TL;DR#
Recurrent sequence models use forget gates to manage information, while Transformers lack an explicit forgetting mechanism, potentially limiting their ability to handle long sequences effectively. Current models also suffer in long-context tasks. Addressing these issues is crucial for advancing sequence modeling capabilities. This paper explores integrating a forget gate into the Transformer architecture to improve its ability to process long-range dependencies.
The paper introduces the Forgetting Transformer (FoX), which incorporates a forget gate into the softmax attention mechanism by down-weighting unnormalized attention scores. FoX outperforms the standard Transformer on long-context language modeling and length extrapolation tasks. It’s also compatible with FlashAttention. FoX retains retrieval abilities and achieves near-perfect accuracy in the needle-in-the-haystack test. The Pro block improves both FoX and Transformer.
Key Takeaways#
Why does it matter?#
This paper introduces a novel attention mechanism, potentially influencing future architectures. The Forgetting Transformer’s superior performance and ability to incorporate forget gates and hardware-aware implementation offer valuable insights for the community. It addresses the limitations of transformers, opening new research.
Visual Insights#

🔼 Figure 1 illustrates the architecture of the Forgetting Transformer (FoX) model. The left panel shows a single FoX block, a fundamental building block of the model, consisting of a multi-head self-attention mechanism, followed by a feed-forward network. The right panel presents a single FoX (Pro) layer, an enhanced layer incorporating additional architectural components often found in recurrent sequence models for improved performance. These components include output gates for regulating the output of each layer and QK-norm (query-key normalization) for better attention score normalization. Both diagrams show how operations such as RMSNorm (Root Mean Square Layer Normalization), sigmoid activation (σ), and element-wise multiplication are utilized within each block and layer. The ShiftLinear operation, as detailed in Equation 14 of the paper, processes the key inputs to add a recency bias, making recent information more influential in the attention mechanism. All RMSNorm operations in the (Pro) layer are applied independently to each head.
read the caption
Figure 1: Default architecture of FoX. (left) A single FoX block. (right) A single FoX (Pro) layer. All RMSNorms on the right are applied independently to each head. σ𝜎\sigmaitalic_σ is the sigmoid function. ⊗tensor-product\otimes⊗ is element-wise multiplication. ShiftLinear implements the computation in Equation 14.
| Model | Wiki. | LMB. | LMB. | PIQA | Hella. | Wino. | ARC-e | ARC-c | COPA | OBQA | SciQA | BoolQ | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ppl | ppl | acc | acc | acc-n | acc | acc | acc-n | acc | acc-n | acc | acc | ||
| FoX (Pro) | 23.04 | 14.91 | 42.75 | 64.09 | 38.39 | 52.33 | 52.23 | 26.54 | 71.00 | 29.80 | 85.10 | 46.57 | 50.88 |
| Transformer (Pro) | 24.12 | 16.16 | 41.47 | 64.04 | 36.60 | 49.72 | 51.98 | 25.26 | 62.00 | 29.20 | 82.80 | 60.86 | 50.39 |
| FoX (LLaMA) | 26.45 | 18.27 | 40.17 | 63.44 | 35.17 | 51.78 | 49.66 | 25.09 | 69.00 | 28.00 | 81.90 | 54.04 | 49.82 |
| Transformer (LLaMA) | 28.14 | 22.34 | 38.27 | 63.22 | 34.20 | 49.49 | 47.98 | 24.49 | 66.00 | 29.40 | 78.90 | 58.93 | 49.09 |
| Mamba-2 | 28.20 | 21.05 | 36.50 | 63.17 | 35.86 | 50.59 | 49.96 | 25.60 | 71.00 | 31.00 | 80.90 | 57.49 | 50.21 |
| HGRN2 | 30.57 | 20.14 | 38.60 | 63.49 | 34.94 | 51.78 | 50.13 | 25.51 | 66.00 | 30.00 | 75.60 | 58.41 | 49.45 |
| DeltaNet | 29.17 | 29.14 | 34.27 | 62.73 | 33.28 | 50.28 | 47.39 | 24.32 | 70.00 | 29.00 | 74.30 | 54.37 | 47.99 |
🔼 Table 1 presents the zero-shot performance of various language models on a range of short-context downstream tasks from the LM-evaluation-harness benchmark. The models all share approximately 760M non-embedding parameters and were trained on roughly 48 billion tokens of the LongCrawl64 dataset. The table displays the results for various tasks, comparing perplexity scores (lower is better) for language modeling tasks and accuracy scores (higher is better) for other tasks. Length-normalized accuracy (‘acc-n’) is also shown for some tasks, accounting for variations in task difficulty based on sequence length. The best and second-best performance for each task is highlighted in bold and underlined text, respectively.
read the caption
Table 1: Evaluation results on LM-eval-harness. All models have roughly 760760760760M non-embedding parameters and are trained on roughly 48484848B tokens on LongCrawl64. “acc-n” means length-normalized accuracy. Bold and underlined numbers indicate the best and the second best results, respectively.
In-depth insights#
FoX: Forgetful Attn#
The idea of a ‘Forgetful Attention’ (FoX) is intriguing, suggesting an attention mechanism with a capacity to selectively discard information. This could address a key limitation in standard attention, where all prior context is treated equally. FoX could enhance long-range dependency modeling by mitigating the noise from irrelevant tokens. It is key that FoX enables models to dynamically manage their context window, focusing on pertinent data. It’d be important to understand the criteria by which FoX decides what to forget, and prevent catastrophic forgetting, while maintaining stability. Overall, the concept of Forgetful Attention represents a promising direction for improving efficiency and robustness of attention mechanisms, thus making it a powerful architecture.
