TL;DR#
Retrieval-augmented generation (RAG) enhances QA by leveraging external knowledge. Current RAG methods face challenges: (1) segmenting corpus without considering semantics, causing context loss, and (2) balancing relevant vs. irrelevant context is difficult, leading to inaccurate answers and token cost inefficiencies. These limitations stem from ineffective corpus segmentation and noisy retrieval issues.
This paper introduces SAGE, a RAG framework, designed to overcome these limitations. SAGE employs a semantic segmentation model for coherent chunks, a gradient-based selection for relevant context, and LLM feedback for refining the context. This approach boosts the quality of QA by 61.25% and cost efficiency by 49.41% by avoiding noisy context and improving the retrieved context for LLMs.
Key Takeaways#
Why does it matter?#
This work enhances RAG by improving retrieval precision, significantly boosting QA accuracy and cost-efficiency. It opens new research directions in semantic segmentation and adaptive chunk selection for better context utilization.
Visual Insights#

🔼 This figure showcases three common problems in the precise retrieval phase of Retrieval-Augmented Generation (RAG) systems. Panel A demonstrates ‘Ineffective Corpus Segmentation,’ where the crucial segment containing the answer is improperly divided, hindering retrieval. Panel B illustrates ‘Noisy Retrieval,’ where the retrieval process returns both relevant and irrelevant segments, leading to an ambiguous and potentially inaccurate LLM response. Finally, Panel C shows ‘Missing Retrieval,’ where a critical segment containing the answer is missed, resulting in an incorrect LLM response. Each panel shows the question, the relevant segment, the retrieved segments, and the resulting LLM response, highlighting the failures that result from poor segmentation and retrieval strategies.
read the caption
Figure 1: Three motivational examples illustrating the current limitations of precise retrieval for RAG.
| Notation | Description |
| Segmented Chunks | |
| Embedding model | |
| MLP model used in segmentation model | |
| Chunks queried from vector database | |
| Chunks after gradient based selection | |
| The number of chunks queried from a vector database | |
| The number of retrieved chunks | |
| Price per input/output token of a LLM |
🔼 This table lists the notations used throughout the paper. It defines acronyms and symbols used to represent various aspects of the SAGE framework, including corpus elements, models, and performance metrics. This provides a handy reference for understanding the mathematical descriptions and algorithms presented later in the paper.
read the caption
TABLE I: Notations.
In-depth insights#
Precise Retrieval#
Precise retrieval in RAG systems hinges on semantically coherent data chunks. Current methods often segment corpora without semantic awareness, leading to retrieval of incomplete or irrelevant information. Effective segmentation is essential to capture the full context needed for accurate question answering. Strategies to ensure precise retrieval dynamically adjust the amount of context based on the specific question, avoiding a fixed number of chunks that may introduce noise or miss crucial data. This approach leverages feedback mechanisms to refine retrieval accuracy, aiming to provide LLMs with only the most relevant and complete information, ultimately boosting QA performance and cost-efficiency by reducing unnecessary token processing.
Semantic Chunks#
Semantic chunks play a crucial role in enhancing RAG. Current methods often overlook semantic coherence, leading to irrelevant or incomplete information retrieval. Effective segmentation ensures retrieved chunks are semantically complete and relevant, improving QA capabilities. Unlike fixed-length chunks, semantics-aware chunks better capture context, reducing noisy information and improving answer accuracy. Training lightweight models for rapid and accurate semantic segmentation is key. This approach minimizes token requirements and lowers LLM inference costs, ultimately leading to more precise and efficient RAG systems, while Gradient-based chunk selection is used to find the optimal chunk
Gradient Selection#
The research paper introduces a ‘Gradient-based Chunk Selection’ method for improving the precision of retrieval-augmented generation (RAG). This approach dynamically selects context chunks based on the relevance score gradient, aiming to identify the most pertinent information while minimizing noise. Traditional methods often rely on a fixed number of retrieved chunks, leading to either insufficient context or the inclusion of irrelevant data. By leveraging the gradient, the system identifies points where relevance sharply decreases, effectively truncating the context to only include the most valuable segments. This technique enhances accuracy, reduces computational costs, and optimizes the information retrieval process within RAG frameworks.
