TL;DR#
Likelihood-based generative models, like diffusion and autoregressive models, have shown great image generation quality. However, maximizing likelihood estimation suffers from a mode-covering tendency, which affects image quality when the model has limited capacity. Traditional GANs, which don’t rely on likelihoods, avoid this but are complex to train and integrate with models needing iterative processes. To solve this, Direct Discriminative Optimization (DDO) bridges likelihood-based training and GAN objectives for enhanced generative models.
DDO cleverly parameterizes a discriminator using the likelihood ratio between a learnable target model and a fixed reference model. This method avoids joint training of generator and discriminator networks, allowing direct and efficient fine-tuning of pre-trained models. Iterative DDO refinement enhances performance, significantly improving diffusion and autoregressive models on standard benchmarks while simplifying the training process and lowering computational costs.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces DDO, a novel approach that enhances generative model performance without complex GAN setups. DDO’s efficiency and effectiveness offer new avenues for improving visual generation, potentially impacting various research directions by providing a simpler more effective alternative to refine pre-trained models.
Visual Insights#

🔼 This figure provides a visual illustration of Direct Discriminative Optimization (DDO). Panel (a) shows a comparison of models trained with maximum likelihood estimation (MLE) versus those trained with DDO. The MLE models show a dispersed density, indicating that they struggle to capture the important modes of the data distribution. In contrast, the DDO method demonstrates a contrastive force, pulling the model’s distribution closer to the true data distribution. Panel (b) highlights how the DDO fine-tuned model significantly improves, concentrating its density more effectively on the main mode of the data, leading to superior sample quality.
read the caption
Figure 1: Toy example illustrating DDO. (a) Models pretrained via maximum likelihood estimation (MLE) exhibit dispersed density, while DDO imposes contrastive forces toward the data distribution. (b) The finetuned model concentrates better on the main mode.
| Type | Model | NFE | Uncond | Cond |
| FID | FID | |||
| GAN† | StyleGAN2-ADA (Karras et al., 2020) | 1 | 2.92 | 2.42 |
| StyleGAN-XL (Sauer et al., 2022) | 1 | - | 1.85 | |
| R3GAN (Huang et al., 2025) | 1 | - | 1.96 | |
| CTM (Kim et al., 2023b) | 1 | 1.98 | 1.73 | |
| GDD-I (Zheng & Yang, 2024) | 1 | 1.54 | 1.44 | |
| CAF (Park et al., 2024) | 1 | 1.48 | 1.39 | |
| SiD2A (Zhou et al., 2024b) | 1 | 1.50 | 1.40 | |
| Diffusion | DDPM (Ho et al., 2020) | 1000 | 3.17 | - |
| iDDPM (Nichol & Dhariwal, 2021) | 4000 | 2.90 | - | |
| DDIM (Ho et al., 2020) | 100 | 4.16 | - | |
| DPM-Solver (Lu et al., 2022b) | 48 | 2.65 | - | |
| DPM-Solver-v3 (Zheng et al., 2023a) | 12 | 2.24 | - | |
| NCSN++ (Song et al., 2021b) | 2000 | 2.20 | - | |
| LSGM (Vahdat et al., 2021) | 138 | 2.10 | - | |
| VDM (Kingma et al., 2021) | 1000 | 4.00 | - | |
| Flow Matching (Lipman et al., 2022) | 142 | 6.35 | - | |
| i-DODE (Zheng et al., 2023b) | 215 | 3.76 | - | |
| EDM (Karras et al., 2022) | 35 | 1.97 | 1.79 | |
| + DG (Kim et al., 2023a) | 53 | 1.77 | 1.64 | |
| Ours | EDM (retested) | 35 | 1.97 | 1.85 |
| + DDO | 35 | 1.38 | 1.30 |
🔼 Table 1 presents a comparison of FID scores achieved by various generative models on the CIFAR-10 dataset. It breaks down results into unconditional image generation (where the model generates images without any class label guidance) and class-conditional image generation (where the model generates images of a specific class, given a class label). The table includes both standard generative adversarial networks (GANs) and diffusion models. Notably, it also highlights diffusion models that incorporate auxiliary GAN loss during training, a technique known as diffusion distillation, demonstrating the impact of this approach on model performance. FID (Fréchet Inception Distance) is a metric used to quantify the quality of generated images by comparing their feature statistics to those of real images; lower FID indicates better image quality.
