TL;DR#
Large Reasoning Models(LRMs) need Reinforcement Fine-Tuning(RFT) to learn. RFT is useful when fine-tuning data is scarse. But the application in multi-modal domains remains under-explored. Thus, this paper introduces Visual Reinforcement Fine-Tuning. It extends the application areas of RFT on visual tasks. It uses Large Vision-Language Models(LVLMs) to generate multiple responses and uses visual perception verifiable reward functions to update the model.
Visual-RFT offers data-efficient, reward-driven approach that enhances reasoning and adaptability for domain-specific tasks. It achieves better performance than Supervised Fine-Tuning on tasks such as Open Vocabulary/Few-shot Detection, Reasoning Grounding, and Fine-grained Classification. Visual-RFT improves accuracy by 24.3% in one-shot fine-grained image classification with around 100 samples. In few-shot object detection, Visual-RFT also exceeds the baseline.
Key Takeaways#
Why does it matter?#
This paper introduces Visual-RFT, a novel approach to fine-tuning LVLMs that significantly improves performance with limited data. It offers a data-efficient, reward-driven method for enhancing reasoning and adaptability, opening new avenues for research in visual perception and multi-modal learning.
Visual Insights#

🔼 Figure 1 showcases the superior performance of Visual Reinforcement Fine-Tuning (Visual-RFT) compared to Supervised Fine-Tuning (SFT) across various visual tasks. The figure presents several bar charts and graphs that illustrate the improvement in accuracy achieved by Visual-RFT over SFT in open vocabulary (OV) and few-shot object detection, reasoning grounding, and fine-grained image classification. Each chart displays metrics like mean average precision (mAP) or Intersection over Union (IoU), highlighting the significant gains obtained through the Visual-RFT method. The visualization effectively demonstrates that Visual-RFT is a data-efficient technique that surpasses SFT by a significant margin, particularly beneficial when fine-tuning data is scarce.
read the caption
Figure 1: Our Visual Reinforcement Fine-Tuning (Visual-RFT) performs better than previous Supervised Fine-Tuning (SFT) on a variety of tasks, such as Open Vocabulary(OV)/Few-shot Detection, Reasoning Grounding, and Fine-grained Classification.
| Detection Prompt: Detect all objects belonging to the category ’category’ in the image, and provide the bounding boxes (between 0 and 1000, integer) and confidence (between 0 and 1, with two decimal places). If no object belonging to the category ’category’ in the image, return ’No Objects’. Output the thinking process in think /think and final answer in answer /answer tags. The output answer format should be as follows: think … /thinkanswer[’Position’: [x1, y1, x2, y2], ’Confidence’: number, …]/answer Please strictly follow the format. |
| Classification Prompt: This is an image containing a plant. Please identify the species of the plant based on the image. Output the thinking process in think /think and final answer in /think /answer tags. The output answer format should be as follows: think … /think /thinkspecies name/answer Please strictly follow the format. |
🔼 Table 1 details the prompts used to generate the dataset for training the Visual-RFT model. It shows separate prompts for object detection and image classification tasks. The detection prompt instructs the model to identify objects of a specified category in an image, provide their bounding boxes and confidence scores, and describe the reasoning process. The classification prompt asks the model to identify the species of a plant in an image, also requiring a description of the reasoning process. These prompts guide the model to produce both an answer and a step-by-step explanation of its decision-making process.
read the caption
Table 1: Prompts used to construct the dataset. We have listed the detection prompt and classification prompt separately.
In-depth insights#
Visual-RFT Intro#
The paper introduces Visual Reinforcement Fine-Tuning (Visual-RFT), extending Reinforcement Fine-Tuning (RFT) to visual tasks. RFT efficiently fine-tunes models with limited data, useful when data is scarce. Visual-RFT uses Large Vision-Language Models (LVLMs) to generate responses with reasoning tokens, then updates the model using visual perception verifiable reward functions and policy optimization algorithms like Group Relative Policy Optimization (GRPO). It designs different verifiable reward functions, such as Intersection over Union (IoU) for object detection. Experimental results show Visual-RFT’s competitive performance and advanced generalization compared to Supervised Fine-tuning (SFT) on various tasks, offering data efficiency and reward-driven approach. Visual-RFT enhances reasoning and adaptability for domain-specific tasks. The key distinction between RFT and previous SFT is data efficiency.
Verifiable Reward#
The concept of a verifiable reward is pivotal, especially in scenarios with limited data. Unlike traditional methods that rely on human feedback and complex reward models, verifiable rewards offer a direct and efficient way to assess the correctness of a model’s response. This approach is particularly beneficial in tasks where clear, objective criteria exist, allowing for rule-based evaluation. By defining specific rules that determine the reward score, the model can be trained to optimize for desired outcomes without the need for extensive labeled data or intricate reward systems. This is more data-efficient as well as better tailored to visual-RFT, which benefits the reasoning and adaptability for domain-specific tasks. By integrating verifiable reward into a visual perception tasks can significantly improve the performance and reasoning abilities of LVLMs.
