TL;DR#
Recent progress in auto-regressive models has overshadowed advancements in encoders like BERT, crucial for many NLP tasks. There’s a growing need for updated encoders leveraging modern techniques. Existing solutions focus on fine-tuning but neglect inherent limitations of pre-trained backbones. The lack of standardized evaluation makes comparison between the pre-trained backbones difficult.
To tackle this, the study introduces NeoBERT, a next-generation encoder with state-of-the-art architecture, data, and training methods. It is a plug-and-play replacement with an optimal depth-to-width ratio and an extended context length. It uses a standardized fine-tuning to ensure fair evaluation and achieves state-of-the-art results on MTEB with only 250M parameters. The released code, data, and checkpoints promote research.
Key Takeaways#
Why does it matter?#
NeoBERT offers researchers a robust, efficient, and accessible encoder model, pushing the boundaries of bidirectional language understanding and providing a valuable tool for diverse NLP applications, especially in resource-constrained environments. Its detailed ablation studies and standardized evaluation framework promote reproducibility and fair comparisons.
Visual Insights#

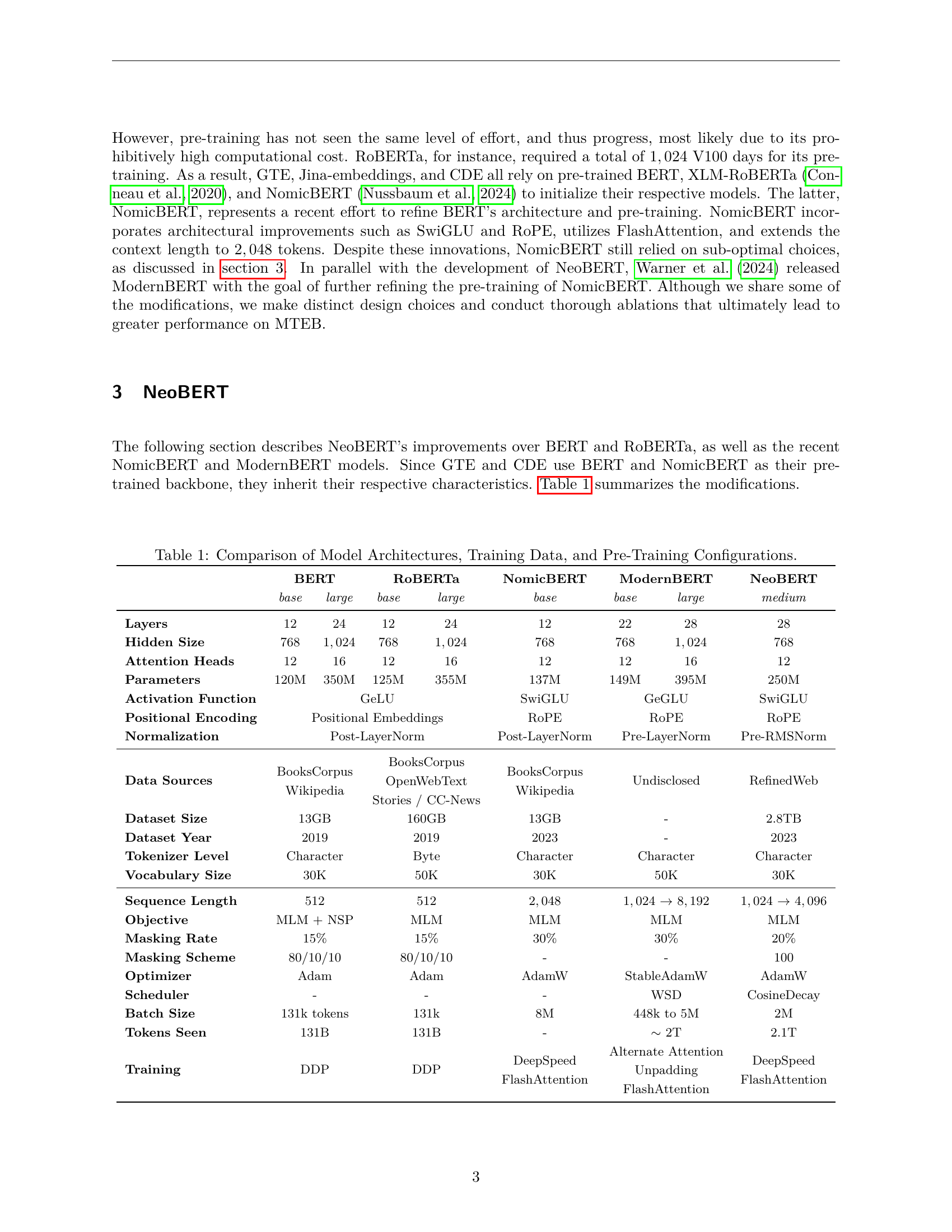
🔼 This figure displays the results of an ablation study conducted on the GLUE benchmark. The study systematically incorporates modifications to a BERT-base model, evaluating the impact of each change on the overall GLUE score. The x-axis represents the successive models (M0-M10), with each model incorporating a modification. The y-axis shows the GLUE development set score. The figure highlights that increasing dataset size (M2) and model size (M7) lead to the largest positive impact on performance. Conversely, modifying the tokenizer (M3) and packing sequences (M6) result in significant performance decreases. The greyed-out modifications indicate changes that were not included in subsequent model iterations.
