TL;DR#
Issue-resolving frameworks often rely on costly commercial models and struggle with generalization, failing to fully utilize open-source resources. Existing training methods fall short of leveraging the wealth of information available in open-source development. Addressing these challenges is crucial for creating more accessible and robust automated software development tools.
This paper introduces Subtask-oriented Reinforced Fine-Tuning (SoRFT). It decomposes issue resolving into structured subtasks: file localization, function localization, line localization, and code edit generation. SoRFT utilizes rejection-sampled supervised fine-tuning and rule-based reinforcement learning to enhance LLMs’ issue-resolving capabilities, achieving state-of-the-art performance among open-source models.
Key Takeaways#
Why does it matter?#
This paper introduces SoRFT, a novel approach for issue resolving, offering a cost-effective, open-source alternative to commercial models. It enhances LLMs’ capabilities through subtask-oriented, reinforced fine-tuning, improving generalization and opening new research avenues in automated software development.
Visual Insights#

🔼 This figure illustrates the reward calculation mechanism in the rule-based reinforcement learning stage of SoRFT for the file localization subtask. The process begins with an LLM generating Chain-of-Thought (CoT) data in response to a given software issue. This CoT data represents the LLM’s reasoning process toward identifying the relevant file(s). A reward score, specifically the F-beta score (Fβ), is then computed. This score compares the files identified by the LLM (extracted answer) against the actual files modified in the ground truth solution (ground-truth answer). A higher F-beta score indicates better accuracy in the LLM’s file localization. This reward signal is crucial in guiding the LLM’s learning during the reinforcement learning phase to improve its file localization capabilities.
read the caption
