TL;DR#
Extending the context window of Large Language Models (LLMs) is crucial, but existing methods face challenges like performance degradation and high training costs. The core issue is the out-of-distribution (OOD) problem in rotary positional embeddings (RoPE), where higher dimensions aren’t sufficiently trained. Previous rescaling methods don’t fully address this, leading to suboptimal performance and the need for extensive retraining.
To solve these issues, LongRoPE2 adopts a new approach: It uses needle-driven perplexity evaluation and evolutionary search to identify optimal RoPE rescaling factors, focusing on critical answer tokens. Mixed context window training simultaneously trains with original and rescaled RoPE, preserving short-context performance while adapting to long sequences. Experiments show that LongRoPE2 achieves state-of-the-art results, extending context windows to 128k with minimal performance loss and significantly less training data.
Key Takeaways#
Why does it matter?#
LongRoPE2 overcomes limitations in extending the context window of LLMs, retaining short-context performance while achieving 128k context length with significantly less training data. This enables more efficient and effective handling of long-range dependencies.
Visual Insights#

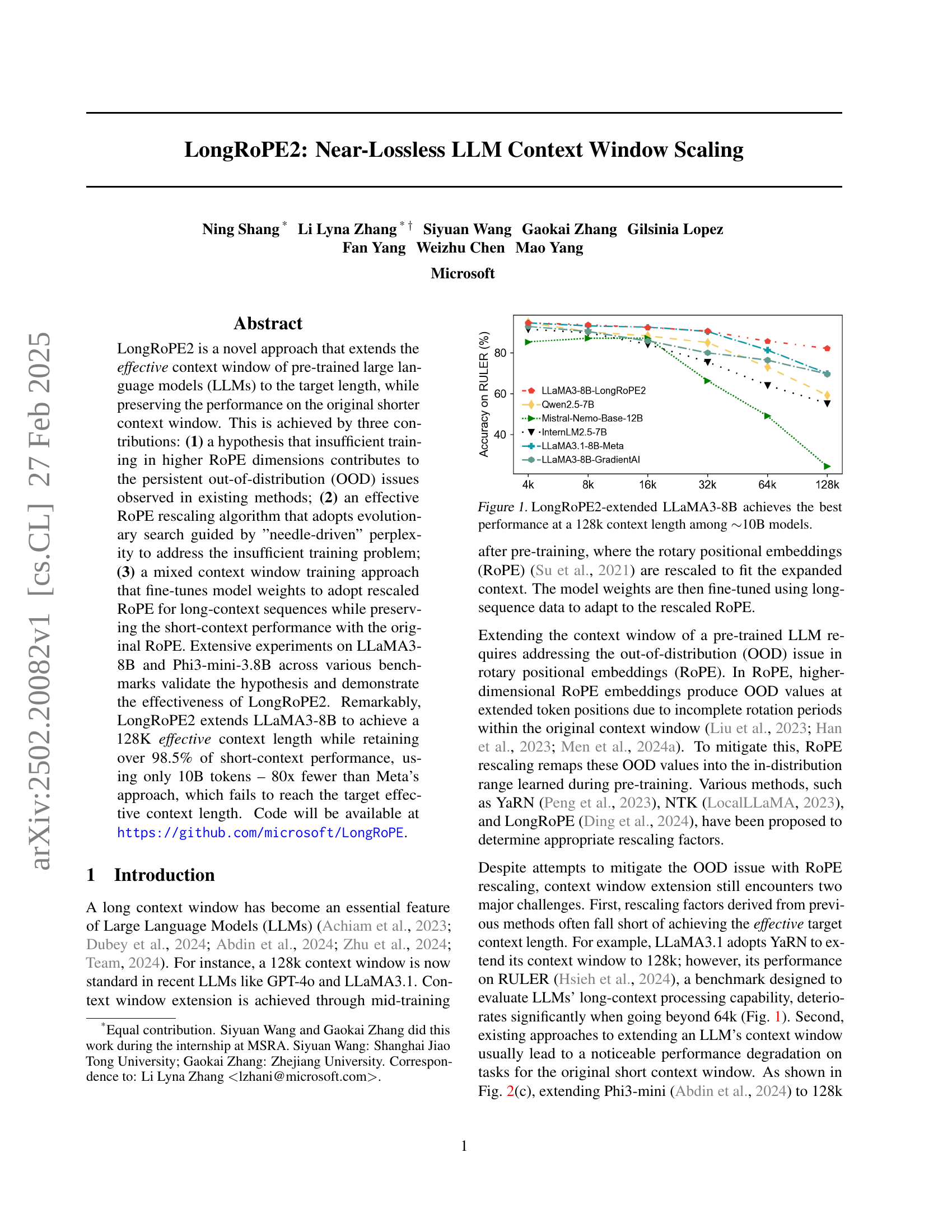
🔼 The figure is a graph showing the performance of various large language models (LLMs) on a task requiring long-context understanding. The x-axis represents the effective context window length (in tokens), and the y-axis represents the accuracy or a similar performance metric on the task. The graph demonstrates that the LongRoPE2-enhanced LLaMA3-8B model achieves the highest accuracy when using an effective context window of 128k tokens. Importantly, this performance is achieved while maintaining a model size (around 10B parameters) competitive with other models included in the comparison, showcasing the efficiency of the LongRoPE2 approach.
read the caption
Figure 1: LongRoPE2-extended LLaMA3-8B achieves the best performance at a 128k context length among ∼similar-to\sim∼10B models.
| Short Context Window | Long Context Window | ||
| -100k | 100k-200k | ||
| Tokens | 3B | 3B | 4B |
🔼 This table details the composition of the training dataset used in the LongRoPE2 model’s mixed context window training approach. It shows the distribution of training data across two distinct context window sizes: short context windows and long context windows. The numbers indicate the number of tokens allocated to each context window size for training purposes. This split in the data allows the model to maintain performance on short contexts while learning effective long-context representations.
read the caption
Table 1: Mid-training data mix.
In-depth insights#
ROPE undertraining#
The research posits that insufficient training in higher RoPE dimensions is a core issue in context window extension. It suggests that while lower dimensions are well-trained, higher ones, crucial for processing long-range dependencies, receive inadequate exposure during pre-training. This leads to shorter effective ROPE rotation ranges and distorts extended rotation periods beyond theoretical predictions. This ROPE undertraining explains why scaling factors larger than analytically derived values improve long-context performance, effectively mitigating the out-of-distribution issues across all dimensions. The work emphasizes the need to address this training imbalance for effective context extension.
Needle-driven PPL#
Needle-driven Perplexity (PPL) evaluation offers a targeted method for assessing long-context understanding in LLMs. Traditional PPL averages across all tokens, potentially obscuring the model’s ability to grasp dependencies within extended sequences. By focusing solely on specific “needle” tokens—answer tokens deeply reliant on contextual understanding—the evaluation becomes more sensitive to long-range dependencies. This contrasts with vanilla PPL, which may be skewed by irrelevant tokens, leading to inaccurate assessments of long-context capabilities. This method helps in identifying true RoPE dimensions.