read the caption
Table 1: Results on unconditional and class-conditional CIFAR-10. †Including diffusion distillation methods with auxiliary GAN loss.
In-depth insights#
MLE vs. GANs#
Maximum Likelihood Estimation (MLE), while foundational for generative models, suffers from a key limitation: mode-covering. This means MLE-trained models tend to spread their probability mass thinly, leading to blurry or overly generic samples, especially with limited model capacity. Generative Adversarial Networks (GANs), on the other hand, excel at producing sharp, realistic samples, theoretically grounded in minimizing Jensen-Shannon divergence or Wasserstein distance. GANs, however, introduce their own challenges, primarily training instability and mode collapse, where the generator focuses on a limited subset of the data distribution, sacrificing diversity. Therefore MLE tends to create blurry images, while GANs are too specific and have issues with diversity.
Likelihood Ratio#
The likelihood ratio is a fundamental concept in statistical inference and signal detection theory. It quantifies the relative likelihood of observing the data under two competing hypotheses: the null hypothesis and the alternative hypothesis. A high likelihood ratio suggests that the data is more consistent with the alternative hypothesis, while a low likelihood ratio favors the null hypothesis. In generative modeling, it plays a crucial role in discriminator design, as the ratio helps to distinguish between the model and data distributions. The log-likelihood ratio is often used for computational stability and ease of analysis. Models can be further analyzed and improved using the ratio as a metric for evaluating the goodness of fit. However, the accuracy of the ratio depends on the accuracy of the likelihood estimates under both hypotheses.
Iterative DDO#
Iterative DDO, as suggested, likely involves repeated application of the Direct Discriminative Optimization (DDO) technique to refine a generative model progressively. This approach could be beneficial because each DDO application nudges the model closer to the true data distribution. It may be necessary because a single application of DDO might not fully overcome limitations of the initial pre-trained model or due to approximations made in the objective. Self-play, by using the model refined in the last iteration, can be performed in the iterative process to allow for progressive model refinement. Each round involving only a fraction of pretraining epochs can be efficient. This iterative process can also offer a way to mitigate the risk of overfitting or instability, as each round involves only a small adjustment based on the discriminator signal. The framework must converge to an optimal point for the whole iteration to be helpful, therefore it is crucial to keep a closer look to the gradient during the iterative refinement process.
Align & Diversity#
Aligning generative models with real-world data distributions is crucial for producing realistic and diverse outputs. Diversity ensures the model captures the full spectrum of the data, preventing mode collapse and generating varied samples. Alignment, on the other hand, focuses on matching the generated samples to the true data manifold, minimizing artifacts and improving fidelity. A successful generative model should strike a balance, generating high-quality, diverse samples that accurately reflect the underlying data distribution, avoiding the generation of unrealistic or out-of-distribution samples. Techniques like adversarial training and diverse loss functions are employed to encourage both alignment and diversity, while careful evaluation metrics are needed to assess the model’s ability to achieve this delicate equilibrium.
Beyond Images#
The progression from images signifies a pivotal shift towards more intricate data modalities. Expanding beyond static visuals unlocks potential for models to grasp temporal dynamics inherent in videos. The comprehension of motion is paramount, demanding architectures that can discern nuanced changes. Moreover, modalities like audio may enrich the understanding of scenes. Fusing visual and auditory information mirrors human cognition, enabling context-aware reasoning. Generative models can extrapolate from existing frames, creating cohesive narratives. The synthesis of realistic videos is a computationally intensive task, requiring efficient algorithms. Furthermore, the ability to generate novel scenes poses challenges, as it requires an understanding of spatial relationships. Datasets must encompass diversity, reflecting the complexity of real-world phenomena. Evaluating the fidelity of generated videos involves subjective assessments and objective metrics. These assessments capture both the visual quality and the semantic coherence of video content.
