TL;DR#
Multi-modal Large Language Models (MLLMs) show promise in video understanding, their grasp of human actions lags due to data scarcity. Existing datasets often provide coarse captions, failing to capture nuanced behaviors crucial for emotional analysis and relationship modeling, especially in multi-person scenarios. Challenges include accumulating videos with clear multi-person actions and defining caption formats that distinguish individuals and detail their interactions.
To solve the issue, the paper introduces a novel two-stage data generation pipeline. The method accumulates videos featuring clear human actions and annotates them using a standardized caption format that distinguishes individuals by attributes and details their actions/interactions chronologically. This approach curates HAICTrain (126K video-caption pairs) for training and HAICBench (500 annotated pairs, 1,400 QA pairs) for evaluation. Experiments show HAICTrain enhances human understanding abilities and text-to-video generation.
Key Takeaways#
Why does it matter?#
This work significantly enhances human action understanding by introducing high-quality, detailed video caption data and evaluation resources, offering immediate improvements and opening new avenues for research in video understanding and generation. It provides the resources of HAICTrain and HAICBench.
Visual Insights#

🔼 This figure showcases the standardized caption format used to annotate videos in the HAIC dataset. Each caption chronologically details the attributes (e.g., age, clothing, etc.) of each individual in the video clip, describes their body actions, and outlines their interactions with others. This structured format significantly improves the clarity and facilitates accurate understanding of complex multi-person interactions compared to simpler captioning methods.
read the caption
Figure 1: Our standardized caption format presents each individual’s detailed attributes, body actions, and interactions in chronological order, making it easier to distinguish individuals and comprehend their behaviors.
| Category | Example |
|---|---|
| What gesture does the middle-aged woman make while talking to the other man? | |
| Interaction | (A) Gestures with both hands clasped in front of her (B) Claps her hands (C) Waves her hands in the air (D) Points at the desk |
| What does the man in the black hat do with his right hand as he starts skateboarding? | |
| Action Details | (A) He waves it in greeting (B) He points down the slope (C) He places it on his hip (D) He keeps it in his pocket |
| What does the man in the gray cap do immediately after gripping the barbell? | |
| Action Sequence | (A) He looks at the camera (B) He adjusts his hat (C) He bends down and lowers the barbell (D) He walks towards his front left and rubs his hands together |
| How many times does the man clap his hands? | |
| Count | (A) Three (B) Four times (C) Once (D) Twice |
| What color is the cropped jacket worn by the young female character in the video? | |
| Attribute | (A) Pink (B) White (C) Blue (D) Black |
🔼 Table 1 presents example questions from the HAICBench dataset, illustrating its comprehensive evaluation of human action understanding. It showcases how the dataset assesses understanding across different dimensions: spatial (details of individual actions), temporal (order and number of actions), and multi-person interactions (actions and attributes of multiple individuals). The questions highlight the nuanced aspects of human action captured by HAICBench, demonstrating its ability to test a wide range of understanding capabilities beyond simple action recognition.
read the caption
Table 1: Task examples of HAICBench, showcasing a comprehensive human action understanding across spatial (action details), temporal (sequence, count), and multi-human interaction (interaction and attribute) aspects.
In-depth insights#
Action-centric LLM#
While the paper doesn’t explicitly discuss an “Action-centric LLM,” we can infer its potential role by analyzing the paper’s focus on human action understanding. Such a model would likely prioritize detailed action recognition and prediction. This means going beyond simple activity classification to analyzing fine-grained movements, interactions, and temporal sequences. The HAIC dataset’s rich captions could be crucial for training this type of LLM, enabling it to differentiate between subtle variations in action and understand the context in which they occur. Furthermore, an Action-centric LLM would need to effectively model multi-person interactions, accurately attributing actions to specific individuals based on their attributes and relationships. This would require a sophisticated understanding of human social dynamics and the ability to reason about intent and motivation. HAIC’s question answering dataset, particularly the interaction-focused questions, would be invaluable for evaluating this aspect of the model’s performance. Ultimately, an Action-centric LLM could have significant implications for applications like human-computer interaction, autonomous driving, and video generation, enabling more natural and intuitive interactions and more realistic virtual environments.
