TL;DR#
The paper addresses the challenge of creating powerful yet compact multimodal models. Existing multimodal models are large and difficult to deploy on resource-constrained devices and often require fine-tuning the base language model, reducing original language capabilities. Phi-4-Multimodal aims to solve these problems by unifying text, vision and audio into a single model.
Phi-4-Multimodal introduces a novel “mixture of LoRAs” technique to achieve multimodal capabilities without modifying the base language model. It has modality-specific LoRA adapters and encoders allowing efficient handling of vision and audio inputs. The model supports several tasks such as QA, summarization, and translation, outperforming larger models in a range of benchmarks.
Key Takeaways#
Why does it matter?#
This paper introduces efficient multimodal models, crucial for advancing AI in resource-constrained environments. By leveraging LoRA techniques, it sets a new benchmark for integrating diverse data types, paving the way for future research on scalable and versatile AI systems. The findings enable new applications on edge devices.
Visual Insights#
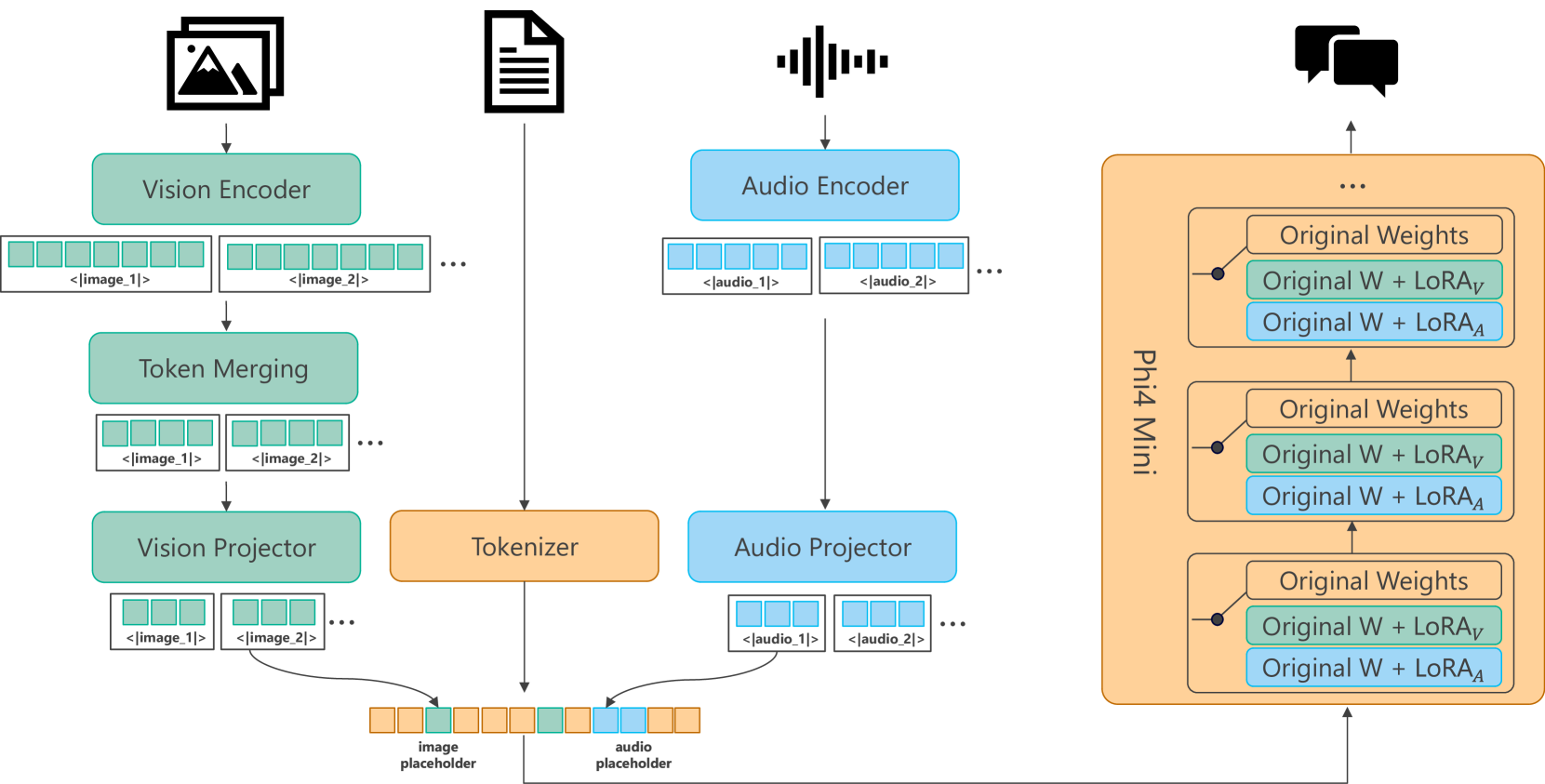
🔼 Phi-4-Multimodal is a unified multimodal model that processes multiple input modalities (text, vision, audio/speech) simultaneously. The architecture uses a frozen language model (Phi-4-Mini) as its base. Modality-specific encoders (vision, audio) project their respective features to the language model’s embedding space. LoRA adapters are applied to the language decoder to adapt to the different modalities, allowing seamless integration of modalities. This approach ensures that the language model is only adapted and is not fine-tuned, thereby maintaining original language model performance.