More visual insights#
More on figures

🔼 This figure illustrates the Direct Discriminative Optimization (DDO) framework. It shows three key components: (1) Two models are involved: a pretrained reference model (θref) that remains frozen during training, and a target model (θ) that is initially the same as the reference model but will be updated. (2) Data sources consist of real data samples (from pdata) and synthetic samples generated by the reference model (from pθref). (3) The training objective is a GAN loss where the discriminator is implicitly defined by the likelihood ratio of the target and reference models. The goal is to train the target model (θ) to better match the true data distribution (pdata) by discriminating between real and fake samples.
read the caption
Figure 2: Illustration of DDO. (1) Models. θrefsubscript𝜃ref\theta_{\text{ref}}italic_θ start_POSTSUBSCRIPT ref end_POSTSUBSCRIPT is the (pretrained) reference model frozen during training. θ𝜃\thetaitalic_θ is the learnable model initialized as θrefsubscript𝜃ref\theta_{\text{ref}}italic_θ start_POSTSUBSCRIPT ref end_POSTSUBSCRIPT. (2) Data. Samples from pdatasubscript𝑝datap_{\text{data}}italic_p start_POSTSUBSCRIPT data end_POSTSUBSCRIPT are drawn from the training dataset. Samples from pθrefsubscript𝑝subscript𝜃refp_{\theta_{\text{ref}}}italic_p start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT ref end_POSTSUBSCRIPT end_POSTSUBSCRIPT are generated by the reference model, either offline or online. (3) Objective. The target model θ𝜃\thetaitalic_θ is optimized by applying the GAN discriminator loss with the implicitly parameterized discriminator dθsubscript𝑑𝜃d_{\theta}italic_d start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT to distinguish between real samples from pdatasubscript𝑝datap_{\text{data}}italic_p start_POSTSUBSCRIPT data end_POSTSUBSCRIPT and fake samples from pθrefsubscript𝑝subscript𝜃refp_{\theta_{\text{ref}}}italic_p start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT ref end_POSTSUBSCRIPT end_POSTSUBSCRIPT.

🔼 This figure compares Direct Discriminative Optimization (DDO) with Direct Preference Optimization (DPO). It illustrates the key differences in their methodologies. DPO uses paired human preference data to align a language model with human preferences by expressing the reward model as a likelihood ratio. DDO, in contrast, uses unpaired data from the data distribution and the pretrained model to improve the target model by implicitly parameterizing a discriminator using the likelihood ratio. This allows for direct and efficient finetuning of the pretrained model without the need for additional networks or alternating optimization processes. The figure visually represents these differences and highlights how DDO achieves model alignment using an implicitly defined discriminator.
read the caption
Figure 3: Comparison with DPO.

🔼 Figure 4 compares the number of parameters and the inference time required for different image generation methods. The methods compared include several guidance techniques (Classifier-Free Guidance, Discriminator Guidance, and Autoguidance) as well as the proposed Direct Discriminative Optimization (DDO) method. The baseline model is also shown. The evaluation is performed on two different datasets: CIFAR-10 and ImageNet-64, with Discriminator Guidance evaluated on class-conditional CIFAR-10 and Autoguidance on ImageNet-64. This allows for a direct comparison of the computational efficiency and model complexity associated with various approaches to improving image generation quality.
read the caption
Figure 4: Comparison of model parameter counts and inference time across different guidance methods and DDO. For DG, we measure the statistics on class-conditional CIFAR-10. For AG, we measure the statistics on ImageNet-64.

