TL;DR#
Large language models are powerful, but their slow generation speed limits their practicality. Speculative decoding improves this by using a smaller “draft” model to predict multiple tokens at once, which are then verified by the larger “target” model. However, the draft model introduces overhead, becoming a bottleneck. Prior solutions often compromise the quality of the draft model to reduce this overhead.
DuoDecoding tackles this challenge by running the draft model on the CPU and the target model on the GPU, enabling parallel processing. It introduces a hardware-aware draft budget to balance CPU and GPU usage and uses dynamic multi-sequence drafting to improve draft quality. Experiments show DuoDecoding significantly speeds up generation while maintaining performance.
Key Takeaways#
Why does it matter?#
This paper is important as it addresses the critical challenge of inference speed in LLMs, offering a practical solution that balances performance and efficiency. By creatively leveraging heterogeneous computing, DuoDecoding opens new avenues for optimizing LLM deployment and can inspire future research.
Visual Insights#
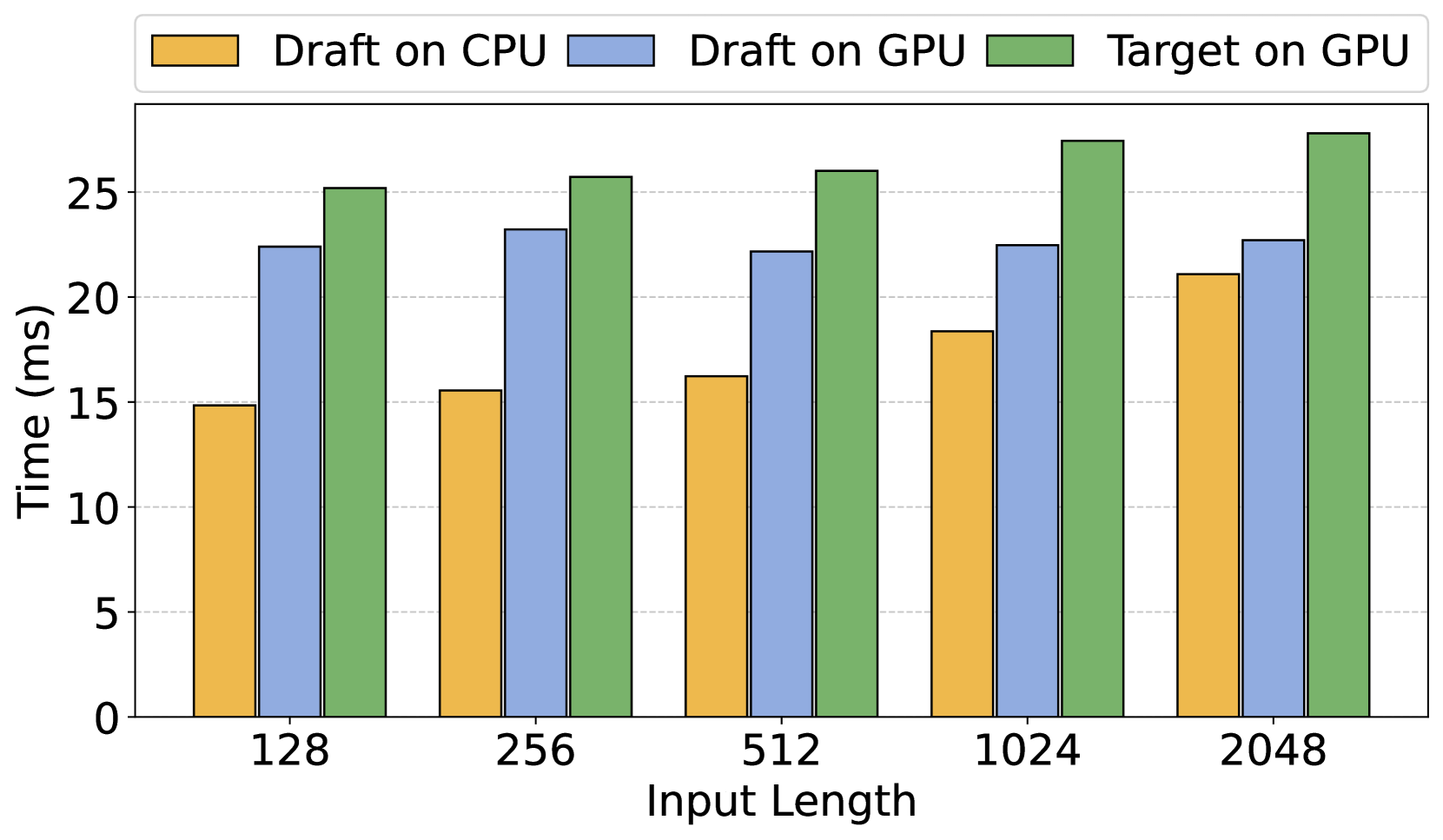
🔼 This figure displays the time taken for autoregressive generation using the draft model and parallel verification using the target model, both processing 8 tokens. The input sequence length varies, allowing for observation of how this affects the time for each phase. The key takeaway is that the draft model’s processing time, even when run on the CPU, becomes comparable to the target model’s verification time (which runs on the GPU), highlighting that it is a significant bottleneck. The results demonstrate that offloading the draft model to the CPU does not negatively impact overall generation efficiency.
