TL;DR#
Recent neural rendering methods like NeRF and 3D Gaussian Splatting (3DGS) have revolutionized 3D reconstruction and novel-view synthesis. However, generating photorealistic renderings from novel viewpoints remains challenging due to persistent artifacts, especially in under-constrained regions. Existing methods struggle with issues like spurious geometry, missing regions, and inconsistencies, which limit their applicability in real-world settings. Large 2D generative models could help, but integrating them efficiently into 3D reconstruction pipelines is still an open problem.
DIFIX3D+ addresses these issues with a novel pipeline that uses single-step diffusion models to enhance 3D reconstruction and novel-view synthesis. The core of this approach is DIFIX, a single-step image diffusion model trained to enhance and remove artifacts in rendered novel views. DIFIX acts as a neural enhancer during both the reconstruction phase and at inference time, improving overall 3D representation quality and effectively removing residual artifacts. By progressively refining the 3D representation and using a fast single-step diffusion model, DIFIX3D+ achieves significant improvements in visual quality and 3D consistency.
Key Takeaways#
Why does it matter?#
This paper is important for its innovative approach to enhancing 3D reconstruction using single-step diffusion models, offering a practical solution to common artifacts. The method’s compatibility with both NeRF and 3DGS, along with its real-time processing capability, makes it highly valuable. It paves the way for future research in integrating advanced generative models to improve the visual fidelity and consistency of 3D models.
Visual Insights#

🔼 Figure 1 showcases the performance of Difix3D+ on various scenes. The top row presents in-the-wild scenes, while the bottom row displays driving scenes. It highlights how Difix3D+ addresses challenges faced by other novel-view synthesis methods that often struggle with sparse input data or when generating views significantly different from the input camera viewpoints. Difix3D+ leverages 2D generative models to improve the quality of 3D reconstructions. The model acts as a neural renderer during inference, correcting any inconsistencies. The effectiveness of Difix3D+ is particularly emphasized by its ability to rectify artifacts present in established methods like NeRF and 3DGS.
read the caption
Figure 1: We demonstrate Difix3D+ on both in-the-wild scenes (top) and driving scenes (bottom). Recent Novel-View Synthesis methods struggle in sparse-input settings or when rendering views far from the input camera poses. Difix distills the priors of 2D generative models to enhance reconstruction quality and can further act as a neural-renderer at inference time to mitigate the remaining inconsistencies. Notably, the same model effectively corrects NeRF [37] and 3DGS [20] artifacts.
| 1000 | 800 | 600 | 400 | 200 | 10 | |
|---|---|---|---|---|---|---|
| PSNR | 12.18 | 13.63 | 15.64 | 17.05 | 17.73 | 17.72 |
| SSIM | 0.4521 | 0.5263 | 0.6129 | 0.6618 | 0.6814 | 0.6752 |
🔼 This table details the data curation methods used to create a paired dataset for training the DIFIX3D+ model. The dataset contains images with common artifacts found in novel view synthesis, paired with their corresponding ground truth images. For the DL3DV dataset, sparse reconstruction and model underfitting were used to generate the artifacts. For internal Real Driving Scene (RDS) data, cycle reconstruction, cross-referencing, and model underfitting techniques were employed.
read the caption
Table 1: Data curation. We curate a paired dataset featuring common artifacts in novel-view synthesis. For DL3DV scenes [23], we employ sparse reconstruction and model underfitting, while for internal real driving scene (RDS) data, we utilize cycle reconstruction, cross reference, and model underfitting techniques.
In-depth insights#
Diffusion 3D Fix#
The idea of a ‘Diffusion 3D Fix’ is intriguing, suggesting the use of diffusion models to rectify or enhance 3D reconstructions. This approach likely leverages the powerful generative priors learned by diffusion models to address common issues in 3D, such as artifacts, incompleteness, or inconsistencies. The process might involve using the diffusion model to ‘inpaint’ missing regions, refine noisy surfaces, or ensure multi-view consistency. A key advantage would be the ability to incorporate prior knowledge from large datasets, leading to more plausible and robust 3D models, especially in challenging scenarios with sparse or noisy input data. This method could be applied to diverse 3D representations, including neural radiance fields and meshes, and the efficiency of implementation is a crucial factor.