Gates Beat RoPE#
The potential claim “Gates Beat RoPE” suggests a performance comparison where attention mechanisms employing gating mechanisms outperform Rotary Position Embeddings (RoPE) in a specific context. This might involve tasks where dynamic context management is crucial, as gates can selectively filter information. RoPE, while efficient, offers a fixed positional encoding, lacking the adaptability of gates. The context is still important. The success is also dependent on the design. This could manifest as superior performance on long-context tasks, improved handling of irrelevant information, or better generalization to varying sequence lengths. The claim highlights gates’ ability to dynamically modulate information flow within the Transformer architecture to the effectiveness RoPE, but the implementation of gates are also very important.
Long Context FoX#
When considering “Long Context FoX,” several aspects become crucial. FoX’s ability to handle extended sequences is likely a core focus, examining how it manages information across very long input windows. The retention of relevant information and the efficient forgetting of irrelevant details are essential for effective long-context processing. Evaluation metrics would likely emphasize performance on tasks requiring reasoning over long dependencies, comparing FoX against both Transformers and recurrent models. A key consideration is the computational cost associated with long contexts; strategies for maintaining efficiency while processing extensive data would be vital.
Parallel Recurrence#
Parallel recurrence could refer to methods enabling simultaneous computation across sequential data, which is traditionally processed one step at a time. In neural networks, this could involve transforming recurrent layers (like LSTMs or GRUs) into forms suitable for parallel processing on GPUs or specialized hardware. The core idea is to reformulate the sequential dependencies so that multiple time steps can be calculated concurrently, leading to significant speedups. This might involve techniques like approximating recurrent connections, using attention mechanisms to capture long-range dependencies in parallel, or employing state-space models that have efficient parallel implementations. The challenge lies in maintaining the representational power and sequential nature of recurrence while unlocking the benefits of parallel computation.
