TL;DR#
Current text-to-image generation models struggle with complex instructions that weave text and visuals. Though methods exist to add control signals like edges or depth maps, they lack flexibility for complex text-image instructions, like merging visual elements from multiple images using natural language. To solve this issue, the paper explores utilizing large multimodal models (LMMs) to use their capabilities for more flexible control.
The paper introduces DREAM ENGINE, a framework for text-image interleaved control in image generation models. It replaces text encoders with versatile multimodal encoders like QwenVL, and uses a two-stage training: text-image alignment and interleaved instruction tuning. This enables the model to generate images guided by text and image, designs a new object driven generation task to enable composition. Achieves a 0.69 score on GenEval.
Key Takeaways#
Why does it matter?#
This research is pivotal as it simplifies complex image manipulation tasks by leveraging LMMs. The DREAM ENGINE framework introduces new methods for creative image generation, improving efficiency and customization, opening doors for further exploration in multimodal AI research.
Visual Insights#
🔼 Figure 1 showcases the capabilities of Dream Engine in generating images using a novel text-image interleaved control mechanism. Unlike traditional methods that rely solely on text prompts, Dream Engine merges concepts from multiple source images to produce a single output image guided by both text and image input. The figure presents several example images generated by Dream Engine, demonstrating its ability to combine visual elements from diverse sources according to complex textual instructions. This illustrates the power of Dream Engine in generating highly customized and creative images by flexibly integrating textual instructions with visual elements selected from a variety of source images.
read the caption
Figure 1: Generation examples of Dream Engine. Leveraging powerful text-to-image diffusion model and large multimodal models, Dream Engine is capable of generating image with text-image interleaved control by merging concepts from different images.
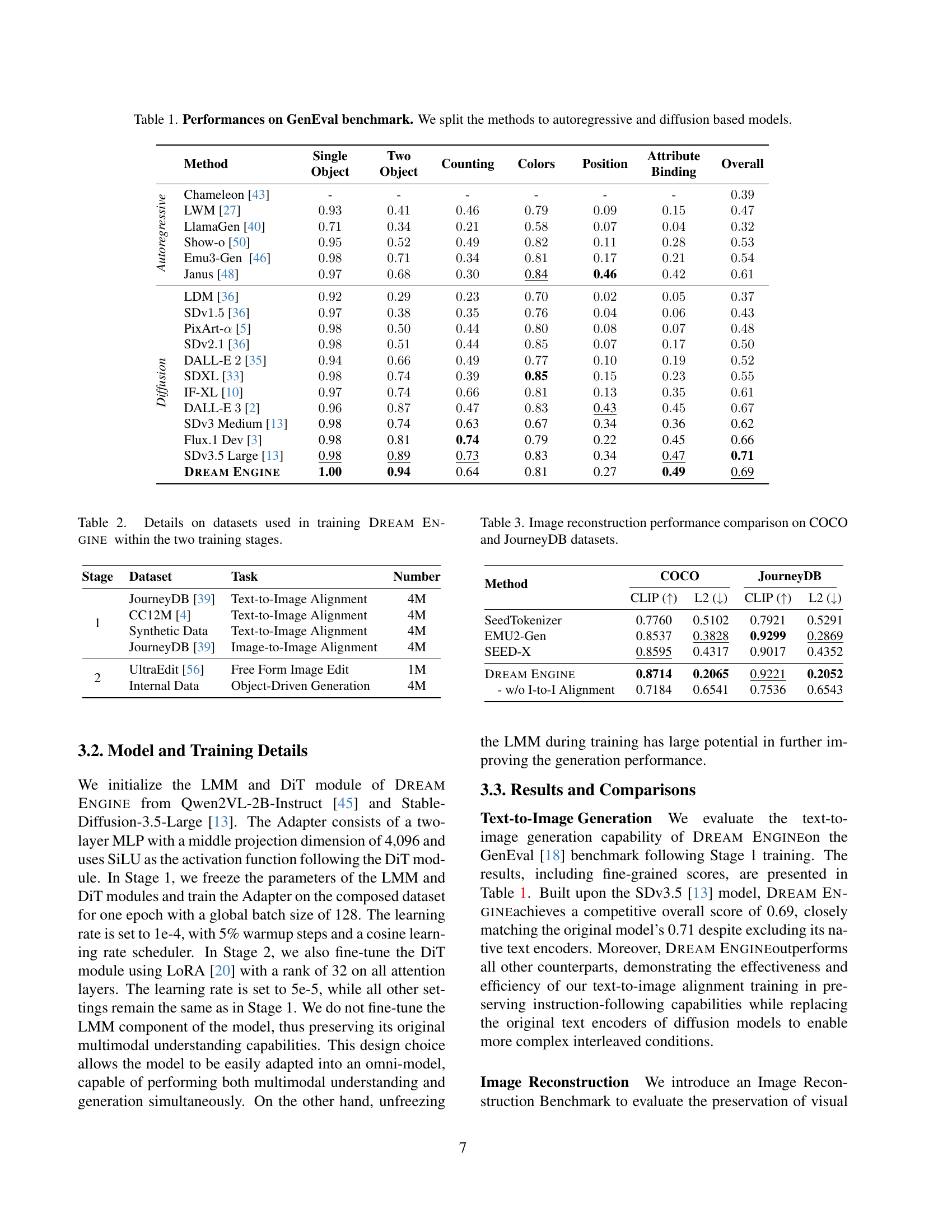
| Method | Single Object | Two Object | Counting | Colors | Position | Attribute Binding | Overall | |
|---|---|---|---|---|---|---|---|---|
| Autoregressive | Chameleon [43] | - | - | - | - | - | - | |
| LWM [27] | ||||||||
| LlamaGen [40] | ||||||||
| Show-o [50] | ||||||||
| Emu-Gen [46] | ||||||||
| Janus [48] | 0.84 | 0.46 | ||||||
| Diffusion | LDM [36] | |||||||
| SDv [36] | ||||||||
| PixArt- [5] | ||||||||
| SDv [36] | ||||||||
| DALL-E [35] | ||||||||
| SDXL [33] | 0.85 | |||||||
| IF-XL [10] | ||||||||
| DALL-E [2] | 0.43 | |||||||
| SDv3 Medium [13] | 0.98 | 0.74 | 0.63 | 0.67 | 0.34 | 0.36 | 0.62 | |