Progressive Refine#
Progressive refinement is a crucial technique for enhancing 3D reconstruction, enabling iterative improvements. The process likely involves gradually refining the geometry and texture of the 3D model, leading to enhanced detail and accuracy. This technique combats issues arising from noise or incomplete data, as it allows initial estimates to be refined over multiple iterations. Techniques like iterative closest point (ICP) or bundle adjustment could be used to align and refine the model. In the context of neural rendering, progressive refinement might involve gradually increasing the resolution of the neural radiance field or employing curriculum learning strategies to improve the model’s understanding of the scene. Methods involving the distillation or incorporation of generative priors also benefit, with each iteration boosting the overall model quality.
Artifact Removal#
The notion of artifact removal in 3D reconstruction and novel view synthesis highlights a critical challenge: achieving visually plausible and geometrically consistent results, especially in areas with limited observational data. Artifacts can stem from noisy input data, inaccuracies in camera pose estimation, or the inherent ambiguities in learning 3D representations from 2D projections. Effective artifact removal is essential for creating immersive and realistic experiences. This involves cleaning up spurious geometry, filling missing regions, and reducing blurriness without introducing inconsistencies or compromising overall structural integrity. The success hinges on carefully balancing data-driven reconstruction with incorporating external priors, such as those learned by large-scale generative models. In effect, artifact removal serves as a crucial step towards bridging the gap between imperfect reconstructions and compelling visual outputs.
Single-Step Speed#
The concept of “Single-Step Speed” suggests a focus on efficient processing, especially relevant in fields like 3D reconstruction and novel-view synthesis where computational demands are high. It implies a methodology that minimizes iterative refinement, opting instead for a direct, streamlined approach. This could involve using advanced models or algorithms that can achieve desired results in a single pass or a minimal number of steps, thereby reducing latency and computational cost. The trade-offs might include a need for more powerful models or specialized hardware to handle the complexity of single-step processing. Success here hinges on balancing speed with accuracy and quality of the generated 3D representations.
Consistency?#
In 3D reconstruction, consistency refers to the agreement between different views or renderings of the same scene. It is essential for a realistic and plausible 3D representation. Inconsistent views lead to visual artifacts, such as ghosting or flickering. Multi-view consistency ensures that the rendered images are geometrically and photometrically compatible. Achieving multi-view consistency can be challenging due to noisy input data, occlusions, and limitations in the underlying 3D representation. To address these challenges, researchers often employ techniques such as bundle adjustment, robust losses, and regularization. Some methods query the diffusion model at each training step. To ensure consistency the views are updated progressively.
More visual insights#
More on figures

🔼 The figure illustrates the DIFIX3D+ pipeline, a three-step process for enhancing 3D reconstruction and novel view synthesis. Step 1 involves rendering novel views from a pre-trained 3D model and using DIFIX (a single-step diffusion model) to remove artifacts and improve their quality. The camera poses for these novel views are gradually interpolated from reference poses towards target poses. In Step 2, these enhanced views are used to refine the 3D representation. Steps 1 and 2 are iterated to progressively expand the reconstruction, improving the diffusion model’s conditioning. Finally, in Step 3, DIFIX is used as a real-time neural enhancer to further improve the quality of rendered novel views.
read the caption
Figure 2: Difix3D+ pipeline. The overall pipeline of the Difix3D+ model involves the following stages: Step 1: Given a pretrained 3D representation, we render novel views and feed them to Difix which acts as a neural enhancer, removing the artifacts and improving the quality of the noisy rendered views (Sec. 4.1). The camera poses selected to render the novel views are obtained through pose interpolation, gradually approaching the target poses from the reference ones. Step 2: The cleaned novel views are distilled back to the 3D representation to improve its quality (Sec. 4.2). Steps 1 and 2 are applied in several iterations to progressively grow the spatial extent of the reconstruction and hence ensure strong conditioning of the diffusion model (Difix3D). Step 3: Difix additional acts as a real-time neural enhancer, further improving the quality of the rendered novel views.

