TL;DR#
Low-bit training is a key area for efficient Large Language Models (LLMs), yet it suffers from unstable gradient norms and high sensitivity to learning rates, causing divergence. Existing optimizers like SPAM, while improving performance, still struggle with gradient stabilization, requiring careful tuning, especially in 4-bit training, limiting practical applications and widespread adoption.
This paper introduces Stable-SPAM, an optimizer that enhances gradient normalization and clipping. Stable-SPAM adaptively updates clipping thresholds, normalizes gradients based on historical statistics, and inherits momentum reset from SPAM. The experiments show the effectiveness of Stable-SPAM in stabilizing gradient norms, delivering superior performance, and reducing training steps in 4-bit LLM training.
Key Takeaways#
Why does it matter?#
This paper introduces Stable-SPAM, stabilizing 4-bit LLM training. It outperforms Adam and SPAM, reducing training steps and improving performance. It is crucial for researchers aiming for efficient, low-precision LLM training, opening avenues for exploration of stabilized optimization.
Visual Insights#

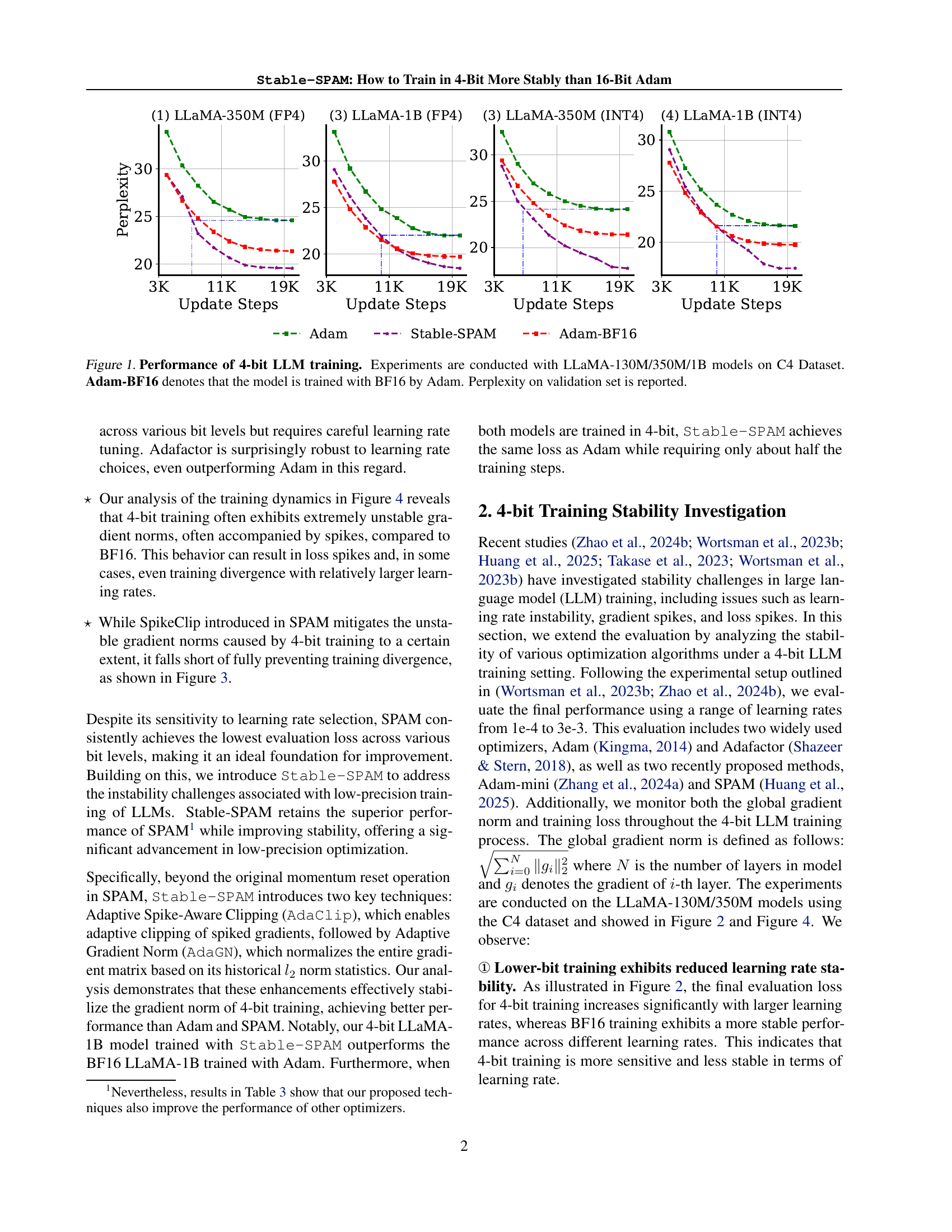
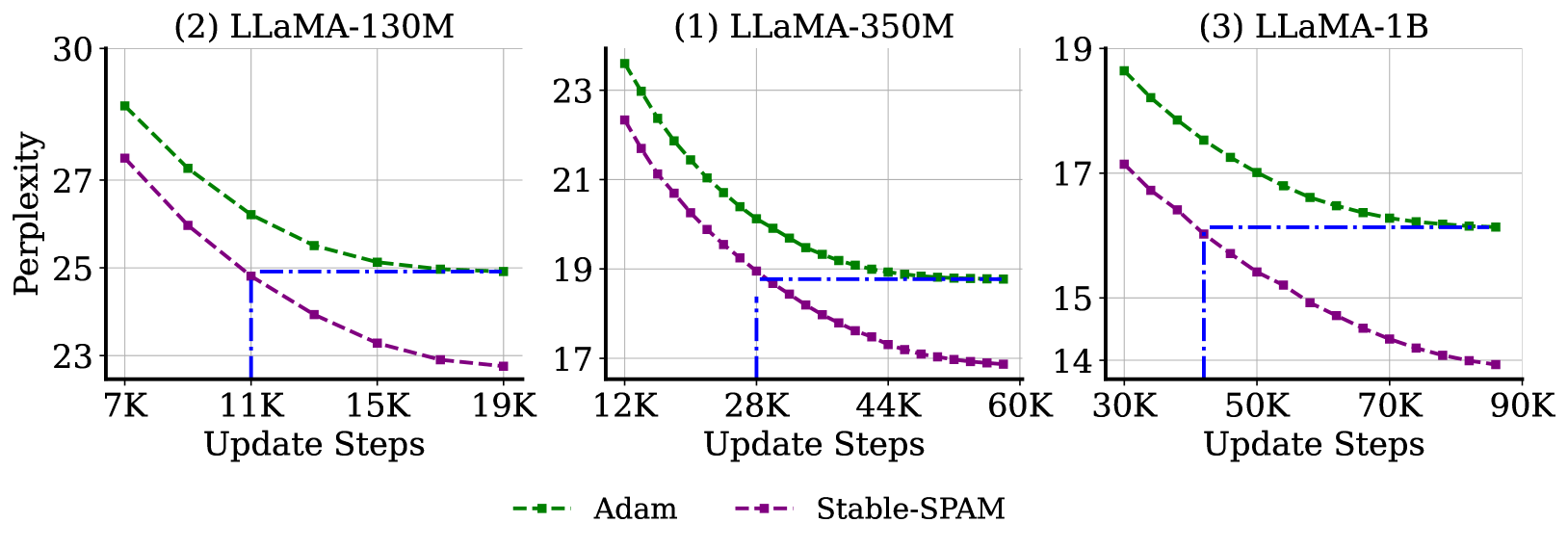
🔼 This figure displays the perplexity results of training 4-bit large language models (LLMs) using different optimizers. The experiments were conducted on three sizes of the LLaMA model (130M, 350M, and 1B parameters) using the C4 dataset. For comparison, results for training the same models with Adam using BF16 precision (16-bit) are also shown. Lower perplexity indicates better performance. The x-axis represents the number of training steps, and the y-axis shows perplexity.
