TL;DR#
Reinforcement Learning from Human Feedback (RLHF) is vital for aligning large language models (LLMs) with human preferences. However, traditional RLHF methods using Proximal Policy Optimization (PPO) suffer from high computational complexity and training instability. This is due to the joint training of an actor and critic, as well as the lack of access to ground-truth rewards in LLM tasks. Existing methods like Direct Preference Optimization (DPO) lack the iterative refinement of RL and struggles with distribution shifts.
To solve this, the paper introduces Decoupled Value Policy Optimization (DVPO), a lean framework that replaces traditional reward modeling with a pretrained global value model (GVM). The GVM is conditioned on policy trajectories and predicts token-level return-to-go estimates. DVPO eliminates actor-critic interdependence. Experiments show that DVPO achieves performance comparable to existing RLHF approaches while improving memory usage and training time.
Key Takeaways#
Why does it matter?#
This paper is important for researchers interested in efficient LLM alignment. DVPO’s decoupled approach reduces computational costs and improves training stability. It offers a practical alternative to existing RLHF methods and opens new avenues for exploring decoupled optimization techniques in LLMs.
Visual Insights#

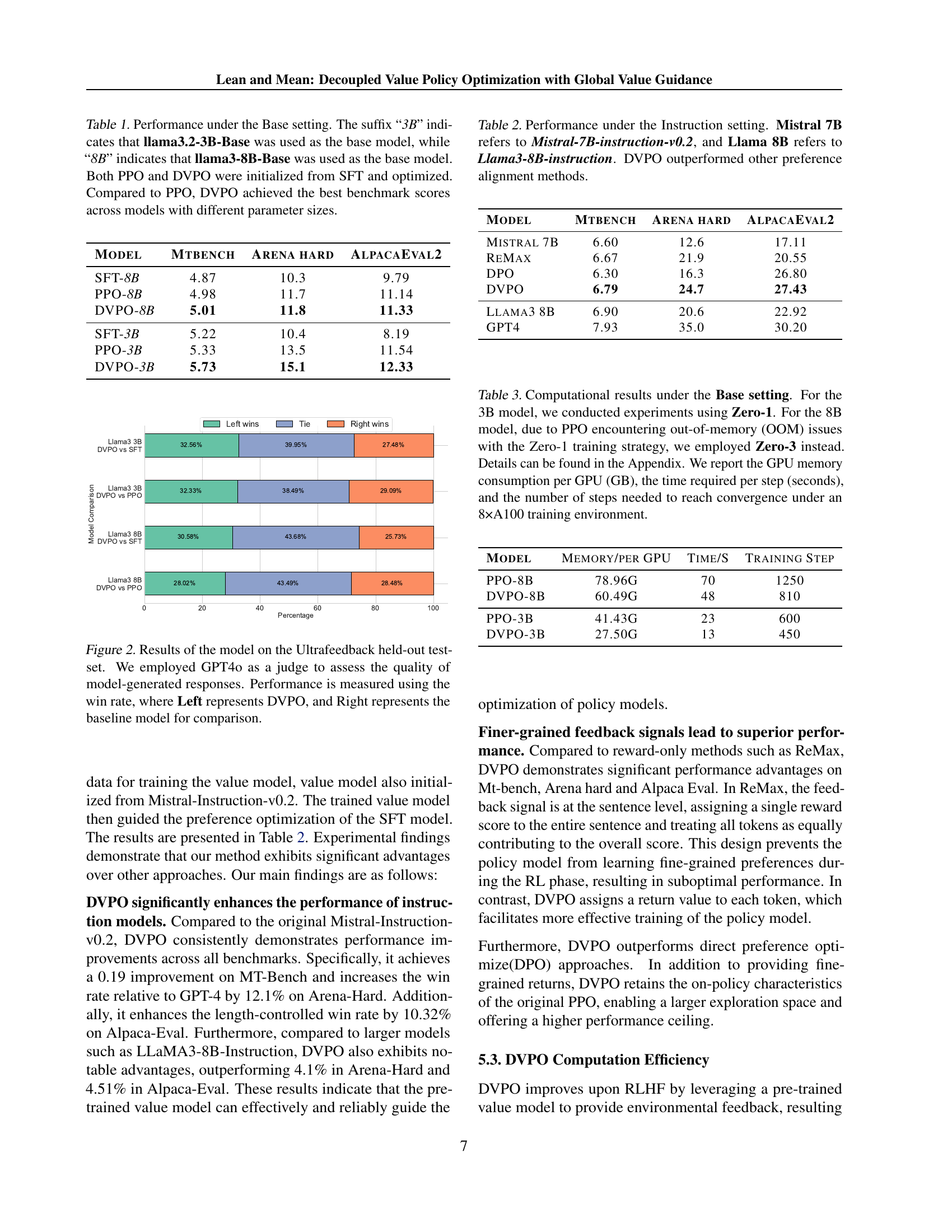
🔼 This figure compares the architectures of Decoupled Value Policy Optimization (DVPO) and Proximal Policy Optimization (PPO) in the context of Reinforcement Learning from Human Feedback (RLHF). It highlights that DVPO replaces the need for a separate reward model with a pre-trained global value model, decoupling the policy and value learning phases. In contrast, PPO requires joint training of both a policy and a value function, guided by a separately trained reward model. Both methods utilize offline data, but DVPO doesn’t require any additional ground truth reward signals during policy optimization.
read the caption
Figure 1: Overview of Decoupled Value Policy Optimization (DVPO) and PPO in RLHF. DVPO eliminates the need for a reward model and decouples policy and value learning during policy optimization. In contrast, PPO requires training a reward model before policy optimization. DVPO instead trains a global value model using the same offline data as the reward model. During policy training, no additional ground-truth rewards are obtained.