read the caption
Figure 1: Wall time for draft model autoregressive generation and target model parallel verification of 8 tokens with varying input lengths. The draft phase has become a comparable bottleneck to the verification phase, and executing the lightweight draft model on CPU does not compromise generation efficiency.
| Draft Process on CPU: | Target Process on GPU: |
| dynamic_drafting(, ) |
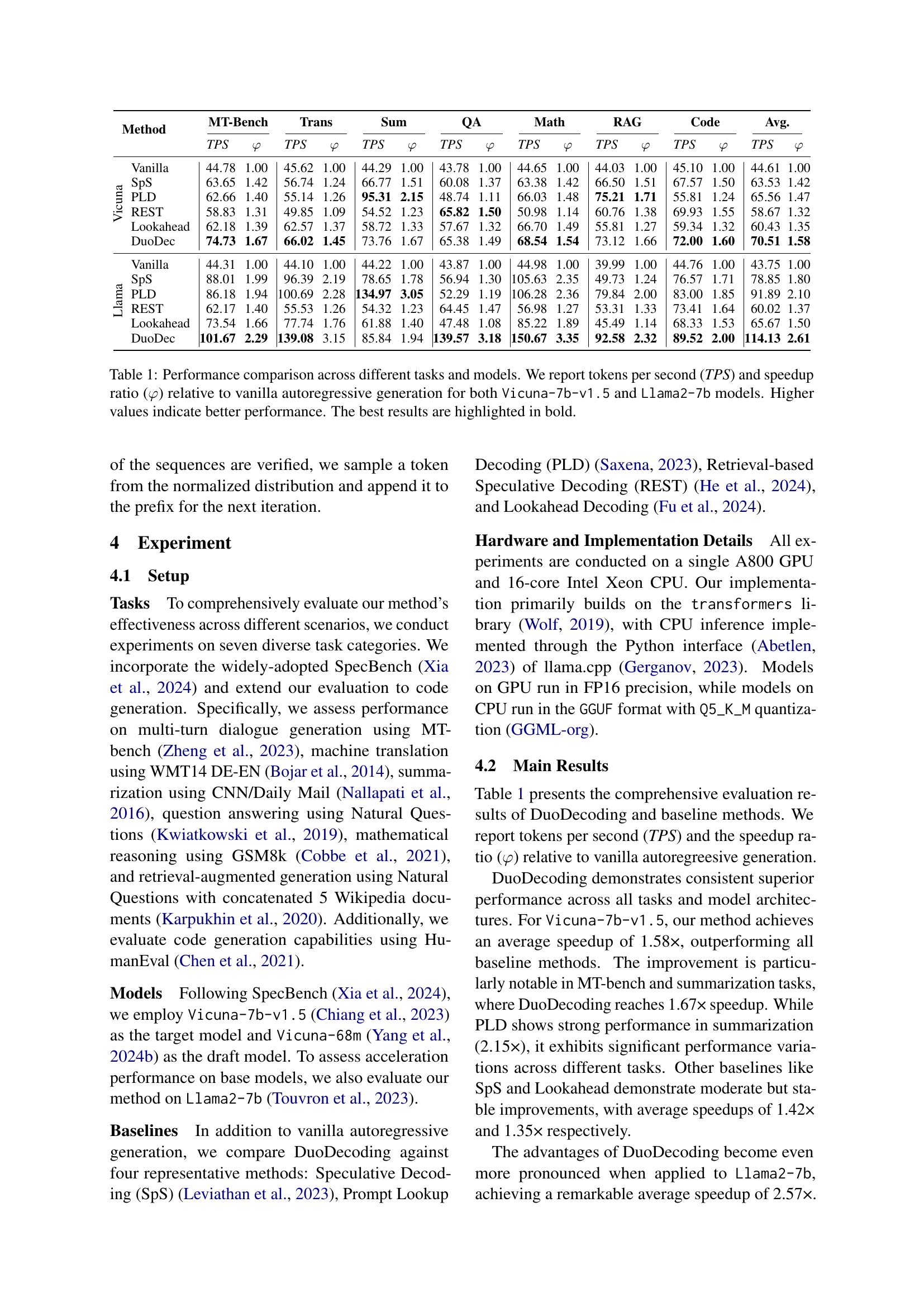
🔼 This table compares the performance of different language model decoding methods across various tasks and models. The metrics used are tokens per second (TPS), indicating the generation speed, and the speedup ratio (φ), showing the improvement compared to a standard autoregressive generation method. The comparison is done for two different language models: Vicuna-7b-v1.5 and Llama2-7b. Higher values for both TPS and φ are better, representing faster generation and greater efficiency. The best results for each task are highlighted in bold.
read the caption
Table 1: Performance comparison across different tasks and models. We report tokens per second (TPS) and speedup ratio (φ𝜑\varphiitalic_φ) relative to vanilla autoregressive generation for both Vicuna-7b-v1.5 and Llama2-7b models. Higher values indicate better performance. The best results are highlighted in bold.
In-depth insights#
CPU/GPU Synergy#
Leveraging CPU/GPU synergy is an intriguing direction for optimizing LLM inference, particularly in speculative decoding. Offloading the draft model to the CPU can alleviate the GPU bottleneck, allowing for parallel execution. The hardware-aware draft budget optimizes resource allocation by dynamically adjusting draft length based on the relative speeds of the CPU and GPU. This approach minimizes idle time and maximizes hardware utilization. A key benefit is the potential for