TL;DR#
Humans easily read scrambled words, a phenomenon called Typoglycemia, by leveraging word form and contextual cues. While LLMs can do the same, it’s unclear how. This paper investigates how LLMs internally process scrambled text, focusing on the roles of word form and context. They conduct controlled experiments using LLaMA models, introducing a metric called SemRecScore to measure semantic reconstruction.
The study reveals that LLMs primarily depend on word form, using specialized attention heads, with context playing a minimal role. This contrasts with human readers who adaptively balance word form and context. These findings suggest that improving LLMs’ context awareness could lead to more human-like semantic understanding. The authors anticipate that the future research direction would be a broader range of model architectures and languages.
Key Takeaways#
Why does it matter?#
This paper is important as it reveals the inner workings of LLMs when processing scrambled text and highlights key differences between LLMs and human cognition. These insights can inform the development of more adaptable and context-aware LLMs, pushing the boundaries of natural language processing.
Visual Insights#
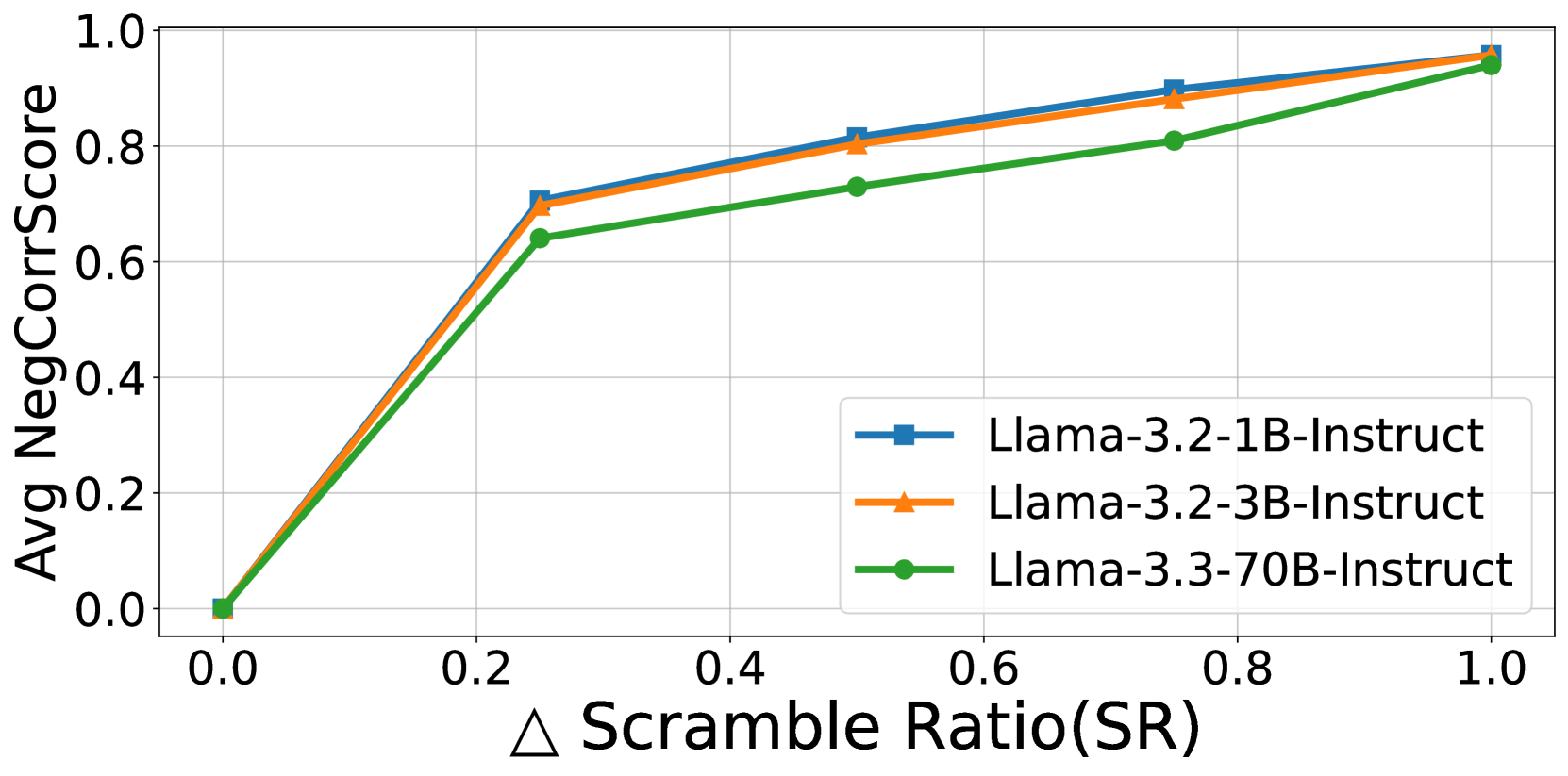
🔼 This figure illustrates the correlation between the increase in scrambling ratio (ΔSR) and the average negative correlation rate (NegCorrRate) across various LLaMA models. The x-axis represents the change in scrambling ratio (ΔSR), indicating the extent of character scrambling within words. The y-axis shows the average NegCorrRate, a metric reflecting the consistency of the model’s completion probability across different scrambling levels. The graph reveals a strong positive correlation: as the scrambling ratio increases, the NegCorrRate also increases. This demonstrates that SemRecScore (a metric used to quantify semantic reconstruction) is reliably associated with completion probability consistency and is a valid measure for semantic reconstruction. The different colored lines represent the results for different sized LLAMA models, indicating the trend holds across a range of model sizes.
read the caption
Figure 1: Relationship between ΔΔ\Deltaroman_ΔSR and Average NegCorrScore across LLaMA models of different scales. The increasing trend of NegCorrScore with ΔΔ\Deltaroman_ΔSR validates SemRecScore as a reliable measure of semantic reconstruction.
In-depth insights#
LLM Typoglycemia#
LLMs demonstrate resilience to scrambled words (Typoglycemia), but their mechanisms differ from humans. While humans adaptively balance word form and context, LLMs primarily rely on word form. LLMs possess specialized attention heads for processing word form, exhibiting a structured approach regardless of context. Further research could explore methods that can enhance LLM ability to incorporate human-like, context-aware mechanisms, which results in enhanced LLM performance.
SemRecScore Metric#
The study introduces a novel metric called SemRecScore to quantify the degree of semantic reconstruction in LLMs when processing scrambled words, a phenomenon known as Typoglycemia. This metric is crucial for understanding how LLMs internally handle and recover meaning from perturbed word forms. SemRecScore calculates the cosine similarity between the representation of the original word’s token and the representation of the final subword token of the scrambled word at each layer of the LLM. This layer-wise comparison allows for tracking the progressive recovery of word meaning across the network’s depth. The choice of cosine similarity is likely motivated by its ability to capture semantic relatedness in a vector space, where closer vectors indicate greater similarity. Furthermore, by focusing on the final subword token of the scrambled word, the metric aims to capture the most integrated semantic representation after the LLM has processed the fragmented input. The metric’s effectiveness is validated using Negative Correlation Rate, showing a link between the metric’s scores and the models’ ability to generate relevant completion.
Form vs. Context#
The interplay between form and context is a central theme in understanding language processing, whether by humans or machines. Word form, encompassing the visual or orthographic properties of a word, often serves as the initial access point for meaning. If the word form is degraded or unfamiliar, such as in cases of scrambled letters (typoglycemia), the reader relies more heavily on contextual information to infer the intended meaning. This context can include surrounding words, sentence structure, and broader discourse knowledge. In essence, there exists a dynamic interaction where the relative importance of form and context shifts based on the clarity and completeness of the available cues. While humans adaptively balance these two sources to maintain efficient comprehension even with noisy or incomplete input, large language models(LLMs) tend to rely on word form, but context is negligible for LLMs.
