TL;DR#
Current AI-driven frameworks struggle with insufficient operational knowledge for mobile device automation. Manually written knowledge is labor-intensive and inefficient. To address this, a new framework is needed for seamlessly automating tasks. By improving knowledge acquisition, the researchers hope to enhance how devices respond to their owners.
To tackle these issues, Mobile-Agent-V is introduced, a framework leveraging video guidance for rich and cost-effective operational knowledge. It enhances task execution by using video inputs without specialized sampling or preprocessing. A sliding window strategy and agents ensure actions align with user instructions. Mobile-Agent-V demonstrates a 30% performance improvement over existing methods.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it addresses the critical need for improved mobile device automation. The innovative video-guided approach offers a more scalable and adaptable solution to operational knowledge acquisition, impacting areas like accessibility, productivity, and human-computer interaction.
Visual Insights#

🔼 This figure compares three approaches to mobile device automation: a baseline agent without operational knowledge, a manually-written knowledge base, and the proposed Mobile-Agent-V. The baseline agent fails to complete the task, requiring many steps. Manually creating a knowledge base is time-consuming and requires repeated testing. Mobile-Agent-V, in contrast, uses video demonstrations for knowledge injection, making the process significantly more efficient. Users simply record a video of the task, and the system learns from it, reducing effort and increasing efficiency.
read the caption
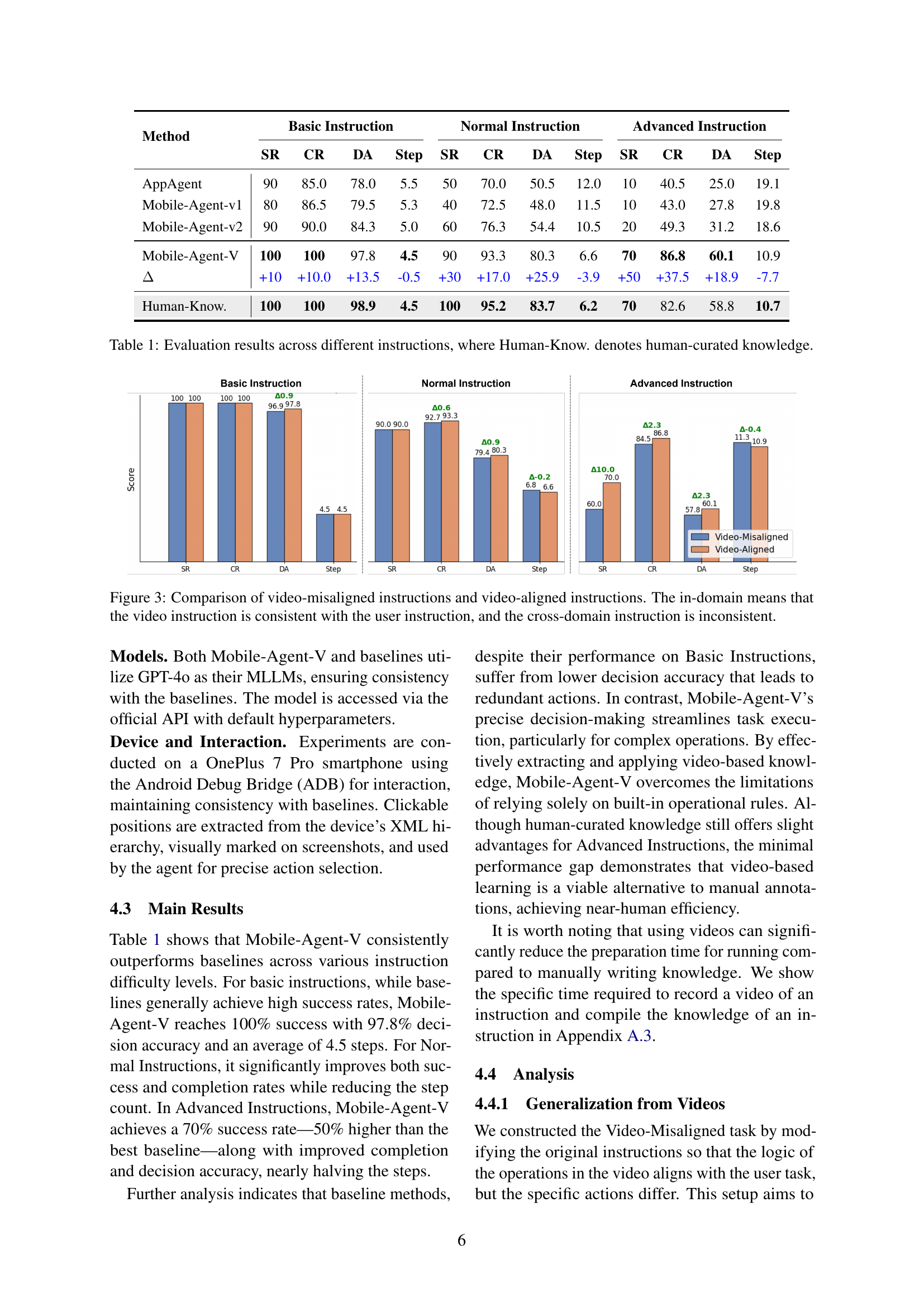
Figure 1: Comparison between a baseline agent, manually written knowledge, and Mobile-Agent-V. The baseline agent, lacking operation knowledge, struggles to complete the task, requiring excessive steps and still failing. Manually written knowledge requires documentation and iterative verification. In contrast, Mobile-Agent-V leverages operation videos, requiring only execution and recording, making knowledge injection far more efficient.