read the caption
Figure 1: Performance of 4-bit LLM training. Experiments are conducted with LLaMA-130M/350M/1B models on C4 Dataset. Adam-BF16 denotes that the model is trained with BF16 by Adam. Perplexity on validation set is reported.
| INT4 Training | FP4 Training | |||||
|---|---|---|---|---|---|---|
| 130M | 350M | 1B | 130M | 350M | 1B | |
| Adam | 26.4 | 24.14 | 21.59 | 28.9 | 24.59 | 22.01 |
| Adam+GradClip | 26.30 | 21.64 | 19.74 | 28.27 | 20.84 | 20.25 |
| Adafactor | 25.11 | 20.45 | 20.65 | 26.89 | 20.53 | 20.03 |
| SPAM | 25.03 | 20.19 | 19.98 | 26.78 | 20.35 | 19.74 |
| Stable-SPAM | 24.33 | 17.76 | 17.42 | 26.31 | 19.49 | 18.48 |
| Adam (BF16) | 24.53 | 21.38 | 19.73 | 24.53 | 21.38 | 19.73 |
| Training Tokens | 2.2B | |||||
🔼 This table presents a comparison of the performance of different optimizers when training LLaMA language models using INT4 (4-bit integer) and FP4 (4-bit floating-point) precision. The models were trained on the C4 dataset, and the table shows the resulting evaluation loss (perplexity) for each optimizer and model size (130M, 350M, and 1B parameters). This allows for a direct comparison of optimizer effectiveness at low-bit precision training. The perplexity metric measures the model’s uncertainty in predicting the next word in a sequence.
read the caption
Table 1: Comparison of various optimizers of INT4 and FP4 training of LLaMA models on C4444. Perplexity is reported.
In-depth insights#
LLM 4-bit Training#
LLM 4-bit training presents a pathway to reducing computational and memory demands of large language models, making them more accessible. However, this introduces unique challenges. Quantization to 4-bit precision amplifies the sensitivity to learning rates, leading to unstable gradient norms. The paper identifies that gradient and loss spikes are more frequent. Existing optimizers, struggle to maintain stability in this environment. Addressing these issues requires careful calibration of hyperparameters and novel techniques. The goal is to retain the performance of higher-precision training while capitalizing on the efficiency gains of 4-bit quantization, such as reduced infrastructure costs and faster inference.
Stable SPAM model#
Stable SPAM focuses on addressing instability in low-precision training. Building upon the SPAM optimizer, it incorporates adaptive gradient normalization (AdaGN) and adaptive spike-aware clipping (AdaClip). AdaGN stabilizes gradients by adaptively scaling them based on historical 12-norm statistics, mitigating abrupt surges in gradient norms. AdaClip dynamically adjusts the clipping threshold for spiked gradients by tracking their historical maxima. Together, these techniques aim to stabilize training, particularly in 4-bit quantization settings, leading to improved performance and robustness compared to standard optimizers.
Gradient Stability#
Gradient stability is a crucial aspect of training deep learning models, especially Large Language Models (LLMs). Unstable gradients, characterized by spikes or vanishing norms, can lead to divergence or slow convergence. Low-precision training, like 4-bit quantization, exacerbates these issues by amplifying the sensitivity to learning rates and creating unstable gradient norms. Techniques like gradient clipping and normalization are used to mitigate these instabilities. Effective strategies involve adaptively adjusting clipping thresholds based on historical gradient data and normalizing the entire gradient matrix. Momentum reset can also help by mitigating the accumulation of spiked gradients, leading to more stable and consistent training.
Low-Precision LLM#
Low-precision LLM training is emerging as a pivotal approach for enhancing computational and memory efficiency, impacting deployment feasibility. FP16 and BF16 formats have been the standard, with a growing interest in 8-bit training via LM-FP8. Activation outliers pose representation challenges, especially in scaling beyond 250B tokens; smoothing and Hadamard transformations aim to mitigate this. Data format choice impacts performance; INT8 is widely supported, while NVIDIA’s Hopper GPUs specialize in FP8. MX format offers superior representation but lacks hardware support. Research focuses on training instability, proposing optimizer designs to stabilize low-precision training, thus improving its stability with complementary techniques.