| Flux.1 Dev [3] | 0.98 | 0.81 | 0.74 | 0.79 | 0.22 | 0.45 | 0.66 | |
| SDv3.5 Large [13] | 0.98 | 0.89 | 0.73 | 0.83 | 0.34 | 0.47 | 0.71 | |
| Dream Engine | 1.00 | 0.94 | 0.64 | 0.81 | 0.27 | 0.49 | 0.69 |
🔼 This table presents the performance comparison of various generative models on the GenEval benchmark. The benchmark evaluates the models’ capabilities across multiple aspects of image generation, including their ability to generate images containing a single object, two objects, attributes, and to accurately count, represent colors, and position objects within the generated image. The models are categorized into autoregressive and diffusion-based models for clearer comparison, providing a comprehensive overview of their strengths and weaknesses in different aspects of image generation.
read the caption
Table 1: Performances on GenEval benchmark. We split the methods to autoregressive and diffusion based models.
In-depth insights#
LMMs for GenAI#
Large Multimodal Models (LMMs) are emerging as a pivotal component in Generative AI (GenAI), particularly for tasks involving image generation and manipulation. The key advantage lies in their ability to process and align information from both textual and visual domains, enabling more sophisticated control over the generative process. By encoding both text prompts and visual cues (e.g., reference images, object segmentations) into a unified representation space, LMMs allow for nuanced instructions that go beyond simple text-to-image synthesis. This is crucial for tasks like image editing, where users can specify precise modifications using natural language while preserving visual consistency. The power of LMMs stems from their pre-training on massive datasets, which equips them with a rich understanding of visual concepts and their relationships with language. This pre-existing knowledge can then be transferred to downstream tasks through fine-tuning or adapter-based approaches, reducing the need for extensive task-specific training. One promising direction is the use of LMMs to guide diffusion models, which have become the dominant approach for high-quality image generation. By replacing or augmenting the traditional text encoders in diffusion models with LMMs, it becomes possible to incorporate visual information and complex textual instructions into the generation process. This can lead to more controllable and creative image synthesis, with applications in areas such as content creation, design, and art. Further research is needed to explore the full potential of LMMs for GenAI, particularly in areas such as multimodal reasoning, few-shot learning, and robustness to adversarial attacks. However, the initial results are promising, suggesting that LMMs will play an increasingly important role in shaping the future of GenAI.