reduced TTFT, as the GPU is not burdened by the draft model’s computations. Dynamic multi-sequence drafting helps to enhance draft quality by generating multiple token candidates in parallel, improving acceptance rates and overall efficiency. The effectiveness is heavily reliant on the specific hardware configuration, and the relative performance characteristics of the CPU and GPU. By employing CPU/GPU synergy, we can achieve better LLM inference performance.
Dynamic Drafting#
Dynamic drafting in speculative decoding dynamically adjusts the draft model’s output based on uncertainty. It seeks to enhance draft quality and reduce computational costs. This involves adjusting drafting length and sequence numbers, using metrics like uncertainty to guide decisions. A core idea is to use the draft model’s probabilities as a proxy for accuracy, influencing the decision to explore diverse candidate tokens. By varying drafting strategies based on context and generation stages, it aims to achieve better performance across diverse tasks. Different from static sequences, it improves overall efficiency by leveraging dynamic adaptations.
TTFT Reduction#
Reducing Time To First Token (TTFT) is crucial for interactive applications using Large Language Models(LLMs). While speculative decoding boosts overall generation speed, it often introduces overhead that can increase TTFT. This overhead stems from the initial drafting process, which requires additional computation before the first verified token can be produced. Effectively mitigating this requires careful optimization of the drafting stage. Strategies might involve lightweight draft models, parallel processing, or caching mechanisms to minimize the initial delay. A reduction in TTFT ensures a more responsive and user-friendly experience, especially for real-time interactions.