HAIC: Details Matter#
HAIC: Details Matter emphasizes the critical role of fine-grained details in human action understanding within videos. Existing MLLMs often struggle due to coarse captions lacking nuanced descriptions of behaviors, interactions, and individual attributes. HAIC addresses this by introducing a novel data annotation pipeline that meticulously accumulates videos featuring clear human actions and employs a standardized caption format. This format distinguishes individuals using human attributes like age, clothing, and accessories while chronologically detailing body actions and interactions. By focusing on these details, HAIC aims to enhance MLLMs’ comprehension of complex human behavior, enabling tasks like emotional analysis, motivation prediction, and relationship modeling. This shift towards detail-oriented data promises to significantly improve the accuracy and applicability of MLLMs in various downstream tasks, including human-computer interaction, autonomous driving, and embodied intelligence. Essentially, HAIC recognizes that a deeper understanding of human actions requires moving beyond superficial descriptions and capturing the intricate nuances of human behavior within video data.
Action Data Pipeline#
The data pipeline focuses on curating videos with clear human actions. The pipeline starts with large-scale video sources, applying metadata filters to remove low-resolution videos and those lacking action-related descriptions. Scene splitting divides the videos into shorter clips with unique scenes. A crucial step is human existence filtering, ensuring that each frame contains a sufficient number of humans and that the bounding box area covers a significant portion of the frame. Human action filtering identifies and retains videos with clear human movement, discarding static scenes or gallery videos. The pipeline uses body keypoints and affine transformations to detect and remove static backgrounds. Overall, the video accumulation process prioritizes high-quality videos with evident human actions.
Better video generation#
While not explicitly a section, the paper hints at improving video generation through better action understanding. The authors create datasets with detailed captions, enabling models to learn fine-grained human actions and interactions. Training with this data demonstrably enhances the quality of generated videos, as captions become more semantically accurate. This implies that robust video generation relies heavily on the model’s capacity to comprehend the complexities of human behavior, moving beyond simplistic scene descriptions. Therefore, a future research direction should include an approach that can utilize these understandings for video generation.
Beyond visual data#
While visual data forms the cornerstone of many AI systems, particularly in areas like image recognition and video understanding, venturing beyond this modality unlocks significant potential. Integrating audio information, for instance, could provide crucial contextual cues currently missing. Imagine understanding a scene not just by what is seen, but also by the sounds accompanying it – a dog barking, a car screeching, or even the subtle nuances of human speech. Such additions can drastically improve the accuracy and robustness of AI systems. Furthermore, incorporating textual data beyond simple descriptions offers avenues for deeper analysis. Think of subtitles providing dialogue, scene descriptions offering emotional context, or metadata revealing cultural nuances. By fusing these diverse data streams, AI models can achieve a more holistic understanding, mimicking the way humans perceive and interpret the world. This multi-modal approach is paramount for truly intelligent systems capable of tackling complex real-world scenarios.
More visual insights#
More on figures

🔼 This figure illustrates the two-stage data generation pipeline used to create the HAICTrain and HAICBench datasets. Stage (a) shows the process of accumulating videos from the internet that contain clear human actions. This involves filtering videos based on metadata (resolution, presence of action verbs), ensuring sufficient human presence and action. Stage (b) details the creation of HAICTrain, where the collected videos are re-captioned using the Gemini-1.5-Pro LLM to create a standardized caption format. Finally, stage (c) describes the construction of HAICBench. This dataset is built using a combination of LLM-generated captions and QA pairs, which are subsequently reviewed and refined by human annotators. This results in a high-quality, manually-verified dataset ideal for evaluating multi-modal large language models.
read the caption
Figure 2: Our data generation pipeline. (a) The video accumulation stage collects videos featuring clear human actions from the Internet. Based on this, (b) HAICTrain is curated through Gemini-1.5-Pro re-captioning, and (c) HAICBench is created by LLM-assisted human annotation.