LLM Self-Feedback#
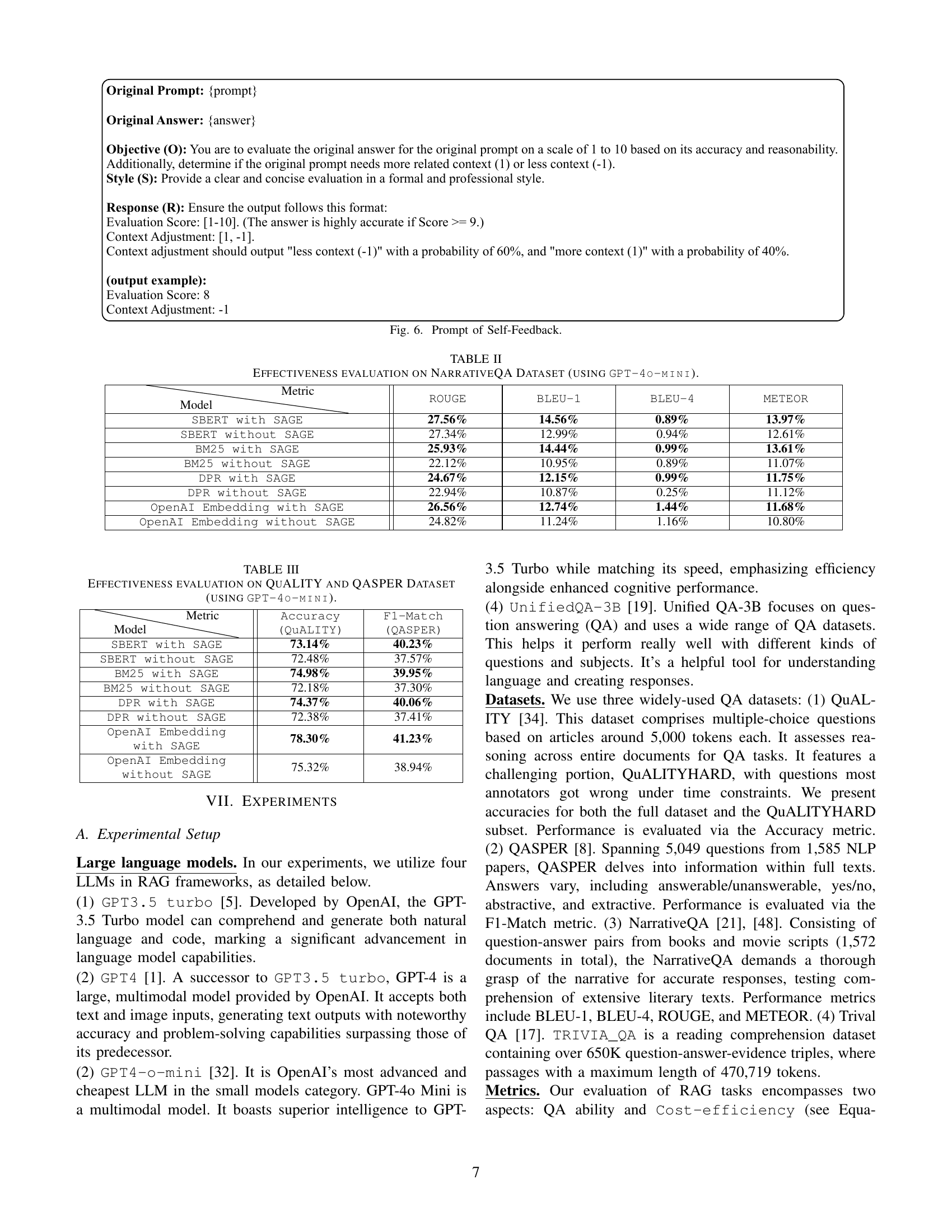
LLM Self-Feedback is presented as an integral component for refining retrieval precision. By prompting the LLM to evaluate both the quality of its answer and the relevance of the retrieved context, the framework actively identifies and mitigates issues like noisy retrieval or missing context. This iterative feedback loop dynamically adjusts the number of retrieved chunks based on the LLM’s assessment, ensuring a balance between sufficient information and minimal noise. A self-feedback loop has two outcomes, the first being an evaluation score and the second denoting context adjustment. If there is excessive information, the retrieved chunks reduce by one, or if there is information lacking, the chunks increase by one. This approach harnesses the LLM’s understanding of the question and the ideal context, allowing for a more adaptive and context-aware retrieval process than traditional methods with fixed retrieval sizes.
Scalable SAGE#
Scalable SAGE highlights the importance of the solution’s adaptability to growing datasets & user loads. Key considerations include segmentation & retrieval speed, memory footprint, and concurrent processing capabilities. Efficiency in these areas is critical to maintaining real-time responsiveness. The system must leverage hardware acceleration (GPUs) and algorithmic optimizations to handle large-scale datasets. Maintaining performance as data volume and user concurrency increases is a core factor. It should also be cost-effective in terms of computational resources and energy consumption. Scalability is not merely about handling more data; it is about doing so efficiently, cost-effectively, and without sacrificing the accuracy or relevance of the generated answers. The system must adapt to new domains without significant performance degradation.
