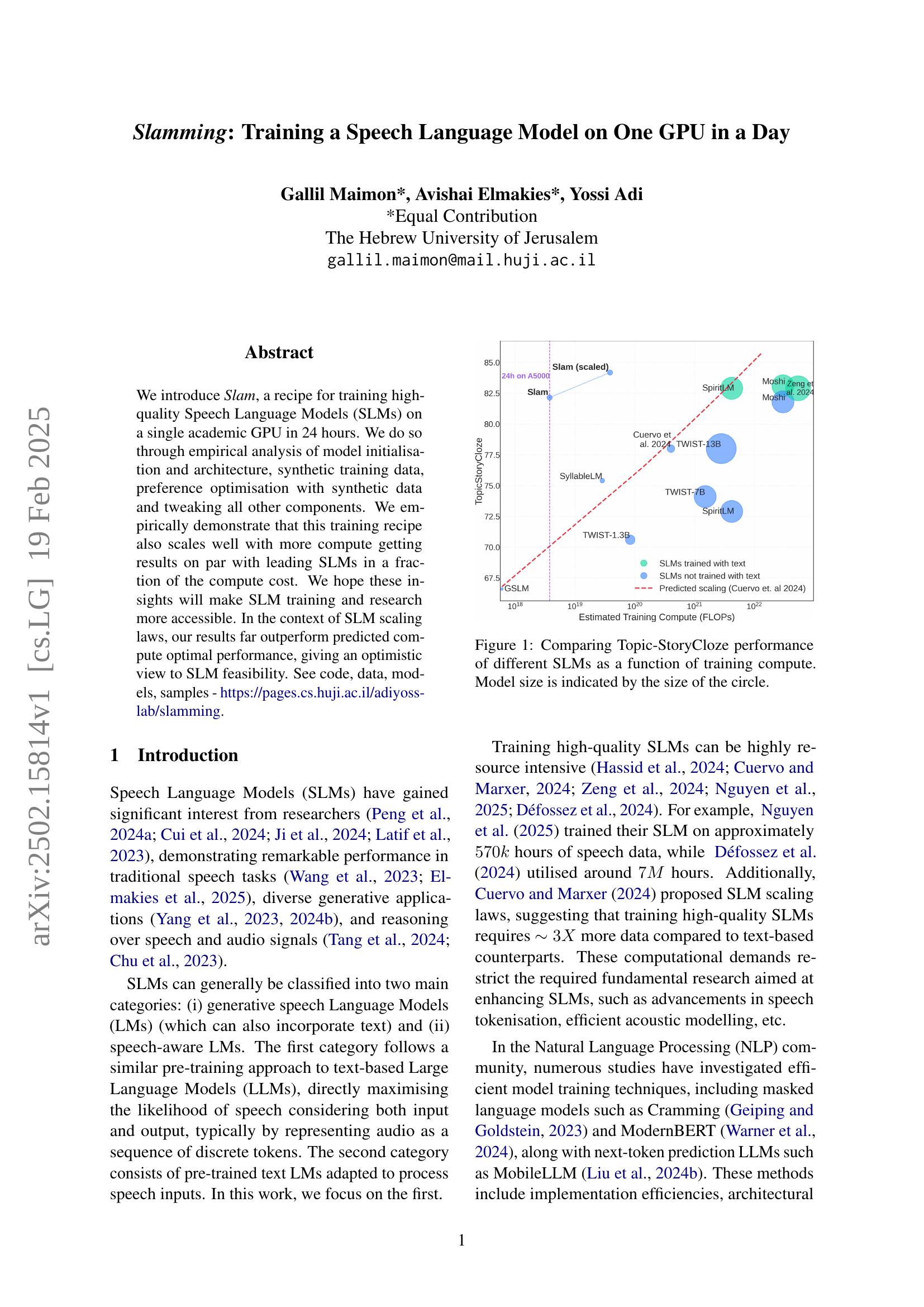
🔼 This figure compares the Topic-StoryCloze performance of various Speech Language Models (SLMs) against the amount of computational resources (measured in FLOPs) used for training. The size of each circle in the plot corresponds to the size of the respective SLM, providing a visual representation of the model’s scale. The plot shows that even with increased compute, performance gains level off and there are significant differences between SLMs.
read the caption
Figure 1: Comparing Topic-StoryCloze performance of different SLMs as a function of training compute. Model size is indicated by the size of the circle.
| Model | Data | Metric | ||||
|---|---|---|---|---|---|---|
| Div. | Syn. | sBLIMP | sSC | tSC | GenPPL | |
| OPT125M | ✗ | ✓ | 55.28 | 55.46 | 75.18 | 96.8 |
| ✓ | ✓ | 55.06 | 55.00 | 74.83 | 116.6 | |
| ✗ | ✗ | 55.88 | 54.52 | 70.82 | 160.3 | |
| ✓ | ✗ | 55.65 | 54.78 | 70.18 | 172.7 | |
| Qwen-0.5B | ✗ | ✓ | 56.45 | 55.59 | 78.01 | 88.3 |
| ✓ | ✓ | 56.17 | 55.37 | 77.13 | 101.3 | |
| ✗ | ✗ | 56.60 | 53.50 | 71.14 | 145.4 | |
| ✓ | ✗ | 56.10 | 53.72 | 70.66 | 161.8 | |
🔼 This table presents the results of an experiment investigating the impact of data diversity and synthetic data on the performance of Speech Language Models (SLMs). It compares the performance of SLMs trained using only the Libri-light and LibriSpeech datasets (representing limited diversity) versus models trained with additional diverse datasets. The impact of including synthetic data, specifically sTinyStories, is also examined. Performance is evaluated across several metrics, showing how different data compositions affect the model’s ability to perform various speech tasks.