Mixed context FT#
Mixed Context Fine-Tuning (FT) is a pivotal strategy for adapting pre-trained LLMs to extended context windows. It involves training the model on a blend of short and long sequences. This preserves performance on original tasks while enabling effective handling of extended contexts. Short sequences maintain pre-trained knowledge; long sequences adapt the model to rescaled positional embeddings like RoPE. Careful data mixing and masking strategies are key to prevent cross-document attention and ensure optimal adaptation. FT helps the model retain short-context proficiency while extending its capabilities.
Effective dRCD#
Effective dRCD (Real Critical Dimension) is crucial for optimizing long-context LLMs. This parameter determines the boundary between RoPE dimensions that are sufficiently trained and those that are not. Insufficiently trained higher dimensions lead to OOD issues. Correctly identifying and utilizing the true dRCD, not just relying on theoretical calculations, significantly improves performance, especially in long contexts, by guiding the rescaling of RoPE dimensions. By identifying and focusing on the practical critical dimension, the LongRoPE2 is able to outperform YaRN and NTK.
OOD RoPE scaling#
Out-of-Distribution (OOD) issues in RoPE scaling arise when extending the context window of LLMs. RoPE, a positional encoding method, can produce OOD values at extended token positions because higher-dimensional embeddings have incomplete rotation periods relative to the original context window. ROPE rescaling methods aim to remap these OOD values into the in-distribution range learned during pre-training to mitigate this. Common techniques involve adjusting the per-dimensional rotation angles to ensure higher ROPE dimensions remain within the pre-trained RoPE range. The challenge is finding optimal rescaling factors that effectively mitigate OOD issues without sacrificing short-context performance. Ideally, the rescaling should shift the critical dimensions, aligning with the actual data distribution and retaining as much of the original RoPE information as possible, thus improving overall performance.
More visual insights#
More on figures

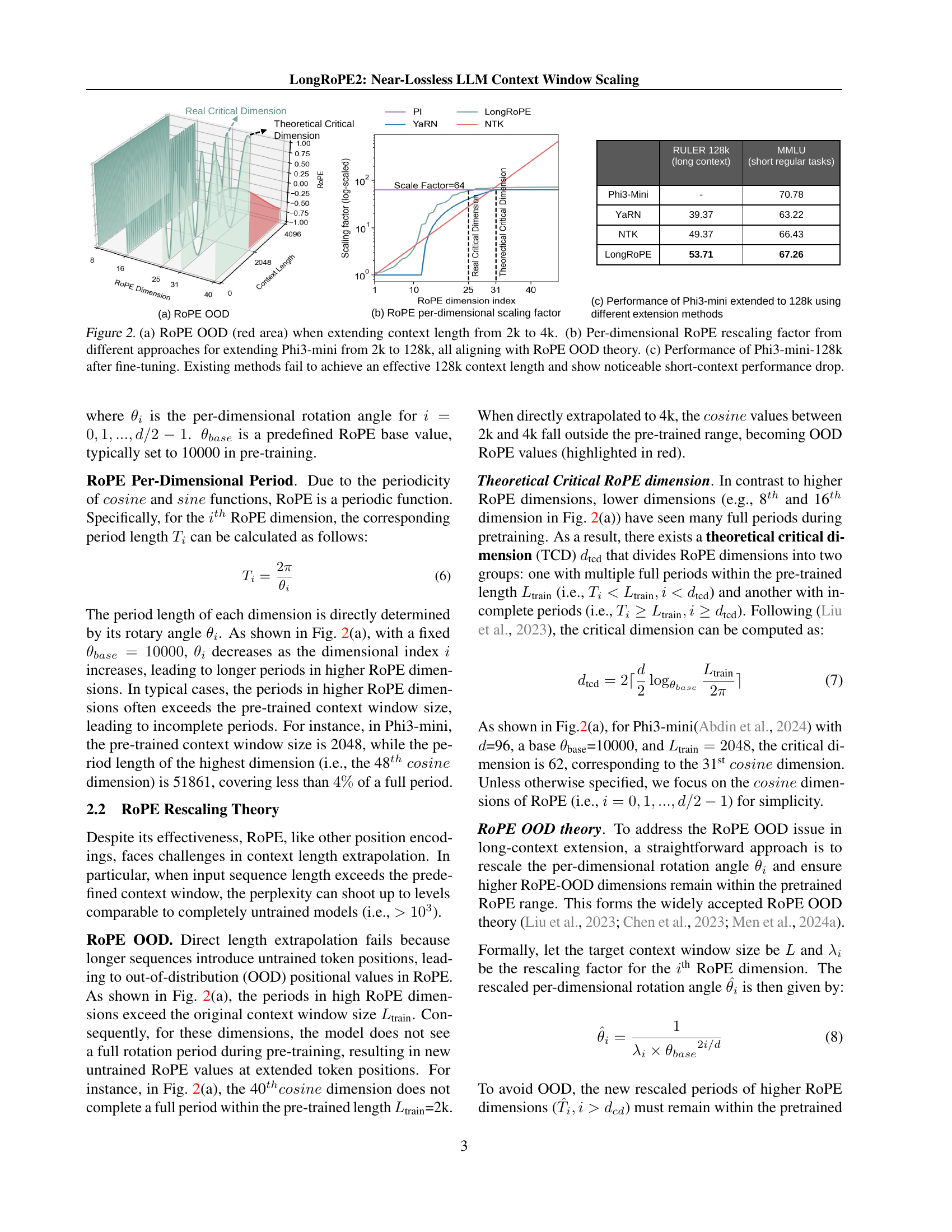
🔼 This figure demonstrates the challenges of extending context windows in LLMs. Panel (a) visually shows the out-of-distribution (OOD) problem of Rotary Positional Embeddings (RoPE) when extending the context length from 2k to 4k tokens. The red area highlights the OOD regions, which are problematic for model performance. Panel (b) compares the per-dimensional RoPE rescaling factors used by different methods (YaRN, NTK, LongRoPE) to extend the context length of the Phi3-mini model from 2k to 128k tokens. All methods attempt to align with the RoPE OOD theory to mitigate the OOD issue. Panel (c) shows the performance of the Phi3-mini model extended to 128k tokens using different methods, revealing that existing approaches fail to reach an effective 128k context length while maintaining short-context performance. There is a clear performance drop in short-context tasks after extending the context length.
read the caption
Figure 2: (a) RoPE OOD (red area) when extending context length from 2k to 4k. (b) Per-dimensional RoPE rescaling factor from different approaches for extending Phi3-mini from 2k to 128k, all aligning with RoPE OOD theory. (c) Performance of Phi3-mini-128k after fine-tuning. Existing methods fail to achieve an effective 128k context length and show noticeable short-context performance drop.

