TL;DR#
Generating 3D assets often requires extensive 3D datasets, which are challenging to collect and can be of limited quality. Current methods are either time-consuming or heavily dependent on these datasets, hindering their applicability. There’s a growing interest in leveraging the power of 2D diffusion models, which have shown remarkable success, to improve 3D generation, but effectively translating these 2D priors into complete 3D representations remains a key challenge.
Kiss3DGen tackles this challenge by repurposing a pre-trained 2D image diffusion model for 3D asset generation. It introduces a ‘3D Bundle Image,’ combining multi-view images and corresponding normal maps. The model fine-tunes a diffusion model to generate these bundle images, which are then used to reconstruct complete 3D models. This approach efficiently transforms the 3D generation problem into a 2D image generation task. Experiments show it can generate high-quality 3D models efficiently.
Key Takeaways#
Why does it matter?#
This paper introduces a new 3D asset generation method with a novel architecture that researchers can use to generate high-quality 3D models, opening up new avenues for research in this rapidly evolving field. The models show strong performance even with limited training data, showing promise in future research.
Visual Insights#

🔼 This figure showcases a 3D scene from the Harry Potter universe, created using the Kiss3DGen framework. Kiss3DGen is a versatile 3D generation tool capable of producing 3D models from text descriptions, images, or a combination of both. The scene demonstrates various features of the framework. Many objects were generated from short text prompts (e.g., ‘A red sofa’), while some assets were created by converting images into 3D models (indicated by dashed lines). The main characters, Hermione, Ron, and Harry Potter, were created using a more complex process: an image was converted to a 3D model and further refined with text-based mesh editing. This highlights Kiss3DGen’s ability to handle different generation approaches and tasks.
read the caption
Figure 1: A 3D Harry Potter scene built with Kiss3DGen. Our proposed framework, KISS3DGen, is a unified 3D generation framework that facilitates various 3D generation tasks, including text-to-3D, image-to-3D, 3D enhancement, editing and more. Specifically, most of the assets in the figure is generated from text (captioned with abbreviated text prompts) or image (marked by dash lines) conditions, while the main characters (Hermoine, Ron and Potter) are created using a hybrid pipeline that combines image-to-3D and text-guided mesh editing. Please zoom in for details and refer to our main paper for a more introduction.
| Method | Dataset size | CLIP | Quality | Aesthetic |
|---|---|---|---|---|
| Real Data | N/A | 0.884 | 3.138 | 1.911 |
| MVDream | 350K | 0.809 | 2.509 | 1.526 |
| Ours-Base | 147K | 0.844 | 3.248 | 1.94 |
| Ours-50K | 50K | 0.804 | 2.972 | 1.879 |
🔼 This table presents a quantitative comparison of the proposed method’s performance against the MVDream method [48] for text-to-multi-view image synthesis. The comparison uses three metrics: CLIP score (measuring text-image alignment), Quality, and Aesthetic scores. The results demonstrate that the proposed method significantly outperforms MVDream. Surprisingly, the proposed method even surpasses the performance of using the actual multiple views (‘Real Data’) as input for text generation, suggesting that the method learns effective image representations that are superior to simply using real images. The dataset size used for training each method is also indicated.
read the caption
Table 1: The quantitative comparison with MVDream in text-to-multi-view synthesis shows that our method outperforms MVDream [48] by a large margin. Notably, our method even surpasses the “Real Data” in both “Quality” and “Aesthetic” metrics, where “Real Data” refers to the multiple views used to generate text by GPT-4V.
In-depth insights#
2D->3D Retarget#
Retargeting 2D to 3D involves transforming existing 2D assets into 3D representations. This task is crucial for expanding the utility of legacy content and enabling new applications. Methods range from simple extrusion to complex neural network-based reconstruction. Key challenges include generating depth information from flat images, maintaining consistency across views, and ensuring the 3D object accurately reflects the original 2D design. Addressing these challenges can unlock the potential of vast libraries of 2D artwork for use in modern 3D environments, enhancing user experiences and creating new opportunities for interactive design.
3D Bundle Image#
The “3D Bundle Image” concept is a crucial element; it efficiently packages both geometry and texture details of a 3D object. It involves rendering a 3D object from multiple perspectives, each paired with its corresponding normal map. This combination yields a comprehensive representation. The design choice aligns with the existing knowledge in pre-trained 2D diffusion models. Leveraging pre-trained models ensures efficient training and strong generalization. This method aims to encode semantic information about the 3D object, providing an additional supervisory signal during training. It also associates textual descriptions with specific geometric and visual features, and aligns with the prior distribution of pre-trained image diffusion models.
Kiss3DGen-Base#
Based on the paper, Kiss3DGen-Base serves as the foundational model for generating 3D assets. It focuses on creating high-quality “3D Bundle Images” that effectively capture the geometry and texture of objects. A key design principle involves aligning these bundle images with the prior knowledge embedded in pre-trained 2D image diffusion models. This alignment helps preserve the generative capabilities of the pre-trained model. The process leverages ISOMER to produce textured 3D meshes from these bundle images. A DiT model, specifically Flux, is used to capture long-range dependencies for coherent multi-view relationships. The model is further enhanced by using GPT-4V to generate descriptive captions for the 3D Bundle Images, providing additional semantic information. Overall, Kiss3DGen-Base provides the foundation for the method’s 3D generation capabilities.
Edit via ControlNet#
ControlNet offers a promising avenue for detailed 3D editing by leveraging its ability to condition diffusion models on spatial cues. The integration of ControlNet could allow users to guide edits with masks or edge detections, enabling precise manipulation of specific areas in the 3D model. This approach avoids global changes and focuses on local refinements. The combination of ControlNet with textual prompts could further enhance editing capabilities, allowing users to add details, change textures, or stylize specific parts of the 3D object with natural language instructions. This level of control would be a significant advancement over current 3D editing tools.
Consistent Detail#
Achieving consistent detail across various 3D generation tasks, particularly in texturing and geometry, remains a significant challenge. The paper addresses this by leveraging a ‘3D Bundle Image’ representation, effectively transforming the 3D generation problem into a 2D image generation task. This approach is designed to maintain a consistent level of detail, as the model leverages knowledge from pre-trained 2D diffusion models. Furthermore, the integration of ControlNet allows for controlled enhancement and editing, ensuring details align across views and modalities. The use of a DiT model, especially the architecture’s attention blocks, is crucial for capturing long-range dependencies, ensuring coherence in multi-view relationships. By balancing enhancement strength with control, the framework achieves consistent detail by retaining original mesh semantics while enriching texture and geometry, showcasing effectiveness of our approach.
More visual insights#
More on figures