| Model | Mtbench | Arena hard | AlpacaEval2 |
|---|---|---|---|
| SFT-8B | 4.87 | 10.3 | 9.79 |
| PPO-8B | 4.98 | 11.7 | 11.14 |
| DVPO-8B | 5.01 | 11.8 | 11.33 |
| SFT-3B | 5.22 | 10.4 | 8.19 |
| PPO-3B | 5.33 | 13.5 | 11.54 |
| DVPO-3B | 5.73 | 15.1 | 12.33 |
🔼 This table presents a comparison of the performance of different models on three benchmark tasks (MT-Bench, Arena-Hard, and AlpacaEval) under the Base setting. The Base setting involves using the Ultrafeedback dataset and starting from an SFT (Supervised Fine-Tuning) model. Two different base models were used: llama3.2-3B-Base (indicated by ‘3B’) and llama3-8B-Base (indicated by ‘8B’). For each base model, three models are evaluated: the original SFT model, a model optimized with PPO (Proximal Policy Optimization), and a model optimized with DVPO (Decoupled Value Policy Optimization). The table shows that DVPO consistently outperforms both SFT and PPO across all benchmarks and model sizes, demonstrating its effectiveness in improving model performance.
read the caption
Table 1: Performance under the Base setting. The suffix “3B” indicates that llama3.2-3B-Base was used as the base model, while “8B” indicates that llama3-8B-Base was used as the base model. Both PPO and DVPO were initialized from SFT and optimized. Compared to PPO, DVPO achieved the best benchmark scores across models with different parameter sizes.
In-depth insights#
Lean Value RL#
Lean Value Reinforcement Learning (LVRL) likely refers to a paradigm shift in RL, prioritizing computational efficiency and stability without sacrificing performance. This likely involves reducing model complexity, perhaps by decoupling actor-critic architectures or simplifying reward structures. LVRL could focus on pre-training value functions to minimize online learning, enabling faster convergence. The core idea of LVRL is to achieve state-of-the-art performance using significantly fewer resources, this approach is critical for real-world applications where computational constraints are prevalent. This approach may use knowledge distillation or model compression techniques to create smaller value functions that can be easily deployed. Emphasis on interpretability is another key aspect, making the model transparent and debuggable.