| Method | Basic Instruction | Normal Instruction | Advanced Instruction | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SR | CR | DA | Step | SR | CR | DA | Step | SR | CR | DA | Step | |
| AppAgent | 90 | 85.0 | 78.0 | 5.5 | 50 | 70.0 | 50.5 | 12.0 | 10 | 40.5 | 25.0 | 19.1 |
| Mobile-Agent-v1 | 80 | 86.5 | 79.5 | 5.3 | 40 | 72.5 | 48.0 | 11.5 | 10 | 43.0 | 27.8 | 19.8 |
| Mobile-Agent-v2 | 90 | 90.0 | 84.3 | 5.0 | 60 | 76.3 | 54.4 | 10.5 | 20 | 49.3 | 31.2 | 18.6 |
| Mobile-Agent-V | 100 | 100 | 97.8 | 4.5 | 90 | 93.3 | 80.3 | 6.6 | 70 | 86.8 | 60.1 | 10.9 |
| +10 | +10.0 | +13.5 | -0.5 | +30 | +17.0 | +25.9 | -3.9 | +50 | +37.5 | +18.9 | -7.7 | |
| Human-Know. | 100 | 100 | 98.9 | 4.5 | 100 | 95.2 | 83.7 | 6.2 | 70 | 82.6 | 58.8 | 10.7 |
🔼 This table presents a quantitative comparison of Mobile-Agent-V’s performance against several baseline methods across various task complexities. The tasks are categorized into three difficulty levels: Basic, Normal, and Advanced, reflecting increasing levels of operational knowledge required. For each level, the table displays the Success Rate (SR), Completion Rate (CR), Decision Accuracy (DA), and average number of Steps taken. A final row shows the performance of a human expert who has access to the operational knowledge, serving as an upper bound for performance comparison. The results highlight Mobile-Agent-V’s superior performance across all levels, showcasing its ability to leverage video guidance effectively for mobile automation.
read the caption
Table 1: Evaluation results across different instructions, where Human-Know. denotes human-curated knowledge.
In-depth insights#
Video-Guided AI#
Video-guided AI represents a significant paradigm shift, leveraging visual data for enhanced learning and task execution. Unlike traditional methods relying on pre-programmed rules or extensive text-based training data, this approach utilizes videos to impart operational knowledge. This offers several advantages, including reducing the need for manual annotation, capturing nuanced interactions, and adapting to dynamic environments. By observing demonstrations, AI agents can learn complex procedures and improve decision-making, mirroring human learning processes. Scalability and adaptability are also key benefits, enabling the development of robust systems capable of handling diverse tasks and adapting to new situations. However, challenges remain in processing and understanding video data effectively, requiring innovative techniques for feature extraction, knowledge representation, and reasoning. Further research is needed to optimize video-guided AI systems and unlock their full potential.
Multi-Agent Auto#
Multi-agent automation represents a paradigm shift, enabling sophisticated task orchestration through collaborative AI. Unlike single-agent systems, multiple agents can concurrently address diverse sub-problems, improving efficiency and robustness. This approach allows for specialization, where each agent excels in a specific area (e.g., perception, planning, execution). Key challenges involve agent communication, conflict resolution, and maintaining overall system coherence. Successful implementation necessitates a well-defined architecture that supports effective agent interaction and resource allocation to prevent bottlenecking of the system and to maximize output capabilities.