read the caption
Figure 1: A overview of the Multimodal architecture for Phi-4-Multimodal
| Phi-4-Multimodal | WhisperV3 | SeamlessM4T-V2 | Qwen2-audio | Gemini- | GPT-4o | |||
| Task | Metric | Dataset | 5.6B | 1.5B | 2.3B | 8B | 2.0-Flash | - |
| ASR | WER | CV15 | 6.80 | 8.13 | 8.46 | 8.55 | 9.29 | 18.14 |
| FLEURS | 4.00 | 4.58 | 7.34 | 8.28 | 4.73 | 5.42 | ||
| OpenASR | 6.14 | 7.44 | 20.70 | 7.43 | 8.56 | 15.76 | ||
| AST | BLEU | Inference Type | (0-shot, CoT) | 0-shot | 0-shot | 0-shot | 0-shot | 0-shot |
| CoVoST2 X-EN | (39.33, 40.76) | 33.26 | 37.54 | 34.80 | 36.62 | 37.09 | ||
| CoVoST2 EN-X | (37.82, 38.73) | N/A | 32.84 | 34.04 | 35.93 | 37.19 | ||
| FLEURS X-EN | (29.86, 32.35) | 25.76 | 28.87 | 23.72 | 30.69 | 32.61 | ||
| FLEURS EN-X | (32.15, 33.56) | N/A | 30.44 | 23.24 | 37.33 | 36.78 | ||
| SQQA | Score 1-10 | MT-Bench | 7.05 | N/A | N/A | 4.92 | 8.07 | 8.11 |
| ACC | MMMLU | 38.50 | N/A | N/A | 15.53 | 72.31 | 72.56 | |
| SSUM | Score 1-7 | Golden3 | 6.28 | N/A | N/A | 2.25 | 6.29 | 6.76 |
| AMI | 6.29 | N/A | N/A | 1.34 | 5.97 | 6.53 | ||
| AU | Score 1-10 | AirBench-chat | 6.98 | N/A | N/A | 6.93 | 6.68 | 6.54 |
| ACC | MMAU | 55.56 | N/A | N/A | 52.50 | 61.23 | 53.29 |
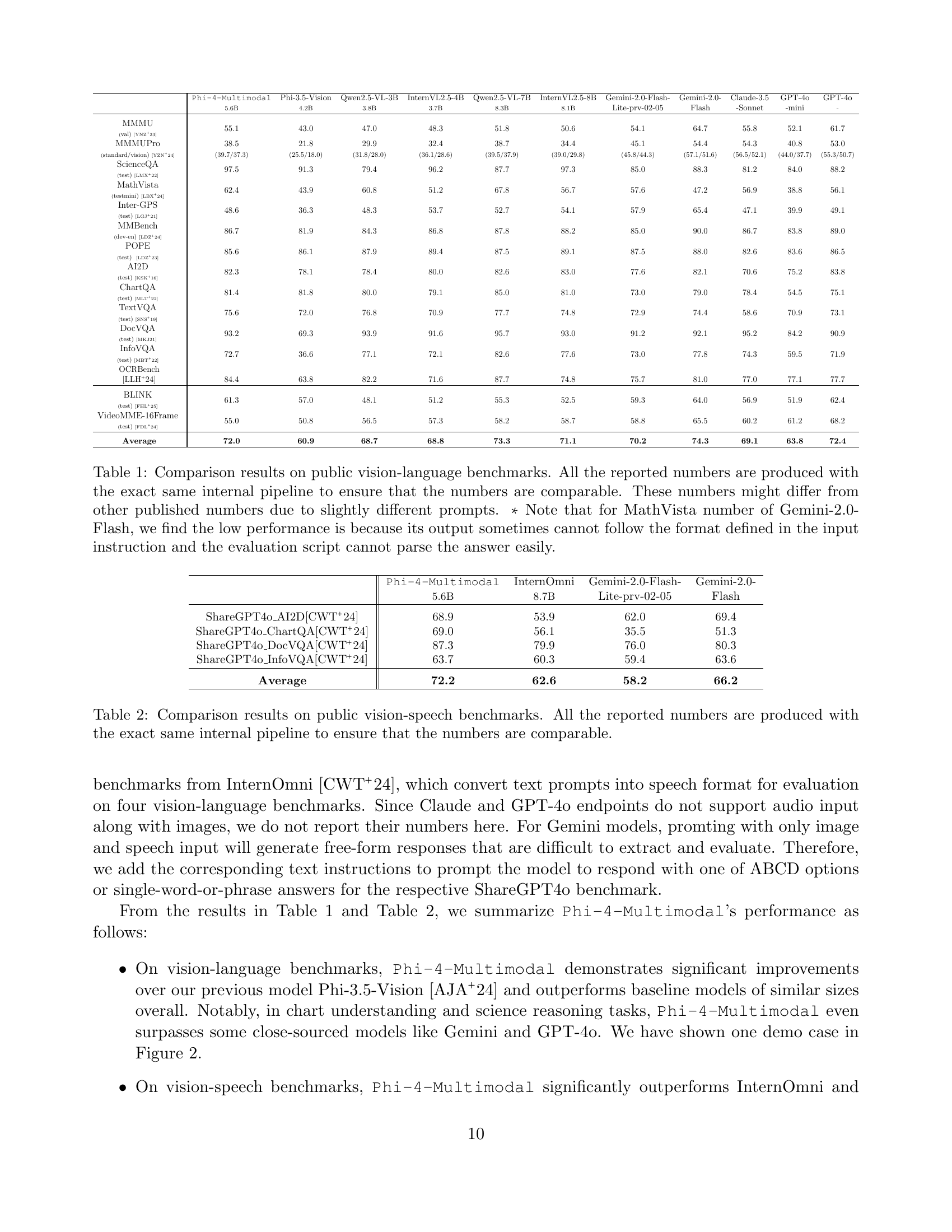
🔼 This table presents a comparison of the performance of Phi-4-Multimodal and other state-of-the-art vision-language models across thirteen public benchmarks. The benchmarks evaluate various aspects of vision-language understanding, including reasoning and perception capabilities. All results were obtained using the same internal evaluation pipeline to ensure fair comparison. Minor discrepancies with previously published results might be attributed to differences in prompt phrasing. A notable exception is the relatively low performance of Gemini-2.0-Flash on the MathVista benchmark; this is attributed to the model’s inability to consistently adhere to the specified output format, thus rendering the evaluation results unreliable.
read the caption
Table 1: Comparison results on public vision-language benchmarks. All the reported numbers are produced with the exact same internal pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different prompts. ∗*∗ Note that for MathVista number of Gemini-2.0-Flash, we find the low performance is because its output sometimes cannot follow the format defined in the input instruction and the evaluation script cannot parse the answer easily.
In-depth insights#
LoRA Mixture SLM#
The concept of a LoRA (Low-Rank Adaptation) Mixture SLM (Small Language Model) presents a compelling approach to enhancing multimodal capabilities within resource constraints. By employing a “mixture of LoRAs,” the model can integrate modality-specific adaptations while keeping the base language model frozen. This contrasts with full fine-tuning, which can diminish original language prowess. This mixture of LoRAs enables a nuanced approach, offering a path to balance multimodal competence without compromising the core language model’s established abilities. Crucially, it promotes modularity, allowing seamless integration of new modalities via additional LoRAs without disrupting existing functionalities. This modular design contrasts with cross-attention mechanisms, offering a novel trade-off between performance and flexibility, and presents a new path for the community while achieving minimal performance loss on multimodal benchmarks compared to fully fine-tuned baselines. The mixture of LoRAs enables handling multiple inference modes combining various modalities without interference.