Few-Shot LVLM#
While the paper doesn’t explicitly use the heading “Few-Shot LVLM,” the research heavily implies it. The core idea involves leveraging Reinforcement Learning to fine-tune Visual Language Models (LVLMs) with minimal data. The experiments demonstrate substantial gains in few-shot settings across tasks like image classification, object detection, and reasoning, highlighting the potential of this method to overcome the data scarcity that often hinders LVLM performance. It is evident that Visual-RFT excels in quickly adapting to new tasks with limited examples, significantly outperforming supervised fine-tuning (SFT) in low-data regimes. This suggests that RFT enables the models to learn more efficiently and generalize better from a few examples. It is plausible that the authors are addressing a critical challenge in applying LVLMs to real-world scenarios where collecting large amounts of labeled data is impractical or expensive. Hence, this approach is a way for data-efficient solutions to improve the practical applicability of these powerful models.
Reasoning LISA#
Reasoning about objects and their relationships in images is a critical aspect of visual intelligence, allowing systems to understand complex scenes and answer questions that require inference beyond simple object recognition. Traditional methods often struggle with such tasks due to their limited ability to understand contextual information. This research explores ways to enhance reasoning in visual models, potentially through incorporating techniques that allow the model to infer relationships between objects and their attributes from visual information or using techniques like causal reasoning. The study highlights the necessity of integrating structured knowledge with visual data for advanced reasoning capabilities.
RFT Generalization#
While “RFT Generalization” isn’t explicitly a heading in this paper, the research strongly implies its importance. The study demonstrates how Visual-RFT allows models to generalize better than traditional Supervised Fine-Tuning (SFT). The results across various tasks (few-shot classification, open vocabulary object detection, and reasoning grounding) consistently showcase Visual-RFT’s ability to adapt to new categories and datasets effectively, even with limited data. This suggests that the reward-driven approach of RFT enables models to learn more robust representations, rather than simply memorizing training examples. The model’s reasoning ability is also the key for better generalization, allowing it to understand underlying concepts and apply them to unseen scenarios. Visual-RFT excels in tasks requiring reasoning and compositional understanding, particularly in the LISA reasoning grounding experiments. The experiments highlight that RFT promotes a deeper understanding of the underlying task, rather than just memorizing surface-level correlations.
More visual insights#
More on figures

🔼 Figure 2 illustrates the core concept of Visual-RFT and its advantages over traditional Visual Instruction Tuning. Panel (a) shows Visual Instruction Tuning, which requires large-scale datasets for training. In contrast, panel (b) presents Visual-RFT, highlighting its data efficiency by requiring only limited data (10-1000 samples) for effective fine-tuning. This is achieved through reinforcement learning with verifiable rewards, shown schematically. Panel (c) demonstrates the successful application of Visual-RFT to various multi-modal tasks (detection, grounding, and classification), showcasing the model’s ability to perform reasoning and generate detailed answers, as exemplified in the detailed examples at the bottom of the figure.
read the caption
Figure 2: Overview of Visual-RFT. Compared to the (a) Visual Instruction Tuning that is data-hungry, (b) our Visual Reinforcement Fine-Tuning (Visual-RFT) is more data efficient with limited data. (c) We successfully empower Large Vision-Language Models (LVLMs) with RFT on a series of multi-modal tasks, and present examples of the model’s reasoning process at the bottom.

🔼 Visual-RFT’s framework involves receiving a question and a visual image as input. A policy model processes this input and generates multiple response options, each including reasoning steps and a final answer. The quality of each response is assessed using a verifiable reward function, specifically the Intersection over Union (IoU) reward for object detection tasks and a Classification (CLS) reward for classification tasks. These reward signals, combined with a policy gradient optimization algorithm, are then used to iteratively refine the policy model, improving its ability to generate accurate and well-reasoned responses.
read the caption
Figure 3: Framework of Visual-RFT. Given the question and visual image inputs, the policy model generates multiple responses containing reasoning steps. Then the verifiable reward such as IoU reward and CLS reward is used with the policy gradient optimization algorithm to update the policy model.