🔼 This figure illustrates the two-stage process of the Kiss3DGen framework for text-to-3D generation. First, a high-quality text-3D dataset is created and used to train a LoRA (Low-Rank Adaptation) layer on a pre-trained text-to-image diffusion transformer model. This model is enhanced using flow matching. The resulting model, Kiss3DGen-base, generates a 3D Bundle Image (a multi-view representation combining RGB and normal maps) from text prompts (Stage I). In Stage II, this 2D image is processed to reconstruct a 3D mesh and texture. Reconstruction uses either LRM (Large Reconstruction Model) or sphere initialization, followed by mesh refinement and texture projection with ISOMER. The output is a complete 3D model. The figure visually depicts each step of the process, including data preparation, model training, and the two-stage generation.
read the caption
Figure 2: The overview of our text-to-3D training and generation framework. In this work, we curate a high-quality text-3D dataset, then train a LoRA [15] layer for text to 3D bundle image (Sec. 3) generation upon a pretrained text-to-image diffusion transformer model with flow matching [25]. After training, our framework generates 3D assets with text condition in two stages: the 3D-Bundle-Image (Sec. 3) generation (Stage I) and the 3D reconstruction (Stage II). In Stage I, we generate 3D bundle image with our Kiss3DGen base model guided by text prompts. In Stage II, we reconstruct the geometry and texture of the 3D asset via LRM [60, 14] or sphere initialization followed by optimization-based mesh refinement and texture projection approach, i.e., ISOMER [56]. Please zoom in for details.
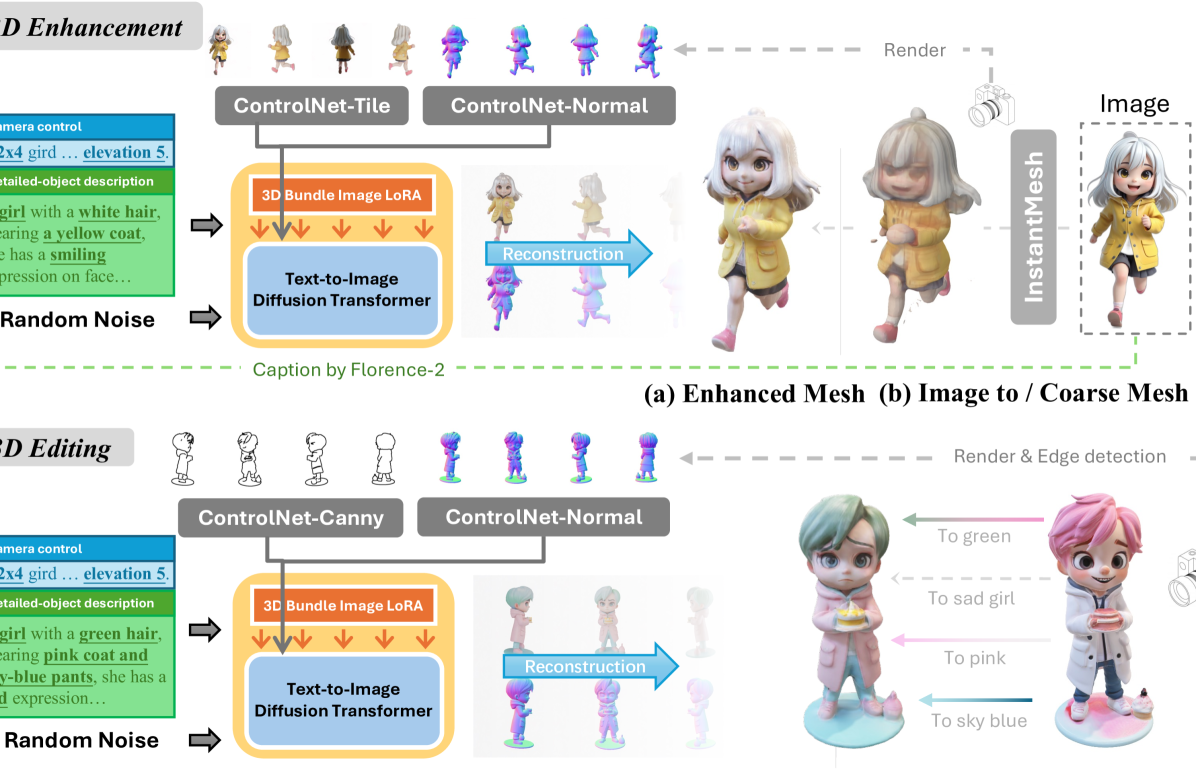
🔼 Figure 3 demonstrates Kiss3DGen’s capabilities in 3D enhancement and editing. It showcases how a low-quality input mesh (or a coarse mesh from a 2D image) can be significantly improved using ControlNet, a technique that integrates additional information to guide the generation process. Specifically, the figure illustrates 3D enhancement by refining a mesh with blurry textures and geometry lacking detail (subfigures (a) and (b)). It also shows 3D editing, where attributes like color, shape, and expression are modified from a base mesh through caption-based editing (subfigures (c) and (d)). This highlights Kiss3DGen’s ability to handle both enhancement and targeted edits, leveraging a combination of its base 3D generation model and the ControlNet framework.
read the caption
Figure 3: 3D enhancement and editing with Kiss3DGen. In order to achieve high-quality image-to-3D generation, we incorporate the existing image-to-3D pipeline [60] with our general 3D enhancement pipeline. Please zoom in for details.