Sliding Keyframes#
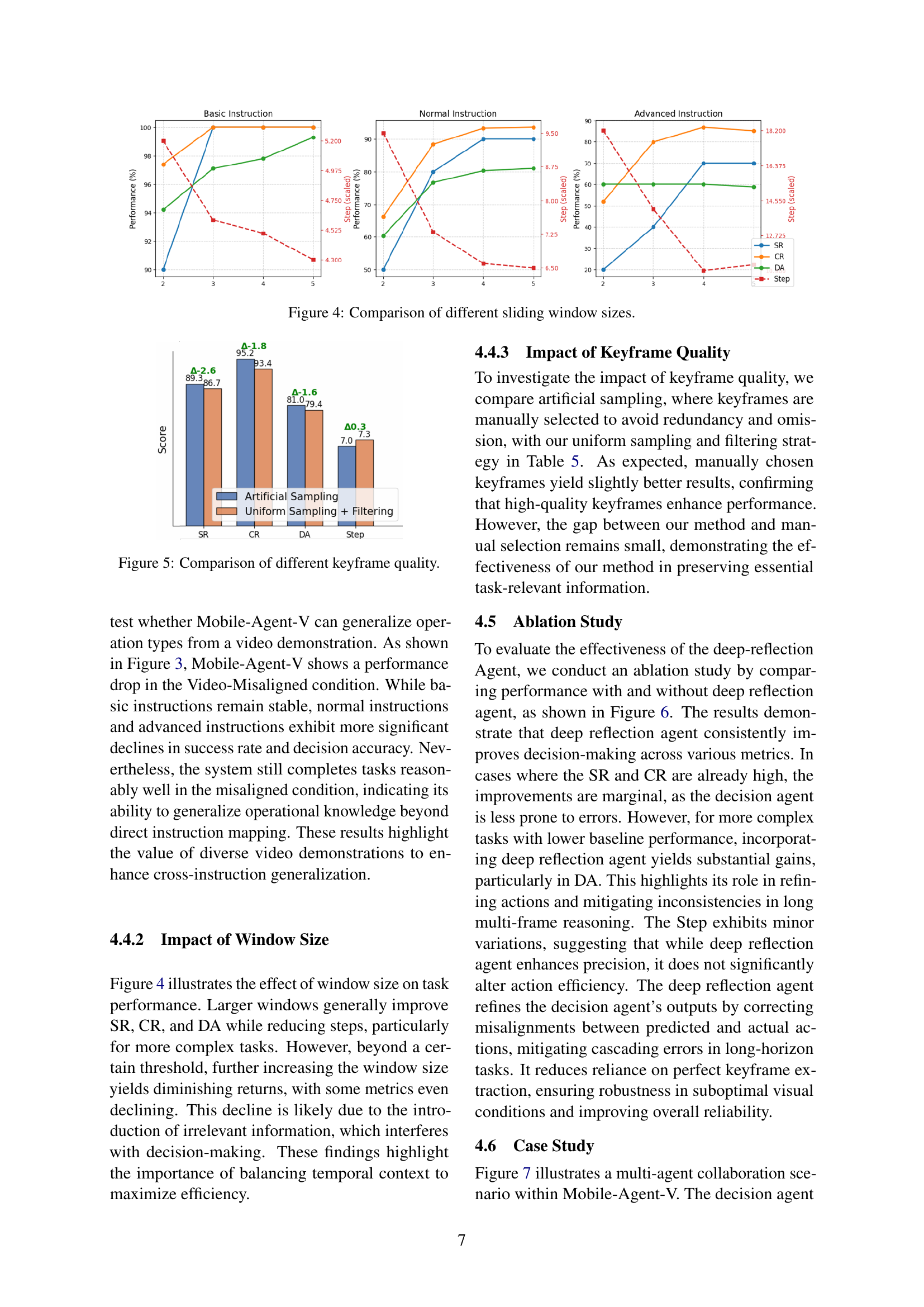
The research addresses challenges in mobile device automation by proposing a novel sliding window approach for processing operational videos. This technique aims to improve video comprehension for MLLMs by reducing input length and focusing on keyframes relevant to the current operation. The sliding window dynamically adjusts, selecting keyframes between start and end points to predict state transitions. The window size is typically greater than two to provide context. Overall, it balances the need for detailed visual information with the constraints of MLLM input sizes, to derive valuable insights.
Operational Learn#
The paper introduces a innovative method for mobile automation using video guidance. By leveraging video inputs, the system aims to enhance task execution capabilities without requiring specialized sampling or pre-processing, addressing limitations of existing AI frameworks that often struggle due to insufficient operational knowledge. The core innovation lies in the Mobile-Agent-V framework, which integrates a sliding window strategy alongside video and deep-reflection agents. This ensures actions align with user instructions, enabling autonomous learning and efficient task execution from guided recordings. Experimental results demonstrate a 30% performance improvement, highlighting the effectiveness of video-based operational knowledge injection, offering a pathway for scalable agent learning.
Task Generalize#
Mobile-Agent-V demonstrates a valuable capacity for task generalization. The system still manages to complete tasks reasonably well, highlighting its ability to extend operational knowledge beyond direct instruction mapping. The value of diverse video demonstrations to enhance cross-instruction generalization is highlighted by those insights. The results show that baseline methods, despite their performance on Basic Instructions, suffer from lower decision accuracy that leads to redundant actions. In contrast, Mobile-Agent-V’s precise decision-making streamlines task execution, particularly for complex operations.
More visual insights#
More on figures

🔼 The figure illustrates the workflow of Mobile-Agent-V, a framework designed for mobile device automation using video guidance. It shows how video input (V) is processed through uniform sampling and redundancy removal to create keyframes (F’). A sliding window (Vw) selects a subset of keyframes for the decision agent (Da), which generates actions (Oi) based on the window, video instructions (Iv), device state (Di), user instructions (Iu), and historical operations. The deep-reflection agent (Ra) refines these actions (ROi), which are then executed on the device, updating its state (Di+1). Finally, the video agent (Va) determines the next window’s starting point (Si+1), dynamically adjusting the observation scope as the task progresses.
read the caption
Figure 2: The framework of Mobile-Agent-V.

🔼 This figure compares the performance of Mobile-Agent-V on two types of instructions: video-aligned and video-misaligned. Video-aligned instructions refer to scenarios where the instructions given to the user and the demonstrated actions in the video are consistent (in-domain). Video-misaligned instructions, conversely, represent cases where the instructions and the video demonstration are inconsistent (cross-domain). The figure shows how well Mobile-Agent-V generalizes beyond exact video matches to instructions. It displays success rate (SR), completion rate (CR), decision accuracy (DA), and step count for basic, normal, and advanced instructions under both aligned and misaligned conditions.
read the caption
Figure 3: Comparison of video-misaligned instructions and video-aligned instructions. The in-domain means that the video instruction is consistent with the user instruction, and the cross-domain instruction is inconsistent.