Hardware Is Key#
Hardware optimization is crucial for advancing deep learning. Specialized hardware, like GPUs and TPUs, significantly accelerates training and inference, allowing for larger models and datasets. Algorithmic innovations must be designed with hardware capabilities and limitations in mind to achieve real-world performance gains. Furthermore, efficient memory management and parallel processing are key to maximizing hardware utilization. The development of novel hardware architectures tailored to specific deep learning tasks promises even greater performance improvements, enabling the deployment of AI in resource-constrained environments.
More visual insights#
More on figures

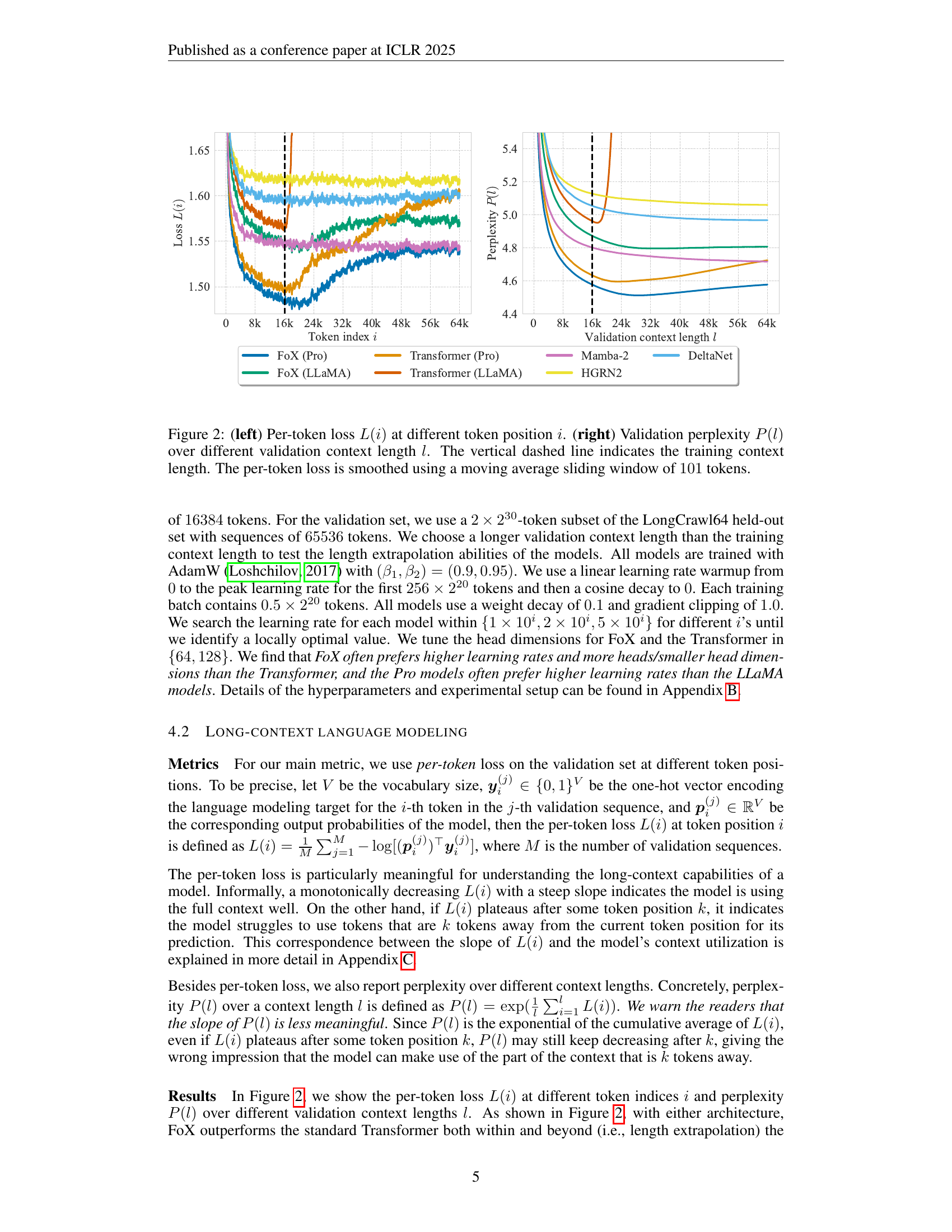
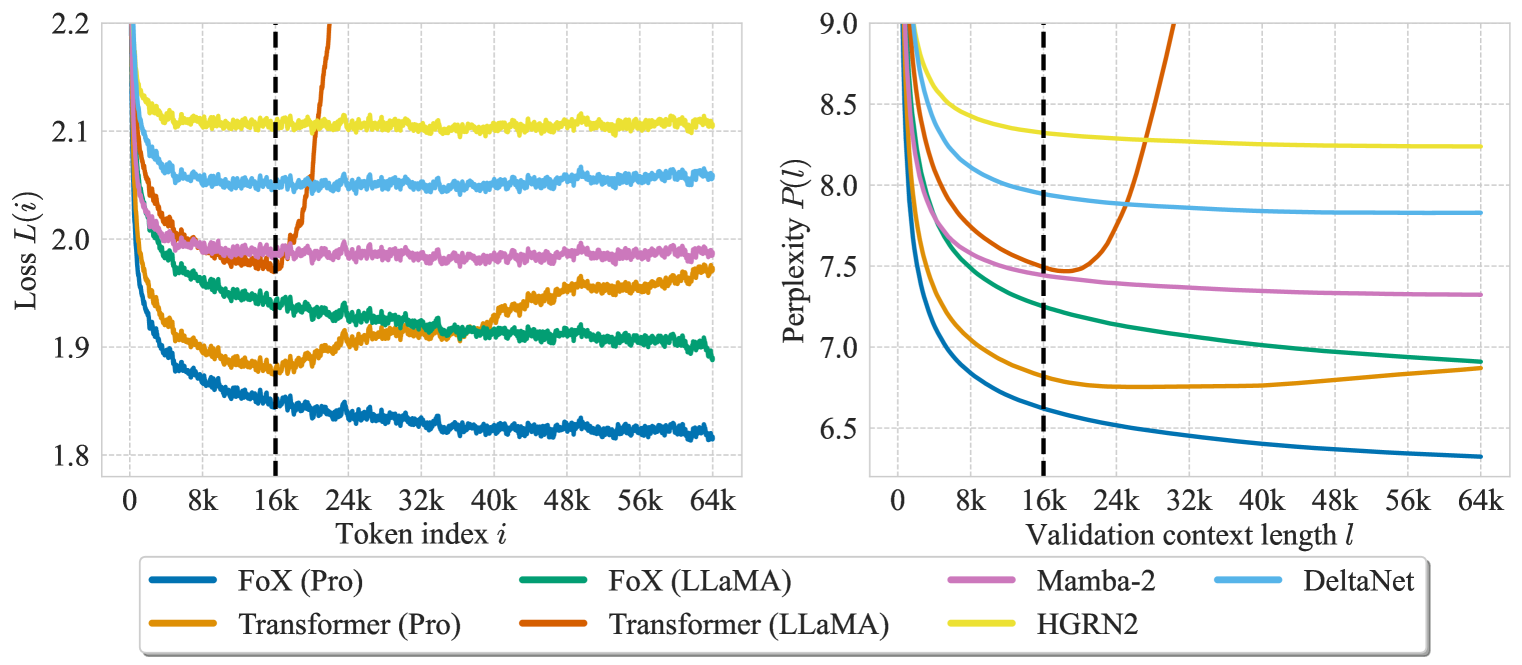
🔼 Figure 2 presents a comparison of the Forgetting Transformer (FoX) and the standard Transformer, and also several recurrent models (Mamba-2, HGRN2, DeltaNet), on long-context language modeling. The left panel shows the per-token loss (L(i)) plotted against the token position (i) within a validation sequence. A lower loss indicates better performance. The right panel shows validation perplexity (P(l)) which is the average loss over a given context length (l). Lower perplexity means better performance. The dashed vertical line in both panels denotes the length of the context seen during training. The per-token loss curves are smoothed using a moving average to reduce noise.
read the caption
Figure 2: (left) Per-token loss L(i)𝐿𝑖L(i)italic_L ( italic_i ) at different token position i𝑖iitalic_i. (right) Validation perplexity P(l)𝑃𝑙P(l)italic_P ( italic_l ) over different validation context length l𝑙litalic_l. The vertical dashed line indicates the training context length. The per-token loss is smoothed using a moving average sliding window of 101101101101 tokens.

