TL;DR#
Generating ultra-long sequences with large language models is crucial, yet time-intensive. Existing methods like speculative decoding are insufficient for sequences up to 100K tokens due to limitations such as frequent model reloading, dynamic key-value management, and repetitive generation. Addressing this bottleneck is essential for unleashing LLMs’ full potential in real-world applications.
To solve this, the study introduces TokenSwift, a new framework that accelerates the generation of ultra-long sequences while maintaining model quality. TokenSwift uses n-gram retrieval and dynamic KV cache updates to achieve >3x speedup across different model scales and architectures, which alleviates model reloading, KV management and output repetition issues. The approach helps save hours of time.
Key Takeaways#
Why does it matter?#
This paper introduces TokenSwift, a novel framework designed to accelerate ultra-long sequence generation in LLMs. TokenSwift demonstrates superior acceleration performance and effectively mitigates issues related to repetitive content, which is essential for future research.
Visual Insights#
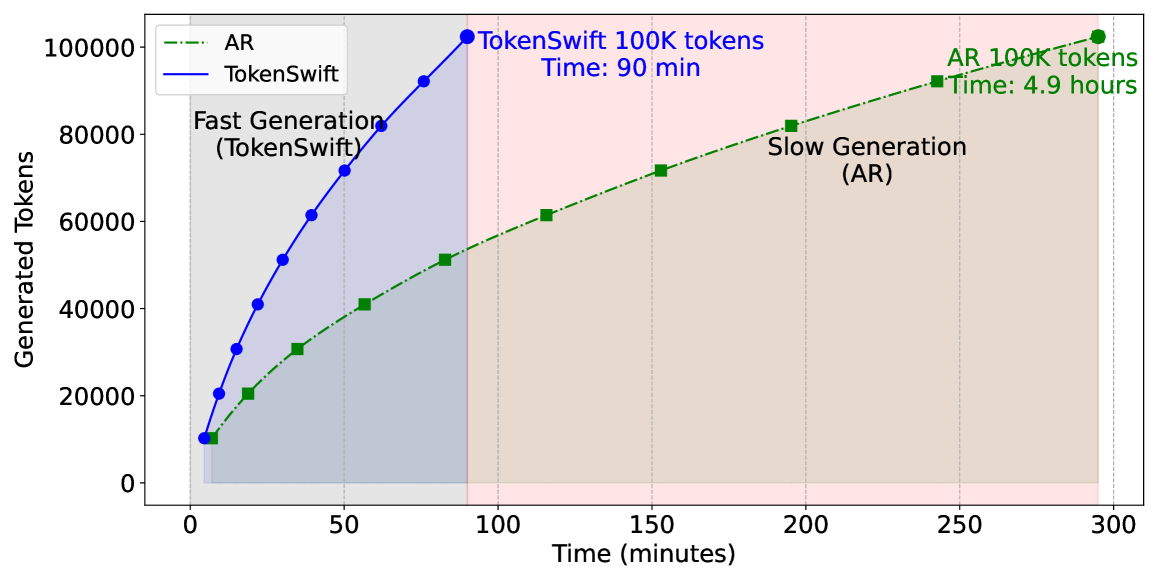
🔼 This figure compares the time taken to generate 100,000 tokens using two different methods: autoregressive (AR) generation and the TokenSwift method. The experiment was conducted using the LLaMA3.1-8b language model with a prefix length of 4096 tokens. The graph clearly shows that TokenSwift significantly reduces the generation time, from nearly 5 hours (around 300 minutes) for the AR method to just 90 minutes for the TokenSwift method. This demonstrates the substantial acceleration achieved by TokenSwift in generating ultra-long sequences.
read the caption
Figure 1: Comparison of the time taken to generate 100K tokens using autoregressive (AR) and TokenSwift with prefix length of 4096 on LLaMA3.1-8b. As seen, TokenSwift accelerates the AR process from nearly 5 hours to just 90 minutes.
| Method | Gen. Len. | Draft Form | Speed Up |
| TriForce | 256 | Standalone Draft | 1.02 |
| MagicDec | 64 | Self-Speculation | 1.20 |
| Standalone Draft | 1.06 |
🔼 This table presents a comparison of the performance of two speculative decoding methods, TriForce and MagicDec, when used with the LLaMA3.1-8b language model. It shows the generation length (Gen. Len.) each method was tested with, the type of draft used (Draft Form), and the resulting speedup achieved compared to a standard autoregressive generation approach. The results highlight that even with optimized methods, increasing generation length beyond short sequences significantly reduces the effectiveness of speculative decoding. The batch size for MagicDec was set to 1 for these experiments.
read the caption
Table 1: Experimental results of TriForce (Sun et al., 2024a) and MagicDec (Chen et al., 2024a) with default parameters on LLaMA3.1-8b. The Batch Size of MagicDec is set to 1.
In-depth insights#
Ultra-Long LLMs#
Ultra-long LLMs represent a significant leap in AI, enabling processing of extensive contexts. Key challenges include managing computational costs, preventing information loss over long sequences, and ensuring coherence. Efficient memory management and attention mechanisms are crucial for scalability. Innovations in sparse attention and hierarchical structures can help. Maintaining contextual relevance and avoiding repetitive outputs is vital. Furthermore, the demand for high-quality, diverse datasets tailored for ultra-long contexts becomes paramount. Addressing these aspects will unlock new applications such as comprehensive document summarization and creative content creation. The need to balance model size and computational efficiency will drive future research. Overcoming the above hurdles is important in ultra long LLMs.
Tokenswift Design#
While the provided content lacks a section explicitly titled ‘Tokenswift Design,’ the paper’s core innovation centers on an acceleration framework designed to optimize ultra-long sequence generation. The design likely addresses key bottlenecks: frequent model reloading, KV cache management, and repetitive content. TokenSwift probably employs techniques like multi-token generation to reduce model calls and dynamic KV cache updates to handle growing context efficiently. A contextual penalty mechanism might also be integrated to enhance output diversity. A careful balance between exploration (generating diverse candidate tokens) and exploitation (verifying and selecting the best ones) is at the heart of TokenSwift. To ensure efficiency, multi-token drafting with lightweight additional layers would be an advantage, coupled with token re-utilization based on n-gram frequency. Tree attention can also be leveraged. The overall design must also promote lossless sequence generation.
KV Cache Control#
KV cache control is crucial for efficient and scalable LLM inference, especially when dealing with long sequences. Managing the KV cache effectively mitigates memory bottlenecks and accelerates generation. Dynamic KV cache updates are essential to prioritize relevant information while discarding less important data. Strategies for calculating importance scores of KV pairs, such as using dot products between queries and keys, and optimizing attention mechanisms like Group Query Attention (GQA) can improve performance. Careful cache management ensures the model retains critical contextual information while minimizing memory usage, which is key for long sequence generation.