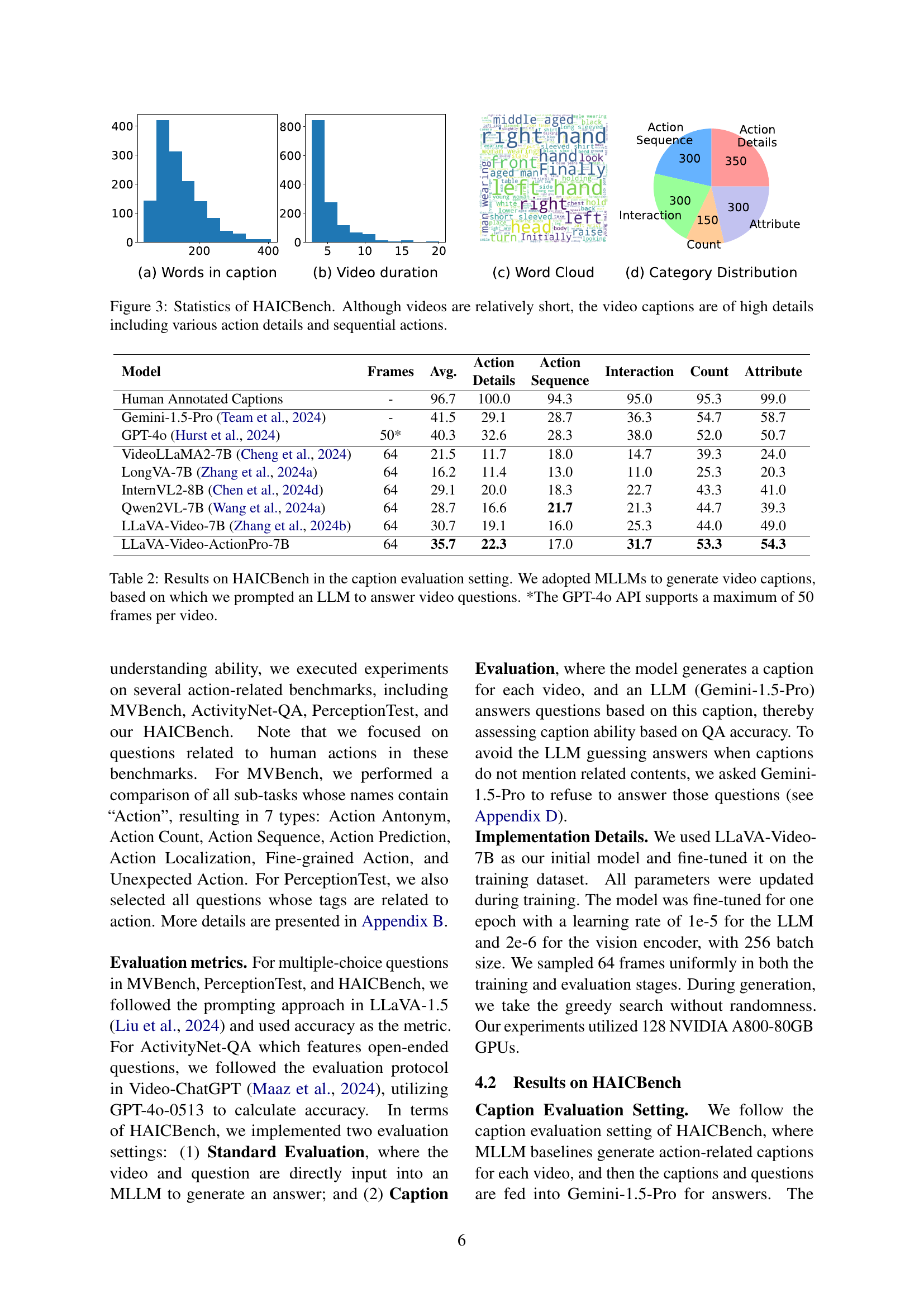
🔼 Figure 3 presents a statistical overview of the HAICBench dataset, showcasing several key characteristics. The first subplot (a) displays a histogram of the word counts in the captions, revealing the length and detail level of the descriptive text. The second subplot (b) is a histogram of the video durations within the dataset, demonstrating the generally short length of the videos. Subplot (c) provides a word cloud visualization of the most frequently used words in the captions, highlighting the common themes and actions captured within the dataset. Finally, subplot (d) illustrates the distribution of questions across five different categories (interaction, action details, action sequence, count, and attribute), offering insights into the diversity and scope of the information captured in the HAICBench annotations.
read the caption
Figure 3: Statistics of HAICBench. Although videos are relatively short, the video captions are of high details including various action details and sequential actions.