Attention Analysis#
Analyzing attention mechanisms offers a lens into how LLMs process information, particularly concerning word form and context. By dissecting attention weights, we can discern which parts of the input the model deems most relevant for semantic reconstruction. Attention heads specialized in processing word form might emerge, revealing a structured approach to leveraging form information. Understanding how attention shifts with varying degrees of scrambling and contextual integrity could uncover whether LLMs adaptively adjust their focus, or rely on fixed patterns. Comparing LLM attention strategies with human reading behavior may highlight key differences in how each handles scrambled words. This knowledge could inform methods to enhance LLM performance by incorporating more human-like context-aware mechanisms.
Fixed Attention#
Fixed attention mechanisms, in the context of neural networks and particularly transformers, refer to attention patterns that remain relatively stable regardless of input variations. This contrasts with adaptive attention, where attention weights dynamically adjust based on the specific relationships within the input data. A fixed attention might imply a pre-defined allocation of focus, potentially simplifying computation but also limiting the model’s ability to capture nuanced dependencies. This could arise from inherent architectural constraints, training biases, or a deliberate design choice to prioritize efficiency over maximal expressiveness. This could reveal insights into the inductive biases present within the model architecture or the training data. Understanding the conditions under which attention remains fixed, and the consequences for model performance, is crucial for both interpreting and improving these models.
More visual insights#
More on figures
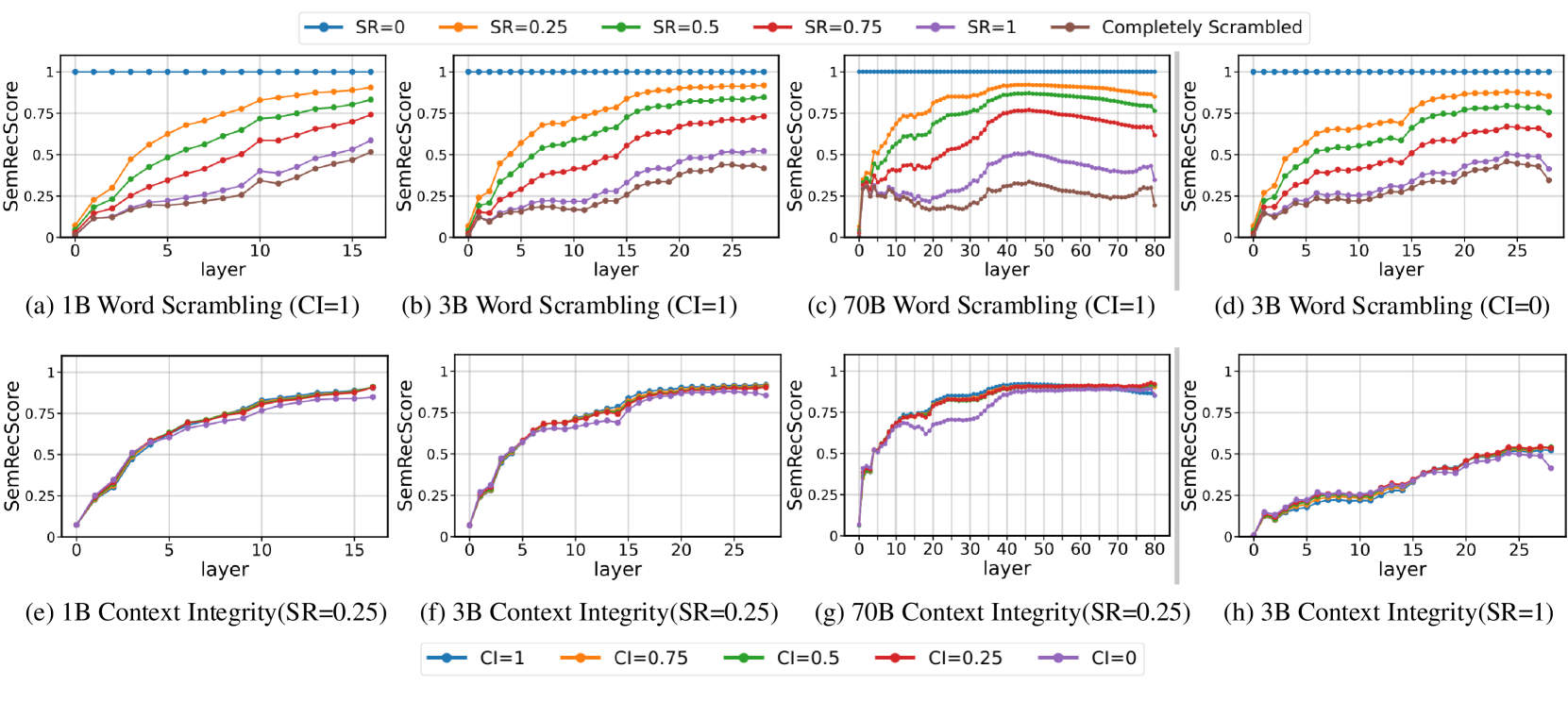
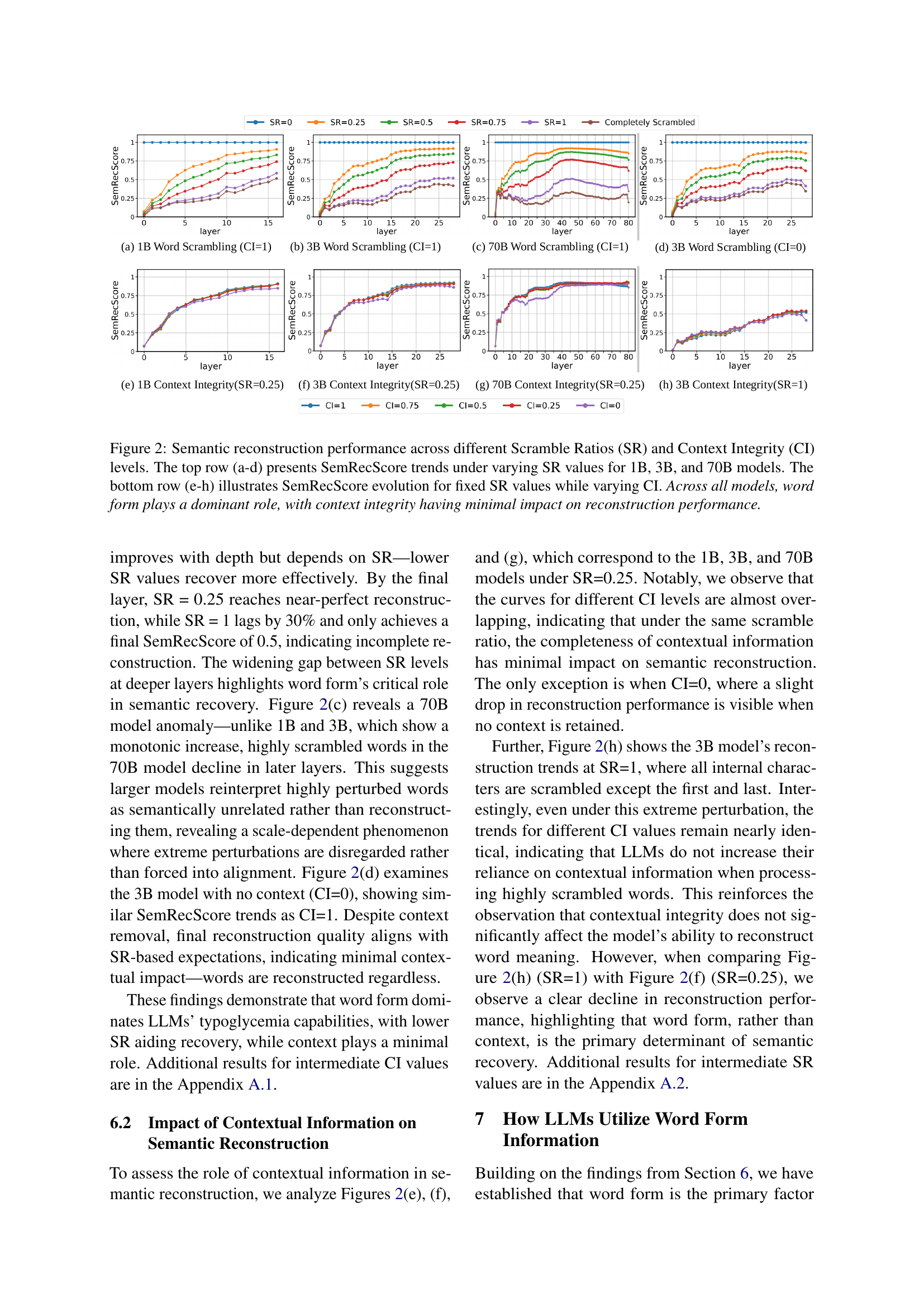
🔼 Figure 2 visualizes the performance of semantic reconstruction by LLMs (1B, 3B, and 70B parameter models) under varying levels of word scrambling (Scramble Ratio, SR) and contextual information (Context Integrity, CI). The top row displays the SemRecScore (a metric quantifying semantic reconstruction) across different SR levels for each model, holding CI constant at its highest value (CI=1). The bottom row shows the impact of varying CI levels on SemRecScore, while keeping SR constant (SR=0.25 and SR=1). This figure demonstrates that across all three models and varying CI conditions, word form is the primary driver of successful semantic reconstruction in the face of scrambled letters, with context playing a minimal role.
