TL;DR#
Current long-context language models (LCLMs) hold promise for real-world software engineering applications but lack rigorous evaluation frameworks for long code understanding. Current benchmarks are limited by task diversity, use of synthetic code, and entangled tasks. To address this, this paper introduces LONGCODEU benchmark, designed to comprehensively evaluate LCLMs’ capacity to understand real-world, dependency-rich, long code contexts. This benchmark contains comprehensive and practical tasks, extra-long code context, real-world repositories, and reduced data contamination.
The paper evaluates nine popular LCLMs using LONGCODEU. The experiments reveal key limitations in LCLMs’ capabilities for long code understanding. LCLMs’ performance drops dramatically beyond 32K tokens. Inter-code unit relation understanding is the most challenging aspect. The evaluation results provide insights for optimizing LCLMs. This can help for real-world applications of those technologies in software engineering.
Key Takeaways#
Why does it matter?#
This paper is a crucial step towards developing better software engineering tools. It provides a comprehensive benchmark that can be used to evaluate and improve the long code understanding capabilities of LCLMs, fostering progress in areas like code generation and issue resolution, driving future research & innovation.
Visual Insights#

🔼 This figure showcases two examples of long code to illustrate the difference between synthetic and real-world codebases. The first example (a) is a synthetic long code constructed from independent functions, highlighting the simplicity of such an approach. The second example (b) is a real-world long code snippet, emphasizing the presence of non-standalone functions and the complex dependencies between them. The dependencies are visually highlighted within both code examples to emphasize the intricate relationships present in real-world code.
read the caption
Figure 1: Examples of a synthetic long code with independent functions and a real-world long code with non-standalone functions. Dependencies are highlighted.
| Benchmark | Comprehensive Code Tasks | Extra-long Data | Real-world Repository | Reduce Data Leaking | Data Scale | ||||||
| #Num | #Div Tasks | #High Disp | #Max-L | #Avg-L | #Length-L | Code | #Doc | #Num | Data Time | #Task | |
| The second category benchmarks (Only some benchmarks are listed) | |||||||||||
| LongBench [6] | 2 | ✗ | ✗ | – | 0.4K | ✗ | Function | ✗ | – | 2023.02–2023.08 | 1,000 |
| LC-Arena [8] | 6 | ✗ | ✗ | – | – | ✗ | File | ✗ | 62 | 2023.01–2024.05 | – |
| LONGPROC [30] | 1 | ✗ | ✓ | – | 2K | ✓ | Function | ✗ | 0 | No Limit | 200 |
| DevEval [21] | 1 | ✗ | ✓ | – | 0.3K | ✓ | File | ✗ | 164 | 2023.11-2024.02 | 1,825 |
| The first category benchmarks | |||||||||||
| RepoQA [22] | 1 | ✗ | ✗ | 16K | – | ✗ | Function | ✗ | 50 | No Limit | 500 |
| L-Eval [5] | 1 | ✗ | ✗ | 36.5K | 31.5K | ✗ | Function | ✗ | 0 | No Limit | 90 |
| LongCodeU | 8 | ✓ | ✓ | 128K | 54.8K | ✓ | File | ✓ | 116 | 2024.06–2024.11 | 3,983 |
🔼 This table compares various long code understanding benchmarks, including LongCodeU, across several key features. These features assess the comprehensiveness and realism of the benchmarks. Specifically, it contrasts the number of tasks, task diversity, length distribution of code examples (maximum and average), the presence of length labels for each example, whether the benchmark uses real-world repositories and associated documentation, and the total number of examples in each benchmark. This allows for a clear understanding of the strengths and weaknesses of each benchmark in terms of evaluating long-context language models.
read the caption
Table 1: The comparison between existing benchmarks and LongCodeU. #Num is the abbreviation of number. #Div Tasks refers to diverse tasks. #High Disp represents high dispersion. #Max-L and #Avg-L mean the maximum length and the average length of long code. #Trunk-L means whether each example has the length label. #Doc refers to documentation related to repositories. #Task represents the number of tasks (i.e., examples).
