TL;DR#
Recent advancements in music generation face limitations like generating disjointed vocal & accompaniment tracks. Many rely on multi-stage architectures & are restricted to short segments. Language model approaches also suffer from slow inference speeds. There’s a need for holistic solutions that capture the interplay between vocals and accompaniment while being scalable and efficient.
To solve these issues, DiffRhythm, a diffusion-based song generation model, synthesizes full-length songs with vocals & accompaniment for up to ~5 mins in just 10 secs! It has a simple design, eliminating complex data preparation and using a straightforward model. Also, a novel sentence-level lyrics alignment mechanism for better vocal intelligibility is used. It demonstrates robustness and enables plug-and-play substitution in latent diffusion.
Key Takeaways#
Why does it matter?#
This paper introduces an innovative end-to-end model for song generation, potentially transforming how music is created and studied. By enabling the fast synthesis of full-length songs, it opens new avenues for exploring music generation. The released code and pre-trained models encourage reproducibility and further research, accelerating progress in the field.
Visual Insights#

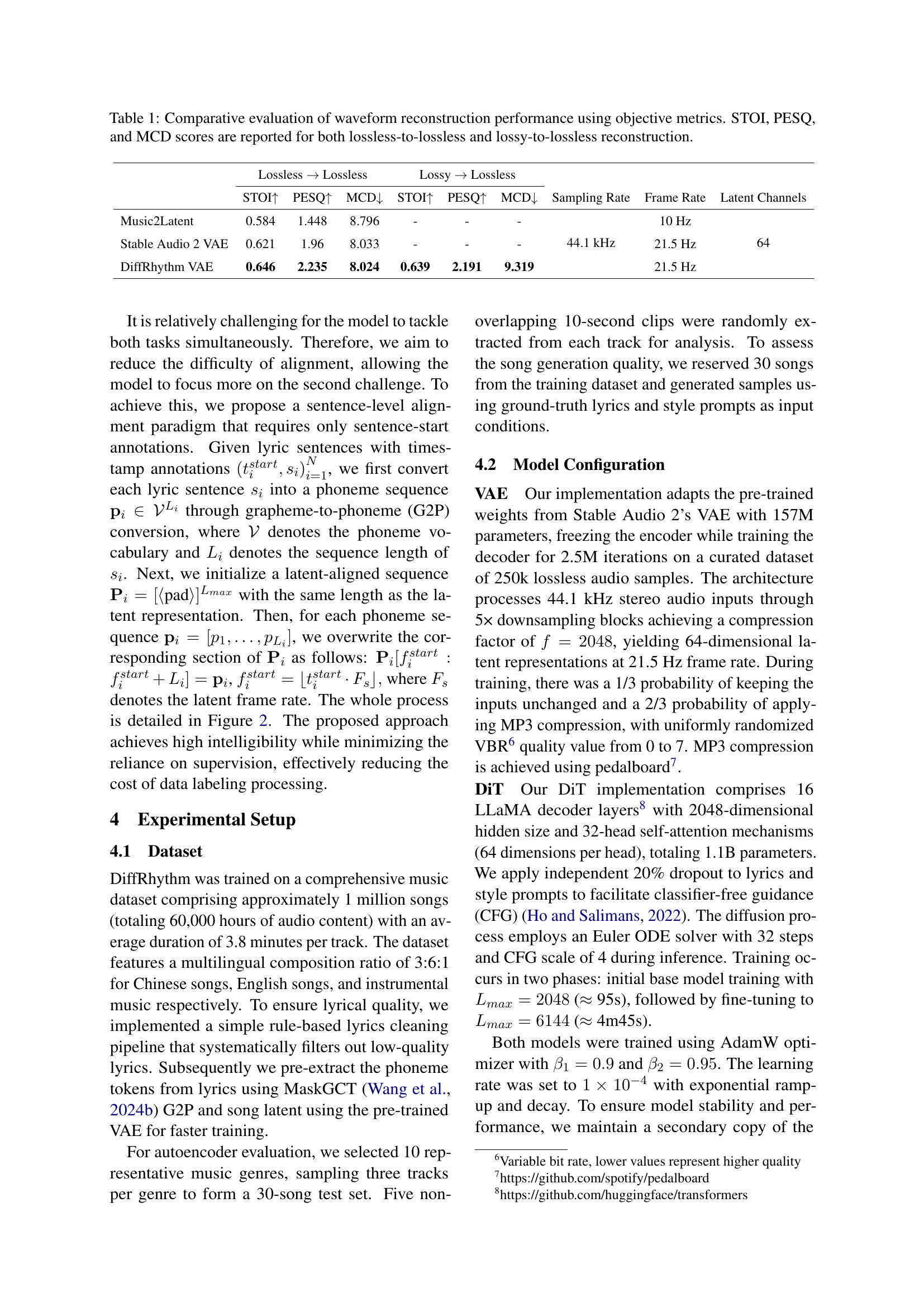
🔼 The DiffRhythm model uses both style and lyrics as input. The style prompt is processed through an LSTM to generate a style embedding. The lyrics are processed to generate a sequence of phoneme tokens. Both the style embedding and phoneme tokens, along with the timestep, are fed into a diffusion transformer (DiT) which generates a latent representation. This latent representation is decoded using a Variational Autoencoder (VAE) to produce the final audio output containing both vocals and accompaniment.
