TL;DR#
Temporal reasoning is fundamental to human cognition and is crucial for various real-world applications. Existing benchmarks primarily rely on rule-based construction, lack contextual depth, and involve a limited range of temporal entities. To address these limitations, this paper focuses on building a new benchmark.
This paper introduces Chinese Time Reasoning (CTM), a new benchmark designed to evaluate LLMs on temporal reasoning within the extensive scope of Chinese dynastic chronology. It emphasizes cross-entity relationships, pairwise temporal alignment, and contextualized and culturally-grounded reasoning, providing a comprehensive evaluation. The experimental results reveal the challenges posed by CTM.
Key Takeaways#
Why does it matter?#
This paper is important as it introduces a challenging new benchmark for temporal reasoning in LLMs, pushing the boundaries of AI’s understanding of historical context. It is relevant to current research trends and opens avenues for improved pretraining and structured knowledge integration.
Visual Insights#
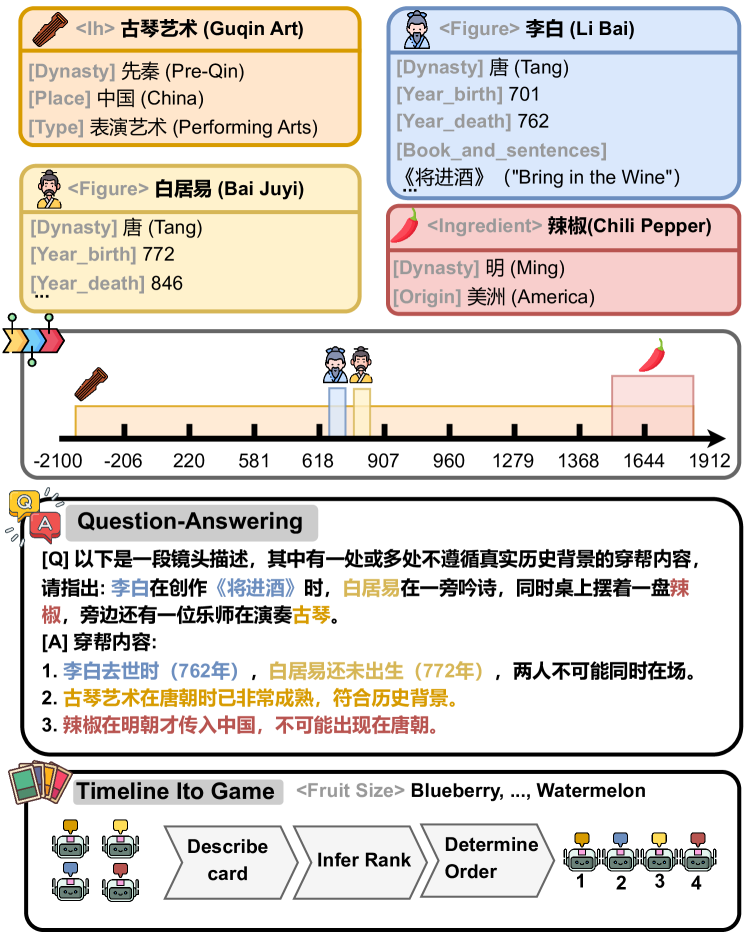
🔼 Figure 1 presents two examples from the CTM benchmark. The first is a Question Answering (QA) task focusing on script error correction. A scenario is presented, and the model must identify historical inaccuracies. The example shown includes a scene featuring Li Bai and Bai Juyi together, along with chili peppers and a Guqin, which is historically incorrect given the timelines of their lives and chili pepper introduction to China. The second example illustrates the Timeline Ito Game. This is a collaborative game where models have to infer the chronological order of historical entities, using a thematic metaphor to aid reasoning. In the example, the theme is ‘fruit size,’ and the models have to determine the order of three figures from Chinese history (represented by different fruit sizes) based on their historical timelines.
read the caption
Figure 1: A QA pair from a script error correction task and an instance of the Timeline Ito Game with a “fruit size” theme from CTM. 333The English translation is presented in App. B.2.
| Language | Construction | Time Scope | Contextualization | Temporal Alignment | Complex Aspects | |
| TimeQA Chen et al. (2021) | En | Rule-based | 1367–2018 | ✗ | ✗ | ✗ |
| TempLAMA Dhingra et al. (2022) | En | Rule-based | 2010–2020 | ✗ | ✗ | ✗ |
| TempReason Tan et al. (2023) | En | Rule-based | 634–2023 | ✗ | ✗ | ✗ |
| SituatedGen Zhang and Wan (2023) | En | LLM-based | - | ✓ | ✗ | ✓ |
| CoTempQA Su et al. (2024) | En | Rule-based | - | ✗ | ✗ | ✗ |
| TimeBench Chu et al. (2024) | En | - | - | ✓ | ✗ | ✓ |
| TRAM Wang and Zhao (2024) | En | Rule-based | - | ✓ | ✗ | ✓ |
| ChronoSense Islakoglu and Kalo (2025) | En | Rule-based | - | ✗ | ✗ | ✗ |
| CTM | Zh | LLM-based | -2100–1912 | ✓ | ✓ | ✓ |
🔼 This table compares the Chinese Time Reasoning (CTM) benchmark with other existing temporal reasoning benchmarks across various aspects, including language, construction method, time scope covered, contextualization capabilities, temporal alignment abilities, and the complexity of aspects involved. It highlights the unique features of CTM, such as its focus on Chinese dynastic chronology and its emphasis on contextualized and culturally-grounded reasoning.