🔼 Figure 4 presents a qualitative comparison of fine-grained image classification results between standard supervised fine-tuning (SFT) and the proposed Visual-RFT method. The figure showcases examples where Visual-RFT significantly enhances the reasoning process of Large Vision-Language Models (LVLMs). Visual-RFT leverages a verifiable reward mechanism during reinforcement learning, guiding the model toward more accurate classification by explicitly incorporating a ’thinking’ step. This contrasts with the direct prediction of SFT. The improved reasoning process, as demonstrated by the more detailed and accurate reasoning steps within the ’thinking’ section of the Visual-RFT outputs, leads to substantially better classification accuracy. The figure provides visual examples of the differences in reasoning quality and accuracy between both approaches for fine-grained classification tasks.
read the caption
Figure 4: Qualitative results of Fine-Grained Image Classification. The thinking process significantly improves the reasoning ability of LVLMs, leading to higher image classification performance.

🔼 Figure 5 presents a qualitative comparison of reasoning grounding results on the LISA dataset between the standard Supervised Fine-Tuning (SFT) approach and the proposed Visual-RFT method. The figure showcases several examples where Visual-RFT significantly enhances reasoning capabilities leading to more accurate and contextually appropriate grounding of objects within images. Each example consists of a question, SFT model’s reasoning and answer, and the corresponding results from the Visual-RFT model. The Visual-RFT responses show a clear improvement in the quality of the reasoning process and in the accuracy of the grounding boxes.
read the caption
Figure 5: Qualitative results of reasoning grounding on LISA [11]. Thinking process significantly improves reasoning grounding ability with Visual-RFT.
More on tables
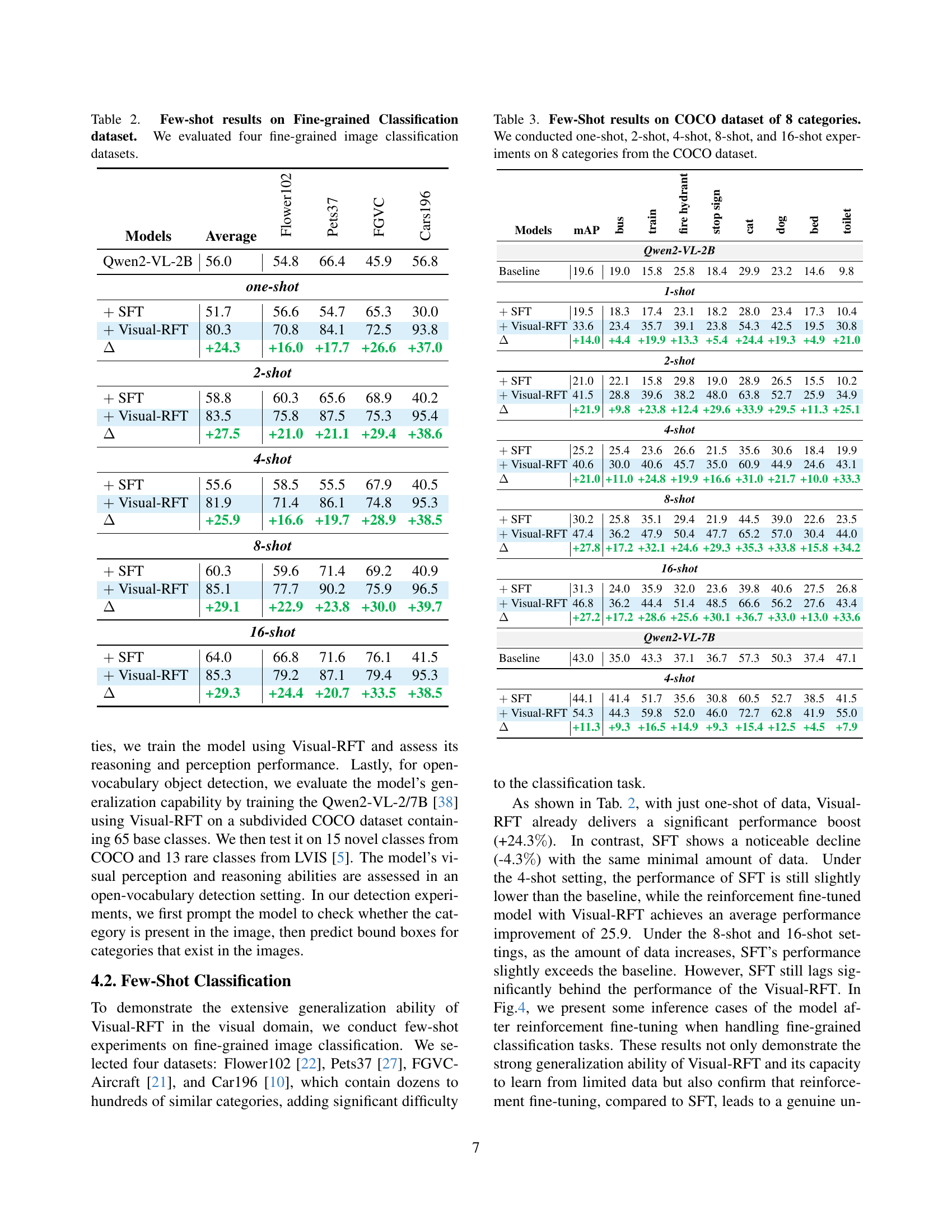
| Models | Average | Flower102 | Pets37 | FGVC | Cars196 |
|---|---|---|---|---|---|
| Qwen2-VL-2B | 56.0 | 54.8 | 66.4 | 45.9 | 56.8 |
| one-shot | |||||
| SFT | 51.7 | 56.6 | 54.7 | 65.3 | 30.0 |
| Visual-RFT | 80.3 | 70.8 | 84.1 | 72.5 | 93.8 |
| +24.3 | +16.0 | +17.7 | +26.6 | +37.0 | |
| 2-shot | |||||