Vision-Speech SOTA#
Vision-Speech SOTA models represent a frontier in multimodal AI, seamlessly integrating visual and auditory information. These models aim to understand scenes and events by processing both what is seen and heard, leading to enhanced performance in tasks like activity recognition, scene understanding, and human-computer interaction. The core challenge lies in effectively fusing these disparate modalities, capturing the complex correlations between visual cues and corresponding sounds. Recent advancements leverage deep learning architectures, particularly transformers, to achieve state-of-the-art results. Key research areas include developing novel fusion mechanisms, addressing the temporal alignment of vision and speech, and improving robustness to noisy or ambiguous inputs. Datasets for vision-speech tasks are becoming increasingly large and diverse, facilitating the training of more capable models. However, significant challenges remain in creating models that generalize well across different environments and exhibit robust performance under real-world conditions. The success of vision-speech models hinges on their ability to capture both fine-grained details and high-level contextual information from both modalities, ultimately creating a holistic understanding of the world.
Enhanced Reason#
The ‘Enhanced Reasoning’ section likely details how the model’s capacity for logical deduction, problem-solving, and knowledge application has been improved. It probably involves training techniques, architectural augmentations, or data enhancements specifically designed to bolster reasoning skills. A crucial aspect would be the model’s performance on tasks demanding multi-step inference or abstract concept manipulation. Key metrics probably include accuracy on benchmarks that assess common-sense reasoning, mathematical problem-solving, or symbolic reasoning. The section would need to demonstrate how the changes impact the model’s ability to extrapolate and generalize beyond the training data.
Dynamic MultiCrop#
Dynamic MultiCrop strategies are crucial for handling varying resolutions in visual inputs. The technique allows models to efficiently process images with diverse aspect ratios without excessive resizing that could distort features. A key benefit is adaptability, enabling the model to dynamically adjust the number and size of crops based on the input image’s dimensions. This maximizes information retention while minimizing computational overhead. Effective multi-crop avoids simply upscaling small images or downscaling large ones to maintain a consistent input size. Instead, it smartly divides the image to capture crucial details from high-resolution inputs and prevents over-expansion of smaller images, thereby preserving their inherent characteristics. Careful implementation improves overall performance in tasks requiring detailed visual understanding.
Multi Tier1 Safety#
Multi-Tier 1 Safety in AI development emphasizes a comprehensive risk mitigation approach, addressing harmful content generation across languages. This involves employing datasets to enhance model helpfulness and harmlessness, conducting red-teaming to uncover vulnerabilities, and performing systematic safety evaluations. The goal is to reduce toxicity in AI responses across violence, sexual content, self-harm, and hate speech. It is crucial to balance safety with utility, preventing over-cautious refusals of innocuous prompts. This often entails fine-tuning to improve model robustness against jailbreaks, and focusing on fairness to ensure equitable performance across demographics. The success hinges on creating a safe and valuable AI experience.
More visual insights#
More on figures

🔼 Figure 2 presents a demonstration of Phi-4-Multimodal’s capabilities in understanding and reasoning with vision and language. The example shows a chart depicting the percentage of people across various generations using AI tools at work, and the model correctly answers a question based on this chart. This showcases the model’s ability to process visual data along with text inputs, demonstrating its multimodal understanding and reasoning skills.
read the caption
Figure 2: One demo case to show the vision-language understanding and reasoning capability of Phi-4-Multimodal.

🔼 Figure 3 presents a comprehensive example illustrating the multimodal capabilities of Phi-4-Multimodal. It showcases the model’s ability to process audio input, perform automatic speech recognition (ASR) to transcribe the audio into text, and then automatic speech translation (AST) to translate the audio into another language. Further, the figure displays the model’s capacity for summarization by generating a concise summary of the conversation contained within the audio clip. This example highlights Phi-4-Multimodal’s proficiency in handling multiple modalities simultaneously and delivering coherent, insightful responses.
read the caption
Figure 3: An example to showcase the understanding capabilities for Phi-4-Multimodal, including audio understanding, summarization, ASR, and AST.
More on tables
| Phi-4-Multimodal | nvidia/canary | WhisperV3 | SeamlessM4T-V2 | Qwen2-audio | Gemini- | GPT-4o | ||
| Dataset | Sub-Category | 5.6B | 1B | 1.5B | 2.3B | 8B | 2.0-Flash | - |
| CV15 | EN | 7.61 | N/A | 9.30 | 7.65 | 8.68 | 11.21 | 21.48 |
| DE | 5.13 | N/A | 5.70 | 6.43 | 7.61 | 6.2 | 10.91 | |
| ES | 4.47 | N/A | 4.70 | 5.42 | 5.71 | 4.81 | 11.24 | |
| FR | 8.08 | N/A | 10.80 | 9.75 | 9.57 | 10.45 | 17.63 | |
| IT | 3.78 | N/A | 5.50 | 5.50 | 6.78 | 4.88 | 13.84 | |
| JA | 10.98 | N/A | 10.30 | 12.37 | 13.55 | 13.46 | 19.36 | |
| PT | 6.97 | N/A | 5.90 | 9.19 | 10.03 | 7.4 | 23.07 | |
| ZH | 7.35 | N/A | 12.80 | 11.36 | 6.47 | 15.87 | 27.55 | |
| Average | 6.80 | N/A | 8.13 | 8.46 | 8.55 | 9.29 | 18.14 | |
| FLEURS | EN | 3.38 | N/A | 4.10 | 6.54 | 5.27 | 3.96 | 6.52 |
| DE | 3.96 | N/A | 4.90 | 6.95 | 8.77 | 4.06 | 4.17 | |
| ES | 3.02 | N/A | 2.80 | 5.39 | 6.90 | 2.61 | 3.69 | |
| FR | 4.35 | N/A | 5.30 | 7.40 | 9.00 | 5.06 | 6.42 | |
| IT | 1.98 | N/A | 3.00 | 4.70 | 5.78 | 1.86 | 3.28 | |
| JA | 4.50 | N/A | 4.80 | 11.47 | 12.68 | 4.94 | 5.18 | |
| PT | 3.98 | N/A | 4.00 | 7.67 | 10.59 | 3.57 | 6.33 | |
| ZH | 6.83 | N/A | 7.70 | 8.6 | 7.21 | 11.74 | 7.77 | |
| Average | 4.00 | N/A | 4.58 | 7.34 | 8.28 | 4.73 | 5.42 | |
| OpenASR | AMI | 11.69 | 13.90 | 15.95 | 56.1 | 15.24 | 21.58 | 57.76 |
| Earnings22 | 10.16 | 12.19 | 11.29 | 37.18 | 14.09 | 13.13 | 20.94 | |
| Gigaspeech | 9.78 | 10.12 | 10.02 | 26.22 | 10.26 | 10.71 | 13.64 | |
| Spgispeech | 3.13 | 2.06 | 2.01 | 12.04 | 3.00 | 3.82 | 5.66 | |
| Tedlium | 2.90 | 3.56 | 3.91 | 19.26 | 4.05 | 3.01 | 5.79 | |
| LS-clean | 1.68 | 1.48 | 2.94 | 2.60 | 1.74 | 2.49 | 3.48 | |
| LS-other | 3.83 | 2.93 | 3.86 | 4.86 | 4.03 | 5.84 | 7.97 | |
| Voxpopuli | 5.91 | 5.79 | 9.54 | 7.37 | 7.05 | 7.89 | 10.83 | |
| Average | 6.14 | 6.50 | 7.44 | 20.70 | 7.43 | 8.56 | 15.76 |
🔼 This table presents a comparison of the performance of Phi-4-Multimodal against several other vision-speech models on publicly available benchmark datasets. The results are directly comparable because the same internal evaluation pipeline was used for all models. The table shows that Phi-4-Multimodal performs competitively, often outperforming larger models.