read the caption
Table 1: Comparison between CTM and other benchmarks. Detailed discussion is presented in Appendix A.
In-depth insights#
Chinese Dyn.#
The paper extensively discusses temporal reasoning and alignment across Chinese dynasties. It introduces a new benchmark, CTM, designed to evaluate LLMs’ ability to understand the nuances of Chinese dynastic chronology. CTM emphasizes cross-entity relationships, pairwise temporal alignment, and contextualized reasoning, a significant step beyond existing benchmarks. The focus on Chinese dynasties provides a rich cultural context, which allows for more complex temporal reasoning tasks. The tasks include dynasty determination, plausibility judgment, and script error correction. The results reveal that current LLMs still struggle with nuanced temporal understanding and reasoning, particularly when dealing with multiple entities or precise timestamp calculations. Further analysis suggests that improving pretraining strategies and knowledge integration are crucial for advancing temporal reasoning in LLMs.
CTM Benchmark#
The CTM benchmark seems to be a novel contribution, addressing the limitations of existing temporal reasoning benchmarks. By focusing on the complexities of Chinese dynastic chronology, it introduces a deeper level of contextual and cultural grounding. This approach allows for a more comprehensive evaluation of LLMs’ ability to handle nuanced temporal relationships. The benchmark’s emphasis on cross-entity relationships and pairwise temporal alignment is particularly valuable. Introducing the Timeline Ito Game is a creative way to assess collaborative reasoning and temporal ordering skills. The curation of a detailed Chinese cultural entity repository with over 4,700 entities is commendable. The evaluation of LLMs using both zero-shot and CoT settings provides a thorough understanding of their capabilities. CTM promises to be a valuable resource for advancing temporal reasoning research, offering new challenges and insights into LLMs’ abilities in this crucial area.
Temporal Tasks#
Temporal reasoning is fundamental to human cognition. It has many applications in the real world. However, existing benchmarks are limited in contextual depth and the number of entities involved. LLMs have demonstrated abilities in this area. Evaluating whether a model has a clear understanding of time within a temporal coordinate system is essential. The Chinese dynastic chronology is suitable for temporal reasoning because of the wide historical scope and the culturally grounded knowledge it encompasses. Chinese culture has a vast timeline, with each dynasty rich in figures and cultural narratives. The design tasks examine LLMs’ ability to perceive and reason about temporal relationships.
LLM Evaluation#
LLM evaluation is crucial for understanding their capabilities and limitations, especially in complex tasks. Metrics like accuracy are common, but nuanced evaluations are needed. The paper utilizes GPT-4o as an evaluator, which helps determine correctness by comparing predictions with ground truth using Chain-of-Thought (CoT). Pass@K assesses sequential alignment, which is essential in tasks like the Timeline Ito Game. The evaluation setup influences the results, and the paper acknowledges potential variations in prompt effectiveness across tasks and models. Therefore, careful consideration of evaluation settings is vital for interpreting LLM performance.
Limited scope#
While the current research offers valuable insights, it’s acknowledged that the scope has limitations. The evaluation primarily uses direct prompting and chain-of-thought (CoT), and other prompt engineering techniques may yield varied results across tasks and LLMs. Future work should explore more adaptive prompting and diverse few-shot or zero-shot settings to provide a more robust evaluation. Also, the dataset, despite its diversity in Chinese temporal reasoning tasks, has potential for expansion. Enriching the dataset with more complex scenarios, longer historical events, and varied question types, along with the timeline Ito game will provide greater challenges for the model.
More visual insights#
More on figures
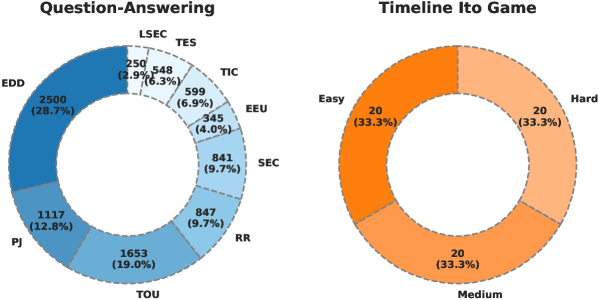
🔼 Figure 2 presents a statistical overview of the Chinese Time Reasoning (CTM) benchmark dataset. It visually summarizes the distribution of various question types within the dataset and also shows the breakdown of the Timeline Ito Game dataset into different difficulty levels based on the number of entities involved.
read the caption
Figure 2: Statistic of CTM.