🔼 This figure shows the effect of different sliding window sizes on the performance of Mobile-Agent-V. The x-axis represents different window sizes, and the y-axis represents the performance metrics including success rate (SR), completion rate (CR), decision accuracy (DA), and step count (Step) for three different instruction types (Basic, Normal, and Advanced). The results indicate that larger window sizes generally improve performance, but beyond a certain point, adding more frames to the window starts to negatively affect the model’s performance, highlighting the importance of balancing temporal context in the model.
read the caption
Figure 4: Comparison of different sliding window sizes.

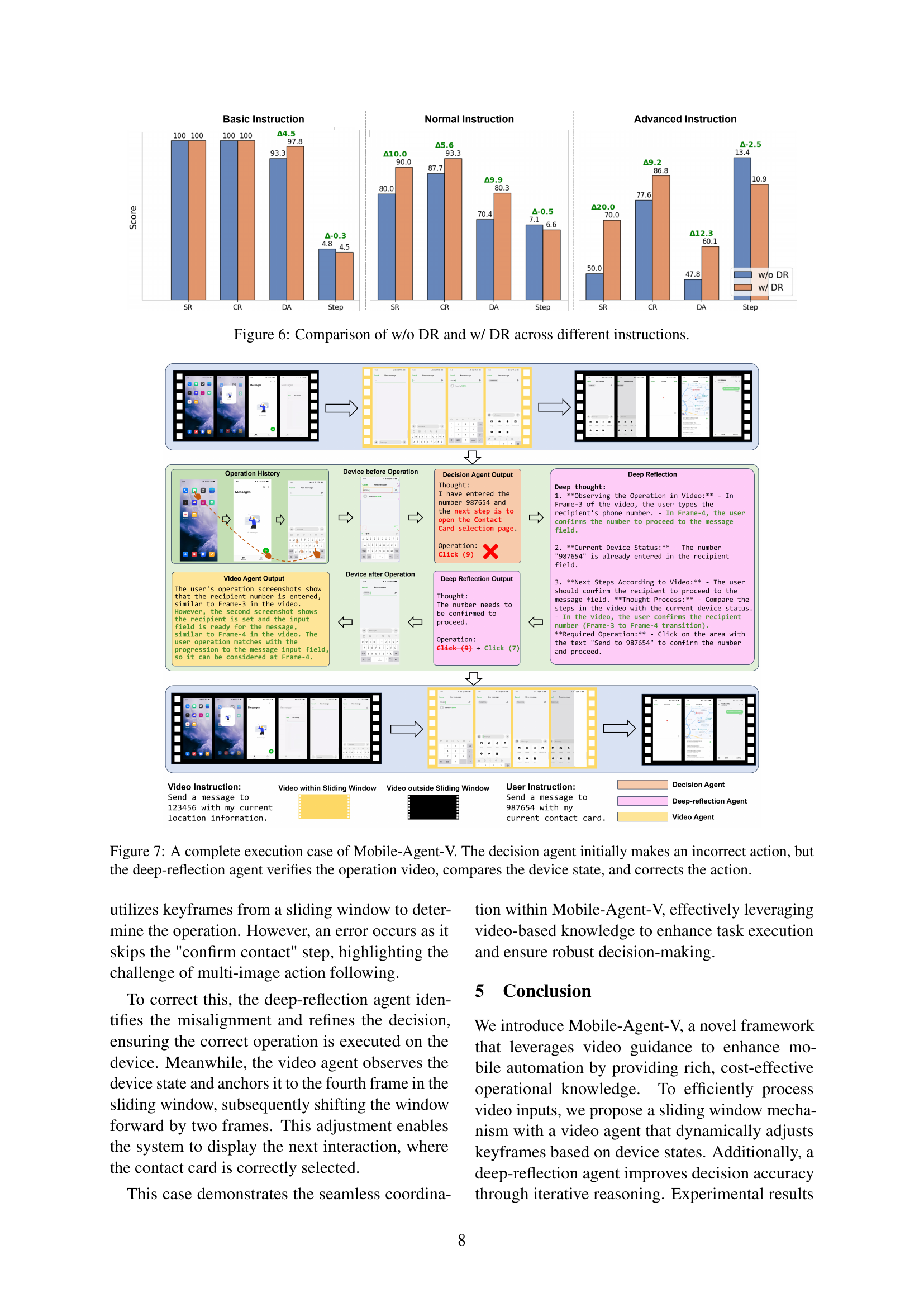
🔼 This figure compares the performance of Mobile-Agent-V using different keyframe extraction methods. It contrasts the results of using manually selected high-quality keyframes against the automatically generated keyframes produced by the model’s uniform sampling and filtering technique. The goal is to illustrate the impact of keyframe quality on the model’s performance, specifically in terms of Success Rate (SR), Completion Rate (CR), Decision Accuracy (DA), and the number of Steps taken to complete a task. The manual selection method serves as an upper bound of performance.
read the caption
Figure 5: Comparison of different keyframe quality.