read the caption
Table 2: Comparison results on public vision-speech benchmarks. All the reported numbers are produced with the exact same internal pipeline to ensure that the numbers are comparable.
| Phi-4-Multimodal | (CoT) | WhisperV3 | SeamlessM4T-V2 | Qwen2-audio | Gemini- | GPT-4o | ||
| Dataset | Sub-Category | 5.6B | 1.5B | 2.3B | 8B | 2.0-Flash | - | |
| CoVoST2 X-EN | DE | 39.81 | 40.83 | 34.17 | 39.90 | 34.99 | 38.34 | 39.29 |
| ES | 43.60 | 44.84 | 39.21 | 42.90 | 39.91 | 41.74 | 41.49 | |
| FR | 42.24 | 43.42 | 35.43 | 42.18 | 38.31 | 38.96 | 38.56 | |
| IT | 41.42 | 42.45 | 35.82 | 39.85 | 36.35 | 37.76 | 37.33 | |
| JA | 30.54 | 31.87 | 23.59 | 22.18 | 22.98 | 28.04 | 30.46 | |
| PT | 55.28 | 56.25 | 50.22 | 53.82 | 47.79 | 50.81 | 50.60 | |
| ZH | 22.39 | 25.64 | 14.36 | 21.92 | 23.27 | 20.69 | 21.93 | |
| Average | 39.33 | 40.76 | 33.26 | 37.54 | 34.8 | 36.62 | 37.09 | |
| CoVoST2 EN-X | DE | 34.22 | 34.87 | N/A | 37.16 | 29.72 | 34.32 | 34.38 |
| JA | 32.93 | 34.04 | N/A | 24.94 | 27.30 | 32.56 | 32.98 | |
| ZH | 46.30 | 47.28 | N/A | 36.41 | 45.09 | 40.91 | 44.22 | |
| Average | 37.82 | 38.73 | N/A | 32.84 | 34.04 | 35.93 | 37.19 | |
| FLEURS X-EN | DE | 37.71 | 39.43 | 33.49 | 36.80 | 32.88 | 38.48 | 41.03 |
| ES | 25.33 | 27.56 | 22.68 | 25.67 | 22.40 | 26.51 | 29.10 | |
| FR | 35.10 | 37.42 | 30.98 | 33.78 | 30.82 | 35.18 | 37.98 | |
| IT | 26.06 | 28.45 | 23.00 | 26.80 | 22.12 | 25.02 | 28.51 | |
| JA | 21.62 | 25.22 | 16.63 | 18.63 | 4.49 | 23.89 | 24.17 | |
| PT | 40.80 | 42.85 | 37.50 | 37.61 | 35.38 | 41.51 | 43.33 | |
| ZH | 22.37 | 25.49 | 16.07 | 22.78 | 17.95 | 24.27 | 24.12 | |
| Average | 29.86 | 32.35 | 25.76 | 28.87 | 23.72 | 30.69 | 32.61 | |
| FLEURS EN-X | DE | 34.44 | 35.94 | N/A | 32.35 | 23.60 | 37.15 | 36.68 |
| ES | 23.66 | 25.09 | N/A | 23.37 | 19.47 | 26.40 | 25.99 | |
| FR | 37.92 | 40.12 | N/A | 42.08 | 27.71 | 46.51 | 44.26 | |
| IT | 23.44 | 24.85 | N/A | 24.55 | 19.61 | 29.04 | 28.59 | |
| JA | 30.67 | 30.81 | N/A | 20.46 | 12.38 | 35.51 | 33.99 | |
| PT | 37.79 | 38.94 | N/A | 42.36 | 32.52 | 45.34 | 45.82 | |
| ZH | 37.10 | 39.19 | N/A | 27.93 | 27.38 | 41.36 | 42.16 | |
| Average | 32.15 | 33.56 | N/A | 30.44 | 23.24 | 37.33 | 36.78 | |
🔼 This table presents the performance of Phi-4-Multimodal and several other models on various speech benchmarks. It includes results for automatic speech recognition (ASR), automatic speech translation (AST), spoken query question answering (SQQA), speech summarization (SSUM), and audio understanding (AU). The evaluation methods vary by task, using zero-shot, chain-of-thought (CoT), and multi-turn conversation approaches. The scores are evaluated and ranked by GPT-4-0613. ‘N/A’ means the model doesn’t support that specific task.
read the caption
Table 3: Main Results on the speech benchmarks. All results are obtained with 0-shot evaluations except additional CoT evaluations on the AST task, where CoT refers to chain-of-thoughts decoding with transcription plus translation in generation. MT-Bench results are averaged scores over two-turn SQA conversations. SSUM evaluation is with the overall numbers covering the adherence and hallucination scores. The scores in the table are judged by GPT-4-0613. N/A indicates the model does not have such a capability.