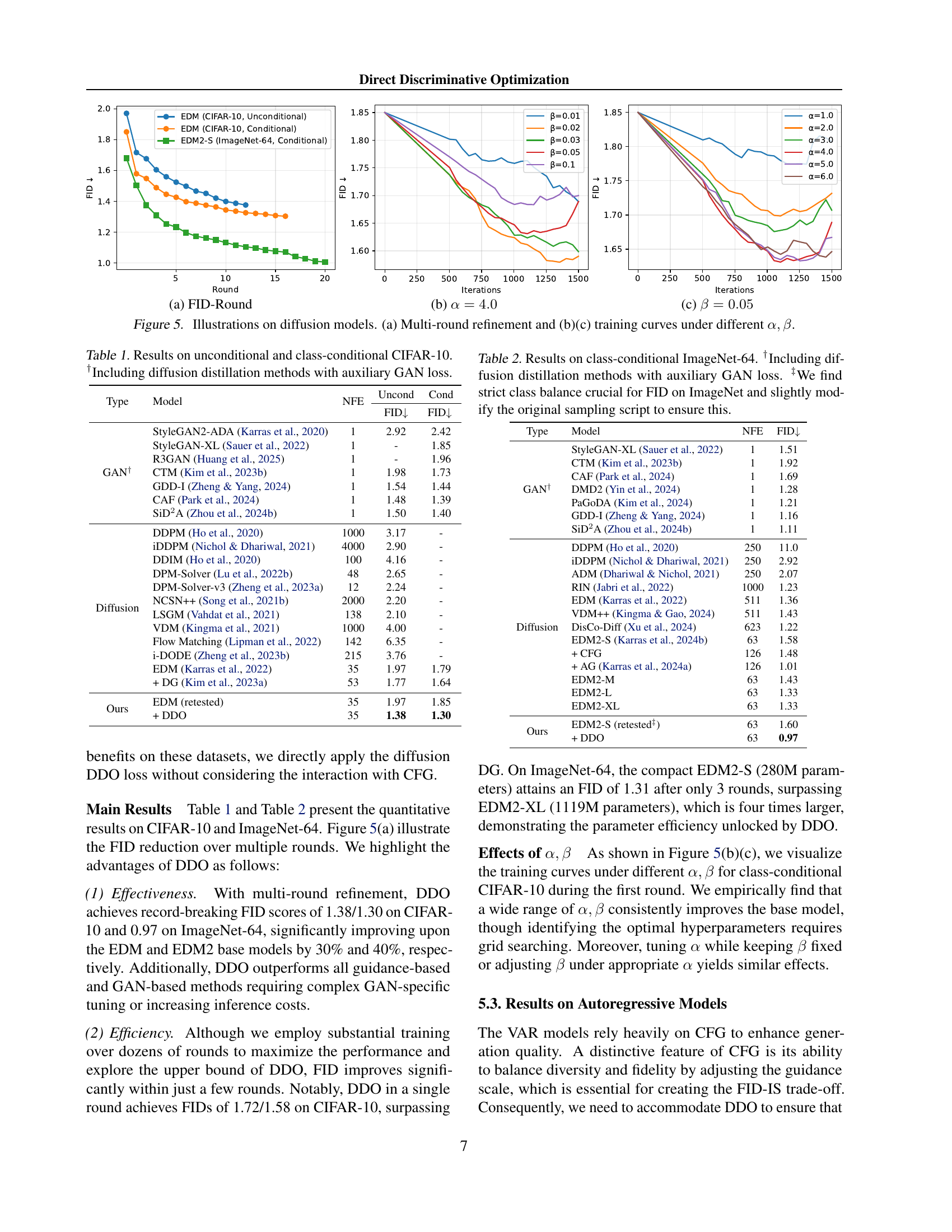
🔼 This figure shows the results of applying Direct Discriminative Optimization (DDO) to diffusion models. Specifically, it illustrates (a) the impact of iterative refinement (self-play) on model performance across multiple rounds, and training curves under different hyperparameter settings (b) α and (c) β. The plots in (b) and (c) show how the FID (Fréchet Inception Distance) score changes with the number of iterations during training for different values of α and β, demonstrating the effect of these hyperparameters on model performance.
read the caption
Figure 5: Illustrations on diffusion models. (a) Multi-round refinement and (b)(c) training curves under different α,β𝛼𝛽\alpha,\betaitalic_α , italic_β.