read the caption
Figure 1: GLUE ablation scores on the development set. Modifications in grey are not included in the subsequent models. Increasing data size and diversity leads to the highest relative improvement (M2𝑀2M2italic_M 2, +3.6%percent3.6+3.6\%+ 3.6 %), followed by the model size (M7𝑀7M7italic_M 7, +2.9%percent2.9+2.9\%+ 2.9 %). Packing the sequences and using the LLaMA 2 tokenizer cause the largest relative drops (M6𝑀6M6italic_M 6, −2.9%percent2.9-2.9\%- 2.9 %, M3𝑀3M3italic_M 3, −2.1%percent2.1-2.1\%- 2.1 %).
| BERT | RoBERTa | NomicBERT | ModernBERT | NeoBERT | |||||||||||
| base | large | base | large | base | base | large | medium | ||||||||
| Layers | 12 | 24 | 12 | 24 | 12 | 22 | 28 | 28 | |||||||
| Hidden Size | 768 | 768 | 768 | 768 | 768 | ||||||||||
| Attention Heads | 12 | 16 | 12 | 16 | 12 | 12 | 16 | 12 | |||||||
| Parameters | 120M | 350M | 125M | 355M | 137M | 149M | 395M | 250M | |||||||
| Activation Function | GeLU | SwiGLU | GeGLU | SwiGLU | |||||||||||
| Positional Encoding | Positional Embeddings | RoPE | RoPE | RoPE | |||||||||||
| Normalization | Post-LayerNorm | Post-LayerNorm | Pre-LayerNorm | Pre-RMSNorm | |||||||||||
| Data Sources |
|
|
| Undisclosed | RefinedWeb | ||||||||||
| Dataset Size | 13GB | 160GB | 13GB | - | 2.8TB | ||||||||||
| Dataset Year | 2019 | 2019 | 2023 | - | 2023 | ||||||||||
| Tokenizer Level | Character | Byte | Character | Character | Character | ||||||||||
| Vocabulary Size | 30K | 50K | 30K | 50K | 30K | ||||||||||
| Sequence Length | 512 | 512 | |||||||||||||
| Objective | MLM + NSP | MLM | MLM | MLM | MLM | ||||||||||
| Masking Rate | 15% | 15% | 30% | 30% | 20% | ||||||||||
| Masking Scheme | 80/10/10 | 80/10/10 | - | - | 100 | ||||||||||
| Optimizer | Adam | Adam | AdamW | StableAdamW | AdamW | ||||||||||
| Scheduler | - | - | - | WSD | CosineDecay | ||||||||||
| Batch Size | 131k tokens | 131k | 8M | 448k to 5M | 2M | ||||||||||
| Tokens Seen | 131B | 131B | - | 2T | 2.1T | ||||||||||
| Training | DDP | DDP |
|
|
| ||||||||||
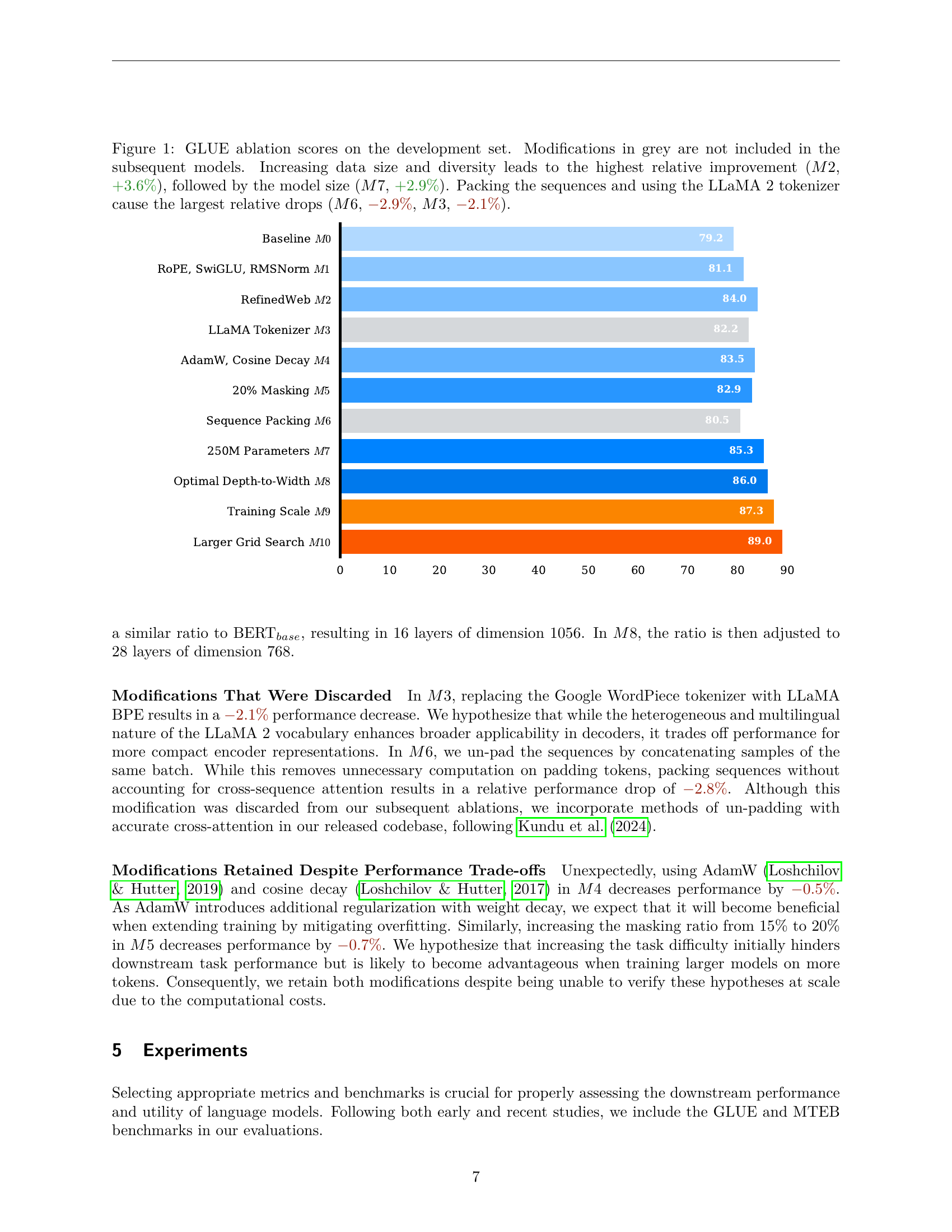
🔼 This table provides a detailed comparison of the architectures, training data, and pre-training configurations used for several BERT-like language models, including BERT, RoBERTa, NomicBERT, ModernBERT, and NeoBERT. For each model, it lists key architectural parameters such as the number of layers, hidden size, attention heads, and the total number of parameters. It also details the training data used (size and source), the vocabulary size, sequence length, the pre-training objective (masked language modeling, and next sentence prediction if used), masking rate, masking scheme, optimizer, learning rate scheduler, batch size, and the total number of tokens seen during training. This allows for a comprehensive understanding of the differences in model design and training procedures across these related models.