| Phi-4-Multimodal | Qwen2-audio | Gemini- | GPT-4o | ||||
| Task | Metric | Dataset | Sub-Category | 5.6B | 8B | 2.0-Flash | - |
| SQQA | Score 1-10 | MT-Bench | turn-1 | 7.42 | 5.07 | 8.08 | 8.27 |
| turn-2 | 6.67 | 4.76 | 8.06 | 7.94 | |||
| AVG | 7.05 | 4.92 | 8.07 | 8.11 | |||
| ACC | MMMLU | EN | 54.25 | 16.00 | 74.00 | 78.75 | |
| DE | 39.50 | 10.50 | 78.75 | 73.70 | |||
| ES | 42.25 | 25.00 | 75.75 | 78.32 | |||
| FR | 38.50 | 19.25 | 74.25 | 76.21 | |||
| IT | 35.00 | 18.50 | 70.50 | 71.84 | |||
| JA | 30.00 | 14.25 | 68.75 | 67.40 | |||
| PT | 34.00 | 11.25 | 70.50 | 70.48 | |||
| ZH | 34.50 | 9.50 | 66.00 | 63.77 | |||
| AVG | 38.50 | 15.53 | 72.31 | 72.56 | |||
| SSUM | Score 1-7 | Golden3 | Hallucination | 0.14 | 0.51 | 0.20 | 0.09 |
| Instruction adherence | 5.87 | 2.64 | 6.25 | 6.73 | |||
| Overall | 6.28 | 2.25 | 6.29 | 6.76 | |||
| AMI | Hallucination | 0.13 | 0.96 | 0.28 | 0.10 | ||
| Instruction adherence | 6.50 | 1.40 | 6.25 | 6.83 | |||
| Overall | 6.29 | 1.34 | 5.97 | 6.53 | |||
| AU | Score 1-10 | AirBench-chat | mixed | 6.78 | 6.77 | 6.84 | 6.00 |
| music | 6.67 | 6.79 | 6.33 | 5.55 | |||
| sound | 7.00 | 6.99 | 5.62 | 7.45 | |||
| speech | 7.47 | 7.18 | 7.92 | 7.17 | |||
| AVG | 6.98 | 6.93 | 6.68 | 6.54 | |||
| ACC | MMAU | music | 52.87 | 53.26 | 58.33 | 55.27 | |
| sound | 60.97 | 58.34 | 62.60 | 48.30 | |||
| speech | 52.83 | 45.90 | 62.77 | 56.30 | |||
| AVG | 55.56 | 52.50 | 61.23 | 53.29 |
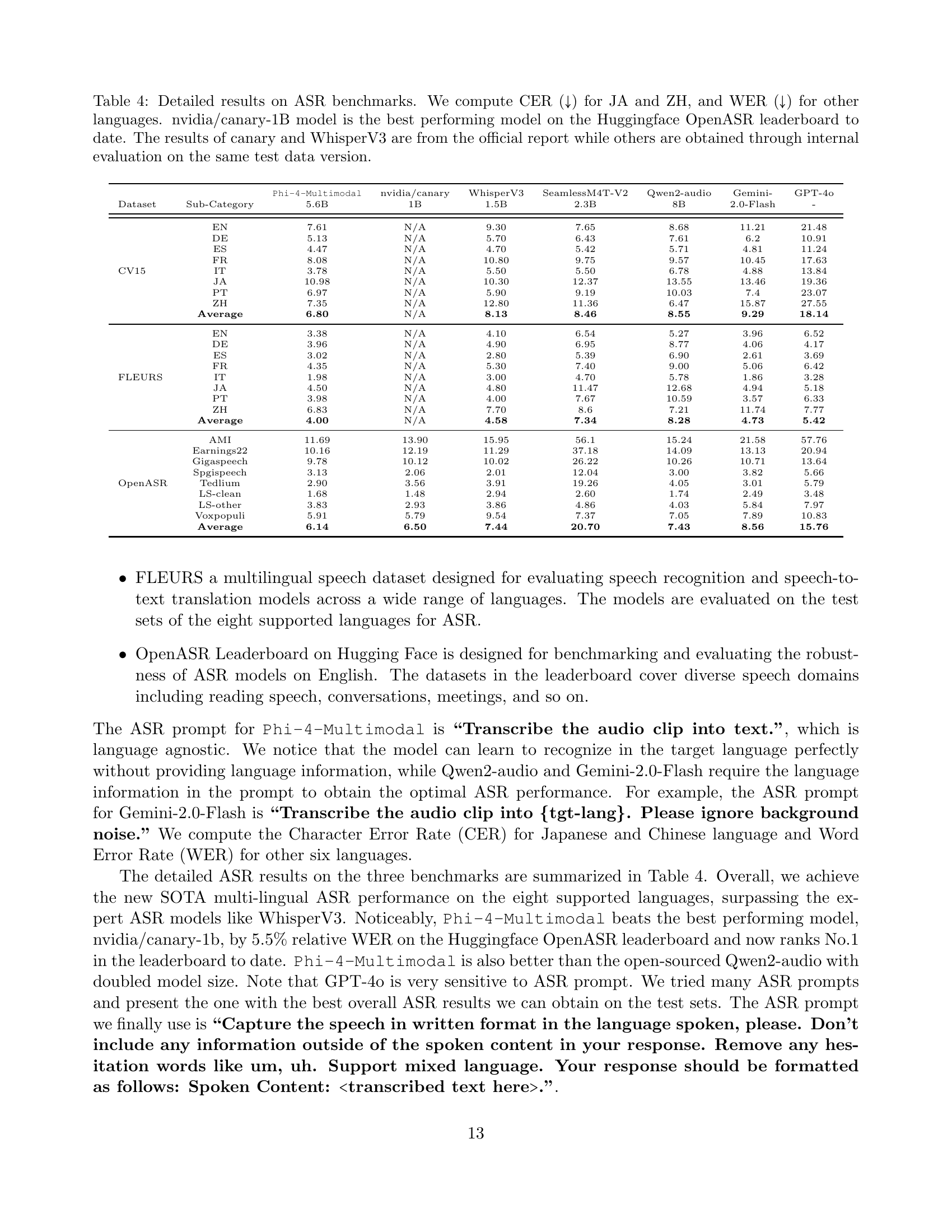
🔼 Table 4 presents a detailed comparison of Automatic Speech Recognition (ASR) performance across various models and benchmarks. It specifically focuses on Character Error Rate (CER) for Japanese (JA) and Chinese (ZH) and Word Error Rate (WER) for other languages. A key highlight is that the nvidia/canary-1B model is identified as the top-performing model on the Huggingface OpenASR leaderboard. The table contrasts results from different models, noting that the results for nvidia/canary-1B and WhisperV3 are sourced directly from official reports, while the remaining model results were generated through internal testing. All evaluations were conducted on the same test data version for a consistent comparison.
read the caption
Table 4: Detailed results on ASR benchmarks. We compute CER (↓↓\downarrow↓) for JA and ZH, and WER (↓↓\downarrow↓) for other languages. nvidia/canary-1B model is the best performing model on the Huggingface OpenASR leaderboard to date. The results of canary and WhisperV3 are from the official report while others are obtained through internal evaluation on the same test data version.