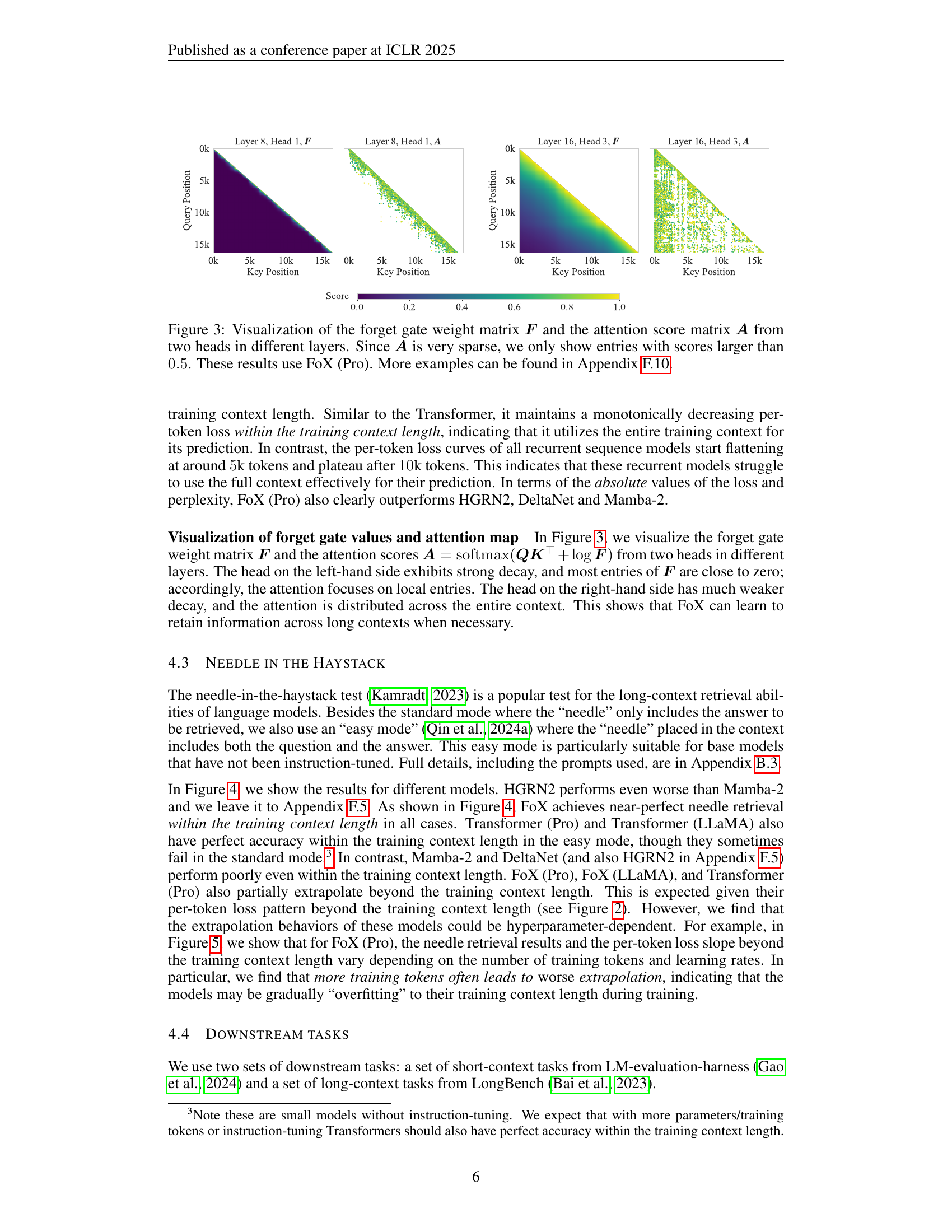
🔼 This figure visualizes the forget gate weight matrix (F) and the attention score matrix (A) from two different layers of the Forgetting Transformer (FoX) model. The heatmaps show how the forget gate mechanism modulates attention weights. Because the attention score matrix (A) is sparse, only the entries with scores above 0.5 are displayed. This visualization helps to understand how the model’s attention is influenced by the forget gate, allowing it to selectively focus on relevant parts of the input sequence and effectively ‘forget’ less relevant information.
read the caption
Figure 3: Visualization of the forget gate weight matrix 𝑭𝑭{\bm{F}}bold_italic_F and the attention score matrix 𝑨𝑨{\bm{A}}bold_italic_A from two heads in different layers. Since 𝑨𝑨{\bm{A}}bold_italic_A is very sparse, we only show entries with scores larger than 0.50.50.50.5. These results use FoX (Pro). More examples can be found in Appendix F.10.
