TL;DR#
LLMs like Chain-of-Thought (CoT) improve reasoning, but demand more computational resources and verbose outputs. This contrasts with human problem-solving, which captures essential insights with concise drafts. The discrepancy motivates this paper to pursue a more efficient strategy to align with human reasoning.
This paper introduces Chain of Draft (CoD), a novel strategy that mimics human thought processes by generating concise intermediate reasoning outputs. Results show CoD matching/surpassing CoT in accuracy, cutting token use to 7.6%, reducing cost/latency across tasks.
Key Takeaways#
Why does it matter?#
This paper introduces a new prompting strategy that reduces computational costs and latency without sacrificing accuracy, thus offering practical benefits for real-world LLM applications. CoD offers a middle ground between CoT and standard prompting, allowing for more efficient resource utilization and faster response times. It aligns LLMs with human-like reasoning, paving the way for future research in minimalist reasoning strategies.
Visual Insights#

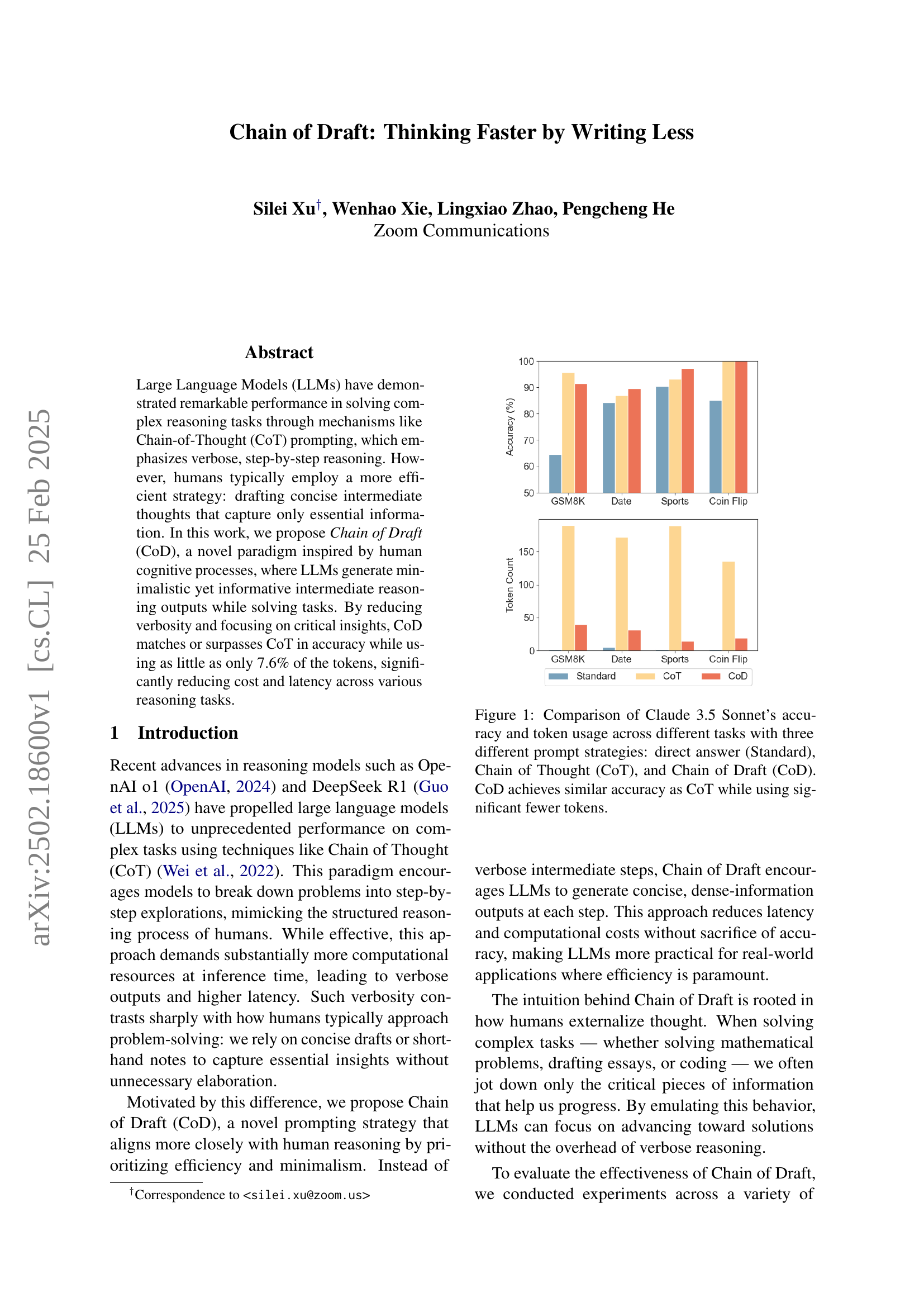
🔼 Figure 1 compares the performance of three different prompting strategies (Standard, Chain of Thought, and Chain of Draft) on Claude 3.5 Sonnet across various reasoning tasks (GSM8K, Date, Sports, Coin Flip). It shows that Chain of Draft (CoD) achieves comparable accuracy to Chain of Thought (CoT) but uses significantly fewer tokens (7.6%). The bar chart visually represents the accuracy and token usage for each task and strategy, highlighting CoD’s efficiency advantage.
