TL;DR#
Existing methods to assess code generation by Large Language Models (LLMs) face issues such as benchmark contamination, data loss, and limited accessibility. The subjective problem difficulty assessments made by human curators also impact the accuracy of model evaluations. These shortcomings hinder the efficient and accurate assessment of LLM coding capabilities.
To counter these issues, CodeArena was introduced as an online evaluation framework. The platform mitigates score biases using a collective evaluation system, dynamically adjusting model scores based on overall performance. The system includes automated APIs and ensures open access to both submitted solutions and test cases, streamlining the evaluation workflow. This setup enables a fairer, more accessible, and efficient way to evaluate and improve code generation.
Key Takeaways#
Why does it matter?#
This paper introduces a dynamic evaluation system and an open data repository to address the challenges of LLM code generation. It offers valuable resources and tools for researchers to evaluate models and advance code generation.
Visual Insights#

🔼 CodeArena’s architecture is illustrated, highlighting its key components: an API layer for user interaction, runtime environments for code execution, a dynamic evaluation layer that continuously adjusts scores based on overall performance, and a data layer to store solutions and test cases. The figure walks through the submission process, detailing the steps from problem retrieval to solution evaluation and storage.
read the caption
Figure 1: The CodeArena framework allows users to interact with the system through APIs. The depicted workflow shows the code submission process.
| Rank | Model Name | DP | Pass |
|---|---|---|---|
| 1 | DeepSeek-Coder Zhu et al. (2024) | 249.28 | 90.63% |
| 2 | GPT-4o Achiam et al. (2023) | 247.32 | 89.06% |
| 3 | Claude-3-5-sonnet Anthropic (2024) | 227.87 | 74.22% |
| 4 | Gemini-1.5-flash Team et al. (2023) | 225.67 | 73.05% |
| 5 | DeepSeek-Coder-V2-Lite Zhu et al. (2024) | 223.67 | 71.24% |
| 6 | Claude-3-Opus Anthropic (2024) | 221.93 | 69.92% |
| 7 | Gemini-1.5-pro Team et al. (2023) | 209.16 | 61.72% |
| 8 | Llama-3.1-8B Touvron et al. (2023) | 177.34 | 46.09% |
| 9 | Llama-3-8B Touvron et al. (2023) | 164.51 | 40.63% |
| 10 | GPT-4-Turbo Achiam et al. (2023) | 160.55 | 34.38% |
| 11 | GPT-3.5-Turbo Achiam et al. (2023) | 157.70 | 33.98% |
| 12 | Mistral-Nemo Jiang et al. (2023) | 141.78 | 29.30% |
| 13 | CodeLlama-13b Roziere et al. (2023) | 123.15 | 25.39% |
| 14 | Claude-3-Haiku Anthropic (2024) | 100.37 | 18.75% |
| 15 | Mistral-7B-v0.3 Jiang et al. (2023) | 77.43 | 14.84% |
| 16 | Codestral-22B-v0.1 Jiang et al. (2023) | 77.43 | 14.84% |
| 17 | Claude-3-sonnet Anthropic (2024) | 56.17 | 8.98% |
| 18 | CodeLlama-34b Roziere et al. (2023) | 53.83 | 8.98% |
| 19 | CodeLlama-7b Roziere et al. (2023) | 50.38 | 6.25% |
🔼 This table presents a leaderboard ranking the performance of various Large Language Models (LLMs) in code generation tasks as of July 30, 2024. Models are categorized as either open-source or closed-source. The ranking is based on a ‘Dynamic Points’ (DP) score, which considers both the number of problems solved and the efficiency of the solutions. The ‘Pass’ score indicates the percentage of problems successfully solved by each LLM, offering a complementary measure of performance.
read the caption
Table 1: Leaderboard shows the code generation performance of leading open-source (♣♣\clubsuit♣) and closed-source (♢♢\diamondsuit♢) LLMs as of July 30, 2024. DP stands for Dynamic Points, and the Pass score reports the percentage of solved problems out of total problems.