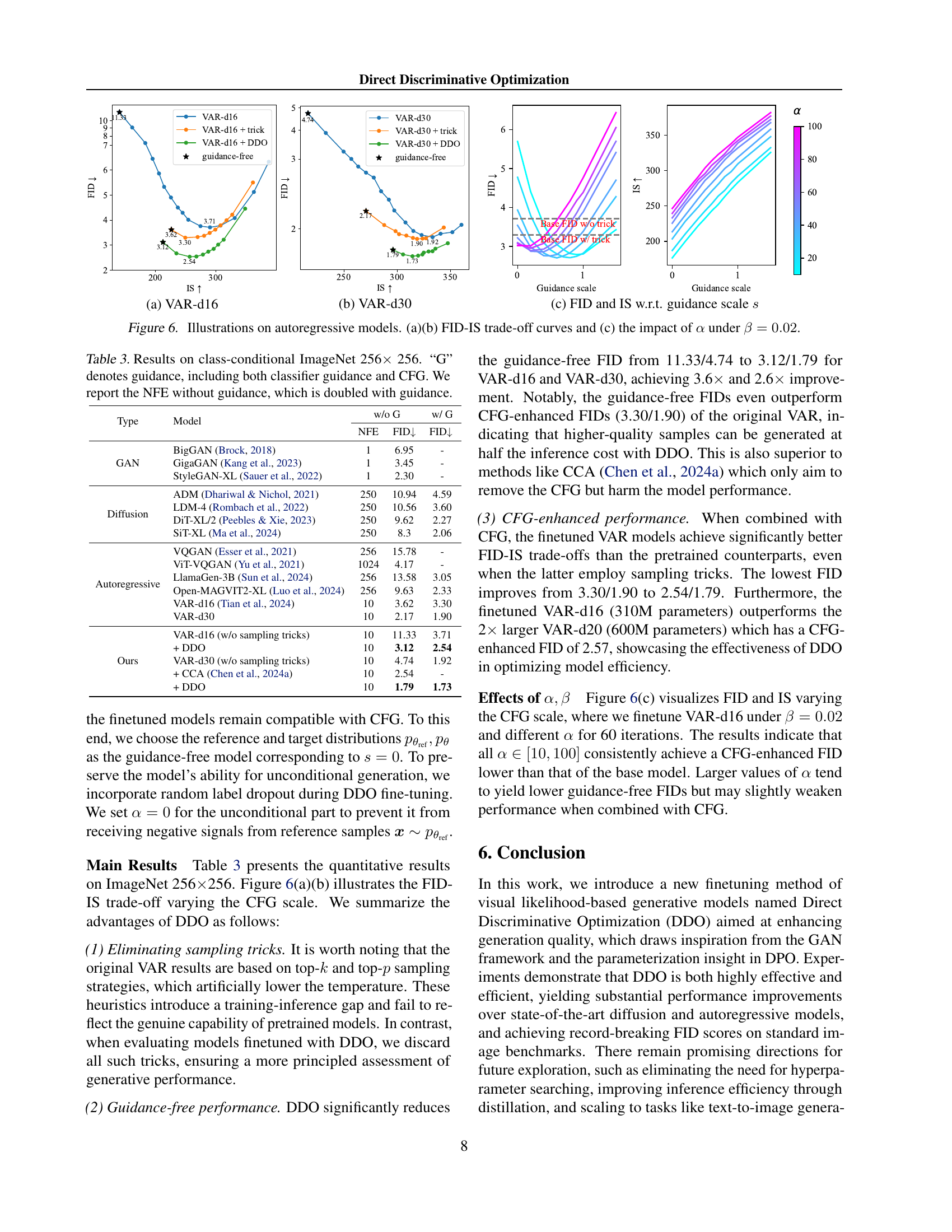
🔼 Figure 6 presents an analysis of autoregressive models, specifically focusing on the impact of hyperparameters on model performance. Subfigures (a) and (b) show FID (Fréchet Inception Distance) and IS (Inception Score) trade-off curves for different autoregressive models (VAR-d16 and VAR-d30). These curves illustrate the balance between image diversity (IS) and image quality (FID) at varying guidance scales. Subfigure (c) explores the effect of hyperparameter α on model performance, while keeping β constant at 0.02. This analysis reveals how adjustments to α influence the FID and IS, offering insights into optimizing the generation process.