Stabilizing LLMs#
Stabilizing Large Language Models (LLMs) is a pivotal area, given the inherent training instability that often plagues these models. The research paper addresses these concerns through innovative optimization techniques. The techniques are adaptive gradient normalization (AdaGN) and adaptive spike-aware clipping (AdaClip). These mechanisms are intended to smooth out the training process by mitigating the adverse effects of gradient explosions and loss spikes. These spikes are very detrimental to training LLMs. The paper underscores the significance of preprocessing gradients. The results demonstrate how judicious gradient management leads to more stable convergence and better overall model performance, ultimately contributing to the advancement and efficient training of very large language models.
More visual insights#
More on figures

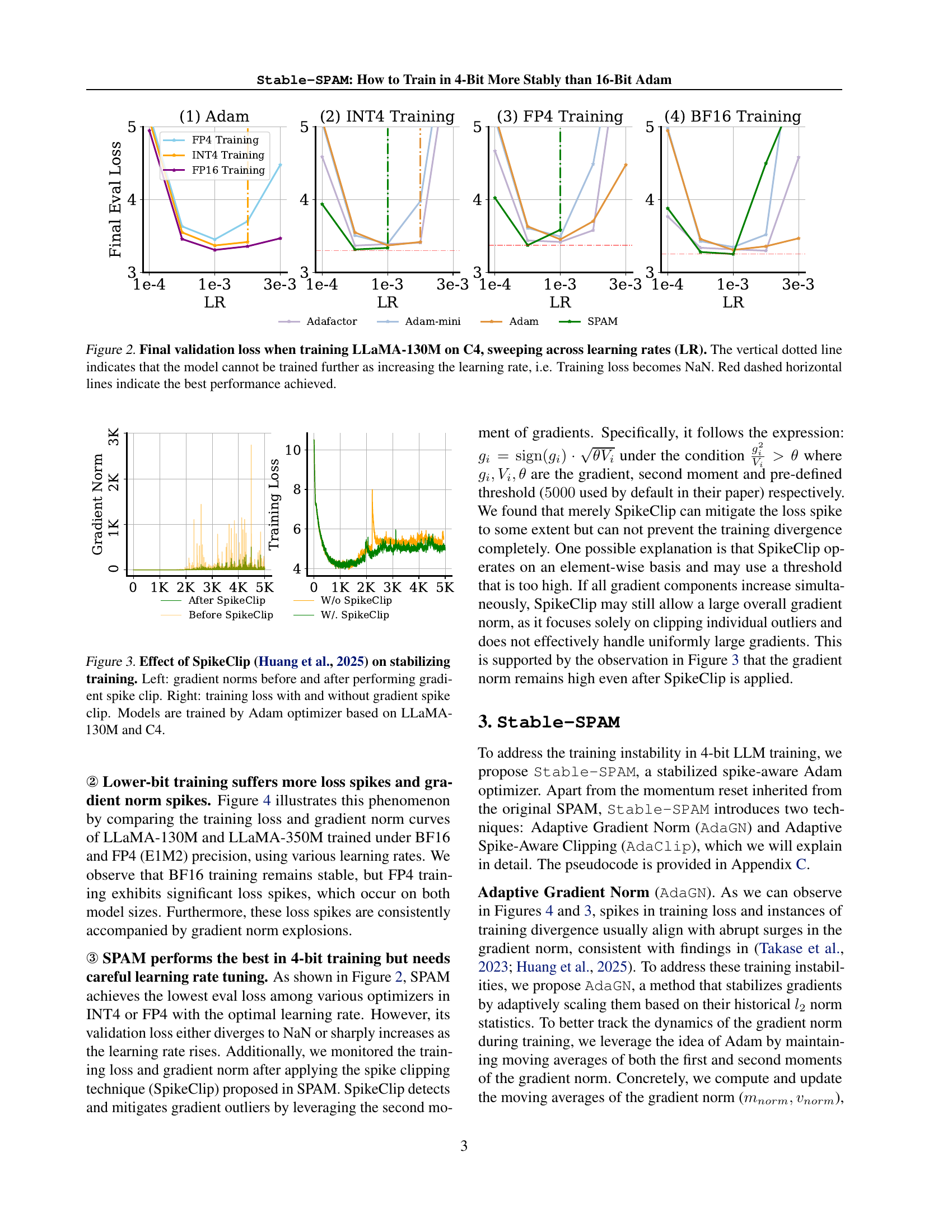
🔼 This figure displays the final validation loss achieved when training a LLaMA-130M language model on the C4 dataset using different learning rates. Each curve represents a different optimizer (Adam, Adafactor, Adam-mini, and SPAM). The x-axis shows the learning rate used, and the y-axis shows the final validation loss. The vertical dotted lines indicate points where a learning rate caused the training loss to become NaN (Not a Number), signifying that the model training failed to converge and could not continue with that specific hyperparameter. The red horizontal dashed lines highlight the lowest validation loss obtained by each optimizer during the experiment, representing the best performance attainable under various learning rates.
read the caption
Figure 2: Final validation loss when training LLaMA-130M on C4, sweeping across learning rates (LR). The vertical dotted line indicates that the model cannot be trained further as increasing the learning rate, i.e. Training loss becomes NaN. Red dashed horizontal lines indicate the best performance achieved.