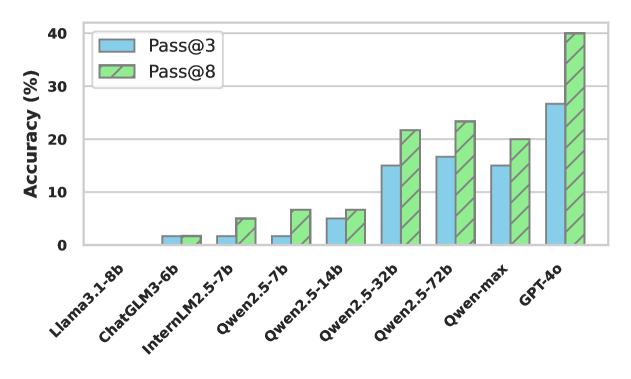
🔼 This figure displays the average performance across different LLMs in the Timeline Ito Game. It shows the average accuracy of various LLMs in correctly ordering historical entities based on contextual clues and thematic metaphors. The game involves multiple steps: describing an entity, inferring its rank based on the theme, and determining its order in the timeline. The figure provides a summary of the overall performance, while the detailed results for each LLM are available in Appendix I.
read the caption
Figure 3: Average performance of Ito’s Guessing Game. Detailed results can be found in Appendix I.

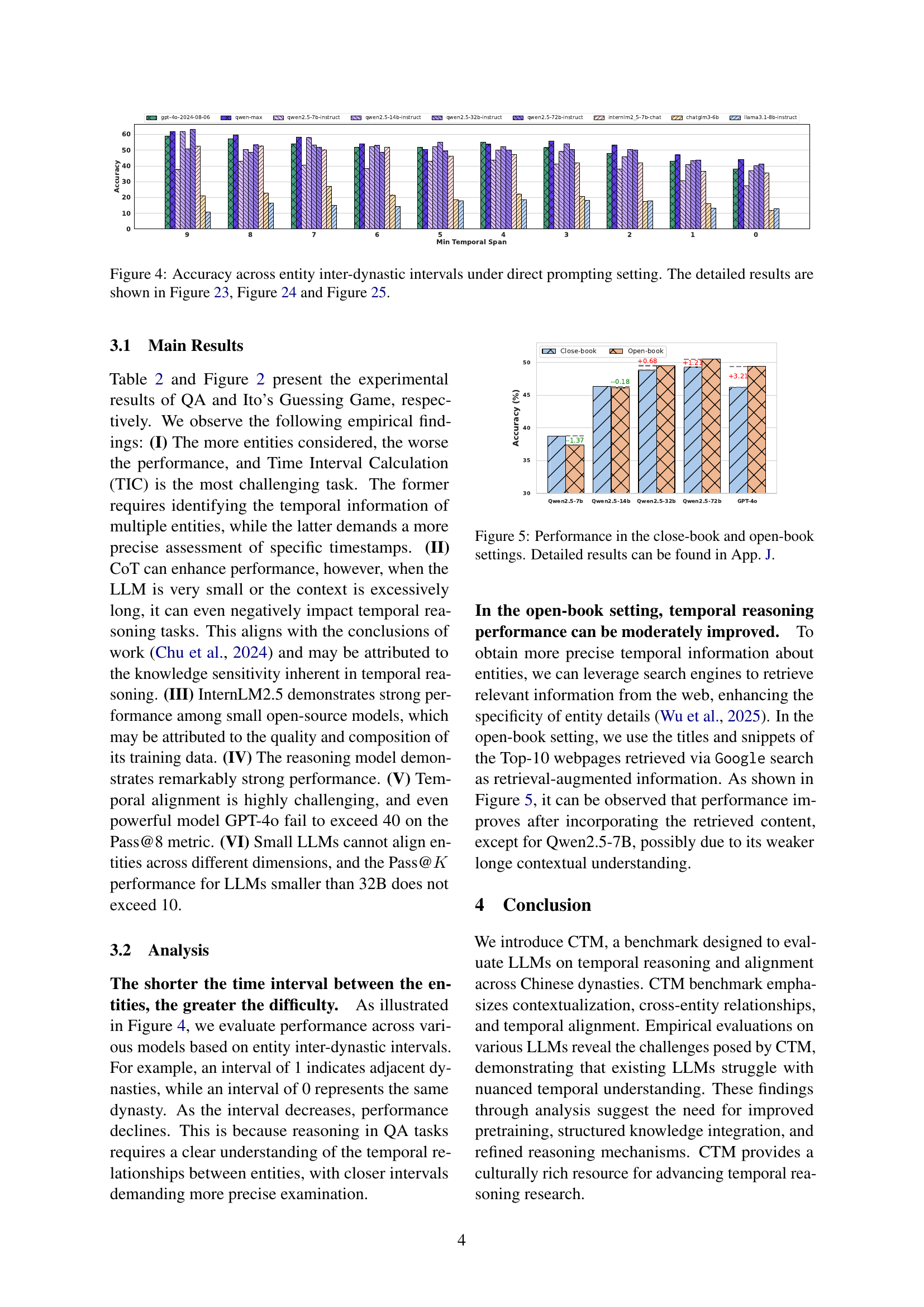
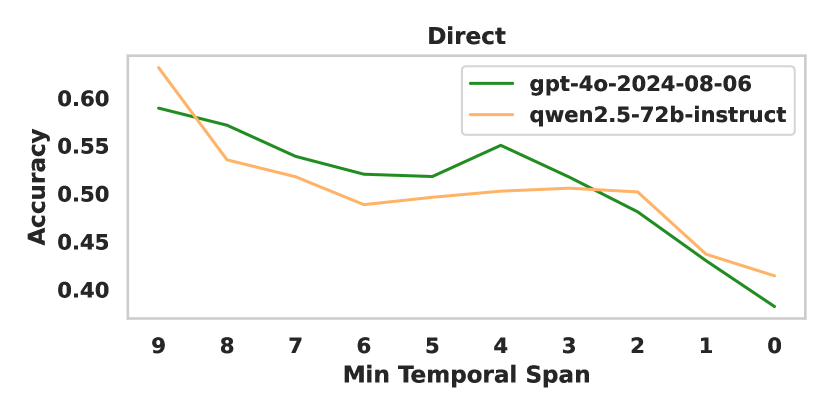
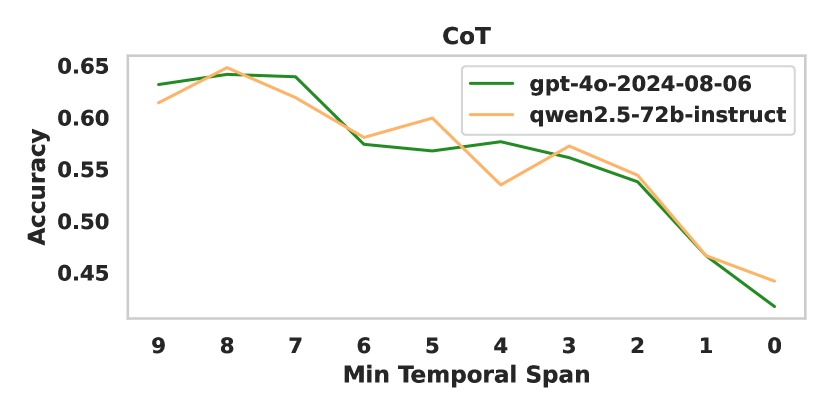
🔼 This figure displays the accuracy of various large language models (LLMs) in temporal reasoning tasks, specifically focusing on the ability to correctly identify temporal relationships between entities spanning different Chinese dynasties. The x-axis represents the minimum temporal span (in dynasties) between the entities involved in the task, while the y-axis shows the accuracy of the LLMs’ predictions. The graph illustrates how the difficulty of the task, and thus the model accuracy, changes as the time interval between entities increases. More detailed breakdowns of this accuracy are presented in Figures 23, 24, and 25.
read the caption
Figure 4: Accuracy across entity inter-dynastic intervals under direct prompting setting. The detailed results are shown in Figure 23, Figure 24 and Figure 25.