Text-Image Fusion#
While ‘Text-Image Fusion’ isn’t a direct heading in this paper, the entire work fundamentally revolves around it. The core idea is to effectively merge textual and visual information to guide image generation. The authors emphasize the limitations of existing methods in handling complex, interleaved text-image instructions. The paper highlights the potential of Large Multimodal Models (LMMs) as a unified representation space for both text and images. This is crucial for coherent alignment and allows the model to understand intricate relationships between textual descriptions and visual elements extracted from multiple source images. The proposed DREAM ENGINE leverages this fusion to enable creative image manipulation tasks like object insertion, attribute transfer, and scene composition, demonstrating a significant step towards more intuitive and controllable image generation. This fusion contrasts with earlier methods that primarily rely on text alone or treat images as simple conditioning signals.
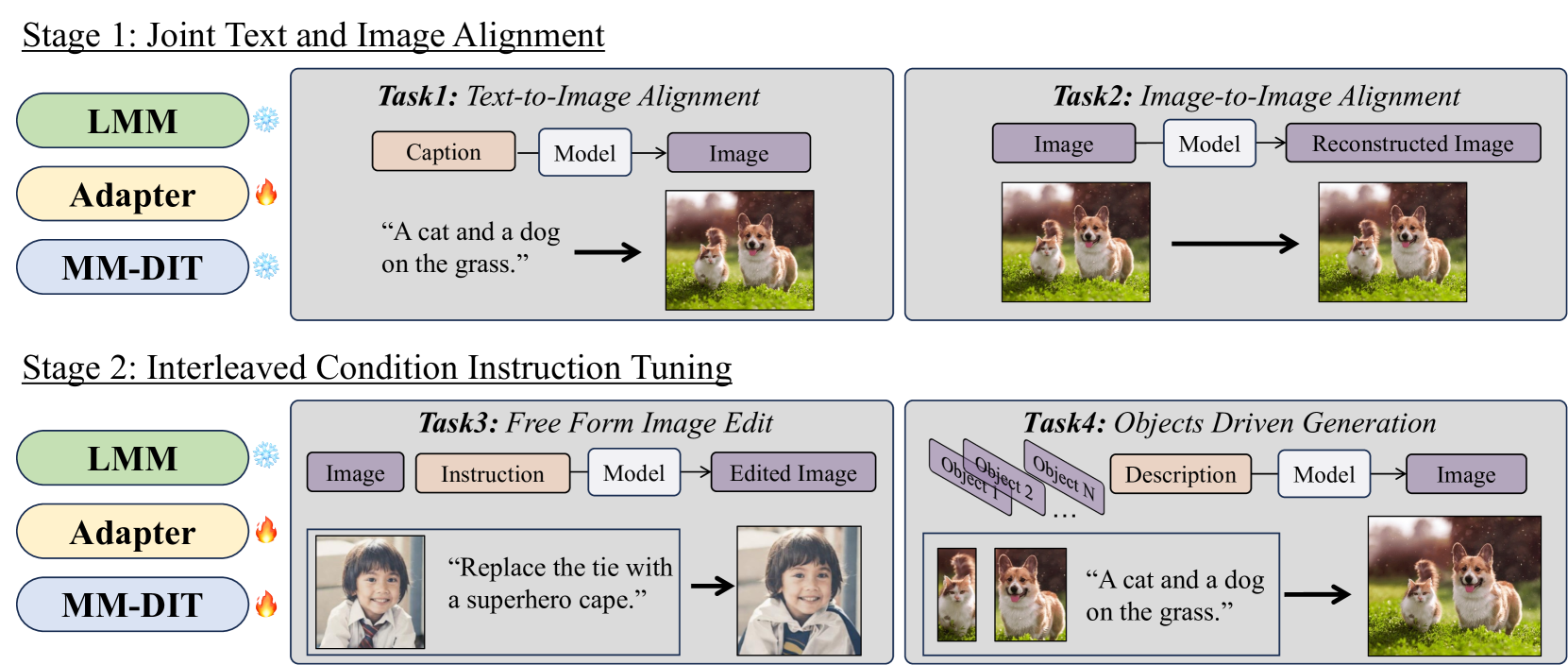
Two-Stage Tuning#
The paper introduces a two-stage training paradigm designed for aligning the LMM with the diffusion model, addressing the critical challenge of bridging different representation spaces. The first stage focuses on joint text and image alignment, freezing the LMM and DiT while training an adapter to map LMM outputs to the DiT’s conditioning space. This stage establishes foundational understanding of image-text correspondence. Then, in the second stage the interleaved condition instruction tuning, the DiT module is unfrozen and trained alongside the adapter. This dual approach facilitates sophisticated control of the generation process, leveraging both modalities and generating high-quality images with a great level of detail.