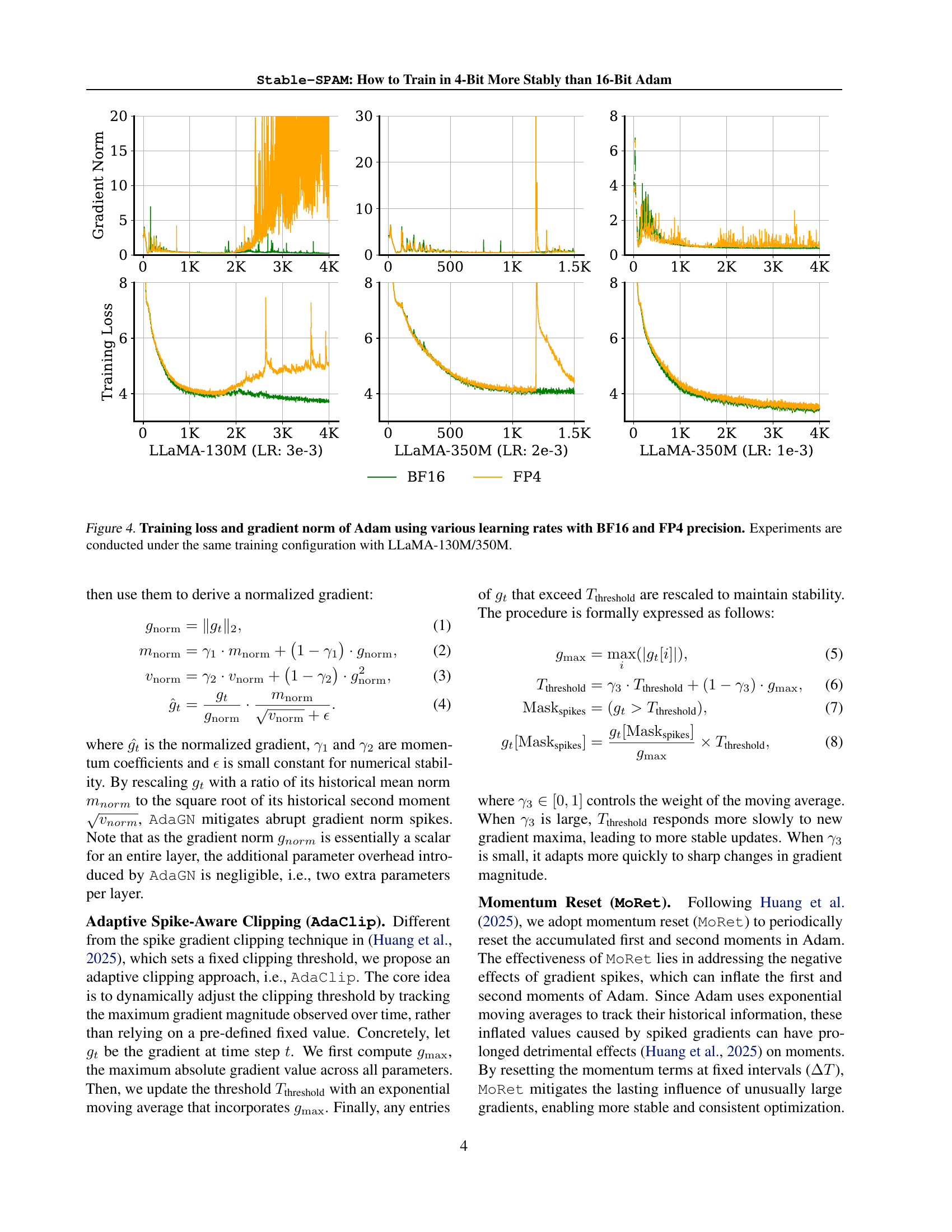
🔼 This figure demonstrates the impact of SpikeClip, a technique from the SPAM optimizer, on stabilizing the training process of a 4-bit LLM. The left panel displays gradient norms before and after applying SpikeClip, revealing its effectiveness in mitigating the abrupt increases or spikes in the gradients. The right panel shows the training loss curves with and without SpikeClip, further showcasing the stabilization effect, leading to a smoother training process.
read the caption
Figure 3: Effect of SpikeClip (Huang et al., 2025) on stabilizing training. Left: gradient norms before and after performing gradient spike clip. Right: training loss with and without gradient spike clip. Models are trained by Adam optimizer based on LLaMA-130M and C4.

🔼 This figure displays the training loss and gradient norm of the Adam optimizer under different learning rates, using both BF16 (16-bit floating-point) and FP4 (4-bit floating-point) precision. The experiments were performed using the LLaMA-130M and LLaMA-350M language models, maintaining consistent training configurations across all experiments. This visualization helps understand the impact of different precision levels and learning rates on the stability and performance of training large language models.
read the caption
Figure 4: Training loss and gradient norm of Adam using various learning rates with BF16 and FP4 precision. Experiments are conducted under the same training configuration with LLaMA-130M/350M.

🔼 This figure compares the performance of Stable-SPAM against Adam under extremely low-precision training settings (INT2, INT3, INT4). The experiments were conducted using 350M parameter LLaMA models trained on the C4 dataset. The chart shows the final validation loss achieved by each optimizer under various bit-width configurations. It demonstrates Stable-SPAM’s ability to maintain competitive performance, even surpassing the performance of Adam trained with BF16 (higher precision) in the INT3 setting. This highlights the robustness of Stable-SPAM in handling extremely low-precision training scenarios.
read the caption
Figure 5: StableSPAM under Extremely Low-Precision Training. Experiments are conducted with 350M models on C4 Dataset. BF16-Adam denotes that the model is trained with BF16 by Adam. The final loss on validation set is reported.