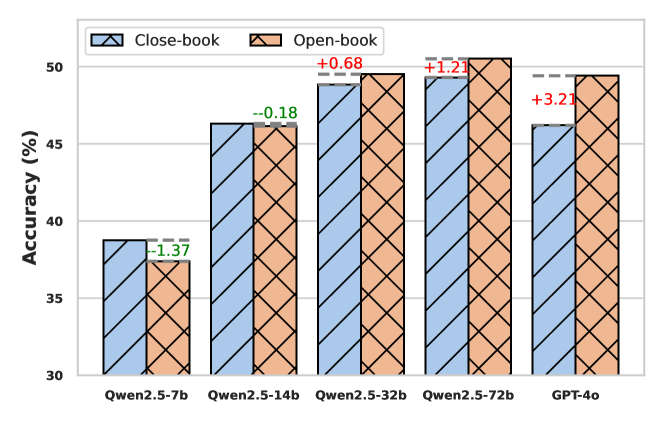
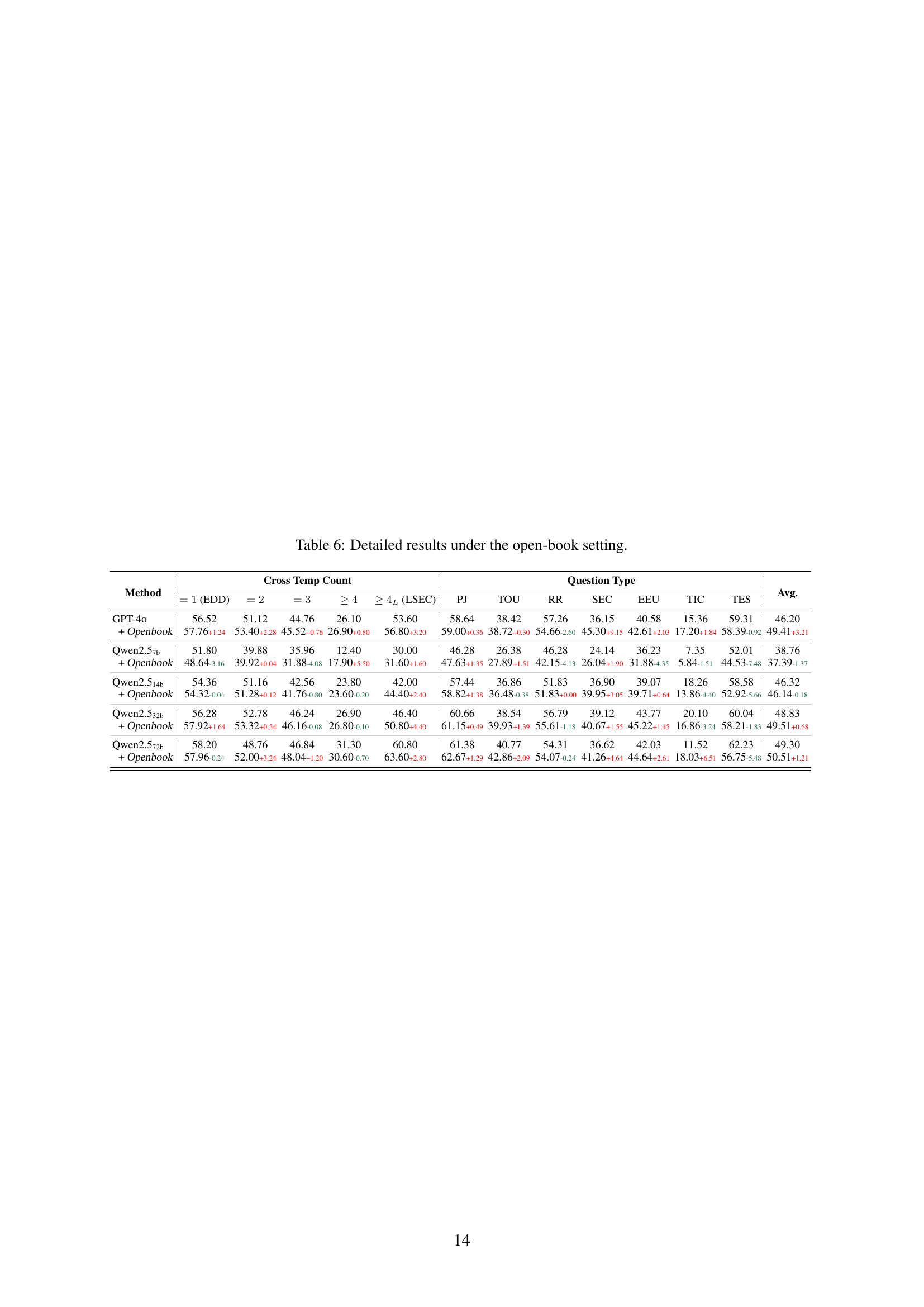
🔼 This figure compares the performance of different LLMs in temporal reasoning tasks under two settings: close-book (no external knowledge) and open-book (allowing access to external information via search engines). The x-axis represents the different LLMs evaluated. The y-axis displays the accuracy achieved. The bars illustrate the performance difference between the two settings for each LLM, highlighting the impact of access to external information on temporal reasoning capabilities. More detailed results are available in Appendix J.
read the caption
Figure 5: Performance in the close-book and open-book settings. Detailed results can be found in App. J.

🔼 This JSON data represents a structured format for storing information about a historical figure. It includes fields for the person’s name (‘屈原’), the dynasty they lived in (‘先秦’), their place of birth, birth and death years, and a list of their writings and associated sentences from their works. Each work is listed with a title and a specific excerpt. This structured format is used to organize the data in a consistent manner for processing by a computer, allowing for easy data retrieval and analysis.
read the caption
Figure 6: A JSON-format case for historical figure entity.
🔼 The figure displays a JSON-formatted example representing a place entity within the CTM benchmark dataset. The JSON structure includes fields such as ‘dynasty’ (specifying the Chinese dynasty), ‘id’, ‘begin’ and ’end’ (for temporal range), ‘pre_address’ (the modern equivalent of the location), and ‘subordinate_units’ (containing information about administrative divisions within the place during that period). This is a structured way of representing the data for historical places within the dataset, facilitating efficient processing and analysis by machine learning models during evaluation.
read the caption
Figure 7: A JSON-format case for place entity.