read the caption
Figure 2: Semantic reconstruction performance across different Scramble Ratios (SR) and Context Integrity (CI) levels. The top row (a-d) presents SemRecScore trends under varying SR values for 1B, 3B, and 70B models. The bottom row (e-h) illustrates SemRecScore evolution for fixed SR values while varying CI. Across all models, word form plays a dominant role, with context integrity having minimal impact on reconstruction performance.
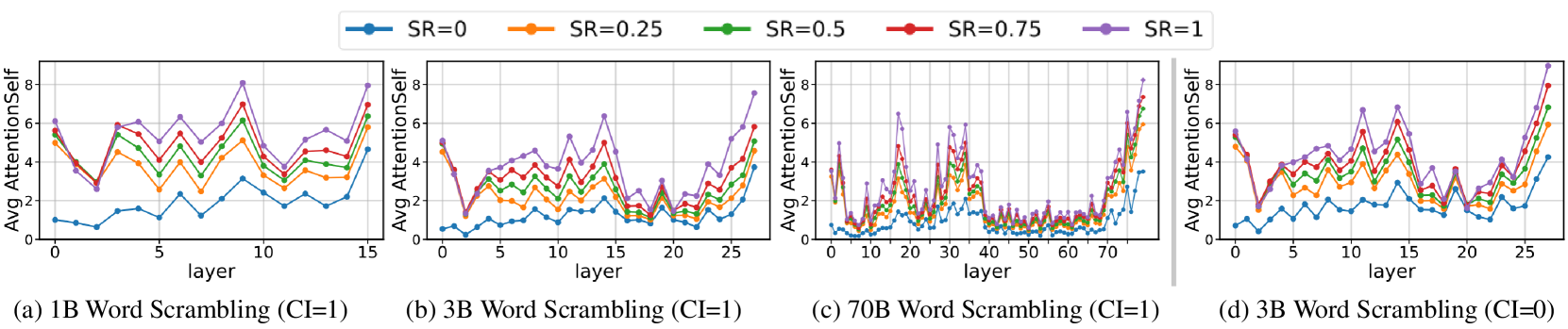
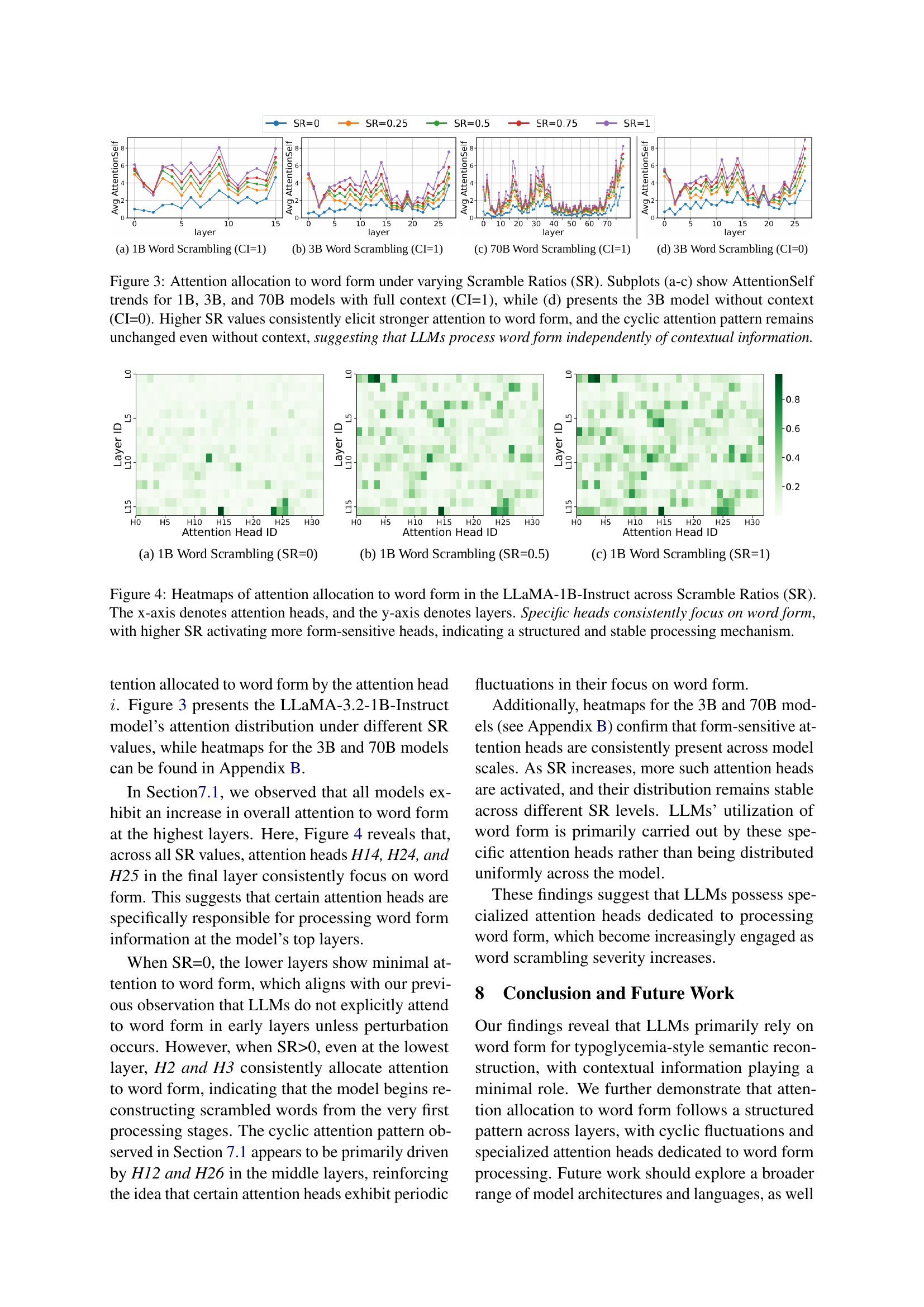
🔼 This figure displays the average AttentionSelf across all samples at each layer for different Scramble Ratios (SR) and model sizes. It shows how much attention the final token of a scrambled word gives to all other tokens in the same word, across different layers of the LLM. Subplots (a), (b), and (c) show the results for 1B, 3B, and 70B parameter models, respectively, all with complete contextual information (CI=1). Subplot (d) shows results for the 3B parameter model with no contextual information (CI=0). The key observation is that as the SR increases (meaning more scrambling), the AttentionSelf consistently increases across all layers and model sizes. Furthermore, a cyclic pattern in attention allocation is observed across layers. Critically, the similar cyclic pattern even in the absence of context (subplot (d)) indicates that LLMs focus on word form independently of context.