Budgeting Tradeoffs#
In the context of DuoDecoding, a strategic resource allocation is crucial for optimal performance. The ‘Budgeting Tradeoffs’ encapsulates the delicate balance between drafting and verification processes. A higher drafting budget allows the draft model to generate more candidate tokens, potentially uncovering longer sequences and greater acceleration. However, this comes at the risk of diminishing returns, where later tokens in a long draft sequence exhibit lower acceptance rates, thereby wasting computational resources. Conversely, a smaller budget restricts the potential for acceleration, limiting the number of speculated tokens verified in parallel. Finding the optimal budget point necessitates careful consideration of hardware capabilities and model characteristics. It also involves a dynamic adaptation of the budget based on real-time feedback on draft quality. A hardware-aware strategy dynamically adjusts the drafting budget to keep both CPU and GPU busy. A larger drafting budget can result in the GPU sitting idle. There is less time needed for the target model, resulting in an inefficient outcome. However, too small a budget the inverse is true: the CPU remains inactive.
Hetero Decoding#
Heterogeneous decoding could involve strategically using different decoding algorithms or model architectures within a single system to optimize for various criteria like speed, accuracy, or resource consumption. For example, a smaller, faster model might generate initial drafts, while a larger, more accurate model refines or verifies the output. This approach could leverage specialized hardware, dedicating certain processing units (like CPUs or GPUs) to specific decoding tasks. The strategy would aim to balance computational load and ensure high-quality output, potentially adapting the decoding process dynamically based on input complexity or available resources. The core goal is to achieve efficiency without compromising the integrity or quality of the generated content.
More visual insights#
More on figures

🔼 Figure 2 illustrates the dynamic multi-sequence drafting method used in DuoDecoding. The probability of each token (pi,j) is calculated, where ‘i’ is the token’s position in the sequence, and ‘j’ represents its rank among the generated candidates. A threshold (θ) is set, calculated as the product of the probabilities of the top two tokens in the first position (p1,1 * p2,1). Tokens with probabilities (p1,k) greater than θ will form a new draft sequence, improving overall acceptance rate of draft tokens. This multi-sequence approach is in contrast to single-sequence drafting where only the tokens with probability above the threshold in the first sequence would be accepted.
read the caption
Figure 2: Dynamic multi-sequence drafting. pi,jsubscript𝑝𝑖𝑗p_{i,j}italic_p start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT represents the probability of the j𝑗jitalic_j-th ranked token at the i𝑖iitalic_i-th position in the generated sequence. θ=p1,1×p2,1𝜃subscript𝑝11subscript𝑝21\theta=p_{1,1}\times p_{2,1}italic_θ = italic_p start_POSTSUBSCRIPT 1 , 1 end_POSTSUBSCRIPT × italic_p start_POSTSUBSCRIPT 2 , 1 end_POSTSUBSCRIPT serves as the threshold. Tokens with probabilities p1,ksubscript𝑝1𝑘p_{1,k}italic_p start_POSTSUBSCRIPT 1 , italic_k end_POSTSUBSCRIPT exceeding the threshold θ𝜃\thetaitalic_θ will continue to be predicted sequentially, forming a independent draft sequence.