read the caption
Table 1: Analysing impact of training data diversity and synthetic data on SLM performance. The default Slam recipe does not use diverse data (only Libri-light and LibriSpeech), but uses the synthetic sTinyStories data.
In-depth insights#
SLM Efficiency#
The research focuses on improving the efficiency of Speech Language Models (SLMs), addressing the significant computational demands that hinder broader research and development. The paper introduces “Slam,” a recipe for training high-quality SLMs on a single GPU within 24 hours, a notable achievement compared to existing methods requiring extensive resources. The core idea revolves around optimizing various aspects of the training pipeline, including model initialization, architecture, synthetic data usage, and preference optimization. Empirical analysis demonstrates that Slam can achieve performance on par with leading SLMs but at a fraction of the computational cost. This advancement could democratize SLM research, making it accessible to researchers with limited resources. The paper’s insights challenge pessimistic views on SLM scalability, offering an optimistic outlook on the feasibility of training high-quality SLMs with limited computational resources. The study contributes to the broader field of efficient model training and may inspire further innovations in SLM architectures and training methodologies.
SLAM Recipe#
Diving into the concept of a ‘SLAM Recipe’ for training speech language models (SLMs), it’s essentially a detailed, optimized guide. This ‘recipe’ focuses on efficiently training high-quality SLMs within resource constraints, like using a single GPU in a day. Key aspects would include model initialization strategies, architecture choices, data selection methods (synthetic data generation), and tailored training objectives (e.g., preference optimization). The goal is maximizing SLM performance while minimizing computational demands. This involves tweaking hyperparameters, exploring optimizers and learning rate schedules, and balancing speech-text data. The recipe would provide concrete steps and hyperparameter settings for researchers to reproduce and adapt the SLM training process, making SLM research more accessible and scalable.
DPO benefits#
Direct Preference Optimization (DPO) emerges as a pivotal technique for refining Speech Language Models (SLMs), offering substantial benefits even with limited compute resources. The research indicates that integrating DPO, particularly with synthetically generated data, notably enhances SLM performance. A critical finding is that allocating a small portion of the training budget, as little as 30 minutes, to DPO yields significant improvements compared to models trained solely with next-token prediction. However, excessive DPO training can be detrimental, potentially degrading model performance if it overshadows the initial pre-training phase. This delicate balance suggests that DPO acts as a powerful fine-tuning mechanism, aligning the model’s output more closely with desired preferences. This is done without needing human feedback. Furthermore, employing a repetition penalty during DPO training helps mitigate the risk of the model generating repetitive or nonsensical outputs, a common issue associated with preference optimization methods. The results suggest that DPO improves both modeling and generation performance on the tasks considered.
Text-to-speech#
Text-to-speech (TTS) plays a crucial role in enhancing SLM performance, particularly when synthetic data is used for pre-training or preference optimization. The research highlights the effectiveness of generating synthetic speech using TTS models, enabling better semantic understanding and improved generative capabilities. Different TTS models, such as single-speaker models for computational efficiency, are leveraged to synthesize datasets like TinyStories. DPO has been greatly improved through the data generation by TTS that results in more natural prosody and better language models in the acoustic part. The text-to-speech model is capable of transforming the existing text corpus to the target spoken tokens effectively. Thus it can be an important factor in improving the performance of the acoustic model.