🔼 The DIFIX architecture is a U-Net based model that takes a noisy rendered image and reference views as input and outputs an enhanced version of the input image with reduced artifacts. The model incorporates a cross-view reference mixing layer to maintain consistency between the input image and reference views. This is achieved by using a frozen VAE encoder and a LoRA fine-tuned decoder, fine-tuned from the SD-Turbo model. Identical reference views are generated but discarded during practice.
read the caption
Figure 3: Difix architecture. Difix takes a noisy rendered image and a reference views as input (left), and outputs an enhanced version of the input image with reduced artifacts (right). Difix also generates identical reference views, which we discard in practice and hence depict transparent. The model architecture consists of a U-Net structure with a cross-view reference mixing layer (Sec. 4.1) to maintain consistency across reference views. Difix is fine-tuned from SD-Turbo, using a frozen VAE encoder and a LoRA fine-tuned decoder.

🔼 This figure shows an ablation study on the effect of different noise levels on a single-step denoising diffusion model. The model was fine-tuned on images with artifacts from NeRF and 3DGS. The experiment shows that at high noise levels (τ = 600), the model effectively removes artifacts but modifies image context. At low noise levels (τ = 10), the model makes minor adjustments and leaves most artifacts intact. The best results were obtained at τ = 200, where the model removes artifacts while preserving image context.
read the caption
Figure 4: Noise level. To validate our hypothesis that the distribution of images with NeRF/3DGS artifacts is similar to the distribution of noisy images used to train SD-Turbo [49], we perform single-step “denoising” at varying noise levels. At higher noise levels (e.g., τ=600𝜏600\tau=600italic_τ = 600), the model effectively removes artifacts