🔼 This figure visualizes the relationship between RoPE (Rotary Positional Embedding) dimension and the length of sequences needed to complete one full cycle of RoPE’s periodic function during the Phi3-mini model’s pre-training. Lower dimensions require shorter sequences to complete a full cycle, indicating sufficient training across multiple cycles within the training data. Conversely, higher dimensions necessitate much longer sequences, exceeding the pre-training context window length. This demonstrates insufficient training in these higher dimensions, leading to incomplete rotation periods within the original training context and shorter effective RoPE ranges than theoretically expected. The discrepancy highlights a critical factor contributing to out-of-distribution issues when extrapolating context windows.
read the caption
Figure 3: Sequence length required to span the theoretical period during Phi3-mini pre-training for different RoPE dimensions. Insufficient training in higher RoPE dimensions leads to shorter effective RoPE ranges and longer actual periods.

🔼 This figure compares the per-dimension scaling factors applied to the Rotary Position Embeddings (RoPE) in different context window extension methods. The x-axis represents the RoPE dimension index, and the y-axis shows the scaling factor applied to each dimension. It highlights how LongRoPE2’s scaling factors differ from those of YaRN, NTK, and LongRoPE, particularly in the higher dimensions. This difference reflects the unique approach of LongRoPE2 to address the out-of-distribution (OOD) problem in RoPE by adjusting the scaling factor based on the critical dimension, which is dynamically determined through an evolutionary search guided by needle-driven perplexity.
read the caption
Figure 4: Scale factors across different RoPE rescaling approaches.

🔼 This figure illustrates the mixed context window training approach used to enhance both short and long context capabilities in LLMs. The left panel (a) shows the training process for shorter context windows, where the original ROPE (Rotary Position Embeddings) is used and attention is masked to prevent cross-document attention. The right panel (b) shows the training process for longer context windows, where the rescaled ROPE is used for full attention across the entire window. This dual training strategy helps maintain performance on short contexts while improving the model’s ability to process longer sequences.
read the caption
Figure 5: Mixed context window training to improve both short and long context capabilities.

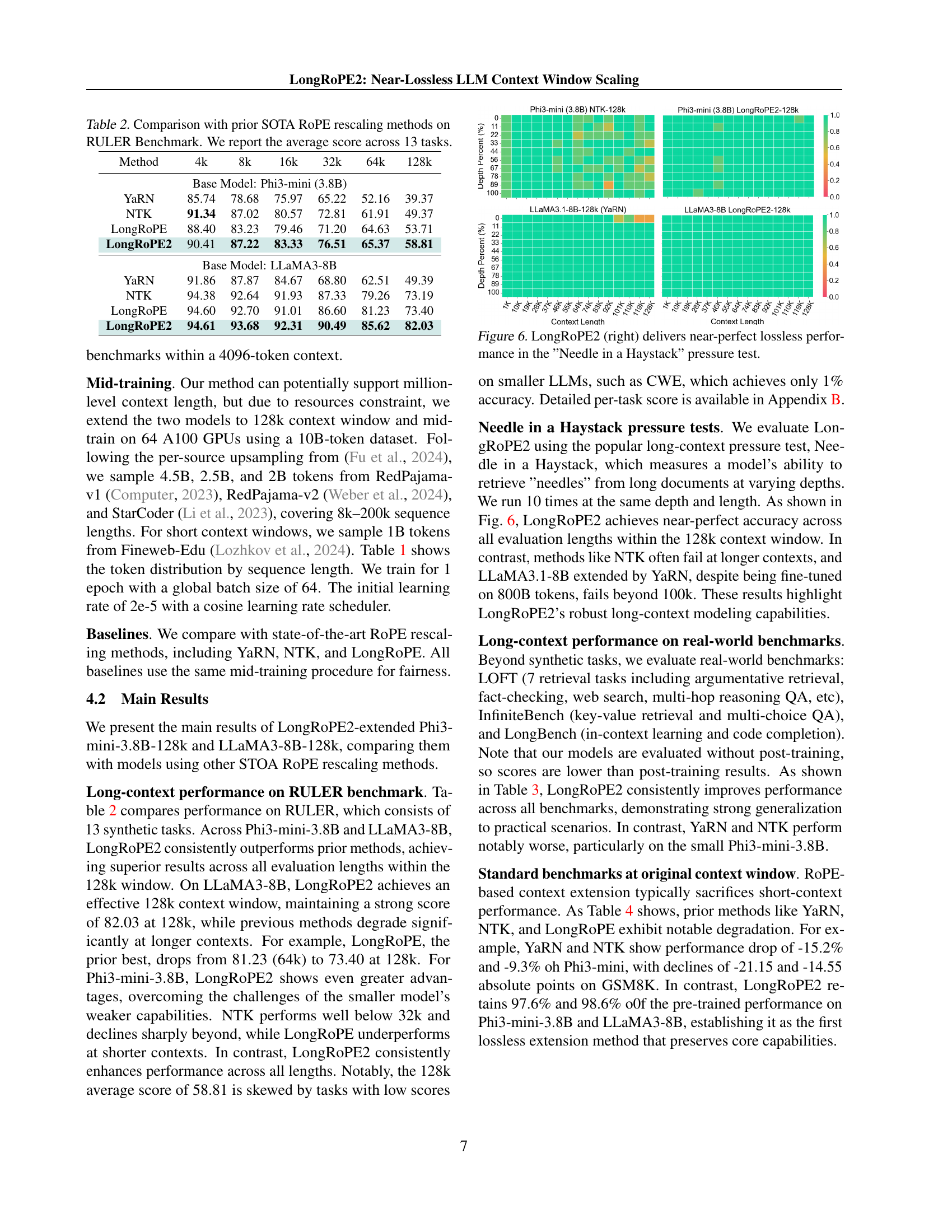
🔼 The Needle in a Haystack pressure test evaluates the ability of a language model to accurately retrieve specific pieces of text (needles) from long documents, assessing its long-context understanding. This figure compares the performance of LongRoPE2 against another model on this task, showing that LongRoPE2 achieves near-perfect accuracy across various retrieval depths within a 128k context window, demonstrating its ability to maintain performance in long-context scenarios.
read the caption
Figure 6: LongRoPE2 (right) delivers near-perfect lossless performance in the ”Needle in a Haystack” pressure test.

🔼 This figure displays the complete results of the ‘Needle in a Haystack’ experiment for the Phi3-mini (3.8B) language model with an extended context window of 128K tokens. The Needle in a Haystack task assesses a language model’s ability to locate specific pieces of text (the ’needles’) within very long documents, testing its long-context understanding capabilities. The visualization likely shows the accuracy or success rate of the model in retrieving the needles at various depths within the extended document, which indicates how effectively it processes information over long contextual spans.
read the caption
Figure 7: Needle in a Haystack full results for Phi3-mini (3.8B)-128k.