Model Tuning#
While the provided research paper does not explicitly contain a heading titled ‘Model Tuning,’ the document extensively explores methods for optimizing Speech Language Models (SLMs). This optimization, in effect, constitutes model tuning. The study investigates various facets of SLM architecture and training, effectively ’tuning’ the model through different initializations (TWIST, pretrained text LMs), architecture (model size using Qwen2.5), hyperparameters. The optimization process involves also tuning the datasets to get the most semantic information using synthetic data generation to create more diversity in the SLM training data. The paper also uses DPO, in-place of DPO
More visual insights#
More on figures
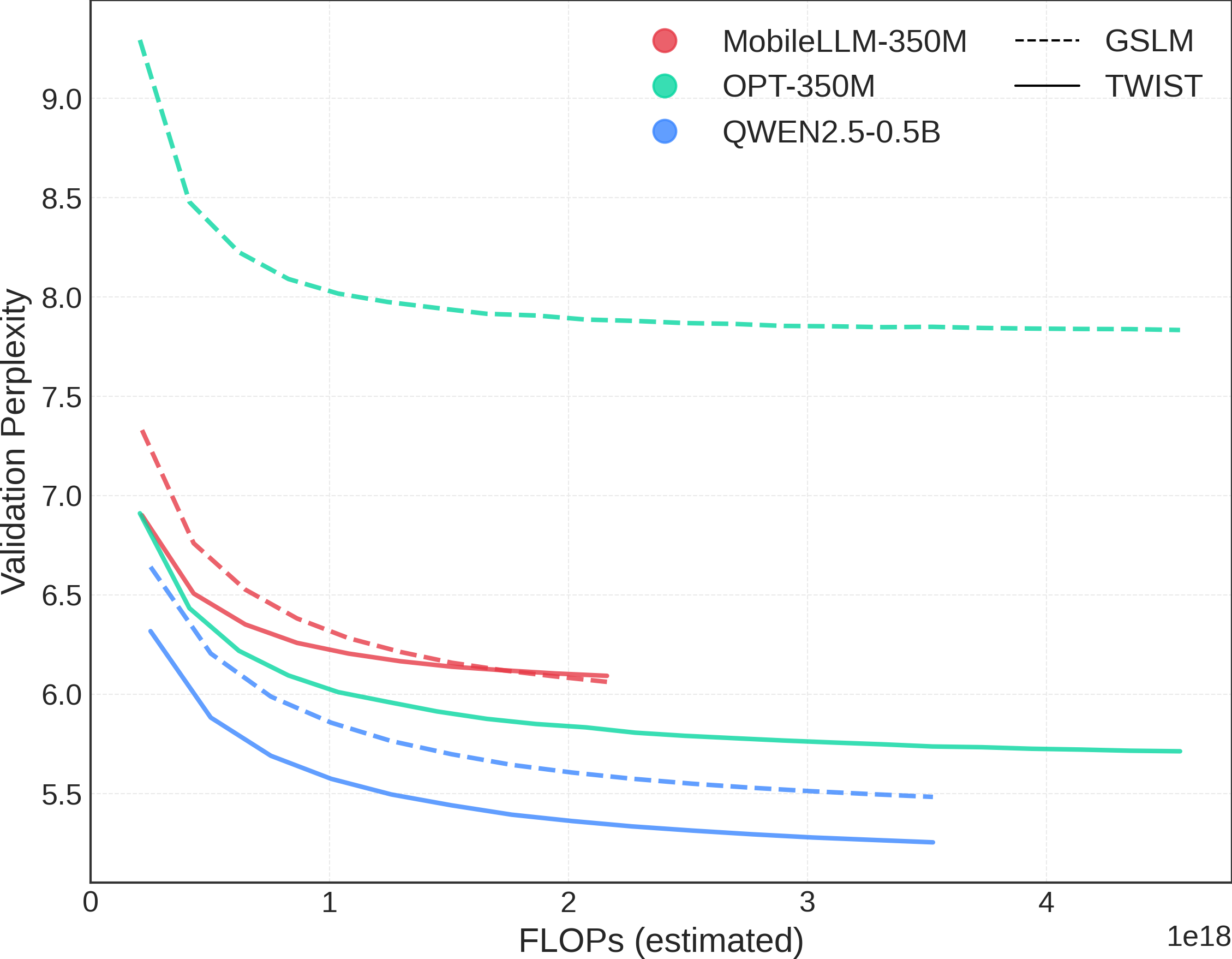
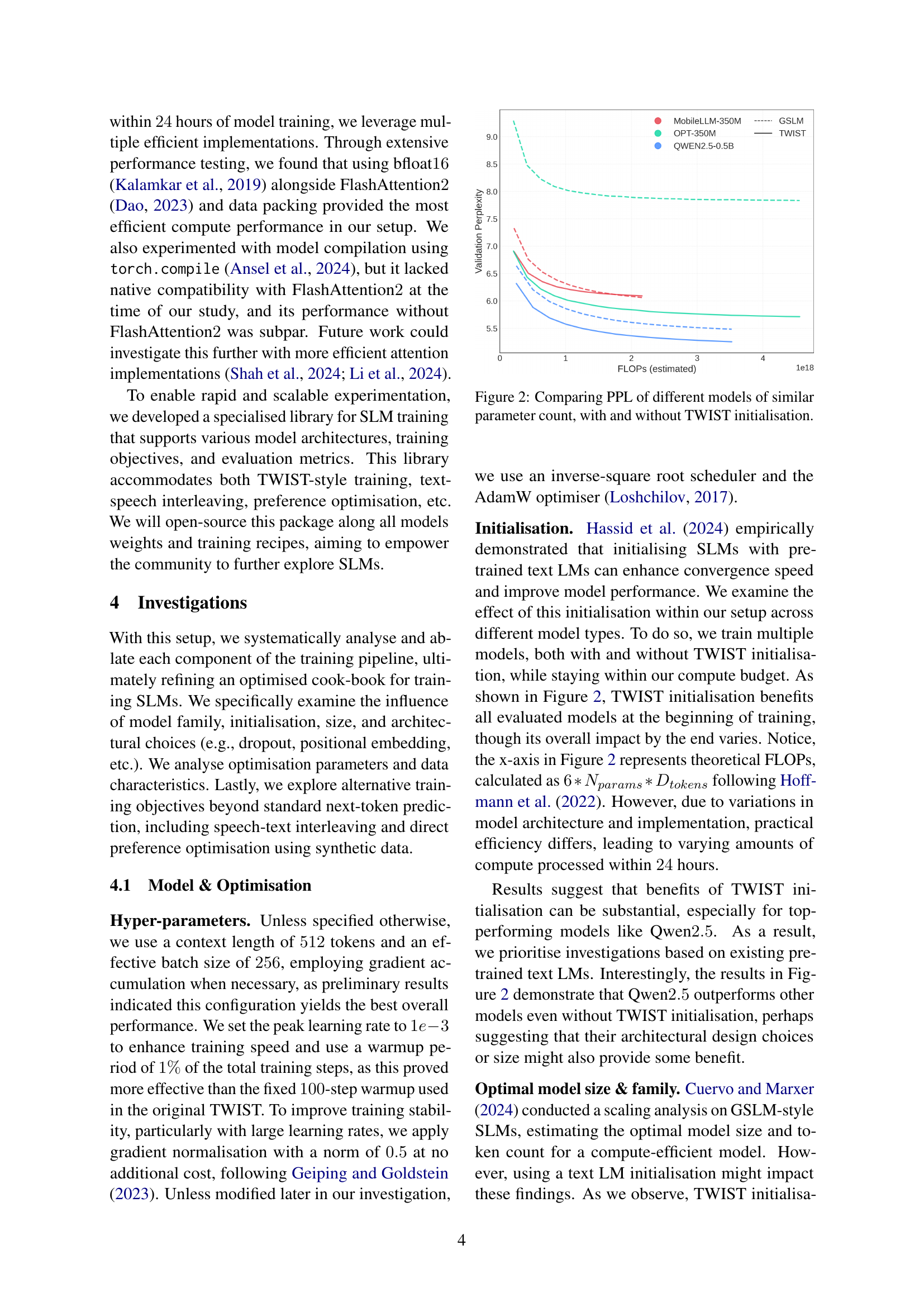
