TL;DR#
Generating realistic and expressive dance movements from static images is a complex challenge, requiring synchronization with music and detailed body motion. Existing methods often rely on 3D human pose estimation, which can be inaccurate and limit the diversity of generated motions, particularly lacking head and hand details. Moreover, creating high-fidelity video outputs that maintain visual consistency with the original image and ensure temporal smoothness remains difficult.
The paper introduces a novel approach that creates diverse and lifelike dance videos from a single static image using music as the sole driver. This is achieved through a unified transformer-diffusion framework that generates extended, music-synchronized sequences of 2D body poses, which then guide a diffusion model to produce coherent and realistic dance video frames. The framework features an autoregressive transformer model for synthesizing 2D poses, capturing both large body movements and fine-grained motions. This approach addresses data limitations and enhances scalability by modeling a wide spectrum of 2D dance motions, resulting in high-quality, expressive dance videos.
Key Takeaways#
Why does it matter?#
This paper introduces a novel method to generate human dance videos from a single image, pushing the boundaries of AI-driven content creation. It offers researchers new avenues for exploring human motion synthesis and its applications in entertainment and virtual reality.
Visual Insights#

🔼 Figure 1 showcases X-Dancer’s capabilities. Given a single, static image of a person, X-Dancer generates a full-body dance video synchronized to an input music track. The system handles diverse body types and appearances, producing highly expressive and realistic movements, including detailed hand and head motions. The results are seamless, lifelike dance videos. The code and model will be made available for research.
read the caption
Figure 1: We present X-Dancer, a unified transformer-diffusion framework for zero-shot, music-driven human image animation from a single static image, capable of handling diverse body forms and appearances. Our method enables the synthesis of highly expressive and diverse full-body dance motions that are synchronized with music, including detailed movements at the head and hands, which are then seamlessly translated into vivid and lifelike dance videos. Code and model will be available for research purposes.
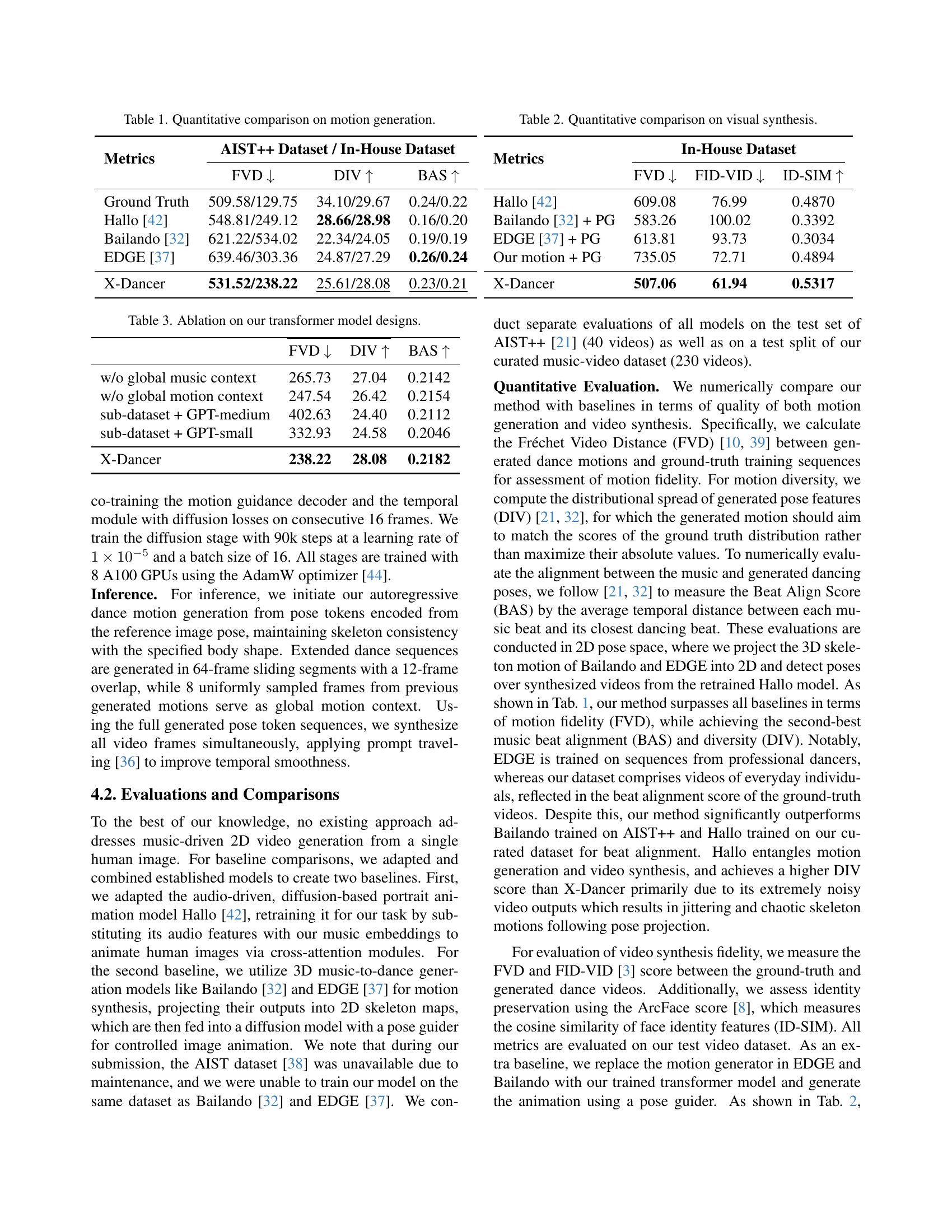
| Metrics | AIST++ Dataset / In-House Dataset | ||
|---|---|---|---|
| FVD | DIV | BAS | |
| Ground Truth | 509.58/129.75 | 34.10/29.67 | 0.24/0.22 |
| Hallo [42] | 548.81/249.12 | 28.66/28.98 | 0.16/0.20 |
| Bailando [32] | 621.22/534.02 | 22.34/24.05 | 0.19/0.19 |
| EDGE [37] | 639.46/303.36 | 24.87/27.29 | 0.26/0.24 |
| X-Dancer | 531.52/238.22 | 25.61/28.08 | 0.23/0.21 |
🔼 This table presents the results of ablation experiments conducted on the transformer model design within the X-Dancer framework. It shows the impact of removing different components of the model, such as the global music context, global motion context, and variations in the size of the transformer model (GPT-medium vs. GPT-small), on the performance of the model, measured using FVD (Fréchet Video Distance), DIV (distributional spread), and BAS (beat alignment score). Lower FVD indicates better motion fidelity, higher DIV signifies greater motion diversity, and higher BAS represents better alignment between the music and the generated dance.