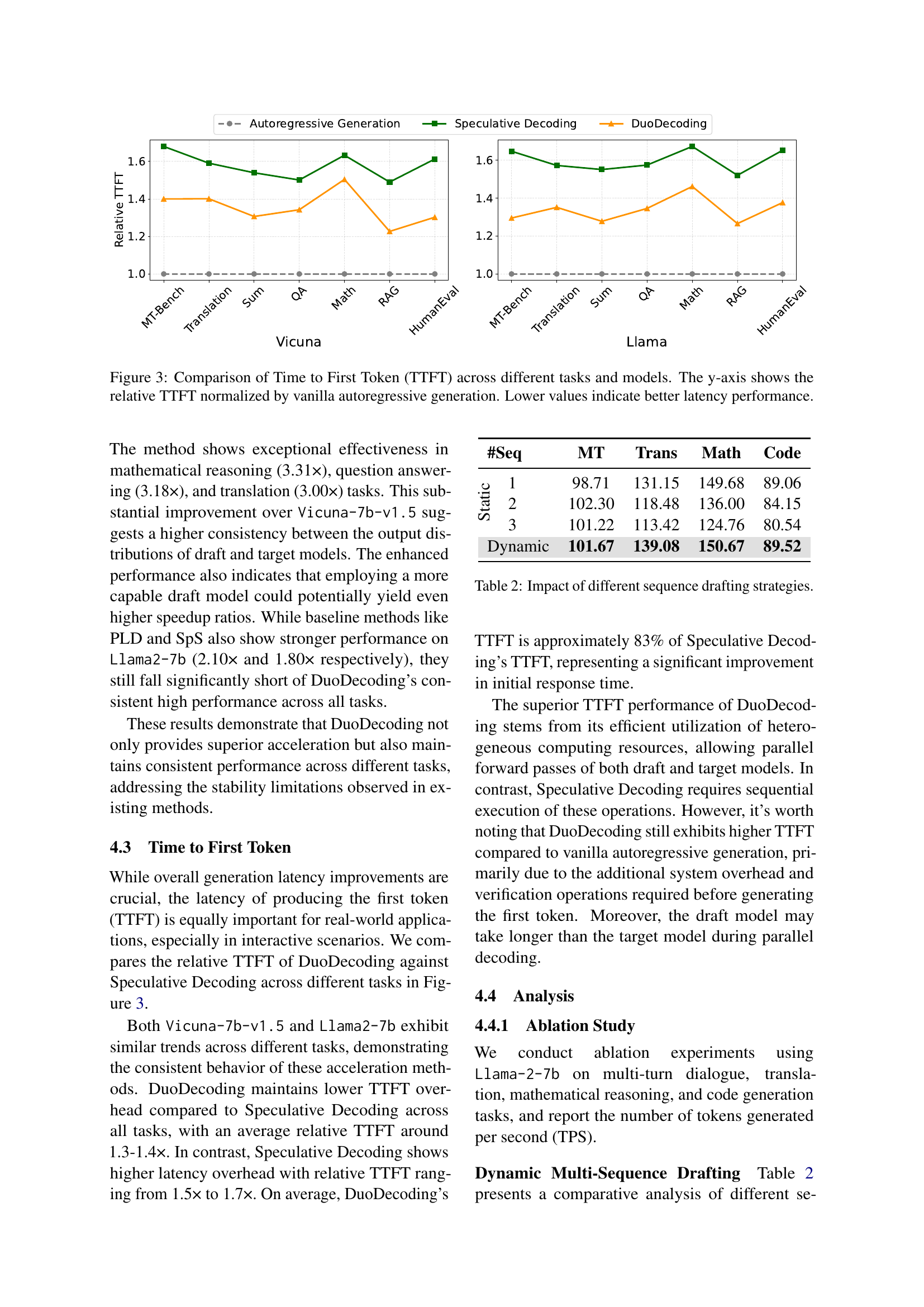
🔼 Figure 3 presents a comparison of the time to generate the first token (TTFT) across various tasks and language models, specifically Vicuna and Llama. The y-axis displays the relative TTFT, normalized against the TTFT achieved by a standard autoregressive generation method, providing a clear representation of latency improvements. Lower values on the y-axis represent a faster TTFT, indicating superior latency performance.
read the caption
Figure 3: Comparison of Time to First Token (TTFT) across different tasks and models. The y-axis shows the relative TTFT normalized by vanilla autoregressive generation. Lower values indicate better latency performance.