Object Control#
Object control in image generation signifies manipulating specific objects within a scene based on user input. This involves isolating, modifying, or replacing objects while maintaining overall scene coherence. Achieving precise object control requires models to understand object boundaries, attributes, and relationships within the image. Current research explores methods like bounding box control, segmentation masks, and attribute-based manipulation. Challenges include handling complex scenes with occlusions, preserving object identities during modifications, and ensuring semantic consistency. Future advancements may involve incorporating 3D object representations, integrating knowledge graphs for reasoning about object relationships, and developing interactive interfaces for fine-grained control. Effective object control opens avenues for creative applications such as personalized content creation, image editing, and virtual environment design by allowing focused manipulation.
Visual Fidelity#
Visual fidelity is a critical aspect of image generation, referring to the degree to which a generated image accurately and realistically represents the intended scene or subject. Achieving high visual fidelity involves several factors. Color accuracy ensures that the generated image exhibits colors consistent with the real world. Similarly, texture reproduction is vital for capturing the tactile and visual characteristics of surfaces. Geometric accuracy guarantees that shapes and forms are depicted correctly and without distortions. Lighting and shading effects contribute significantly to the realism of an image, influencing how objects interact with light and shadows. Overall, visual fidelity is crucial for producing images that are not only aesthetically pleasing but also plausible and believable. High-fidelity image generation requires sophisticated techniques to handle the complexities of light, materials, and spatial relationships, pushing the boundaries of current AI models. Visual Fidelity is the Key to making realistic and believable images.
More visual insights#
More on figures
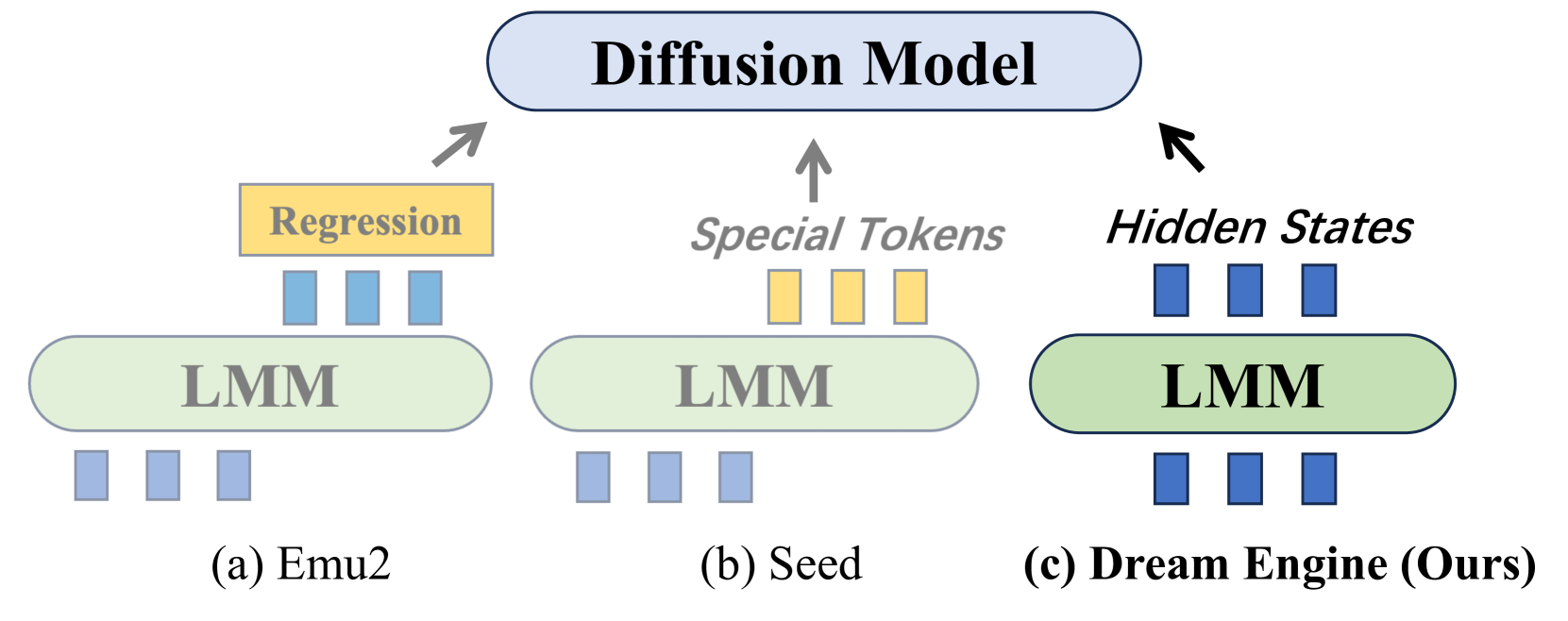
🔼 This figure compares different approaches of integrating Large Multimodal Models (LMMs) with diffusion models for image generation. It showcases three different architectures: Emu1/Emu2 which add a regression head to the LMM’s hidden states; Seed Tokenizer which expands the LMM vocabulary with visual tokens; and Dream Engine (the authors’ method), which uses a simpler design involving a direct connection between the LMM and the diffusion model. The figure highlights that Dream Engine achieves superior performance despite its simpler design.