Figure 1: Rule-based reward example for file localization subtask. LLM generates CoT data for a given issue, the reward for the sampled CoT is then calculated by the Fβsubscript𝐹𝛽F_{\beta}italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT score based on the extracted answer and the ground-truth answer.
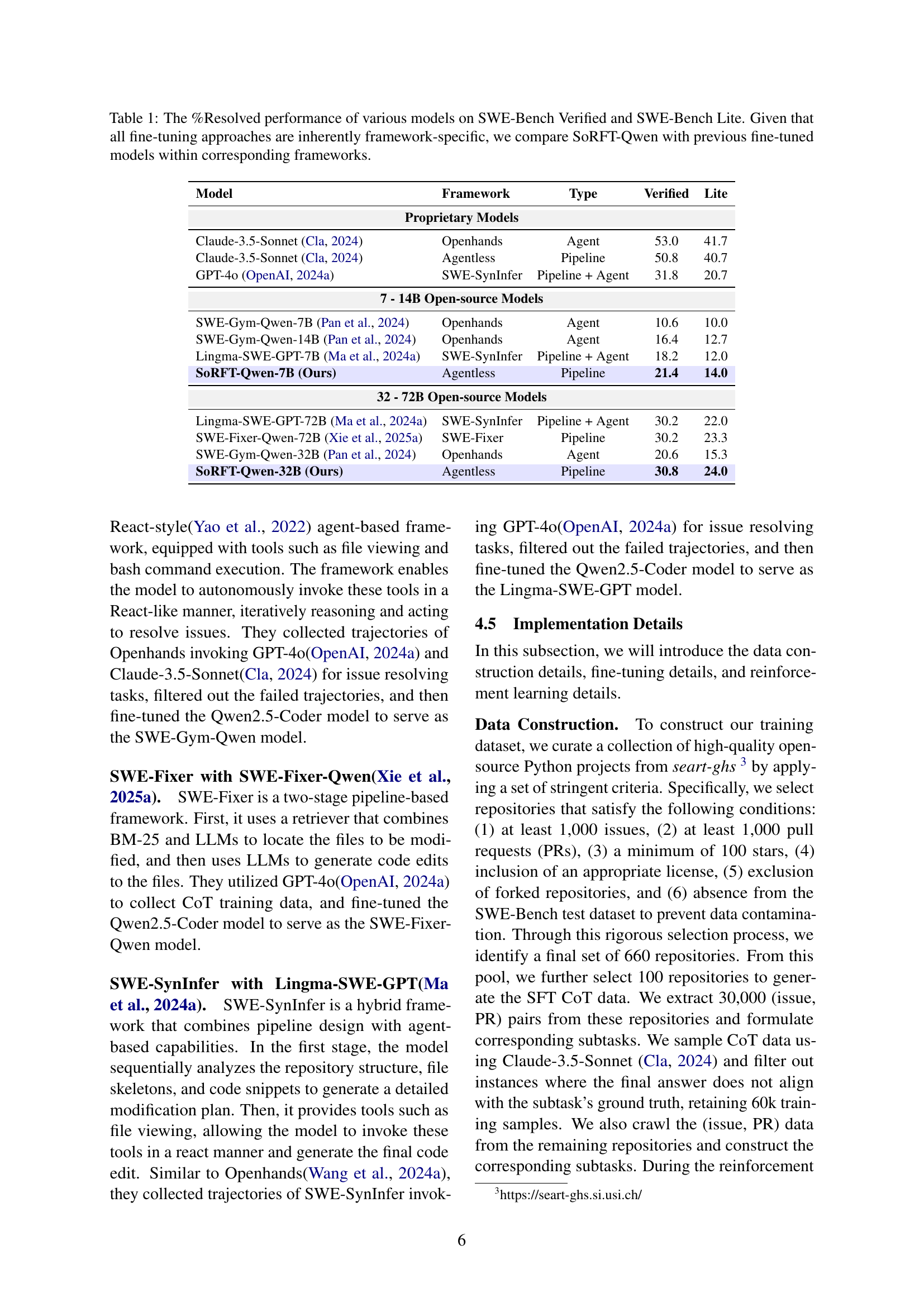
| Model | Framework | Type | Verified | Lite |
| Proprietary Models | ||||
| Claude-3.5-Sonnet Cla (2024) | Openhands | Agent | 53.0 | 41.7 |
| Claude-3.5-Sonnet Cla (2024) | Agentless | Pipeline | 50.8 | 40.7 |
| GPT-4o OpenAI (2024a) | SWE-SynInfer | Pipeline + Agent | 31.8 | 20.7 |
| 7 - 14B Open-source Models | ||||
| SWE-Gym-Qwen-7B Pan et al. (2024) | Openhands | Agent | 10.6 | 10.0 |
| SWE-Gym-Qwen-14B Pan et al. (2024) | Openhands | Agent | 16.4 | 12.7 |
| Lingma-SWE-GPT-7B (Ma et al., 2024a) | SWE-SynInfer | Pipeline + Agent | 18.2 | 12.0 |
| SoRFT-Qwen-7B (Ours) | Agentless | Pipeline | 21.4 | 14.0 |
| 32 - 72B Open-source Models | ||||
| Lingma-SWE-GPT-72B (Ma et al., 2024a) | SWE-SynInfer | Pipeline + Agent | 30.2 | 22.0 |
| SWE-Fixer-Qwen-72B (Xie et al., 2025a) | SWE-Fixer | Pipeline | 30.2 | 23.3 |
| SWE-Gym-Qwen-32B Pan et al. (2024) | Openhands | Agent | 20.6 | 15.3 |
| SoRFT-Qwen-32B (Ours) | Agentless | Pipeline | 30.8 | 24.0 |
🔼 This table compares the performance of different large language models (LLMs) on two benchmark datasets for software issue resolution: SWE-Bench Verified and SWE-Bench Lite. The performance metric used is the percentage of issues resolved (%Resolved). Because different LLMs were fine-tuned within specific frameworks (e.g., Agentless, Openhands), this table focuses on comparing the SoRFT-Qwen model to other models that were fine-tuned using the same framework. This ensures a fair comparison by controlling for the influence of the underlying framework.
read the caption
Table 1: The %Resolved performance of various models on SWE-Bench Verified and SWE-Bench Lite. Given that all fine-tuning approaches are inherently framework-specific, we compare SoRFT-Qwen with previous fine-tuned models within corresponding frameworks.