🔼 Figure 8 displays a JSON formatted example representing an event entity from the CTM dataset. It shows the structure used to represent events in a standardized way, including fields like ‘id’, ‘dynasty’ (the historical dynasty in which the event occurred), and ‘main_figures’ (key individuals involved). This structured format facilitates data processing and analysis for tasks involving temporal reasoning.
read the caption
Figure 8: A JSON-format case for event entity.
More on tables
| Method | Cross Temp Count | Question Type | Avg. | ||||||||||
| (EDD) | (LSEC) | PJ | TOU | RR | SEC | EEU | TIC | TES | |||||
| Closed-Sourced LLMs | |||||||||||||
| GPT-4o | 56.52 | 51.12 | 44.76 | 26.10 | 53.60 | 58.64 | 38.42 | 57.26 | 36.15 | 40.58 | 15.36 | 59.31 | 48.08 |
| + CoT | 67.40+10.88 | 58.08+6.96 | 49.24+4.48 | 29.60+3.50 | 31.60-22.0 | 64.10+5.46 | 44.71+6.29 | 59.62+2.36 | 47.09+10.94 | 44.06+3.48 | 17.70+2.34 | 61.68+2.37 | 54.21+6.13 |
| Qwen-max | 60.48 | 53.12 | 50.54 | 30.80 | 62.00 | 64.39 | 42.55 | 59.10 | 40.71 | 46.38 | 20.87 | 60.22 | 52.27 |
| + CoT | 69.56+9.08 | 59.32+6.20 | 54.48+3.94 | 31.90+1.10 | 39.60-22.40 | 63.29-1.10 | 48.58+6.03 | 63.75+4.65 | 55.77+15.06 | 53.91+7.53 | 15.19-5.68 | 63.14+2.92 | 57.24+4.97 |
| o1-preview | 52.80 | 46.56 | 49.64 | 32.70 | 67.20 | 58.28 | 44.28 | 53.01 | 43.16 | 40.87 | 11.02 | 56.02 | 48.24 |
| Open-Sourced LLMs | |||||||||||||
| LLaMA3.1 | 33.04 | 16.86 | 15.60 | 9.10 | 10.80 | 19.66 | 12.95 | 18.65 | 7.37 | 0.87 | 2.01 | 37.04 | 20.14 |
| + CoT | 35.05+2.01 | 26.44+9.58 | 19.96+4.36 | 10.70+1.60 | 12.40+1.60 | 26.48+6.82 | 19.55+6.60 | 23.20+4.55 | 20.02+12.65 | 15.70+14.83 | 5.51+3.50 | 34.37-2.67 | 24.91+4.77 |
| ChatGLM3 | 38.40 | 21.60 | 16.04 | 5.80 | 4.80 | 21.40 | 12.28 | 22.67 | 12.25 | 12.75 | 1.84 | 35.58 | 22.52 |
| + CoT | 37.24-1.16 | 22.72+1.12 | 15.28-0.76 | 8.20+2.40 | 4.00-0.80 | 20.32-1.08 | 15.92+3.64 | 20.12-2.55 | 14.98+2.73 | 16.52+3.77 | 3.01+1.17 | 29.74-5.84 | 22.61+0.09 |
| InternLM2.5 | 60.64 | 47.32 | 39.36 | 21.60 | 42.00 | 51.39 | 30.16 | 48.64 | 45.78 | 42.61 | 11.19 | 50.18 | 45.75 |
| + CoT | 61.44+0.80 | 51.40+4.08 | 39.36+0.00 | 20.20-1.40 | 38.00-4.00 | 51.70+0.31 | 31.45+1.29 | 49.47+0.83 | 52.86+7.08 | 44.19+1.58 | 11.52+0.33 | 48.54-1.64 | 46.90+1.15 |
| Qwen2.5 | 51.80 | 39.88 | 35.96 | 12.40 | 30.00 | 46.28 | 26.38 | 46.28 | 24.14 | 36.23 | 7.35 | 52.01 | 38.76 |
| + CoT | 59.96+8.16 | 47.60+7.72 | 36.64+0.68 | 18.30+5.90 | 30.80+0.80 | 52.46+6.18 | 29.95+3.57 | 52.18+5.90 | 34.13+9.99 | 40.58+4.35 | 8.18+0.83 | 49.64-2.37 | 44.22+5.46 |
| Qwen2.5 | 54.36 | 51.16 | 42.56 | 23.80 | 42.00 | 57.44 | 36.86 | 51.83 | 36.90 | 39.07 | 18.26 | 58.58 | 46.32 |
| + CoT | 57.92+3.56 | 45.44-5.72 | 41.24-1.32 | 22.50-1.30 | 30.80-11.20 | 52.73-4.71 | 34.36-2.50 | 46.52-5.31 | 42.57+5.67 | 36.81-2.26 | 10.02-8.24 | 51.82-6.76 | 44.89-1.43 |
| Qwen2.5 | 56.28 | 52.78 | 46.24 | 26.90 | 46.40 | 60.66 | 38.54 | 56.79 | 39.12 | 43.77 | 20.10 | 60.04 | 48.83 |
