TL;DR#
Existing Vision-Language Models (VLMs) hold promise for solving complex robotic manipulation tasks, but they often struggle with the intricacies of physical reasoning and long-horizon planning due to compounding errors. These limitations hinder their ability to perform intricate action sequences that require nuanced physical interactions. Therefore, there is a need to enhance VLMs’ understanding of physics and ability to plan over extended horizons.
This paper introduces a novel test-time computation framework, named ReflectVLM, that significantly enhances VLMs’ capabilities for multi-stage robotic manipulation tasks. ReflectVLM iteratively improves a pre-trained VLM using a reflection mechanism and diffusion models to predict future world states, enabling the VLM to refine its decisions by examining the predicted outcomes of its proposed actions. Experiments demonstrate that ReflectVLM outperforms state-of-the-art commercial VLMs and traditional planning approaches.
Key Takeaways#
Why does it matter?#
This paper introduces ReflectVLM, a novel framework enhancing VLMs’ physical reasoning for robotic manipulation, with implications for autonomous systems requiring visual understanding and sequential decision-making.
Visual Insights#

🔼 The figure illustrates the reflective planning process. A Vision-Language Model (VLM) initially suggests an action. A diffusion dynamics model then simulates the outcome of that action, predicting the future state of the environment. This prediction is fed back to the VLM, allowing it to reconsider its initial plan and potentially propose a more effective action. This iterative refinement process, using imagined future states, is what is meant by ‘reflective planning’.
read the caption
Figure 1: Reflective planning. Our method uses a VLM to propose actions and a diffusion dynamics model to imagine the future state of executing the plan. The imagined future helps the VLM reflect the initial plan and propose better action.
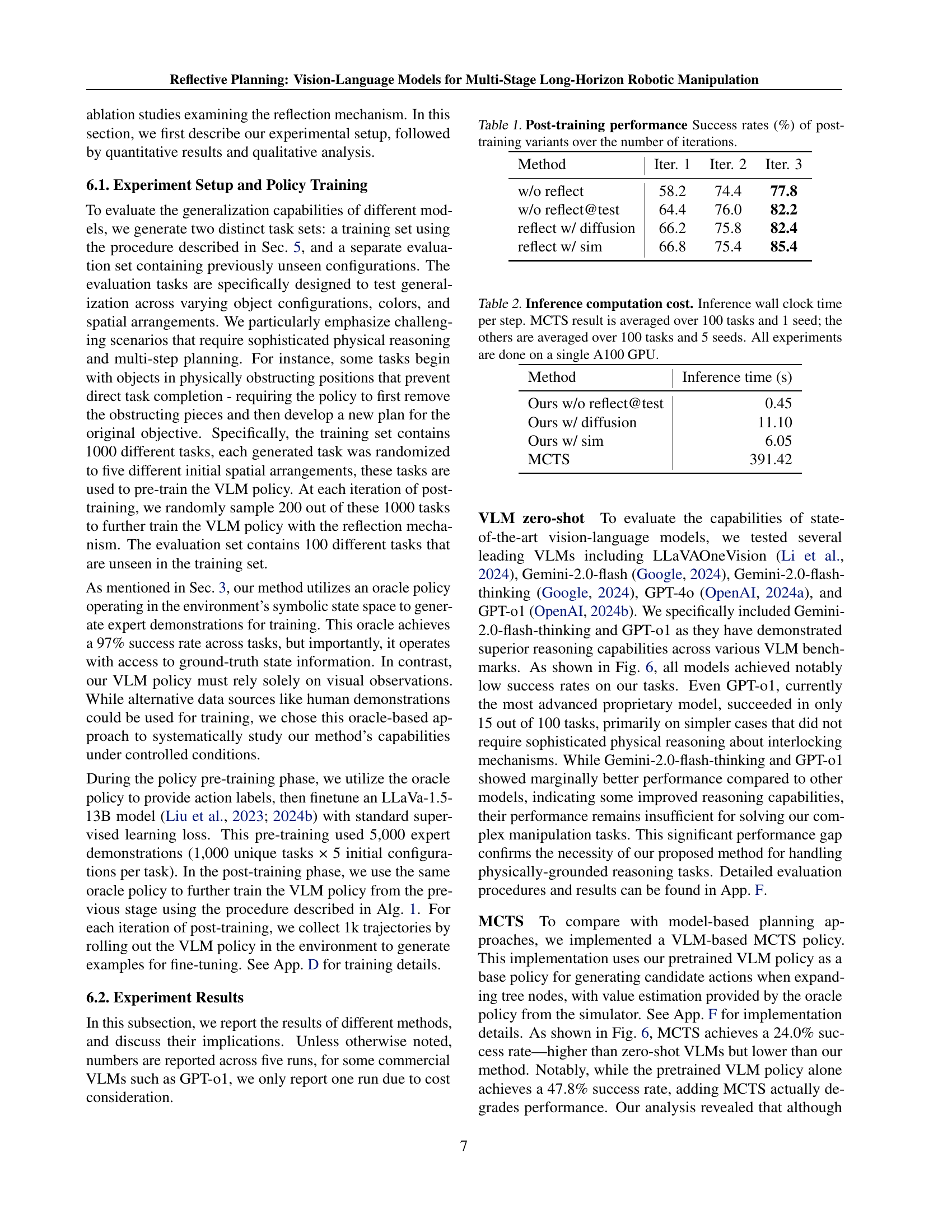
| Method | Iter. 1 | Iter. 2 | Iter. 3 |
|---|---|---|---|
| w/o reflect | 58.2 | 74.4 | 77.8 |
| w/o reflect@test | 64.4 | 76.0 | 82.2 |
| reflect w/ diffusion | 66.2 | 75.8 | 82.4 |
| reflect w/ sim | 66.8 | 75.4 | 85.4 |
🔼 This table presents the success rates achieved by different training approaches for a robotic manipulation task across three iterations of post-training. It shows how the success rate improves over iterations for models with and without a reflection mechanism, and using simulation versus real-world data for training. The comparison highlights the impact of using reflection and a diffusion dynamics model on the overall performance of the vision-language model (VLM).
read the caption
Table 1: Post-training performance Success rates (%) of post-training variants over the number of iterations.