| Refusal Rate | Phi-4-Mini | Phi-4-Multimodal | Phi-3.5-mini | Llama-3.2-3B | Qwen-2.5-3B |
| IPRR | 93.5% | 92% | 87% | 92.5% | 92% |
| VPRR | 20.8% | 26.4% | 21.2% | 15.6% | 25.6% |
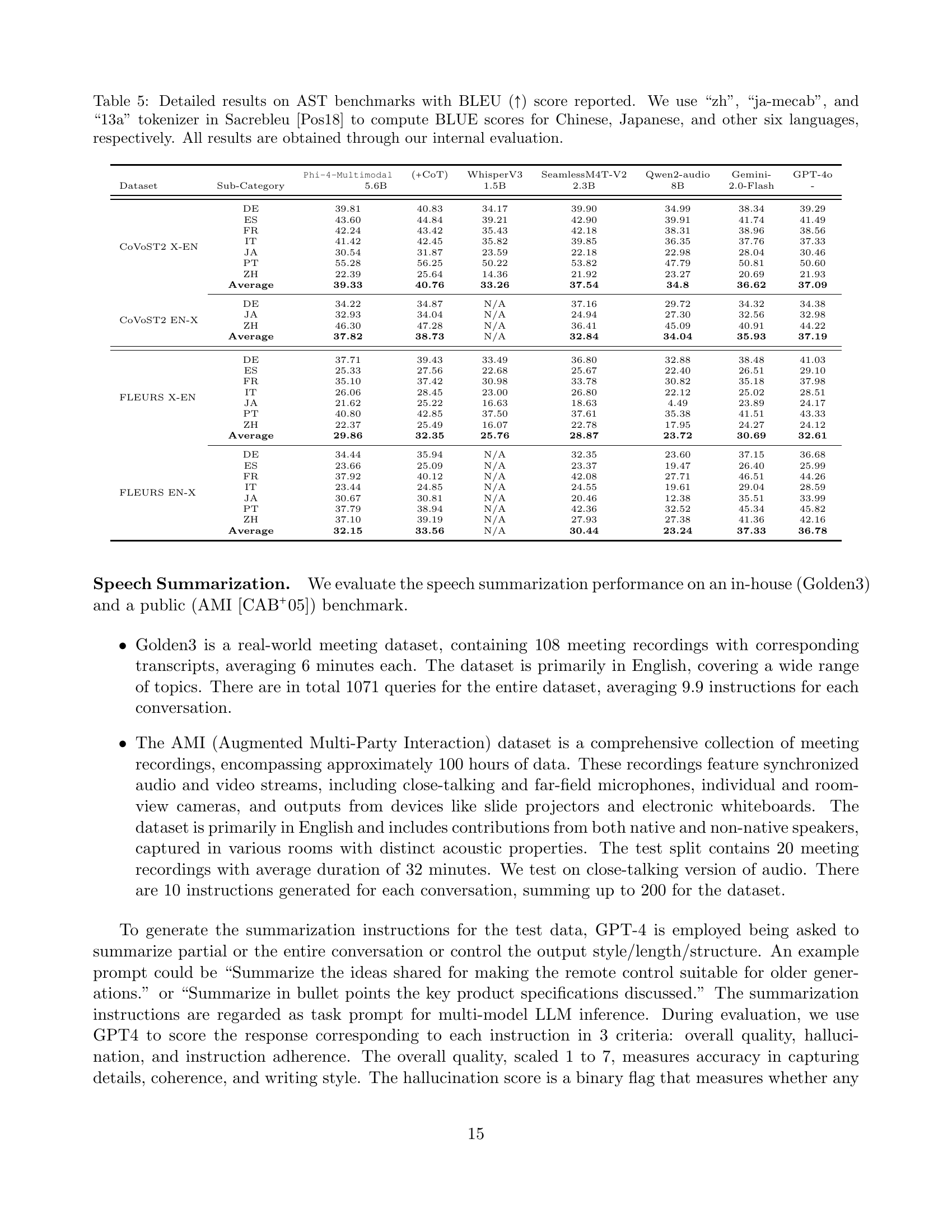
🔼 Table 5 presents a detailed comparison of Automatic Speech Translation (AST) performance across various models and languages on two benchmark datasets, COVOST2 and FLEURS. The evaluation focuses on BLEU scores, a common metric assessing the quality of machine translation. Different tokenizers within the Sacrebleu toolkit (zh, ja-mecab, and 13a) were used to optimize BLEU score calculation for Chinese, Japanese, and the remaining six languages, respectively. The results shown are entirely based on internal evaluations performed by the authors.
read the caption
Table 5: Detailed results on AST benchmarks with BLEU (↑↑\uparrow↑) score reported. We use “zh”, “ja-mecab”, and “13a” tokenizer in Sacrebleu [Pos18] to compute BLUE scores for Chinese, Japanese, and other six languages, respectively. All results are obtained through our internal evaluation.
| Defect Rate | Phi-4-Multimodal | GPT-4o |
| Violence | 4% | 2% |
| Sexual | 4% | 1% |
| Self-Harm | 1% | 1% |
| Hateful | 4% | 0% |
| Average | 3.25% | 1% |
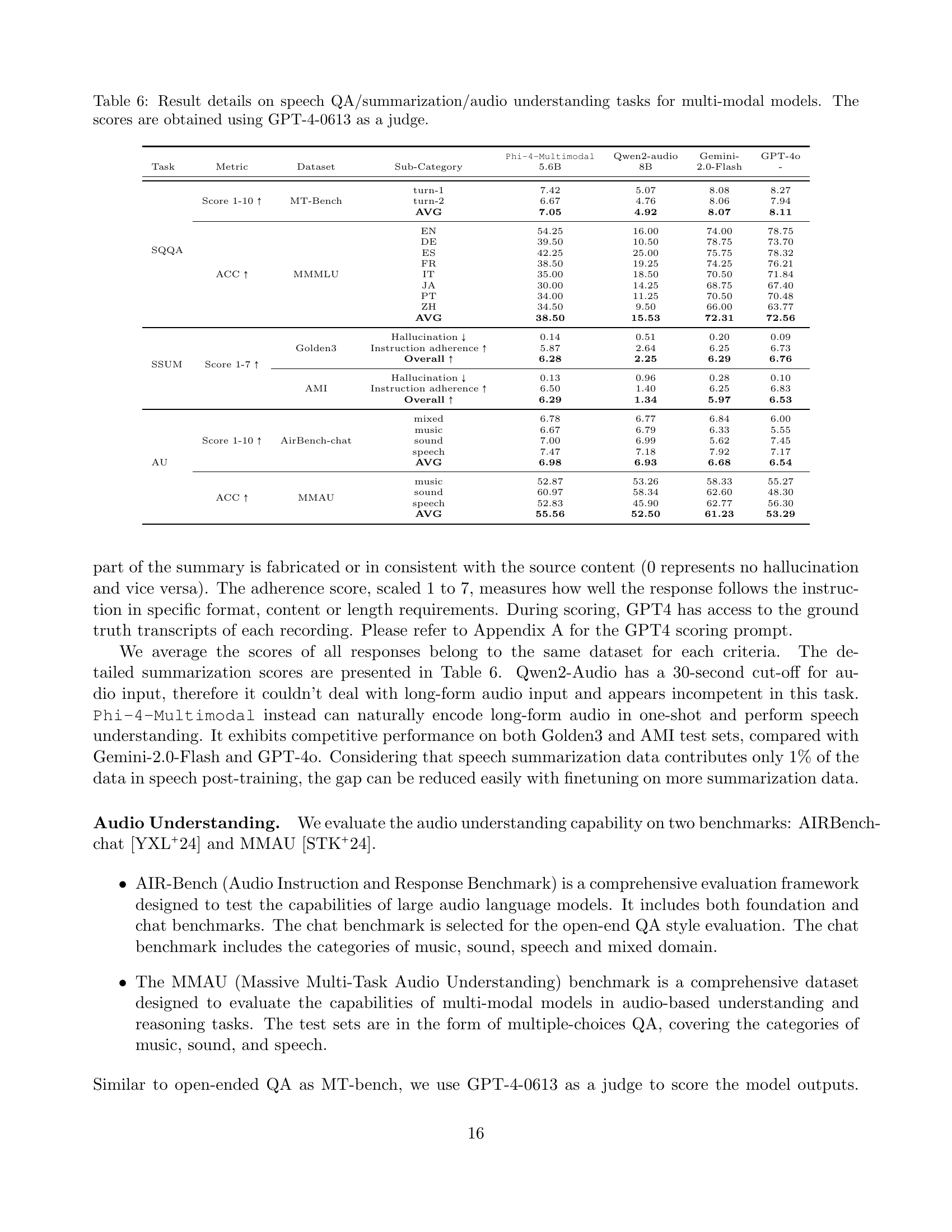