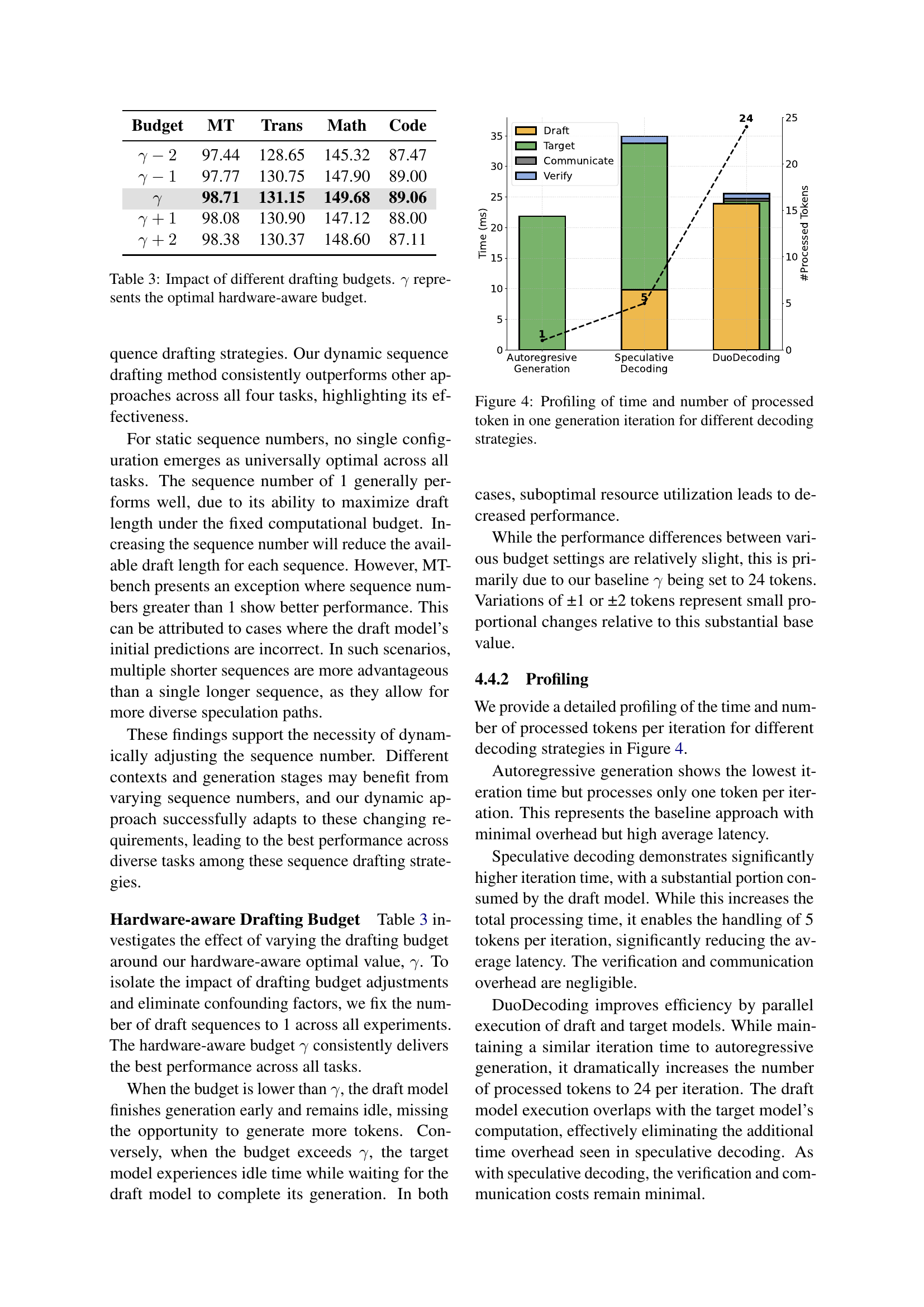
🔼 This figure presents a detailed performance breakdown for different decoding methods during a single generation iteration. It compares autoregressive generation, speculative decoding, and the proposed DuoDecoding approach. The figure shows the time spent and the number of tokens processed within each iteration. This allows for a direct comparison of computational efficiency and throughput between the methods. The visual comparison clearly highlights the trade-offs between speed and the number of tokens processed per iteration for each method.
read the caption
Figure 4: Profiling of time and number of processed token in one generation iteration for different decoding strategies.