In-depth insights#
Reflective VLMs#
Reflective VLMs enhance physical reasoning in robotic manipulation by iteratively improving pretrained VLMs with a ‘reflection’ mechanism. This involves using a generative model to imagine future world states, guiding action selection, and critically reflecting on potential suboptimalities to refine reasoning. The system leverages visual predictions and iterative refinement, enabling a more sophisticated understanding of physical constraints. By combining VLMs with reflection and targeted post-training, the system gains a better understanding of physical constraints and their implications for action planning. This approach contrasts with existing methods that primarily focus on language-only or visual comprehension tasks, by addressing physical reasoning and robotics applications through visual imagination and revision. The approach leverages internet-scale knowledge while overcoming limitations in physical reasoning and long-horizon planning. This combination of visual prediction and iterative refinement allows the VLM to improve its decision-making capabilities without requiring extensive retraining.
Test-Time Adapt#
Test-time adaptation is crucial for deploying machine learning models in real-world scenarios where data distributions can shift. It involves adjusting the model’s parameters or outputs on the fly, using only the input data encountered during deployment, without access to the original training data. This can be achieved through techniques like self-training, where the model iteratively refines its predictions by treating high-confidence outputs as pseudo-labels, or through meta-learning approaches that train the model to quickly adapt to new tasks. Effective test-time adaptation requires careful consideration of factors like the adaptation rate, the regularization strength, and the potential for catastrophic forgetting, where the model loses its previously learned knowledge while adapting to new data. Ultimately, successful test-time adaptation leads to more robust and reliable model performance in dynamic and uncertain environments.
Visual Dynamics#
Visual dynamics, especially in the context of robotic manipulation, involve understanding how actions change the visual state of the environment. Predicting these changes is crucial for planning and control. Models that can accurately simulate the consequences of actions enable robots to reason about potential outcomes without physically executing them. These models can range from simple kinematic predictors to complex physics engines or learned models like diffusion models. The effectiveness of visual dynamics hinges on the fidelity of the predictions; a model that accurately captures the nuances of object interactions and environmental constraints will lead to better planning and execution. Incorporating visual dynamics into a robotic system typically involves a learning phase, where the model is trained on data of robot actions and their resulting visual changes. At inference, the model predicts how the environment will change given a sequence of actions, allowing the robot to select the most promising plan.
Assembly Tasks#
The research paper addresses the intricate challenges of robotic assembly, focusing on multi-stage long-horizon manipulation. Assembly tasks, especially those involving interlocking parts, are central to evaluating the method’s ability to reason about physical constraints and action sequences. Performance in assembly demonstrates the model’s understanding of complex physical interactions and planning over extended horizons. Task complexity underscores the importance of reflection mechanisms for refining actions based on imagined outcomes. Assembly provides a grounded environment for assessing the VLM’s capabilities in sequential decision-making and error recovery, highlighting the need for robust long-horizon manipulation.
Iterative Refine#
The concept of iterative refinement, though not explicitly mentioned as a heading, is a powerful paradigm. It allows for the successive approximation of a solution, starting with an initial guess and improving it over multiple iterations. This is crucial when facing complex tasks where a direct, one-shot solution is difficult to obtain. In robotics, iterative refinement can be used to improve robot actions gradually and create a robust system. By iteratively evaluating and correcting actions, robots can learn to adapt to the complexities of the environment and achieve desired outcomes in dynamic and unpredictable conditions. The iterative refinement process also involves continuous self-assessment to identify shortcomings in the initial steps. By identifying these points of suboptimal action, it contributes to building a robust and generalizable planning system. This iterative process promotes increased precision and resilience to unexpected situations.
More visual insights#
More on figures

🔼 This figure illustrates how training data is generated for the reflection mechanism. For each timestep in a rollout (a sequence of actions and observations), two training examples are created. The first example (Q1, A1) consists of a question (Q1) that asks what action should be taken next, given the current and goal states and a history of previous actions. The answer (A1) is the action the expert policy would take in this situation. The second example (Q2, A2) focuses on reflection. The question (Q2) is similar to Q1, but it adds the hypothetical future state that would result from taking the proposed action. This enables the VLM to learn to evaluate its proposed actions and revise them if the imagined future looks suboptimal. ‘H’ represents the number of steps the model is asked to look ahead into the future to make this evaluation, and ‘h’ represents the length of the history of previous actions considered.
read the caption
Figure 2: Training data generation. Training data for the reflection mechanism is collected by relabeling the rollouts. For each timestep, two training examples are generated: (Q1, A1) for action proposal and (Q2, A2) for reflection. H𝐻Hitalic_H is the imagination horizon, and hℎhitalic_h is the history length. at∗superscriptsubscript𝑎𝑡a_{t}^{*}italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT is the action label given by the expert policy.