🔼 Figure 4 presents a qualitative comparison of multi-view image generation results between the proposed method, Kiss3DGen, and the existing MVDream method [48]. The comparison focuses on text-to-image generation, where a textual description is used to generate multiple views of an object. The figure visually demonstrates that Kiss3DGen achieves significantly superior results in two key aspects: First, the generated images from Kiss3DGen show stronger alignment with the input text descriptions, meaning the generated images more accurately reflect the content described in the text. Second, Kiss3DGen produces images with improved geometric coherence. This means the generated views of the object are more consistent and realistic across different viewpoints, leading to a more unified and believable 3D representation. The figure uses example text prompts and corresponding generated images from both methods to visually illustrate the differences in image quality and consistency.
read the caption
Figure 4: Qualitative comparisons with MVDream [48] for text-to-multiview generation. Within the context of text-conditioned multi-view generation, our method produces significantly better results in both text-image alignment and geometric coherence.

🔼 Figure 5 presents a qualitative comparison of 3D models generated by Kiss3DGen and other state-of-the-art text-to-3D generation methods. For each method, several example 3D objects are shown, illustrating the quality of mesh generation and the accuracy of texture mapping from text prompts. The figure visually demonstrates that Kiss3DGen outperforms other approaches in generating high-quality 3D meshes and accurately reflecting the textual descriptions in the generated textures.
read the caption
Figure 5: Qualitative comparisons with state-of-the-art methods for text-to-3D generation. It demonstrates that Kiss3DGen achieves the highest quality 3D mesh, delivering more accurate texture generation from the input prompts compared to others.

🔼 This figure compares the results of text-to-3D generation using two different models: the base model and a specialized doll model. The same text prompt (‘A realistic photo of a cute cat, orange fur, smiling, sitting with body straight up, rich details’) was used for both models. Multiple generations were produced using each model with different random seeds to illustrate the variability in the outputs. All images shown are renderings of the generated 3D mesh.
read the caption
Figure 6: Text-to-3D generation comparison between our Base and Doll models (Sec. 4.1). Each model generates different results with different seeds. All images are rendered from 3D mesh.