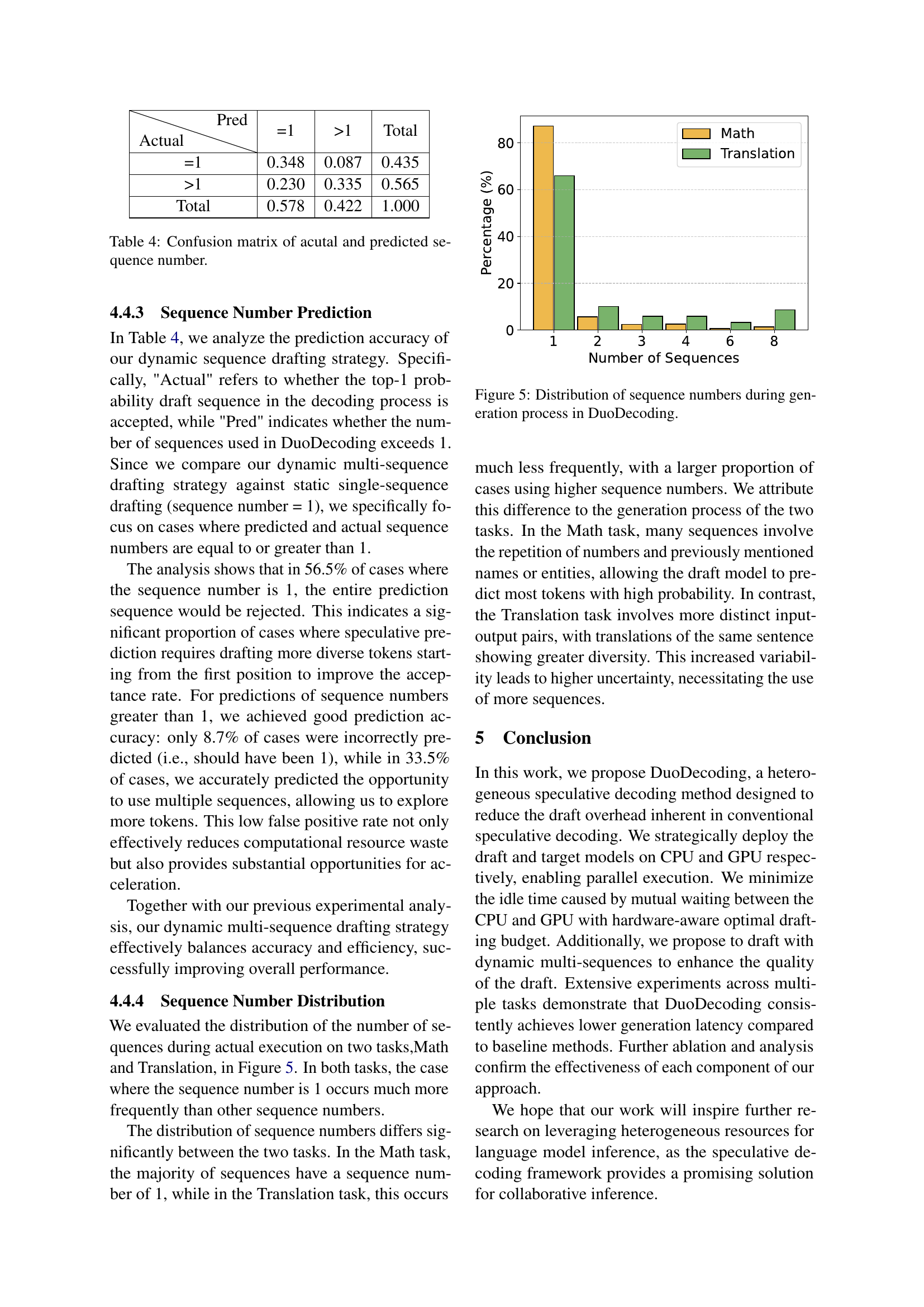
🔼 This figure shows the distribution of the number of draft sequences used during the text generation process in the DuoDecoding model. The x-axis represents the number of sequences, and the y-axis shows the percentage of occurrences. The data is separated into two tasks: Math and Translation, highlighting the differences in sequence number usage across different tasks. This distribution reveals insights into the model’s adaptability to varying degrees of uncertainty in different text generation scenarios.
read the caption
Figure 5: Distribution of sequence numbers during generation process in DuoDecoding.