| SFT | 58.8 | 60.3 | 65.6 | 68.9 | 40.2 |
| Visual-RFT | 83.5 | 75.8 | 87.5 | 75.3 | 95.4 |
| +27.5 | +21.0 | +21.1 | +29.4 | +38.6 | |
| 4-shot | |||||
| SFT | 55.6 | 58.5 | 55.5 | 67.9 | 40.5 |
| Visual-RFT | 81.9 | 71.4 | 86.1 | 74.8 | 95.3 |
| +25.9 | +16.6 | +19.7 | +28.9 | +38.5 | |
| 8-shot | |||||
| SFT | 60.3 | 59.6 | 71.4 | 69.2 | 40.9 |
| Visual-RFT | 85.1 | 77.7 | 90.2 | 75.9 | 96.5 |
| +29.1 | +22.9 | +23.8 | +30.0 | +39.7 | |
| 16-shot | |||||
| SFT | 64.0 | 66.8 | 71.6 | 76.1 | 41.5 |
| Visual-RFT | 85.3 | 79.2 | 87.1 | 79.4 | 95.3 |
| +29.3 | +24.4 | +20.7 | +33.5 | +38.5 | |
🔼 This table presents the results of a few-shot learning experiment on four fine-grained image classification datasets. It compares the performance of different models, including a baseline, supervised fine-tuning (SFT), and the proposed Visual-RFT method. The metrics used to evaluate performance are likely accuracy scores for each dataset and potentially an average accuracy across all four datasets. The ‘few-shot’ aspect refers to training the models with a limited number of samples per class.
read the caption
Table 2: Few-shot results on Fine-grained Classification dataset. We evaluated four fine-grained image classification datasets.
| Models | mAP | bus | train | fire hydrant | stop sign | cat | dog | bed | toilet |
|---|---|---|---|---|---|---|---|---|---|
| Qwen2-VL-2B | |||||||||
| Baseline | 19.6 | 19.0 | 15.8 | 25.8 | 18.4 | 29.9 | 23.2 | 14.6 | 9.8 |
| 1-shot | |||||||||
| SFT | 19.5 | 18.3 | 17.4 | 23.1 | 18.2 | 28.0 | 23.4 | 17.3 | 10.4 |
| Visual-RFT | 33.6 | 23.4 | 35.7 | 39.1 | 23.8 | 54.3 | 42.5 | 19.5 | 30.8 |
| +14.0 | +4.4 | +19.9 | +13.3 | +5.4 | +24.4 | +19.3 | +4.9 | +21.0 | |
| 2-shot | |||||||||
| SFT | 21.0 | 22.1 | 15.8 | 29.8 | 19.0 | 28.9 | 26.5 | 15.5 | 10.2 |
| Visual-RFT | 41.5 | 28.8 | 39.6 | 38.2 | 48.0 | 63.8 | 52.7 | 25.9 | 34.9 |
| +21.9 | +9.8 | +23.8 | +12.4 | +29.6 | +33.9 | +29.5 | +11.3 | +25.1 | |
| 4-shot | |||||||||
| SFT | 25.2 | 25.4 | 23.6 | 26.6 | 21.5 | 35.6 | 30.6 | 18.4 | 19.9 |
| Visual-RFT | 40.6 | 30.0 | 40.6 | 45.7 | 35.0 | 60.9 | 44.9 | 24.6 | 43.1 |
| +21.0 | +11.0 | +24.8 | +19.9 | +16.6 | +31.0 | +21.7 | +10.0 | +33.3 | |
| 8-shot | |||||||||
| SFT | 30.2 | 25.8 | 35.1 | 29.4 | 21.9 | 44.5 | 39.0 | 22.6 | 23.5 |