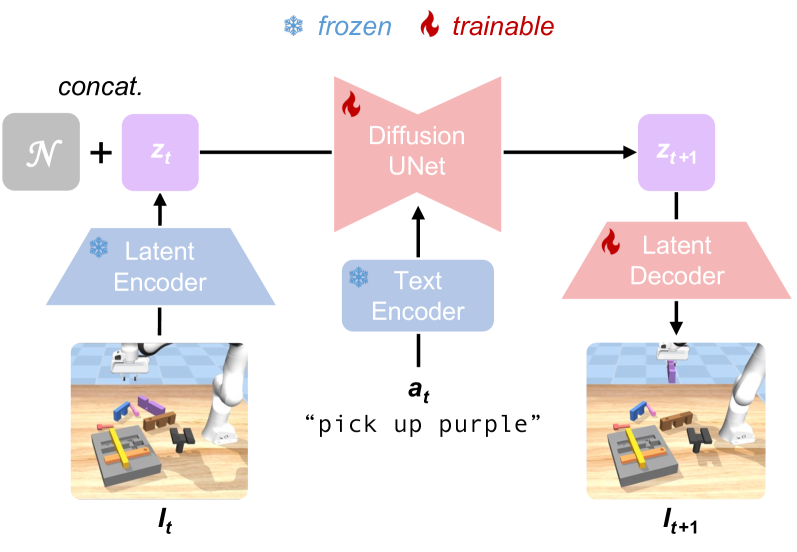
🔼 The figure showcases the architecture of the Diffusion Dynamics Model (DDM), a key component in the Reflective Planning framework. The DDM uses a diffusion process to predict future visual states based on current observations and planned actions. It comprises four main parts: a latent encoder and a text encoder (both frozen during training), a Diffusion UNet, and a latent decoder. The latent encoder converts image inputs into latent representations. Concurrently, the text encoder processes the action text into a corresponding representation. Both latent representations are fed into the Diffusion UNet which performs the core diffusion process, refining the noise added to the latent image representation. Finally, the latent decoder reconstructs a visual representation from the refined latent representation output by the UNet. Only the Diffusion UNet and the latent decoder are fine-tuned on task data; the encoder components remain frozen to leverage their pre-trained knowledge. The symbol 𝒩 denotes the addition of random noise during the diffusion process.
read the caption
Figure 3: Architecture of Diffusion Dynamics Model, which consists of a latent encoder, text encoder, Diffusion UNet and latent decoder. The latent encoder and text encoder are frozen during training, while Diffusion UNet and latent decoder are finetuned on our task data. 𝒩𝒩\mathcal{N}caligraphic_N: random noise.

🔼 This figure shows a filmstrip illustrating the ReflectVLM solving a complex assembly task. Each frame represents a timestep, starting with the initial state and the goal state (top-left, green border). The black text above each frame indicates the action taken at that step. Greyed-out actions show the VLM’s initial incorrect action proposal before reflection. The red border around one of the images highlights a key moment (timestep 15) where the VLM initially suggested picking up a purple brick but reconsidered after using its reflection mechanism to visualize the next steps. The reflection process showed that picking up the purple brick would not lead to progress towards the goal; therefore, the VLM corrected its action to pick up the yellow brick.
read the caption
Figure 4: Filmstrip of our method solving a complicated assembly task. Frames are indexed by timestep. The goal image is in the top-left corner (with a green border). Each frame is the observation after executing the action (in black) above it. The other action in gray is the original action proposed by the VLM if it is revised after reflection. We highlight the reflection process at timestep 15, where the VLM first proposes an action to pick up the purple brick, but after reflection, it chooses to pick up the yellow brick instead as the generated future state (red-bordered image) shows little progress towards the goal.
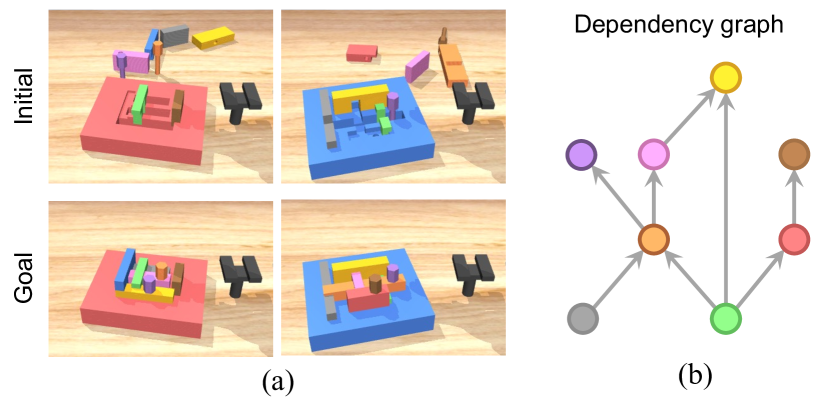
🔼 Figure 5 illustrates examples of multi-stage robotic manipulation tasks. Part (a) displays several example tasks. Each example shows the initial state (top) and the desired goal state (bottom) of the task. These tasks involve assembling interlocking pieces into a specified configuration on a board. Appendix B provides additional examples. Part (b) uses a graph to represent the dependencies between the objects on the board in a sample task. Each node represents an object, and the directed edges indicate the order in which the objects must be placed; that is, an object cannot be placed until its predecessor objects are already in place.
read the caption
Figure 5: Task examples. (a) Generated multi-stage manipulation tasks with interlocking pieces. Top: initial configurations. Bottom: goal configurations. See App. B for more examples. (b) The graph shows the dependencies between the objects in the blue assembly board on the left. Each node represents an object, and each directed edge indicates the predecessor object should be assembled before the successor object.