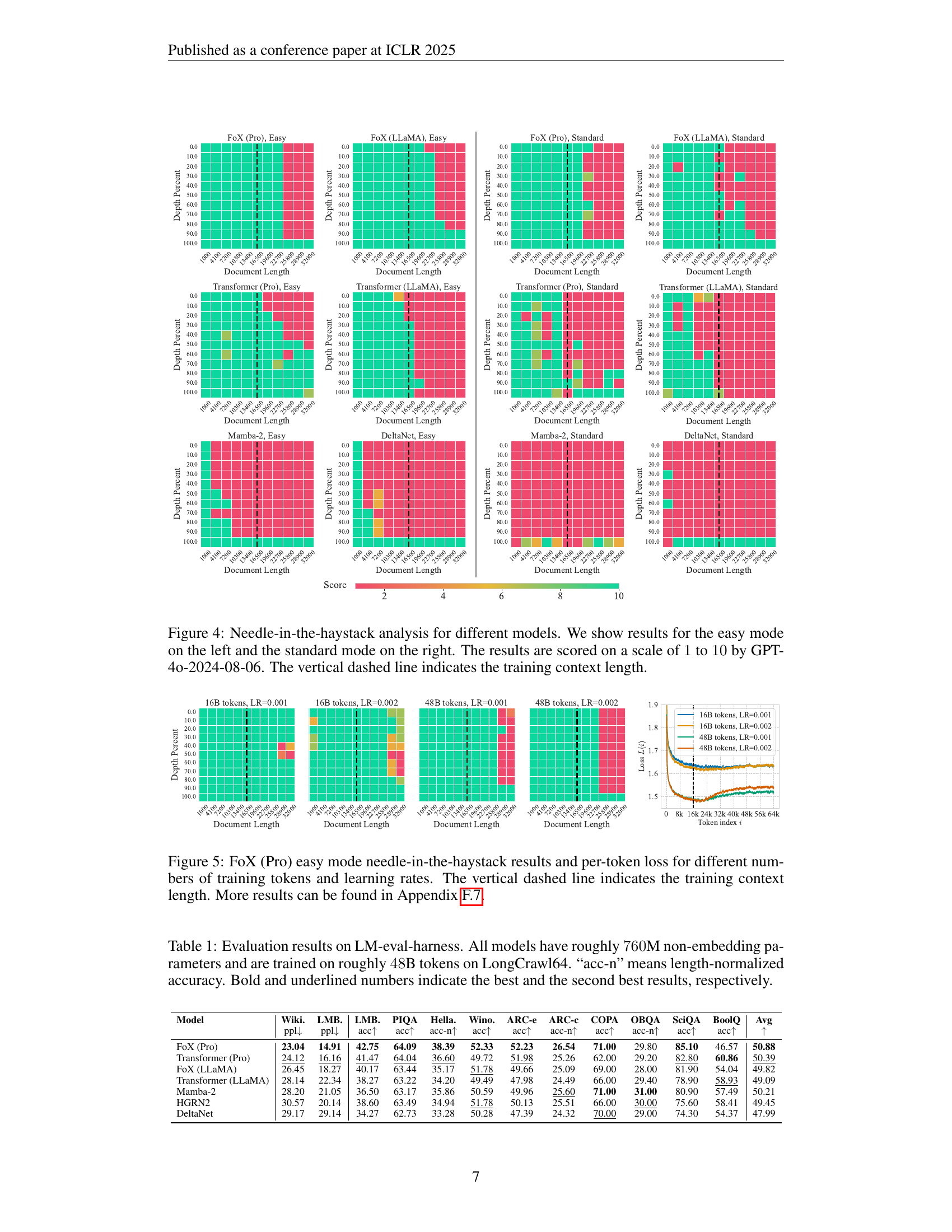
🔼 This figure displays the results of a needle-in-the-haystack test, which evaluates a language model’s ability to retrieve specific information from a long sequence of text. The test is performed using two different modes: an ’easy mode’ and a ‘standard mode’. In the easy mode, both the question and the answer are explicitly present in the context. In the standard mode, only the answer is present. The model’s success rate in each mode is presented as a heatmap, where different colors represent different accuracy scores. Scores range from 1 to 10 and were determined by GPT-4. The vertical dashed line in each heatmap represents the length of the training context used to train the model. By comparing performance across the two modes and different context lengths, we can gain insight into the model’s long-context retrieval capabilities.
read the caption
Figure 4: Needle-in-the-haystack analysis for different models. We show results for the easy mode on the left and the standard mode on the right. The results are scored on a scale of 1111 to 10101010 by GPT-4o-2024-08-06. The vertical dashed line indicates the training context length.

🔼 This figure displays the results of the ’needle in the haystack’ experiment, a test of long-context retrieval capabilities, using the Forgetting Transformer (FoX) model. It shows the accuracy of the model at retrieving information from a long document. The ’easy mode’ of the experiment includes both the question and answer in the ’needle.’ The figure also presents the per-token loss, which measures how well the model uses context at various distances from the predicted token. Different lines correspond to different numbers of training tokens and learning rates, allowing for the comparison of training data quantity and rate on the performance and loss. The dashed line indicates where the training context ends.
read the caption
Figure 5: FoX (Pro) easy mode needle-in-the-haystack results and per-token loss for different numbers of training tokens and learning rates. The vertical dashed line indicates the training context length. More results can be found in Appendix F.7.

🔼 Figure 6 illustrates the impact of model size, training data size, and training context length on the per-token loss of language models. The plots show the average loss calculated across a 101-token sliding window for each token position. Results are shown only for token positions within the training context length to improve clarity, but Appendix F.6 provides additional results, including an analysis of length extrapolation and results for a 125M parameter model.
read the caption
Figure 6: Per-token loss given different model sizes, numbers of training tokens, and training context lengths. At each token index i𝑖iitalic_i, we report the averaged loss over a window of 101101101101 centered at i𝑖iitalic_i. We only show results within the training context length to reduce visual clutter. See Appendix F.6 for additional results, including length extrapolation and 125M-parameter model results.
🔼 Figure 7 compares the performance of different forget gate mechanisms in the Forgetting Transformer model. It contrasts data-dependent, data-independent, and fixed forget gates across two model architectures: the LLaMA and Pro architectures. The results show the per-token loss for each configuration, calculated using a 360M parameter model trained on 7.5B tokens of the LongCrawl64 dataset. Smoothing is applied to the loss curves using a moving average over 1001 tokens. The training context length is marked by a dashed vertical line.
read the caption
Figure 7: Data-dependent forget gate (data-dep) vs. data-independent (data-indep) and fixed forget gate. (left and middle-left) Comparison using the LLaMA architecture. (middle-right and right) Comparison using the Pro architecture. We use 360360360360M-parameter models trained on roughly 7.57.57.57.5B tokens on LongCrawl64. All per-token loss curves are smoothed with a moving average sliding window of 1001100110011001 tokens. The vertical dashed line indicates the training context length.