| Visual-RFT | 47.4 | 36.2 | 47.9 | 50.4 | 47.7 | 65.2 | 57.0 | 30.4 | 44.0 |
| +27.8 | +17.2 | +32.1 | +24.6 | +29.3 | +35.3 | +33.8 | +15.8 | +34.2 | |
| 16-shot | |||||||||
| SFT | 31.3 | 24.0 | 35.9 | 32.0 | 23.6 | 39.8 | 40.6 | 27.5 | 26.8 |
| Visual-RFT | 46.8 | 36.2 | 44.4 | 51.4 | 48.5 | 66.6 | 56.2 | 27.6 | 43.4 |
| +27.2 | +17.2 | +28.6 | +25.6 | +30.1 | +36.7 | +33.0 | +13.0 | +33.6 | |
| Qwen2-VL-7B | |||||||||
| Baseline | 43.0 | 35.0 | 43.3 | 37.1 | 36.7 | 57.3 | 50.3 | 37.4 | 47.1 |
| 4-shot | |||||||||
| SFT | 44.1 | 41.4 | 51.7 | 35.6 | 30.8 | 60.5 | 52.7 | 38.5 | 41.5 |
| Visual-RFT | 54.3 | 44.3 | 59.8 | 52.0 | 46.0 | 72.7 | 62.8 | 41.9 | 55.0 |
| +11.3 | +9.3 | +16.5 | +14.9 | +9.3 | +15.4 | +12.5 | +4.5 | +7.9 | |
🔼 This table presents the results of a few-shot object detection experiment on the COCO dataset. The experiment evaluated the performance of different models (baseline, SFT, and Visual-RFT) under various data settings (one-shot, 2-shot, 4-shot, 8-shot, and 16-shot). The performance is measured using mean Average Precision (mAP) across 8 object categories from the COCO dataset. The table allows for a comparison of Visual-RFT’s performance against supervised fine-tuning (SFT) and a baseline model with varying amounts of training data, highlighting the data efficiency of Visual-RFT.
read the caption
Table 3: Few-Shot results on COCO dataset of 8 categories. We conducted one-shot, 2-shot, 4-shot, 8-shot, and 16-shot experiments on 8 categories from the COCO dataset.
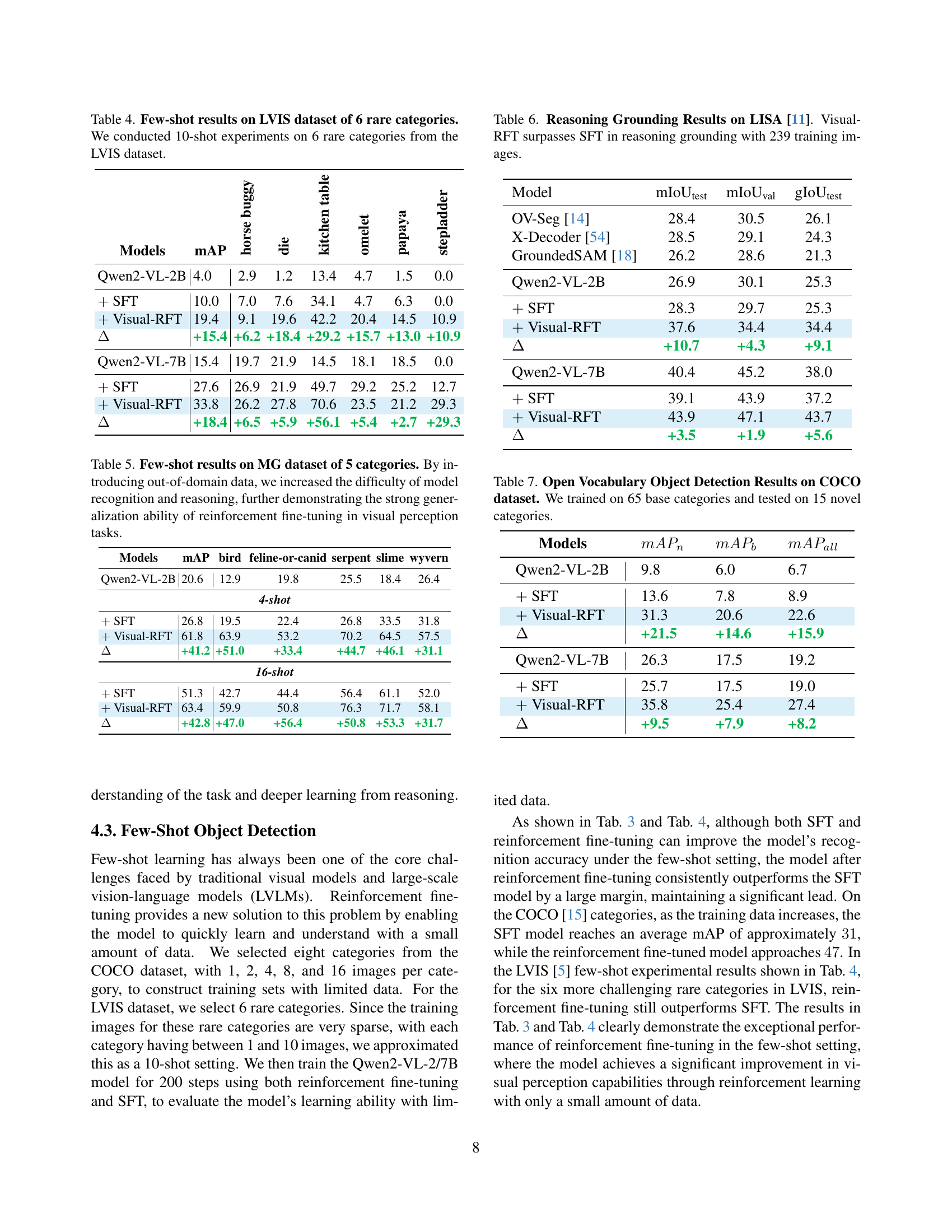
| Models | mAP | horse buggy | die | kitchen table | omelet | papaya | stepladder |
|---|---|---|---|---|---|---|---|
| Qwen2-VL-2B | 4.0 | 2.9 | 1.2 | 13.4 | 4.7 | 1.5 | 0.0 |
| SFT | 10.0 | 7.0 | 7.6 | 34.1 | 4.7 | 6.3 | 0.0 |
| Visual-RFT | 19.4 | 9.1 | 19.6 | 42.2 | 20.4 | 14.5 | 10.9 |
| +15.4 | +6.2 | +18.4 | +29.2 | +15.7 | +13.0 | +10.9 | |
| Qwen2-VL-7B | 15.4 | 19.7 | 21.9 | 14.5 | 18.1 | 18.5 | 0.0 |
| SFT | 27.6 | 26.9 | 21.9 | 49.7 | 29.2 | 25.2 | 12.7 |
| Visual-RFT | 33.8 | 26.2 | 27.8 | 70.6 | 23.5 | 21.2 | 29.3 |
| +18.4 | +6.5 | +5.9 | +56.1 | +5.4 | +2.7 | +29.3 |