In-depth insights#
LCLM Shortfall#
While Large Context Language Models (LCLMs) promise transformative capabilities in software engineering, several shortfalls limit their practical application. One key issue is the degradation of performance with increasing context length. Despite claims of supporting hundreds of thousands of tokens, LCLMs often struggle with code exceeding 32K tokens, rendering them less effective for large codebases. This limitation stems from the models’ inability to effectively model code context. Additionally, LCLMs face challenges in inter-code unit relation understanding, making it difficult to analyze dependencies and semantic relationships within and across code files. Code understanding is also restricted by memorization, where models may generate responses based on training data rather than genuine reasoning. Finally, the evaluation metrics used to benchmark LCLMs may not accurately capture the nuances of code understanding, leading to an overestimation of their capabilities. These are some of the many LCLM’s shortfalls.
Dependency Key#
Dependency analysis is vital for grasping how code units interact, going beyond individual functions. Understanding dependencies aids in identifying related vulnerable components. It also enables tracing the impact of modifications across the codebase. LCLMs that excel in dependency analysis can better support code generation by ensuring correct invocation of existing code units. This enhances integration into the current repository. To understand the dependency relation, LCLMs need to first find the code unit that is invoked by the given unit from the long code. Dependency analysis is useful in practical applications, as it can assist in correctly identifying other code units related to vulnerable units.
32K Context Limit#
LCLMs struggle with long contexts: Current LCLMs dramatically decline when input exceeds 32K tokens, failing to use larger advertised context windows (128k-1M). This 32K limit suggests a bottleneck in effectively processing very long sequences. Performance drops are task-specific: The severity varies depending on the task; dependency relation extraction suffers most. Context modeling issues: LCLMs may not properly model dependencies or lose information across long distances. Future research needs to improve long-range attention and information retention. Current LCLMs do not take advantage of the 128K~1M context windows well.
Repo Data Counts#
While “Repo Data Counts” isn’t explicitly present as a heading in this research paper, we can infer its significance based on the methodology described. The paper emphasizes the creation of LONGCODEU, a benchmark for evaluating long-context language models (LCLMs) in understanding code. Therefore, meticulous data collection from repositories is crucial. The ‘Repo Data Counts’ would likely detail the number of repositories scraped, the criteria for selecting repositories (e.g., creation date, stars, non-fork), the types of files extracted, and the volume of code collected. This information is essential for assessing the benchmark’s scope and representativeness. Higher data counts, especially across diverse repositories, would indicate a more robust and reliable benchmark. Moreover, information about data cleaning and deduplication methods becomes vital to mitigate biases and ensure the benchmark’s integrity. Data about counts, for instance, helps in understanding how well is the variety of real-world cases tackled.
Metrics Correlate#
Evaluation metrics are crucial for assessing language model performance, particularly in tasks involving long code understanding. The choice of metric significantly impacts the interpretation of results, and relying solely on one metric can be misleading. For instance, metrics like Exact Match (EM) might be too strict, especially when dealing with code generation or retrieval, where minor variations can be semantically equivalent. CodeBLEU, while designed for code, may not fully capture the nuances of long code understanding if it primarily focuses on surface-level similarity. Metrics must correlate well with human judgments to be reliable and accurately reflect model capabilities. If a metric doesn’t align with human evaluation, its usefulness is questionable. The evaluation process should be thorough, encompassing a range of metrics that capture different aspects of code understanding, such as functional correctness, code style, and the ability to follow complex dependencies. Without a robust and validated evaluation framework, it’s challenging to make meaningful comparisons between different models or track progress in long code understanding research. A metrics correlation score measures the consistency of an evaluation, so in the case the metrics correlate with human evaluation, it means the models are reliable.
More visual insights#
More on figures

🔼 This figure illustrates the four key aspects of long code understanding that are evaluated in the LONGCODEU benchmark. These aspects are: 1) Code Unit Perception (identifying individual code units such as functions); 2) Intra-Code Unit Understanding (analyzing the internal logic and semantics of a single code unit); 3) Inter-Code Unit Relation Understanding (analyzing relationships between different code units); and 4) Long Documentation Understanding (understanding and extracting relevant information from code documentation). Each aspect is represented visually, showing how LONGCODEU aims to comprehensively assess a model’s ability to understand long code.
read the caption
Figure 2: Four understanding aspects in LongCodeU.