read the caption
Figure 1: Architecture of DiffRhythm. The style and lyrics are used as external control signals, which are preprocessed to get the style embedding and lyrics token, input to DiT to generate latent, and subsequently go through the VAE decoder to generate the audio.
| Lossless Lossless | Lossy Lossless | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| STOI | PESQ | MCD | STOI | PESQ | MCD | Sampling Rate | Frame Rate | Latent Channels | |
| Music2Latent | 0.584 | 1.448 | 8.796 | - | - | - | 44.1 kHz | 10 Hz | 64 |
| Stable Audio 2 VAE | 0.621 | 1.96 | 8.033 | - | - | - | 21.5 Hz | ||
| DiffRhythm VAE | 0.646 | 2.235 | 8.024 | 0.639 | 2.191 | 9.319 | 21.5 Hz | ||
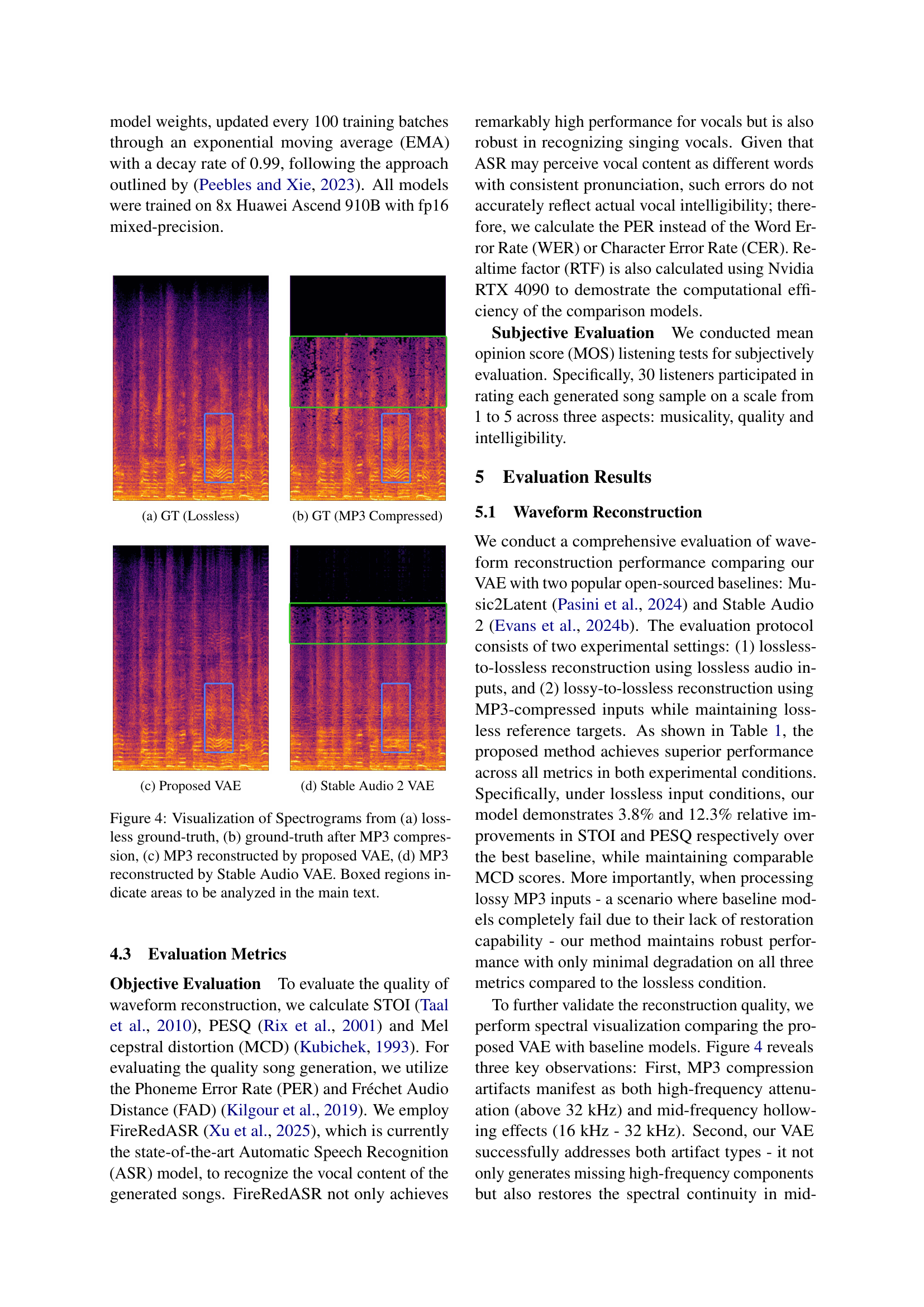
🔼 Table 1 presents a quantitative comparison of waveform reconstruction performance across three different models: the proposed DiffRhythm VAE, Stable Audio 2 VAE, and Music2Latent. The evaluation uses standard metrics - STOI (Short-Time Objective Intelligibility), PESQ (Perceptual Evaluation of Speech Quality), and MCD (Mel Cepstral Distortion) - to assess the quality of audio reconstruction. Importantly, the results are reported under two conditions: lossless-to-lossless (input and output audio are both lossless) and lossy-to-lossless (input audio is compressed in MP3 format, output is lossless). This comparison highlights the robustness and superior performance of the proposed DiffRhythm VAE, particularly in handling lossy input data.
read the caption
Table 1: Comparative evaluation of waveform reconstruction performance using objective metrics. STOI, PESQ, and MCD scores are reported for both lossless-to-lossless and lossy-to-lossless reconstruction.
In-depth insights#
Latent Diffusion#
Latent diffusion models, often employed to reduce computational costs, operate in a lower-dimensional latent space learned by an autoencoder. This approach allows for more efficient processing compared to operating directly in the high-dimensional pixel space. A key component is the autoencoder, which compresses the data into a compact latent representation and reconstructs it. The