More visual insights#
More on figures

🔼 This figure illustrates the workflow of the SAGE framework for precise retrieval in RAG. It begins with corpus segmentation, where the corpus is divided into semantically complete chunks using a trained model. These chunks are then converted into vector embeddings and stored in a vector database. When a question arrives, it is embedded and used to query the database, retrieving the top N most similar chunks. A gradient-based reranking model then dynamically selects the most relevant chunks (Top K). These top K chunks, along with the original question, are provided as input to a large language model (LLM) for answer generation. Finally, a self-feedback loop is implemented: the LLM’s generated answer and the context are assessed to determine if additional or fewer chunks are needed for a more accurate response. If the answer quality is not sufficient, the system iteratively refines chunk selection and LLM input until the quality reaches the set threshold or the iteration limit is reached.
read the caption
Figure 2: Workflow of SAGE, where the ⇢⇢\dashrightarrow⇢ inidcates the pipelines of self-feedback.

🔼 This figure illustrates the motivation behind choosing a suitable corpus segmentation method for retrieval-augmented generation (RAG). It compares four different approaches: partitioning by a small fixed length, partitioning by whole sentences using a small fixed length, partitioning by whole sentences using a large fixed length, and using a semantics-based segmentation model. The examples highlight how fixed-length segmentation often leads to semantically incomplete or incoherent chunks, whereas a semantic approach ensures the retrieved context is relevant and complete. The numbers within the figure represent chunk IDs.
read the caption
Figure 3: Motivation of corpus segmentation. The number in 1 means the chunk ID.

🔼 This figure illustrates the architecture of the corpus segmentation model used in the SAGE framework. The model takes pairs of sentences as input, embedding them using a pre-trained embedding model. Feature augmentation then calculates the difference and product of the sentence embeddings. Finally, a Multi-Layer Perceptron (MLP) processes these features (embeddings, difference, and product) to produce a score indicating whether the two sentences should belong to the same semantically coherent chunk or be separated. A threshold on this score determines the final segmentation decision.
read the caption
Figure 4: Corpus segmentation model.

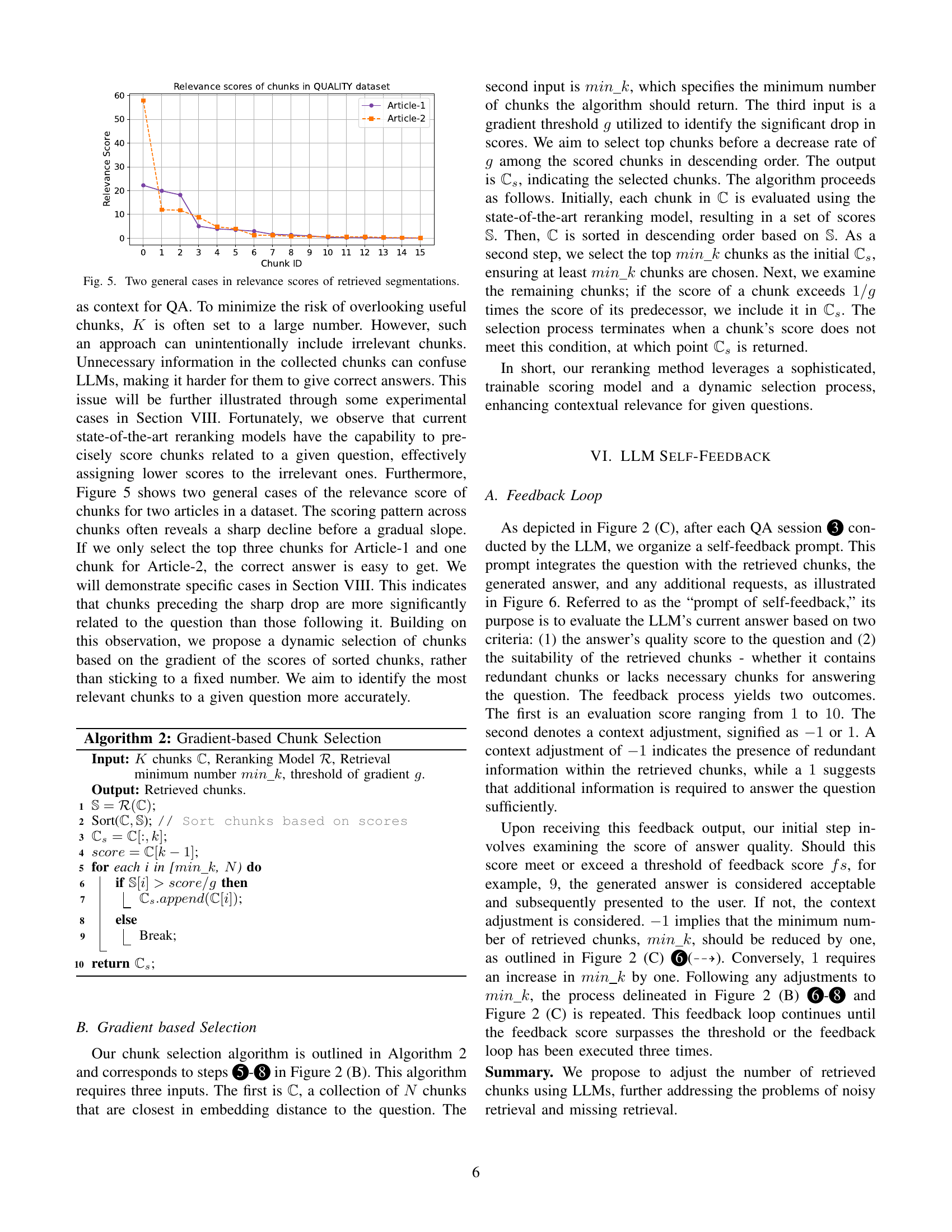
🔼 This figure illustrates two common patterns observed in the relevance scores assigned to retrieved document segments by a reranking model in a RAG system. The x-axis represents the ID of each retrieved segment, and the y-axis shows its relevance score. The first pattern shows a sharp drop in relevance scores after the top few segments, indicating a clear separation between highly relevant and less relevant content. The second pattern shows a more gradual decrease in relevance, suggesting a less distinct boundary between highly relevant and less relevant segments. These patterns highlight the challenge of dynamically selecting the optimal number of relevant segments for input to the language model.