| + CoT | 60.80+4.52 | 49.32-3.46 | 45.32-0.92 | 24.80-2.10 | 31.20-15.20 | 50.67-9.99 | 40.65+2.11 | 51.12-5.67 | 43.40+4.28 | 40.29-3.48 | 17.03-3.07 | 57.12-2.92 | 48.14-0.69 |
| Qwen2.5 | 58.20 | 48.76 | 46.84 | 31.30 | 60.80 | 61.38 | 40.77 | 54.31 | 36.62 | 42.03 | 11.52 | 62.23 | 49.30 |
| + CoT | 69.00+10.80 | 57.24+8.48 | 49.88+3.04 | 32.50+1.20 | 46.00-14.80 | 61.50+0.12 | 45.01+4.24 | 61.51+7.20 | 50.18+13.56 | 49.86+7.83 | 17.53+6.01 | 59.85-2.38 | 55.39+6.09 |
| Deepseek-R1 | 70.84 | 67.12 | 60.64 | 45.50 | 72.40 | 76.63 | 58.17 | 67.30 | 59.69 | 61.16 | 24.37 | 67.70 | 64.02 |
🔼 This table presents the main results of the Question Answering tasks within the Chinese Time Reasoning (CTM) benchmark. It shows the accuracy of various Large Language Models (LLMs) across eight different question types, categorized by the number of temporal entities involved. The best performing model for each task is bolded, while the second-best is underlined, allowing for easy comparison of LLM performance on this challenging temporal reasoning benchmark.
read the caption
Table 2: Main results on QA tasks within CTM benchmark. The best results among all backbones are bolded, and the second-best results are underlined.
| Statistic | Question-Answering | ||||||||
| EDD | PJ | TOU | RR | SEC | EEU | TIC | TES | LSEC | |
| # Sample | 2500 | 1117 | 1653 | 847 | 841 | 345 | 599 | 548 | 250 |
| Cross Temp Count | 1 | 2, 3, 4..10 | 4..15 | ||||||
| Statistic | Timeline Ito Game | ||||||||
| Easy | Medium | Hard | |||||||
| # Sample | 20 | 20 | 20 | ||||||
| Cross Temp Count | 3 | 4 | 5 | ||||||
| Agent Num | 3 | 4 | 5 | ||||||
🔼 Table 3 presents a detailed statistical overview of the CTM (Chinese Time Reasoning) benchmark dataset. It breaks down the number of samples for each of the eight question-answering tasks (EDD, PJ, TOU, RR, SEC, EEU, TIC, TES, and LSEC) within CTM. Additionally, it provides the distribution of questions based on the number of temporal entities involved. For the Timeline Ito Game component of the benchmark, the table shows the sample counts for the easy, medium, and hard difficulty levels, as categorized by the number of agents involved and cross-temporal entity counts.
read the caption
Table 3: The statistics of CTM.
| Models | Full Name | Open Source? | Model Size |
| GPT-4o | gpt-4o-2024-08-06 | ✗ | - |
| Qwen-max | qwen-max | ✗ | - |
| o1-preview | o1-preview | ✗ | - |
| LLaMA3.1 | Meta-Llama-3.1-8B-Instruct | ✓ | 8B |
| ChatGLM3 | chatglm3-6b | ✓ | 6B |
| InternLM2.5 | internlm2_5-7b-chat | ✓ | 7B |
| Qwen2.5 | qwen2.5-7b-instruct | ✓ | 7B |
| Qwen2.5 | qwen2.5-14b-instruct | ✓ | 14B |
| Qwen2.5 | qwen2.5-32b-instruct | ✓ | 32B |
| Qwen2.5 | qwen2.5-14b-instruct | ✓ | 72B |
| DeepSeek-R1 | deepseek-r1 | ✓ | 671B |
🔼 This table lists the twelve large language models (LLMs) used in the experiments presented in the paper. It indicates whether each model is open-source or closed-source and provides the model size in billions of parameters.