🔼 This table presents a detailed breakdown of the performance of various multi-modal models on speech-related tasks, including question answering (QA), summarization (SSUM), and audio understanding (AU). The models are evaluated across different benchmarks and sub-categories, providing a comprehensive assessment of their capabilities. GPT-4 (version 0613) is used as the evaluation metric.
read the caption
Table 6: Result details on speech QA/summarization/audio understanding tasks for multi-modal models. The scores are obtained using GPT-4-0613 as a judge.
| Text & Vision | |||||
| Safety Evaluation | Phi-4-Multimodal | Phi-3.5-Vision | Llava-1.6 Vicuna | Qwen-VL-Chat | GPT4-V |
| Internal (private) | 7.96 | 8.16 | 5.44 | 7.27 | 8.55 |
| RTVLM (public) | 6.39 | 5.44 | 3.86 | 4.78 | 6.81 |
| VLGuard (public) | 8.91 | 9.10 | 5.62 | 8.33 | 8.90 |
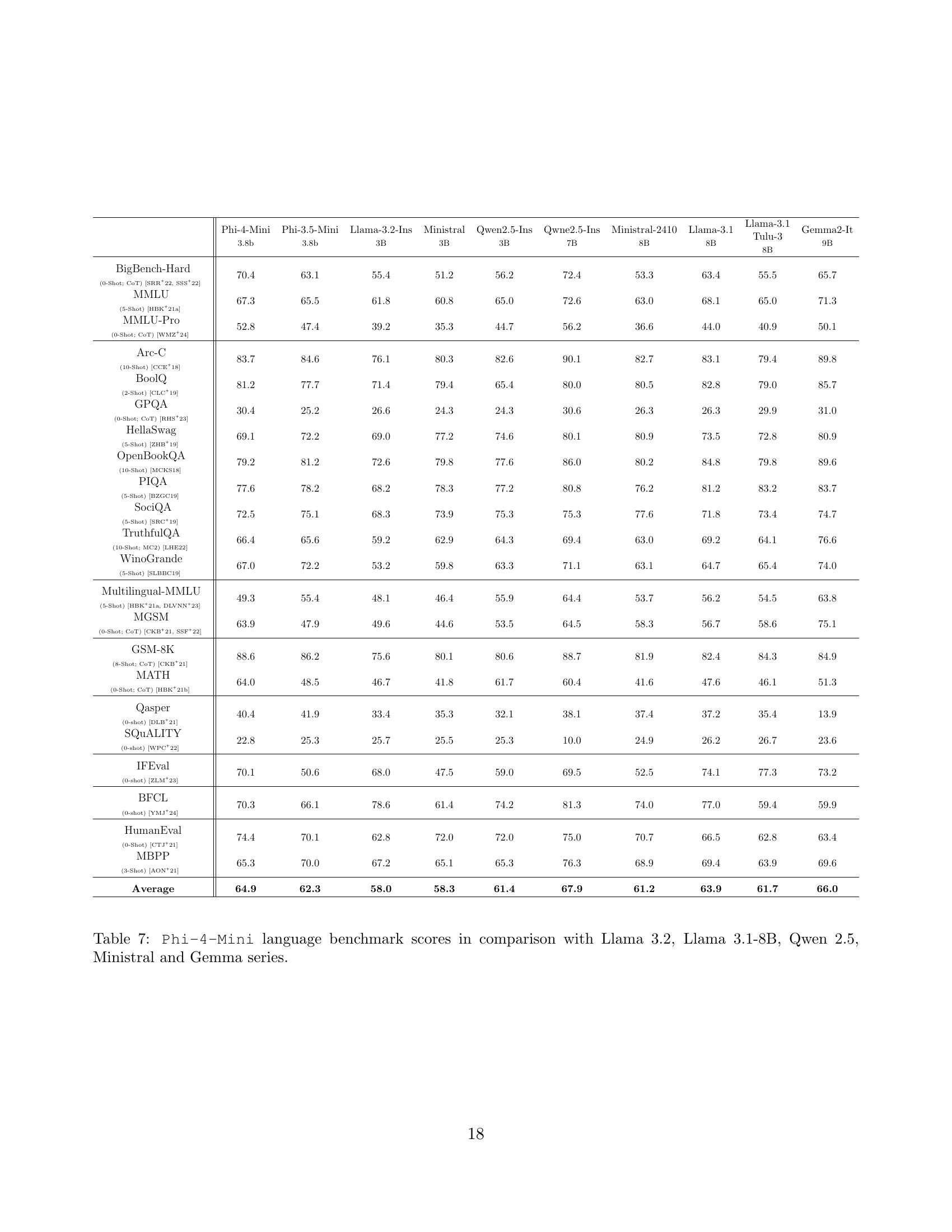
🔼 This table presents a comparison of Phi-4-Mini’s performance on various language benchmarks against several other language models, including Llama 3.2, Llama 3.1-8B, Qwen 2.5, Ministral, and Gemma series. The benchmarks assess different aspects of language understanding capabilities, such as reasoning, math, and coding skills. The table allows readers to directly compare the performance of Phi-4-Mini to these models across multiple tasks, highlighting its strengths and weaknesses relative to its size and capabilities.