🔼 This table presents the results of a few-shot object detection experiment conducted on the LVIS dataset. Specifically, it focuses on six rare categories within LVIS, evaluating the performance of different models (Qwen2-VL-2B and Qwen2-VL-7B) using both supervised fine-tuning (SFT) and the proposed Visual-RFT method. The experiment involved a 10-shot setting for each category, meaning 10 images per category were used for training. The table displays the mean average precision (mAP) and its breakdown across individual categories, revealing the effectiveness of Visual-RFT compared to SFT in handling data scarcity for object detection of rare items.
read the caption
Table 4: Few-shot results on LVIS dataset of 6 rare categories. We conducted 10-shot experiments on 6 rare categories from the LVIS dataset.
| Models | mAP | bird | feline-or-canid | serpent | slime | wyvern |
|---|---|---|---|---|---|---|
| Qwen2-VL-2B | 20.6 | 12.9 | 19.8 | 25.5 | 18.4 | 26.4 |
| 4-shot | ||||||
| SFT | 26.8 | 19.5 | 22.4 | 26.8 | 33.5 | 31.8 |
| Visual-RFT | 61.8 | 63.9 | 53.2 | 70.2 | 64.5 | 57.5 |
| +41.2 | +51.0 | +33.4 | +44.7 | +46.1 | +31.1 | |
| 16-shot | ||||||
| SFT | 51.3 | 42.7 | 44.4 | 56.4 | 61.1 | 52.0 |
| Visual-RFT | 63.4 | 59.9 | 50.8 | 76.3 | 71.7 | 58.1 |
| +42.8 | +47.0 | +56.4 | +50.8 | +53.3 | +31.7 | |
🔼 This table presents the results of a few-shot learning experiment on the Monster Girls (MG) dataset, which consists of five categories of anime-style monster girls. The experiment evaluates the performance of different models (Qwen2-VL-2B and Qwen2-VL-7B) under two settings: supervised fine-tuning (SFT) and Visual-RFT (Visual Reinforcement Fine-Tuning). The use of out-of-domain data (i.e., images outside the standard training categories) increases the complexity of object recognition and reasoning for the models. The table shows the mean average precision (mAP) for each model and setting, highlighting the improved generalization ability of Visual-RFT compared to SFT in challenging, out-of-domain visual tasks, even when data is scarce (4-shot and 16-shot settings). The mAP scores for each category (bird, feline-or-canid, serpent, slime, and wyvern) are also provided.
read the caption
Table 5: Few-shot results on MG dataset of 5 categories. By introducing out-of-domain data, we increased the difficulty of model recognition and reasoning, further demonstrating the strong generalization ability of reinforcement fine-tuning in visual perception tasks.