read the caption
Figure 1: Comparison of Claude 3.5 Sonnet’s accuracy and token usage across different tasks with three different prompt strategies: direct answer (Standard), Chain of Thought (CoT), and Chain of Draft (CoD). CoD achieves similar accuracy as CoT while using significant fewer tokens.
| Model | Prompt | Accuracy | Token # | Latency |
|---|---|---|---|---|
| GPT-4o | Standard | 53.3% | 1.1 | 0.6 s |
| CoT | 95.4% | 205.1 | 4.2 s | |
| CoD | 91.1% | 43.9 | 1.0 s | |
| Claude 3.5 Sonnet | Standard | 64.6% | 1.1 | 0.9 s |
| CoT | 95.8% | 190.0 | 3.1 s | |
| CoD | 91.4% | 39.8 | 1.6 s |
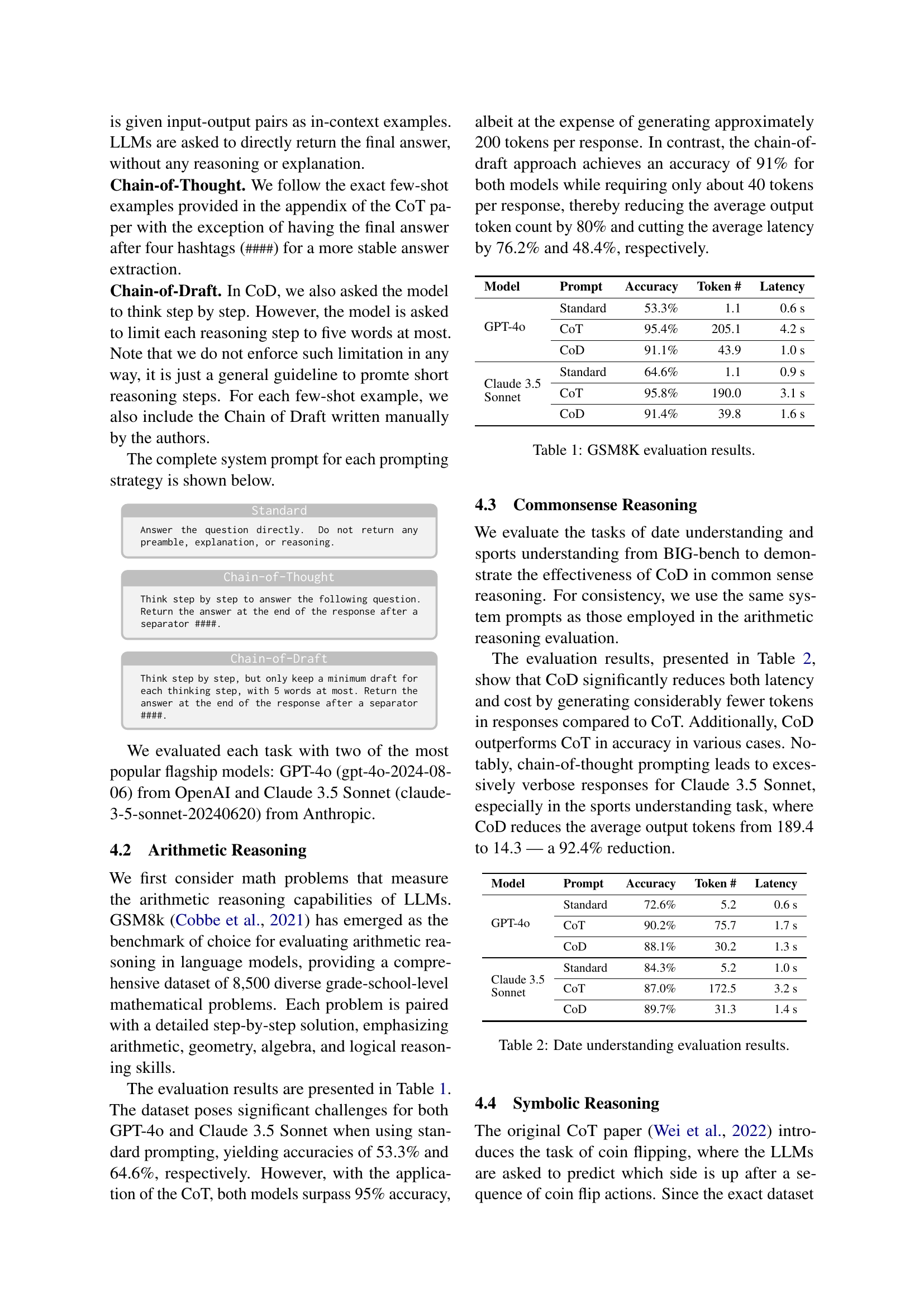
🔼 This table presents the results of evaluating the GSM8K benchmark dataset using three different prompting strategies: Standard, Chain-of-Thought (CoT), and Chain-of-Draft (CoD). For each strategy, it shows the accuracy achieved by the GPT-40 and Claude 3.5 Sonnet language models, along with the average number of tokens used and the latency experienced. This allows for a comparison of the accuracy, efficiency (in terms of tokens and time), and overall performance of the three prompting techniques on a complex arithmetic reasoning task.
read the caption
Table 1: GSM8K evaluation results.
In-depth insights#
Less is Faster#
Less is Faster encapsulates the idea that efficiency and conciseness can sometimes lead to better results than verbose and complex methods. This concept suggests that reducing the amount of information or steps involved in a process can paradoxically improve its speed and accuracy. This can be seen in various applications such as the Chain of Draft approach, which achieves high accuracy while using significantly fewer tokens. By focusing on essential information and avoiding unnecessary elaboration, systems can operate more efficiently, reducing both computational cost and latency. The principle also highlights the value of minimalism, emphasizing that simpler, more streamlined solutions can often outperform more intricate ones because they are easier to understand, implement, and maintain. This is vital for optimizing performance and enhancing usability.