In-depth insights#
RL for Issue Fix#
Reinforcement Learning (RL) offers a promising avenue for automated issue fixing by training models to generate code edits based on rewards derived from ground-truth patches. This approach leverages the vast repository of resolved issues in open-source projects, using the (issue, patch) pairs as training data. By decomposing the complex issue-resolving task into subtasks like file, function, and line localization, and code edit generation, RL can be applied more effectively. Rule-based reward systems, which use ground-truth data to evaluate the LLM generated code, can mitigate reward hacking. Fine-tuning techniques like Rejection-sampled Supervised Fine-Tuning (SFT) and Proximal Policy Optimization (PPO) enhance model generalization and produce more accurate and reliable code modifications. RL in conjunction with SFT helps to reduce redundant code generation, improve code length and accuracy.
Subtask SoRFT#
The paper introduces Subtask-oriented Reinforced Fine-Tuning (SoRFT) as a method to enhance LLMs for issue resolution by decomposing the task into subtasks such as file, function, and line localization, and code edit generation. This approach aims to improve generalization and leverage open-source resources effectively. SoRFT includes two stages: rejection-sampled supervised fine-tuning (SFT) and rule-based reinforcement learning (RL). The SFT stage filters CoT data using ground truth, and the RL stage uses PPO with ground-truth rewards. The SoRFT addresses the challenge of constructing end-to-end training data for complex tasks, enabling targeted training for each phase of issue resolution, ultimately improving the model’s issue-resolving performance.
SOTA Open Models#
The paper presents SoRFT, achieving state-of-the-art (SOTA) performance among open-source LLMs in issue resolution. Specifically, SoRFT-Qwen-7B outperforms SWE-Gym-Qwen-32B on SWE-bench Verified, showing its efficiency. The more powerful version, SoRFT-Qwen-32B even surpasses Lingma-SWE-GPT-72B, despite having fewer parameters. This demonstrates SoRFT’s ability to effectively leverage open-source resources. While OpenHands benefits from proprietary models, the SWE-Gym model, tailored for it, underperforms. This highlights the advantage of the pipelined approach for CoT data filtering and reward calculation.
No Unique Fixes#
Issue resolution often lacks a single, definitive solution, reflecting the complexity of real-world software development. Different approaches may address the same problem with varying degrees of effectiveness or side effects. This variability stems from factors like coding style, system architecture, and project-specific requirements. A successful fix could involve multiple valid code changes, each impacting performance, maintainability, or security differently. The absence of a ‘one-size-fits-all’ solution necessitates a nuanced understanding of the problem context and careful evaluation of potential fixes. Researchers need to account for this non-uniqueness when evaluating issue-resolving frameworks, considering multiple acceptable solutions rather than rigidly adhering to a single ground truth. This challenge requires more sophisticated metrics and evaluation methodologies that can effectively compare and contrast the quality of different valid fixes.
Limited to Py#
The paper acknowledges a limitation in their experimental setup: they only conducted experiments on Python repositories. This constraint stems from the absence of a multilingual SWE-Bench test set. While acknowledging this restriction, they express confidence that SoRFT, their proposed framework, remains language-agnostic. They believe it possesses the inherent potential to enhance issue-resolving capabilities of LLMs, even when applied to code written in other languages beyond just Python. This highlights an area for future research and development.
More visual insights#
More on figures

🔼 SoRFT is composed of three stages: (1) Issue decomposition into four subtasks (file, function, line localization and code edit generation); (2) Supervised fine-tuning of LLMs using rejection-sampled Chain-of-Thought (CoT) data to align model reasoning with task format and methods; (3) Rule-based reinforcement learning using Proximal Policy Optimization (PPO) with ground-truth rewards to further enhance issue-resolving performance.
read the caption
Figure 2: SoRFT consists three parts: (1) decompose issue resolving into four subtasks: file localization, function localization, line localization and code edit generation; (2) fine-tune LLMs with rejection-sampled CoT data to enable it follow the task format and reasoning methods for each subtask; (3) employ rule-based reinforcement learning to further enhance the issue resolving ability of LLMs.