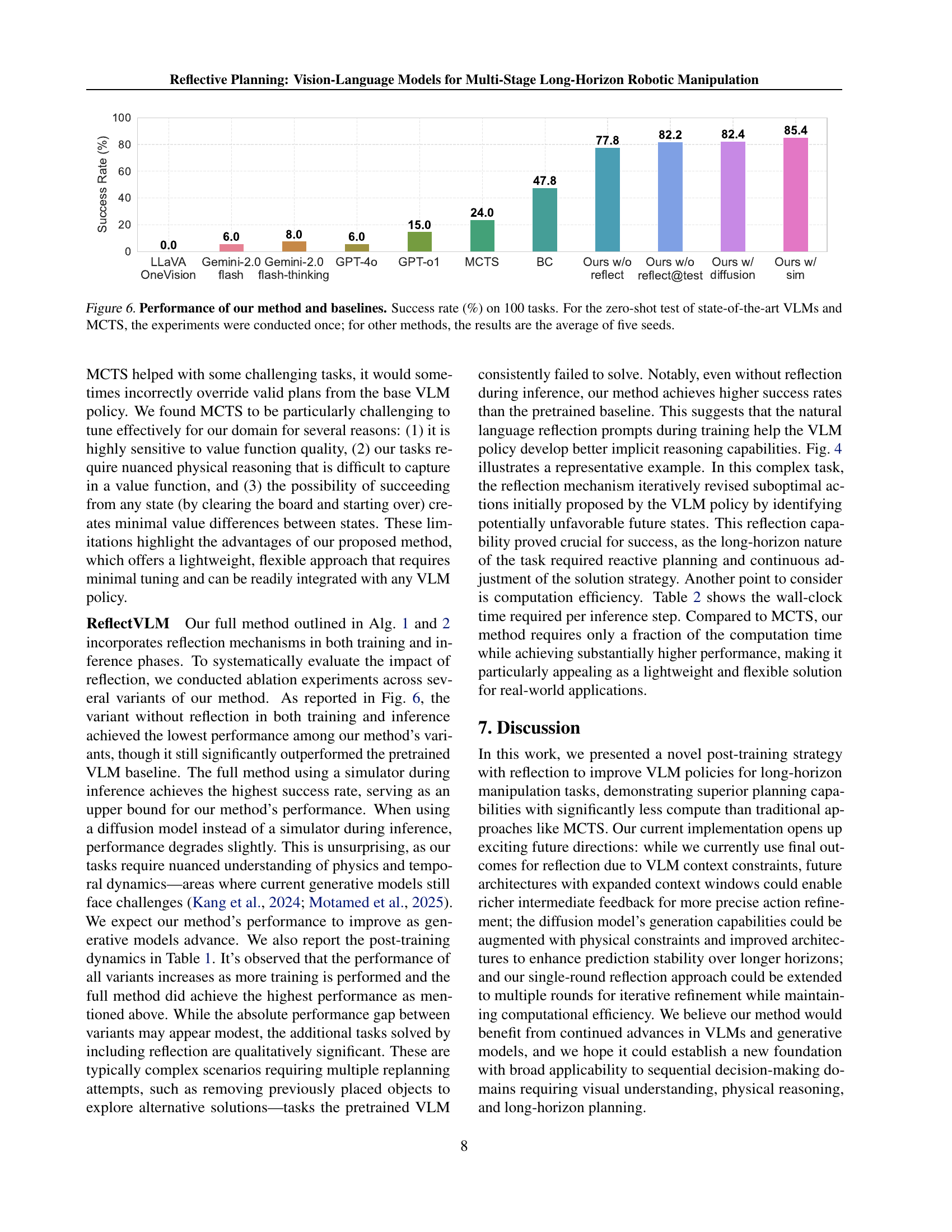
🔼 Figure 6 presents a bar chart comparing the success rates of various methods on 100 multi-stage robotic manipulation tasks. The methods include several state-of-the-art Vision-Language Models (VLMs) evaluated in a zero-shot setting (meaning no fine-tuning on the specific task), a Monte Carlo Tree Search (MCTS) approach, and the proposed ReflectVLM method with and without a diffusion model for future state prediction and with and without reflection. The ReflectVLM method uses the same amount of labeled data and maintains computational efficiency compared to existing methods. ReflectVLM significantly outperforms all baselines. Note that the zero-shot VLMs and MCTS results are from single runs, while ReflectVLM results are averaged over five runs to account for variability.
read the caption
Figure 6: Performance of our method and baselines. Success rate (%) on 100 tasks. For the zero-shot test of state-of-the-art VLMs and MCTS, the experiments were conducted once; for other methods, the results are the average of five seeds.