🔼 This figure displays the complete results of the ‘Needle in a Haystack’ test for the LLaMA3-8B model with its context window extended to 128k tokens using different methods. The test evaluates the model’s ability to accurately retrieve a specific piece of text (’needle’) from long documents at different depths. Each subplot shows the success rate at various depths (percentage of the total context length) and context lengths using different ROPE methods (YaRN, NTK, LongRoPE, and LongRoPE2). The color intensity represents the accuracy rate, showing how well each model performs in retrieving the needles across various positions within the long sequence. The comparison helps to illustrate the effectiveness and limitations of each ROPE method in handling long context windows.
read the caption
Figure 8: Needle in a Haystack full results for LLaMA3-8B-128k.

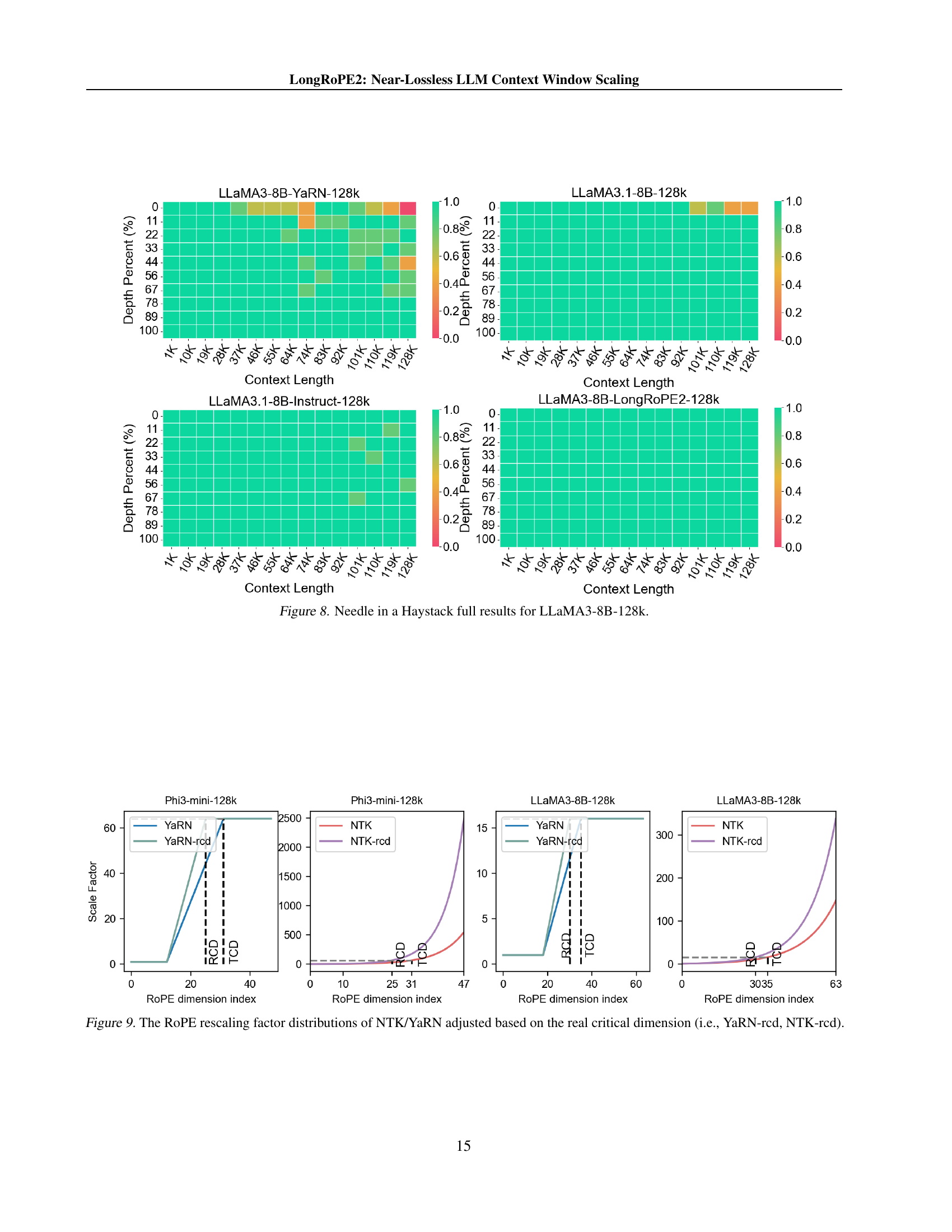
🔼 This figure compares the per-dimensional RoPE scaling factors from NTK and YaRN methods, both before and after adjusting for the real critical dimension. The original NTK and YaRN methods use different scaling strategies across various RoPE dimensions. By incorporating the ‘real critical dimension’ (determined empirically), the adjusted methods (YaRN-rcd and NTK-rcd) demonstrate how the recalibration impacts the scaling factor distribution, showing differences in how each method adapts scaling across different dimension ranges.
read the caption
Figure 9: The RoPE rescaling factor distributions of NTK/YaRN adjusted based on the real critical dimension (i.e., YaRN-rcd, NTK-rcd).

🔼 This figure shows the pseudocode for LongRoPE2’s mixed context window training and inference. The code demonstrates how the model uses different positional embeddings (original RoPE and rescaled RoPE) depending on whether the input sequence length is within the original pre-trained context window or exceeds it. If the input length exceeds the original context window, rescaled RoPE is utilized; otherwise, the original ROPE is used. The pseudocode also highlights the use of FlashAttention-2 for efficient attention calculation during both training and inference, showing how it handles different sequence lengths using functions like
flash_attn_funcandflash_attn_varlen_func.read the caption
Figure 10: The pseudocode for mixed context window training and inference.