but also alters the image context. At lower noise levels (e.g., τ=10𝜏10\tau=10italic_τ = 10), the model makes only minor adjustments, leaving most artifacts intact. τ=200𝜏200\tau=200italic_τ = 200 strikes a good balance, removing artifacts while preserving context, and achieves the highest metrics.

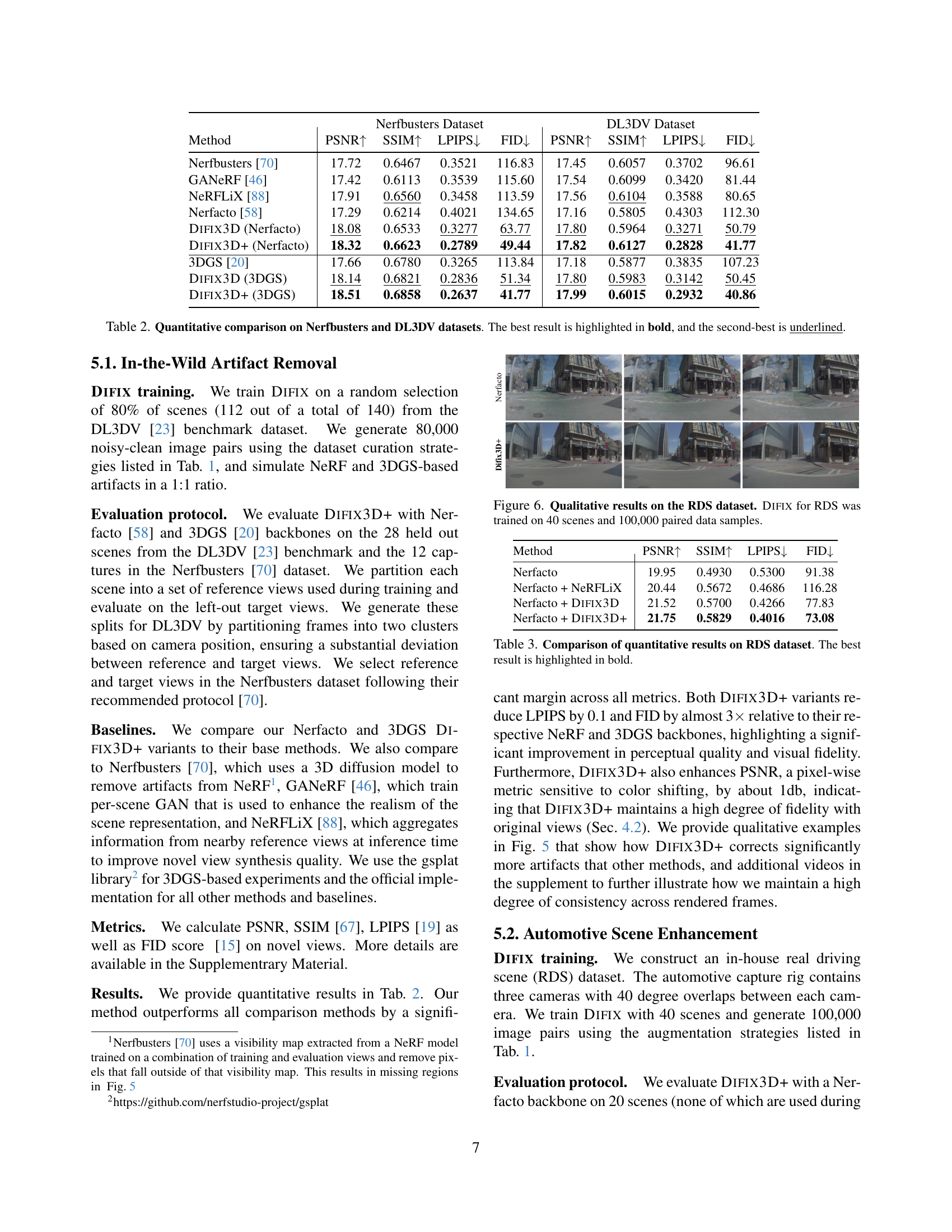
🔼 This figure demonstrates the performance of DIFIX3D+ on real-world scenes with challenging conditions. The top half shows comparisons on held-out scenes from the DL3DV dataset, while the bottom half uses scenes from the Nerfbusters dataset. Both datasets contain examples where existing novel view synthesis methods struggle. Each row shows the ground truth image (GT) followed by results from several state-of-the-art methods (Nerfbusters, GANERF, NeRFLIX, Nerfacto) and finally, the results obtained using the proposed DIFIX3D+ method. The visual comparison highlights DIFIX3D+’s superior ability to remove artifacts and generate more photorealistic novel views.
read the caption
Figure 5: In-the-wild artifact removal. We show comparisons on held-out scenes from the DL3DV dataset [23] (top, above the dashed line) and the Nerfbusters [70] dataset (bottom). Difix3D+ corrects significantly more artifacts that other methods.

🔼 Figure 6 presents a qualitative comparison of 3D reconstruction results on the Real Driving Scenes (RDS) dataset. The model, DIFIX, was trained using 40 distinct scenes and 100,000 image pairs, which were carefully curated to include various common artifacts in 3D reconstruction. The figure showcases the impact of DIFIX on improving the quality of novel view synthesis. It visually demonstrates the differences in image quality and realism achieved by several models, emphasizing the enhancements provided by the DIFIX method.
read the caption
Figure 6: Qualitative results on the RDS dataset. Difix for RDS was trained on 40 scenes and 100,000 paired data samples.