read the caption
Table 1: Comparison of Model Architectures, Training Data, and Pre-Training Configurations.
In-depth insights#
NeoBERT Intro#
NeoBERT, a next-generation encoder, aims to bridge the gap between the rapid advancements in auto-regressive language models and the relatively stagnant progress of bidirectional encoders like BERT and RoBERTa. The paper addresses the need for incorporating state-of-the-art innovations in architecture, data, and pre-training methodologies into BERT-like models. NeoBERT is designed for seamless adoption as a plug-and-play replacement, with an optimal depth-to-width ratio and an extended context length. It achieves superior results on the MTEB benchmark while maintaining a compact size, outperforming larger models. The authors also emphasize their commitment to open research by releasing all code, data, checkpoints, and training scripts. This makes NeoBERT a valuable contribution to the NLP community.
GLUE Analysis#
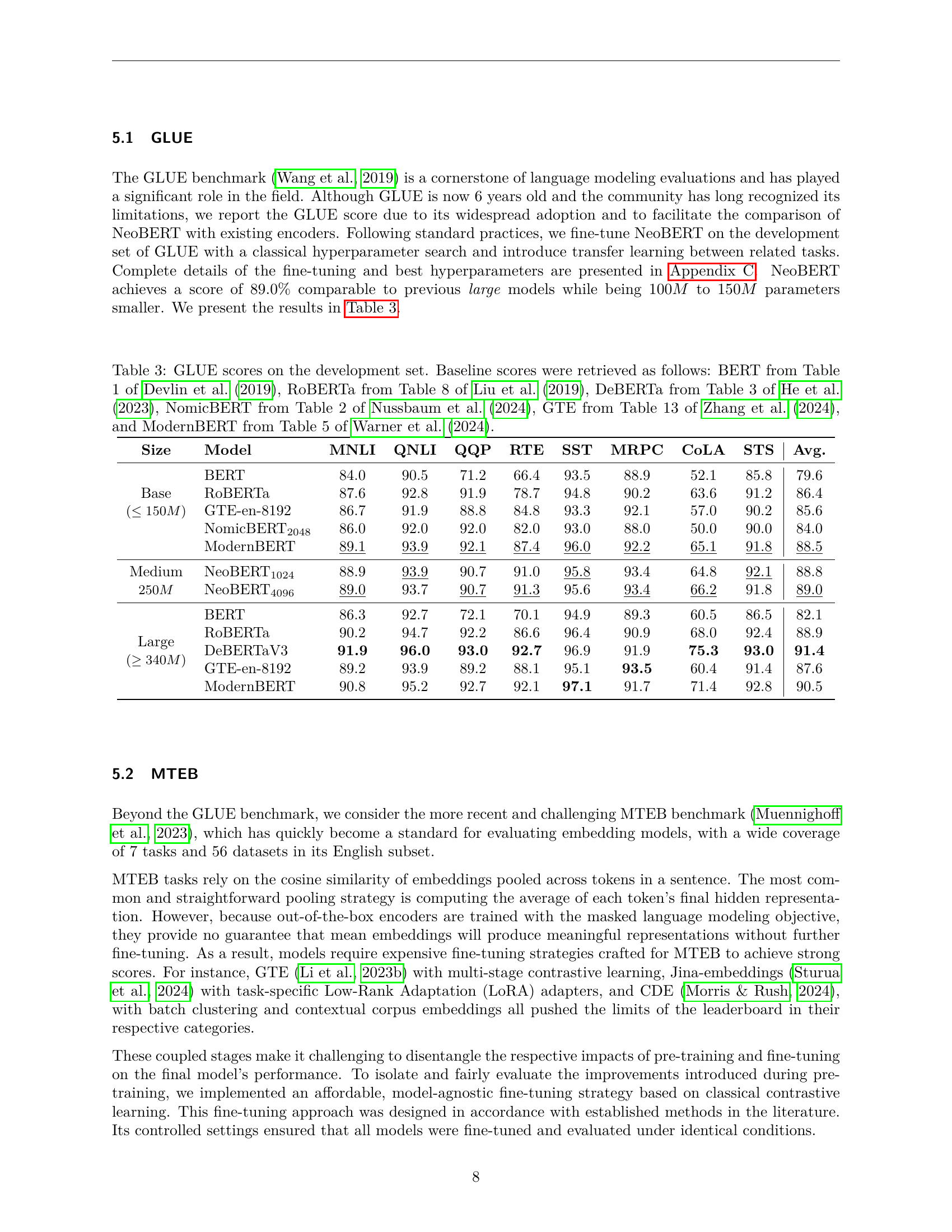
The GLUE benchmark’s role as a cornerstone for language modeling is discussed, yet its limitations due to its age and tendency for models to overfit are acknowledged. Despite these limitations, the paper uses GLUE scores to allow for comparison with existing encoders. To fine-tune, the standard practices are followed: classical hyperparameter search and transfer learning between related tasks. As a result of the above NeoBERT shows comparable results to large models, despite being 100M to 150M parameters smaller, and the full results are in Table 3.