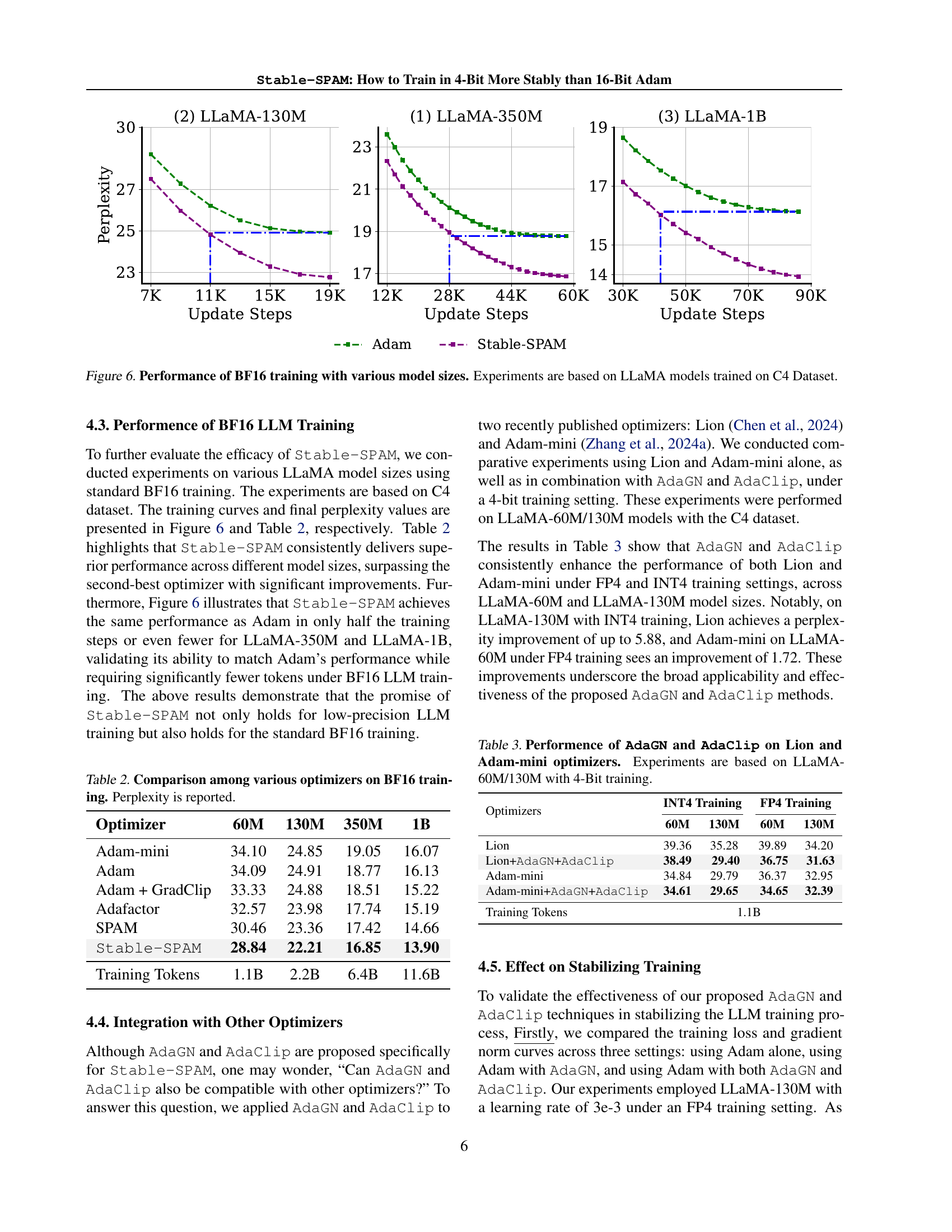
🔼 This figure displays the performance of training large language models (LLMs) using the BF16 (Brain Floating Point 16-bit) precision format. It compares the performance of different LLaMA model sizes (60M, 130M, 350M, and 1B parameters) trained on the C4 dataset. The x-axis represents the number of update steps during training, and the y-axis shows the perplexity, a measure of how well the model predicts the next word in a sequence. The different colored lines represent different optimizers used, allowing for a comparison of their effectiveness across various model sizes in the context of BF16 training.
read the caption
Figure 6: Performance of BF16 training with various model sizes. Experiments are based on LLaMA models trained on C4 Dataset.

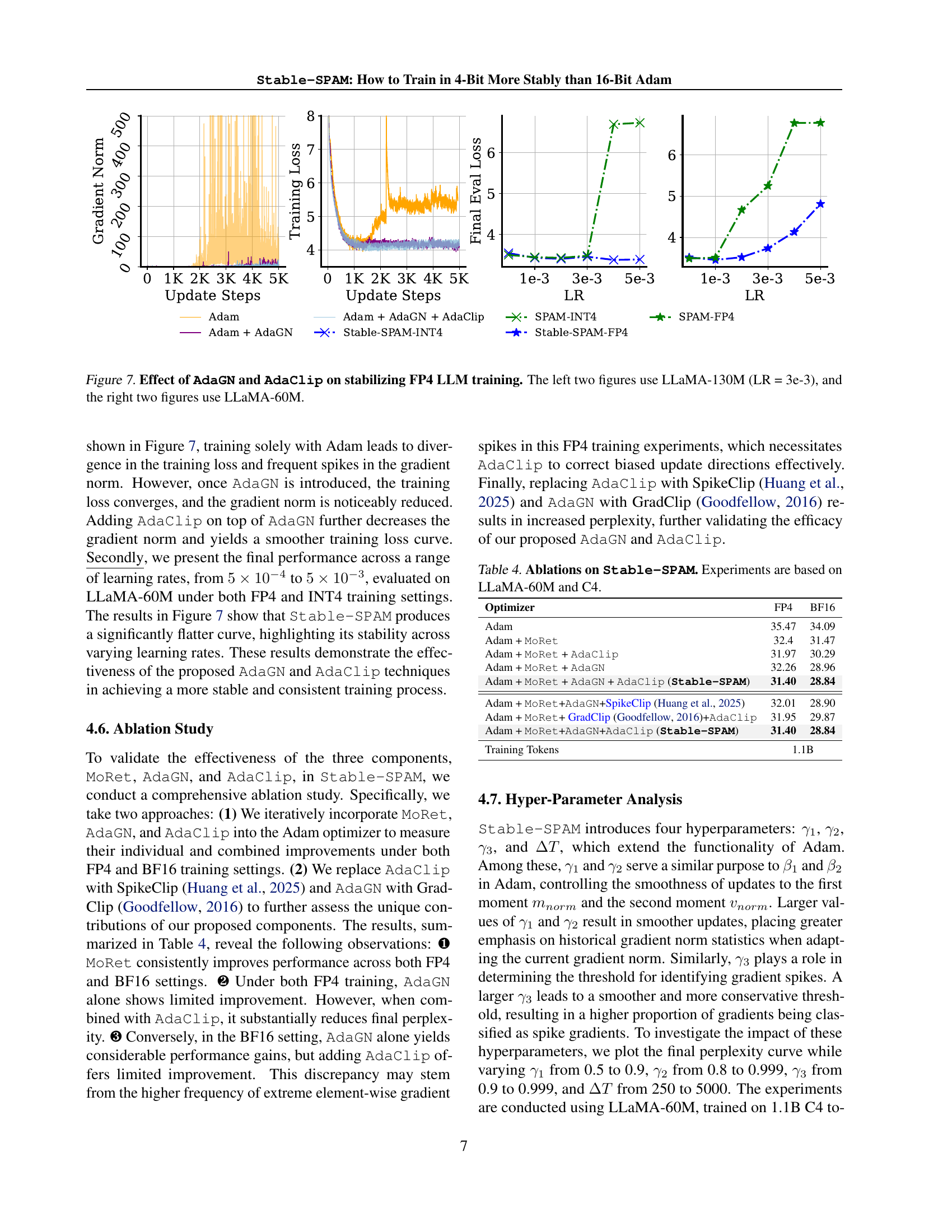
🔼 This figure shows the effects of AdaGN and AdaClip on the stability of 4-bit LLM training using the FP4 precision. The left two subfigures display the training loss and gradient norm for a LLaMA-130M model trained with a learning rate of 3e-3, comparing Adam alone, Adam with AdaGN, Adam with both AdaGN and AdaClip, and Stable-SPAM. The right two subfigures show the final evaluation loss for LLaMA-60M trained using various learning rates (1e-3, 3e-3, and 5e-3) with four different training methods: Adam, Adam + AdaGN, Adam + AdaGN + AdaClip and Stable-SPAM. It demonstrates how AdaGN and AdaClip work together to stabilize the training process, reducing loss spikes and gradient norm explosions.