🔼 This figure shows the results of real-time post-render processing using DIFIX3D+. The pipeline includes an additional neural enhancement step after the initial 3D reconstruction and rendering. This step effectively removes residual artifacts that remain after the main reconstruction process. The effectiveness of this additional step is demonstrated by comparing the PSNR (Peak Signal-to-Noise Ratio) and LPIPS (Learned Perceptual Image Patch Similarity) scores of the processed images to the original rendered images. Higher PSNR and lower LPIPS values in the processed images indicate improved image quality due to reduced artifacts. The green and red boxes highlight zoomed-in sections of the images, allowing for a more detailed comparison of the artifact removal.
read the caption
Figure 7: Qualitative ablation of real-time post-render processing: Difix3D+ uses an additional neural enhancer step that effectively removes residual artifacts, resulting in higher PSNR and lower LPIPS scores. The images displayed in green or red boxes correspond to zoomed-in views of the bounding boxes drawn in the main images.
More on tables
| Sparse | Cycle | Cross | Model | |
|---|---|---|---|---|
| Reconstruction | Reconstruction | Reference | Underfitting | |
| DL3DV [23] | ✓ | ✓ | ||
| Internal RDS | ✓ | ✓ | ✓ |
🔼 Table 2 presents a quantitative comparison of different novel-view synthesis methods on two benchmark datasets: Nerfbusters and DL3DV. The methods are evaluated using four metrics: PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), LPIPS (Learned Perceptual Image Patch Similarity), and FID (Fréchet Inception Distance). Higher PSNR and SSIM values, and lower LPIPS and FID values indicate better performance. The table highlights the best performing method for each metric in bold, and the second-best method is underlined, allowing for easy identification of top performers and relative comparisons across different techniques.
read the caption
Table 2: Quantitative comparison on Nerfbusters and DL3DV datasets. The best result is highlighted in bold, and the second-best is underlined.
| Nerfbusters Dataset | DL3DV Dataset | |||||||
| Method | PSNR | SSIM | LPIPS | FID | PSNR | SSIM | LPIPS | FID |
| Nerfbusters [70] | 17.72 | 0.6467 | 0.3521 | 116.83 | 17.45 | 0.6057 | 0.3702 | 96.61 |
| GANeRF [46] | 17.42 | 0.6113 | 0.3539 | 115.60 | 17.54 | 0.6099 | 0.3420 | 81.44 |
| NeRFLiX [88] | 17.91 | 0.6560 | 0.3458 | 113.59 | 17.56 | 0.6104 | 0.3588 | 80.65 |
| Nerfacto [58] | 17.29 | 0.6214 | 0.4021 | 134.65 | 17.16 | 0.5805 | 0.4303 | 112.30 |
| Difix3D (Nerfacto) | 18.08 | 0.6533 | 0.3277 | 63.77 | 17.80 | 0.5964 | 0.3271 | 50.79 |
| Difix3D+ (Nerfacto) | 18.32 | 0.6623 | 0.2789 | 49.44 | 17.82 | 0.6127 | 0.2828 | 41.77 |
| 3DGS [20] | 17.66 | 0.6780 | 0.3265 | 113.84 | 17.18 | 0.5877 | 0.3835 | 107.23 |
| Difix3D (3DGS) | 18.14 | 0.6821 | 0.2836 | 51.34 | 17.80 | 0.5983 | 0.3142 | 50.45 |
| Difix3D+ (3DGS) | 18.51 | 0.6858 | 0.2637 | 41.77 | 17.99 | 0.6015 | 0.2932 | 40.86 |
🔼 This table presents a quantitative comparison of different methods for enhancing the quality of novel view synthesis in real driving scenes (RDS). The methods compared include a baseline (Nerfacto), Nerfacto enhanced with NeRFLIX, Nerfacto enhanced with DIFIX3D, and Nerfacto enhanced with DIFIX3D+. The metrics used for comparison are PSNR, SSIM, LPIPS, and FID, which are standard measures for evaluating image quality and perceptual similarity. Higher PSNR and SSIM values and lower LPIPS and FID values indicate better performance. The best performing method in each metric is highlighted in bold.