🔼 This figure compares the performance of Mobile-Agent-V with and without the deep-reflection (DR) agent across different instruction difficulty levels (Basic, Normal, Advanced). It displays the success rate (SR), completion rate (CR), decision accuracy (DA), and step count for each condition and difficulty level, illustrating the impact of the DR agent on the overall performance of the model. The bars visually represent the quantitative differences in these metrics between the two versions of the model.
read the caption
Figure 6: Comparison of w/o DR and w/ DR across different instructions.

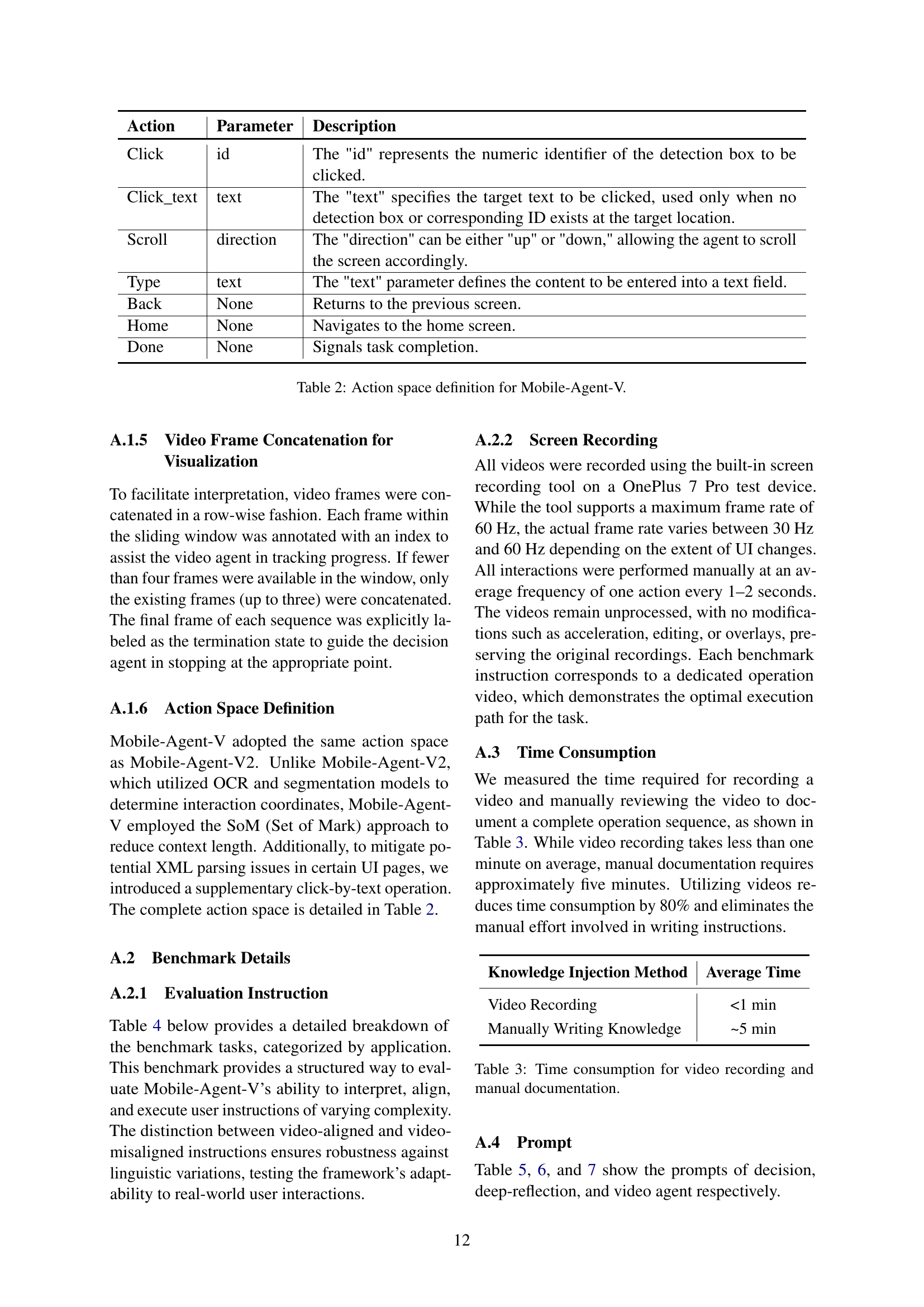
🔼 This figure illustrates a scenario where the decision agent in Mobile-Agent-V initially makes an incorrect action. However, the deep-reflection agent intervenes by verifying the actions against the video instructions and the current device state. The deep-reflection agent identifies the discrepancy and provides the corrected action. The video agent also dynamically adjusts the sliding window, updating the context for the decision-making process. This example demonstrates the collaborative functionality of Mobile-Agent-V’s multi-agent architecture in ensuring accurate and efficient task completion.
read the caption
Figure 7: A complete execution case of Mobile-Agent-V. The decision agent initially makes an incorrect action, but the deep-reflection agent verifies the operation video, compares the device state, and corrects the action.