🔼 Figure 2 illustrates the impact of TWIST initialization on the performance of various speech language models (SLMs) with similar parameter counts. It compares the validation perplexity (PPL), a measure of how well a model predicts unseen data, for models trained both with and without TWIST initialization. The x-axis represents the estimated FLOPs (floating-point operations), reflecting the computational cost of training, while the y-axis shows the validation PPL. The figure helps to demonstrate whether initializing SLMs with pre-trained text Language Models (like TWIST) improves performance, especially in a computationally constrained setting.
read the caption
Figure 2: Comparing PPL of different models of similar parameter count, with and without TWIST initialisation.

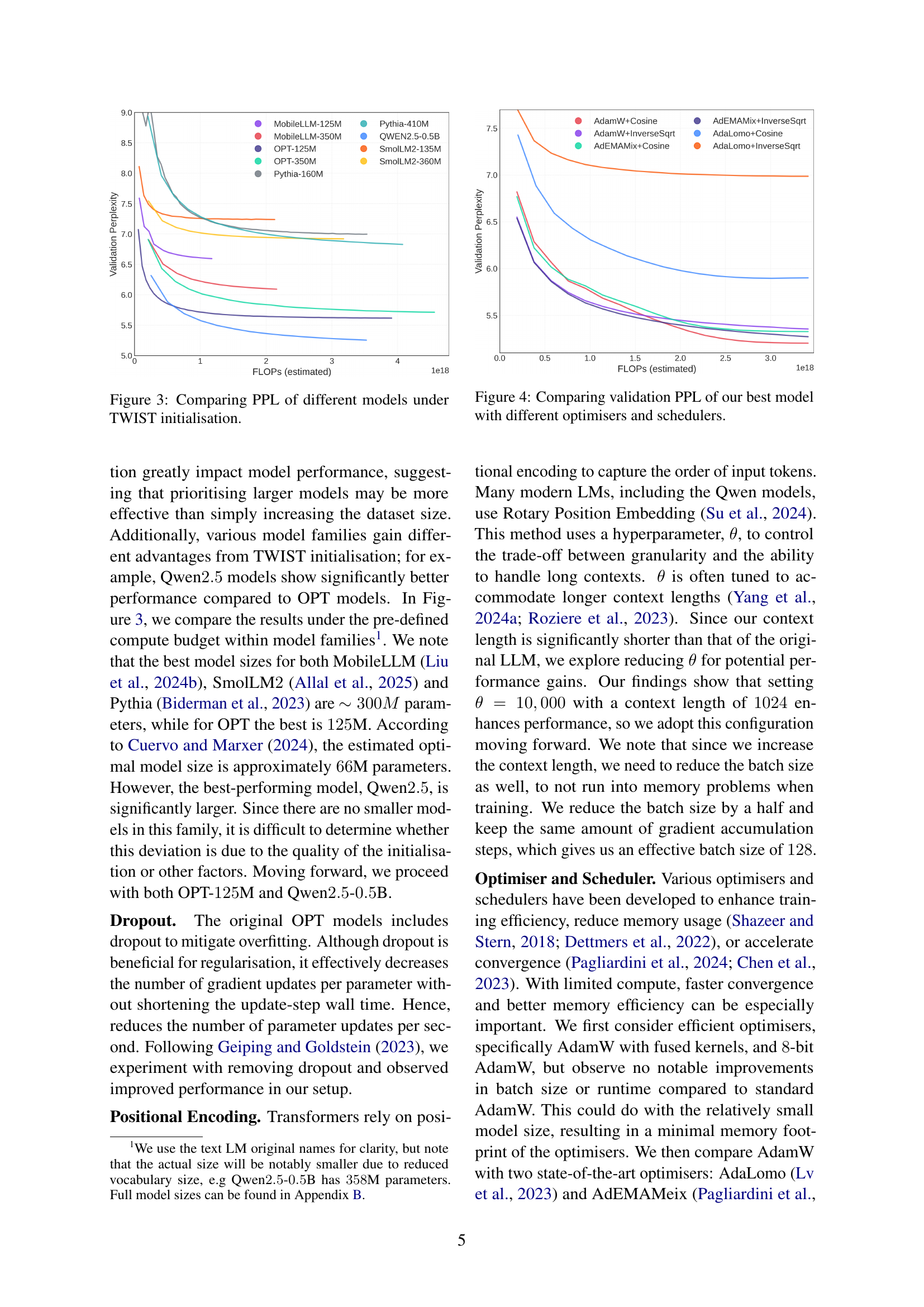
🔼 This figure compares the validation perplexity (PPL) scores of various speech language models (SLMs) of different sizes and architectures when initialized using the TWIST method. It demonstrates the impact of model size and architecture on the PPL, showcasing