More on tables
| Method | 4k | 8k | 16k | 32k | 64k | 128k |
| Base Model: Phi3-mini (3.8B) | ||||||
| YaRN | 85.74 | 78.68 | 75.97 | 65.22 | 52.16 | 39.37 |
| NTK | 91.34 | 87.02 | 80.57 | 72.81 | 61.91 | 49.37 |
| LongRoPE | 88.40 | 83.23 | 79.46 | 71.20 | 64.63 | 53.71 |
| LongRoPE2 | 90.41 | 87.22 | 83.33 | 76.51 | 65.37 | 58.81 |
| Base Model: LLaMA3-8B | ||||||
| YaRN | 91.86 | 87.87 | 84.67 | 68.80 | 62.51 | 49.39 |
| NTK | 94.38 | 92.64 | 91.93 | 87.33 | 79.26 | 73.19 |
| LongRoPE | 94.60 | 92.70 | 91.01 | 86.60 | 81.23 | 73.40 |
| LongRoPE2 | 94.61 | 93.68 | 92.31 | 90.49 | 85.62 | 82.03 |
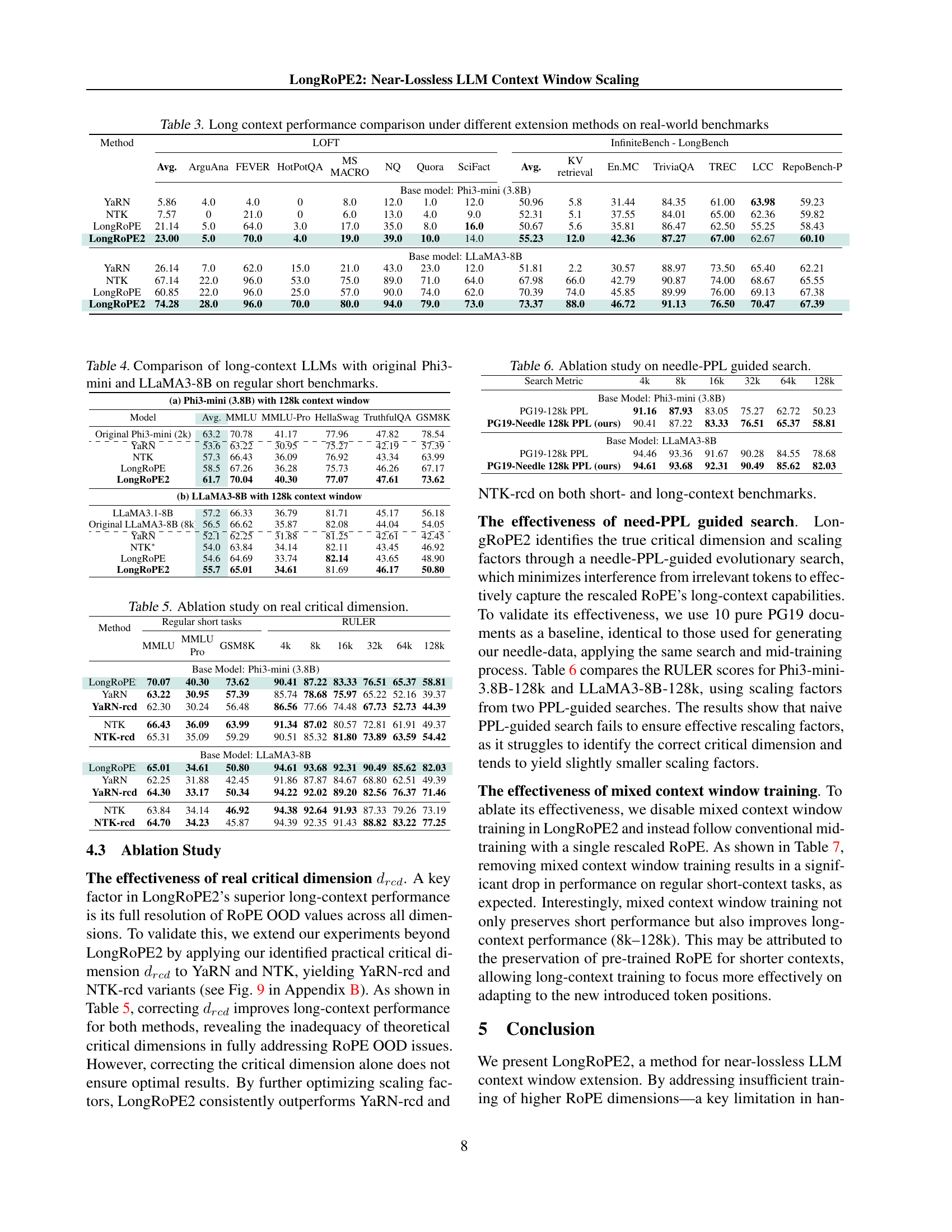
🔼 This table presents a comparison of LongRoPE2’s performance against other state-of-the-art (SOTA) RoPE rescaling methods on the RULER benchmark. The RULER benchmark consists of thirteen tasks designed to evaluate the ability of large language models to handle long contexts. The table shows the average score across these thirteen tasks for each method at various context lengths, highlighting the effectiveness of LongRoPE2 in maintaining performance as context length increases.
read the caption
Table 2: Comparison with prior SOTA RoPE rescaling methods on RULER Benchmark. We report the average score across 13 tasks.
| Method | LOFT | InfiniteBench - LongBench | ||||||||||||||
| Avg. | ArguAna | FEVER | HotPotQA | MS MACRO | NQ | Quora | SciFact | Avg. | KV retrieval | En.MC | TriviaQA | TREC | LCC | RepoBench-P | ||
| Base model: Phi3-mini (3.8B) | ||||||||||||||||
| YaRN | 5.86 | 4.0 | 4.0 | 0 | 8.0 | 12.0 | 1.0 | 12.0 | 50.96 | 5.8 | 31.44 | 84.35 | 61.00 | 63.98 | 59.23 | |
| NTK | 7.57 | 0 | 21.0 | 0 | 6.0 | 13.0 | 4.0 | 9.0 | 52.31 | 5.1 | 37.55 | 84.01 | 65.00 | 62.36 | 59.82 | |
| LongRoPE | 21.14 | 5.0 | 64.0 | 3.0 | 17.0 | 35.0 | 8.0 | 16.0 | 50.67 | 5.6 | 35.81 | 86.47 | 62.50 | 55.25 | 58.43 | |
| LongRoPE2 | 23.00 | 5.0 | 70.0 | 4.0 | 19.0 | 39.0 | 10.0 | 14.0 | 55.23 | 12.0 | 42.36 | 87.27 | 67.00 | 62.67 | 60.10 | |
| Base model: LLaMA3-8B | ||||||||||||||||
| YaRN | 26.14 | 7.0 | 62.0 | 15.0 | 21.0 | 43.0 | 23.0 | 12.0 | 51.81 | 2.2 | 30.57 | 88.97 | 73.50 | 65.40 | 62.21 | |
| NTK | 67.14 | 22.0 | 96.0 | 53.0 | 75.0 | 89.0 | 71.0 | 64.0 | 67.98 | 66.0 | 42.79 | 90.87 | 74.00 | 68.67 | 65.55 | |
| LongRoPE | 60.85 | 22.0 | 96.0 | 25.0 | 57.0 | 90.0 | 74.0 | 62.0 | 70.39 | 74.0 | 45.85 | 89.99 | 76.00 | 69.13 | 67.38 | |
| LongRoPE2 | 74.28 | 28.0 | 96.0 | 70.0 | 80.0 | 94.0 | 79.0 | 73.0 | 73.37 | 88.0 | 46.72 | 91.13 | 76.50 | 70.47 | 67.39 | |
🔼 This table presents a comparison of the performance of different context window extension methods on several real-world long-context benchmarks. It shows the average scores achieved by various methods (YaRN, NTK, LongRoPE, and LongRoPE2) on different benchmarks, such as LOFT (which includes tasks like argumentative retrieval, fact-checking, etc.), InfiniteBench (for tasks like key-value retrieval and multi-choice QA), and LongBench (evaluating performance on in-context learning and code completion). The results are broken down by benchmark and method, allowing for easy comparison of performance across the different techniques.