More on tables
| Action | Parameter | Description |
|---|---|---|
| Click | id | The "id" represents the numeric identifier of the detection box to be clicked. |
| Click_text | text | The "text" specifies the target text to be clicked, used only when no detection box or corresponding ID exists at the target location. |
| Scroll | direction | The "direction" can be either "up" or "down," allowing the agent to scroll the screen accordingly. |
| Type | text | The "text" parameter defines the content to be entered into a text field. |
| Back | None | Returns to the previous screen. |
| Home | None | Navigates to the home screen. |
| Done | None | Signals task completion. |
🔼 This table details the six fundamental actions Mobile-Agent-V uses to interact with mobile devices. Each action has a parameter that refines the action’s effect. For example, the ‘Click’ action uses an ‘id’ parameter which specifies the numeric identifier of the target on-screen element. ‘Click_text’ provides an alternative way to click using text instead of an ID. ‘Scroll’ has a direction parameter (‘up’ or ‘down’). ‘Type’ takes a text parameter to input text, while ‘Back’ and ‘Home’ navigate back and to the home screen, respectively. Finally, ‘Done’ signals the task’s completion.
read the caption
Table 2: Action space definition for Mobile-Agent-V.
| Knowledge Injection Method | Average Time |
|---|---|
| Video Recording | <1 min |
| Manually Writing Knowledge | ~5 min |
🔼 This table presents a comparison of the time required for two different methods of knowledge injection: video recording and manual knowledge writing. It shows that creating a video of a task takes significantly less time (less than 1 minute on average) compared to manually documenting the same task (approximately 5 minutes on average). This highlights a key advantage of using video guidance for Mobile-Agent-V, as it offers greater efficiency in acquiring operational knowledge.
read the caption
Table 3: Time consumption for video recording and manual documentation.
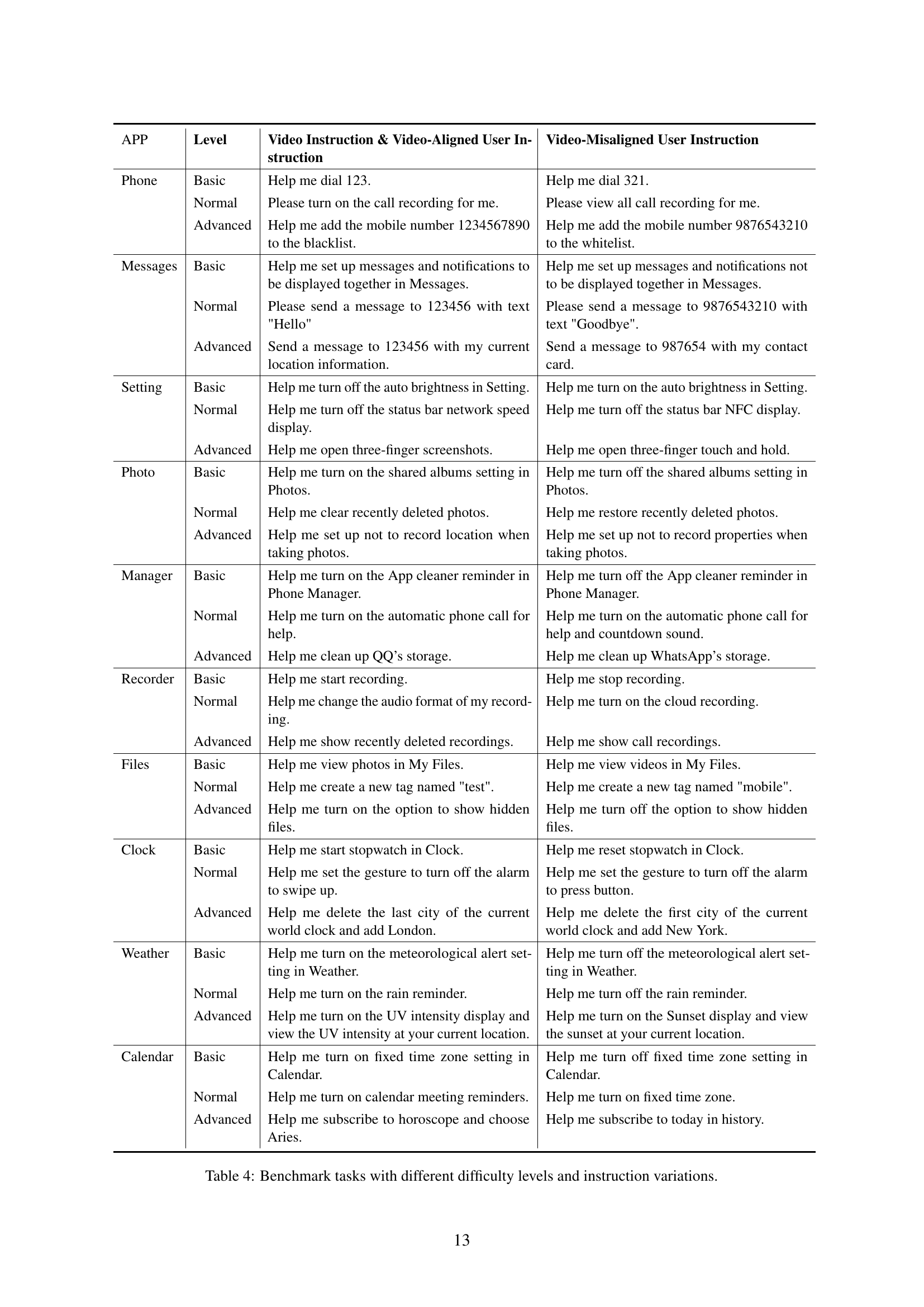
| APP | Level | Video Instruction & Video-Aligned User Instruction | Video-Misaligned User Instruction |
|---|---|---|---|
| Phone | Basic | Help me dial 123. | Help me dial 321. |
| Normal | Please turn on the call recording for me. | Please view all call recording for me. | |
| Advanced | Help me add the mobile number 1234567890 to the blacklist. | Help me add the mobile number 9876543210 to the whitelist. | |
| Messages | Basic | Help me set up messages and notifications to be displayed together in Messages. | Help me set up messages and notifications not to be displayed together in Messages. |
| Normal | Please send a message to 123456 with text "Hello" | Please send a message to 9876543210 with text "Goodbye". | |
| Advanced | Send a message to 123456 with my current location information. | Send a message to 987654 with my contact card. | |
| Setting | Basic | Help me turn off the auto brightness in Setting. | Help me turn on the auto brightness in Setting. |
| Normal | Help me turn off the status bar network speed display. | Help me turn off the status bar NFC display. | |