MTEB Focus#
The paper emphasizes MTEB (Massive Text Embedding Benchmark) as a crucial evaluation benchmark, going beyond traditional metrics like GLUE. It highlights MTEB’s capacity to assess embedding models across diverse tasks. A key focus is the decoupling of pre-training and fine-tuning impacts on MTEB performance. The authors critique existing approaches that heavily rely on complex, task-specific fine-tuning, making it difficult to isolate the benefits of the underlying pre-trained models. They advocate for a standardized, model-agnostic fine-tuning strategy to fairly compare different pre-training techniques. The approach emphasizes the need for simple, reproducible fine-tuning. The core idea is to establish a clear understanding of how pre-training enhancements translate to downstream performance without the confounding effects of intricate fine-tuning methods. Ultimately, this helps drive progress in pre-training and unlocks more generalizable encoder models.
Future Encoder#
While the provided paper centers on NeoBERT, a next-generation encoder model, and doesn’t explicitly detail ‘Future Encoder’ concepts, one can infer potential advancements. Future encoders will likely leverage novel architectural designs beyond the current Transformer, perhaps exploring attention alternatives or incorporating ideas from mixture of experts paradigm. They will be pre-trained on increasingly massive and diverse datasets, potentially synthetic or incorporating multi-modal information. Future progress includes efficient long context handling using techniques like sparse attention or recurrence, allowing modeling of complex relationships. Crucially, future research will involve standardizing fine-tuning protocols and developing zero-shot evaluation methods to ensure unbiased assessments and fair comparisons of different encoder architectures, contributing towards robust, adaptable, and high-performing models.
Training Detail#
The training details section is crucial for understanding the experimental setup. NeoBERT used 8 H100 GPUs for 1,050,000 steps, totaling 6,000 GPU hours, showcasing resource intensity. A local batch size of 32 was used with 8 gradient accumulation steps, equaling a 2M token batch size. The max sequence length was 1,024 initially, and raised to 4,096 later. Keeping the batch size fixed while extending sequence length is vital, influencing model performance. This methodology helps maximize memory and compute resources during training, optimizing the architecture and training hyperparameters.
More visual insights#
More on figures

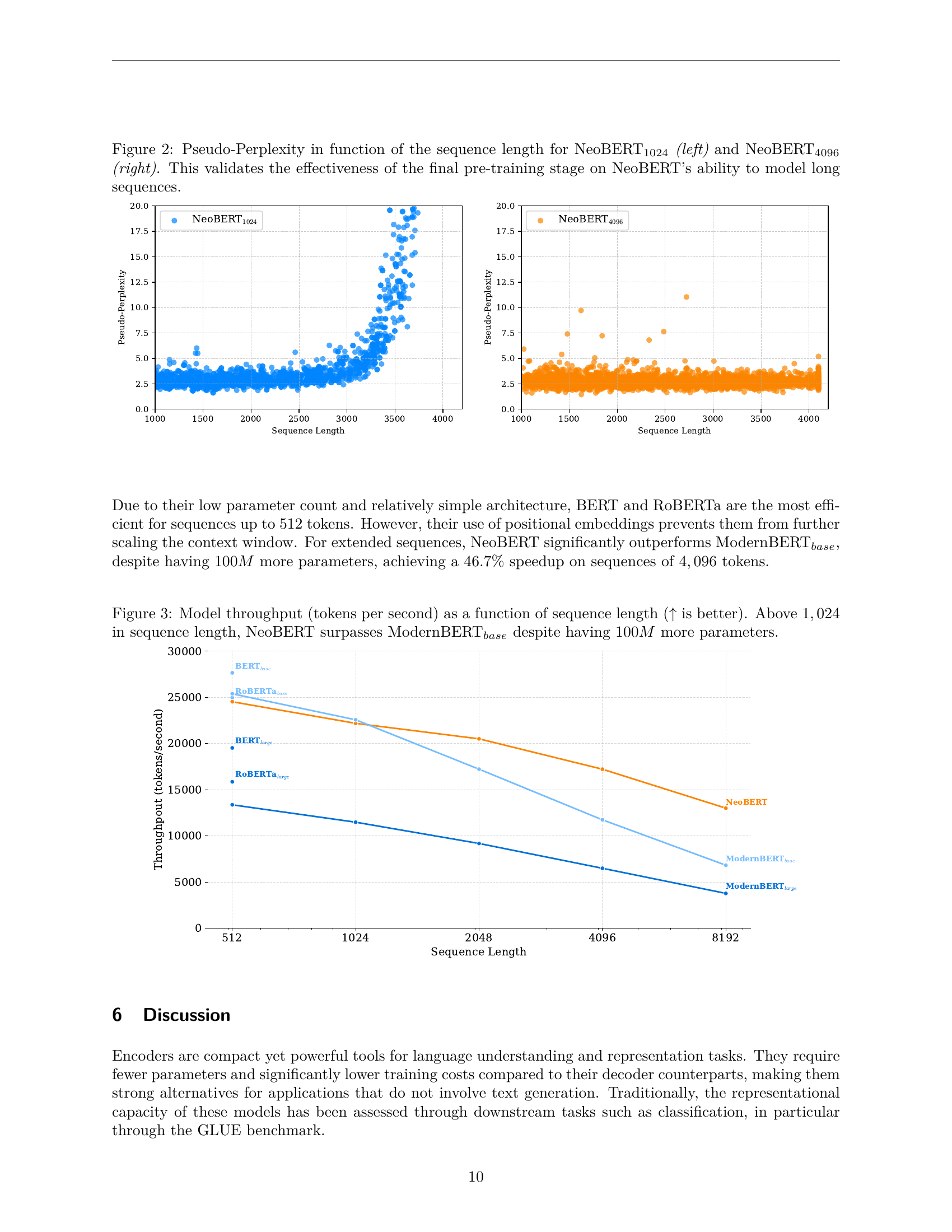
🔼 Figure 2 presents a comparison of the pseudo-perplexity scores achieved by two versions of the NeoBERT model – NeoBERT1024 and NeoBERT4096 – across varying sequence lengths. Pseudo-perplexity serves as a measure of how well the model predicts the next token in a sequence; lower scores indicate better performance. The left panel shows NeoBERT1024’s performance, trained with a maximum sequence length of 1024 tokens. The right panel shows NeoBERT4096, which underwent an additional training phase with longer sequences (up to 4096 tokens). The figure demonstrates that extending the pre-training with longer sequences significantly improves the NeoBERT model’s ability to handle and generate longer sequences accurately, as evidenced by the lower perplexity scores for NeoBERT4096, particularly at longer sequence lengths.