🔼 Figure 3 visualizes the SoRFT framework’s architecture. It is composed of three main stages: subtask decomposition, rejection-sampled supervised fine-tuning (SFT), and rule-based reinforcement learning (RL). The subtask decomposition breaks down the issue-resolving task into four subtasks: file localization, function localization, line localization, and code edit generation. The SFT stage uses a teacher LLM to generate Chain-of-Thought (CoT) data and filters out negative samples based on ground truth answers before fine-tuning the LLM. Finally, the RL stage employs rule-based reinforcement learning with proximal policy optimization (PPO) and reward mechanisms based on ground truth answers for each subtask, further enhancing the LLM’s issue-resolving abilities.
read the caption
(a)

🔼 Figure 2(b) shows the second stage of the SoRFT framework, which is rejection-sampled supervised fine-tuning. In this stage, a teacher LLM generates Chain-of-Thought (CoT) data for each subtask (file, function, line localization, and code edit generation). Negative samples are filtered out based on ground truth answers. Then, supervised fine-tuning is performed on the remaining positive samples to enable the model to understand the format and reasoning mechanisms of each subtask.
read the caption
(b)

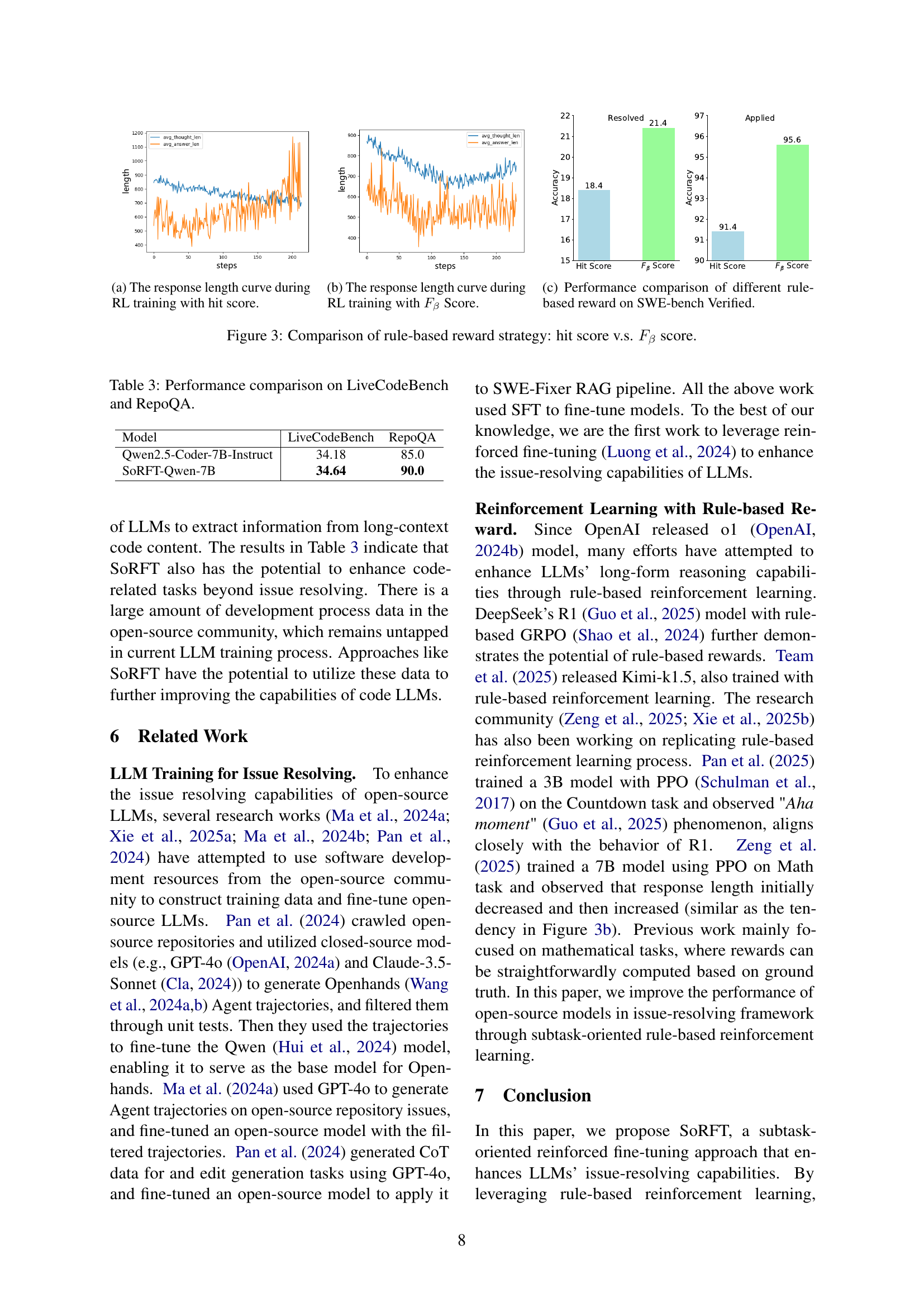
🔼 This figure shows the performance comparison of different rule-based reward strategies on the SWE-bench Verified dataset. The x-axis represents the training steps, and the y-axis represents the average length of responses and thoughts generated by the model during training. The left chart displays the response length, and the right chart displays the thought length for different reward strategies. The results reveal that a robust reward rule using FB score leads to more stable and better performance compared to the simpler hit score.