read the caption
Figure 3: Attention allocation to word form under varying Scramble Ratios (SR). Subplots (a-c) show AttentionSelf trends for 1B, 3B, and 70B models with full context (CI=1), while (d) presents the 3B model without context (CI=0). Higher SR values consistently elicit stronger attention to word form, and the cyclic attention pattern remains unchanged even without context, suggesting that LLMs process word form independently of contextual information.
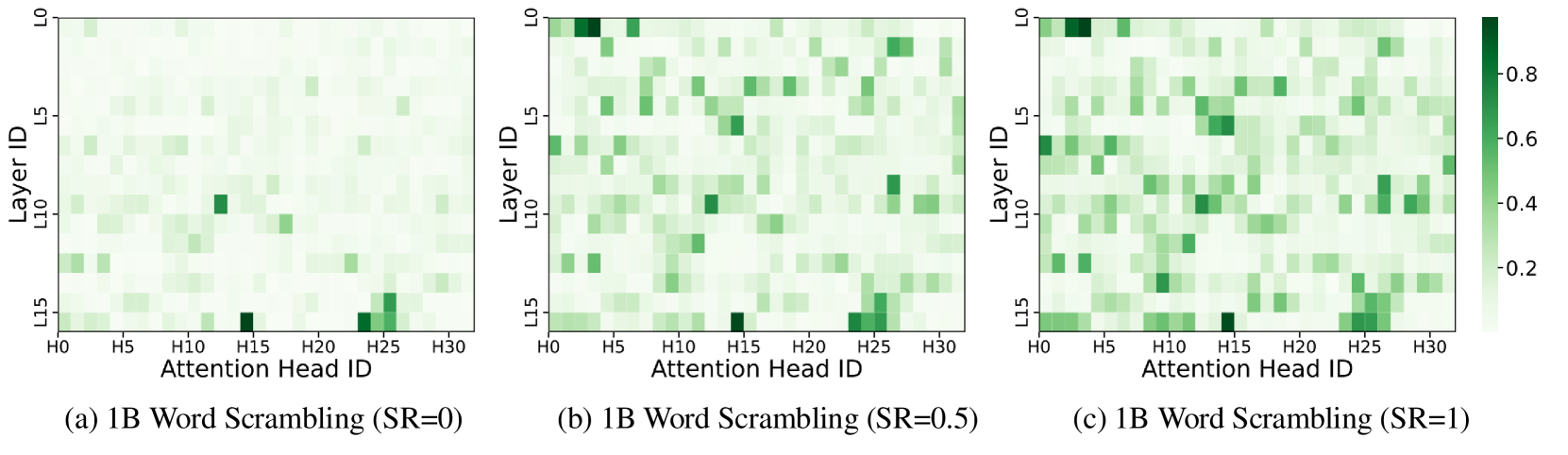
🔼 This figure visualizes how attention is allocated to word forms within the LLaMA-1B-Instruct language model under varying degrees of word scrambling (Scramble Ratio or SR). Each heatmap represents a different SR level (0, 0.5, and 1, indicating no scrambling, moderate scrambling, and extreme scrambling, respectively). The x-axis shows the different attention heads in the model, and the y-axis represents the layers of the model’s architecture. The color intensity of each cell in the heatmap indicates the strength of attention paid to the word form by a specific attention head at a particular layer. Brighter colors signify stronger attention. The figure demonstrates that certain attention heads consistently focus on word form regardless of the SR level, but a higher SR activates more of these specialized attention heads. This suggests a structured and stable mechanism within the model for processing word-form information, even when the words are significantly scrambled.
read the caption