read the caption
Figure 2: Pseudo-Perplexity in function of the sequence length for NeoBERT1024 (left) and NeoBERT4096 (right). This validates the effectiveness of the final pre-training stage on NeoBERT’s ability to model long sequences.

🔼 Figure 3 illustrates the throughput (tokens processed per second) of various language models as the sequence length increases. The models compared are BERTbase, ROBERTabase, BERTlarge, ROBERTalarge, NeoBERT, ModernBERTbase, and ModernBERTlarge. The x-axis represents the sequence length, and the y-axis represents the throughput. The figure shows that NeoBERT, despite having 100 million more parameters than ModernBERTbase, achieves a significantly higher throughput when the sequence length exceeds 1024 tokens. This highlights NeoBERT’s efficiency in handling long sequences.
read the caption
Figure 3: Model throughput (tokens per second) as a function of sequence length (↑↑\uparrow↑ is better). Above 1,02410241,0241 , 024 in sequence length, NeoBERT surpasses ModernBERTbase despite having 100M100𝑀100M100 italic_M more parameters.
🔼 This figure displays the performance of BERT and RoBERTa models on the English subset of the MTEB benchmark without any fine-tuning. It demonstrates the zero-shot performance of these models, meaning their performance is evaluated directly after pre-training without any task-specific adaptation. The graph likely shows the average score across multiple tasks within the MTEB benchmark, indicating the models’ inherent abilities to handle various tasks before any further training or optimization.
read the caption
Figure 4: Zero-shot evaluation of BERT and RoBERTa on the English subset of MTEB.
More on tables
| BooksCorpus |
| Wikipedia |
🔼 This table details the modifications made during a series of ablation experiments to improve a BERT-like model, ultimately resulting in NeoBERT. It shows the changes introduced iteratively to the base model (M0, similar to BERT) in each step (M1-M9), highlighting modifications to embeddings, activation functions, normalization, datasets, tokenizers, optimizers, schedulers, masking schemes, model size, and context length. The final model, M9, represents NeoBERT.
read the caption
Table 2: Modifications between successive ablations. The initial M0𝑀0M0italic_M 0 baseline corresponds to a model similar to BERT, while M9𝑀9M9italic_M 9 corresponds to NeoBERT.
| BooksCorpus |
| OpenWebText |
| Stories / CC-News |
🔼 This table presents the GLUE (General Language Understanding Evaluation) benchmark scores achieved by various language models on their development sets. It compares the performance of NeoBERT against several established models including BERT, RoBERTa, DeBERTa, NomicBERT, GTE, and ModernBERT. The scores are broken down by individual tasks within the GLUE benchmark, allowing for a detailed comparison of each model’s strengths and weaknesses across different NLP tasks. The table also indicates the size (in parameters) of each model, showing how NeoBERT’s performance compares even with smaller model size.
read the caption
Table 3: GLUE scores on the development set. Baseline scores were retrieved as follows: BERT from Table 1 of Devlin et al. (2019), RoBERTa from Table 8 of Liu et al. (2019), DeBERTa from Table 3 of He et al. (2023), NomicBERT from Table 2 of Nussbaum et al. (2024), GTE from Table 13 of Zhang et al. (2024), and ModernBERT from Table 5 of Warner et al. (2024).