In-depth insights#
LLM Code Arena#
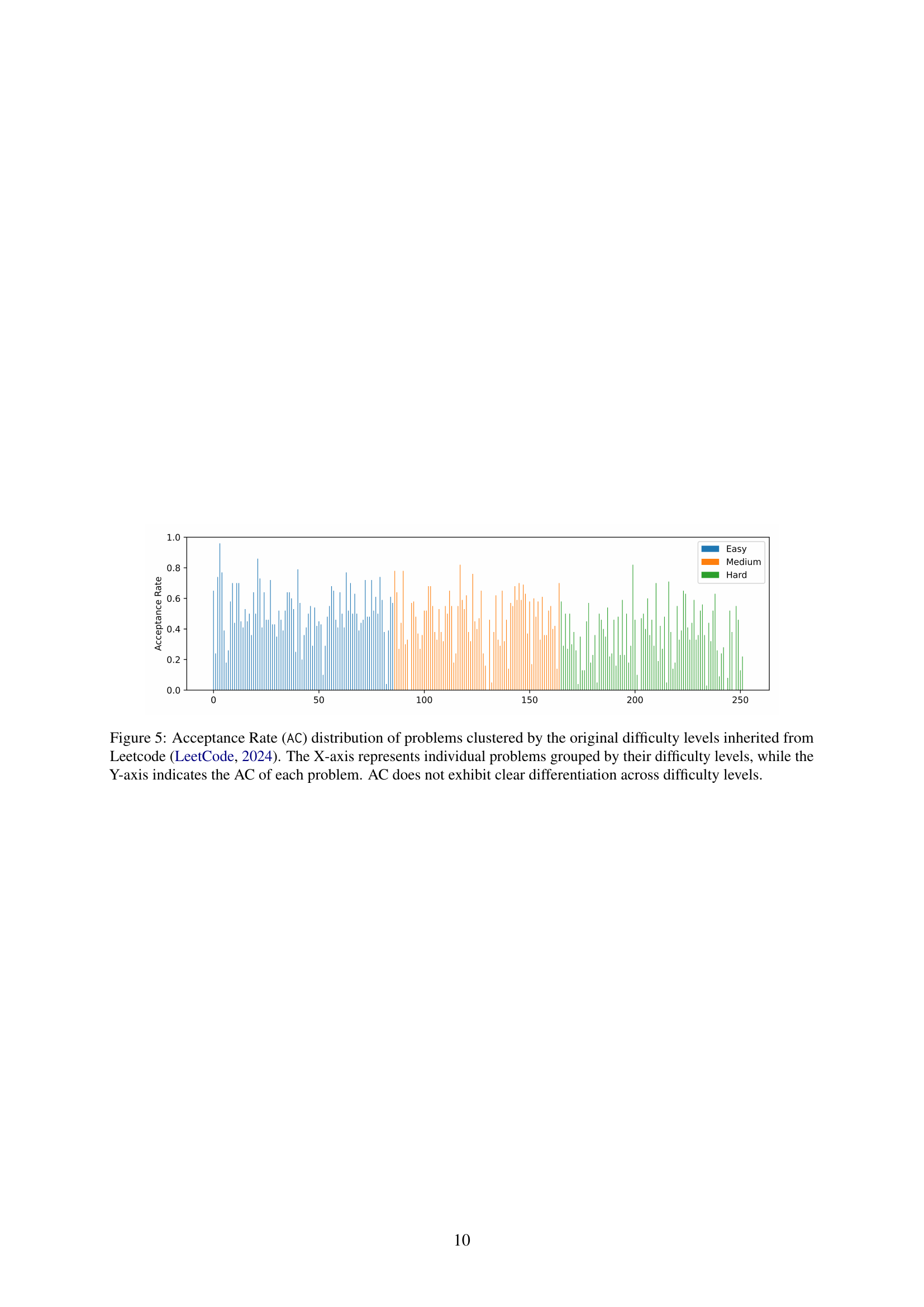
Assuming “LLM Code Arena” refers to an environment or platform for evaluating Large Language Models (LLMs) in code generation, several aspects become crucial. Firstly, the platform’s design should ensure fair and unbiased comparisons between models, accounting for factors like prompt engineering and varying hardware. It should offer diverse coding challenges, ranging from algorithm implementation to software design, to gauge LLMs’ comprehensive coding abilities. The evaluation metrics must go beyond simple pass/fail tests, incorporating aspects like code efficiency, security, and maintainability. Crucially, the arena needs mechanisms to mitigate benchmark contamination, a prevalent issue where LLMs are inadvertently trained on evaluation data, leading to inflated performance. Dynamic scoring systems and regularly updated problem sets are essential here. Furthermore, a good arena should provide detailed insights into model behavior, allowing researchers to understand why a model succeeds or fails. This includes features for debugging generated code, visualizing execution traces, and analyzing error patterns. The platform’s user interface (UI) and Application Programming Interface (API) must be designed with automation in mind, thereby, assisting the user effectively with code generation. In short, an LLM Code Arena should be a rigorous, transparent, and informative environment for driving progress in LLM-based code generation.