Figure 4: Heatmaps of attention allocation to word form in the LLaMA-1B-Instruct across Scramble Ratios (SR). The x-axis denotes attention heads, and the y-axis denotes layers. Specific heads consistently focus on word form, with higher SR activating more form-sensitive heads, indicating a structured and stable processing mechanism.
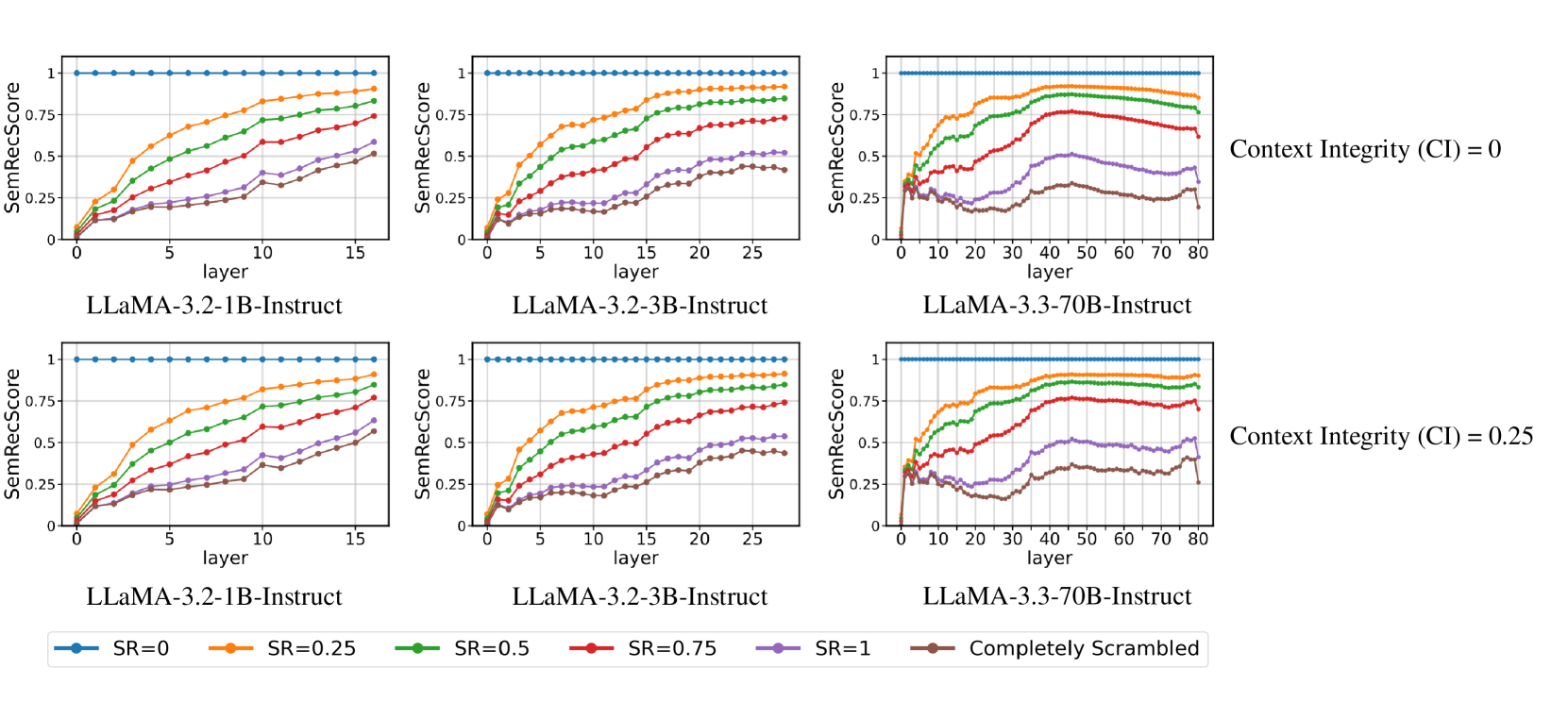
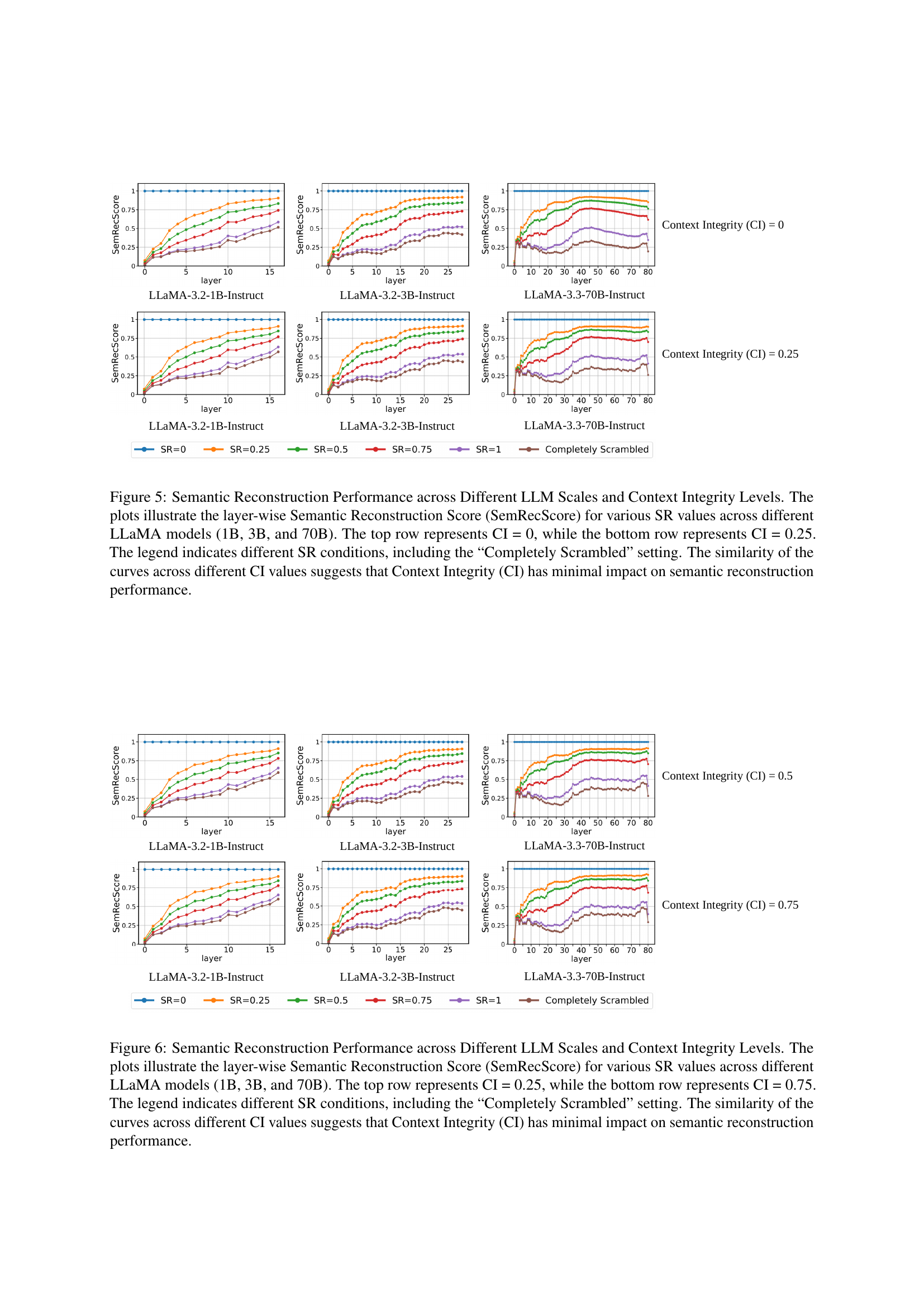
🔼 Figure 5 displays the layer-wise semantic reconstruction scores (SemRecScore) for different LLaMA models (1B, 3B, and 70B parameters) under varying levels of word scrambling (SR). The scores are shown for two levels of context integrity (CI): 0 and 0.25. Each plot shows how well the model reconstructs the meaning of a scrambled word across the different layers of the model. The consistent performance across different levels of CI, regardless of scrambling level, demonstrates that the amount of surrounding context has minimal effect on the model’s ability to reconstruct the meaning of a scrambled word.
read the caption
Figure 5: Semantic Reconstruction Performance across Different LLM Scales and Context Integrity Levels. The plots illustrate the layer-wise Semantic Reconstruction Score (SemRecScore) for various SR values across different LLaMA models (1B, 3B, and 70B). The top row represents CI = 0, while the bottom row represents CI = 0.25. The legend indicates different SR conditions, including the “Completely Scrambled” setting. The similarity of the curves across different CI values suggests that Context Integrity (CI) has minimal impact on semantic reconstruction performance.