read the caption
(c)

🔼 This figure compares the performance of two different reward strategies used in reinforcement learning for an issue-resolving task. The first strategy, ‘hit score’, simply rewards the model if any part of its generated response matches the ground truth. The second strategy, ‘Fβ score’, uses a more nuanced evaluation metric (F-beta score) which balances precision and recall, giving more weight to recall (β > 1). The plots in Figure 3 show the change in response length and the total number of answers generated over training steps using each of these reward strategies. The comparison demonstrates that the Fβ score leads to more stable and effective model learning compared to the simpler hit score which is vulnerable to reward hacking.
read the caption
Figure 3: Comparison of rule-based reward strategy: hit score v.s. Fβsubscript𝐹𝛽F_{\beta}italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT score.

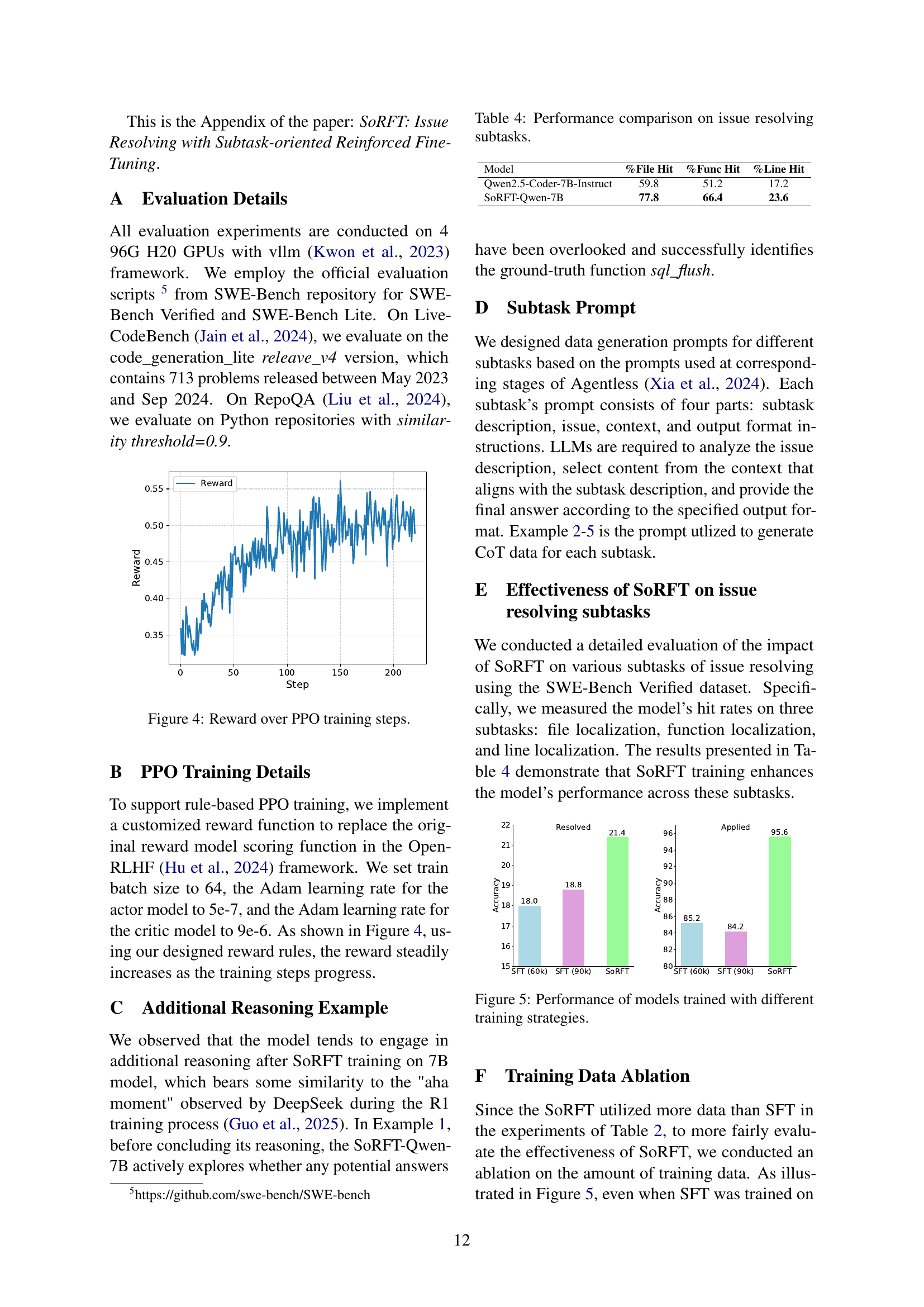
🔼 This figure shows the reward trend during the Proximal Policy Optimization (PPO) training process. The reward, which reflects the performance of the model on the issue-resolving subtasks, steadily increases as the training progresses, indicating successful learning and improvement of the model.
read the caption
Figure 4: Reward over PPO training steps.
More on tables
| Model | %Resolved | %Applied |
| Qwen2.5-Coder-7B-Instruct | 7.6 | 55.6 |
| + SFT | 18.0 | 85.2 |
| + SFT + RL (Our SoRFT-Qwen-7B) | 21.4 | 95.6 |
| Qwen2.5-Coder-32B-Instruct | 25.6 | 84.4 |
| + SFT | 28.8 | 90.6 |
| + SFT + RL (Our SoRFT-Qwen-32B) | 30.8 | 95.8 |