read the caption
Figure 5: Two general cases in relevance scores of retrieved segmentations.

🔼 This figure shows the prompt template used for the LLM self-feedback mechanism in the SAGE framework. The prompt includes the original question, the LLM’s generated answer, and a request for the LLM to evaluate the answer’s quality (on a scale of 1-10) and assess whether the provided context was sufficient or excessive (+1/-1). This feedback is crucial for dynamically adjusting the number of retrieved chunks in subsequent iterations, improving the accuracy and efficiency of the RAG system.
read the caption
Figure 6: Prompt of Self-Feedback.

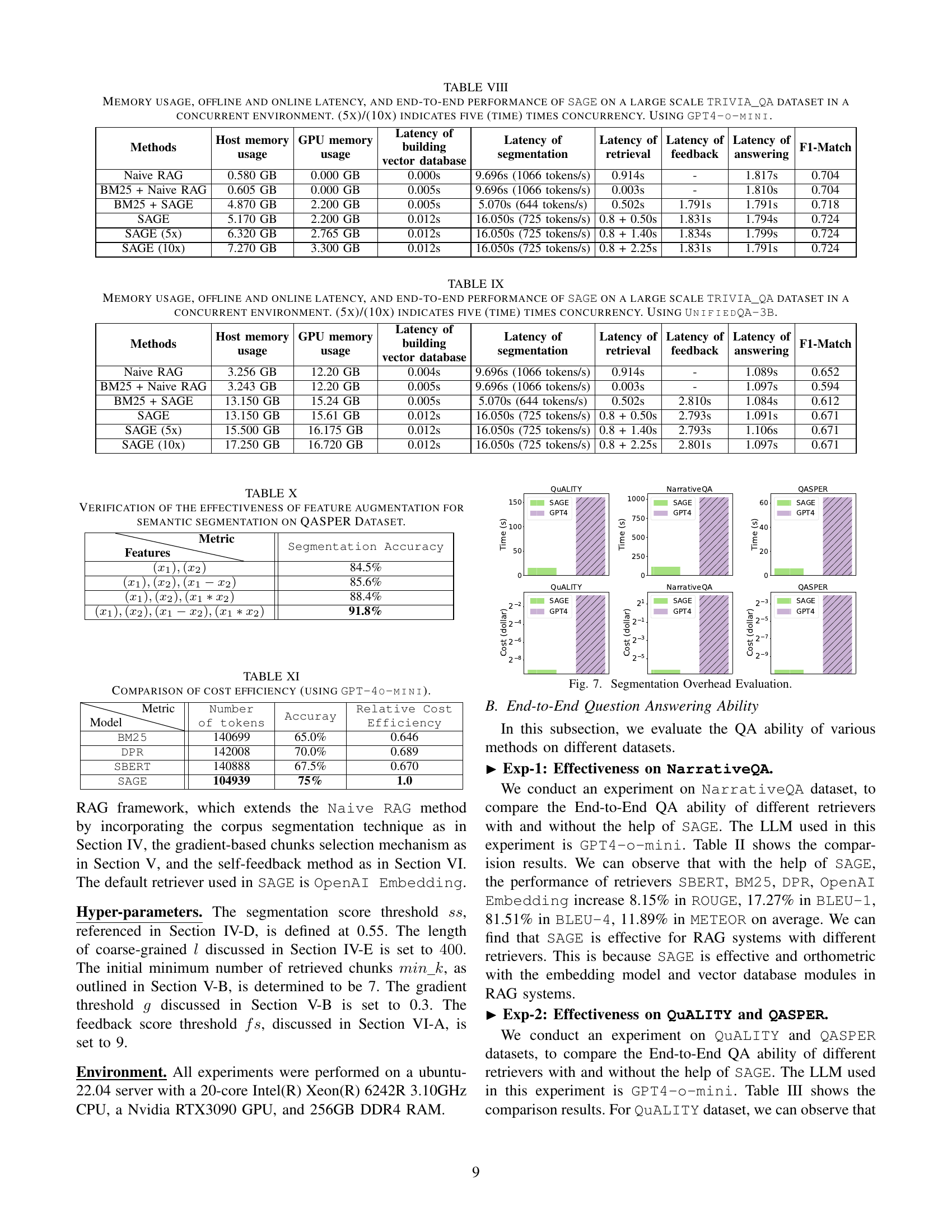
🔼 Figure 7 presents a bar chart comparing the time overhead introduced by the semantic segmentation module in SAGE across three different datasets: QUALITY, NarrativeQA, and QASPER. It illustrates the additional time required for SAGE’s segmentation process, comparing it to the time taken by a typical LLM approach. The chart visually demonstrates whether the time savings from using a lightweight segmentation model in SAGE outweighs the overhead added by the extra steps in SAGE’s process. The use of different LLMs (GPT-4 and GPT-4-o-mini) for different parts of the experiment are also shown in the graph.