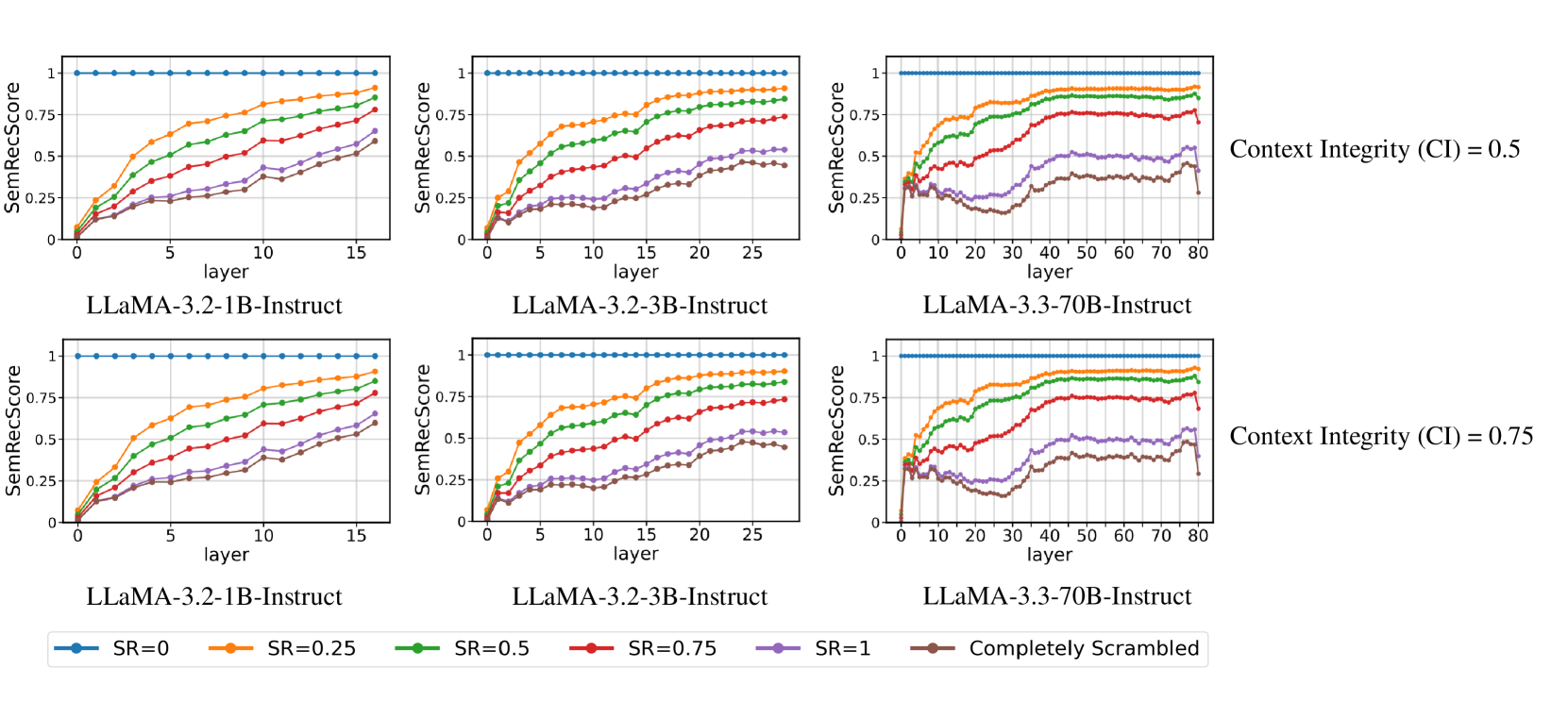
🔼 Figure 6 shows the impact of context on semantic reconstruction performance across different LLaMA model sizes (1B, 3B, and 70B parameters). It presents layer-wise Semantic Reconstruction Scores (SemRecScores) for various levels of word scrambling (Scramble Ratio, SR). Two rows show results for different levels of context integrity (CI): the top row for CI=0.25 and the bottom for CI=0.75. Across different levels of scrambling, the consistency of SemRecScore curves for various CI levels suggests that the amount of context has very little effect on the models’ ability to reconstruct the meaning of scrambled words. Word form is the primary determinant of performance.
read the caption
Figure 6: Semantic Reconstruction Performance across Different LLM Scales and Context Integrity Levels. The plots illustrate the layer-wise Semantic Reconstruction Score (SemRecScore) for various SR values across different LLaMA models (1B, 3B, and 70B). The top row represents CI = 0.25, while the bottom row represents CI = 0.75. The legend indicates different SR conditions, including the “Completely Scrambled” setting. The similarity of the curves across different CI values suggests that Context Integrity (CI) has minimal impact on semantic reconstruction performance.

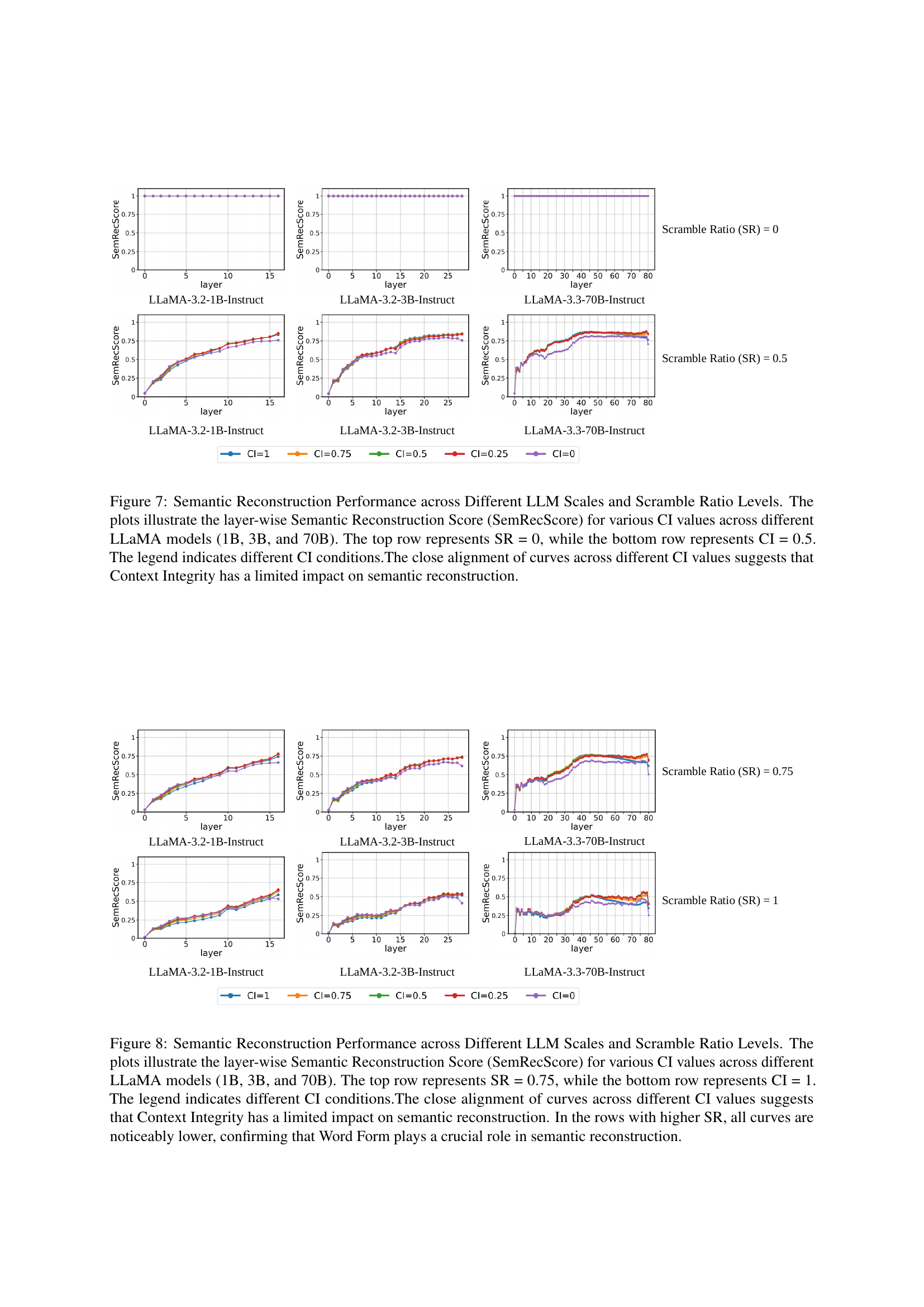
🔼 Figure 7 displays the semantic reconstruction performance of LLMs (LLaMA 1B, 3B, and 70B) across different context integrity (CI) levels and scramble ratios (SR). The plots show the layer-wise SemRecScore for each model, illustrating how well the models reconstruct the original word meaning from scrambled versions. The top row shows the performance when there is no word scrambling (SR=0), and the bottom row demonstrates performance when CI is 0.5. The legend clarifies the different CI levels used in the experiment. The results indicate that variations in CI have minimal effect on semantic reconstruction, implying that word form plays a more significant role than context in LLMs’ ability to process scrambled text.
read the caption
Figure 7: Semantic Reconstruction Performance across Different LLM Scales and Scramble Ratio Levels. The plots illustrate the layer-wise Semantic Reconstruction Score (SemRecScore) for various CI values across different LLaMA models (1B, 3B, and 70B). The top row represents SR = 0, while the bottom row represents CI = 0.5. The legend indicates different CI conditions.The close alignment of curves across different CI values suggests that Context Integrity has a limited impact on semantic reconstruction.