| Advanced | Help me open three-finger screenshots. | Help me open three-finger touch and hold. | |
| Photo | Basic | Help me turn on the shared albums setting in Photos. | Help me turn off the shared albums setting in Photos. |
| Normal | Help me clear recently deleted photos. | Help me restore recently deleted photos. | |
| Advanced | Help me set up not to record location when taking photos. | Help me set up not to record properties when taking photos. | |
| Manager | Basic | Help me turn on the App cleaner reminder in Phone Manager. | Help me turn off the App cleaner reminder in Phone Manager. |
| Normal | Help me turn on the automatic phone call for help. | Help me turn on the automatic phone call for help and countdown sound. | |
| Advanced | Help me clean up QQ’s storage. | Help me clean up WhatsApp’s storage. | |
| Recorder | Basic | Help me start recording. | Help me stop recording. |
| Normal | Help me change the audio format of my recording. | Help me turn on the cloud recording. | |
| Advanced | Help me show recently deleted recordings. | Help me show call recordings. | |
| Files | Basic | Help me view photos in My Files. | Help me view videos in My Files. |
| Normal | Help me create a new tag named "test". | Help me create a new tag named "mobile". | |
| Advanced | Help me turn on the option to show hidden files. | Help me turn off the option to show hidden files. | |
| Clock | Basic | Help me start stopwatch in Clock. | Help me reset stopwatch in Clock. |
| Normal | Help me set the gesture to turn off the alarm to swipe up. | Help me set the gesture to turn off the alarm to press button. | |
| Advanced | Help me delete the last city of the current world clock and add London. | Help me delete the first city of the current world clock and add New York. | |
| Weather | Basic | Help me turn on the meteorological alert setting in Weather. | Help me turn off the meteorological alert setting in Weather. |
| Normal | Help me turn on the rain reminder. | Help me turn off the rain reminder. | |
| Advanced | Help me turn on the UV intensity display and view the UV intensity at your current location. | Help me turn on the Sunset display and view the sunset at your current location. | |
| Calendar | Basic | Help me turn on fixed time zone setting in Calendar. | Help me turn off fixed time zone setting in Calendar. |
| Normal | Help me turn on calendar meeting reminders. | Help me turn on fixed time zone. | |
| Advanced | Help me subscribe to horoscope and choose Aries. | Help me subscribe to today in history. |
🔼 This table presents benchmark tasks designed to evaluate the performance of mobile automation agents. The tasks are categorized by app (e.g., Phone, Messages, Settings) and difficulty level (Basic, Normal, Advanced). Each task includes two sets of instructions: one aligned with the video demonstration used for training and one misaligned to test generalization capabilities. The table highlights the complexity and variance of real-world mobile device operations, providing a nuanced assessment of the agent’s ability to learn and adapt.
read the caption
Table 4: Benchmark tasks with different difficulty levels and instruction variations.