read the caption
Figure 6: Illustrations on autoregressive models. (a)(b) FID-IS trade-off curves and (c) the impact of α𝛼\alphaitalic_α under β=0.02𝛽0.02\beta=0.02italic_β = 0.02.

🔼 This figure displays several randomly generated images from the Enhanced Diffusion Model (EDM) trained on the CIFAR-10 dataset. The generation process is unconditional, meaning that no specific class label or other guidance was provided to the model during generation. The FID score (Fréchet Inception Distance) of 1.97 indicates the model’s performance, with lower scores suggesting better image quality and similarity to real images from the CIFAR-10 dataset.
read the caption
Figure 7: Random samples of EDM (CIFAR-10, Unconditional), FID 1.97.

🔼 This figure displays 100 randomly generated images from the EDM (Energy-based Diffusion Model) model after being fine-tuned using the Direct Discriminative Optimization (DDO) method. The model was trained on the CIFAR-10 dataset in an unconditional setting (meaning no class labels were provided during training, allowing the model to generate images from all classes). The FID (Fréchet Inception Distance) score of 1.38 indicates a high level of image quality and realism, suggesting that the DDO fine-tuning significantly improved the model’s generation capabilities compared to the original EDM model.
read the caption
Figure 8: Random samples of EDM + DDO (CIFAR-10, Unconditional), FID 1.38.

🔼 This figure displays random image samples generated by the Enhanced Diffusion Model (EDM) when trained on the CIFAR-10 dataset in a class-conditional setting. The Fréchet Inception Distance (FID) score achieved by this model is 1.85, indicating its performance in generating realistic and diverse images. Each image is an example of the model’s output for a given class label.
read the caption
Figure 9: Random samples of EDM (CIFAR-10, Class-conditional), FID 1.85.

🔼 This figure displays several randomly generated images from a class-conditional generative model trained on the CIFAR-10 dataset. The model is a diffusion model enhanced with Direct Discriminative Optimization (DDO), which aims to improve its performance beyond the limitations of maximum likelihood estimation. The FID (Fréchet Inception Distance) score for these samples is 1.30, indicating high visual quality and diversity.
read the caption
Figure 10: Random samples of EDM + DDO (CIFAR-10, Class-conditional), FID 1.30.