read the caption
Table 3: Ablation on our transformer model designs.
In-depth insights#
2D Dance Motion#
2D dance motion analysis and synthesis offer a compelling alternative to 3D methods, particularly in the context of music-driven human image animation. The primary advantage lies in the wealth of available 2D dance videos, sourced from platforms like TikTok and YouTube, which far exceeds the limited datasets of 3D motion capture. This abundance of data facilitates the training of more robust and expressive models. Relying on 2D pose estimation mitigates the challenges associated with 3D pose recovery from monocular video, which can be error-prone and introduce artifacts. Furthermore, 2D representations offer a natural way to capture subtle nuances in dance, such as finger movements, head tilts, and clothing dynamics, that are often lost or oversimplified in 3D skeletal models. However, directly translating 2D dance motion into realistic video presents unique challenges. One significant hurdle is maintaining temporal coherence and avoiding jittering artifacts, especially when dealing with noisy or incomplete pose estimations. Another key consideration is preserving the identity and body shape of the reference person throughout the animation sequence, which requires careful attention to detail when mapping 2D motion onto the target image.
Tokenization Scheme#
The paper introduces a novel tokenization scheme for human poses to enhance music-driven dance video generation. Instead of directly using raw pose coordinates, it uses a compositional, confidence-aware VQ-VAE. This tokenization captures diverse and nuanced human dance poses, discretizing poses into tokens. The approach is to train separate codebooks for different body parts (upper/lower body, hands, head), allowing the model to decompose pose variations across frequency levels. Partitioning the pose in this way improves expressiveness and flexibility. The quantized pose latents are concatenated and fed to a shared decoder. This is helpful for the model to capture finer details. A major component of this tokenization is keypoint confidence; by building confidence into the tokens, the model can handle motion blur and occlusions robustly. All of this adds up to a system that can create believable poses that align well with music.
Music Alignment#
Music alignment in dance video generation is a critical aspect, ensuring the generated human motions synchronize seamlessly with the provided music track. It involves understanding the musical rhythm, beats, and overall structure and translating these elements into corresponding dance movements. Challenges arise from the freeform nature of dance and the need to capture subtle nuances in musicality. Effective music alignment necessitates extracting relevant features from the audio—such as tempo, beat locations, and harmonic content—and using these features to guide the motion generation process. Techniques may include cross-modal attention mechanisms or recurrent neural networks that learn to map musical cues to appropriate pose sequences. The evaluation of music alignment is often performed using metrics like Beat Alignment Score (BAS), which quantifies the temporal consistency between music beats and the generated dance motions. Overall, music alignment is key to creating believable and engaging dance videos that resonate with the viewer.