Dynamic Scoring#
Dynamic scoring in LLM evaluation is crucial to mitigate benchmark leakage. By recalibrating model scores based on the performance of all models, it reduces biases from leaked data. This approach dynamically adjusts the challenge score, rewarding solutions to difficult problems more significantly. Also it incentivizes solving truly challenging problems while reducing the impact of leaked or simple tasks on the overall leaderboard. It also calculates code efficiency by runtime, and provides Dynamic Points. These dynamic points further help to observe the performance trending of each user. In summary it ensures that benchmark results reflect genuine coding proficiency and that the benchmarks are up to date.
API Automation#
API automation represents a critical domain within software engineering, especially in the context of modern microservices architectures and cloud-native applications. It involves using programmatic methods to test, deploy, and manage APIs, reducing manual effort and increasing efficiency. API automation frameworks often leverage tools like Postman, SoapUI, or custom scripts using languages like Python or JavaScript to automate the process of sending requests, validating responses, and ensuring API functionality. A key aspect of API automation is test automation, where automated tests are created to verify API endpoints’ behavior under different conditions, including functional correctness, performance, and security. Effective API automation requires a robust strategy that includes defining clear test cases, setting up appropriate environments, and integrating with continuous integration/continuous delivery (CI/CD) pipelines to ensure consistent and reliable API performance. Furthermore, comprehensive API automation strategies encompass monitoring and logging to provide real-time insights into API health and usage, allowing for proactive issue detection and resolution.
Open Data Access#
Open data access is crucial for advancing research in LLM code generation. It facilitates reproducibility and allows researchers to build upon existing work. Providing access to both solutions and test cases fosters a collaborative environment, accelerating innovation. Publicly available datasets enable comprehensive analysis, identifying strengths and weaknesses of different models. Open access also encourages the development of more robust and generalizable evaluation metrics, mitigating the risks associated with benchmark leakage. By democratizing data, we can promote fair comparison of models and ensure progress in the field.
Addressing Bias#
While the provided paper doesn’t have a section explicitly titled “Addressing Bias,” it implicitly tackles bias through its dynamic evaluation mechanism. Traditional benchmarks often suffer from biases stemming from subjective difficulty assessments and benchmark contamination. CodeArena’s collective evaluation system mitigates these biases by dynamically recalibrating model scores based on the performance of all participating models. This approach reduces the impact of subjective difficulty assignments, ensuring a fairer comparison. Additionally, the platform’s open data policy promotes transparency, allowing the research community to scrutinize and identify potential biases in the evaluation process. By providing a standardized environment and unified prompt to invoke both open-source and closed-source LLMs, CodeArena seeks to establish a level playing field for assessing code generation capabilities. The inclusion of efficiency scores (ES) also helps to address potential biases related to code optimization, as models are evaluated not only on correctness but also on runtime performance, which fosters a more balanced and holistic evaluation.
More visual insights#
More on figures

🔼 CodeArena’s architecture is depicted, highlighting its four main layers: The green layer shows runtime environments supporting various programming languages. These runtimes accept either code directly or model prompts and return test results. The yellow layer is the dynamic evaluation unit, which updates model rankings based on submission results using a weighted scoring system. The blue and maroon components represent the RESTful APIs used for interaction: GET requests for data retrieval and POST requests for data submission.
read the caption
Figure 2: Overview of CodeArena. The Green component provides runtime environments for programming languages, capable of accepting either generated code or model prompt as the input, and outputting test results. The Yellow component is the dynamic evaluation unit, updating the LLM weighted ranking score based on each submission result. The Blue and Maroon components are RESTful API GET (⊲subgroup-of\lhd⊲) and POST (⊳contains-as-subgroup\rhd⊳) calls, respectively.

🔼 Figure 3 illustrates the calculation of Dynamic Points (DP), a novel scoring metric in CodeArena. Unlike traditional methods, DP considers the overall system performance, adjusting individual model scores based on the collective performance of all participating models. This dynamic approach mitigates bias caused by benchmark leakage. The example shows how Challenge Scores (CS) and Efficiency Scores (ES) contribute to the final DP. Note that CS and ES are only awarded if a model passes all test cases for a given problem.
read the caption
Figure 3: Example of Dynamic Point (𝒟𝒫𝒟𝒫\mathcal{DP}caligraphic_D caligraphic_P) calculation. Each individual model score is influenced by the overall system performance. 𝒞𝒮𝒞𝒮\mathcal{CS}caligraphic_C caligraphic_S and ℰ𝒮ℰ𝒮\mathcal{ES}caligraphic_E caligraphic_S are counted only when the model passes (✓) all test cases.