diffusion process, involving iterative noising and denoising, happens in this latent space, guided by conditions like text or style prompts. This is particularly useful in scenarios like music generation, where dealing with long audio sequences directly can be prohibitive. The quality of the autoencoder significantly impacts the model’s performance, as it determines the level of detail preserved in the latent space. Advanced techniques, like adversarial training, improve the reconstruction quality, ensure the latent representation retains essential features of the original data.
Fast Synthesis#
The paper emphasizes the model’s ability to generate full-length songs very quickly. This fast synthesis is a key advantage, distinguishing it from slower, autoregressive methods that are common in music generation. The model’s non-autoregressive structure and efficient architecture are crucial for achieving these speeds. The authors present a diffusion-based model’s high generation speed while retaining song musicality and intelligibility. The model’s rapid synthesis rate allows real-time applications and user interactivity. These speeds also benefit commercial music production. Fast synthesis is critical for broader adoption and experimentation in the field. The model’s scalability is guaranteed by its efficiency, with the potential for future research and development.
Lyrics Alignment#
In addressing lyric alignment, a critical facet of song generation, the model confronts unique challenges beyond conventional text-to-speech tasks. Unlike TTS models handling shorter segments with continuous articulation, song generation grapples with discontinuous temporal correspondence due to instrumental intervals disrupting phonetic continuity. Furthermore, accompaniment interference arises as simultaneous modeling of voice and accompaniment leads to words having varying instrumental contexts, complicating alignment. The model has sentence-level alignment paradigm requiring only sentence-start annotations. A grapheme-to-phoneme conversion facilitates semantic correspondence between lyrics and vocals.