Decoupled DVPO#
Decoupled DVPO proposes an innovative approach to reinforcement learning from human feedback (RLHF), addressing key limitations of traditional methods. By pre-training a global value model (GVM) separate from the policy optimization, DVPO breaks the tight loop of actor-critic training, leading to increased stability and reduced computational cost. The GVM, conditioned on policy trajectories, provides token-level return-to-go estimates, offering fine-grained guidance during policy updates. Unlike methods requiring joint training, DVPO fixes the GVM, promoting stability and enabling efficient offline use of data. This design choice mitigates the “moving target” problem in actor-critic methods, leading to more predictable policy improvements. DVPO is especially advantageous in offline RLHF scenarios, where additional environmental rewards cannot be collected. By decoupling, DVPO maintains fine-grained supervision while substantially lowering training complexity and resource consumption, offering a promising avenue for scalable and stable RLHF.
Fixed GVM Guide#
Fixed GVM guide maintains stability in policy updates by freezing the Global Value Model (GVM), eliminating the ‘moving target’ problem of actor-critic methods. This leads to more stable and predictable policy updates. It also enables efficient offline use, as the static GVM provides all necessary supervisory information, facilitating the reuse of offline datasets for policy optimization. Freezing the GVM after pre-training ensures that the policy optimization process relies on a stable and consistent value function, thereby reducing instability and improving convergence.
No New Rewards#
The absence of fresh environment rewards during policy training is a crucial constraint in offline RLHF. Because neither the reward model nor the global value model (GVM) can be updated with new data reflecting policy changes, they essentially act as static supervisors. This limitation implies that any improvements achieved stem solely from effectively utilizing the existing offline dataset. The proof emphasizes that, under these conditions, the choice between using a reward model or a GVM for guidance becomes a matter of approximation accuracy within the offline data distribution. As approximation errors diminish, the policy gradients derived from either model converge, leading to equivalent optimization outcomes. This equivalence highlights the importance of thorough pre-training of either model to capture the nuances of the desired behavior from the fixed dataset, as no further refinement based on interaction is possible.
Better Feedback#
While not explicitly present, the concept of ‘better feedback’ is intrinsically linked to the research. The transition from traditional RLHF, reliant on a fixed reward model, to DVPO, which employs a pretrained global value model (GVM), embodies the pursuit of enhanced feedback mechanisms. The GVM, conditioned on policy trajectories, generates token-level return-to-go estimates, offering a more granular and nuanced assessment compared to the coarse, sentence-level rewards often used. This finer-grained feedback empowers the policy to learn more effectively, enabling the model to discern subtle preferences and adapt its behavior accordingly. The paper’s focus on improving training efficiency, stability, and convergence speed indirectly aims at better feedback loops. A more stable and efficient training process allows for more rapid iteration and refinement, leading to improved alignment with human preferences. Furthermore, the equivalence between pretraining a reward model and a GVM suggests that the key to better feedback lies in capturing comprehensive information from offline data. The GVM approach represents a shift towards leveraging richer, more informative signals to guide policy optimization, ultimately resulting in models that are better aligned with human values and preferences.
More visual insights#
More on tables
| Model | Mtbench | Arena hard | AlpacaEval2 |
|---|---|---|---|
| Mistral 7B | 6.60 | 12.6 | 17.11 |
| ReMax | 6.67 | 21.9 | 20.55 |
| DPO | 6.30 | 16.3 | 26.80 |
| DVPO | 6.79 | 24.7 | 27.43 |
| Llama3 8B | 6.90 | 20.6 | 22.92 |
| GPT4 | 7.93 | 35.0 | 30.20 |
🔼 This table presents the performance comparison of different preference alignment methods on two language models: Mistral-7B-instruction-v0.2 and Llama3-8B-instruction. The metrics used for comparison are the scores obtained from three different benchmarks: MT-Bench, Arena-Hard, and AlpacaEval. The table shows that the Decoupled Value Policy Optimization (DVPO) method outperforms other methods (ReMax and DPO) across all three benchmarks and both language models.