🔼 The figure shows a comparison of video captions generated by different models for the same video clip. The first caption is a concise description of the video, suitable for general video understanding tasks. However, it lacks the level of detail necessary for fine-grained action understanding. The second caption, generated using the HAIC annotation pipeline, shows a significantly more detailed and structured description. This caption includes specific attributes of the individuals involved (e.g., age, clothing, accessories), precise descriptions of their actions, and an accurate chronological ordering of events. This demonstrates the HAIC caption format’s ability to provide richer, more detailed annotations than existing methods, thereby improving the performance of downstream multimodal tasks.
read the caption
Figure 4: A video caption example in HAICBench.

🔼 This figure shows the detailed prompt used to instruct the Gemini-Pro language model to generate captions for videos in the HAICTrain dataset. The prompt emphasizes the importance of accurately describing the number of people in the video, their attributes (gender, age, clothing, etc.), and the sequence of their actions. It stresses that the description should be based solely on what is visually apparent in the video and not on any external knowledge or assumptions. The prompt provides two examples of correctly formatted captions to guide the model.
read the caption
Figure 5: Prompt for Gemini-Pro Re-captioning.

🔼 This figure shows the prompt used for generating question-answer pairs focusing on the interactions between individuals in a video. The prompt instructs an AI assistant to analyze a video caption describing the number of people, their attributes, and their actions. The assistant should then generate a multiple-choice question and answer about the interaction between subjects. The JSON format for the output is specified, requiring a question, candidate answers, and the correct answer.
read the caption
Figure 6: Prompt for action interaction QA generation.

🔼 This figure details the prompt used for generating question-answer pairs focusing on the details of actions within videos. The prompt instructs the LLM to create multiple-choice questions concerning precise actions, body movements, expressions, or postures within a video, emphasizing the use of specific body parts (e.g., left hand, right leg) and directional details (e.g., upward, downward, diagonally). The prompt further specifies the response format as JSON, with an example provided for clarity. It also requests the use of distinctive attributes to identify the subjects instead of generic labels like ‘Subject 1’.
read the caption
Figure 7: Prompt for action details QA generation.

🔼 This figure shows the prompt used for generating question-answer pairs focusing on action sequences within videos. The prompt instructs a large language model (LLM) to generate QA pairs from a video caption, where the question should focus on the order of actions. The question must include a phrase like ‘What does…do immediately after (or just before)…’, and it should specify attributes of the person to ensure clear identification. The answer options are limited to 15 words or less, with a JSON format required for the output. The prompt also includes examples for better understanding and proper formatting.
read the caption
Figure 8: Prompt for action sequence QA generation.

🔼 This figure displays the prompt used to instruct a large language model (LLM) for generating question-answer pairs related to the count of actions within a video. The prompt instructs the LLM to format the output as JSON, including a question about the number of times an action occurs, multiple choice answers, and the correct answer. The prompt also specifies that the question should be phrased as ‘How many…’, ensuring consistency in question formatting.
read the caption
Figure 9: Prompt for action count QA generation.
🔼 This figure shows the prompt used for generating question-answer pairs related to human attributes in the HAICBench dataset. The prompt instructs an AI assistant to generate a multiple-choice question-answer pair focusing on the attributes of the human subjects in a video. The AI should use detailed attributes to describe the people in the video instead of using generic labels like ‘Subject 1’. The format of the output should be JSON.
read the caption
Figure 10: Prompt for human attribute QA generation.