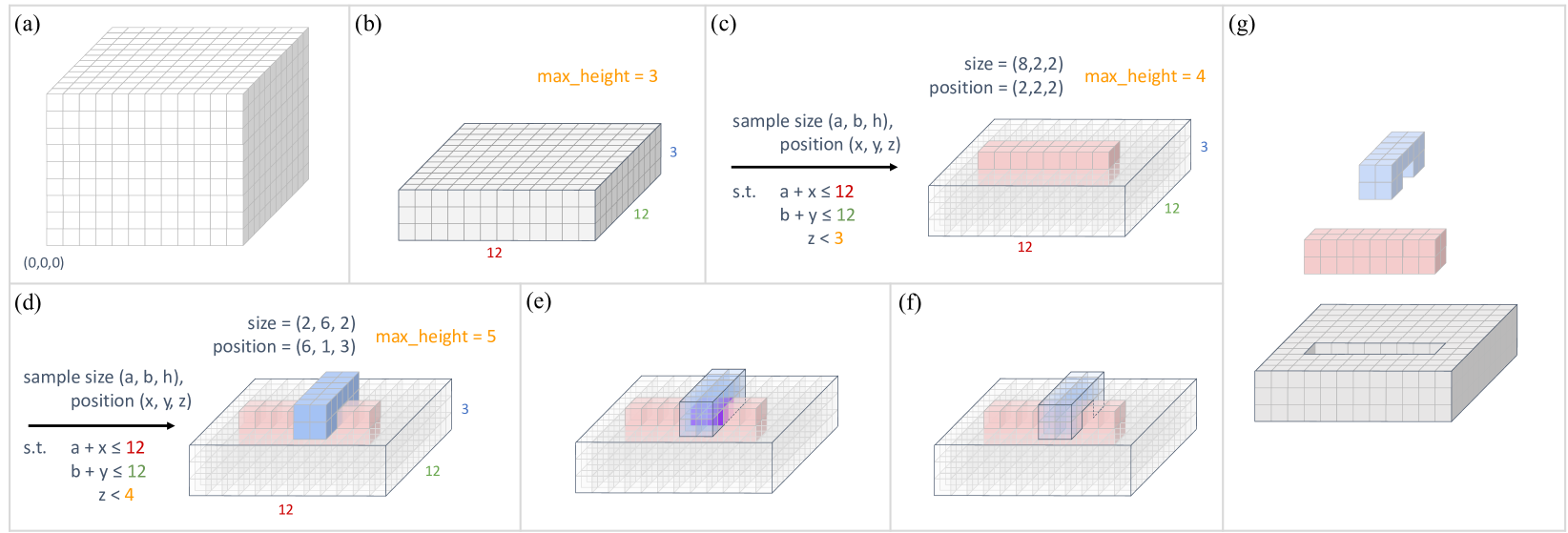
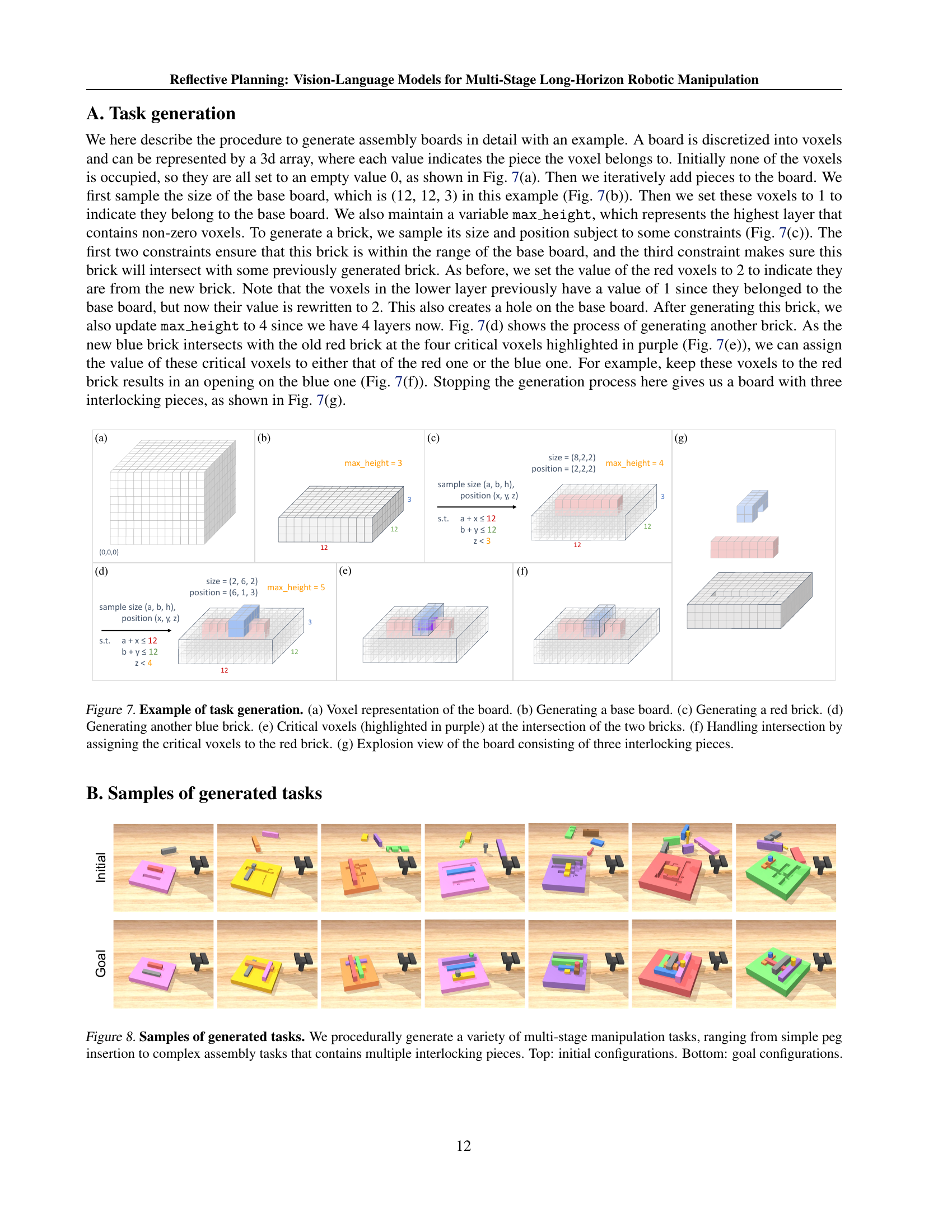
🔼 Figure 7 demonstrates the process of procedurally generating assembly tasks for robotic manipulation. It starts with an empty voxel representation of the board (a). A base board is then generated (b), followed by the iterative addition of interlocking bricks. Panel (c) shows the creation of a red brick, and (d) shows a blue brick intersecting with the red one. Panel (e) highlights the critical voxels where the bricks overlap. The choice of assigning these voxels to either brick impacts the resulting structure, as shown in (f). Finally, (g) presents an exploded view of the resulting board, comprised of three interlocking pieces, which is a sample task generated using this procedure.