More on tables
| Model | Single-Document QA | Multi-Document QA | Summarization | Few-shot Learning | Code | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
NarrativeQA | Qasper | MFQA | HotpotQA | 2WikiMQA | Musique | GovReport | QMSum | MultiNews | TREC | TriviaQA | SamSum | LCC | RepoBench-P | |
| FoX (Pro) | 13.38 | 18.88 | 28.73 | 15.27 | 25.39 | 6.49 | 22.71 | 13.51 | 12.27 | 63.5 | 37.36 | 22.74 | 10.9 | 9.1 |
| Transformer (Pro) | 11.42 | 21.54 | 22.89 | 19.58 | 22.65 | 6.09 | 21.92 | 10.7 | 8.11 | 55.0 | 40.67 | 30.66 | 10.79 | 14.25 |
| FoX (LLaMA) | 10.47 | 14.81 | 24.71 | 13.03 | 21.58 | 5.25 | 20.05 | 10.97 | 4.86 | 61.5 | 34.48 | 19.13 | 7.69 | 8.12 |
| Transformer (LLaMA) | 11.11 | 13.5 | 21.52 | 9.42 | 21.33 | 4.32 | 18.53 | 8.43 | 10.99 | 51.5 | 28.41 | 19.17 | 8.21 | 14.06 |
| Mamba-2 | 10.65 | 11.26 | 16.98 | 11.59 | 16.69 | 5.0 | 9.31 | 11.22 | 10.89 | 28.5 | 15.6 | 16.19 | 12.07 | 15.17 |
| HGRN2 | 8.78 | 10.94 | 18.66 | 7.78 | 15.29 | 4.32 | 6.13 | 12.19 | 7.83 | 16.5 | 14.46 | 6.37 | 18.17 | 16.62 |
| DeltaNet | 9.36 | 9.76 | 16.49 | 6.57 | 15.09 | 2.76 | 8.19 | 12.3 | 7.62 | 35.5 | 17.57 | 18.42 | 12.24 | 3.94 |
🔼 This table presents the performance of various language models on the LongBench benchmark. Each model has approximately 760 million non-embedding parameters and was trained on roughly 48 billion tokens from the LongCrawl64 dataset. The table shows the results for a range of downstream tasks, allowing for a comparison of the models’ performance across different types of long-context understanding challenges. The best and second-best results for each task are highlighted in bold and underlined, respectively.
read the caption
Table 2: Evalution results on LongBench. All models have roughly 760760760760M non-embedding parameters and are trained on roughly 48484848B tokens on LongCrawl64. Bold and underlined numbers indicate the best and the second-best results, respectively.
| Model | RoPE | Forget gate | QK-norm | Output gate | Output norm | KV-shift | Perplexity |
|---|---|---|---|---|---|---|---|
| Transformer (LLaMA) w/o RoPE | 29.30 | ||||||
| Transformer (LLaMA) | ✓ | 7.49 | |||||
| ✓ | ✓ | 7.19 | |||||
| FoX (LLaMA) | ✓ | 7.25 | |||||
| ✓ | ✓ | 7.08 | |||||
| ✓ | ✓ | ✓ | 6.88 | ||||
| ✓ | ✓ | ✓ | ✓ | 6.80 | |||
| FoX (Pro) | ✓ | ✓ | ✓ | ✓ | ✓ | 6.62 | |
| - QK-norm | ✓ | ✓ | ✓ | ✓ | 6.79 | ||
| - output gate | ✓ | ✓ | ✓ | ✓ | 6.86 | ||
| - output norm | ✓ | ✓ | ✓ | ✓ | 6.69 | ||
| - KV-shift | ✓ | ✓ | ✓ | ✓ | 6.80 | ||
| + RoPE | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 6.63 |
| - forget gate + RoPE (i.e. Transformer (Pro)) | ✓ | ✓ | ✓ | ✓ | ✓ | 6.82 | |
| - forget gate | ✓ | ✓ | ✓ | ✓ | 7.40 |
🔼 This ablation study investigates the impact of individual components within the Forgetting Transformer (FoX) model. Using 360M parameter models trained on a 7.5B token subset of the LongCrawl64 dataset, the experiment measures the validation perplexity on a 16384-token context length. The bottom half of the table shows incremental additions and removals of components, comparing the results against the baseline FoX (Pro) model. This allows for a precise understanding of each component’s contribution to the model’s overall performance.
read the caption
Table 3: Ablation experiments for FoX. We use 360360360360M-parameter models trained on 7.57.57.57.5B tokens on LongCrawl64. The perplexity is measured over a validation context length of 16384163841638416384 tokens. For the bottom half, all addition (+) or removal (-) of components are relative to FoX (Pro).
| Configuration | Peak learning rate | |||
|---|---|---|---|---|
| 760M params / 48B tokens | 24 | 1536 | 64 for FoX, 128 for Transformer | See Table 5 |
| 760M params / 16B tokens | 24 | 1536 | 64 for FoX, 128 for Transformer | |
| 360M params / 7.5B tokens | 24 | 1024 | 64 | |
| 125M params / 2.7B tokens | 12 | 768 | 64 |
🔼 This table details the hyperparameters used for various model configurations in the experiments. It shows the different settings for model size (number of parameters), training data size (number of tokens), the number of layers, and the head dimension (d_head). The head dimension is only relevant to the FoX and Transformer models, and the authors tuned its value within the set {64, 128} for the 760M parameter models. The number of layers (n_layer) indicates the total number of blocks in the model; for the Transformer, each block consists of one attention layer and one multi-layer perceptron (MLP) layer.