read the caption
Table 3: Comparison of quantitative results on RDS dataset. The best result is highlighted in bold.
| Method | PSNR | SSIM | LPIPS | FID |
|---|---|---|---|---|
| Nerfacto | 19.95 | 0.4930 | 0.5300 | 91.38 |
| Nerfacto + NeRFLiX | 20.44 | 0.5672 | 0.4686 | 116.28 |
| Nerfacto + Difix3D | 21.52 | 0.5700 | 0.4266 | 77.83 |
| Nerfacto + Difix3D+ | 21.75 | 0.5829 | 0.4016 | 73.08 |
🔼 This table presents an ablation study evaluating the impact of different components of the DIFIX3D+ pipeline on the Nerfbusters dataset. It compares the performance of a Nerfacto baseline model against four variations: (a) using DIFIX alone on rendered views without any 3D updates; (b) incorporating DIFIX and non-incremental 3D updates (all at once); (c) employing DIFIX with incremental 3D updates (progressive refinement); and (d) adding DIFIX as a final post-rendering enhancement step. The results across different metrics are used to analyze the contribution of each component to the overall performance of DIFIX3D+.
read the caption
Table 4: Ablation study of Difix3D+ on Nerfbusters dataset. We compare a Nerfacto baseline to: (a) directly running Difix on rendered views without 3D updates, (b) distilling Difix outputs via 3D updates in a non-incremental manner, (c) applying the 3D updates incrementally, and (d) add Difix as a post-rendering step.
| Method | PSNR | SSIM | LPIPS | FID |
|---|---|---|---|---|
| Nerfacto | 17.29 | 0.6214 | 0.4021 | 134.65 |
| + (a) (Difix) | 17.40 | 0.6279 | 0.2996 | 49.87 |
| + (a) + (b) (Difix + single-step 3D update) | 17.97 | 0.6563 | 0.3424 | 75.94 |
| + (a) + (b) + (c) (Difix3D) | 18.08 | 0.6533 | 0.3277 | 63.77 |
| + (a) + (b) + (c) + (d) (Difix3D+) | 18.32 | 0.6623 | 0.2789 | 49.44 |
🔼 This ablation study analyzes the impact of different components of the DIFIX model on its performance. The Nerfbusters dataset is used for evaluation. The table shows how reducing the noise level during training, incorporating reference views for conditioning, and including a Gram loss in the training objective improve the model’s ability to remove artifacts and enhance image quality.
read the caption
Table 5: Ablation study of Difix components on Nerfbusters dataset. Reducing the noise level, conditioning on reference views, and incorporating Gram loss improve our model.
| Method | SD Turbo Pretrain. | Gram | Ref | LPIPS | FID | |
|---|---|---|---|---|---|---|
| pix2pix-Turbo | 1000 | ✓ | 0.3810 | 108.86 | ||
| Difix | 200 | ✓ | 0.3190 | 61.80 | ||
| Difix | 200 | ✓ | ✓ | 0.3064 | 55.45 | |
| Difix | 200 | ✓ | ✓ | ✓ | 0.2996 | 47.87 |
🔼 This table presents a quantitative evaluation of multi-view consistency for different methods on the DL3DV dataset. Multi-view consistency refers to how well the methods maintain consistency across multiple views of a 3D scene. The evaluation metric used is Thresholded Symmetric Epipolar Distance (TSED) at different thresholds (Terror = 2, 4, and 8). A higher TSED score indicates better multi-view consistency, meaning the generated views align more accurately with the underlying 3D structure. The table compares the performance of Nerfacto, NeRFLIX, GANERF, DIFIX3D, and DIFIX3D+.
read the caption
Table S1: Multi-view consistency evaluation on the DL3DV dataset. A higher TSED score indicates better multi-view consistency.
Full paper#