Diversity Matters#
In the context of LLMs, “Diversity Matters” underscores the importance of varied training data. Models trained on homogeneous datasets risk generating repetitive or biased outputs. A diverse dataset, encompassing various writing styles, topics, and perspectives, is crucial for robust performance. This enables the model to generalize better across different prompts and avoid overfitting to specific patterns. Diversity also extends to model architecture; experimenting with different architectures can improve a model’s ability to capture complex relationships in the data. Ensuring diversity throughout the model development lifecycle—from data curation to architectural design—leads to more reliable, adaptable, and unbiased LLMs.
Model Scale Up#
Scaling up models often yields improved performance due to their enhanced capacity to capture complex patterns. Larger models generally benefit from increased data, showcasing improved generalization. However, scaling brings challenges, including increased computational cost and memory requirements. Efficient training strategies, such as distributed training and mixed-precision, are crucial to address these limitations. Careful consideration is needed to balance model size and resource constraints for optimal deployment, and larger models may exhibit emergent behaviors, presenting both opportunities and risks. Evaluation metrics must consider both accuracy and efficiency, as the trade-offs become more pronounced with larger models.
More visual insights#
More on figures
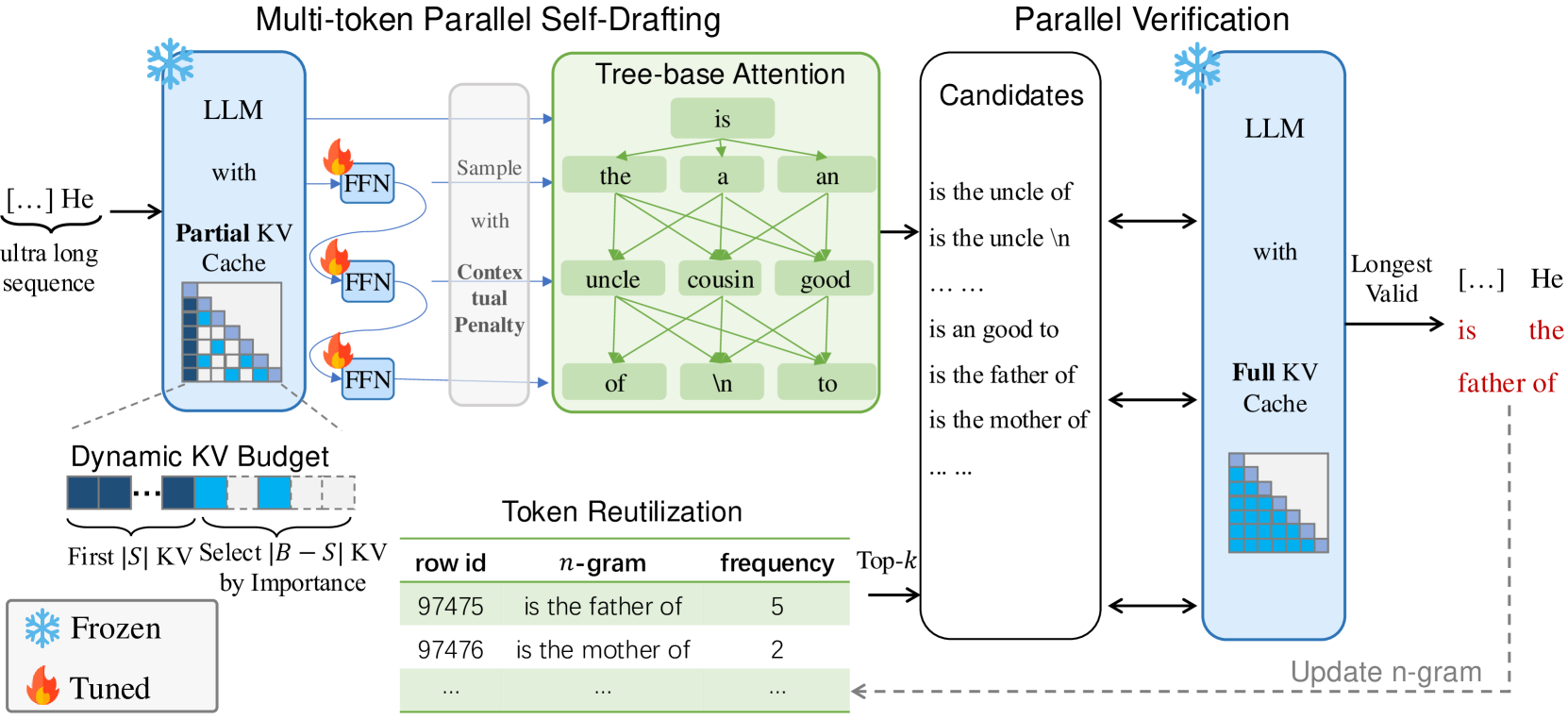
🔼 The TokenSwift framework accelerates ultra-long sequence generation by using a draft-then-verify approach. First, a target language model (LLM) with a limited key-value (KV) cache and three linear layers generates multiple prediction logits simultaneously. Tree-based attention selects the top-k 4-grams as candidate tokens. These are combined to form draft tokens, which are then passed to the full LLM (with complete KV cache) to generate target tokens. The draft and target tokens are compared; if they match exactly, the generation is deemed successful. Finally, the longest valid draft token is randomly chosen, and the n-gram table and KV cache are updated for the next iteration. This process minimizes frequent model reloads, streamlines KV management, and improves generation speed while preserving accuracy.
read the caption
Figure 2: Illustration of TokenSwift Framework. First, target model (LLM) with partial KV cache and three linear layers outputs 4 logits in a single forward pass. Tree-based attention is then applied to construct candidate tokens. Secondly, top-k𝑘kitalic_k candidate 4444-grams are retrieved accordingly. These candidates compose draft tokens, which are fed into the LLM with full KV cache to generate target tokens. The verification is performed by checking if draft tokens match exactly with target tokens (Algorithm 1). Finally, we randomly select one of the longest valid draft tokens, and update n𝑛nitalic_n-gram table and KV cache accordingly.