read the caption
Figure 7: Effect of AdaGN and AdaClip on stabilizing FP4 LLM training. The left two figures use LLaMA-130M (LR = 3e-3), and the right two figures use LLaMA-60M.

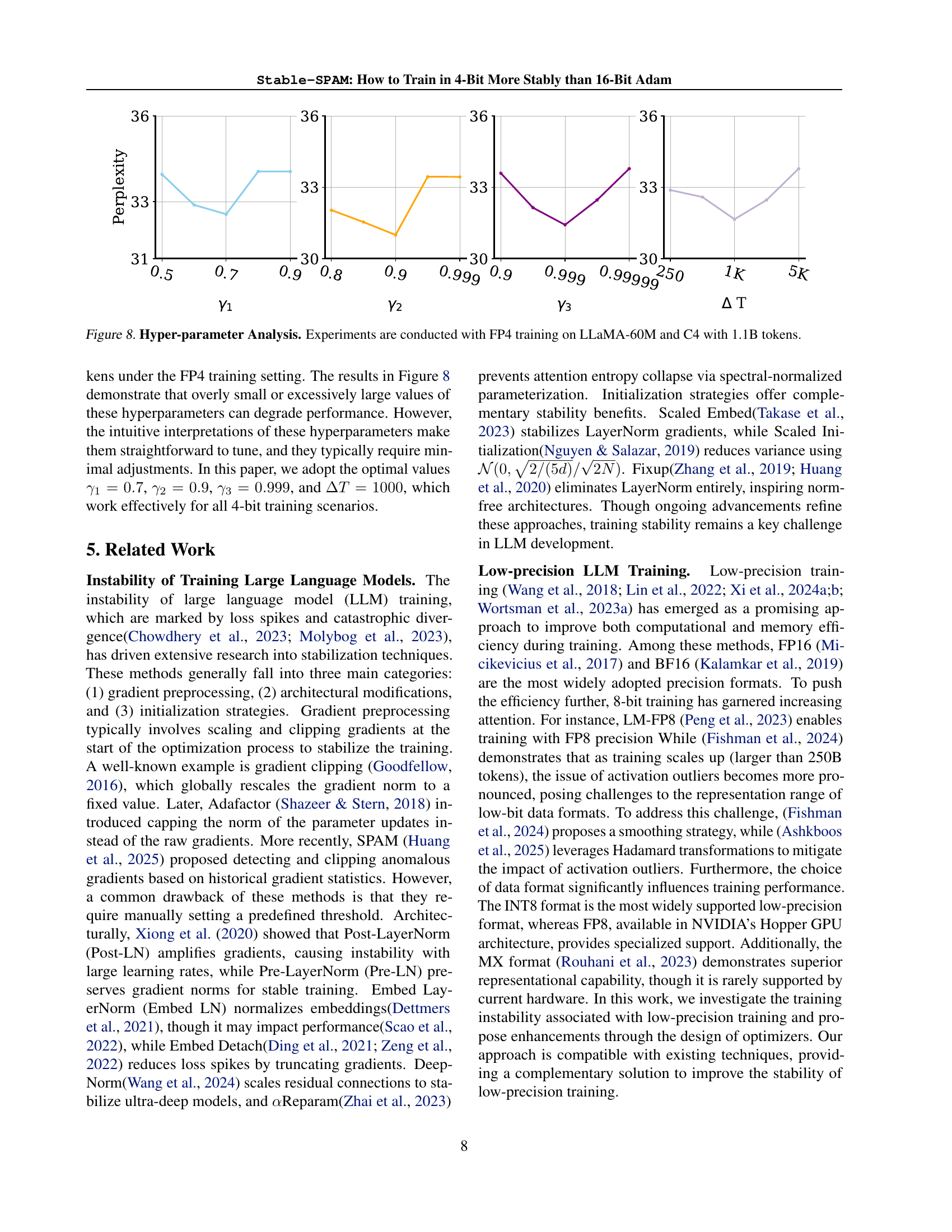
🔼 This figure shows the results of a hyperparameter analysis for Stable-SPAM optimizer. The experiments were performed using 4-bit (FP4) precision training on the LLaMA-60M model with the C4 dataset (1.1B tokens). The x-axis of each subplot represents different values for one of the four hyperparameters (γ1, γ2, γ3, ΔT), while the y-axis shows the resulting perplexity. This analysis aims to find the optimal values for these hyperparameters to achieve the best performance and stability in 4-bit training.
read the caption
Figure 8: Hyper-parameter Analysis. Experiments are conducted with FP4 training on LLaMA-60M and C4 with 1.1B tokens.