read the caption
Table 2: Performance under the Instruction setting. Mistral 7B refers to Mistral-7B-instruction-v0.2, and Llama 8B refers to Llama3-8B-instruction. DVPO outperformed other preference alignment methods.
| Model | Memory/per GPU | Time/S | Training Step |
|---|---|---|---|
| PPO-8B | 78.96G | 70 | 1250 |
| DVPO-8B | 60.49G | 48 | 810 |
| PPO-3B | 41.43G | 23 | 600 |
| DVPO-3B | 27.50G | 13 | 450 |
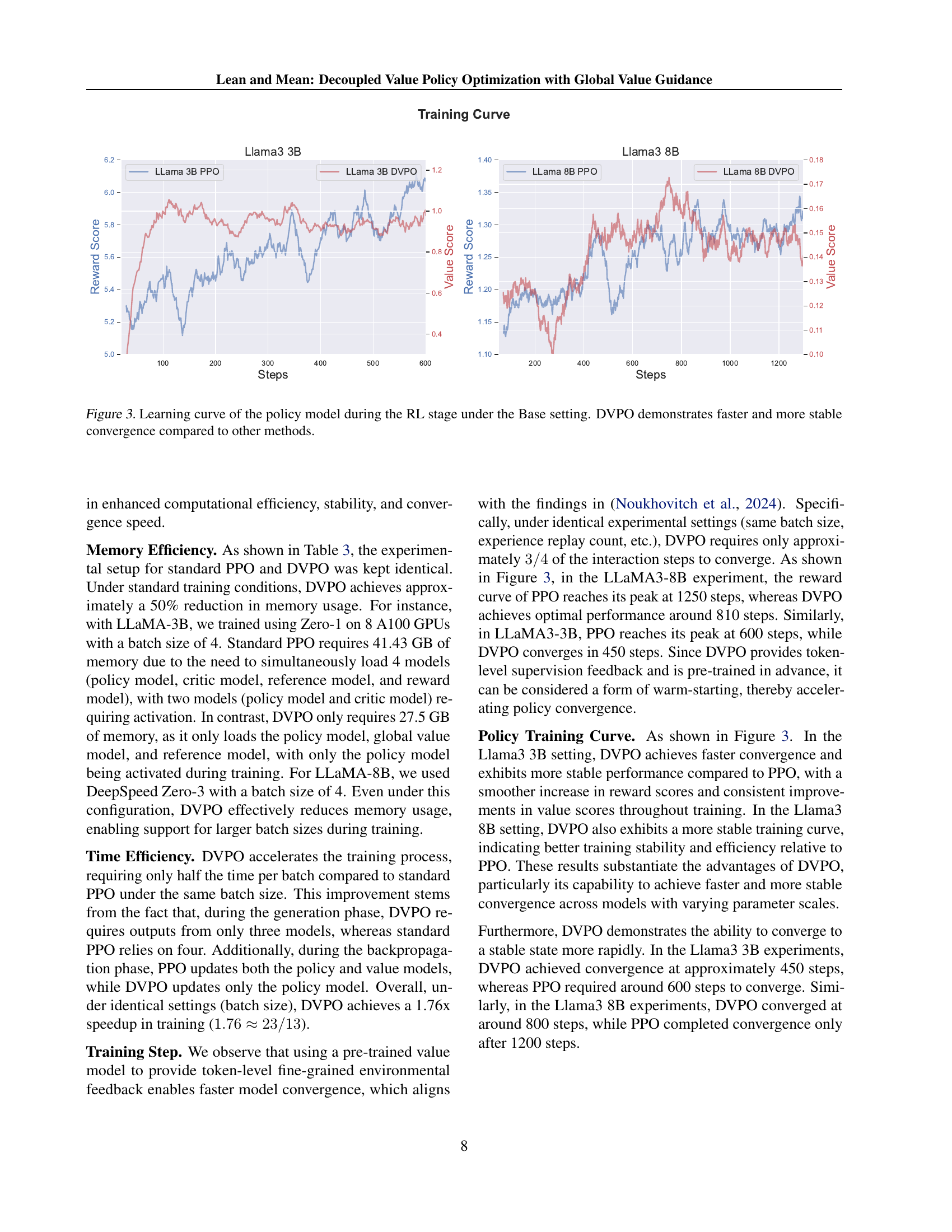
🔼 This table presents a comparison of computational resources and training efficiency for different models under the Base setting. The ‘Base setting’ refers to a specific experimental setup detailed in the paper. Two model sizes are considered: 3B and 8B parameters. Due to memory limitations with the larger model and the chosen optimization technique (PPO), different DeepSpeed optimization strategies (Zero-1 and Zero-3) were employed. The table provides key metrics: GPU memory usage per GPU (in gigabytes), the time taken per training step (in seconds), and the total number of steps needed to achieve convergence. This data allows for comparison of training efficiency and resource requirements between the different models and optimization strategies.