VAE Robustness#
While not explicitly titled ‘VAE Robustness,’ the paper addresses this implicitly through its lossy-to-lossless reconstruction training. This suggests a concern for real-world applicability, where audio data is often compressed (e.g., MP3), introducing artifacts. Training the VAE to reconstruct the original lossless audio from compressed versions forces it to learn robust feature representations, invariant to compression distortions. This is a crucial aspect of VAE robustness, ensuring the model performs well even with imperfect input data. The VAE’s ability to handle MP3 compression is explicitly tested by inputting MP3-compressed data during the training. And it tries to minimize the original lossless audio data with the lossy one. This shows VAE’s high fidelity music reconstruction performance against MP3 compression artifacts. The model’s robustness also extends to noisy audio data or other common signal degradations. The VAE is not just a tool for dimensionality reduction and feature space, but a noise reduction and audio enhancement tool. The ability to share the latent space with Stable Audio VAE, enabling seamless plug-and-play substitution in existing latent diffusion frameworks, suggests the VAE is compatible with existing models.
Full Song Gen#
Considering the advancements in AI music generation, a ‘Full Song Gen’ model signifies a leap towards creating complete musical pieces, not just short segments. This is crucial for practical applications in artistic and commercial music production. The development of DiffRhythm indicates a move away from disjointed track generation towards holistic, end-to-end solutions capable of synthesizing both vocal and accompaniment tracks. The paper highlights the limitations of existing models, such as reliance on multi-stage architectures and slow inference speeds due to language model paradigms. DiffRhythm’s latent diffusion approach, aimed at overcoming these limitations, promises faster generation speeds and improved scalability, particularly for longer audio synthesis where maintaining consistency is paramount. By releasing the complete training code and pre-trained models, they encourage further research and reproducibility, potentially democratizing access to advanced music generation tools.
More visual insights#
More on figures

🔼 This figure illustrates the preprocessing steps involved in preparing the lyrics data for use in the DiffRhythm model. The process begins with the lyrics, which are converted into phonemes using a grapheme-to-phoneme (G2P) converter. These phonemes are then aligned temporally with the corresponding timestamps of the music waveform. This alignment ensures that the generated vocals align with the music during song synthesis. The figure highlights the crucial role of this preprocessing step in ensuring that the model accurately produces synchronized vocals and accompaniment.
read the caption
Figure 2: The data preprocessing pipeline of DiffRhythm. Lyrics go through G2P and are placed at the positions corresponding to their timestamps

🔼 This figure shows the probability density function (PDF) of the logit-normal distribution used for sampling timesteps in the diffusion process. The x-axis represents the timestep t, ranging from 0 to 1, and the y-axis shows the probability density. The curve demonstrates the distribution’s characteristics: concentrated around the middle timesteps (around t = 0.5), indicating that the model focuses more on the challenging intermediate regions during training. The parameters m and s control the distribution’s mean and standard deviation respectively, enabling bias toward either data or noise regions.
read the caption
Figure 3: Logit-normal timestep distribution.