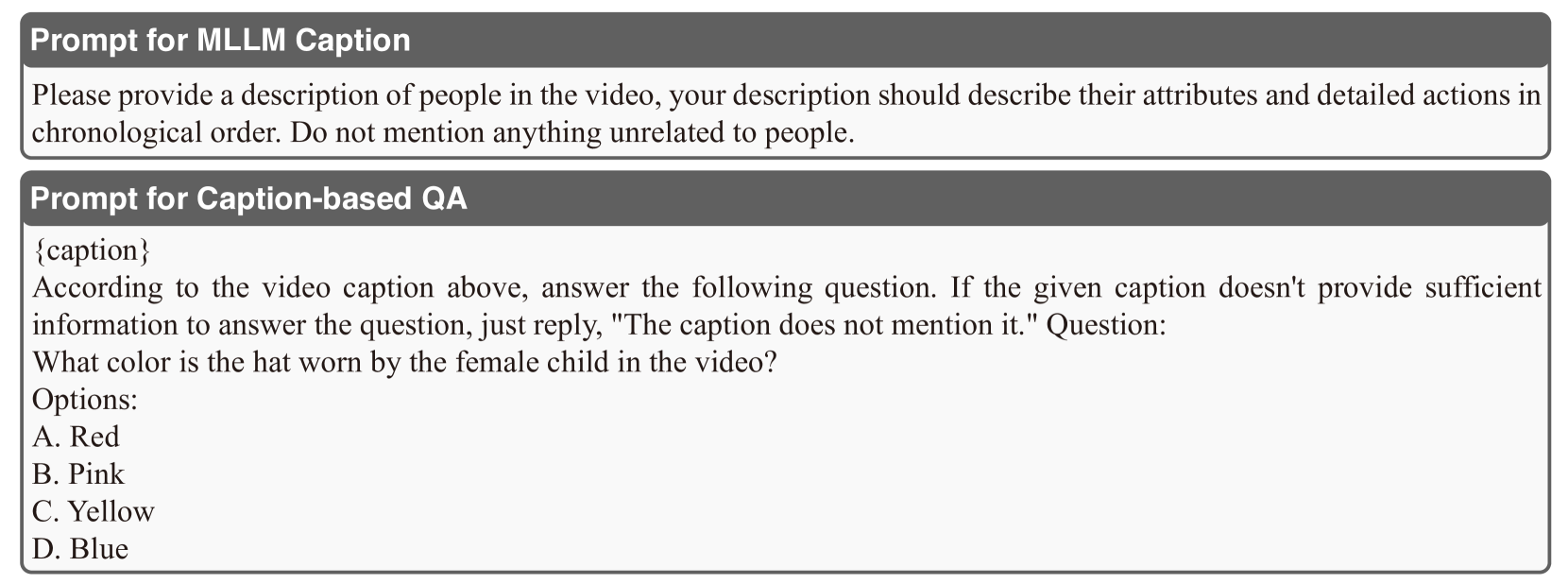
🔼 This figure details the prompt used for evaluating the captioning capabilities of various Multi-modal Large Language Models (MLLMs). The evaluation involves using a given video caption to answer a question about that video. The prompt provides a caption and asks for the color of the hat worn by a specific person shown in the video, providing four color options as choices.
read the caption
Figure 11: Prompt caption evaluation setting.

🔼 This figure displays a comparison of video generation results using two different models: LLaVA-Video and LLaVA-Video-ActionPro. Both models were given the same text caption as input, describing a woman walking down a street. The generated videos are shown, highlighting that LLaVA-Video-ActionPro produces a video with significantly more detail and visual fidelity regarding the woman’s appearance and attire compared to LLaVA-Video, which produces a less detailed and less realistic result.
read the caption
Figure 12: Videos generated by captions from LLaVA-Video and LLaVA-Video-ActionPro of the first sample in MovieGenBench. The main subject in this case is one woman walking along the street. LLaVA-Video-ActionPro provides a more detailed appearance of the woman than LLaVA-Video.