🔼 This table presents a comparison of the performance of a language model trained using different methods on the SWE-Bench Verified dataset. It shows the improvement in issue resolution (% Resolved) and the successful application of generated code edits (% Applied) when using supervised fine-tuning (SFT) alone versus when combining SFT with rule-based reinforcement learning (RL) as in the SoRFT approach. The table helps to demonstrate the effectiveness of the SoRFT method in improving model performance.
read the caption
Table 2: Performance comparison of model with different training strategy on SWE-bench Verified.
| Model | LiveCodeBench | RepoQA |
| Qwen2.5-Coder-7B-Instruct | 34.18 | 85.0 |
| SoRFT-Qwen-7B | 34.64 | 90.0 |
🔼 This table presents a comparison of the performance of two models, Qwen2.5-Coder-7B-Instruct and SoRFT-Qwen-7B, on two code generation benchmarks: LiveCodeBench and RepoQA. LiveCodeBench focuses on self-contained code generation tasks, while RepoQA assesses a model’s ability to extract information from long-context code snippets. The table shows the percentage of tasks successfully completed (%Resolved) and the accuracy of the generated code (%Applied) for each model and benchmark, allowing for a direct comparison of their performance on different types of code generation challenges.
read the caption
Table 3: Performance comparison on LiveCodeBench and RepoQA.
| Model | %File Hit | %Func Hit | %Line Hit |
| Qwen2.5-Coder-7B-Instruct | 59.8 | 51.2 | 17.2 |
| SoRFT-Qwen-7B | 77.8 | 66.4 | 23.6 |
🔼 Table 4 presents a comparison of the performance of different models on three subtasks involved in resolving software issues: file localization, function localization, and line localization. It shows the percentage of times each model successfully identified the correct file, function, and line of code related to the issue. This helps to assess the effectiveness of the models at various stages of the issue-resolution process.
read the caption
Table 4: Performance comparison on issue resolving subtasks.
Full paper#