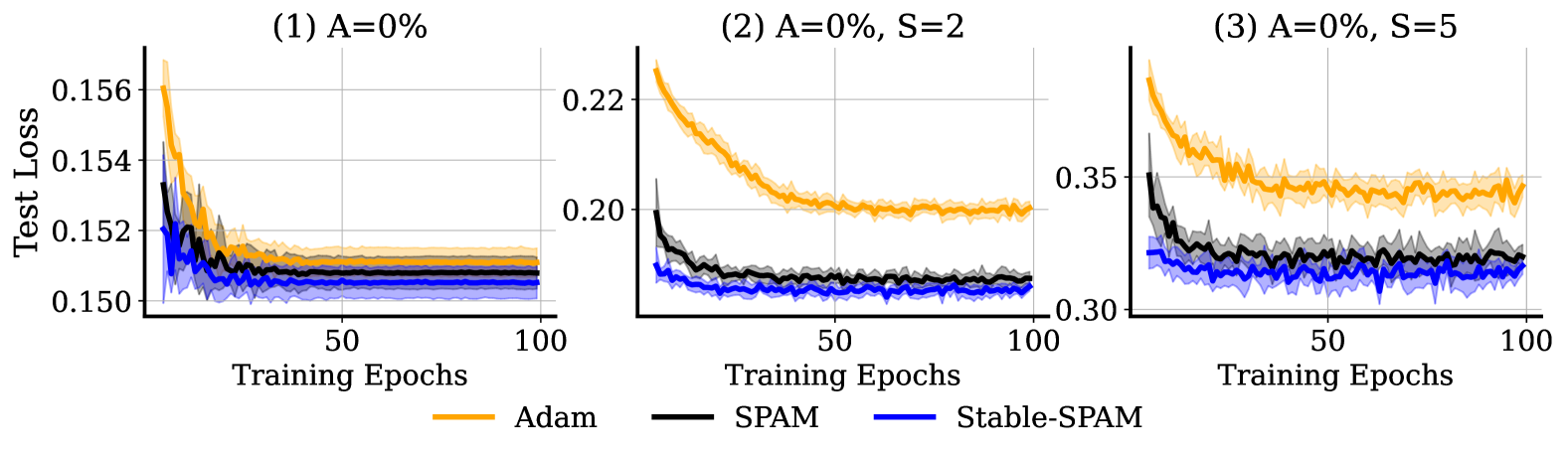
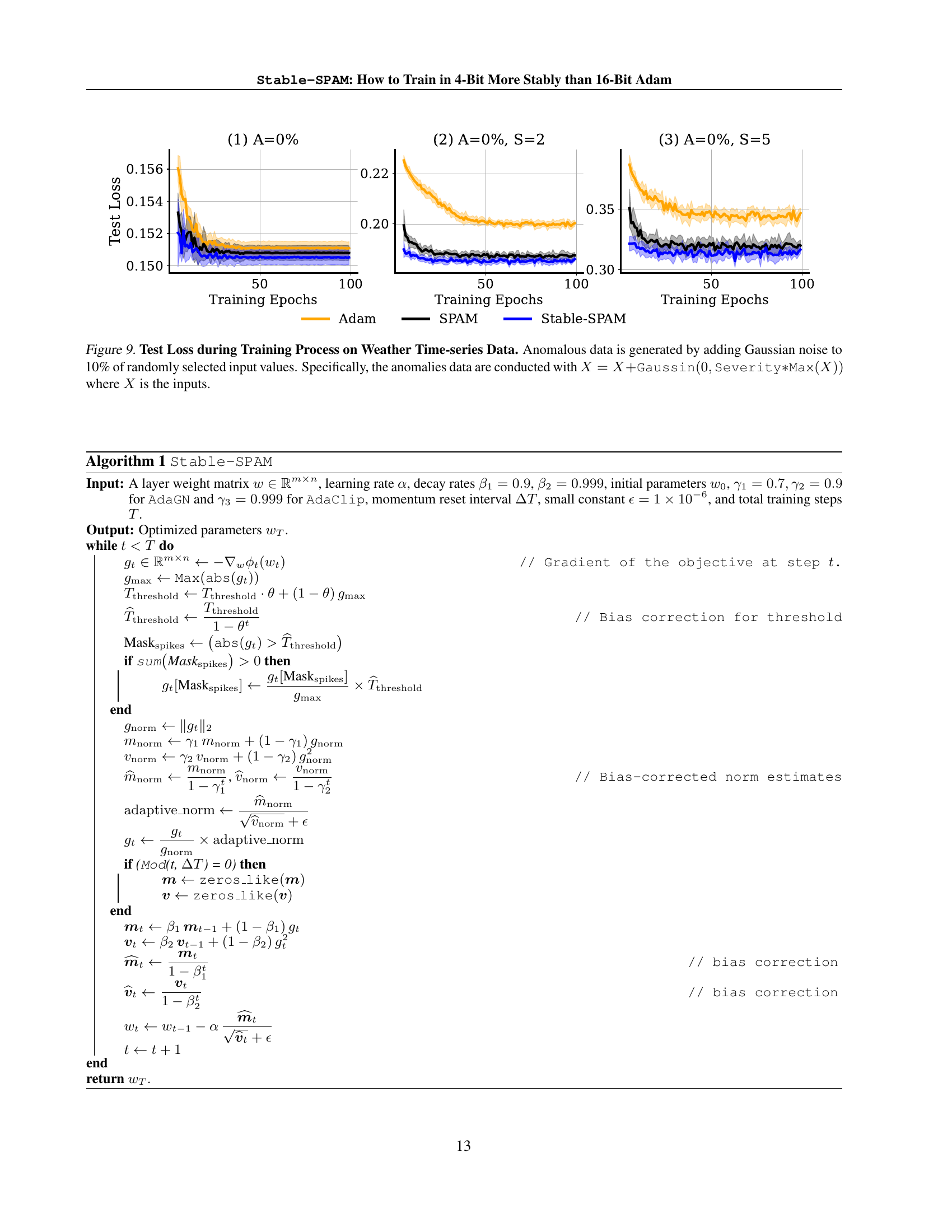
🔼 Figure 9 illustrates the performance of three optimizers (Adam, SPAM, and Stable-SPAM) on a time series forecasting task using the PatchTST model. The key aspect highlighted is the robustness of the optimizers to anomalous data. To simulate real-world scenarios where data might be corrupted or contain outliers, Gaussian noise was added to 10% of randomly selected data points. The severity of this noise was controlled by a ‘Severity’ parameter, which scales the magnitude of the added noise relative to the maximum value in the original data. The plot shows the test loss over training epochs for each optimizer under different levels of data corruption (A=0%, A=5%, A=10%), demonstrating how Stable-SPAM consistently maintains lower test loss compared to Adam and SPAM, especially when dealing with higher levels of anomalous data.
read the caption
Figure 9: Test Loss during Training Process on Weather Time-series Data. Anomalous data is generated by adding Gaussian noise to 10% of randomly selected input values. Specifically, the anomalies data are conducted with X=X+Gaussin(0,Severity∗Max(X))𝑋𝑋Gaussin0SeverityMax𝑋X=X+\texttt{Gaussin}(0,\texttt{Severity}*\texttt{Max}(X))italic_X = italic_X + Gaussin ( 0 , Severity ∗ Max ( italic_X ) ) where X𝑋Xitalic_X is the inputs.