read the caption
Table 4: Hyperparameters for different configurations. The head dimension dheadsubscript𝑑headd_{\text{head}}italic_d start_POSTSUBSCRIPT head end_POSTSUBSCRIPT is only applicable to FoX and the Transformer. We tune dheadsubscript𝑑headd_{\text{head}}italic_d start_POSTSUBSCRIPT head end_POSTSUBSCRIPT for the 760M-parameter FoX and Transformer models in {64,128}64128\{64,128\}{ 64 , 128 }. nlayersubscript𝑛layern_{\text{layer}}italic_n start_POSTSUBSCRIPT layer end_POSTSUBSCRIPT counts the number of blocks. For example, for the Transformer each block contains an attention layer and an MLP layer.
| Model | Learning rate |
|---|---|
| FoX (Pro) | |
| Transformer (Pro) | |
| FoX (LLaMA) | |
| Transformer (LLaMA) | |
| Mamba-2 | |
| HGRN2 | |
| DeltaNet |
🔼 This table shows the peak learning rates used for various language models in the main experiments. All models used in the main experiments had 760 million parameters and were trained on 48 billion tokens. The learning rates were determined through a hyperparameter search. The search involved testing various learning rates, each multiplied by 1, 2, and 5, which are presented in scientific notation using a power of 10 (10i, 2 × 10i, and 5 × 10i, where i is an integer representing a different magnitude of the learning rate).
read the caption
Table 5: Peak learning rates for different models for the 760M-parameter/48B-token main experiments. These are tuned using a grid {1×10i,2×10i,5×10i}1superscript10𝑖2superscript10𝑖5superscript10𝑖\{1\times 10^{i},2\times 10^{i},5\times 10^{i}\}{ 1 × 10 start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT , 2 × 10 start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT , 5 × 10 start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT } with different values of i𝑖iitalic_i.
| Model | Params | Forward FLOPs/token | Formula for FLOPs/token | Throughput (tokens/sec) |
|---|---|---|---|---|
| FoX (Pro) | 759M | 27k | ||
| Transformer (Pro) | 757M | 30k | ||
| FoX (LLaMA) | 757M | 30k | ||
| Transformer (LLaMA) | 756M | 38k | ||
| Mamba-2 | 780M | 44k | ||
| HGRN2 | 756M | 46k | ||
| DeltaNet | 757M | 48k |
🔼 This table presents a quantitative comparison of different language models in terms of their computational efficiency and training speed. It lists the number of parameters (N), the estimated floating-point operations per token (FLOPs) for a forward pass, the formulas used to calculate these FLOPs, and the training throughput measured in tokens per second on hardware with 4 NVIDIA L40S GPUs. The FLOPs and throughput values provide insights into the computational cost and speed of training each model. The formulas offer further details on the calculation methodology, highlighting the dependencies on the number of parameters (N) and training context length (L). This allows for a comprehensive evaluation of each model’s efficiency and scalability.
read the caption
Table 6: Number of parameters, estimated forward pass FLOPs per token, formulas for FLOPs estimation, and training throughput in tokens per second for different models. Throughput is measured on 4 NVIDIA L40S GPUs. N𝑁Nitalic_N is the number of parameters and L𝐿Litalic_L is the training context length.
| Model | Wiki. | LMB. | LMB. | PIQA | Hella. | Wino. | ARC-e | ARC-c | Avg |
| ppl | ppl | acc | acc | acc-n | acc | acc | acc-n | ||
| Transformer++ (Yang et al., 2024) | 28.39 | 42.69 | 31.00 | 63.30 | 34.00 | 50.40 | 44.50 | 24.20 | 41.23 |
| DeltaNet (Yang et al., 2024) | 28.24 | 37.37 | 32.10 | 64.80 | 34.30 | 52.20 | 45.80 | 23.20 | 42.07 |
| FoX (Pro) | 25.69 | 31.98 | 35.82 | 65.61 | 36.39 | 51.07 | 45.79 | 25.09 | 43.29 |
| Transformer (Pro) | 25.92 | 31.93 | 35.01 | 65.02 | 36.09 | 50.51 | 46.42 | 23.38 | 42.74 |
| FoX (LLaMA) | 27.86 | 43.26 | 32.56 | 64.80 | 34.59 | 50.12 | 45.12 | 23.38 | 41.76 |
| Transformer (LLaMA) | 27.98 | 35.25 | 32.31 | 63.71 | 34.89 | 48.07 | 45.33 | 23.72 | 41.34 |
| Mamba-2 | 27.51 | 41.32 | 29.83 | 65.94 | 35.95 | 50.20 | 45.45 | 23.72 | 41.85 |
🔼 This table presents the results of several language models evaluated on the LM-eval-harness benchmark. The models were trained on the SlimPajama dataset with a training context length of 2048 tokens. All models have approximately 340 million non-embedding parameters and were trained on about 15 billion tokens of SlimPajama data. The evaluation metrics include perplexity (ppl) and accuracy (acc) for various tasks. Length-normalized accuracy (acc-n) is also reported for some tasks. The best and second-best results for each task are highlighted in bold and underlined, respectively. Note that some results (Transformer++, DeltaNet) are taken from a previous publication (Yang et al., 2024) for comparison purposes. The Transformer++ model from Yang et al. (2024) is architecturally identical to the Transformer (LLaMA) model used in this paper.