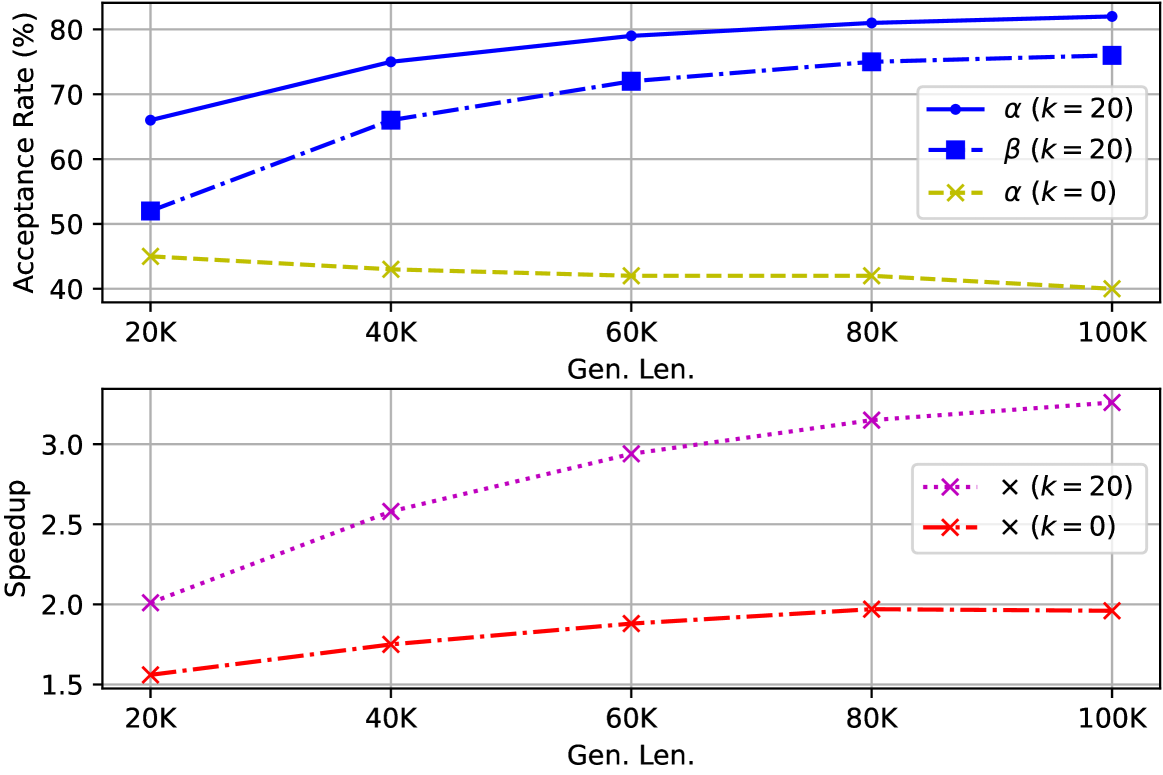
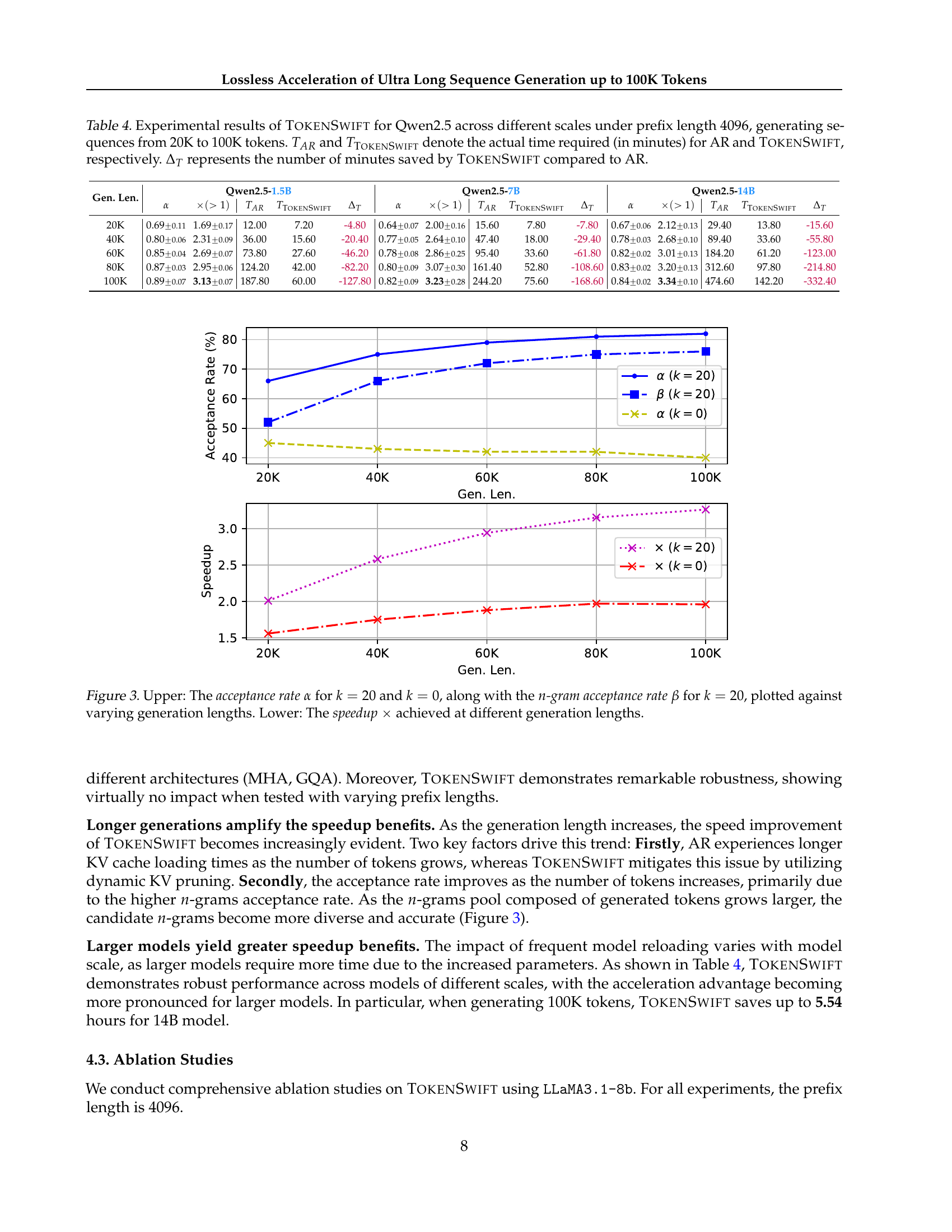
🔼 This figure compares the performance of TOKENSWIFT with different n-gram candidates (k=0 and k=20) across varying generation lengths. The upper panel shows the acceptance rate (α) for both k=0 and k=20, and the n-gram acceptance rate (β) for k=20. The lower panel displays the speedup (×) achieved by TOKENSWIFT compared to the autoregressive baseline (AR) for different generation lengths. This visualization helps demonstrate how the acceptance rate and speedup of TOKENSWIFT change with varying generation length and number of n-gram candidates.
read the caption
Figure 3: Upper: The acceptance rate α𝛼\alphaitalic_α for k=20𝑘20k=20italic_k = 20 and k=0𝑘0k=0italic_k = 0, along with the n𝑛nitalic_n-gram acceptance rate β𝛽\betaitalic_β for k=20𝑘20k=20italic_k = 20, plotted against varying generation lengths. Lower: The speedup ×\times× achieved at different generation lengths.