read the caption
Figure 7: Segmentation Overhead Evaluation.

🔼 This figure demonstrates a real-world example from the QUALITY dataset where noisy retrieval negatively impacts question answering. The question asks for the genetic definition of ‘kin’. While the correct answer is ‘full siblings’, numerous noisy chunks, containing information supporting alternative answers like ‘all humans’, are retrieved along with the correct answer. The chart illustrates how the score assigned to each chunk by the model varies. Crucially, it shows that if the number of retrieved chunks (K) is small (2 ≤ K ≤ 10), the correct answer (‘full siblings’) is selected. However, as K increases (11 ≤ K ≤ 13), incorrect responses arise due to the noisy chunks’ influence, and when K reaches 14, the LLM selects the completely wrong answer ‘all humans’. This highlights the issue of noisy retrieval in RAG systems and the need for a precise retrieval mechanism.
read the caption
Figure 8: A case of noisy retrieval.

🔼 This figure demonstrates a scenario where crucial contextual information, necessary for accurate question answering, is absent from the retrieved text. The question is about which technology has not been developed on Venus. The correct answer (Option 3: Creating fire) requires the presence of a specific chunk of text among those retrieved. However, when the number (K) of retrieved chunks is set to a value less than or equal to 6, this essential chunk is missing, leading to an incorrect answer (Option 4: Metallurgy). Only when K is between 7 and 14 does the model have access to the necessary information and provide the correct answer. Increasing K to 15 leads to another incorrect answer.
read the caption
Figure 9: A case of missing retrieval.

🔼 This figure shows an example from the QUALITY dataset where ineffective corpus segmentation leads to an incorrect answer. The question is: ‘Who asked Gavir to sing a tribal song?’ The correct answer is ‘The moderator.’ However, the corpus is segmented such that the two sentences containing the answer (‘Well, enough of that!’ the moderator said briskly. ‘How about singing one of your tribal songs for us?’ Gavir said, ‘I will sing the Song of Going to Hunt.’) are split into separate chunks. As a result, the model cannot connect the moderator’s request with Gavir’s response, making it impossible to determine the correct answer.
read the caption
Figure 10: A case of ineffective corpus segmentation.