the performance differences between models with and without TWIST initialization under a fixed computational budget. The x-axis represents the estimated FLOPs (floating-point operations), which correlates with the model’s computational cost. The y-axis shows the validation perplexity. The graph illustrates that TWIST initialization provides benefits in terms of reduced perplexity.
read the caption
Figure 3: Comparing PPL of different models under TWIST initialisation.

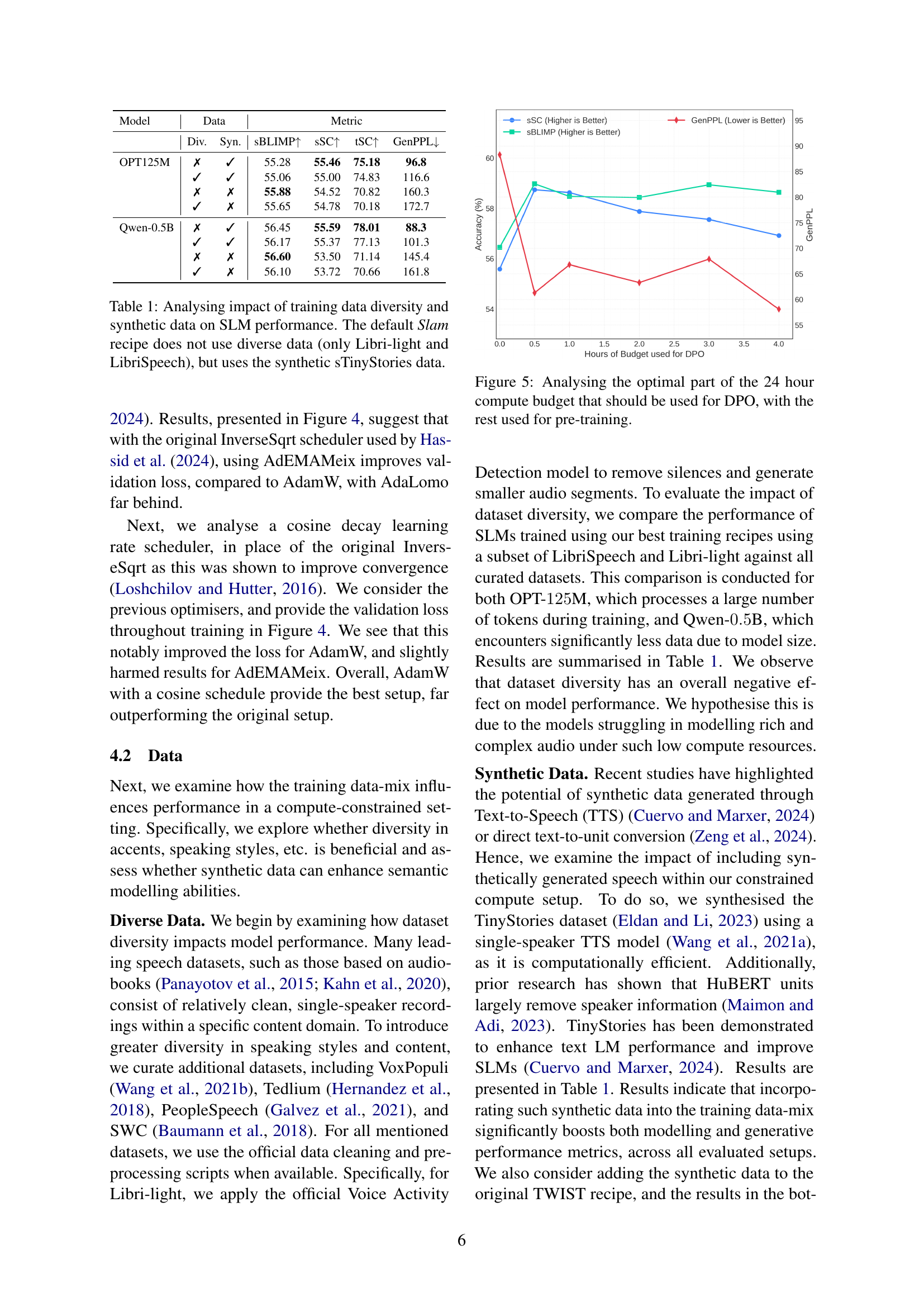
🔼 This figure compares the validation perplexity (PPL) achieved by the best-performing speech language model (SLM) when trained using different optimization algorithms (AdamW, AdaLomo, AdEMAMix) and learning rate schedules (cosine decay, inverse square root). The goal is to determine the combination that yields the lowest validation perplexity, indicating optimal model performance within the resource constraints of a single GPU.