| Model | mIoU | mIoU | gIoU |
|---|---|---|---|
| OV-Seg [14] | 28.4 | 30.5 | 26.1 |
| X-Decoder [54] | 28.5 | 29.1 | 24.3 |
| GroundedSAM [18] | 26.2 | 28.6 | 21.3 |
| Qwen2-VL-2B | 26.9 | 30.1 | 25.3 |
| SFT | 28.3 | 29.7 | 25.3 |
| Visual-RFT | 37.6 | 34.4 | 34.4 |
| +10.7 | +4.3 | +9.1 | |
| Qwen2-VL-7B | 40.4 | 45.2 | 38.0 |
| SFT | 39.1 | 43.9 | 37.2 |
| Visual-RFT | 43.9 | 47.1 | 43.7 |
| +3.5 | +1.9 | +5.6 |
🔼 This table presents the results of reasoning grounding experiments conducted on the LISA dataset [11]. The experiment used 239 training images. It compares the performance of Visual-RFT (Visual Reinforcement Fine-Tuning) against Supervised Fine-Tuning (SFT). The comparison is done across three different evaluation metrics: mIoUtest, mIoUval, and gIoUtest. The table shows that Visual-RFT achieves superior results compared to SFT on all metrics, indicating its improved ability in reasoning grounding tasks.
read the caption
Table 6: Reasoning Grounding Results on LISA [11]. Visual-RFT surpasses SFT in reasoning grounding with 239 training images.
| Models | |||
|---|---|---|---|
| Qwen2-VL-2B | 9.8 | 6.0 | 6.7 |
| SFT | 13.6 | 7.8 | 8.9 |
| Visual-RFT | 31.3 | 20.6 | 22.6 |
| +21.5 | +14.6 | +15.9 | |
| Qwen2-VL-7B | 26.3 | 17.5 | 19.2 |
| SFT | 25.7 | 17.5 | 19.0 |
| Visual-RFT | 35.8 | 25.4 | 27.4 |
| +9.5 | +7.9 | +8.2 |
🔼 This table presents the results of an open vocabulary object detection experiment conducted on the MS COCO dataset. The model was initially trained on 65 common object categories. Subsequently, its performance was evaluated on 15 novel (unseen during training) categories to assess its generalization capabilities in identifying objects outside its initial training scope. The table likely shows various metrics such as mean Average Precision (mAP) to quantify the model’s accuracy and performance on these novel categories, comparing different model variations or training strategies.
read the caption
Table 7: Open Vocabulary Object Detection Results on COCO dataset. We trained on 65 base categories and tested on 15 novel categories.