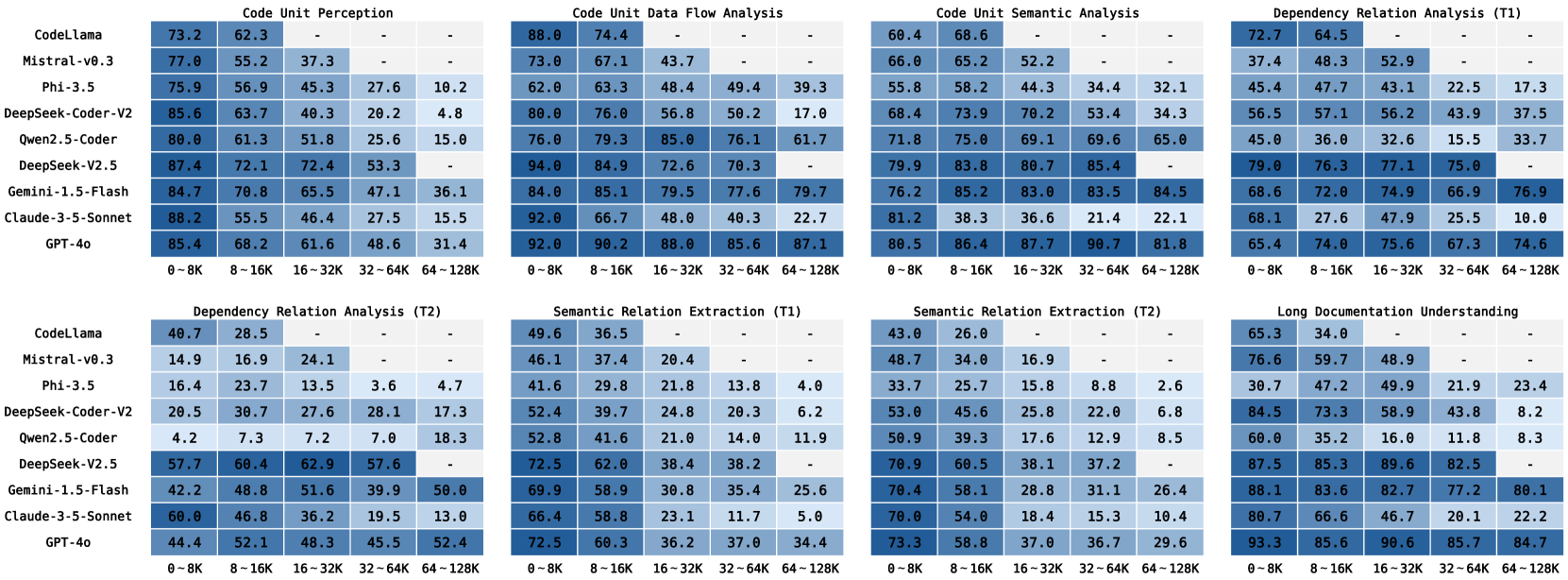
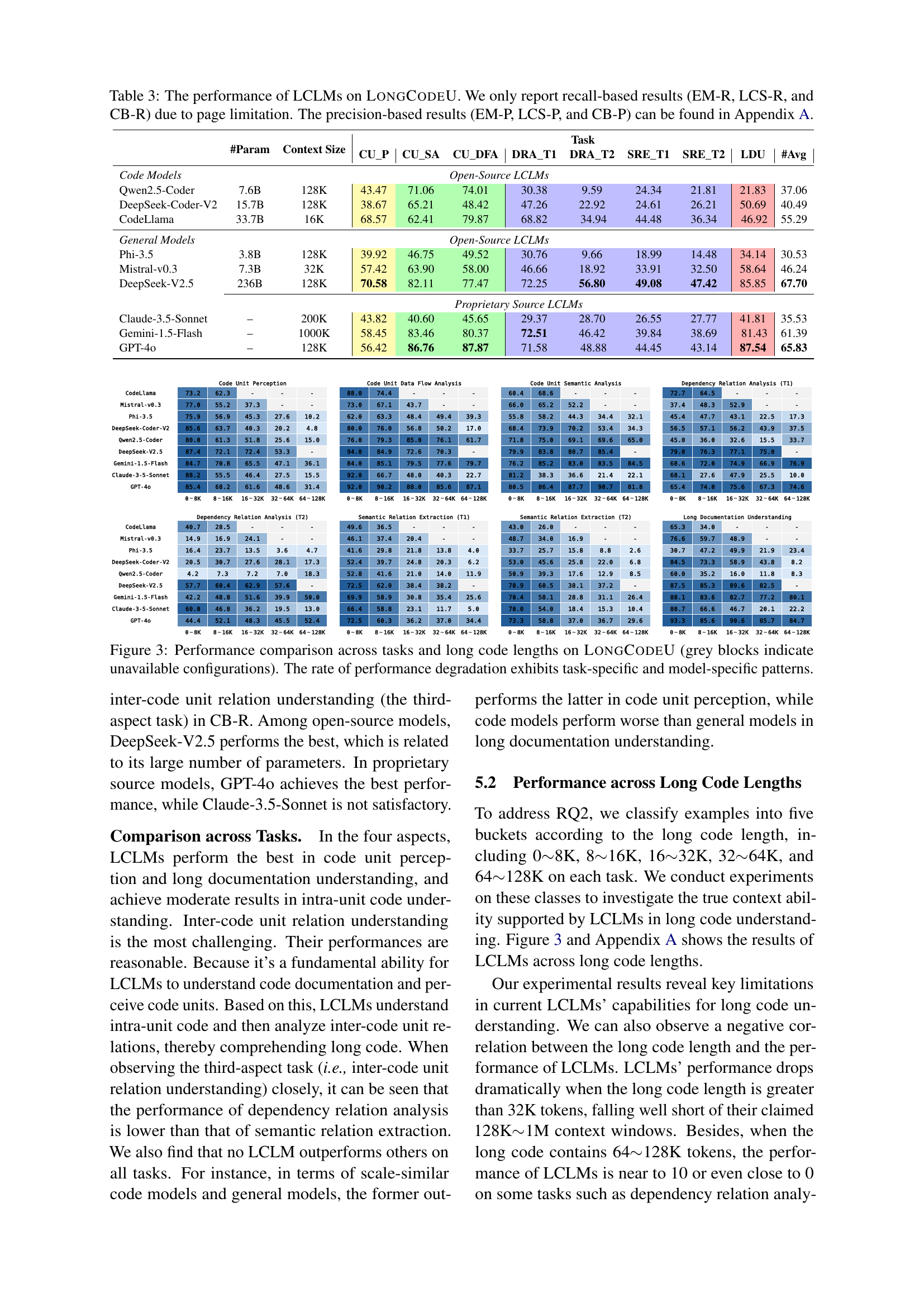
🔼 Figure 3 presents a detailed analysis of the performance of various Large Context Language Models (LCLMs) across different code understanding tasks within the LongCodeU benchmark. The x-axis represents five different length ranges of code (0-8K, 8-16K, 16-32K, 32-64K, and 64-128K tokens), showcasing how model performance changes as code length increases. The y-axis lists nine different LCLMs, categorized into general models and code-specific models. Each cell in the heatmap displays the performance of a specific model on a particular task and code length range, represented by color intensity (higher intensity indicating better performance). Missing data points are represented as grey blocks. The figure highlights that the performance degradation as code length increases is inconsistent and varies across different models and tasks (task-specific and model-specific patterns).
read the caption
Figure 3: Performance comparison across tasks and long code lengths on LongCodeU (grey blocks indicate unavailable configurations). The rate of performance degradation exhibits task-specific and model-specific patterns.