read the caption
Figure 4: Comparing validation PPL of our best model with different optimisers and schedulers.

🔼 This figure analyzes the optimal allocation of a 24-hour compute budget between pre-training and Direct Preference Optimization (DPO) for training a speech language model. It shows how different durations dedicated to DPO affect the model’s performance, measured by various metrics. The results help determine the most efficient balance between pre-training and DPO to maximize model performance within the time constraint.
read the caption
Figure 5: Analysing the optimal part of the 24 hour compute budget that should be used for DPO, with the rest used for pre-training.
More on tables
| Compute (GPU days) | Parameters | sBLIMP | sStoryCloze | tStoryCloze | GenPPL | Auto-BLEU | |
| TWIST-350M Hassid et al. (2024) | 40*V100 | 305M | 56.20 | - | - | 137.3 | 3.46 |
| TWIST-1.3B Hassid et al. (2024) | 160*V100 | 1B | 57.00 | 52.4 | 70.6 | 131.8 | 3.20 |
| TWIST-7B Hassid et al. (2024) | ? | 7B | 59.00 | 55.3 | 74.1 | 93.7 | 3.06 |
| TWIST-13B Hassid et al. (2024) | ? | 13B | 59.20 | 55.4 | 76.4 | - | - |
| Scaled Optimal Cuervo and Marxer (2024) | ? | 823M | 61.3 | 56.7 | 78.0 | - | - |
| Predicted Optimal Cuervo and Marxer (2024) | 1*A5000 | 78M | 56.85 | 54.09 | 70.49 | - | - |
| TWIST-350M (Original recipe) | 1*A5000 | 305M | 51.52 .19 | 53.65 .57 | 68.80 .47 | 259.2 6.7 | 3.26 .46 |
| TWIST-350M + sTinyStories | 1*A5000 | 305M | 51.21 .26 | 54.17 .54 | 72.40 .18 | 159.0 6.0 | 4.18 .24 |
| Slam (-DPO) (ours) | 1*A5000 | 358M | 56.45 .17 | 55.59 .30 | 78.01 .27 | 88.3 1.0 | 3.47 .17 |
| Slam (ours) | 1*A5000 | 358M | 58.86 .20 | 58.04 .51 | 82.04 .21 | 62.8 4.1 | 3.88 .11 |
🔼 This table compares the performance of the proposed SLM training recipe, ‘Slamming,’ against several leading SLMs. It shows key performance metrics (SBLIMP, StoryCloze, TopicStoryCloze, and GenPPL) achieved by these models. A key aspect of the comparison is the compute resources utilized—Slamming demonstrates competitive performance with significantly less compute. The table also includes the performance of a TWIST-350M model trained using the original recipe but with the Slamming code and compute budget. The ‘±’ values show the variance across three separate training runs.
read the caption
Table 2: Comparing slamming to leading SLMs, and predicted optimal performance for the compute. We also consider TWIST-350350350350M using our code and compute budget, but with the original training recipe. ±plus-or-minus\pm± indicates distance to min/max of 3333 seeds.