Scalability Focus#
Focusing on scalability in dance video generation is vital due to the high computational demands and the need to handle diverse dance styles and body types. A scalable solution ensures efficient processing of large datasets and reduces inference time. Prior methods often struggle with limited training data, leading to reduced diversity. By leveraging readily available 2D dance motions and a transformer-diffusion framework, the system can overcome data limitations and enhance scalability. A multi-scale tokenization scheme for whole-body 2D human poses with keypoint confidence helps model complex movements, while cross-modal transformer models with GPT architecture capture long-range synchronized dance movements. Additionally, the system exhibits scalability by generating extended dance sequences, adaptable to realistic and stylized human images. These design choices support scalability by managing data complexity and computational cost.
Shape Fidelity#
While ‘Shape Fidelity’ isn’t explicitly a section header, it’s a crucial aspect of image animation, particularly in the context of human figures. The paper implicitly addresses this through techniques aimed at preserving the subject’s individual characteristics throughout the animation. Methods that directly translate motion into 2D skeletons and then animate risk distorting the initial shape. Therefore, a more nuanced approach is adopted. The framework could incorporate identity-preserving loss functions during training to explicitly encourage the generated video to maintain a consistent appearance with the original still image. This could include perceptual losses that compare high-level features extracted from the original image and the animated frames. Also, there’s a need for robust handling of self-occlusions and extreme poses, where maintaining accurate shape becomes challenging. Techniques like incorporating a 3D prior or using learned shape representations could help the model reason about the underlying structure of the human body and generate more plausible and shape-consistent animations. The choice of latent space and how it encodes shape information also plays a crucial role. A well-designed latent space should be able to disentangle shape from pose, allowing the model to manipulate motion without significantly altering the character’s physical attributes. The paper’s approach emphasizes a balance between motion expressiveness and shape fidelity, recognizing that both are essential for creating realistic and visually appealing dance videos.
More visual insights#
More on figures

🔼 X-Dancer uses a two-stage approach. First, a transformer model processes music and generates a sequence of 2D human poses, broken down by body part (head, hands, upper body, lower body) for more nuanced control, and accounting for keypoint confidence to handle pose uncertainties. This model incorporates global musical context and prior poses for better temporal coherence. Second, a diffusion model uses these poses to animate a single reference image, leveraging a learnable motion decoder and AdaIN for high-quality, temporally smooth video generation that preserves the original image’s appearance.
read the caption
Figure 2: Overview of X-Dancer. We propose a cross-conditional transformer model to autoregressively generate 2D human poses synchronized with input music, followed by a diffusion model that produces high-fidelity videos from a single reference image IR.subscript𝐼𝑅I_{R}.italic_I start_POSTSUBSCRIPT italic_R end_POSTSUBSCRIPT . First, we develop a multi-part compositional tokenization for 2D poses, encoding and quantizing each body part independently with keypoint confidence. These tokens are then merged into a whole-body, confidence-aware pose using a shared decoder. Next, we train a GPT-based transformer to autoregressively predict future pose tokens with causal attention, conditioned on past poses and aligned music embeddings. For global music style and motion context, we incorporate the entire music sequence and sampled prior poses. With a learnable motion decoder, we generate multi-scale spatial pose guidance upsampled from a learned feature map, incorporating the generated motion tokens within a temporal window (16 frames) using AdaIN. By co-training the motion decoder and temporal modules, our diffusion model is capable of synthesizing temporally smooth and high-fidelity video frames, while maintaining consistent appearance with the reference image with a trained reference net.

🔼 Figure 3 presents a qualitative comparison of dance video generation results from different methods: X-Dancer, Hallo, Bailando + PoseGuider, and EDGE + PoseGuider. The figure visually demonstrates that X-Dancer produces the most expressive and high-fidelity dance videos. Importantly, X-Dancer’s generated videos maintain a high degree of consistency with the characteristics of the reference image (the person’s appearance and body shape) as well as the background of the original scene.
read the caption
Figure 3: Qualitative Comparisons. Among all the methods, X-Dancer achieves the most expressive and high-fidelity human dance video synthesis, maintaining the highest consistency with both the reference human characteristics and the background scene.
Full paper#