| System |
|---|
| You are a mobile phone operation assistant. Below is a description of this conversation. |
| In the following part, I will upload a large image made up of many screenshots. These screenshots in this image are all from a screen recording of a mobile phone operation. I will tell you the task completed in the screen recording. You need to observe this screen recording. |
| Then, you need to complete a new task, which is related to the task in the screen recording. You need to combine the operation experience provided by the screen recording and gradually complete this task. I will upload the current screenshot of the device. There will be many detection boxes on this screenshot, and there will be a number in the upper left and lower right corners of the detection box. You need to perform operations on the current page. In order to better operate the phone, the following are the operation tools you can use: |
| - Click (id): The "id" is the numeric serial number of the detection box you need to click. |
| - Click_text (text): The "text" is the text you need to click. This is only used when the detection box and the corresponding id do not exist at the location to be clicked. |
| - Scroll (direction): The "direction" selects from "up", "down", "left", and "right". You can scroll the page a certain distance in the specified direction. |
| - Type (text): The "text" is the content you need to enter. |
| - Back: You can use this operation to return to the previous page. |
| - Home: You can use this operation to return to the home page. |
| - Done: You can use this operation when the task is completed. |
| You need to strictly follow the following json output format: |
| "Thought": You need to think about how to perform this operation on the current device based on the operation path in the video, "Operation": Select one from the operation tools, "Summary": Briefly summarize this operation |
| User during the first operation |
| The first image is the screen recording, in which the tasks are completed: {} |
| The second image is the screenshot of the current device, in which you need to complete the following tasks: {} |
| Note: You need to refer to the operation path in the video more than relying on your own operation experience. Because you may make mistakes. |
| Note: You need to refer to the operation path in the video more than relying on your own operation experience. Because you may make mistakes." |
| <image: ><image: > |
| User during subsequent operations |
| The first image is the screen recording, in which the tasks are completed: {} |
| The second image is the screenshot of the current device, in which you need to complete the following tasks: {} |
| Here is your operation history: |
| Step-1: {operation 1} |
| Step-2: {operation 2} |
| …… |
| Step-n: {operation n} |
| Note: If the operation history and current device can infer that the task has been completed, use Done. |
| Note: You need to refer to the operation path in the video more than relying on your own operation experience. Because you may make mistakes." |
| <image: ><image: > |
🔼 This table displays the prompt given to the decision agent within the Mobile-Agent-V framework. The prompt guides the agent on how to process a series of screenshots from a mobile device operation video and complete a specified task based on the visual input and operational knowledge gained from the video.
read the caption
Table 5: The prompt for decision agent.
| System |
|---|
| You are an expert in mobile phone operation. I will upload two images below. The first image is a keyframe mosaic from an operation video, in which the completed task is "{}"; the second image is a screenshot of the current status of the mobile phone. |
| On the mobile phone shown in the second image, the task to be completed is: "{}". The user will perform the following operation: |
| {Operation from decision agent} |
| Now please observe whether this operation conforms to the operation path shown in the first image. If it conforms, please output "True", otherwise please modify the operation content according to the above json format. |
| The operation should be: |
| - Click (id): The "id" is the numeric serial number of the detection box you need to click. |
| - Click_text (text): The "text" is the text you need to click. This is only used when the detection box and the corresponding id do not exist at the location to be clicked. |
| - Scroll (direction): The "direction" selects from "up" and "down". You can scroll the page a certain distance in the specified direction. |
| - Type (text): The "text" is the content you need to enter. |
| - Back: You can use this operation to return to the previous page. |
| - Home: You can use this operation to return to the home page. |
| - Done: You can use this operation when the task is completed. |
| Note: If the operation history and current device can infer that the task has been completed, use Done. |
| You need to think in the following way: |
| 1. Observe the operation of each step in the video (especially frame-3 and frame-4). |
| 2. Anchor the position of the current device in the video. |
| 3. Complete the current step according to the operation in the video. |
| Please output your thought about this step by step before you output your response. |
| User |
| <image: ><image: > |
🔼 This table details the prompt given to the deep-reflection agent within the Mobile-Agent-V framework. The prompt instructs the agent to analyze the provided video keyframes and compare them to the current device state (shown in a second image). The agent must determine if the decision agent’s proposed operation aligns with the video’s demonstrated steps; if not, the agent must correct the operation and output the corrected action in a specific JSON format. The prompt emphasizes the importance of using the video as a guide, rather than solely relying on the agent’s own knowledge or reasoning.
read the caption
Table 6: The prompt for deep-reflection agent.
| System |
|---|
| You are a mobile phone operation assistant. I will provide you with two images. The first image is a long picture of key frames from a mobile phone operation video, which shows a correct operation trajectory to complete the task: {}. The second image is two screenshots before and after an operation from the user. The user want to complete the task: {}. Please note that these two images are not necessarily the complete operation trajectories, they may only be part of the continuous operation. |
| Although the task shown in the video may not be exactly the same as the task the user needs to complete, there is a strong correlation between the two. So the user is referring to the operation in the video to complete this task. |
| Now you need to determine which frame of the video the user is in after the device is operated. You need to use a number to represent it. If the device is in the state between two frames, the previous frame is output. |
| If the device is not in any frame of the video, please output the number 0 to indicate an operation error and generate an error cause analysis. |
| You need to output in the following json format: |
| {"Thought": Your thought of current question, "Frame": a number, "Analysis": If Frame is 0, generate an error cause analysis, otherwise output null, "Need_Back": If Frame is 0, you need to think about how to get back on track. If you need to return to the previous page, please output true. If you need to continue to perform an operation on the current page to get back on track, please output false. If Frame is not 0, please output False directly.} |
| User |
| Here are the video and operation: |
| <image: ><image: > |
🔼 Table 7 shows the prompt given to the video agent in the Mobile-Agent-V framework. The prompt instructs the agent to analyze a video of a user performing a mobile task and two screenshots representing the device state before and after a single user action. The agent must determine which frame in the video corresponds to the current state of the device, indicating if the action aligns with the video demonstration. If there’s a mismatch (the device isn’t in any of the video frames), the agent must output 0, analyze the error, and suggest whether to return to the previous screen or continue from the current screen.
read the caption
Table 7: The prompt for video agent.
Full paper#