CoD vs. CoT#
CoD (Chain of Draft) vs. CoT (Chain of Thought) represents a shift in reasoning strategy for LLMs. CoT emphasizes detailed, verbose, step-by-step reasoning, mirroring how humans might articulate their thoughts. However, CoD proposes a more efficient approach, inspired by how humans often jot down concise, essential insights when problem-solving. CoD aims to reduce verbosity by encouraging LLMs to generate minimalistic yet informative intermediate reasoning steps. This approach promises to decrease computational costs (token usage) and latency, making LLMs more practical for real-world scenarios where efficiency is crucial. The key difference lies in the level of detail; CoT is exhaustive, while CoD prioritizes essential information. Evaluations using CoD have shown accuracy levels that match or exceed CoT, but with significantly fewer tokens and lower latency. This suggests that LLMs don’t always need to spell out every detail to achieve correct reasoning, and focused, concise drafts can be more effective.
Human Thinking#
The paper cleverly draws inspiration from human cognitive processes, specifically the way we draft concise notes to capture essential information when solving complex problems. This is in contrast to the more verbose approach often seen in Chain-of-Thought prompting with LLMs. The idea is that humans often prioritize efficiency and minimalism, jotting down only the critical pieces of information needed to progress. The motivation behind CoD stems from the observation that LLMs’ verbose reasoning contrasts with efficient strategies humans employ. This offers a novel path forward.