| GPUs | Params | Num tokens | sBLIMP | sStoryCloze | tStoryCloze | GenPPL | Auto-BLEU | |
| Speech only pre-training | ||||||||
| GSLM Lakhotia et al. (2021) | 8*V100 | 100M | 1B | 54.2 | 53.3 | 66.6 | ||
| SyllableLM Baade et al. (2024) | 4*A40 | 300M | 16B | 63.7 | 75.4 | |||
| TWIST-350M Hassid et al. (2024) | 8*V100 | 305M | 10.8B | 56.20 | 137.3 | 3.46 | ||
| TWIST-1.3B Hassid et al. (2024) | 32*V100 | 1B | 10.8B | 57.00 | 52.4 | 70.6 | 131.8 | 3.20 |
| TWIST-7B Hassid et al. (2024) | 32*V100 | 7B | 36B | 59.00 | 55.3 | 74.1 | 93.74 | 3.06 |
| TWIST-13B Hassid et al. (2024) | 32*V100 | 13B | 36B | 59.20 | 55.4 | 76.4 | ||
| Scaled Optimal Cuervo and Marxer (2024) | 823M | 82B | 61.3 | 56.7 | 78.0 | |||
| Moshi Défossez et al. (2024) | ?*H100 | 7B | ? | 58.9 | 58.7 | 81.8 | ||
| SpiritLM Nguyen et al. (2025) | 64*A100 | 7B | 100B | 58.0 | 54.8 | 72.9 | ||
| Joint speech-text pre-training / preference optimisation | ||||||||
| Zeng et al. (2024) | 9B | 1T | 62.4 | 82.9 | ||||
| Moshi Défossez et al. (2024) | ?*H100 | 7B | 720B | 58.8 | 60.8 | 83.0 | ||
| SpiritLM Nguyen et al. (2025) | 64*A100 | 7B | 100B | 58.3 | 61.0 | 82.9 | ||
| AlignSLM-1.3B Lin et al. (2024) | 64*A100 | 1B | 10.8B + 158B | 59.8 | 55.0 | 80.0 | ||
| AlignSLM-7B Lin et al. (2024) | 64*A100 | 7B | 36B + 158B | 62.3 | 61.1 | 86.8 | ||
| Slam (-DPO) | 2*A100 | 358M | 16.7B | 58.53 | 58.15 | 80.71 | 67.3 | 3.25 |
| Slam | 1*A5000 | 358M | 1.4B + 5M | 58.86 | 58.04 | 82.04 | 62.8 | 3.88 |
| Slam (scaled) | 2*A100 | 358M | 16.7B + 9M | 61.11 | 61.30 | 84.18 | 46.6 | 3.75 |
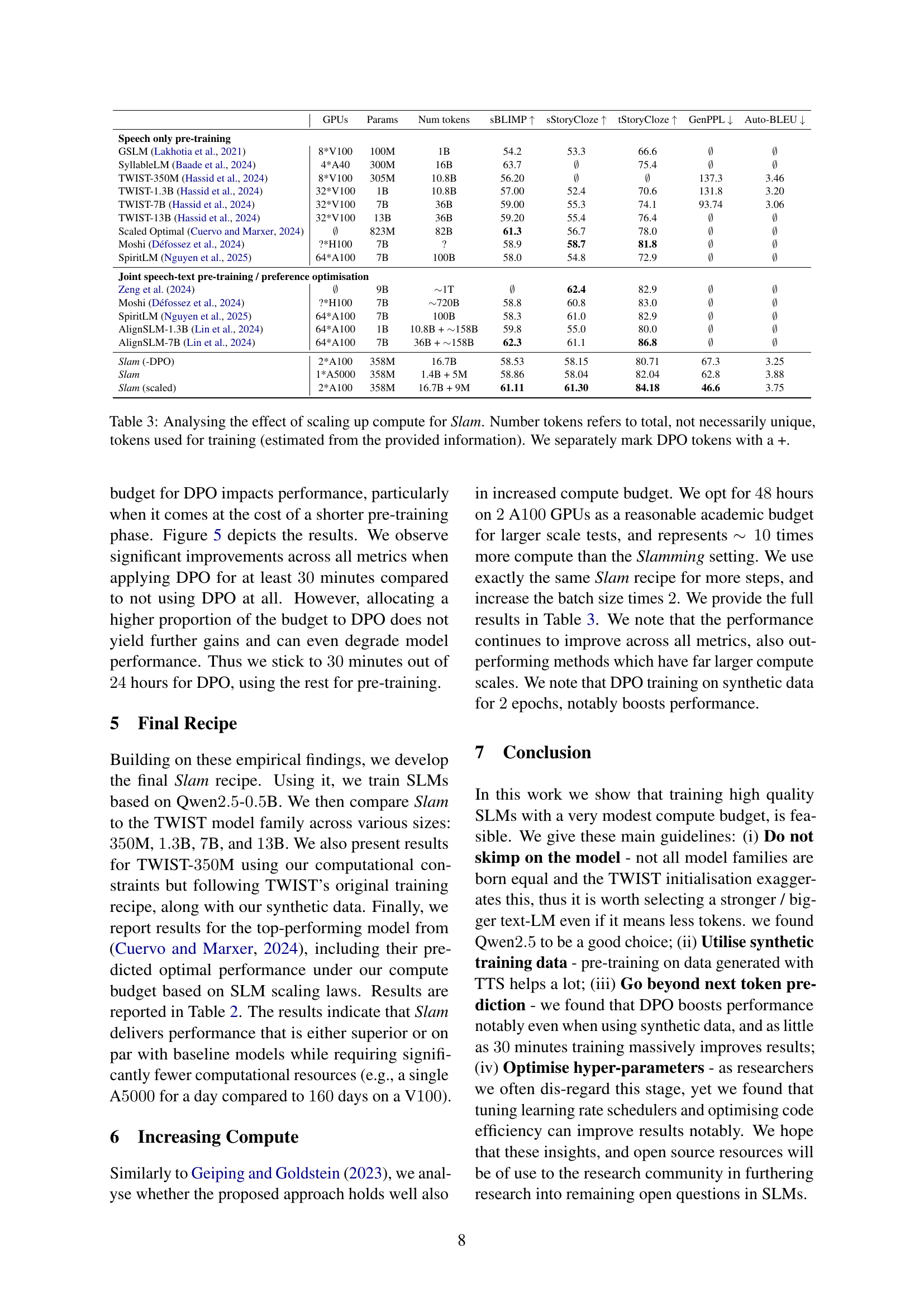
🔼 This table analyzes how the performance of the Slam model changes when more computational resources are used during training. It compares Slam’s results (trained on a single A5000 GPU for 24 hours, then scaled to two A100 GPUs for 48 hours) against existing state-of-the-art speech language models (SLMs). Key performance metrics such as sBLIMP, StoryCloze, and perplexity are presented. The number of tokens used during training is estimated, reflecting both the pre-training phase and the optional Direct Preference Optimization (DPO) phase (indicated with a ‘+’). The goal is to show how Slam scales efficiently compared to models that require significantly greater computational resources.