More on tables
| ROUGE | BLEU-1 | BLEU-4 | METEOR | |
| SBERT with SAGE | 27.56% | 14.56% | 0.89% | 13.97% |
| SBERT without SAGE | 27.34% | 12.99% | 0.94% | 12.61% |
| BM25 with SAGE | 25.93% | 14.44% | 0.99% | 13.61% |
| BM25 without SAGE | 22.12% | 10.95% | 0.89% | 11.07% |
| DPR with SAGE | 24.67% | 12.15% | 0.99% | 11.75% |
| DPR without SAGE | 22.94% | 10.87% | 0.25% | 11.12% |
| OpenAI Embedding with SAGE | 26.56% | 12.74% | 1.44% | 11.68% |
| OpenAI Embedding without SAGE | 24.82% | 11.24% | 1.16% | 10.80% |
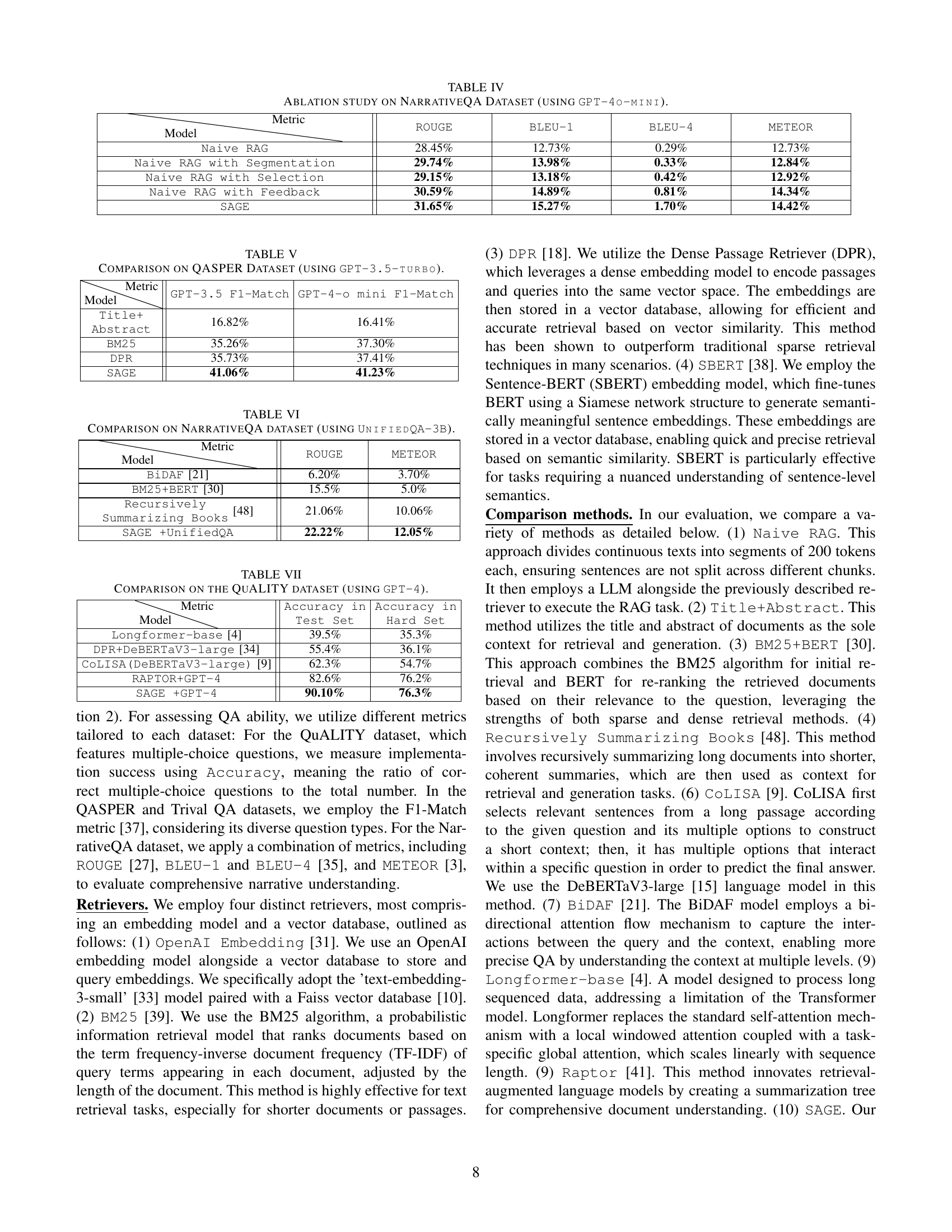
🔼 This table presents the performance comparison of different retrieval methods on the NarrativeQA dataset when using the GPT-4o-mini language model. It shows the ROUGE, BLEU-1, BLEU-4, and METEOR scores for various combinations of retrieval methods (SBERT, BM25, DPR, OpenAI Embedding) with and without the SAGE framework. This allows for an assessment of how SAGE impacts the effectiveness of different retrieval techniques on this specific QA dataset.
read the caption
TABLE II: Effectiveness evaluation on NarrativeQA Dataset (using GPT-4o-mini).
| Accuracy (QuALITY) | F1-Match (QASPER) | |
| SBERT with SAGE | 73.14% | 40.23% |
| SBERT without SAGE | 72.48% | 37.57% |
| BM25 with SAGE | 74.98% | 39.95% |
| BM25 without SAGE | 72.18% | 37.30% |
| DPR with SAGE | 74.37% | 40.06% |
| DPR without SAGE | 72.38% | 37.41% |
| OpenAI Embedding with SAGE | 78.30% | 41.23% |
| OpenAI Embedding without SAGE | 75.32% | 38.94% |
🔼 This table presents the performance evaluation results of different retrieval methods on two distinct question answering datasets: QuALITY and QASPER. The evaluation metric used is Accuracy for the QuALITY dataset and F1-Match for the QASPER dataset. The results show the accuracy and F1-Match scores achieved by various combinations of retrieval techniques (SBERT, BM25, DPR, OpenAI Embedding) with and without the SAGE framework, indicating the improvement in performance offered by the SAGE framework on each dataset.