| BooksCorpus |
| Wikipedia |
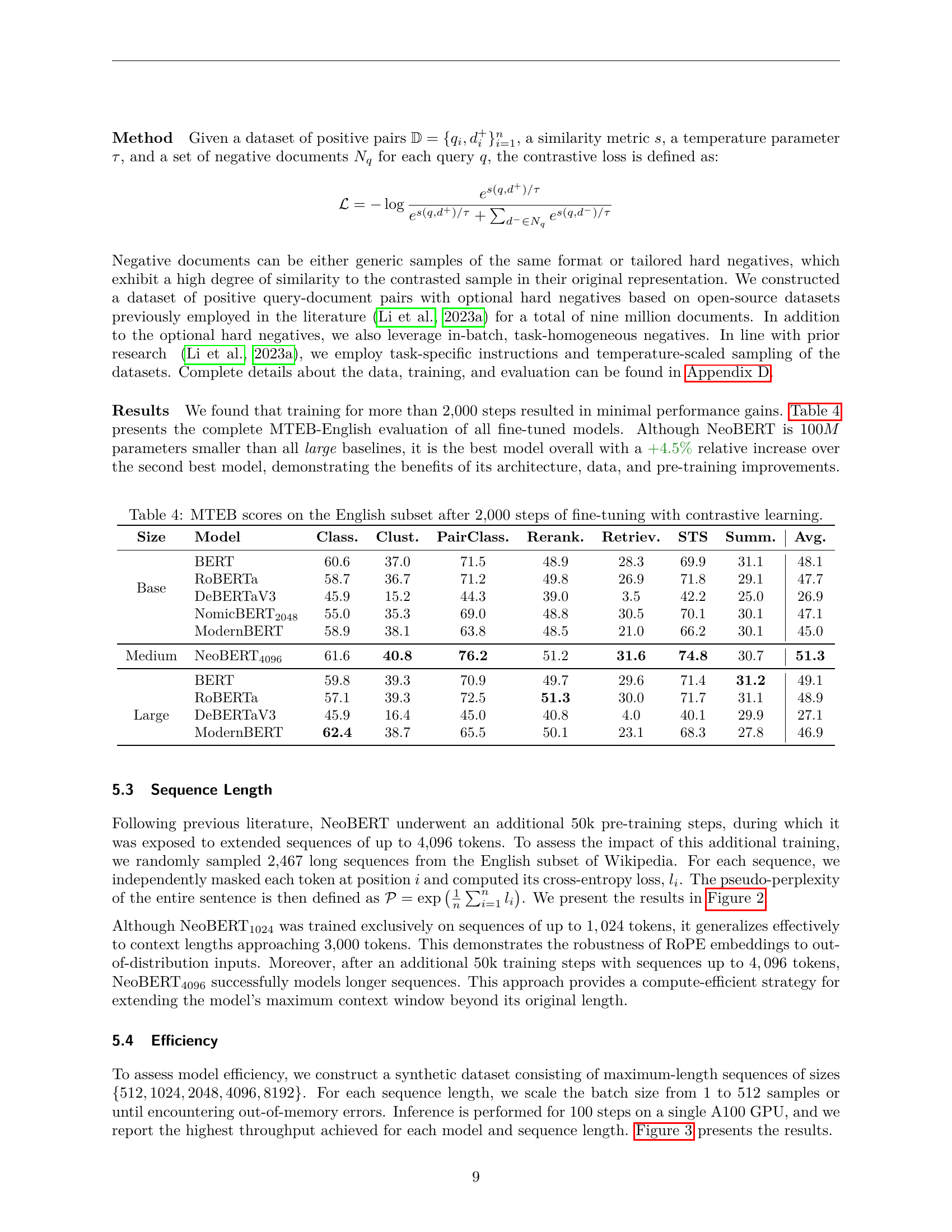
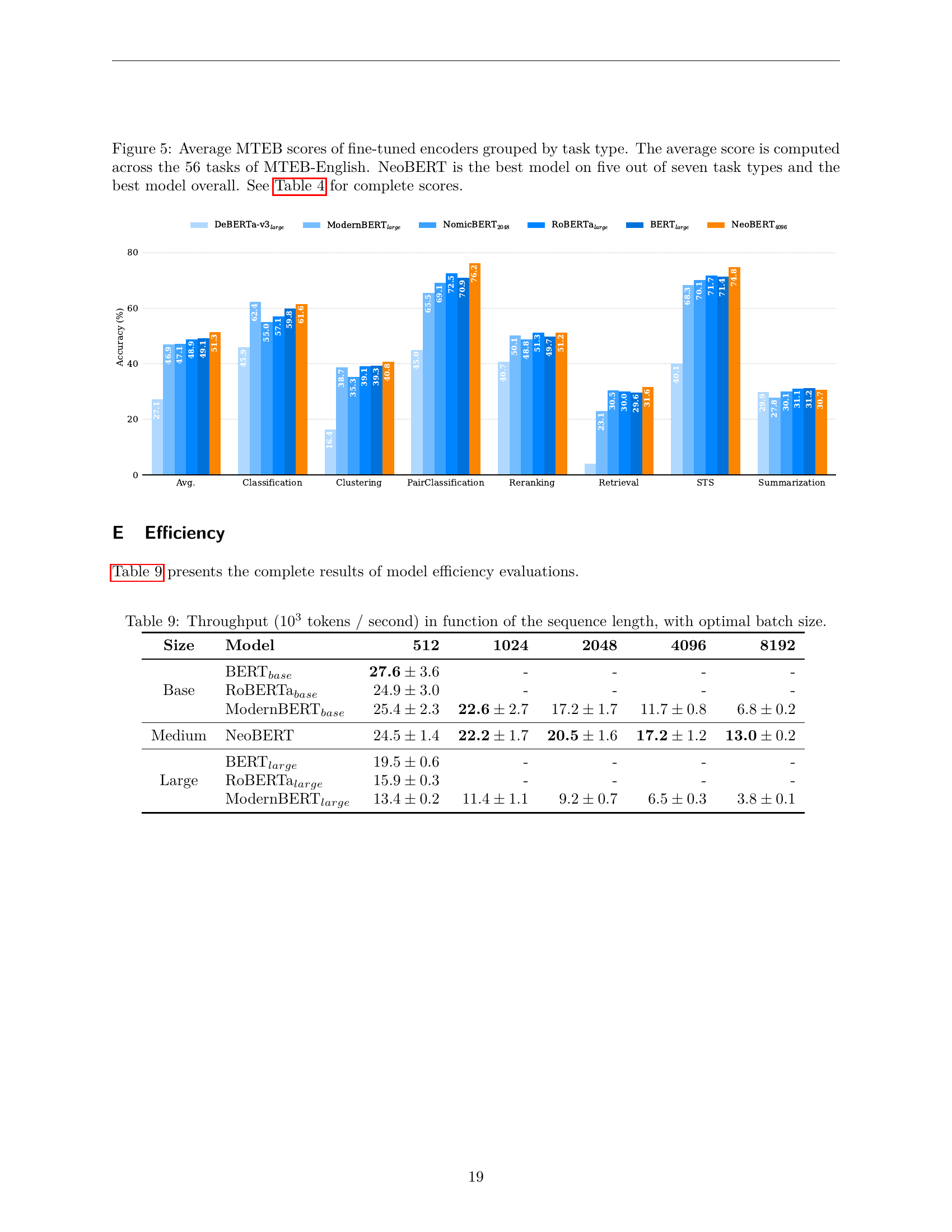
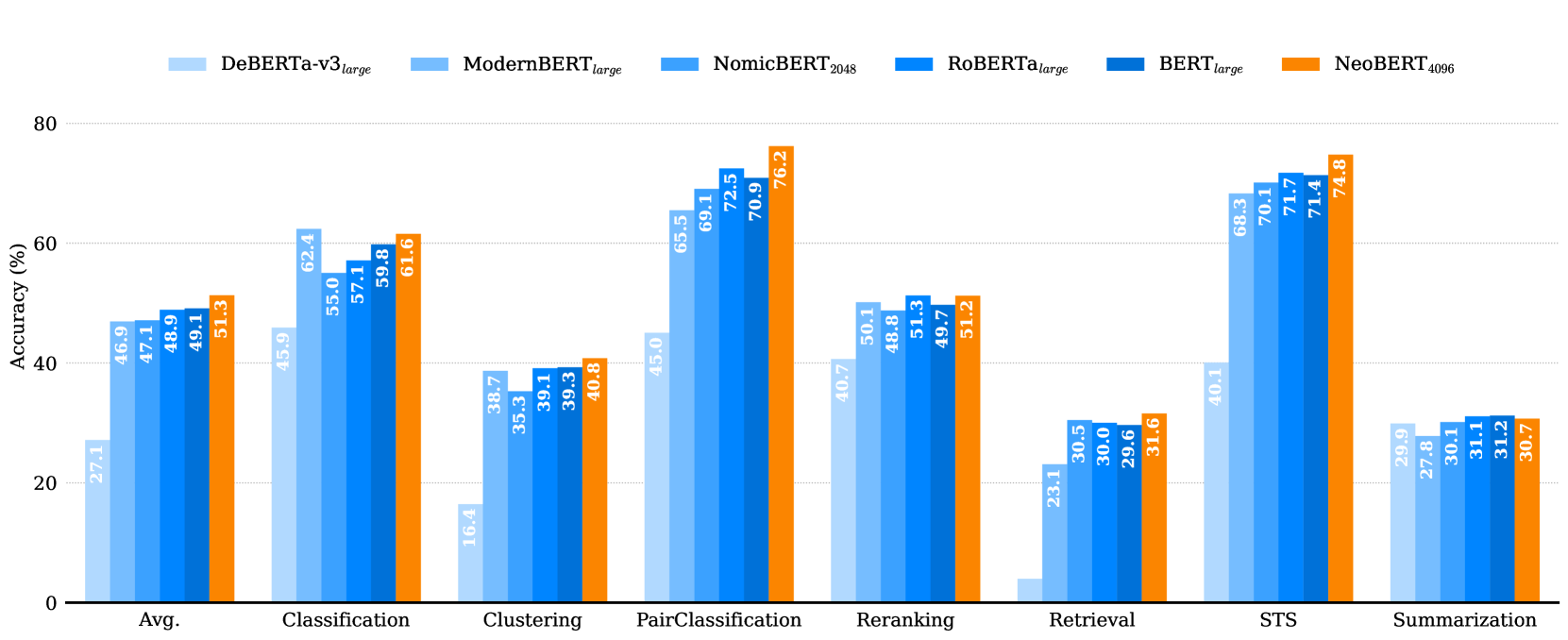
🔼 This table presents the results of the MTEB (Massive Text Embedding Benchmark) English subset evaluation. Multiple pre-trained language models were fine-tuned using a contrastive learning approach for 2000 steps. The table shows the performance of each model across seven different tasks within the benchmark (Classification, Clustering, Pair Classification, Reranking, Retrieval, Semantic Textual Similarity (STS), and Summarization), along with the average score across all tasks. The models are categorized by size (Base, Medium, Large), providing a comparison of performance across different model scales.
read the caption
Table 4: MTEB scores on the English subset after 2,000 steps of fine-tuning with contrastive learning.
| DeepSpeed |
| FlashAttention |
🔼 Table 5 presents the optimal hyperparameters found through a grid search for fine-tuning the NeoBERT model on the GLUE benchmark. The search explored various combinations of batch sizes (2, 4, 8, 16, 32), learning rates (5e-6, 6e-6, 8e-6, 1e-5, 2e-5, 3e-5), and weight decay values (1e-2, 1e-5) for each of the GLUE tasks. The table lists the optimal settings discovered for each task, aiding reproducibility and comparison of results.