read the caption
Table 3: Analysing the effect of scaling up compute for Slam. Number tokens refers to total, not necessarily unique, tokens used for training (estimated from the provided information). We separately mark DPO tokens with a +.
| Parameter | Value |
|---|---|
| Text Base Model | Qwen2.5-0.5B |
| TWIST initialisation | True |
| Data | Librilight + Librispeech + sTinyStories |
| Train Time | hours steps |
| RoPE theta | |
| Context length | |
| Per device Batch Size | |
| Gradient Accumulation | |
| Base Learning Rate | |
| Warmup Ratio | |
| Optimizer | AdamW |
| Learning Rate Scheduler | cosine with min |
| Max Grad Norm | |
| Dtype | bfloat16 |
🔼 This table details the hyperparameters used for pre-training the speech language model in the Slam recipe, excluding the Direct Preference Optimization (DPO) phase. It lists settings such as the base model used, data sources, training time, various regularization parameters, optimization algorithm, learning rate schedule, and data type. These specifications are crucial for replicating the experiment’s results.
read the caption
Table 4: Slam (-DPO) Pre Training Recipe
| Parameter | Value |
|---|---|
| Initial Model | Slam (-DPO) |
| Data | SpokenSwag with auto-bleu smaller than 0.3 |
| Train Time | hour steps |
| RoPE theta | |
| Context length | |
| Per device Batch Size | |
| Gradient Accumulation | |
| Base Learning Rate | |
| Optimizer | AdamW |
| Learning Rate Scheduler | inverse sqrt |
| Max Grad Norm | |
| Dtype | bfloat16 |
| DPO |
🔼 This table details the hyperparameters used during the Direct Preference Optimization (DPO) phase of the Slam training recipe. It includes settings for the initial model, dataset used for DPO training, training time allocated for DPO, ROPE theta (a hyperparameter controlling the trade-off between granularity and ability to handle long contexts in the Rotary Position Embedding), context length, per-device batch size, gradient accumulation, base learning rate, optimizer used, learning rate scheduler, maximum gradient norm, and data type. Understanding this table is crucial for replicating the Slam DPO training process and analyzing the impact of DPO on final model performance.
read the caption
Table 5: Slam DPO Training Recipe
| Model Name | Number of Params |
|---|---|
| MobileLLM-125M Liu et al. (2024b) | 106,492,608 |
| MobileLLM-350M Liu et al. (2024b) | 315,117,120 |
| OPT-125M Zhang et al. (2022) | 87,015,936 |
| OPT-350M Zhang et al. (2022) | 305,714,176 |
| QWEN2.5-0.5B Yang et al. (2024a) | 358,347,904 |
| SmolLM2-135M Allal et al. (2025) | 106,492,608 |
| SmolLM2-360M Allal et al. (2025) | 315,117,120 |
| Pythia-160M Biderman et al. (2023) | 85,827,072 |
| Pythia-410M Biderman et al. (2023) | 303,339,520 |
🔼 This table lists various large language models (LLMs) and their corresponding parameter counts. The original LLMs were adapted to use a vocabulary of only 500 speech units. This table is crucial because it demonstrates the model sizes used after adapting them for speech processing, which is key to understanding the experimental setup and results in the paper.
read the caption
Table 6: Model names and parameter counts after changing vocabulary to speech only units (500).
| Dataset | Number of Hours | Number of Tokens |
|---|---|---|
| Libri-Light Kahn et al. (2020) | ||
| LibriSpeech Panayotov et al. (2015) | ||
| SWC Baumann et al. (2018) | ||
| Tedlium Hernandez et al. (2018) | ||
| PeopleSpeech Galvez et al. (2021) | ||
| VoxPopuli Wang et al. (2021b) | ||
| sTinyStories |
🔼 Table 7 presents a detailed breakdown of the training datasets used in the study. It lists the name of each dataset, the number of hours of audio data it contains, and the total number of tokens extracted from it for training. This allows for a comprehensive understanding of the scale and composition of the data used to train the various models described in the paper. The datasets used are Libri-light, LibriSpeech, SWC, Tedlium, PeopleSpeech, VoxPopuli and sTinyStories.
read the caption
Table 7: Dataset train set sizes that we use.
Full paper#