🔼 This figure compares video generation results from two different models, LLaVA-Video and LLaVA-Video-ActionPro, using the same caption. The caption describes a video clip from the MovieGenBench dataset featuring a single, blue animated character. The generated videos illustrate how LLaVA-Video-ActionPro more accurately captures the main subject of the video, while LLaVA-Video fails to correctly identify it, highlighting the improvement in subject identification achieved through the model’s improved captioning.
read the caption
Figure 13: Videos generated by captions from LLaVA-Video and LLaVA-Video-ActionPro of the 17th sample in MovieGenBench. The main subject in this case is one blue animated character. LLaVA-Video incorrectly identifies the main subject.
More on tables
| Model | Frames | Avg. |
|
| Interaction | Count | Attribute | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Human Annotated Captions | - | 96.7 | 100.0 | 94.3 | 95.0 | 95.3 | 99.0 | ||||
| Gemini-1.5-Pro Team et al. (2024) | - | 41.5 | 29.1 | 28.7 | 36.3 | 54.7 | 58.7 | ||||
| GPT-4o Hurst et al. (2024) | 50* | 40.3 | 32.6 | 28.3 | 38.0 | 52.0 | 50.7 | ||||
| VideoLLaMA2-7B Cheng et al. (2024) | 64 | 21.5 | 11.7 | 18.0 | 14.7 | 39.3 | 24.0 | ||||
| LongVA-7B Zhang et al. (2024a) | 64 | 16.2 | 11.4 | 13.0 | 11.0 | 25.3 | 20.3 | ||||
| InternVL2-8B Chen et al. (2024d) | 64 | 29.1 | 20.0 | 18.3 | 22.7 | 43.3 | 41.0 | ||||
| Qwen2VL-7B Wang et al. (2024a) | 64 | 28.7 | 16.6 | 21.7 | 21.3 | 44.7 | 39.3 | ||||
| LLaVA-Video-7B Zhang et al. (2024b) | 64 | 30.7 | 19.1 | 16.0 | 25.3 | 44.0 | 49.0 | ||||
| LLaVA-Video-ActionPro-7B | 64 | 35.7 | 22.3 | 17.0 | 31.7 | 53.3 | 54.3 |
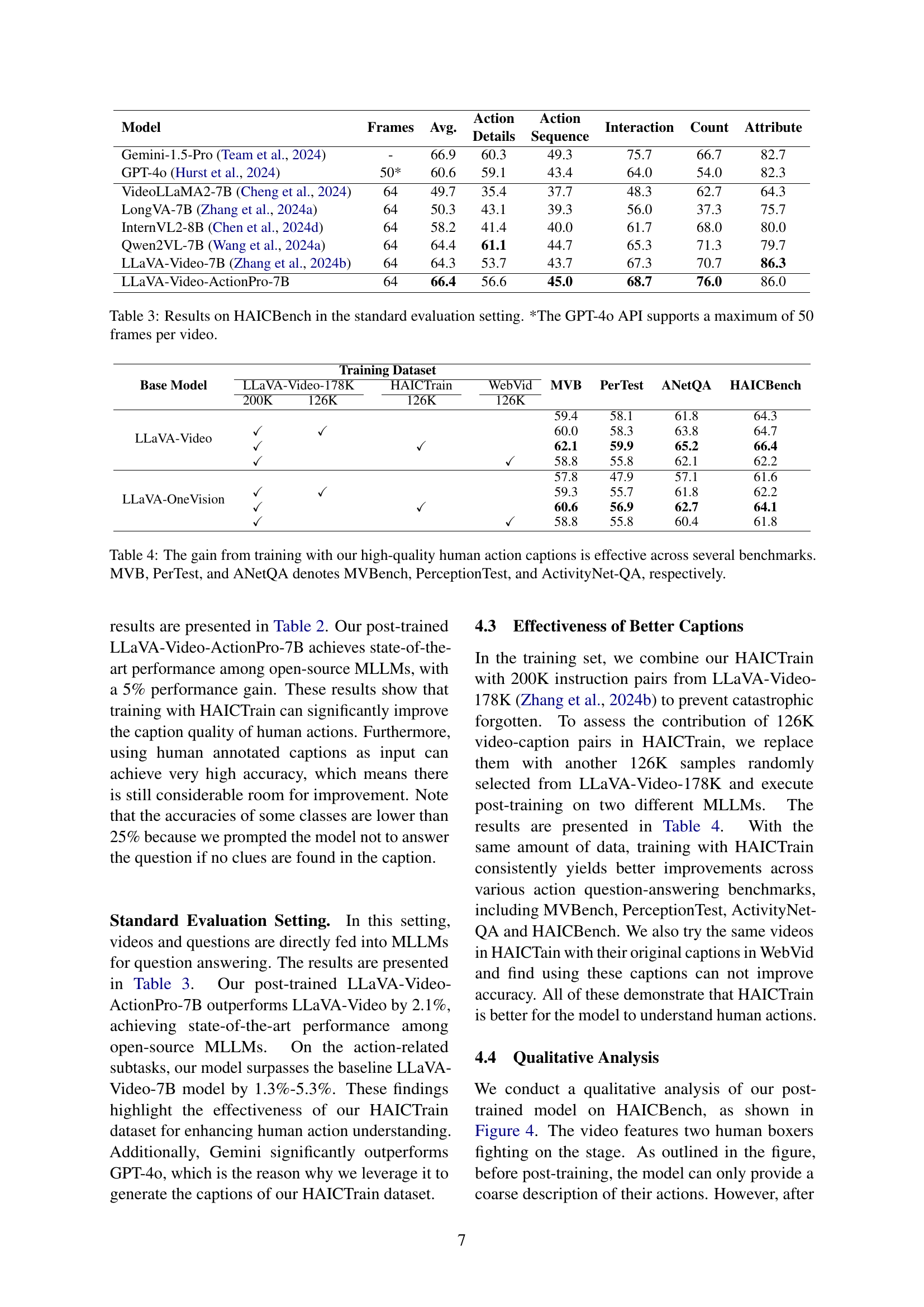
🔼 Table 2 presents the performance of various Multimodal Large Language Models (MLLMs) on the HAICBench dataset when using a caption-based evaluation approach. Each MLLM generated a caption for each video in the dataset, and then another LLM (Gemini-1.5-Pro) was used to answer questions about the video based solely on the generated caption. This setup isolates the quality of the generated caption as the primary factor determining the accuracy of the video understanding. The table shows the average