read the caption
Figure 7: Example of task generation. (a) Voxel representation of the board. (b) Generating a base board. (c) Generating a red brick. (d) Generating another blue brick. (e) Critical voxels (highlighted in purple) at the intersection of the two bricks. (f) Handling intersection by assigning the critical voxels to the red brick. (g) Explosion view of the board consisting of three interlocking pieces.

🔼 Figure 8 presents example multi-stage robotic manipulation tasks procedurally generated for the paper. The figure showcases a range of task complexities, from simple peg insertion to intricate assembly challenges involving multiple interlocking pieces. The top row displays the initial state of each task, showing the starting arrangement of the objects. The bottom row shows the corresponding goal state, illustrating the desired final configuration of the assembled pieces.
read the caption
Figure 8: Samples of generated tasks. We procedurally generate a variety of multi-stage manipulation tasks, ranging from simple peg insertion to complex assembly tasks that contains multiple interlocking pieces. Top: initial configurations. Bottom: goal configurations.
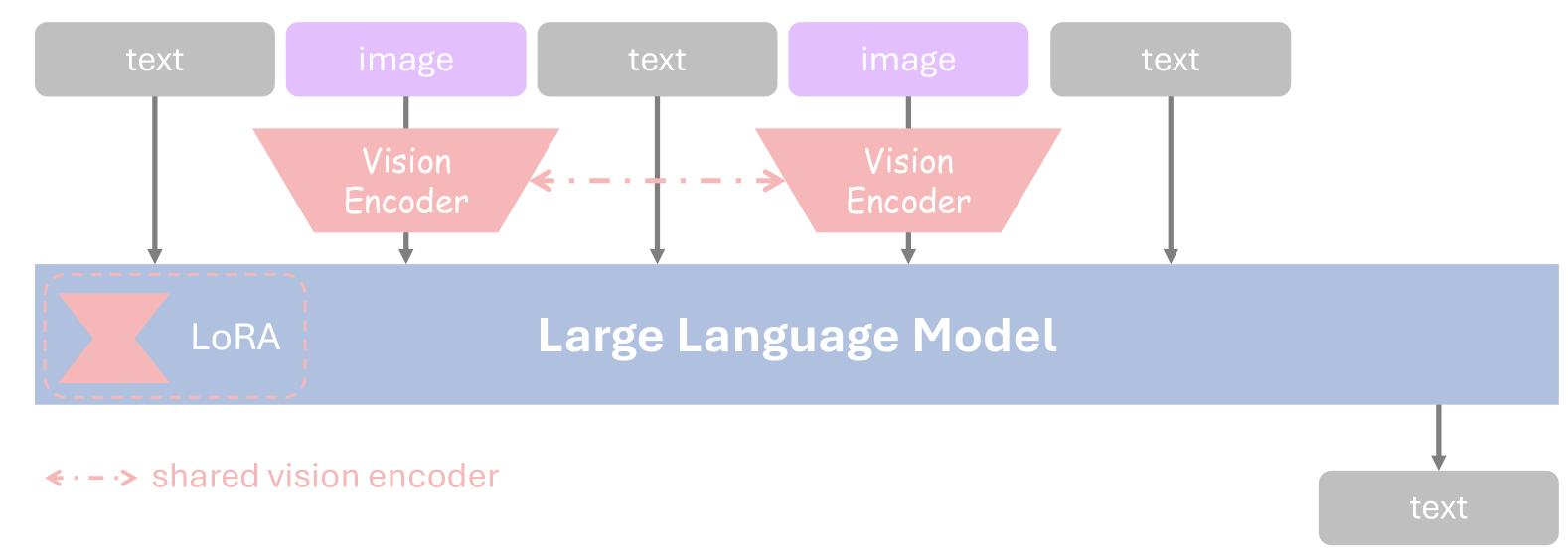
🔼 The figure illustrates the architecture of the Vision-Language Model (VLM) used in the paper. It’s a multimodal model combining a vision encoder and a Large Language Model (LLM). The vision encoder processes images, converting them into latent embeddings. These embeddings, along with textual input, are then fed into the LLM. To improve efficiency and adaptability, Low-Rank Adaptation (LoRA) layers are added to the LLM. The combined image and text embeddings are used for multimodal reasoning within the LLM.
read the caption
Figure 9: Architecture of our VLM. The model consists of a vision encoder and an LLM. We also add Low-Rank Adaptation (LoRA) (Hu et al., 2022) layers to LLM for efficient adaptation. The input sequence contains interleaved images and text, where images are encoded into latent embeddings with a shared vision encoder. Finally, the concatenation of text and image embeddings are fed into VLM for multimodal reasoning.