read the caption
Table 3: Long context performance comparison under different extension methods on real-world benchmarks
| (a) Phi3-mini (3.8B) with 128k context window | ||||||
| Model | Avg. | MMLU | MMLU-Pro | HellaSwag | TruthfulQA | GSM8K |
| Original Phi3-mini (2k) | 63.2 | 70.78 | 41.17 | 77.96 | 47.82 | 78.54 |
| \hdashlineYaRN | 53.6 | 63.22 | 30.95 | 75.27 | 42.19 | 57.39 |
| NTK | 57.3 | 66.43 | 36.09 | 76.92 | 43.34 | 63.99 |
| LongRoPE | 58.5 | 67.26 | 36.28 | 75.73 | 46.26 | 67.17 |
| LongRoPE2 | 61.7 | 70.04 | 40.30 | 77.07 | 47.61 | 73.62 |
| (b) LLaMA3-8B with 128k context window | ||||||
| LLaMA3.1-8B | 57.2 | 66.33 | 36.79 | 81.71 | 45.17 | 56.18 |
| Original LLaMA3-8B (8k) | 56.5 | 66.62 | 35.87 | 82.08 | 44.04 | 54.05 |
| \hdashlineYaRN | 52.1 | 62.25 | 31.88 | 81.25 | 42.61 | 42.45 |
| NTK∗ | 54.0 | 63.84 | 34.14 | 82.11 | 43.45 | 46.92 |
| LongRoPE | 54.6 | 64.69 | 33.74 | 82.14 | 43.65 | 48.90 |
| LongRoPE2 | 55.7 | 65.01 | 34.61 | 81.69 | 46.17 | 50.80 |
🔼 This table presents a comparison of the performance of several large language models (LLMs) on standard short-context benchmark tasks. It compares models extended to have long context windows (using different methods) against their original, unextended versions for both Phi-3 Mini and LLaMA3-8B. The results show the impact of long context window extension on performance in tasks designed for shorter contexts. This comparison highlights the impact of various context extension techniques on short context capabilities.
read the caption
Table 4: Comparison of long-context LLMs with original Phi3-mini and LLaMA3-8B on regular short benchmarks.
| Method | Regular short tasks | RULER | ||||||||
| MMLU | MMLU Pro | GSM8K | 4k | 8k | 16k | 32k | 64k | 128k | ||
| Base Model: Phi3-mini (3.8B) | ||||||||||
| LongRoPE2 | 70.07 | 40.30 | 73.62 | 90.41 | 87.22 | 83.33 | 76.51 | 65.37 | 58.81 | |
| YaRN | 63.22 | 30.95 | 57.39 | 85.74 | 78.68 | 75.97 | 65.22 | 52.16 | 39.37 | |
| YaRN-rcd | 62.30 | 30.24 | 56.48 | 86.56 | 77.66 | 74.48 | 67.73 | 52.73 | 44.39 | |
| NTK | 66.43 | 36.09 | 63.99 | 91.34 | 87.02 | 80.57 | 72.81 | 61.91 | 49.37 | |
| NTK-rcd | 65.31 | 35.09 | 59.29 | 90.51 | 85.32 | 81.80 | 73.89 | 63.59 | 54.42 | |
| Base Model: LLaMA3-8B | ||||||||||
| LongRoPE2 | 65.01 | 34.61 | 50.80 | 94.61 | 93.68 | 92.31 | 90.49 | 85.62 | 82.03 | |
| YaRN | 62.25 | 31.88 | 42.45 | 91.86 | 87.87 | 84.67 | 68.80 | 62.51 | 49.39 | |
| YaRN-rcd | 64.30 | 33.17 | 50.34 | 94.22 | 92.02 | 89.20 | 82.56 | 76.37 | 71.46 | |
| NTK | 63.84 | 34.14 | 46.92 | 94.38 | 92.64 | 91.93 | 87.33 | 79.26 | 73.19 | |
| NTK-rcd | 64.70 | 34.23 | 45.87 | 94.39 | 92.35 | 91.43 | 88.82 | 83.22 | 77.25 | |
🔼 This table presents an ablation study analyzing the impact of using the real (empirically determined) critical dimension, instead of the theoretical critical dimension, on the performance of the LongRoPE2 model. It shows the results of the LongRoPE2 method and two baselines (YaRN and NTK) on various metrics (MMLU, GSM8K, RULER) using different context window sizes. This helps to demonstrate the importance of the real critical dimension in achieving optimal long context performance.
read the caption
Table 5: Ablation study on real critical dimension.
| Search Metric | 4k | 8k | 16k | 32k | 64k | 128k |
| Base Model: Phi3-mini (3.8B) | ||||||
| PG19-128k PPL | 91.16 | 87.93 | 83.05 | 75.27 | 62.72 | 50.23 |
| PG19-Needle 128k PPL (ours) | 90.41 | 87.22 | 83.33 | 76.51 | 65.37 | 58.81 |
| Base Model: LLaMA3-8B | ||||||
| PG19-128k PPL | 94.46 | 93.36 | 91.67 | 90.28 | 84.55 | 78.68 |
| PG19-Needle 128k PPL (ours) | 94.61 | 93.68 | 92.31 | 90.49 | 85.62 | 82.03 |
🔼 This table presents an ablation study comparing the performance of LongRoPE2 using two different search methods for finding optimal rescaling factors: a standard perplexity (PPL)-guided search and a novel needle-driven PPL-guided search. The needle-driven approach focuses on specific, crucial tokens within the long sequences, improving the accuracy of the search and ultimately leading to better performance. The table shows the RULER scores for both Phi3-mini and LLaMA3-8B models at different context lengths (4k to 128k) under each search method, highlighting the improvement achieved by the needle-driven PPL approach.
read the caption
Table 6: Ablation study on needle-PPL guided search.
| Method | MMLU | MMLU Pro | GSM8K | 4k | 8k | 16k | 32k | 64k | 128k |
| Base Model: Phi3 June | |||||||||
| LongRoPE2 | 70.07 | 40.30 | 73.62 | 90.41 | 86.87 | 83.33 | 76.51 | 65.37 | 58.81 |
| LongRoPE2/ wo. | 66.56 | 34.86 | 64.67 | 90.55 | 85.77 | 81.08 | 73.31 | 63.75 | 56.22 |
| Base Model: LLaMA3-8B | |||||||||
| LongRoPE2 | 65.01 | 34.61 | 50.80 | 94.61 | 93.68 | 92.31 | 90.49 | 85.62 | 82.03 |
| LongRoPE2/ wo. | 64.57 | 33.83 | 48.37 | 94.67 | 93.15 | 91.24 | 89.38 | 83.53 | 80.18 |
🔼 This table presents the results of an ablation study investigating the impact of the mixed context window training approach on the overall performance of the model. The study compares the performance of the model with and without the proposed mixed context window training. The performance is evaluated using various metrics across different context window sizes. This helps to determine the effectiveness of this new training method.
read the caption
Table 7: Ablation study on mixed context window training.