read the caption
TABLE III: Effectiveness evaluation on QuALITY and QASPER Dataset (using GPT-4o-mini).
| ROUGE | BLEU-1 | BLEU-4 | METEOR | |
| Naive RAG | 28.45% | 12.73% | 0.29% | 12.73% |
| Naive RAG with Segmentation | 29.74% | 13.98% | 0.33% | 12.84% |
| Naive RAG with Selection | 29.15% | 13.18% | 0.42% | 12.92% |
| Naive RAG with Feedback | 30.59% | 14.89% | 0.81% | 14.34% |
| SAGE | 31.65% | 15.27% | 1.70% | 14.42% |
🔼 This table presents the results of an ablation study conducted on the NarrativeQA dataset using the GPT-4o-mini language model. The study investigates the impact of each component of the proposed SAGE framework (semantic segmentation, gradient-based chunk selection, and LLM self-feedback) on the performance of the system. It compares the performance metrics (ROUGE, BLEU-1, BLEU-4, and METEOR) of several models: a naive RAG baseline, and variants incorporating one or more components of SAGE. This allows for a quantitative assessment of the contribution of each component to the overall performance.
read the caption
TABLE IV: Ablation study on NarrativeQA Dataset (using GPT-4o-mini).
| GPT-3.5 F1-Match | GPT-4-o mini F1-Match | |
| Title+ Abstract | 16.82% | 16.41% |
| BM25 | 35.26% | 37.30% |
| DPR | 35.73% | 37.41% |
| SAGE | 41.06% | 41.23% |
🔼 This table presents a comparison of the F1-Match scores achieved by different retrieval methods on the QASPER dataset using the GPT-3.5-Turbo large language model. It shows the performance of different retrieval techniques in retrieving relevant information for answering questions from the QASPER dataset, a benchmark dataset for question answering tasks. The results highlight the relative effectiveness of each retrieval approach.
read the caption
TABLE V: Comparison on QASPER Dataset (using GPT-3.5-turbo).
| ROUGE | METEOR | |
| BiDAF [21] | 6.20% | 3.70% |
| BM25+BERT [30] | 15.5% | 5.0% |
| Recursively Summarizing Books [48] | 21.06% | 10.06% |
| SAGE +UnifiedQA | 22.22% | 12.05% |
🔼 This table presents a comparison of the performance of different models on the NarrativeQA dataset. The models compared include BIDAF, BM25+BERT, Recursively Summarizing Books, and SAGE+UnifiedQA-3B. The evaluation metrics used are ROUGE and METEOR, which measure the quality of generated summaries. The table highlights the relative performance of SAGE+UnifiedQA-3B in comparison to existing methods for the NarrativeQA task.
read the caption
TABLE VI: Comparison on NarrativeQA dataset (using UnifiedQA-3B).
| Accuracy in Test Set | Accuracy in Hard Set | |
| Longformer-base [4] | 39.5% | 35.3% |
| DPR+DeBERTaV3-large [34] | 55.4% | 36.1% |
| CoLISA(DeBERTaV3-large) [9] | 62.3% | 54.7% |
| RAPTOR+GPT-4 | 82.6% | 76.2% |
| SAGE +GPT-4 | 90.10% | 76.3% |
🔼 This table presents a comparison of the accuracy achieved by different models on the QuALITY dataset, specifically focusing on the performance using GPT-4 as the large language model. It highlights the accuracy scores obtained on both the overall test set and a more challenging subset known as the ‘Hard Set’. The models being compared represent various approaches to question answering, allowing for a quantitative assessment of their relative effectiveness on this particular dataset.
read the caption
TABLE VII: Comparison on the QuALITY dataset (using GPT-4).
| Methods | Host memory usage | GPU memory usage | Latency of building vector database | Latency of segmentation | Latency of retrieval | Latency of feedback | Latency of answering | F1-Match |
| Naive RAG | 0.580 GB | 0.000 GB | 0.000s | 9.696s (1066 tokens/s) | 0.914s | - | 1.817s | 0.704 |
| BM25 + Naive RAG | 0.605 GB | 0.000 GB | 0.005s | 9.696s (1066 tokens/s) | 0.003s | - | 1.810s | 0.704 |
| BM25 + SAGE | 4.870 GB | 2.200 GB | 0.005s | 5.070s (644 tokens/s) | 0.502s | 1.791s | 1.791s | 0.718 |
| SAGE | 5.170 GB | 2.200 GB | 0.012s | 16.050s (725 tokens/s) | 0.8 + 0.50s | 1.831s | 1.794s | 0.724 |
| SAGE (5x) | 6.320 GB | 2.765 GB | 0.012s | 16.050s (725 tokens/s) | 0.8 + 1.40s | 1.834s | 1.799s | 0.724 |
| SAGE (10x) | 7.270 GB | 3.300 GB | 0.012s | 16.050s (725 tokens/s) | 0.8 + 2.25s | 1.831s | 1.791s | 0.724 |
🔼 Table VIII presents a comprehensive performance analysis of the SAGE framework on the large-scale TRIVIA_QA dataset. It details the memory usage (both host and GPU memory), offline latency (for vector database building and segmentation), online latency (for retrieval, feedback, and answering), and the overall F1-Match score, all under varying degrees of concurrency (1x, 5x, and 10x). The experiment utilizes the GPT4-o-mini language model, providing a detailed view of SAGE’s efficiency and scalability in a real-world, concurrent environment.