read the caption
Table 7: Evaluation results on LM-eval-harness for models trained on SlimPajama with a training context length of 2048204820482048 tokens. All models have roughly 340340340340M non-embedding parameters and are trained on roughly 15151515B tokens on SlimPajama. “acc-n” means length-normalized accuracy. Bold and underlined numbers indicate the best and the second best results, respectively. Note the results for Transformer++ and DeltaNet are from Yang et al. (2024). Note that Transformer++ from Yang et al. (2024) and Transformer (LLaMA) in our work have exactly the same architecture.
| Model | Wiki. | LMB. | LMB. | PIQA | Hella. | Wino. | ARC-e | ARC-c | COPA | OBQA | SciQA | BoolQ | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ppl | ppl | acc | acc | acc-n | acc | acc | acc-n | acc | acc-n | acc | acc | ||
| FoX (Pro) | 28.10 | 23.67 | 36.93 | 61.64 | 33.44 | 49.72 | 47.94 | 23.98 | 65.00 | 26.80 | 80.40 | 57.49 | 48.33 |
| Transformer (Pro) | 28.17 | 24.63 | 36.17 | 61.53 | 33.46 | 50.28 | 47.81 | 24.15 | 67.00 | 28.40 | 77.90 | 55.72 | 48.24 |
| FoX (LLaMA) | 31.03 | 28.41 | 34.89 | 61.21 | 32.27 | 50.51 | 46.68 | 24.06 | 67.00 | 29.60 | 77.30 | 61.07 | 48.46 |
| Transformer (LLaMA) | 32.33 | 34.41 | 32.41 | 60.94 | 31.68 | 49.96 | 45.62 | 23.63 | 64.00 | 28.60 | 74.00 | 60.06 | 47.09 |
| Samba | 31.71 | 27.78 | 34.25 | 60.45 | 32.88 | 51.70 | 49.03 | 24.32 | 61.00 | 28.20 | 78.80 | 60.58 | 48.12 |
| Transformer-SWA (LLaMA) | 33.63 | 33.04 | 33.15 | 60.01 | 31.83 | 51.14 | 46.93 | 23.38 | 62.00 | 27.40 | 76.70 | 54.62 | 46.72 |
| Mamba-2 | 33.26 | 42.38 | 27.29 | 60.83 | 32.03 | 50.67 | 46.21 | 23.55 | 64.00 | 28.40 | 76.70 | 57.61 | 46.73 |
🔼 This table presents the results of evaluating various language models on the LM-eval-harness benchmark. All models in the comparison have approximately 760 million non-embedding parameters and were trained on roughly 16 billion tokens from the LongCrawl64 dataset. The benchmark assesses performance across several tasks. Length-normalized accuracy (‘acc-n’) is reported for tasks where sequence length affects the score. The best-performing model for each task is indicated in bold and underlined, along with the second-best performing model.
read the caption
Table 8: Evaluation results on LM-eval-harness. All models have roughly 760760760760M non-embedding parameters and are trained on roughly 16161616B tokens on LongCrawl64. “acc-n” means length-normalized accuracy. Bold and underlined numbers indicate the best and the second best results, respectively.
| Model | Single-Document QA | Multi-Document QA | Summarization | Few-shot Learning | Code | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
NarrativeQA | Qasper | MFQA | HotpotQA | 2WikiMQA | Musique | GovReport | QMSum | MultiNews | TREC | TriviaQA | SamSum | LCC | RepoBench-P | |
| FoX (Pro) | 10.48 | 12.98 | 20.62 | 6.87 | 16.2 | 5.48 | 27.51 | 10.15 | 9.27 | 63.5 | 26.97 | 18.02 | 6.34 | 3.4 |
| Transformer (Pro) | 8.67 | 13.92 | 22.45 | 9.36 | 14.21 | 5.16 | 19.88 | 10.66 | 12.23 | 52.0 | 30.18 | 25.53 | 8.37 | 10.72 |
| FoX (LLaMA) | 9.48 | 15.55 | 17.13 | 5.26 | 15.78 | 3.78 | 21.95 | 10.59 | 8.63 | 29.0 | 19.16 | 10.07 | 6.93 | 9.89 |
| Transformer (LLaMA) | 8.44 | 10.08 | 18.77 | 6.09 | 14.47 | 3.98 | 11.83 | 11.52 | 12.94 | 23.5 | 18.46 | 16.04 | 8.27 | 13.5 |
| Samba | 6.33 | 10.89 | 15.86 | 5.1 | 11.28 | 2.79 | 9.42 | 11.39 | 10.88 | 28.5 | 16.07 | 2.8 | 11.65 | 14.26 |
| Transformer-SWA (LLaMA) | 8.46 | 8.59 | 16.65 | 6.9 | 13.84 | 4.03 | 7.47 | 12.87 | 10.0 | 12.0 | 14.92 | 5.1 | 16.16 | 14.22 |
🔼 Table 9 presents the results of several long-context downstream tasks from the LongBench benchmark. Each model in the table has approximately 760M parameters (excluding embeddings) and was trained using roughly 48 billion tokens from the LongCrawl64 dataset. The table compares the performance of the Forgetting Transformer (FoX) with various architectures against several baseline models (including the standard Transformer and recurrent models like Mamba-2, HGRN2, and DeltaNet). The best-performing model for each task is shown in bold and underlined.
read the caption
Table 9: Evalution results on LongBench. All models have roughly 760760760760M non-embedding parameters and are trained on roughly 16161616B tokens on LongCrawl64. Bold and underlined numbers indicate the best and the second best results, respectively.
Full paper#