More on tables
| Type | Model | NFE | FID |
| GAN† | StyleGAN-XL (Sauer et al., 2022) | 1 | 1.51 |
| CTM (Kim et al., 2023b) | 1 | 1.92 | |
| CAF (Park et al., 2024) | 1 | 1.69 | |
| DMD2 (Yin et al., 2024) | 1 | 1.28 | |
| PaGoDA (Kim et al., 2024) | 1 | 1.21 | |
| GDD-I (Zheng & Yang, 2024) | 1 | 1.16 | |
| SiD2A (Zhou et al., 2024b) | 1 | 1.11 | |
| Diffusion | DDPM (Ho et al., 2020) | 250 | 11.0 |
| iDDPM (Nichol & Dhariwal, 2021) | 250 | 2.92 | |
| ADM (Dhariwal & Nichol, 2021) | 250 | 2.07 | |
| RIN (Jabri et al., 2022) | 1000 | 1.23 | |
| EDM (Karras et al., 2022) | 511 | 1.36 | |
| VDM++ (Kingma & Gao, 2024) | 511 | 1.43 | |
| DisCo-Diff (Xu et al., 2024) | 623 | 1.22 | |
| EDM2-S (Karras et al., 2024b) | 63 | 1.58 | |
| + CFG | 126 | 1.48 | |
| + AG (Karras et al., 2024a) | 126 | 1.01 | |
| EDM2-M | 63 | 1.43 | |
| EDM2-L | 63 | 1.33 | |
| EDM2-XL | 63 | 1.33 | |
| Ours | EDM2-S (retested‡) | 63 | 1.60 |
| + DDO | 63 | 0.97 |
🔼 This table presents the Fréchet Inception Distance (FID) scores achieved by various generative models on the class-conditional ImageNet-64 dataset. The models compared include several state-of-the-art GANs and diffusion models, both with and without additional techniques like classifier-free guidance (CFG) or discriminator guidance (DG). Some models also incorporate diffusion distillation with an auxiliary GAN loss. A key observation noted is the importance of strict class balance for accurate FID calculation on ImageNet-64, with a modified sampling process employed for improved results.
read the caption
Table 2: Results on class-conditional ImageNet-64. †Including diffusion distillation methods with auxiliary GAN loss. ‡We find strict class balance crucial for FID on ImageNet and slightly modify the original sampling script to ensure this.
| Type | Model | w/o G | w/ G | |
| NFE | FID | FID | ||
| GAN | BigGAN (Brock, 2018) | 1 | 6.95 | - |
| GigaGAN (Kang et al., 2023) | 1 | 3.45 | - | |
| StyleGAN-XL (Sauer et al., 2022) | 1 | 2.30 | - | |
| Diffusion | ADM (Dhariwal & Nichol, 2021) | 250 | 10.94 | 4.59 |
| LDM-4 (Rombach et al., 2022) | 250 | 10.56 | 3.60 | |
| DiT-XL/2 (Peebles & Xie, 2023) | 250 | 9.62 | 2.27 | |
| SiT-XL (Ma et al., 2024) | 250 | 8.3 | 2.06 | |
| Autoregressive | VQGAN (Esser et al., 2021) | 256 | 15.78 | - |
| ViT-VQGAN (Yu et al., 2021) | 1024 | 4.17 | - | |
| LlamaGen-3B (Sun et al., 2024) | 256 | 13.58 | 3.05 | |
| Open-MAGVIT2-XL (Luo et al., 2024) | 256 | 9.63 | 2.33 | |
| VAR-d16 (Tian et al., 2024) | 10 | 3.62 | 3.30 | |
| VAR-d30 | 10 | 2.17 | 1.90 | |
| Ours | VAR-d16 (w/o sampling tricks) | 10 | 11.33 | 3.71 |
| + DDO | 10 | 3.12 | 2.54 | |
| VAR-d30 (w/o sampling tricks) | 10 | 4.74 | 1.92 | |
| + CCA (Chen et al., 2024a) | 10 | 2.54 | - | |
| + DDO | 10 | 1.79 | 1.73 | |
🔼 This table presents the results of experiments conducted on the ImageNet 256x256 dataset using class-conditional models. It compares the performance of various generative models, specifically focusing on the Fréchet Inception Distance (FID) metric. The models are categorized into GANs, Diffusion models, and Autoregressive models. The table shows FID scores achieved with and without the use of classifier-free guidance (CFG) and other guidance methods, denoted as ‘G’. The number of function evaluations (NFE) required during inference is also reported; note that the NFE is doubled when guidance techniques are used.
read the caption
Table 3: Results on class-conditional ImageNet 256×\times× 256. “G” denotes guidance, including both classifier guidance and CFG. We report the NFE without guidance, which is doubled with guidance.
Full paper#