🔼 This figure compares the results of 3D mesh enhancement and editing using the proposed Kiss3DGen model and the baseline MVEdit [3] method. The top row shows the input image and the target edits specified using text prompts. The second row presents the results generated by Kiss3DGen. The third row displays the results from MVEdit. The comparison highlights that Kiss3DGen produces significantly better results in terms of maintaining consistency with the input mesh during the enhancement process. Moreover, Kiss3DGen achieves better alignment with the text conditions provided for editing tasks, leading to more accurate and targeted modifications to the 3D mesh.
read the caption
Figure 7: Qualitative comparison on 3D mesh Enhancement and Editing with MVEdit [3]. Our results (line 2) maintain significantly better consistency with the input mesh in enhancement and better align with the given text condition in editing.

🔼 Figure 8 presents a qualitative comparison of image-to-3D generation results produced by the proposed Kiss3DGen model and several state-of-the-art methods. The figure showcases input images alongside their corresponding 3D reconstructions generated by each method. The comparison highlights Kiss3DGen’s superior ability to generate high-quality 3D meshes with accurate and realistic textures. The differences in detail, texture quality, and overall fidelity of the 3D models are clearly illustrated, demonstrating the effectiveness of the proposed approach compared to existing techniques.
read the caption
Figure 8: Qualitative comparisons with state-of-the-art methods for image-to-3D generation. Our framework achieves the highest quality 3D mesh, delivering more accurate and realistic texture generation from input images compared to other models.

🔼 This figure compares two different methods for generating multi-view RGB and normal maps for 3D object representation, both based on the Flux.1-dev model. The first method, ‘3D Bundle Image’, combines RGB and normal map information into a single image, while the second method, ‘Switcher’, generates them separately and combines them later. The figure visually demonstrates the advantages of the ‘3D Bundle Image’ approach by showcasing its superior consistency and coherence in the resulting multi-view representations compared to the ‘Switcher’ method. This highlights the importance of the proposed 3D Bundle Image approach for effective 3D object generation.
read the caption
Figure 9: Ablating the mechanisms of generating multiview RGB and normal maps. Both our “3D Bundle Image” and “Switcher” [30, 20] are built upon Flux.1-dev [1] model.
More on tables
| Method | Dataset size | CLIP | Quality | Aesthetic |
|---|---|---|---|---|
| 3DTopia | 320k | 0.694 | 2.145 | 1.538 |
| Direct2.5 | 500k | 0.773 | 2.158 | 1.459 |
| Hunyuan3D-1.0 | N/A | 0.792 | 2.517 | 1.504 |
| Ours-Base | 147k | 0.837 | 2.700 | 1.800 |
| Ours-50K | 50k | 0.804 | 2.716 | 1.601 |
🔼 This table presents a quantitative comparison of different text-to-3D generation methods. The evaluation metrics used are CLIP score, Quality, and Aesthetic scores, all obtained after rendering the generated 3D models. The results show that the proposed method (Ours-Base and Ours-50K) significantly outperforms existing state-of-the-art methods, such as 3DTopia, Direct2.5, and Hunyuan3D-1.0, across all three evaluation metrics. The higher scores indicate better alignment between the generated 3D models and their corresponding text descriptions, as well as improved overall visual quality.
read the caption
Table 2: Quantitative comparison of text-to-3D generation results after rendering, evaluated in terms of CLIP-score, Quality, and Aesthetic metrics. Our method outperforms 3DTopia [13], Direct2.5 [32], and Hunyuan3D-1.0 [61], achieving higher scores across all metrics, indicating a significant improvement in alignment with textual descriptions and visual quality.
| Method | Dataset size | CD | FS | PSNR | SSIM | LPIPS |
|---|---|---|---|---|---|---|
| CraftsMan | 170k | 0.178 | 0.739 | N/A | N/A | N/A |
| Unique3D | 50k | 0.217 | 0.654 | 19.237 | 0.898 | 0.127 |
| Hunyuan3D-1.0 | N/A | 0.153 | 0.768 | 16.652 | 0.885 | 0.123 |
| Ours-Base | 147k | 0.149 | 0.769 | 20.348 | 0.902 | 0.116 |
| Ours-50K | 50k | 0.151 | 0.766 | 20.215 | 0.884 | 0.131 |
🔼 This table presents a quantitative comparison of several image-to-3D generation methods. The comparison uses multiple metrics to assess the quality of the generated 3D models. Because the CraftsMan method only produces 3D geometry without textures, the evaluation metrics for CraftsMan are limited to those that assess geometric properties, specifically Chamfer Distance (CD) and F-Score (FS). Other methods are evaluated using additional metrics that incorporate texture and visual quality. The table allows readers to see how different methods perform on various aspects of 3D model generation from images.
read the caption
Table 3: Quantitative comparison of image-to-3D generation methods across multiple metrics. Since CraftsMan generates only geometry without textures, the comparison with this method is limited to 3D geometry metrics (Chamfer Distance (CD) and F-Score (FS)).
Full paper#
