read the caption
Table 4: LLMs evaluated in our experiments
| Method | Easy | Medium | Hard | Overall | ||||
| Pass@3 | Pass@8 | Pass@3 | Pass@8 | Pass@3 | Pass@8 | Pass@3 | Pass@8 | |
| GPT-4o | 55.00 | 80.00 | 20.00 | 30.00 | 5.00 | 10.00 | 26.67 | 40.00 |
| Qwen-max | 25.00 | 35.00 | 10.00 | 10.00 | 10.00 | 15.00 | 15.00 | 20.00 |
| LLaMA3.1 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| ChatGLM3 | 5.00 | 5.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.67 | 1.67 |
| InternLM2.5 | 5.00 | 15.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.67 | 5.00 |
| Qwen2.5 | 0.00 | 15.00 | 5.00 | 5.00 | 0.00 | 0.00 | 1.67 | 6.67 |
| Qwen2.5 | 15.00 | 20.00 | 0.00 | 0.00 | 0.00 | 0.00 | 5.00 | 6.67 |
| Qwen2.5 | 40.00 | 50.00 | 5.00 | 15.00 | 0.00 | 0.00 | 15.00 | 21.67 |
| Qwen2.5 | 40.00 | 55.00 | 10.00 | 10.00 | 0.00 | 5.00 | 16.67 | 23.33 |
🔼 This table presents the performance of various Large Language Models (LLMs) on the Timeline Ito Game, a task within the Chinese Time Reasoning (CTM) benchmark. It shows the accuracy (Pass@3 and Pass@8) of each LLM across different difficulty levels of the game, categorized by the number of entities involved (easy, medium, hard). Pass@K indicates whether the correct temporal ordering of entities was achieved within K attempts.
read the caption
Table 5: Main results on Timeline Ito Game within CTM benchmark.
| Method | Cross Temp Count | Question Type | Avg. | ||||||||||
| (EDD) | (LSEC) | PJ | TOU | RR | SEC | EEU | TIC | TES | |||||
| GPT-4o | 56.52 | 51.12 | 44.76 | 26.10 | 53.60 | 58.64 | 38.42 | 57.26 | 36.15 | 40.58 | 15.36 | 59.31 | 46.20 |
| + Openbook | 57.76+1.24 | 53.40+2.28 | 45.52+0.76 | 26.90+0.80 | 56.80+3.20 | 59.00+0.36 | 38.72+0.30 | 54.66-2.60 | 45.30+9.15 | 42.61+2.03 | 17.20+1.84 | 58.39-0.92 | 49.41+3.21 |
| Qwen2.5 | 51.80 | 39.88 | 35.96 | 12.40 | 30.00 | 46.28 | 26.38 | 46.28 | 24.14 | 36.23 | 7.35 | 52.01 | 38.76 |
| + Openbook | 48.64-3.16 | 39.92+0.04 | 31.88-4.08 | 17.90+5.50 | 31.60+1.60 | 47.63+1.35 | 27.89+1.51 | 42.15-4.13 | 26.04+1.90 | 31.88-4.35 | 5.84-1.51 | 44.53-7.48 | 37.39-1.37 |
| Qwen2.5 | 54.36 | 51.16 | 42.56 | 23.80 | 42.00 | 57.44 | 36.86 | 51.83 | 36.90 | 39.07 | 18.26 | 58.58 | 46.32 |
| + Openbook | 54.32-0.04 | 51.28+0.12 | 41.76-0.80 | 23.60-0.20 | 44.40+2.40 | 58.82+1.38 | 36.48-0.38 | 51.83+0.00 | 39.95+3.05 | 39.71+0.64 | 13.86-4.40 | 52.92-5.66 | 46.14-0.18 |
| Qwen2.5 | 56.28 | 52.78 | 46.24 | 26.90 | 46.40 | 60.66 | 38.54 | 56.79 | 39.12 | 43.77 | 20.10 | 60.04 | 48.83 |
| + Openbook | 57.92+1.64 | 53.32+0.54 | 46.16-0.08 | 26.80-0.10 | 50.80+4.40 | 61.15+0.49 | 39.93+1.39 | 55.61-1.18 | 40.67+1.55 | 45.22+1.45 | 16.86-3.24 | 58.21-1.83 | 49.51+0.68 |
| Qwen2.5 | 58.20 | 48.76 | 46.84 | 31.30 | 60.80 | 61.38 | 40.77 | 54.31 | 36.62 | 42.03 | 11.52 | 62.23 | 49.30 |
| + Openbook | 57.96-0.24 | 52.00+3.24 | 48.04+1.20 | 30.60-0.70 | 63.60+2.80 | 62.67+1.29 | 42.86+2.09 | 54.07-0.24 | 41.26+4.64 | 44.64+2.61 | 18.03+6.51 | 56.75-5.48 | 50.51+1.21 |
🔼 This table presents a detailed breakdown of the performance of various Large Language Models (LLMs) on the Chinese Time Reasoning (CTM) benchmark, specifically focusing on the results obtained under the ‘open-book’ setting. The open-book setting allows the LLMs to access external knowledge resources during the evaluation, potentially improving their performance on temporal reasoning tasks. The table shows the accuracy of each model across different question types within the CTM benchmark. Each question type assesses different aspects of temporal understanding. The ‘Cross Temp Count’ column likely refers to the number of temporal entities involved in the question, and an ‘Avg.’ column probably reflects an average accuracy across all question types for each model.
read the caption
Table 6: Detailed results under the open-book setting.
Full paper#