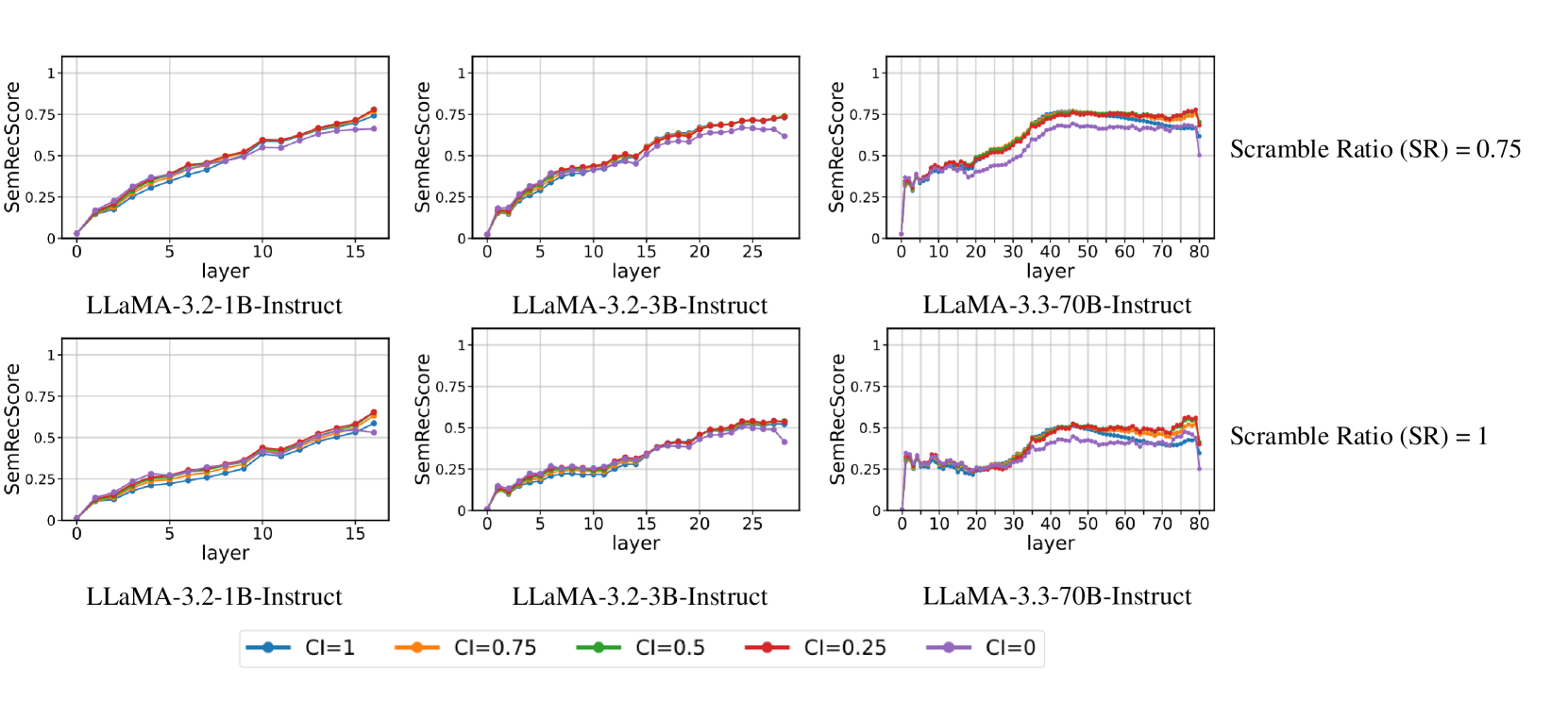
🔼 Figure 8 displays the results of an experiment evaluating the impact of word form and context on semantic reconstruction using three different sizes of the LLaMA language model. The experiment manipulated the Scramble Ratio (SR), representing the degree of letter scrambling within words, and Context Integrity (CI), indicating the amount of surrounding context. The figure plots the Semantic Reconstruction Score (SemRecScore) across different layers of each model. The top row shows results with a Scramble Ratio of 0.75, while the bottom row presents results when the context is complete (CI=1). The close similarity of lines within each row (different CI levels) demonstrates the minor effect of context on semantic reconstruction. The noticeably lower SemRecScores in the higher SR rows highlight the crucial role of word form in the model’s ability to reconstruct the meaning of scrambled words.
read the caption
Figure 8: Semantic Reconstruction Performance across Different LLM Scales and Scramble Ratio Levels. The plots illustrate the layer-wise Semantic Reconstruction Score (SemRecScore) for various CI values across different LLaMA models (1B, 3B, and 70B). The top row represents SR = 0.75, while the bottom row represents CI = 1. The legend indicates different CI conditions.The close alignment of curves across different CI values suggests that Context Integrity has a limited impact on semantic reconstruction. In the rows with higher SR, all curves are noticeably lower, confirming that Word Form plays a crucial role in semantic reconstruction.
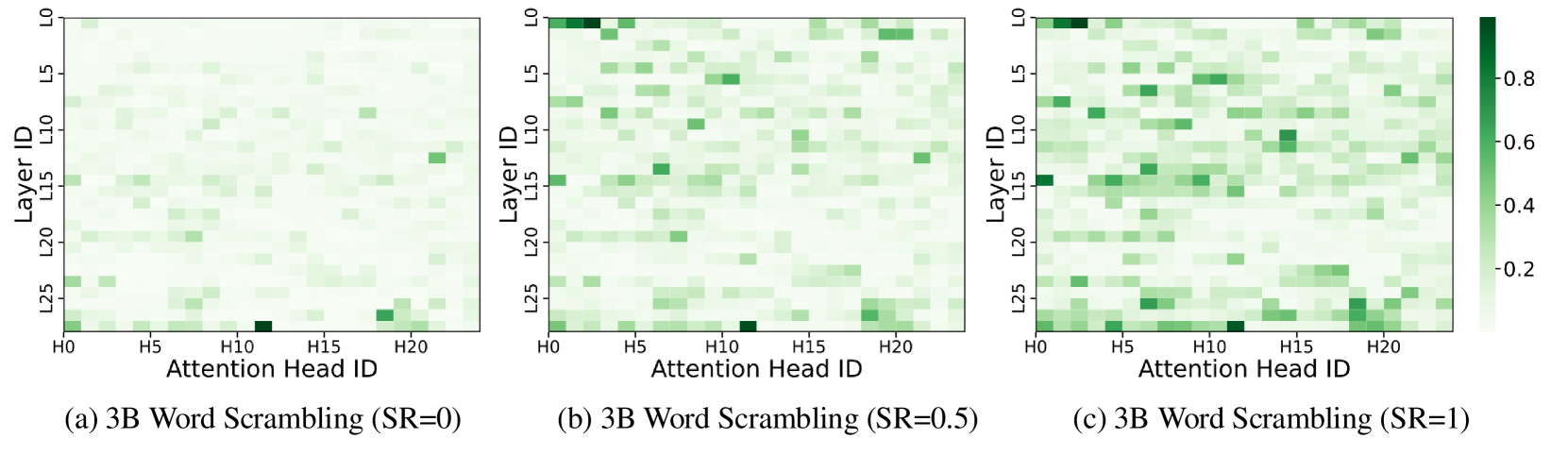
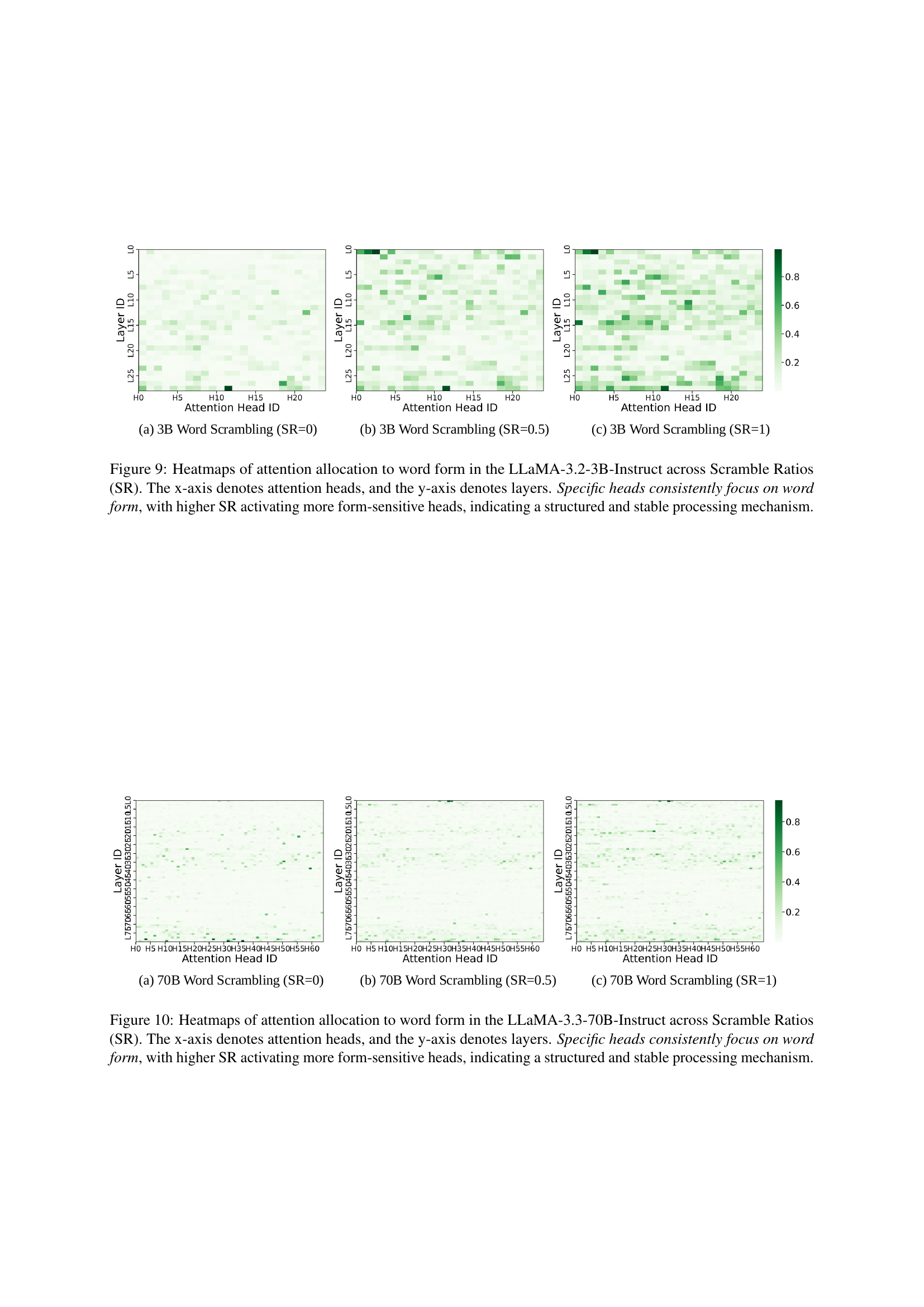
🔼 This figure displays heatmaps visualizing how attention is distributed across different attention heads within the LLaMA-3.2-3B-Instruct model when processing words with varying degrees of character scrambling (Scramble Ratio or SR). Each heatmap represents a different SR level (0, 0.5, and 1, indicating no scrambling, moderate scrambling, and extreme scrambling, respectively). The x-axis represents the attention