read the caption
Table 3: Computational results under the Base setting. For the 3B model, we conducted experiments using Zero-1. For the 8B model, due to PPO encountering out-of-memory (OOM) issues with the Zero-1 training strategy, we employed Zero-3 instead. Details can be found in the Appendix. We report the GPU memory consumption per GPU (GB), the time required per step (seconds), and the number of steps needed to reach convergence under an 8×A100 training environment.
| Metric | Accuracy |
|---|---|
| Mean Value | 64.51 |
| P1 Value | 56.02 |
| P5 Value | 58.46 |
| P10 Value | 59.83 |
| P90 Value | 61.47 |
| P95 Value | 60.30 |
| P99 Value | 59.94 |
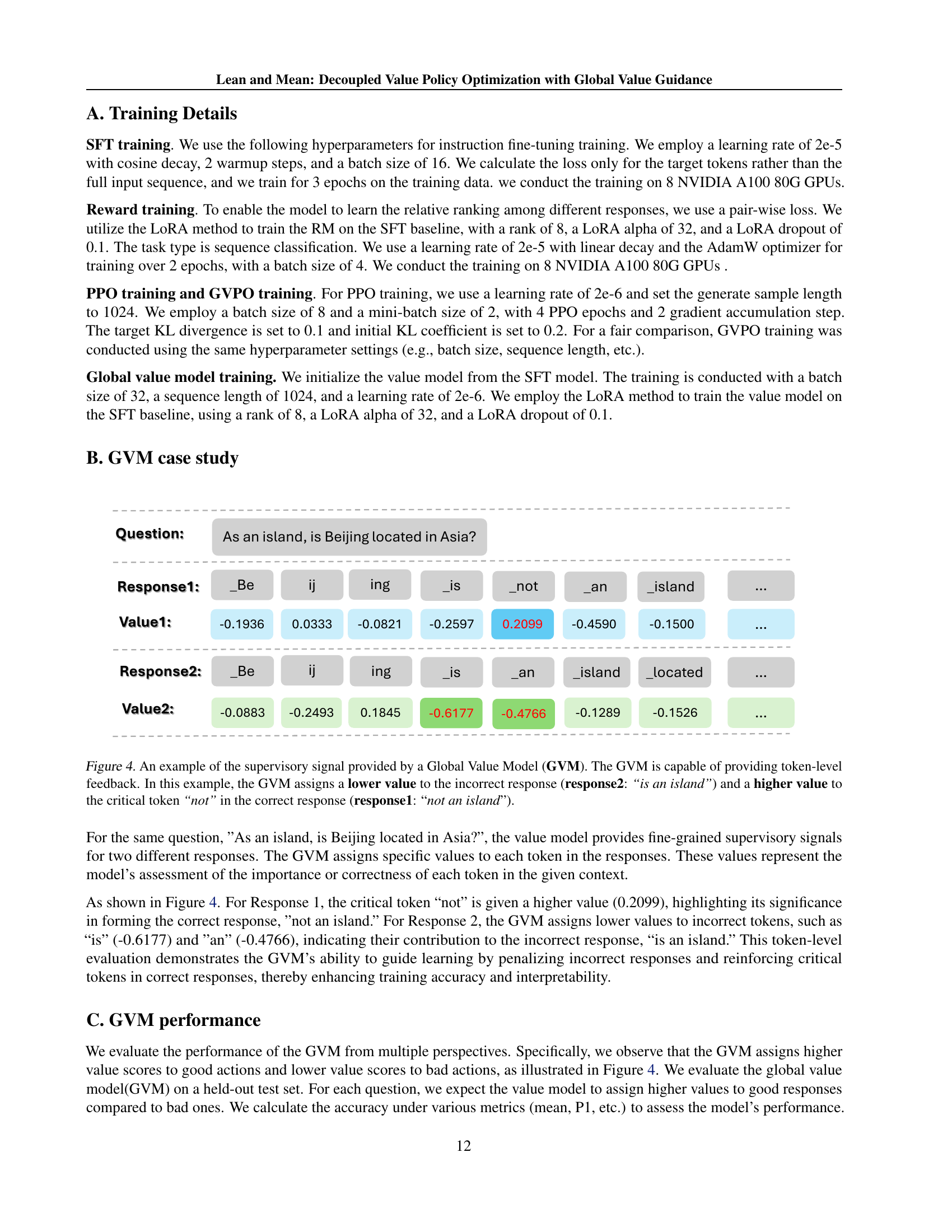
🔼 This table presents a detailed performance evaluation of the Global Value Model (GVM), which is a crucial component of the proposed Decoupled Value Policy Optimization (DVPO) framework. The GVM, initialized using the Mistral-7B-instruction-v0.2 model, plays a key role in providing token-level value estimations to guide the policy optimization process. The table displays key metrics that quantify the GVM’s ability to discriminate between good and bad responses at the token level. These metrics include the average predicted value (mean), various percentile values (P1, P5, P10, P90, P95, P99) to illustrate the distribution of the predicted values, and the overall accuracy. The accuracy metric specifically measures the percentage of instances where the GVM assigns a higher value to a good response compared to a bad response. This comprehensive evaluation helps assess the effectiveness and reliability of the GVM in providing informative and consistent feedback for policy training.
read the caption
Table 4: The performance of the GVM initialized from Mistral-7B-instruction-v0.2. Here, mean represents the average value of the predictions, P1 indicates the 1st percentile value, and accuracy reflects the proportion of cases where the value for a good response exceeds the value for a bad response, which is considered as correct feedback from the global value model.