read the caption
Table 7: Phi-4-Mini language benchmark scores in comparison with Llama 3.2, Llama 3.1-8B, Qwen 2.5, Ministral and Gemma series.
| Abdelrahman Abouelenin | Yuxuan Hu | Bo Ren |
| Atabak Ashfaq | Xin Jin | Liliang Ren |
| Adam Atkinson | Mahmoud Khademi | Sambuddha Roy |
| Hany Awadalla | Dongwoo Kim | Ning Shang |
| Nguyen Bach | Young Jin Kim | Yelong Shen |
| Jianmin Bao | Gina Lee | Saksham Singhal |
| Alon Benhaim | Jinyu Li | Subhojit Som |
| Martin Cai | Yunsheng Li | Xia Song |
| Vishrav Chaudhary | Chen Liang | Tetyana Sych |
| Congcong Chen | Xihui Lin | Praneetha Vaddamanu |
| Dong Chen | Zeqi Lin | Shuohang Wang |
| Dongdong Chen | Mengchen Liu | Yiming Wang |
| Junkun Chen | Yang Liu | Zhenghao Wang |
| Weizhu Chen | Gilsinia Lopez | Haibin Wu |
| Yen-Chun Chen | Chong Luo | Haoran Xu |
| Yi-ling Chen | Piyush Madan | Weijian Xu |
| Qi Dai | Vadim Mazalov | Yifan Yang |
| Xiyang Dai | Ali Mousavi | Ziyi Yang |
| Ruchao Fan | Anh Nguyen | Donghan Yu |
| Mei Gao | Jing Pan | Ishmam Zabir |
| Min Gao | Daniel Perez-Becker | Jianwen Zhang |
| Amit Garg | Jacob Platin | Li Lyna Zhang |
| Abhishek Goswami | Thomas Portet | Yunan Zhang |
| Junheng Hao | Kai Qiu | Xiren Zhou |
| Amr Hendy |
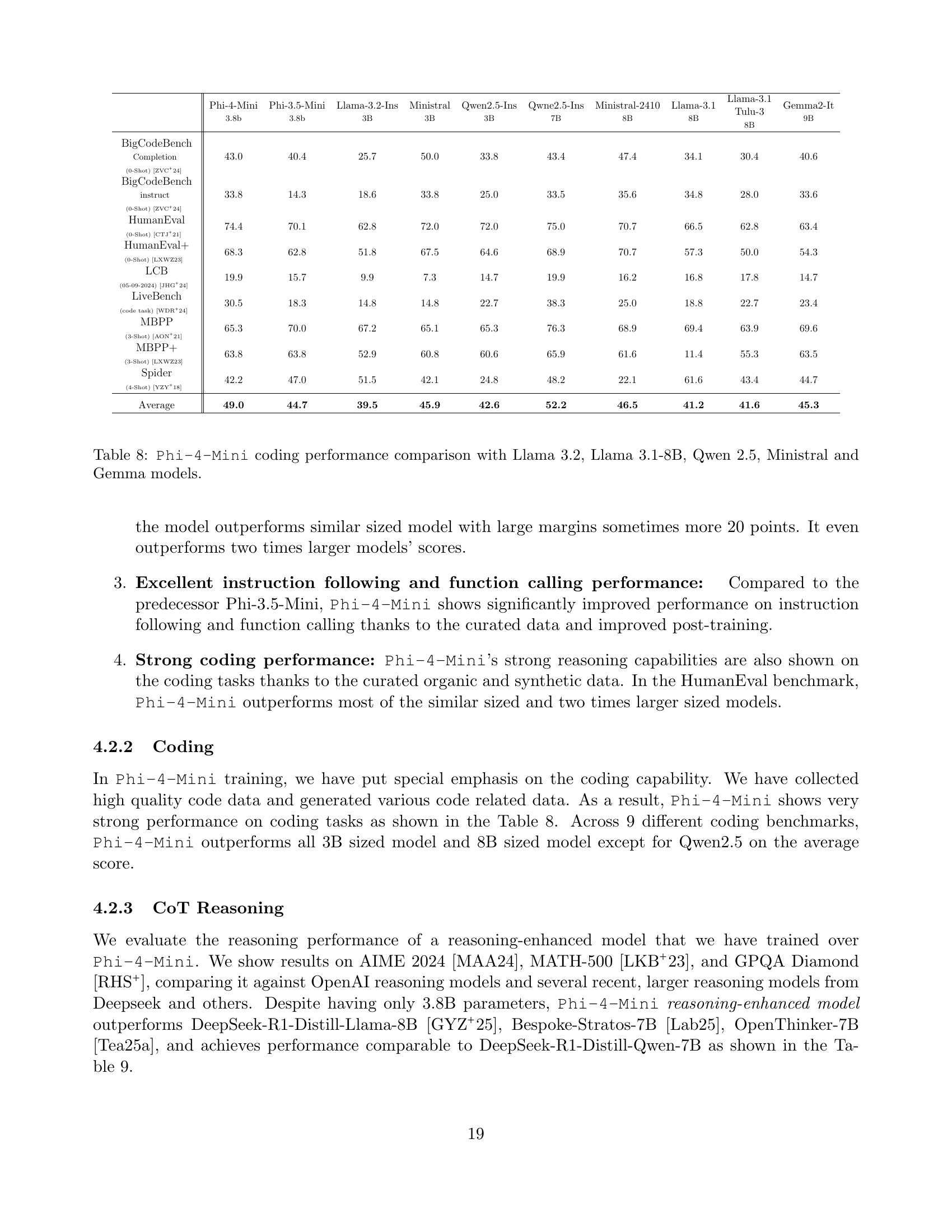
🔼 This table presents a comparison of Phi-4-Mini’s performance on various coding benchmarks against several other language models, including Llama 3.2, Llama 3.1-8B, Qwen 2.5, Ministral, and Gemma models. The benchmarks assess different coding capabilities, offering a comprehensive evaluation of Phi-4-Mini’s strengths and weaknesses in code generation, understanding, and related tasks. The comparison highlights the relative performance of Phi-4-Mini across various model sizes and architectures, providing insights into its efficiency and effectiveness in the coding domain. For each benchmark, the table shows the score achieved by each model, allowing for a direct comparison of performance.
read the caption
Table 8: Phi-4-Mini coding performance comparison with Llama 3.2, Llama 3.1-8B, Qwen 2.5, Ministral and Gemma models.
Full paper#