accuracy across different aspects of human action understanding: frames, average accuracy, action details, action sequence, interaction, count, and attribute. The asterisk (*) indicates a limitation of the GPT-4o API used in this experiment, that only a maximum of 50 frames per video were processed. This table demonstrates the ability of different MLLMs to generate effective and descriptive captions, which are crucial for accurate video understanding.
read the caption
Table 2: Results on HAICBench in the caption evaluation setting. We adopted MLLMs to generate video captions, based on which we prompted an LLM to answer video questions. *The GPT-4o API supports a maximum of 50 frames per video.
| Action |
| Details |
🔼 This table presents the results of the HAICBench evaluation using a standard evaluation setting. The standard setting directly inputs the video and question into a multi-modal large language model (MLLM) to generate an answer. The table compares the performance of several different MLLMs across five action-related categories: Average, Action Details, Action Sequence, Interaction, and Count. Performance is measured by accuracy. Note that for GPT-40, the maximum number of frames processed per video was 50.
read the caption
Table 3: Results on HAICBench in the standard evaluation setting. *The GPT-4o API supports a maximum of 50 frames per video.
| Action |
| Sequence |
🔼 This table presents the performance gains achieved by training a large language model (LLM) on a dataset of high-quality human action captions. The effectiveness of this training is evaluated across four benchmarks: MVBench, PerceptionTest, ActivityNet-QA, and HAICBench. Each benchmark assesses different aspects of video understanding and human action recognition. The table shows that using the high-quality human action captions significantly improves the LLM’s performance on all benchmarks, demonstrating the benefit of this data for improving human action understanding.
read the caption
Table 4: The gain from training with our high-quality human action captions is effective across several benchmarks. MVB, PerTest, and ANetQA denotes MVBench, PerceptionTest, and ActivityNet-QA, respectively.
Full paper#