| Input | Compare and contrast Harry Potter with Percy Jackson series. |
|---|---|
| Llama3 8B SFT | Sure, I’d be happy to help you compare and contrast the Harry Potter and Percy Jackson series!Both Harry Potter and Percy Jackson are popular fantasy series that have captured the hearts of readers around the world. Here are some key similarities and differences between the two:Similarities:1. Magical elements: Both series feature a magical aspect, with Hogwarts School of Witchcraft and Wizardry being the setting for Harry Potter and Camp Half-Blood for Percy Jackson.2. Mythological references: Both series draw heavily on Greek mythology, with Percy Jackson’s stories being based on the Labors of Hercules and other Greek myths.3. Relatable protagonists: Both Harry and Percy are relatable and charming protagonists that readers can connect with.Differences:1. Setting: While both series take place in magical worlds, the settings are quite different. Harry Potter’s stories take place in a more traditional school setting, while Percy Jackson’s stories take place in a summer camp atmosphere.2. Tone: Harry Potter is a more lighthearted and comedic series, while Percy Jackson takes a darker and more serious tone, exploring themes of mortality and responsibility.3. Plot structure: Harry Potter has a more linear plot structure, with each book building on the previous one’s events. Percy Jackson, on the other hand, has a more episodic structure, with each book focusing on a different adventure or challenge for the characters.4. Themes: While both series explore themes of good and evil, Harry Potter focuses more on the importance of friendship and loyalty, while Percy Jackson delves into the consequences of power and responsibility.In conclusion, while both Harry Potter and Percy Jackson share many similarities, their differences in setting, tone, plot structure, and themes offer unique reading experiences for readers. Both series are highly recommended for anyone looking for a magical and engaging read! |
| \hdashlineGPT4-as-Judge | Score: 3 Evaluation evidence: The response provides a relevant comparison of the Harry Potter and Percy Jackson series, highlighting key similarities and differences in magical elements, settings, tone, plot structure, and themes. It addresses the user’s question by outlining basic elements and offering a useful comparison. However, the answer contains inaccuracies, such as misrepresenting the tone of both series and the nature of mythological references in Percy Jackson. Additionally, the response could be more precise and direct, as some points are not entirely accurate or comprehensive. Thus, it meets the criteria for a basic, useful response but lacks thoroughness and precision for a higher score. |
🔼 This table presents a case study illustrating how GPT-4 evaluates model outputs. It shows example inputs (a question and a response generated by the LLaMA3 8B SFT model), the GPT-4’s evaluation score (out of 5), and its justification. The example highlights GPT-4’s assessment of factors like relevance, completeness, clarity, accuracy, and the overall quality of the response.
read the caption
Table 5: A case study for GPT4 evaluation: LLama3 8B SFT
| Input | Compare and contrast Harry Potter with Percy Jackson series. |
|---|---|
| Llama3 8B PPO | Sure, I’d be happy to help you compare and contrast the Harry Potter and Percy Jackson series!Both Harry Potter and Percy Jackson are popular fantasy series that have captured the hearts of readers around the world. Here are some key similarities and differences between the two:Similarities:1. Magical elements: Both series feature a magical aspect, with Hogwarts School of Witchcraft and Wizardry being the setting for Harry Potter and Camp Half-Blood being the setting for Percy Jackson.2. Teenage protagonists: The main characters in both series are teenagers, navigating their way through adolescence while also facing epic challenges and learning valuable life lessons.3. Epic adventures: Both series involve the protagonists on thrilling quests, battling mythical creatures, and uncovering secrets that could change the course of history.4. Portal to another world: In both series, there is a gateway to another world (Harry’s cupboard under the stairs and the portal at Camp Half-Blood) that allows the protagonists access to a realm filled with magical creatures and unparalleled adventure.Differences:1. Setting: While both series take place in magical worlds, the settings are quite different. Harry Potter is set in a medieval-style world with castles and magical creatures, while Percy Jackson is set in a modern-day world with technology and urban landscapes.2. Tone: The tone of the two series is quite different. Harry Potter is lighthearted and comedic, while Percy Jackson is darker and more serious, with themes of mortality and morality.3. Mythological references: While both series draw on mythological references, the specific myths and legends used are different. Harry Potter relies more on European and British myths, while Percy Jackson draws on Greek and Roman mythology.4. Magic systems: The magic systems in the two series are also different. Harry Potter uses a spell-based