Drafts = Insights#
The idea of “Drafts = Insights” highlights a shift in how we approach problem-solving with LLMs. Traditionally, LLMs are prompted to produce verbose, step-by-step reasoning, mirroring human thought processes but often inefficiently. This perspective suggests that concise, draft-like outputs can be equally, if not more, effective for complex tasks. By focusing on capturing essential information and key transformations in a minimal format, LLMs can emulate how humans jot down shorthand notes or crucial calculations during problem-solving. This approach potentially reduces computational cost and latency, making LLMs more practical for real-world applications. Further, the concept emphasizes that the value lies not in verbose expression but in the strategic selection of vital information. These concise drafts serve as insights, guiding the LLM toward the final solution more efficiently, suggesting a move toward more streamlined and insightful interactions with LLMs.
Cost Efficiency#
While the term “Cost Efficiency” isn’t explicitly a heading in this paper, the core concept is heavily woven throughout its arguments. The study introduces Chain of Draft (CoD) which improves computational efficiency and minimize usage of tokens in language models. The paper mentions CoD reduces the need for extensive computational power and decreases output token count by 80%, which directly corresponds to lower costs. A major focus of the paper is to find solutions to excessive resource consumption, which relates to Cost Efficiency. By reducing token count CoD enhances practical applicability in settings with budget restrictions.
More visual insights#
More on tables
| Model | Prompt | Accuracy | Token # | Latency |
|---|---|---|---|---|
| GPT-4o | Standard | 72.6% | 5.2 | 0.6 s |
| CoT | 90.2% | 75.7 | 1.7 s | |
| CoD | 88.1% | 30.2 | 1.3 s | |
| Claude 3.5 Sonnet | Standard | 84.3% | 5.2 | 1.0 s |
| CoT | 87.0% | 172.5 | 3.2 s | |
| CoD | 89.7% | 31.3 | 1.4 s |
🔼 This table presents the results of evaluating three different prompting strategies (Standard, Chain-of-Thought, and Chain-of-Draft) on the date understanding task from the BIG-bench benchmark. It shows the accuracy, the number of tokens used, and the latency for each prompting method and model (GPT-4 and Claude 3.5 Sonnet). The data illustrates the impact of the different prompting approaches on both model performance and efficiency.
read the caption
Table 2: Date understanding evaluation results.
| Model | Prompt | Accuracy | Token # | Latency |
|---|---|---|---|---|
| GPT-4o | Standard | 90.0% | 1.0 | 0.4 s |
| CoT | 95.9% | 28.7 | 0.9 s | |
| CoD | 98.3% | 15.0 | 0.7 s | |
| Claude 3.5 Sonnet | Standard | 90.6% | 1.0 | 0.9 s |
| CoT | 93.2% | 189.4 | 3.6 s | |
| CoD | 97.3% | 14.3 | 1.0 s |
🔼 This table presents the results of evaluating three different prompting strategies (Standard, Chain-of-Thought, and Chain-of-Draft) on a sports understanding task. It shows the accuracy, token count, and latency for each prompting method using two different Large Language Models (LLMs): GPT-40 and Claude 3.5 Sonnet. The results highlight the performance gains in terms of speed and efficiency achieved by using Chain-of-Draft compared to Chain-of-Thought while maintaining accuracy.
read the caption
Table 3: Sports understanding evaluation results.
| Model | Prompt | Accuracy | Token # | Latency |
|---|---|---|---|---|
| GPT-4o | Standard | 73.2% | 1.0 | 0.4 s |
| CoT | 100.0% | 52.4 | 1.4 s | |
| CoD | 100.0% | 16.8 | 0.8 s | |
| Claude 3.5 Sonnet | Standard | 85.2% | 1.0 | 1.2 s |
| CoT | 100.0% | 135.3 | 3.1 s | |
| CoD | 100.0% | 18.9 | 1.6 s |
🔼 This table presents the results of evaluating three prompting strategies (Standard, Chain-of-Thought, and Chain-of-Draft) on a symbolic reasoning task involving coin flips. It shows the accuracy, number of tokens used, and latency for each method using two different large language models (GPT-40 and Claude 3.5 Sonnet). The results demonstrate Chain-of-Draft’s ability to achieve high accuracy with significantly fewer tokens and lower latency compared to Chain-of-Thought.
read the caption
Table 4: Coin flip evaluation results.
Full paper#