🔼 This table presents the ablation study results focusing on the impact of different KV (key-value) cache management strategies on the performance of the TOKENSWIFT model. It shows the acceptance rate (α) and speedup (×) achieved by three different KV management methods: Full Cache, Partial Cache, and Dynamic Partial Cache, for generating sequences of varying lengths (20K, 40K, 60K, 80K, and 100K tokens). The results illustrate the trade-offs between the efficiency of the KV management methods and the model’s overall performance in terms of acceptance rate and speedup.
read the caption
Table 5: The ablation experiment results on KV management.

🔼 This table presents an ablation study on the impact of contextual penalty and different sampling methods on the performance of the TokenSwift model. The experiment varied the contextual penalty parameter (θ) and penalty window size (W), while using top-p, min-p, and n-sampling methods. The table shows the Distinct-n scores (measuring text diversity) for each combination of these parameters. The highlighted cells indicate the parameter settings used in the main TokenSwift model (θ=1.2 and W=1024). The results demonstrate the effect of contextual penalty on reducing repetition in generated text, and its interaction with different sampling techniques.
read the caption
Table 6: The ablation experiment results on contextual penalty using different sampling methods. Light cell represents the settings adopted by TokenSwift. We take θ=1.2,W=1024formulae-sequence𝜃1.2𝑊1024\theta=1.2,W=1024italic_θ = 1.2 , italic_W = 1024.
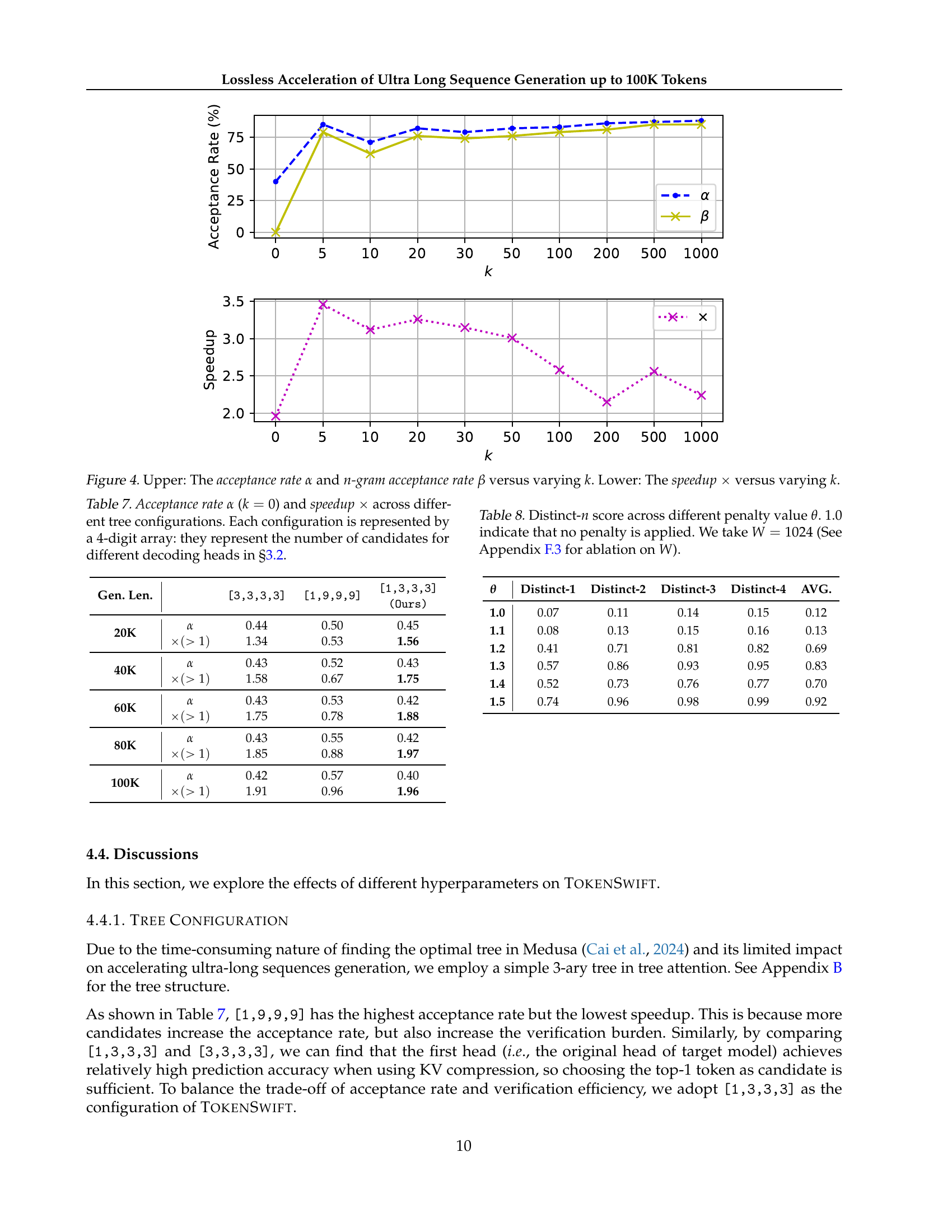
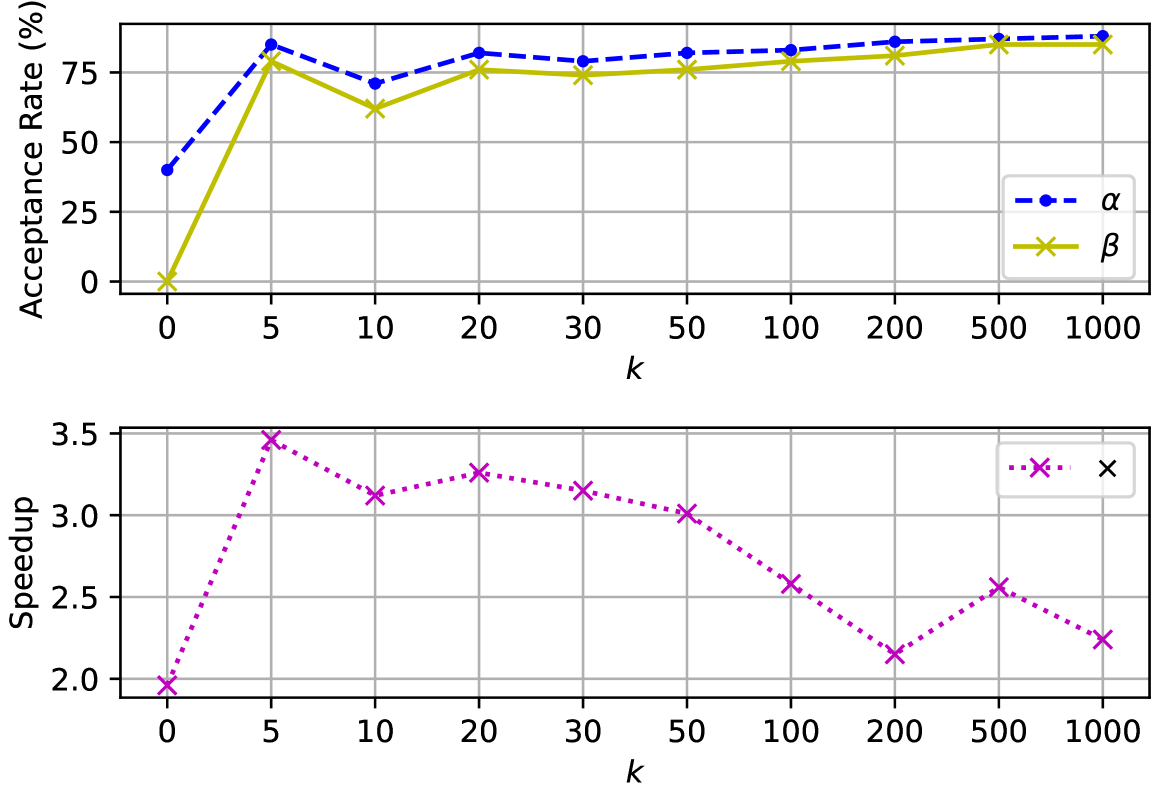
🔼 This figure shows the effects of varying the number of n-gram candidates (k) on the performance of the TOKENSWIFT model. The top panel displays the acceptance rate (α) and n-gram acceptance rate (β) as functions of k. The bottom panel shows the speedup (×) achieved by TOKENSWIFT relative to a standard autoregressive (AR) generation method, also as a function of k. The plots reveal the trade-off between using a larger number of candidates (improving acceptance rates) and the computational cost of evaluating more candidates (decreasing speedup).
read the caption
Figure 4: Upper: The acceptance rate α𝛼\alphaitalic_α and n𝑛nitalic_n-gram acceptance rate β𝛽\betaitalic_β versus varying k𝑘kitalic_k. Lower: The speedup ×\times× versus varying k𝑘kitalic_k.

🔼 Table 7 presents the results of an ablation study investigating the impact of different tree configurations on the performance of the TOKENSWIFT model in accelerating ultra-long sequence generation. The table shows the acceptance rate (α) and speedup (×) achieved with different tree configurations, where each configuration is represented by a 4-digit array. Each digit in the array specifies the number of candidate tokens considered for a given decoding head during the tree-based attention mechanism described in Section 3.2 of the paper. The study evaluates various configurations, comparing them to assess the balance between computational efficiency and accuracy. The results are useful in selecting the optimal tree structure for the model.