magic system, while Percy Jackson uses a more physical, athletic approach to magic.5. Protagonists: The protagonists in the two series are quite different. Harry Potter is a boy wizard who discovers his true identity and heritage, while Percy Jackson is a demigod who must navigate the complexities of his divine heritage and mortal life.6. Plots: The plots of the two series are distinct. Harry Potter focuses on the battle between good and evil, with Harry as the prophesized hero who must face off against Voldemort. Percy Jackson, on the other hand, is about the struggles of the demigods and the impact of their mortal lives on their divine heritage.In conclusion, both Harry Potter and Percy Jackson are captivating fantasy series that share some similarities, but also differ in many ways. While both offer engaging and entertaining reads, they appeal to different audiences and perspectives. |
| \hdashlineGPT4-as-Judge | Score: 3 Evaluation evidence: The response provides a relevant comparison of the Harry Potter and Percy Jackson series, addressing the user’s question with a mix of similarities and differences. It covers key aspects such as magical elements, protagonists, and settings, offering a basic understanding of both series. However, the response contains inaccuracies, particularly in tone descriptions and settings, which detracts from its comprehensiveness and accuracy. While it offers a useful comparison, it does not fully address the user’s question with the depth or precision expected from an AI Assistant, nor does it reflect expert knowledge or exceptional insight. |
🔼 This table presents a case study illustrating the GPT-4 evaluation process for a Llama 3 8B model fine-tuned using Proximal Policy Optimization (PPO). It shows a user prompt, the model’s response, and the GPT-4’s evaluation of that response, including a score and justification. This example highlights how the GPT-4 judge assesses the model’s output based on relevance, completeness, and writing quality.
read the caption
Table 6: A case study for GPT4 evaluation: LLama3 8B PPO
| Input | Compare and contrast Harry Potter with Percy Jackson series. |
|---|---|
| Llama3 8B DVPO | Sure, I’d be happy to help! Both the Harry Potter and Percy Jackson series are popular and successful book series that have captivated readers worldwide. Here are some key similarities and differences between the two:Similarities:1. Magical elements: Both series feature magical aspects, such as spells, wizards, and fantastical creatures.2. Young protagonists: The main characters in both series are young and face challenges and adventures that come with growing up in a magical world.3. Family themes: Both series emphasize the importance of family and the bonds between family members.4. Friendship: The series also highlight the importance of friendship and the power of having loyal and supportive friends.Differences:1. Genre: While both series can be classified as fantasy, Harry Potter is more traditionally fantasy-oriented, while Percy Jackson is urban fantasy with a contemporary setting.2. Setting: Harry Potter is set in a parallel universe where wizardry and magic are prevalent, while Percy Jackson is set in present-day America and Greece.3. Magic system: The magic systems in each series are different. In Harry Potter, magic is cast using wands and spells, while in Percy Jackson, magic is accessed through the use of magical coins and enchanted items.4. Gods and myths: Harry Potter is based on the idea of witches and wizards living among us, while Percy Jackson is based on Greek mythology and features the gods and goddesses of ancient Greece.5. Tone: Harry Potter is written in a more traditional, epic style, while Percy Jackson is written in a more contemporary, humorous tone.Ultimately, both series offer engaging, imaginative storytelling that captures the hearts and minds of readers. While they both explore similar themes, their unique settings, magic systems, and tones make them distinct from one another. I hope this helps! Let me know if you have any other questions. |
| \hdashlineGPT4-as-Judge | Score: 5 Evaluation evidence: The response thoroughly addresses the user’s question by comparing and contrasting the Harry Potter and Percy Jackson series. It identifies key similarities, such as magical elements, young protagonists, and themes of family and friendship. The response also effectively highlights differences in genre, setting, magic systems, mythological influences, and tone. The information is well-organized, relevant, and engaging, demonstrating a comprehensive understanding of both series. The response is tailored specifically to the user’s inquiry, providing insightful and expert knowledge without any extraneous information. |
🔼 This table presents a case study illustrating how GPT-4 evaluates responses generated by the Llama 3 8B model using the DVPO method. It shows example questions, the model’s responses, and GPT-4’s scoring and evaluation of the responses based on specific criteria. This example is used to demonstrate the quality of responses generated by DVPO compared to other methods.
read the caption
Table 7: A case study for GPT4 evaluation: LLama3 8B DVPO
Full paper#