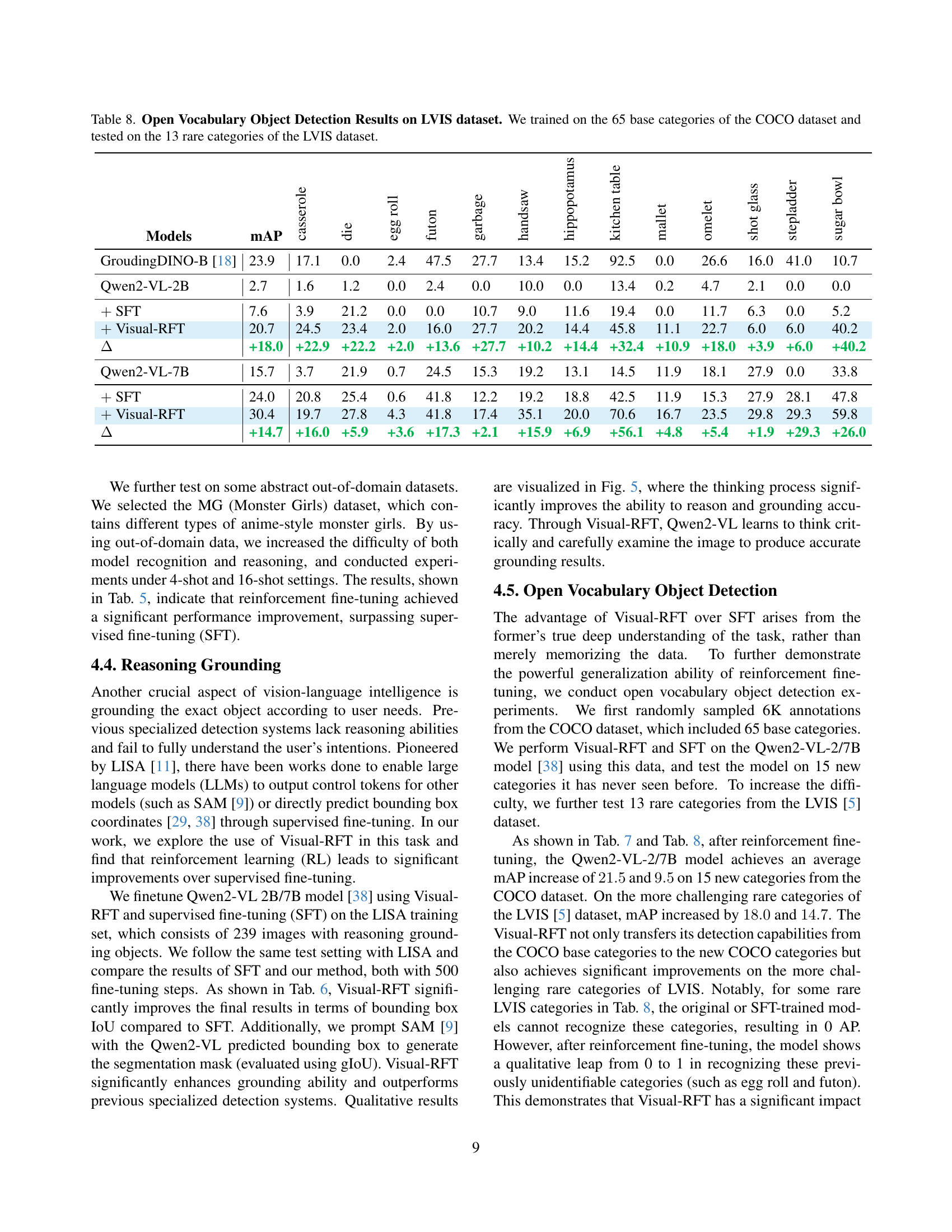
| Models | mAP | casserole | die | egg roll | futon | garbage | handsaw | hippopotamus | kitchen table | mallet | omelet | shot glass | stepladder | sugar bowl |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GroudingDINO-B [18] | 23.9 | 17.1 | 0.0 | 2.4 | 47.5 | 27.7 | 13.4 | 15.2 | 92.5 | 0.0 | 26.6 | 16.0 | 41.0 | 10.7 |
| Qwen2-VL-2B | 2.7 | 1.6 | 1.2 | 0.0 | 2.4 | 0.0 | 10.0 | 0.0 | 13.4 | 0.2 | 4.7 | 2.1 | 0.0 | 0.0 |
| SFT | 7.6 | 3.9 | 21.2 | 0.0 | 0.0 | 10.7 | 9.0 | 11.6 | 19.4 | 0.0 | 11.7 | 6.3 | 0.0 | 5.2 |
| Visual-RFT | 20.7 | 24.5 | 23.4 | 2.0 | 16.0 | 27.7 | 20.2 | 14.4 | 45.8 | 11.1 | 22.7 | 6.0 | 6.0 | 40.2 |
| +18.0 | +22.9 | +22.2 | +2.0 | +13.6 | +27.7 | +10.2 | +14.4 | +32.4 | +10.9 | +18.0 | +3.9 | +6.0 | +40.2 | |
| Qwen2-VL-7B | 15.7 | 3.7 | 21.9 | 0.7 | 24.5 | 15.3 | 19.2 | 13.1 | 14.5 | 11.9 | 18.1 | 27.9 | 0.0 | 33.8 |
| SFT | 24.0 | 20.8 | 25.4 | 0.6 | 41.8 | 12.2 | 19.2 | 18.8 | 42.5 | 11.9 | 15.3 | 27.9 | 28.1 | 47.8 |
| Visual-RFT | 30.4 | 19.7 | 27.8 | 4.3 | 41.8 | 17.4 | 35.1 | 20.0 | 70.6 | 16.7 | 23.5 | 29.8 | 29.3 | 59.8 |
| +14.7 | +16.0 | +5.9 | +3.6 | +17.3 | +2.1 | +15.9 | +6.9 | +56.1 | +4.8 | +5.4 | +1.9 | +29.3 | +26.0 |
🔼 This table presents the results of an open vocabulary object detection experiment on the LVIS dataset. The model was initially trained on 65 common categories from the COCO dataset, and then its performance was evaluated on 13 rare categories from the LVIS dataset that were not included in the initial training. The results show the mean Average Precision (mAP) for different models, comparing the baseline performance (Qwen2-VL-2B) against the performance after supervised fine-tuning (SFT) and visual reinforcement fine-tuning (Visual-RFT). The table demonstrates the effectiveness of Visual-RFT in handling rare and unseen object categories.
read the caption
Table 8: Open Vocabulary Object Detection Results on LVIS dataset. We trained on the 65 base categories of the COCO dataset and tested on the 13 rare categories of the LVIS dataset.
Full paper#