read the caption
TABLE VIII: Memory usage, offline and online latency, and end-to-end performance of SAGE on a large scale TRIVIA_QA dataset in a concurrent environment. (5x)/(10x) indicates five (time) times concurrency. Using GPT4-o-mini.
| Methods | Host memory usage | GPU memory usage | Latency of building vector database | Latency of segmentation | Latency of retrieval | Latency of feedback | Latency of answering | F1-Match |
| Naive RAG | 3.256 GB | 12.20 GB | 0.004s | 9.696s (1066 tokens/s) | 0.914s | - | 1.089s | 0.652 |
| BM25 + Naive RAG | 3.243 GB | 12.20 GB | 0.005s | 9.696s (1066 tokens/s) | 0.003s | - | 1.097s | 0.594 |
| BM25 + SAGE | 13.150 GB | 15.24 GB | 0.005s | 5.070s (644 tokens/s) | 0.502s | 2.810s | 1.084s | 0.612 |
| SAGE | 13.150 GB | 15.61 GB | 0.012s | 16.050s (725 tokens/s) | 0.8 + 0.50s | 2.793s | 1.091s | 0.671 |
| SAGE (5x) | 15.500 GB | 16.175 GB | 0.012s | 16.050s (725 tokens/s) | 0.8 + 1.40s | 2.793s | 1.106s | 0.671 |
| SAGE (10x) | 17.250 GB | 16.720 GB | 0.012s | 16.050s (725 tokens/s) | 0.8 + 2.25s | 2.801s | 1.097s | 0.671 |
🔼 This table presents a comprehensive performance evaluation of the SAGE framework on the large-scale TRIVIA_QA dataset using the UnifiedQA-3B language model. It details the memory usage (both host and GPU), offline latency (for vector database building and segmentation), and online latency (for retrieval, feedback, and answering) under various concurrency levels (1x, 5x, and 10x). The end-to-end performance is assessed using the F1-Match metric. This allows for a detailed understanding of SAGE’s resource consumption and response time in a concurrent environment, showcasing its scalability and efficiency.
read the caption
TABLE IX: Memory usage, offline and online latency, and end-to-end performance of SAGE on a large scale TRIVIA_QA dataset in a concurrent environment. (5x)/(10x) indicates five (time) times concurrency. Using UnifiedQA-3B.
| Segmentation Accuracy | |
| 84.5% | |
| 85.6% | |
| 88.4% | |
| 91.8% |
🔼 This table presents the results of an ablation study conducted to evaluate the impact of feature augmentation on the performance of a semantic segmentation model. The study specifically examines the model’s accuracy in segmenting sentences from the QASPER dataset. Different combinations of features were used to train the model and their corresponding segmentation accuracies are reported. This allows the researchers to assess the contribution of each feature to the overall performance.
read the caption
TABLE X: Verification of the effectiveness of feature augmentation for semantic segmentation on QASPER Dataset.
| Number of tokens | Accuray | Relative Cost Efficiency | |
| BM25 | 140699 | 65.0% | 0.646 |
| DPR | 142008 | 70.0% | 0.689 |
| SBERT | 140888 | 67.5% | 0.670 |
| SAGE | 104939 | 75% | 1.0 |
🔼 This table compares the cost-efficiency of different retrieval methods in a RAG system using the GPT-4o-mini language model. Cost-efficiency is calculated by considering both the accuracy of the question answering (QA) task and the cost of tokens consumed during LLM inference. The table allows a comparison of the balance between achieving high QA accuracy and minimizing the computational cost.
read the caption
TABLE XI: Comparison of cost efficiency (using GPT-4o-mini).
| GPT-3.5 Accuracy | GPT-4o-mini Accuracy | |
| BM25 | 62.70% | 73.50% |
| DPR | 60.4% | 73.0% |
| SAGE | 64.5% | 77.1% |
🔼 This table presents the accuracy results of different LLMs on the QuALITY dataset. It compares the performance of various Large Language Models (LLMs) in a question-answering task using the QuALITY dataset. The results show the accuracy achieved by each LLM on the QuALITY dataset, providing a comparison of their performance on a complex question answering benchmark.
read the caption
TABLE XII: Accuracy on QuALITY Dataset with different LLMs.
Full paper#