read the caption
Table 7: Acceptance rate α𝛼\alphaitalic_α (k=0𝑘0k=0italic_k = 0) and speedup ×\times× across different tree configurations. Each configuration is represented by a 4-digit array: they represent the number of candidates for different decoding heads in §3.2.
🔼 This table presents the Distinct-n scores for different values of the contextual penalty parameter (θ). Distinct-n measures the diversity of generated text; higher scores indicate greater diversity and less repetition. The experiment uses a penalty window size (W) of 1024 tokens. A value of θ = 1.0 indicates that no contextual penalty is applied. This table helps demonstrate the impact of the contextual penalty on the diversity of generated text when generating ultra-long sequences, as discussed in Section 4.3.4 of the paper. The effect of different penalty window sizes (W) is explored further in Section F.3.
read the caption
Table 8: Distinct-n𝑛nitalic_n score across different penalty value θ𝜃\thetaitalic_θ. 1.01.01.01.0 indicate that no penalty is applied. We take W=1024𝑊1024W=1024italic_W = 1024 (See Section F.3 for ablation on W𝑊Witalic_W).
🔼 This figure presents a case study to illustrate the impact of the contextual penalty on the generated text quality of LLaMA3.1-8b model. The left side shows the generated text without applying the contextual penalty, while the right side presents the text generated with the contextual penalty. The repeated sentences in both examples are highlighted in blue for easy identification. The figure demonstrates how the contextual penalty helps reduce the repetition problem often encountered in long text generation. More examples can be found in Appendix G.
read the caption
Figure 5: Case Study on LLaMA3.1-8b. Left: fragments of generated text without Contextual Penalty. Right: fragments of generated text with Contextual Penalty. The blue text is repetition part. See Appendix G for more cases.
🔼 This figure showcases a comparative analysis of text generation using the YaRN-LLaMA2-7b-128k model with and without the contextual penalty mechanism. The left side displays text generated without the penalty, highlighting instances of repetitive phrases marked in blue. In contrast, the right side presents text generated with the contextual penalty applied, demonstrating a significant reduction in repetitive content. This comparison visually illustrates the effectiveness of the contextual penalty in enhancing the diversity and fluency of ultra-long text generation.
read the caption
Figure 6: Case Study on YaRN-LLaMA2-7b-128k. Left: fragments of generated text without Contextual Penalty. Right: fragments of generated text with Contextual Penalty. The blue text is repetition part.