heads, while the y-axis shows the layers of the model. The color intensity of each cell indicates the magnitude of attention allocated to word-form features by that specific attention head at that layer. The heatmaps show that certain attention heads consistently focus on word-form information across all SR levels. Furthermore, as the SR increases (more scrambling), more attention heads become dedicated to processing word-form information, suggesting a structured and consistent mechanism for handling word-form processing even under significant disruption.
read the caption
Figure 9: Heatmaps of attention allocation to word form in the LLaMA-3.2-3B-Instruct across Scramble Ratios (SR). The x-axis denotes attention heads, and the y-axis denotes layers. Specific heads consistently focus on word form, with higher SR activating more form-sensitive heads, indicating a structured and stable processing mechanism.
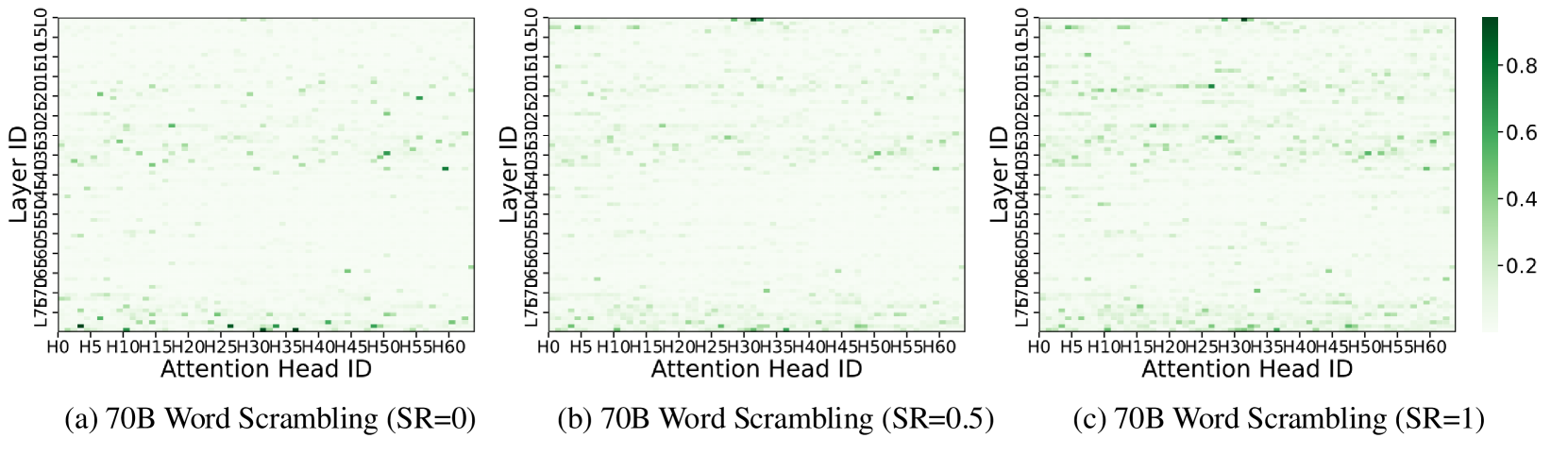
🔼 This figure visualizes how attention is distributed across different attention heads within the LLaMA-3.3-70B-Instruct language model when processing words with varying degrees of character scrambling (Scramble Ratio, SR). The heatmaps show the attention weight assigned by each attention head to each token in a scrambled word across different layers of the model. Warmer colors indicate higher attention weights. The consistent patterns observed across different SR levels demonstrate that specific attention heads consistently focus on word form information, even as the level of scrambling increases. This illustrates a structured and stable processing mechanism within the LLM where certain heads are specialized for handling word form regardless of the degree of perturbation.
read the caption
Figure 10: Heatmaps of attention allocation to word form in the LLaMA-3.3-70B-Instruct across Scramble Ratios (SR). The x-axis denotes attention heads, and the y-axis denotes layers. Specific heads consistently focus on word form, with higher SR activating more form-sensitive heads, indicating a structured and stable processing mechanism.
Full paper#