read the caption
Figure 2: Overview Comparison. Among all types of works connecting LMM and diffusion model, our Dream Engine adopts the simplest design yet achieves the best performance.

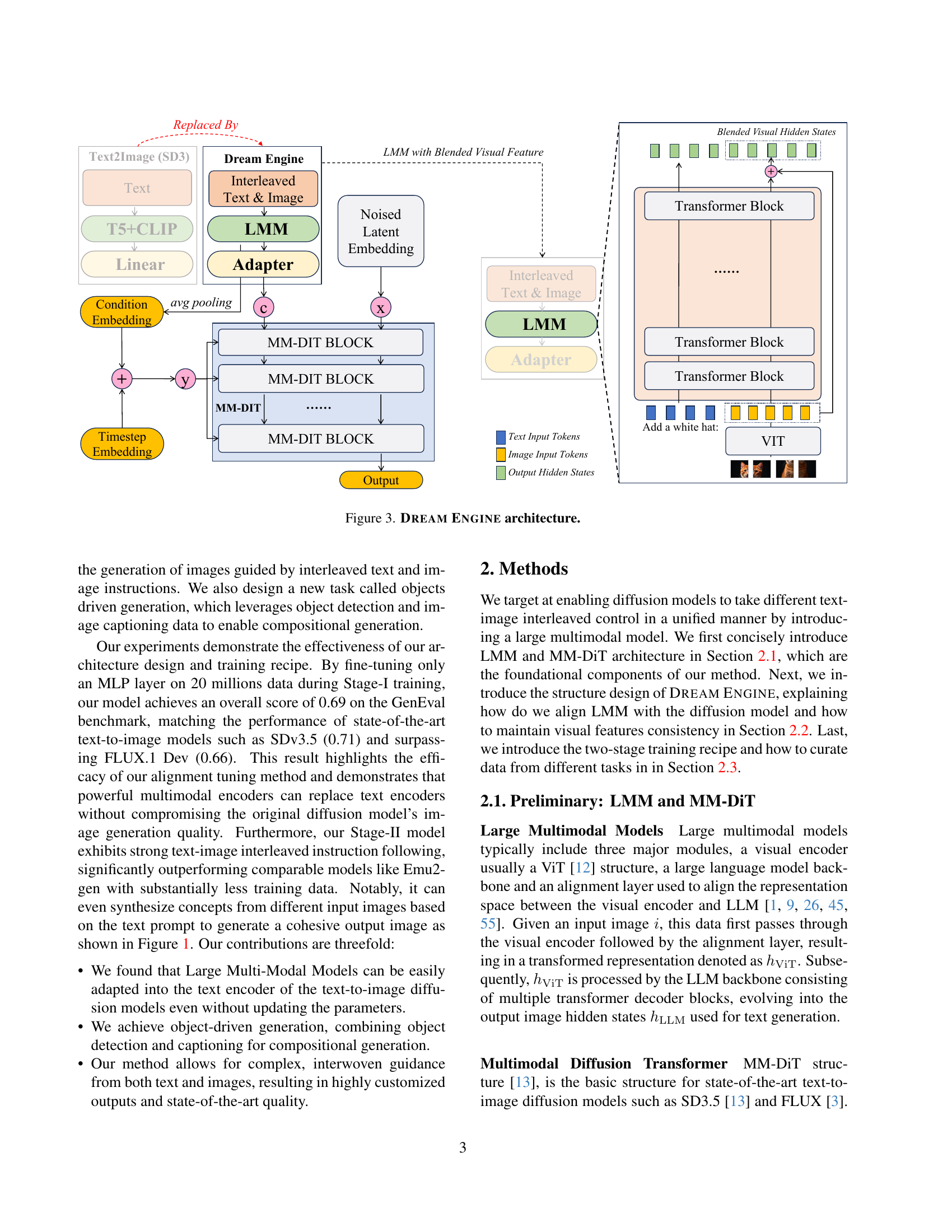
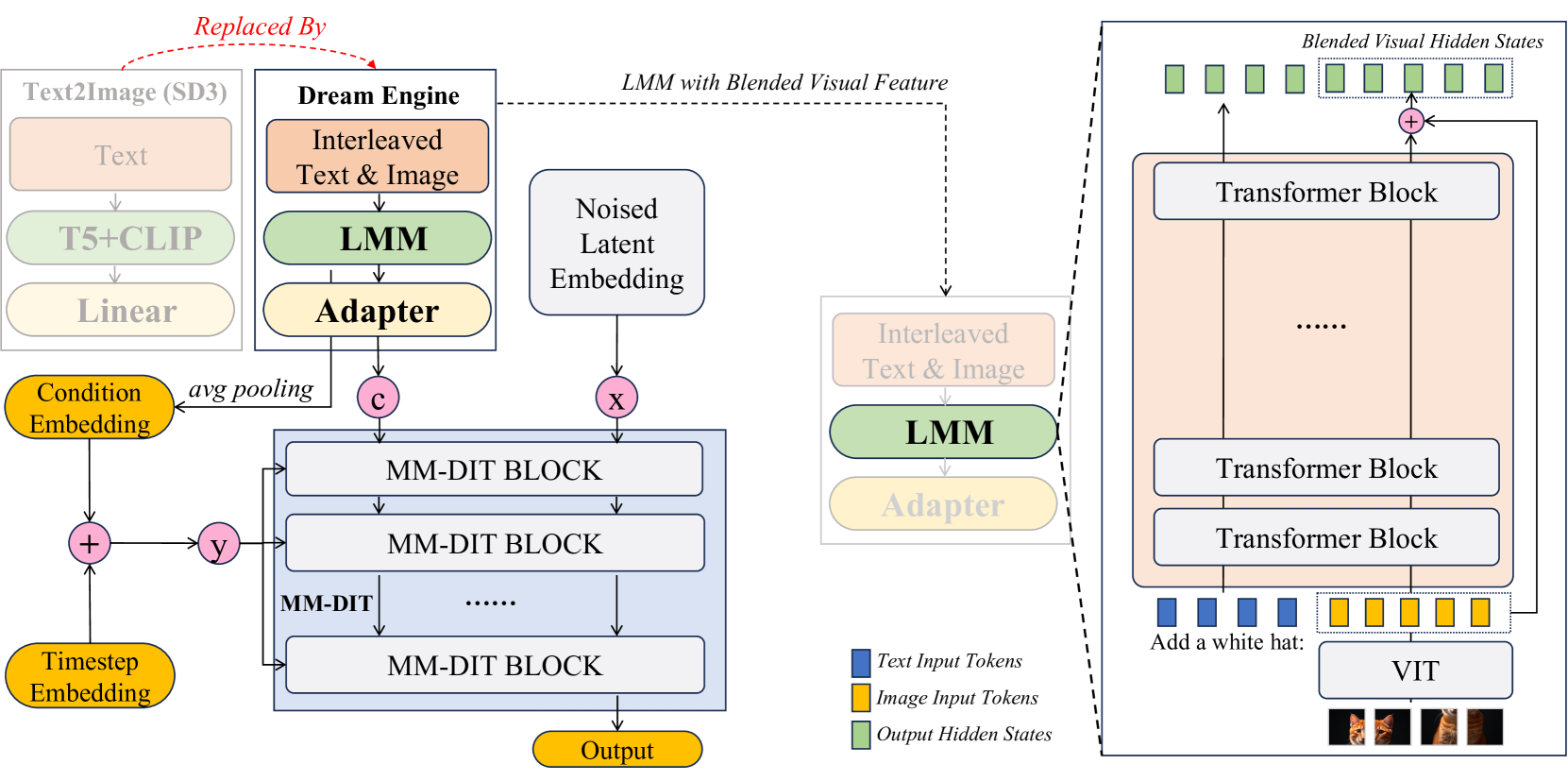
🔼 The DREAM ENGINE architecture diagram illustrates the process of image generation guided by interleaved text and image instructions. It starts with text and image inputs that are processed through a linear layer and a powerful Large Multimodal Model (LMM), producing blended visual features. These features, along with text embeddings and timestep information, are fed into a series of Multimodal Diffusion Transformer (MM-DiT) blocks. These blocks iteratively refine the representation, culminating in a final output that can be converted into a generated image using a text-to-image model (e.g., Stable Diffusion v3.5). An adapter module aligns the output of the LMM with the MM-DiT’s input requirements. The architecture showcases the integration of a powerful LMM for effective multimodal representation and control, leading to sophisticated image generation from text-image interleaved instructions.
read the caption
Figure 3: Dream Engine architecture.
🔼 Figure 4 showcases Dream Engine’s ability to seamlessly integrate multiple objects into complex scenes. Unlike previous models, Dream Engine isn’t limited to simple object placement, it can intelligently merge objects from various sources into a unified background. The example in the last row demonstrates this capability, where a cat and a girl are both added to a beach scene, showcasing a high level of compositional understanding.
read the caption
Figure 4: Performance demonstration on Natural Object Background Merging where Dream Engine can understand complex text-image input. It can even set more than one object in the background (last line).

🔼 This figure illustrates the two-stage training process of Dream Engine. Stage 1 focuses on aligning the representation spaces of the Large Multimodal Model (LMM) and the Multimodal Diffusion Transformer (MM-DiT) using two tasks: Text-to-Image Alignment and Image-to-Image Alignment. In Stage 2, the MM-DiT is fine-tuned to handle interleaved text and image instructions using two more tasks: Free Form Image Editing and Objects Driven Generation. The diagrams show the inputs (text, images, instructions), the model components used, and the outputs (edited images, generated images) for each task, making it clear how the model’s capabilities are built up in stages.
read the caption
Figure 5: Training stages and tasks of Dream Engine.