More on tables
| Memory | Computation |
| Bandwidth: 2.04e12 B/s | BF16: 312e12 FLOPS |
| Model Weights: 15.0 GB | MAX Operations: 83.9 GB |
| Loading Time: 7.4 ms | MAX Computing Time: 0.3 ms |
🔼 This table compares the memory bandwidth and computation performance of an NVIDIA A100 80G GPU when used with the LLaMA3.1-8b model. The ‘MAX’ scenario represents the maximum context window size of 128K tokens. The table shows the memory bandwidth, model weight size, loading time, floating-point operations per second (FLOPS), maximum operations, and maximum computing time. The calculation methodology for these metrics is based on the work of Yuan et al. (2024).
read the caption
Table 2: Taking NVIDIA A100 80G and LLaMA3.1-8b as example, MAX refers to the scenario with a maximum context window 128K. The calculation method is from Yuan et al. (2024).
| Method | Gen. Len. | Prefill Len. 2048 | Prefill Len. 4096 | Prefill Len. 8192 | Prefill Len. 2048 | Prefill Len. 4096 | Prefill Len. 8192 | ||||||
| YaRN-LLaMA2-7b-128k (MHA) | LLaMA3.1-8b (GQA) | ||||||||||||
| Medusa* | 20K | 0.43 | 0.96 | 0.39 | 0.85 | 0.40 | 0.83 | 0.35 | 1.20 | 0.39 | 1.29 | 0.34 | 1.21 |
| TriForce* | 0.80 | 1.50 | 0.89 | 1.51 | 0.92 | 1.36 | 0.89 | 1.13 | 0.89 | 1.08 | 0.99 | 1.16 | |
| TokenSwift | 0.73 | 2.11 | 0.68 | 2.02 | 0.64 | 1.91 | 0.64 | 1.87 | 0.65 | 1.93 | 0.72 | 1.99 | |
| Medusa* | 40K | 0.52 | 1.08 | 0.42 | 0.86 | 0.43 | 0.88 | 0.35 | 1.26 | 0.40 | 1.39 | 0.34 | 1.26 |
| TriForce* | 0.84 | 1.64 | 0.93 | 1.67 | 0.96 | 1.49 | 0.93 | 1.18 | 0.94 | 0.99 | 0.99 | 1.18 | |
| TokenSwift | 0.82 | 2.60 | 0.79 | 2.56 | 0.79 | 2.50 | 0.72 | 2.39 | 0.73 | 2.47 | 0.81 | 2.54 | |
| Medusa* | 60K | 0.59 | 1.18 | 0.47 | 0.95 | 0.45 | 0.91 | 0.35 | 1.29 | 0.40 | 1.42 | 0.34 | 1.29 |
| TriForce* | 0.85 | 1.76 | 0.95 | 1.83 | 0.97 | 1.62 | 0.94 | 1.21 | 0.95 | 0.96 | 1.00 | 1.19 | |
| TokenSwift | 0.87 | 2.92 | 0.85 | 2.89 | 0.85 | 2.84 | 0.75 | 2.73 | 0.79 | 2.88 | 0.85 | 2.93 | |
| Medusa* | 80K | 0.61 | 1.17 | 0.51 | 0.99 | 0.47 | 0.93 | 0.35 | 1.30 | 0.40 | 1.43 | 0.34 | 1.29 |
| TriForce* | 0.84 | 1.86 | 0.95 | 1.98 | 0.97 | 1.74 | 0.95 | 1.23 | 0.95 | 0.94 | 1.00 | 1.21 | |
| TokenSwift | 0.89 | 3.13 | 0.88 | 3.10 | 0.88 | 3.05 | 0.77 | 2.96 | 0.82 | 3.13 | 0.88 | 3.19 | |
| Medusa* | 100K | 0.62 | 1.15 | 0.52 | 0.99 | 0.47 | 0.91 | 0.35 | 1.31 | 0.41 | 1.45 | 0.34 | 1.29 |
| TriForce* | 0.82 | 1.94 | 0.96 | 2.14 | 0.97 | 1.86 | 0.95 | 1.25 | 0.96 | 0.92 | 0.99 | 1.22 | |
| TokenSwift | 0.90 | 3.25 | 0.90 | 3.23 | 0.90 | 3.20 | 0.79 | 3.13 | 0.84 | 3.27 | 0.90 | 3.38 | |
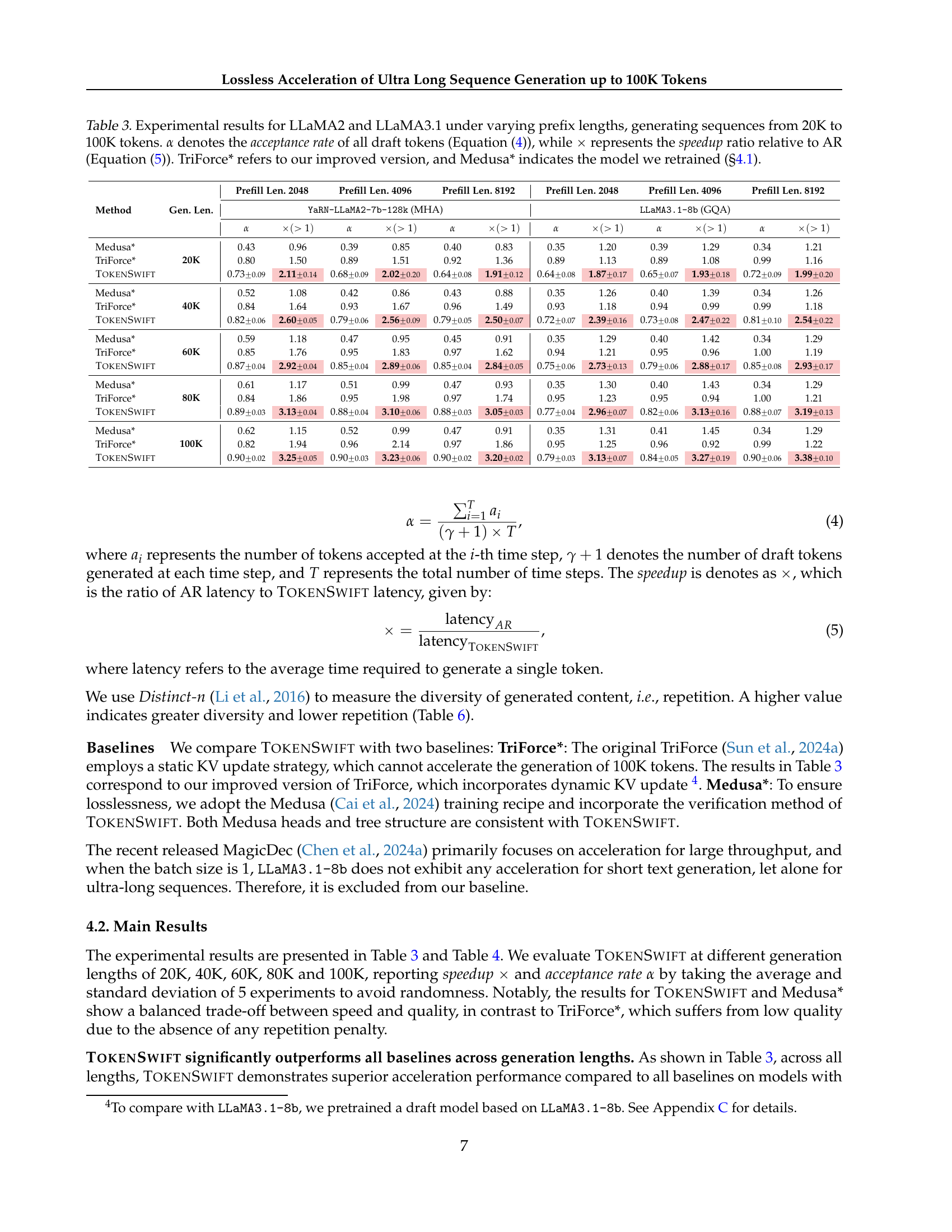
🔼 Table 3 presents a comprehensive evaluation of three different methods (Medusa*, TriForce*, and TOKENSWIFT) for generating sequences ranging from 20K to 100K tokens using two different language models (LLaMA2 and LLaMA3.1). For each method, the table shows the acceptance rate (α) and the speedup relative to the standard autoregressive (AR) approach (×). Different prefix lengths (2048, 4096, and 8192 tokens) are tested, providing a complete analysis of how each method performs under different conditions. Note that TriForce* and Medusa* represent improved and retrained versions of these methods respectively.