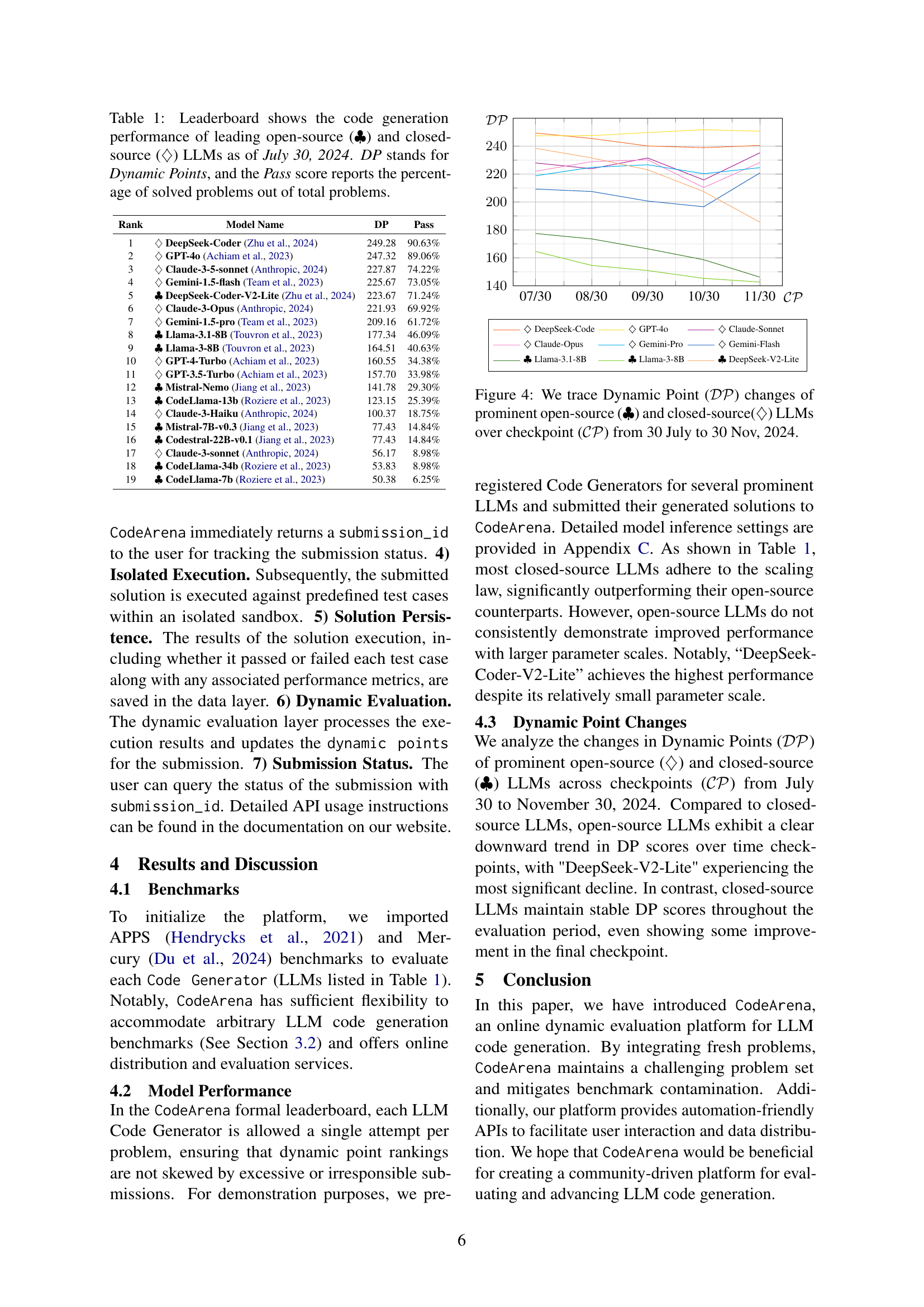
🔼 This figure shows the trend of Dynamic Points (DP) for various prominent open-source and closed-source Large Language Models (LLMs) over time. The DP metric is a novel scoring system used in the CodeArena platform, designed to mitigate bias caused by benchmark leakage and provide a more accurate representation of model performance. The x-axis represents time (checkpoints from July 30th to November 30th, 2024), while the y-axis shows the DP score. Different colored lines represent different LLMs, allowing for a comparison of performance over time. The plot reveals insights into how model performance changes over time and how open-source and closed-source models compare.
read the caption
Figure 4: We trace Dynamic Point (𝒟𝒫𝒟𝒫\mathcal{DP}caligraphic_D caligraphic_P) changes of prominent open-source (♣♣\clubsuit♣) and closed-source(♢♢\diamondsuit♢) LLMs over checkpoint (𝒞𝒫𝒞𝒫\mathcal{CP}caligraphic_C caligraphic_P) from 30 July to 30 Nov, 2024.
Full paper#