🔼 This figure showcases a comparison between Dream Engine and Emu2-Gen on an image generation task involving complex instructions. The task, termed ‘Object Driven Feature Mixing,’ requires the model to generate images incorporating features from two source images according to a textual description. The example demonstrates Dream Engine’s ability to successfully generate images that incorporate features from both source images as instructed. In contrast, Emu2-Gen is shown to fail this task. The figure highlights Dream Engine’s superior ability to understand and execute complex, multi-modal (text and image) instructions, which combines elements from different images based on the user’s instructions.
read the caption
Figure 6: Performance demonstration on Object Driven Feature Mixing task. Dream Engine can understand the complex instruction while Emu2-Gen fails on the task.

🔼 Figure 7 showcases a comparison between Dream Engine and Emu2-Gen on a free-form image editing task. Multiple example edits are shown, highlighting Dream Engine’s superior ability to precisely follow complex and nuanced instructions, resulting in higher-quality output images compared to Emu2-Gen. Each row presents the same source image with various modifications based on different instructions, illustrating how well each model understands and implements the given edits.
read the caption
Figure 7: Performance demonstration on Free Form Image Editing task. Dream Engine outperforms the counterpart Emu2-Gen model in both instruction following and output image quality.

🔼 This figure visualizes the evolution of image reconstruction quality during the training process of the DREAM ENGINE model. The image reconstruction task is part of Stage 1 training, focusing on aligning the representation spaces between the Large Multimodal Model (LMM) and the Multimodal Diffusion Transformer (MM-DiT). The figure shows that initially, the model captures only high-level concepts, such as the presence of a person, an object, or a landscape. As training progresses, the reconstruction gradually incorporates more detail, showcasing a concept-to-detail transition. This visual representation demonstrates how the model learns to accurately reproduce the source image, moving from broad semantic understanding to fine-grained detail.
read the caption
Figure 8: Image reconstruction performance dynamics during training. We can see that there is a concept-to-detail transition during the training period.
More on tables
| Stage | Dataset | Task | Number |
| 1 | JourneyDB [39] | Text-to-Image Alignment | 4M |
| CC12M [4] | Text-to-Image Alignment | 4M | |
| Synthetic Data | Text-to-Image Alignment | 4M | |
| JourneyDB [39] | Image-to-Image Alignment | 4M | |
| 2 | UltraEdit [56] | Free Form Image Edit | 1M |
| Internal Data | Object-Driven Generation | 4M |
🔼 This table details the datasets used to train the Dream Engine model. It breaks down the datasets used in each of the two training stages: Stage 1 (Joint Text and Image Alignment) and Stage 2 (Interleaved Condition Instruction Tuning). For each stage, it lists the specific tasks performed (e.g., Text-to-Image Alignment, Image-to-Image Alignment, Free Form Image Edit, Object Driven Generation), the datasets used for each task, and the number of samples in each dataset. This provides a comprehensive overview of the data that contributed to the model’s training and helps to understand the model’s capabilities and limitations.
read the caption
Table 2: Details on datasets used in training Dream Engine within the two training stages.
| Method | COCO | JourneyDB | ||
|---|---|---|---|---|
| CLIP () | L2 () | CLIP () | L2 () | |
| SeedTokenizer | 0.7760 | 0.5102 | 0.7921 | 0.5291 |
| EMU2-Gen | 0.8537 | 0.3828 | 0.9299 | 0.2869 |
| SEED-X | 0.8595 | 0.4317 | 0.9017 | 0.4352 |
| Dream Engine | 0.8714 | 0.2065 | 0.9221 | 0.2052 |
| - w/o I-to-I Alignment | 0.7184 | 0.6541 | 0.7536 | 0.6543 |
🔼 This table presents a quantitative comparison of image reconstruction performance using different methods on two benchmark datasets: COCO and JourneyDB. It shows the CLIP score (a measure of similarity between the original and reconstructed images) and the L2 distance (a measure of pixel-level difference). The table allows for a comparison of DREAM ENGINE’s performance against several baseline approaches, highlighting its effectiveness in preserving image features during the reconstruction process.
read the caption
Table 3: Image reconstruction performance comparison on COCO and JourneyDB datasets.
Full paper#