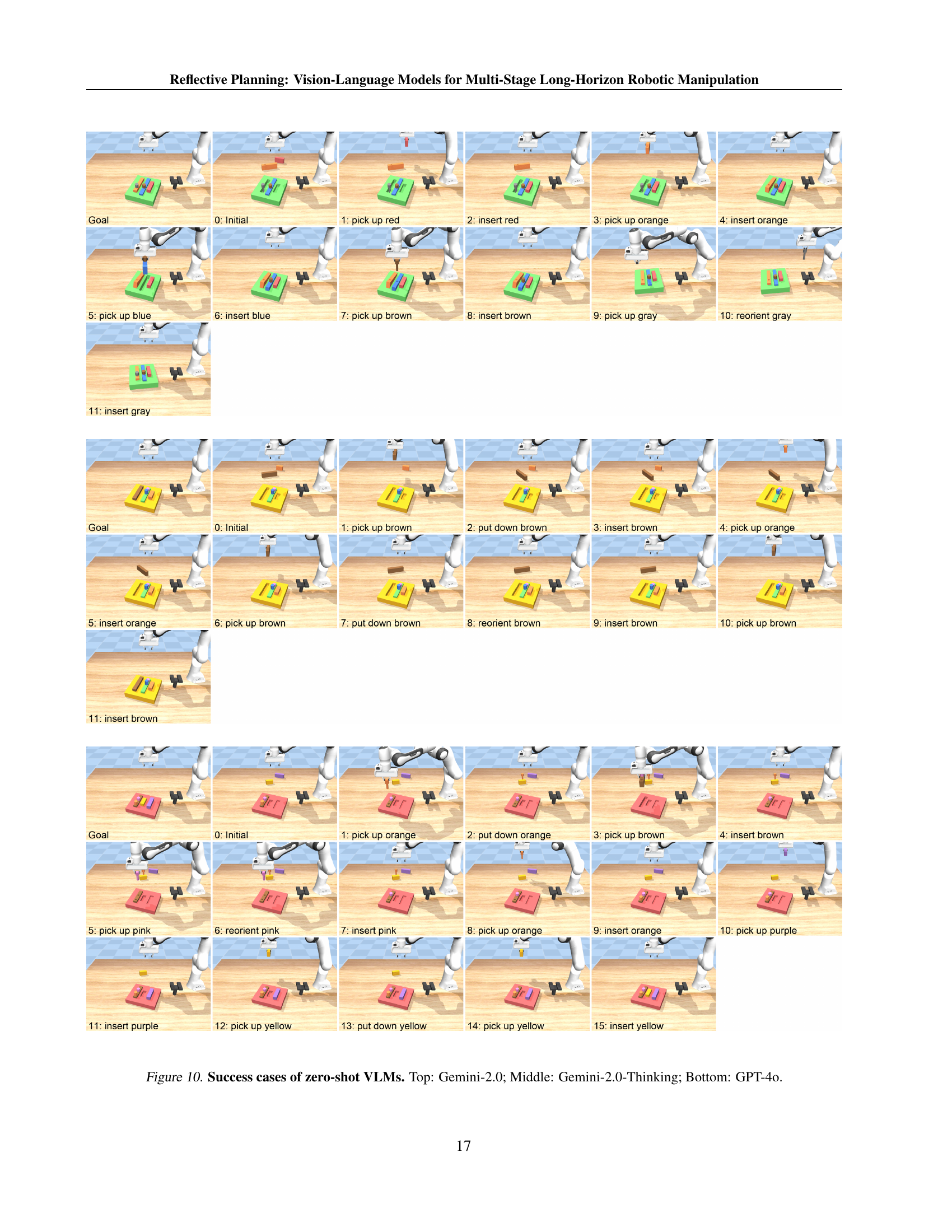
🔼 This figure showcases successful task completions by three different large language models (LLMs) on multi-stage robotic manipulation tasks. Each row represents a separate task, showing the initial state and then a sequence of actions leading to a successful completion. The top row demonstrates results using the Gemini-2.0 LLM, the middle row uses Gemini-2.0-Thinking, and the bottom row displays the results of GPT-40. Each image within a row shows a step in the process, illustrating how the LLM directed the robot arm to interact with the puzzle pieces. This visualization highlights the capabilities of these LLMs to handle multi-step planning and achieve goals in complex environments.
read the caption
Figure 10: Success cases of zero-shot VLMs. Top: Gemini-2.0; Middle: Gemini-2.0-Thinking; Bottom: GPT-4o.

🔼 This figure showcases successful task completion examples by the GPT-01 model, a state-of-the-art Vision-Language Model, tested in a zero-shot setting. Each row represents a separate task. The ‘Goal’ column displays the target configuration. The subsequent columns illustrate the steps taken by the model to achieve the goal, showing the state of the environment at each timestep.
read the caption
Figure 11: Success cases of zero-shot VLMs (GPT-o1).

🔼 This figure shows a failure case of the Gemini-2.0 model in a multi-stage robotic manipulation task. The model attempts to solve a task that involves assembling interlocking pieces on a board. The figure is a sequence of images showing the robot’s actions at each step, starting from the initial state and ending in a failure state where the task is not completed successfully. The failure demonstrates the limitations of the zero-shot VLM model, specifically in its reasoning abilities concerning long-term planning and complex physical interactions, especially when dealing with the spatial constraints and dependencies involved in successfully manipulating interlocking objects.
read the caption
Figure 12: Failure case of Gemini-2.0.