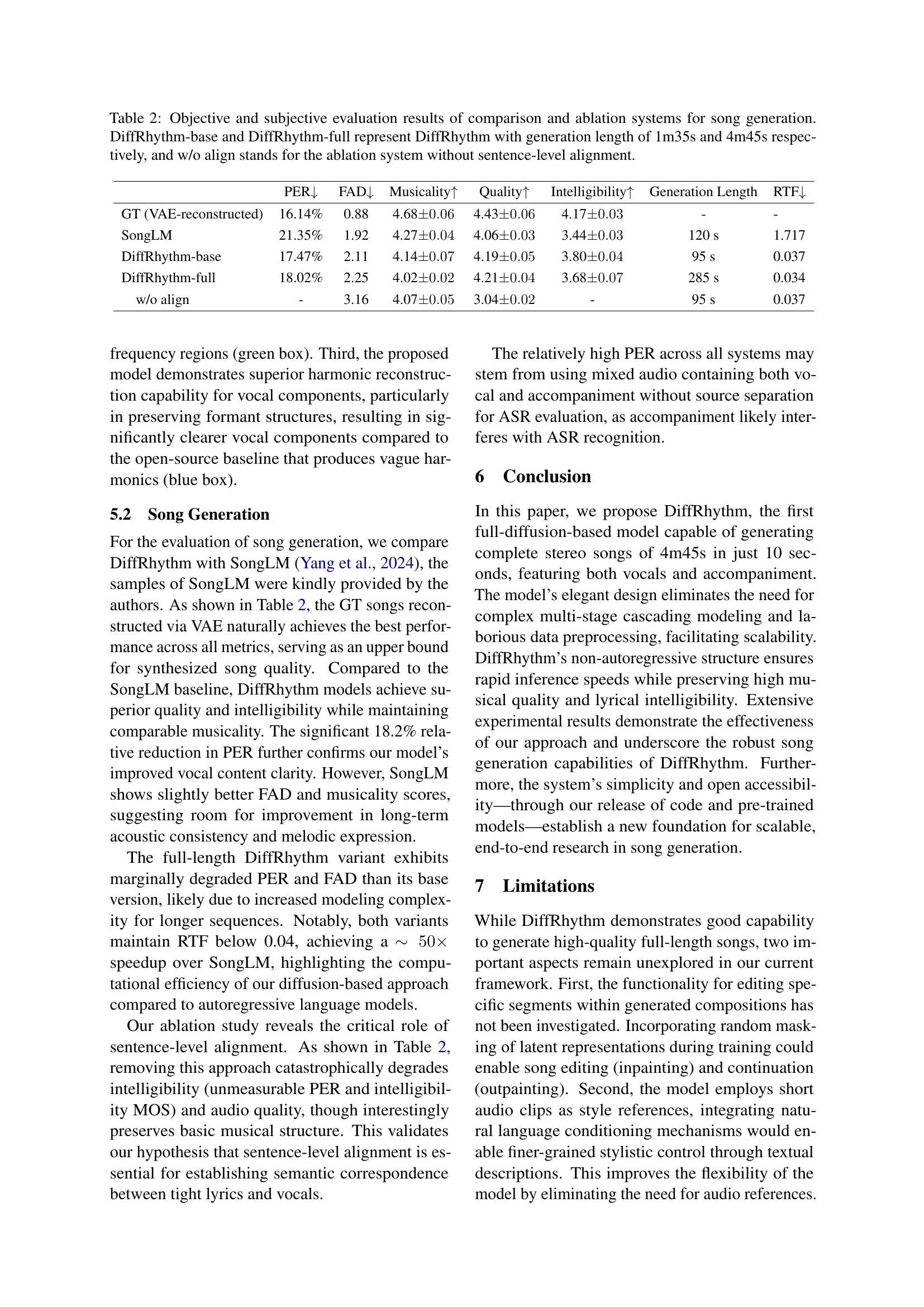
🔼 This figure shows a spectrogram visualization comparing the proposed VAE with baseline models. (a) displays a spectrogram of lossless ground truth audio. The figure highlights the effects of MP3 compression on audio and how the proposed VAE model is able to reconstruct the audio from the compressed version more accurately than a baseline model.
read the caption
(a) GT (Lossless)

🔼 This figure shows a spectrogram of a ground truth song after being compressed using the MP3 format. This visualization helps illustrate the effect of MP3 compression on audio quality, particularly highlighting the loss of high-frequency components and the introduction of artifacts, which is used to evaluate the VAE’s ability to reconstruct high-quality audio even from compressed inputs.
read the caption
(b) GT (MP3 Compressed)

🔼 Spectrogram of an MP3-compressed audio clip reconstructed by the proposed Variational Autoencoder (VAE). The figure shows the effectiveness of the VAE in reconstructing audio from compressed data by visually comparing it to the ground truth (lossless and MP3-compressed versions). Boxed regions highlight specific areas for detailed analysis.
read the caption
(c) Proposed VAE

🔼 The figure displays a spectrogram generated by Stable Audio 2 VAE model after reconstructing an MP3 compressed audio. This allows for visual comparison with other spectrograms, including the ground truth (lossless and MP3 compressed) and the spectrogram generated by the proposed VAE model in the paper. The comparison highlights the performance of different models in reconstructing audio from MP3 compressed versions, focusing on high-frequency attenuation and mid-frequency hollowing effects.
read the caption
(d) Stable Audio 2 VAE
Full paper#