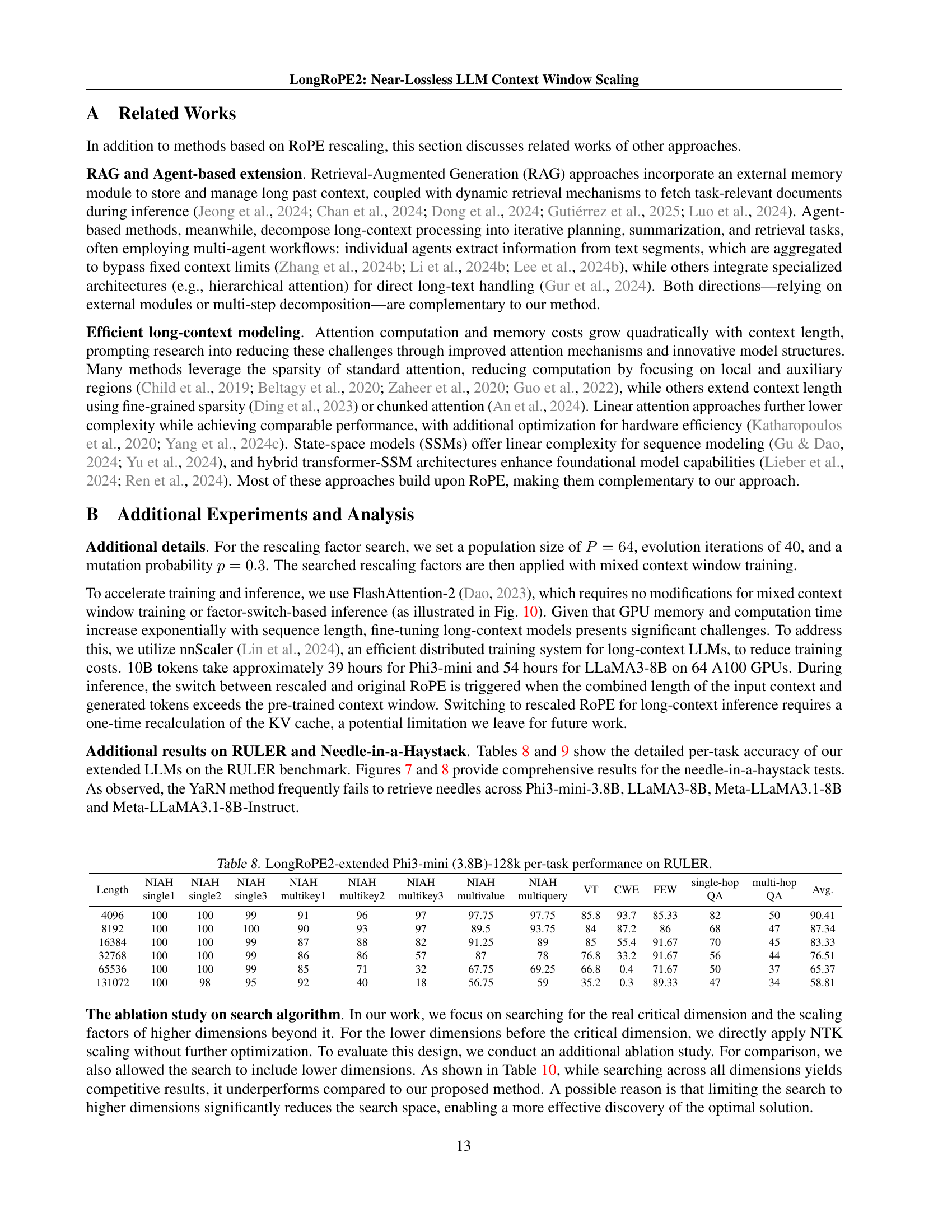
| Length | NIAH single1 | NIAH single2 | NIAH single3 | NIAH multikey1 | NIAH multikey2 | NIAH multikey3 | NIAH multivalue | NIAH multiquery | VT | CWE | FEW | single-hop QA | multi-hop QA | Avg. |
| 4096 | 100 | 100 | 99 | 91 | 96 | 97 | 97.75 | 97.75 | 85.8 | 93.7 | 85.33 | 82 | 50 | 90.41 |
| 8192 | 100 | 100 | 100 | 90 | 93 | 97 | 89.5 | 93.75 | 84 | 87.2 | 86 | 68 | 47 | 87.34 |
| 16384 | 100 | 100 | 99 | 87 | 88 | 82 | 91.25 | 89 | 85 | 55.4 | 91.67 | 70 | 45 | 83.33 |
| 32768 | 100 | 100 | 99 | 86 | 86 | 57 | 87 | 78 | 76.8 | 33.2 | 91.67 | 56 | 44 | 76.51 |
| 65536 | 100 | 100 | 99 | 85 | 71 | 32 | 67.75 | 69.25 | 66.8 | 0.4 | 71.67 | 50 | 37 | 65.37 |
| 131072 | 100 | 98 | 95 | 92 | 40 | 18 | 56.75 | 59 | 35.2 | 0.3 | 89.33 | 47 | 34 | 58.81 |
🔼 This table presents the detailed per-task performance of the Phi3-mini (3.8B) language model after being extended to a 128K context window using the LongRoPE2 method. It shows the performance on the RULER benchmark, which comprises various tasks with varying sequence lengths (4k, 8k, 16k, 32k, 64k, and 128k). The results are broken down by individual task and sequence length, providing a comprehensive view of the model’s performance across different task complexities and context lengths.
read the caption
Table 8: LongRoPE2-extended Phi3-mini (3.8B)-128k per-task performance on RULER.