More on tables
| Method | MT-Bench | Trans | Sum | QA | Math | RAG | Code | Avg. | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TPS | TPS | TPS | TPS | TPS | TPS | TPS | TPS | ||||||||||
| Vicuna | Vanilla | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |||||||||
| SpS | 1.42 | 1.24 | 1.51 | 1.37 | 1.42 | 1.51 | 1.50 | ||||||||||
| PLD | 1.40 | 1.26 | 95.31 | 2.15 | 1.11 | 1.48 | 75.21 | 1.71 | 1.24 | ||||||||
| REST | 1.31 | 1.09 | 1.23 | 65.82 | 1.50 | 1.14 | 1.38 | 1.55 | |||||||||
| Lookahead | 1.39 | 1.37 | 1.33 | 1.32 | 1.49 | 1.27 | 1.32 | ||||||||||
| DuoDec | 74.73 | 1.67 | 66.02 | 1.45 | 1.67 | 1.49 | 68.54 | 1.54 | 1.66 | 72.00 | 1.60 | 70.51 | 1.58 | ||||
| Llama | Vanilla | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |||||||||
| SpS | 1.99 | 2.19 | 1.78 | 1.30 | 2.35 | 1.24 | 1.71 | ||||||||||
| PLD | 1.94 | 2.28 | 134.97 | 3.05 | 1.19 | 2.36 | 2.00 | 1.85 | |||||||||
| REST | 1.40 | 1.26 | 1.23 | 1.47 | 1.27 | 1.33 | 1.64 | ||||||||||
| Lookahead | 1.66 | 1.76 | 1.40 | 1.08 | 1.89 | 1.14 | 1.53 | ||||||||||
| DuoDec | 101.67 | 2.29 | 139.08 | 3.15 | 1.94 | 139.57 | 3.18 | 150.67 | 3.35 | 92.58 | 2.32 | 89.52 | 2.00 | 114.13 | 2.61 | ||
🔼 This table presents a comparison of different sequence drafting strategies used in DuoDecoding, a novel approach for speculative decoding of large language models. It shows the impact of using different numbers of sequences on the tokens per second (TPS) achieved across four distinct tasks (machine translation, summarization, mathematical reasoning, and code generation). The results highlight the effectiveness of the dynamic multi-sequence drafting strategy, which is particularly beneficial for tasks with higher variability.
read the caption
Table 2: Impact of different sequence drafting strategies.
| #Seq | MT | Trans | Math | Code | |
|---|---|---|---|---|---|
| 1 | 98.71 | 131.15 | 149.68 | 89.06 | |
| 2 | 102.30 | 118.48 | 136.00 | 84.15 | |
| Static | 3 | 101.22 | 113.42 | 124.76 | 80.54 |
| Dynamic | 101.67 | 139.08 | 150.67 | 89.52 | |
🔼 This table presents the results of an experiment evaluating the impact of different drafting budgets on the performance of the DuoDecoding method. The drafting budget, denoted by γ (gamma), controls the number of tokens the draft model generates before the target model performs verification. The optimal hardware-aware budget, also represented by γ, was determined beforehand to balance CPU and GPU processing times. The table shows the tokens per second (TPS) achieved for various tasks (MT, Trans, Math, Code) with drafting budgets set at γ-2, γ-1, γ, γ+1, and γ+2. These values show how varying the drafting budget around the optimal value affects the speed of text generation.
read the caption
Table 3: Impact of different drafting budgets. γ𝛾\gammaitalic_γ represents the optimal hardware-aware budget.
| Budget | MT | Trans | Math | Code |
|---|---|---|---|---|
| 97.44 | 128.65 | 145.32 | 87.47 | |
| 97.77 | 130.75 | 147.90 | 89.00 | |
| 98.71 | 131.15 | 149.68 | 89.06 | |
| 98.08 | 130.90 | 147.12 | 88.00 | |
| 98.38 | 130.37 | 148.60 | 87.11 |
🔼 This table presents a confusion matrix that evaluates the accuracy of the dynamic sequence drafting strategy used in DuoDecoding. It shows the counts of instances where the predicted number of sequences matches the actual number of sequences used during the decoding process. The rows represent the actual number of sequences used, and the columns represent the predicted number of sequences. This allows for analysis of the model’s ability to correctly predict when multiple sequences are needed for improved decoding performance.
read the caption
Table 4: Confusion matrix of acutal and predicted sequence number.
Full paper#