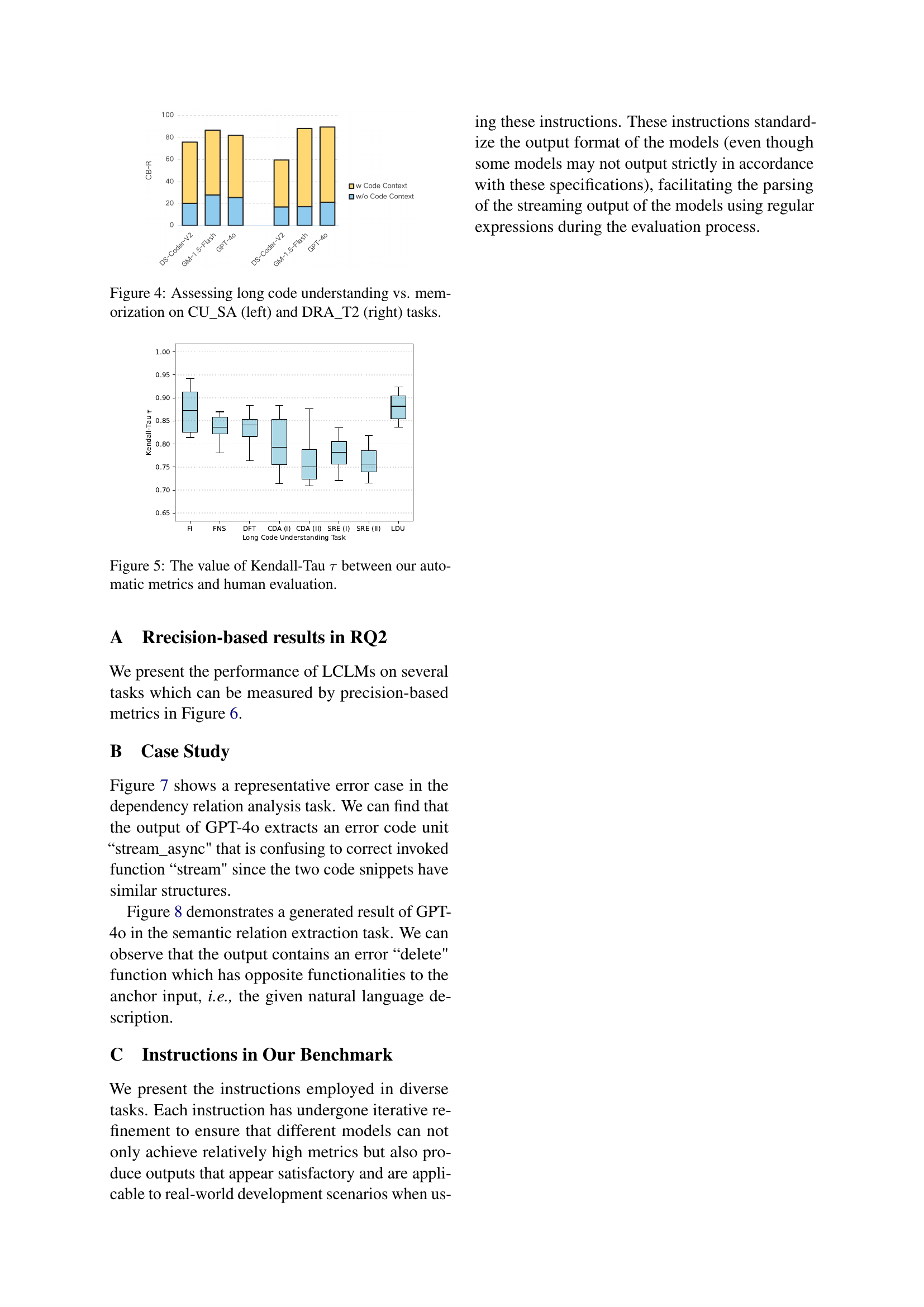
🔼 This figure compares the performance of large language models (LLMs) on two tasks: Code Unit Semantic Analysis (CU_SA) and Dependency Relation Analysis (DRA_T2), both focusing on long code understanding. The left panel (CU_SA) shows the performance with and without the long code context, highlighting the model’s ability to understand code semantics. The right panel (DRA_T2) similarly compares performance with and without context, assessing the model’s ability to identify relationships between different code units within a long code sequence. The comparison reveals the extent to which LLMs rely on memorization versus genuine code understanding.
read the caption
Figure 4: Assessing long code understanding vs. memorization on CU_SA (left) and DRA_T2 (right) tasks.

🔼 This figure displays the correlation between the automatically computed evaluation metrics and the human-evaluated scores for the LONGCODEU benchmark. The Kendall-Tau correlation coefficient (τ) is used to quantify the strength of the monotonic relationship between automatic and human judgments. Higher Kendall-Tau values indicate a stronger correlation and higher reliability of the automated metrics. The figure shows a bar chart with Kendall-Tau values for each of the eight tasks, demonstrating the consistency and reliability of the automatic evaluation metrics.
read the caption
Figure 5: The value of Kendall-Tau τ𝜏\tauitalic_τ between our automatic metrics and human evaluation.