read the caption
Table 3: Experimental results for LLaMA2 and LLaMA3.1 under varying prefix lengths, generating sequences from 20K to 100K tokens. α𝛼\alphaitalic_α denotes the acceptance rate of all draft tokens (Equation 4), while ×\times× represents the speedup ratio relative to AR (Equation 5). TriForce* refers to our improved version, and Medusa* indicates the model we retrained (§4.1).
| Gen. Len. | Qwen2.5-1.5B | Qwen2.5-7B | Qwen2.5-14B | ||||||||||||
| 20K | 0.69 | 1.69 | 12.00 | 7.20 | -4.80 | 0.64 | 2.00 | 15.60 | 7.80 | -7.80 | 0.67 | 2.12 | 29.40 | 13.80 | -15.60 |
| 40K | 0.80 | 2.31 | 36.00 | 15.60 | -20.40 | 0.77 | 2.64 | 47.40 | 18.00 | -29.40 | 0.78 | 2.68 | 89.40 | 33.60 | -55.80 |
| 60K | 0.85 | 2.69 | 73.80 | 27.60 | -46.20 | 0.78 | 2.86 | 95.40 | 33.60 | -61.80 | 0.82 | 3.01 | 184.20 | 61.20 | -123.00 |
| 80K | 0.87 | 2.95 | 124.20 | 42.00 | -82.20 | 0.80 | 3.07 | 161.40 | 52.80 | -108.60 | 0.83 | 3.20 | 312.60 | 97.80 | -214.80 |
| 100K | 0.89 | 3.13 | 187.80 | 60.00 | -127.80 | 0.82 | 3.23 | 244.20 | 75.60 | -168.60 | 0.84 | 3.34 | 474.60 | 142.20 | -332.40 |
🔼 This table presents the performance of the TOKENSWIFT model on the Qwen2.5 large language model at different scales (1.5B, 7B, 14B parameters). The experiment generates text sequences ranging from 20K to 100K tokens, using a prefix length of 4096 tokens. The table compares the time taken by the standard autoregressive (AR) generation method against the time taken by the TOKENSWIFT method. The difference in time represents the time saved by using TOKENSWIFT. The acceptance rate (alpha) and speedup factor (x) are also provided for each condition. The results showcase the speedup achieved by TOKENSWIFT across various model sizes and sequence lengths.
read the caption
Table 4: Experimental results of TokenSwift for Qwen2.5 across different scales under prefix length 4096, generating sequences from 20K to 100K tokens. TARsubscript𝑇𝐴𝑅T_{AR}italic_T start_POSTSUBSCRIPT italic_A italic_R end_POSTSUBSCRIPT and TTokenSwiftsubscript𝑇TokenSwiftT_{\textsc{TokenSwift}}italic_T start_POSTSUBSCRIPT TokenSwift end_POSTSUBSCRIPT denote the actual time required (in minutes) for AR and TokenSwift, respectively. ΔTsubscriptΔ𝑇\Delta_{T}roman_Δ start_POSTSUBSCRIPT italic_T end_POSTSUBSCRIPT represents the number of minutes saved by TokenSwift compared to AR.
| Gen. Len. | Full Cache | Partial Cache | Dynamic Partial Cache | |
| 20K | 0.42 | 0.19 | 0.45 | |
| 1.36 | 0.94 | 1.56 | ||
| 40K | 0.42 | 0.16 | 0.43 | |
| 1.42 | 1.03 | 1.75 | ||
| 60K | 0.42 | 0.18 | 0.42 | |
| 1.45 | 1.19 | 1.88 | ||
| 80K | 0.42 | 0.19 | 0.42 | |
| 1.46 | 1.31 | 1.97 | ||
| 100K | 0.42 | 0.21 | 0.40 | |
| 1.47 | 1.44 | 1.96 |
🔼 This table details the hyperparameters used during the training phase of the linear layers added to the model. It includes optimizer, betas, weight decay, learning rate scheduler, number of GPUs used, gradient accumulation steps, batch size per GPU, number of steps, and learning rate. The note clarifies that these settings did not require extensive fine-tuning.
read the caption
Table 9: Additional training details. Note that these hyperparameters do not require extensive tuning.
| Distinct-1 | Distinct-2 | Distinct-3 | Distinct-4 | AVG. | ||
| top- | 0.15 | 0.25 | 0.29 | 0.31 | 0.25 | 3.42 |
| w/o. penalty | 0.09 | 0.15 | 0.18 | 0.20 | 0.16 | 3.53 |
| -sampling | 0.25 | 0.43 | 0.49 | 0.53 | 0.43 | 3.42 |
| w/o. penalty | 0.06 | 0.10 | 0.12 | 0.13 | 0.11 | 3.57 |
| min- | 0.41 | 0.71 | 0.81 | 0.82 | 0.69 | 3.27 |
| w/o. penalty | 0.07 | 0.11 | 0.14 | 0.15 | 0.12 | 3.58 |
🔼 This table shows the hyperparameters used during the inference stage for different language models. Specifically, it lists the maximum number of n-grams (k) retrieved for token reutilization, the temperature (temp), the top-p value, the minimum probability threshold (min-p), the contextual penalty value (penalty), and the length of the contextual penalty window (penalty len) used for each language model.