More on tables
| Optimizer | 60M | 130M | 350M | 1B |
|---|---|---|---|---|
| Adam-mini | 34.10 | 24.85 | 19.05 | 16.07 |
| Adam | 34.09 | 24.91 | 18.77 | 16.13 |
| Adam + GradClip | 33.33 | 24.88 | 18.51 | 15.22 |
| Adafactor | 32.57 | 23.98 | 17.74 | 15.19 |
| SPAM | 30.46 | 23.36 | 17.42 | 14.66 |
| Stable-SPAM | 28.84 | 22.21 | 16.85 | 13.90 |
| Training Tokens | 1.1B | 2.2B | 6.4B | 11.6B |
🔼 This table presents a comparison of different optimizers’ performance during the training of LLAMA models using BF16 precision. It shows the perplexity scores achieved by each optimizer across various LLAMA model sizes (60M, 130M, 350M, and 1B parameters). The perplexity metric measures the model’s ability to predict the next word in a sequence, with lower scores indicating better performance. The table helps to illustrate the relative performance of different optimization algorithms and the effect of model size on their effectiveness.
read the caption
Table 2: Comparison among various optimizers on BF16 training. Perplexity is reported.
| Optimizers | INT4 Training | FP4 Training | ||
|---|---|---|---|---|
| 60M | 130M | 60M | 130M | |
| Lion | 39.36 | 35.28 | 39.89 | 34.20 |
| Lion+AdaGN+AdaClip | 38.49 | 29.40 | 36.75 | 31.63 |
| Adam-mini | 34.84 | 29.79 | 36.37 | 32.95 |
| Adam-mini+AdaGN+AdaClip | 34.61 | 29.65 | 34.65 | 32.39 |
| Training Tokens | 1.1B | |||
🔼 This table presents the results of experiments evaluating the impact of integrating Adaptive Gradient Norm (AdaGN) and Adaptive Spike-Aware Clipping (AdaClip) into two optimizers: Lion and Adam-mini. The experiments were performed on two different sizes of the LLaMA language model (60M and 130M parameters) using 4-bit training. The table shows the performance (likely measured by perplexity or loss) achieved by each optimizer with and without the addition of AdaGN and AdaClip, demonstrating their effect on model performance under low-bit precision training.
read the caption
Table 3: Performence of AdaGN and AdaClip on Lion and Adam-mini optimizers. Experiments are based on LLaMA-60M/130M with 4-Bit training.
| Optimizer | FP4 | BF16 |
| Adam | 35.47 | 34.09 |
| Adam + MoRet | 32.4 | 31.47 |
| Adam + MoRet + AdaClip | 31.97 | 30.29 |
| Adam + MoRet + AdaGN | 32.26 | 28.96 |
| Adam + MoRet + AdaGN + AdaClip (Stable-SPAM) | 31.40 | 28.84 |
| Adam + MoRet+AdaGN+SpikeClip (Huang et al., 2025) | 32.01 | 28.90 |
| Adam + MoRet+ GradClip (Goodfellow, 2016)+AdaClip | 31.95 | 29.87 |
| Adam + MoRet+AdaGN+AdaClip (Stable-SPAM) | 31.40 | 28.84 |
| Training Tokens | 1.1B | |
🔼 This table presents the results of an ablation study conducted to evaluate the individual and combined effects of the three main components of the Stable-SPAM optimizer: momentum reset (MoRet), adaptive gradient norm (AdaGN), and adaptive spike-aware clipping (AdaClip). The study uses the LLaMA-60M model trained on the C4 dataset. It compares the performance of Adam with different combinations of these components, as well as variations replacing AdaClip with SpikeClip and AdaGN with GradClip, to isolate the contributions of each component and demonstrate the effectiveness of the proposed Stable-SPAM approach. The results are reported in terms of perplexity.
read the caption
Table 4: Ablations on Stable-SPAM. Experiments are based on LLaMA-60M and C4.
| Params | Hidden | Intermediate | Heads | Layers | |
|---|---|---|---|---|---|
| M | |||||
| M | |||||
| M | |||||
🔼 This table presents the configurations of the LLaMA language models used in the experiments described in the paper. It shows the number of parameters, hidden layer size, intermediate layer size, number of attention heads, and number of layers for each of the four LLaMA model sizes: 60M, 130M, 350M, and 1B.
read the caption
Table 5: Configurations of LLaMA models used in this paper.
| Hyper-Parameters | LLaMA-M | LLaMA-M | LLaMA-B |
|---|---|---|---|
| LR | |||
🔼 This table details the hyperparameters used in the Stable-SPAM optimizer during 4-bit pre-training experiments. It shows the values for the learning rate (LR), momentum reset interval (ΔT), and the parameters (γ1, γ2, γ3) controlling the adaptive gradient normalization and clipping for three different LLaMA model sizes: 130M, 350M, and 1B parameters.
read the caption
Table 6: Hyperparameters of Stable-SPAM for 4-bit pre-training experiments in this paper.
| Hyper-Parameters | LLaMA-M | LLaMA-M | LLaMA-M | LLaMA-B |
|---|---|---|---|---|
| Standard Pretraining | ||||
| LR | ||||
🔼 This table lists the hyperparameters used for training the Stable-SPAM optimizer on large language models (LLMs) using BF16 precision. It includes the learning rate (LR), momentum reset interval (ΔT), momentum coefficients (γ1, γ2), and the adaptive clipping threshold coefficient (γ3) for different LLaMA model sizes (60M, 130M, 350M, 1B parameters). These values were tuned for optimal performance in the BF16 pre-training setting.
read the caption
Table 7: Hyperparameters of Stable-SPAM for BF6 pre-training experiments in this paper.
Full paper#