read the caption
Table 5: Optimal hyperparameters for GLUE tasks. The grid search was conducted over batch sizes {2,4,8,16,32}2481632\{2,4,8,16,32\}{ 2 , 4 , 8 , 16 , 32 }, learning rates {5e−6,6e−6,8e−6,1e−5,2e−5,3e−5}5𝑒66𝑒68𝑒61𝑒52𝑒53𝑒5\{5e-6,6e-6,8e-6,1e-5,2e-5,3e-5\}{ 5 italic_e - 6 , 6 italic_e - 6 , 8 italic_e - 6 , 1 italic_e - 5 , 2 italic_e - 5 , 3 italic_e - 5 }, and weight decay values {1e−2,1e−5}1𝑒21𝑒5\{1e-2,1e-5\}{ 1 italic_e - 2 , 1 italic_e - 5 }.
| Alternate Attention |
| Unpadding |
| FlashAttention |
🔼 This table details the instructions used for fine-tuning various pre-trained models on different contrastive learning datasets. Each row represents a dataset, specifying the task and the instructions given to the model for that task. The instructions provide context to the models, guiding them on how to process the data and generate appropriate outputs. The information is crucial for understanding the fine-tuning process and how the models were prepared for the downstream evaluations.
read the caption
Table 6: Instructions for fine-tuning on the different contrastive learning datasets.
| DeepSpeed |
| FlashAttention |
🔼 This table details the specific instructions used for evaluating model performance on each of the sub-tasks within the MTEB benchmark. For each task, it provides a description outlining the input format and the expected output, clarifying the nature of the prediction required from the language model.
read the caption
Table 7: Instructions for evaluation on the different MTEB tasks.
| Modification | Before | After | |
| Embedding | Positional | RoPE | |
| Activation | GELU | SwiGLU | |
| Pre-LN | LayerNorm | RMSNorm | |
| Dataset | Wiki + Book | RefinedWeb | |
| Tokenizer | Google WordPiece | LLaMA BPE | |
| Optimizer | Adam | AdamW | |
| Scheduler | Linear | Cosine | |
| Masking Scheme | 15% (80 / 10 / 10) | 20% (100) | |
| Sequence packing | False | True | |
| Model Size | 120M | 250M | |
| Depth - Width | 16 - 1056 | 28 - 768 | |
| Batch size | 131k | 2M | |
| Context length | 512 | ||
🔼 This table lists instructions for evaluating various tasks within the MTEB (Massive Text Embedding Benchmark). Each row represents a different task, specifying the type of input given (e.g., a question, a review, a news summary) and what the model is expected to retrieve or classify in response (e.g., relevant documents, sentiment, intents). The table provides a comprehensive overview of the diverse tasks included in MTEB, showing the range of natural language understanding abilities being assessed by the benchmark.
read the caption
Table 8: Instructions for evaluation on the different MTEB tasks.
| Size | Model | MNLI | QNLI | QQP | RTE | SST | MRPC | CoLA | STS | Avg. |
| Base () | BERT | 84.0 | 90.5 | 71.2 | 66.4 | 93.5 | 88.9 | 52.1 | 85.8 | 79.6 |
| RoBERTa | 87.6 | 92.8 | 91.9 | 78.7 | 94.8 | 90.2 | 63.6 | 91.2 | 86.4 | |
| GTE-en-8192 | 86.7 | 91.9 | 88.8 | 84.8 | 93.3 | 92.1 | 57.0 | 90.2 | 85.6 | |
| NomicBERT2048 | 86.0 | 92.0 | 92.0 | 82.0 | 93.0 | 88.0 | 50.0 | 90.0 | 84.0 | |
| ModernBERT | 89.1 | 93.9 | 92.1 | 87.4 | 96.0 | 92.2 | 65.1 | 91.8 | 88.5 | |
| Medium | NeoBERT1024 | 88.9 | 93.9 | 90.7 | 91.0 | 95.8 | 93.4 | 64.8 | 92.1 | 88.8 |
| NeoBERT4096 | 89.0 | 93.7 | 90.7 | 91.3 | 95.6 | 93.4 | 66.2 | 91.8 | 89.0 | |
| Large () | BERT | 86.3 | 92.7 | 72.1 | 70.1 | 94.9 | 89.3 | 60.5 | 86.5 | 82.1 |
| RoBERTa | 90.2 | 94.7 | 92.2 | 86.6 | 96.4 | 90.9 | 68.0 | 92.4 | 88.9 | |
| DeBERTaV3 | 91.9 | 96.0 | 93.0 | 92.7 | 96.9 | 91.9 | 75.3 | 93.0 | 91.4 | |
| GTE-en-8192 | 89.2 | 93.9 | 89.2 | 88.1 | 95.1 | 93.5 | 60.4 | 91.4 | 87.6 | |
| ModernBERT | 90.8 | 95.2 | 92.7 | 92.1 | 97.1 | 91.7 | 71.4 | 92.8 | 90.5 |
🔼 This table presents the throughput, measured in thousands of tokens processed per second, for different language models at various sequence lengths. The throughput is determined using the optimal batch size for each model and sequence length combination. This allows for a comparison of the efficiency of each model in handling different input sizes, which is critical for real-world applications where processing speed is often a major constraint. The models are grouped by size (base, medium, large).
read the caption
Table 9: Throughput (103superscript10310^{3}10 start_POSTSUPERSCRIPT 3 end_POSTSUPERSCRIPT tokens / second) in function of the sequence length, with optimal batch size.
Full paper#