read the caption
Table 10: k𝑘kitalic_k stands for the maximum number of retrieved n-grams in token reutilization
| Gen. Len. | [3,3,3,3] | [1,9,9,9] | [1,3,3,3] | |
| (Ours) | ||||
| 20K | 0.44 | 0.50 | 0.45 | |
| 1.34 | 0.53 | 1.56 | ||
| 40K | 0.43 | 0.52 | 0.43 | |
| 1.58 | 0.67 | 1.75 | ||
| 60K | 0.43 | 0.53 | 0.42 | |
| 1.75 | 0.78 | 1.88 | ||
| 80K | 0.43 | 0.55 | 0.42 | |
| 1.85 | 0.88 | 1.97 | ||
| 100K | 0.42 | 0.57 | 0.40 | |
| 1.91 | 0.96 | 1.96 |
🔼 This table details the specific hyperparameters and architectural configurations used for training the 205 million parameter Llama 3.1 model, which serves as the draft model in the TriForce framework. The configuration includes specifications for hidden size, activation function, intermediate size, maximum positional embeddings, number of attention heads, key-value heads, rotary position embedding theta, and vocabulary size.
read the caption
Table 11: Configuration of Llama 3.1 205M.
| Distinct-1 | Distinct-2 | Distinct-3 | Distinct-4 | AVG. | |
| 1.0 | 0.07 | 0.11 | 0.14 | 0.15 | 0.12 |
| 1.1 | 0.08 | 0.13 | 0.15 | 0.16 | 0.13 |
| 1.2 | 0.41 | 0.71 | 0.81 | 0.82 | 0.69 |
| 1.3 | 0.57 | 0.86 | 0.93 | 0.95 | 0.83 |
| 1.4 | 0.52 | 0.73 | 0.76 | 0.77 | 0.70 |
| 1.5 | 0.74 | 0.96 | 0.98 | 0.99 | 0.92 |
🔼 This table presents the ablation study results when token reutilization is disabled, comparing the performance of different sampling methods: top-p, min-p, and -sampling. The results are shown for various sequence lengths (20K, 40K, 60K, 80K, and 100K tokens). For each method and sequence length, the table displays the acceptance rate (α) and the speedup (×) relative to the autoregressive baseline. The acceptance rate signifies the proportion of correctly generated tokens, while speedup quantifies the improvement in generation speed achieved by each sampling method compared to the autoregressive method.
read the caption
Table 12: Ablation results on various sampling methods with disable token reutilization.
| LLaMA3.1-8b | YaRN-LLaMA2-7b-128k | Qwen2.5-1.5b | Qwen2.5-7b | Qwen2.5-14b | |
| optimizer | AdamW | ||||
| betas | (0.9, 0.999) | ||||
| weight decay | 0.1 | ||||
| warmup steps | 50 | ||||
| learning rate scheduler | cosine | ||||
| num. GPUs | 4 | ||||
| gradient accumulation steps | 10 | ||||
| batch size per GPU | 3 | 1 | |||
| num. steps | 200 | 600 | |||
| learning rate | 5e-3 | 1e-3 | |||
🔼 This table presents the ablation study results on varying temperature settings while using top-p sampling with p = 0.9. It shows the impact of temperature on the acceptance rate (α), and speedup (×) for different generation lengths (20K to 100K tokens). Higher temperatures generally lead to lower acceptance rates but relatively stable or slightly lower speedups.
read the caption
Table 13: Ablation results on varying temperatures. Using top-p𝑝pitalic_p sampling, with p𝑝pitalic_p set to 0.90.90.90.9.
| temp. | top- | min- | penalty | penalty len. | ||
| LLaMA3.1-8b | 20 | 1.0 | - | 0.1 | 1.2 | 1024 |
| YaRN-LLaMA2-7b-128k | 0.9 | - | 1.15 | |||
| Qwen2.5-1.5b | 0.9 | - | 1.15 | |||
| Qwen2.5-7b | - | 0.05 | 1.15 | |||
| Qwen2.5-14b | - | 0.05 | 1.13 |
🔼 This table presents ablation study results showing the effects of different prefix lengths on the performance of the model when token reutilization is disabled. It examines the impact of varying prefix lengths (2048, 3072, 4096, 5120, 6144, 7168, 8192) on the model’s ability to generate sequences of varying lengths (20K, 40K, 60K, 80K, 100K tokens). The key metrics evaluated are acceptance rate (α), representing the percentage of draft tokens accepted during the generation process, and speedup (×), which indicates the acceleration achieved compared to the autoregressive baseline.
read the caption
Table 14: Ablation results on different prefill length disable token reutilization.
| hidden_size | 768 |
| hidden_act | silu |
| intermediate_size | 3072 |
| max_position_embeddings | 2048 |
| num_attention_heads | 12 |
| num_key_value_heads | 12 |
| rope_theta | 500000 |
| vocab_size | 128256 |
🔼 This table presents the ablation study results on the impact of different penalty window sizes (W) on the performance of the model for generating ultra-long sequences. It shows how varying the penalty window size affects the acceptance rate (α), speedup (×), and diversity (Distinct-n) of the generated sequences for different lengths (from 20K to 100K tokens). The table helps to analyze the trade-off between mitigating repetition (through the penalty mechanism) and achieving high generation speed and diversity.
read the caption
Table 15: Ablation results on penalty length (W𝑊Witalic_W).
| Gen. Len. | top- | min- | -sampling (2e-4) | |
| 20K | 0.68 | 0.66 | 0.56 | |
| 2.10 | 2.01 | 1.85 | ||
| 40K | 0.81 | 0.75 | 0.71 | |
| 2.80 | 2.58 | 2.59 | ||
| 60K | 0.84 | 0.79 | 0.78 | |
| 3.07 | 2.94 | 2.99 | ||
| 80K | 0.86 | 0.81 | 0.81 | |
| 3.28 | 3.15 | 3.24 | ||
| 100K | 0.87 | 0.82 | 0.84 | |
| 3.42 | 3.26 | 3.42 |
🔼 This table presents the Distinct-n scores, a metric assessing text diversity, for various penalty window sizes (W). Distinct-n counts the number of unique n-grams in a generated text sequence; higher scores indicate greater diversity. The table shows how the diversity of generated text changes as the penalty window size varies, illustrating the impact of the contextual penalty mechanism on text generation quality and repetitiveness.
read the caption
Table 16: Distinct-n𝑛nitalic_n score with different penalty length W𝑊Witalic_W.
Full paper#