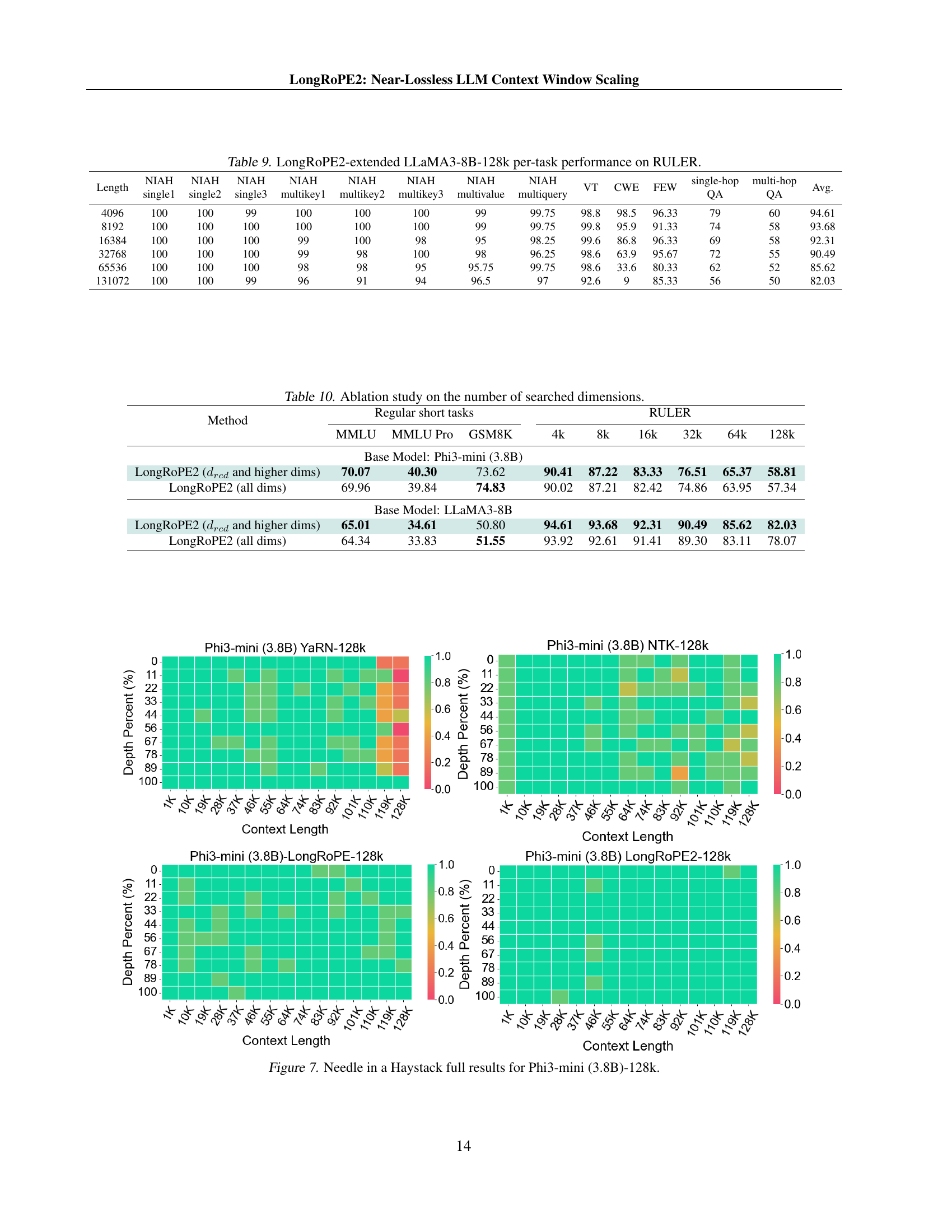
| Length | NIAH single1 | NIAH single2 | NIAH single3 | NIAH multikey1 | NIAH multikey2 | NIAH multikey3 | NIAH multivalue | NIAH multiquery | VT | CWE | FEW | single-hop QA | multi-hop QA | Avg. |
| 4096 | 100 | 100 | 99 | 100 | 100 | 100 | 99 | 99.75 | 98.8 | 98.5 | 96.33 | 79 | 60 | 94.61 |
| 8192 | 100 | 100 | 100 | 100 | 100 | 100 | 99 | 99.75 | 99.8 | 95.9 | 91.33 | 74 | 58 | 93.68 |
| 16384 | 100 | 100 | 100 | 99 | 100 | 98 | 95 | 98.25 | 99.6 | 86.8 | 96.33 | 69 | 58 | 92.31 |
| 32768 | 100 | 100 | 100 | 99 | 98 | 100 | 98 | 96.25 | 98.6 | 63.9 | 95.67 | 72 | 55 | 90.49 |
| 65536 | 100 | 100 | 100 | 98 | 98 | 95 | 95.75 | 99.75 | 98.6 | 33.6 | 80.33 | 62 | 52 | 85.62 |
| 131072 | 100 | 100 | 99 | 96 | 91 | 94 | 96.5 | 97 | 92.6 | 9 | 85.33 | 56 | 50 | 82.03 |
🔼 This table presents a detailed breakdown of the LongRoPE2 model’s performance on the RULER benchmark, specifically for the LLaMA3-8B model extended to a 128k context window. It shows the per-task accuracy across 13 RULER tasks for various context lengths, ranging from 4096 tokens to 131072 tokens. The tasks include various question answering and reasoning tasks assessing different aspects of long-context understanding. The data allows for a precise evaluation of the model’s performance at different context lengths and across multiple task types.
read the caption
Table 9: LongRoPE2-extended LLaMA3-8B-128k per-task performance on RULER.
| Method | Regular short tasks | RULER | ||||||||
| MMLU | MMLU Pro | GSM8K | 4k | 8k | 16k | 32k | 64k | 128k | ||
| Base Model: Phi3-mini (3.8B) | ||||||||||
| LongRoPE2 ( and higher dims) | 70.07 | 40.30 | 73.62 | 90.41 | 87.22 | 83.33 | 76.51 | 65.37 | 58.81 | |
| LongRoPE2 (all dims) | 69.96 | 39.84 | 74.83 | 90.02 | 87.21 | 82.42 | 74.86 | 63.95 | 57.34 | |
| Base Model: LLaMA3-8B | ||||||||||
| LongRoPE2 ( and higher dims) | 65.01 | 34.61 | 50.80 | 94.61 | 93.68 | 92.31 | 90.49 | 85.62 | 82.03 | |
| LongRoPE2 (all dims) | 64.34 | 33.83 | 51.55 | 93.92 | 92.61 | 91.41 | 89.30 | 83.11 | 78.07 | |
🔼 This table presents the results of an ablation study investigating the impact of the number of RoPE dimensions included in the evolutionary search process on the overall model performance. It compares the performance of LongRoPE2 when the search is restricted to only the critical dimensions and higher (drcd and higher dims), versus when all dimensions are included in the search (all dims). The comparison is done across various metrics including MMLU, MMLU-Pro, GSM8K, and RULER scores at different context lengths (4k, 8k, 16k, 32k, 64k, 128k), showing how the search space affects the final model’s ability to handle both short and long contexts effectively.
read the caption
Table 10: Ablation study on the number of searched dimensions.
Full paper#