🔼 This figure visualizes a failure case encountered by the Gemini-2.0-Thinking model during a multi-stage robotic manipulation task. It’s a sequence of images showing the robot’s actions and the state of the environment at each step. The robot attempts to assemble a puzzle with multiple interlocking pieces. The sequence highlights the model’s inability to successfully complete the task due to a series of incorrect actions that lead to a state from which successful completion is no longer possible. Each image depicts the robot’s arm, its current action, and the current state of the puzzle pieces on the board.
read the caption
Figure 13: Failure case of Gemini-2.0-Thinking.

🔼 This figure visualizes a failure case of GPT-40, a large language model, in a multi-stage robotic manipulation task. The task involves assembling a puzzle board by inserting various colored blocks in a specific order. The figure shows a sequence of images, each representing a step in the robot’s attempt to complete the task. The initial state, goal state and actions are displayed in the figure. Each step shows an action performed by the model along with the resulting state of the puzzle. The sequence illustrates a series of incorrect actions that lead to the failure of the task. The model fails to correctly assemble the puzzle due to errors in planning and execution. This example highlights the challenges faced by large language models in handling complex physical tasks that require reasoning over long time horizons and adapting to unexpected situations.
read the caption
Figure 14: Failure case of GPT-4o.

🔼 This figure shows a failure case of GPT-01 in a multi-stage robotic manipulation task. The task involves assembling a puzzle board by inserting various colored pieces. GPT-01’s plan is visualized through a series of steps, each showing the robot’s action and the resulting state. The figure demonstrates the model’s inability to successfully complete the task due to a flawed plan, possibly indicating limitations in its understanding of physical interactions and long-term consequences of actions.
read the caption
Figure 15: Failure case of GPT-o1.
More on tables
| Method | Inference time (s) |
|---|---|
| Ours w/o reflect@test | 0.45 |
| Ours w/ diffusion | 11.10 |
| Ours w/ sim | 6.05 |
| MCTS | 391.42 |
🔼 This table presents the computational cost of different methods in terms of inference time per step. The inference time reflects the time taken for each planning step during the execution of a robotic manipulation task. The results are averaged across multiple tasks (100) to ensure a robust comparison. For MCTS (Monte Carlo Tree Search), only a single trial was used, while for all other approaches, the experiment was run five times, and the average is presented. All experiments were conducted using a single NVIDIA A100 GPU to maintain consistency in computational resources.
read the caption
Table 2: Inference computation cost. Inference wall clock time per step. MCTS result is averaged over 100 tasks and 1 seed; the others are averaged over 100 tasks and 5 seeds. All experiments are done on a single A100 GPU.
| Res | LoRA | Training | Batch | Optimizer | Warmup | Learning rate | Weight | LR | |
|---|---|---|---|---|---|---|---|---|---|
| Rank | Epoch | Size | Epoch | BC | Iter. 1,2,3 | Decay | Schedule | ||
| 336px | 128 | 1 | 128 | AdamW | 0.03 | 5e-5 | 1e-5 | 0.0 | Cosine |
🔼 This table details the hyperparameters used during the training of the Vision-Language Model (VLM). It includes information about the resolution (Res), rank of the Low-Rank Adaptation (LoRA) layers, number of training epochs, batch size, optimizer used (AdamW), warmup epochs, learning rate, weight decay, and learning rate schedule. These parameters are crucial for fine-tuning the pre-trained VLM on the specific robotic manipulation task.
read the caption
Table 3: Training parameters of VLM.
| Model | Res | Training | Batch | Optimizer | Warmup | Learning | Weight | Beta1, | Grad | LR |
|---|---|---|---|---|---|---|---|---|---|---|
| Steps | Size | Steps | Rate | Decay | Beta2 | Norm | Schedule | |||
| UNet | 512px | 20K | 640 | AdamW | 2K | 1e-4 | 0.01 | 0.9, 0.999 | 1.0 | Cosine |
| Decoder | 512px | 4K | 160 | AdamW | 1K | 1e-7 | 0.01 | 0.9, 0.999 | 1.0 | Cosine |
🔼 This table details the hyperparameters used during the training of the Diffusion Dynamics Model (DDM). The DDM is a key component of the ReflectVLM system, used to predict future visual states based on current observations and planned actions. The table specifies the model’s resolution, the optimizer used (AdamW), training steps, batch size, warmup steps, learning rate, weight decay, beta1, beta2, gradient norm, and learning rate schedule. Different configurations are shown for the UNet and Decoder components of the DDM, reflecting distinct training strategies employed for these two parts of the model.
read the caption
Table 4: Training parameters of Diffusion Dynamics Models.
| Model | Success Trajectory ID / Planing Steps | Max Steps | Min Steps | Avg Steps |
|---|---|---|---|---|
| Gemini-2.0 | 5/6, 12/4, 16/18, 47/11, 60/4, 86/6 | 18 | 4 | 8.2 |
| Gemini-2.0-Thinking | 5/6, 12/4, 40/20, 47/16, 50/8, 60/8, 86/10, 90/11 | 20 | 4 | 10.4 |
| GPT-4o | 12/15, 16/5, 19/4, 47/10, 60/4, 90/6 | 15 | 4 | 7.3 |
| GPT-o1 | 12/9, 16/6, 17/15, 47/8, 50/16, 58/18, 60/14, 62/33, | 33 | 4 | 13.1 |
| 66/6, 67/12, 72/32, 77/9, 85/9, 86/6, 90/4 |
🔼 This table presents a detailed breakdown of the performance of several large language models (LLMs) in a zero-shot setting on multi-stage robotic manipulation tasks. It shows the success rate, the range of planning steps used, and the average number of steps taken by each model to complete the tasks.
read the caption
Table 5: Detailed evaluation results of zero-shot VLMs.
Full paper#