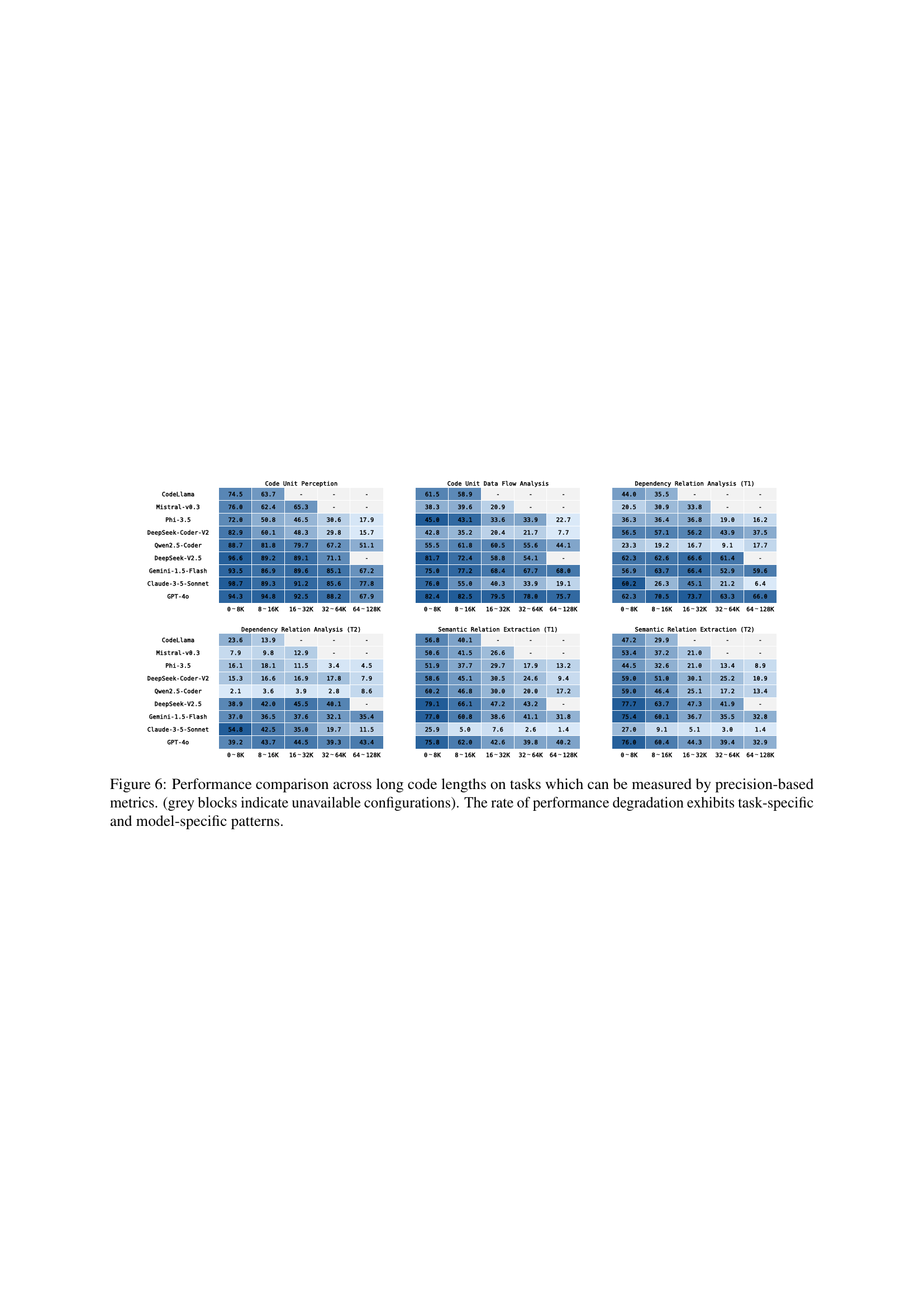
🔼 Figure 6 presents a detailed analysis of Large Language Model (LLM) performance across varying lengths of code, focusing on tasks where precision-based metrics are applicable. The heatmaps visualize the performance (precision) of different LLMs on various tasks, categorized by code length ranges (0-8K, 8-16K, 16-32K, 32-64K, 64-128K tokens). Grey blocks represent unavailable data points due to limitations in LLM context window sizes. The key finding highlighted is that the performance degradation patterns are not uniform across LLMs and tasks, showcasing task-specific and model-specific variations in how effectively LLMs handle increasingly long code inputs.
read the caption
Figure 6: Performance comparison across long code lengths on tasks which can be measured by precision-based metrics. (grey blocks indicate unavailable configurations). The rate of performance degradation exhibits task-specific and model-specific patterns.

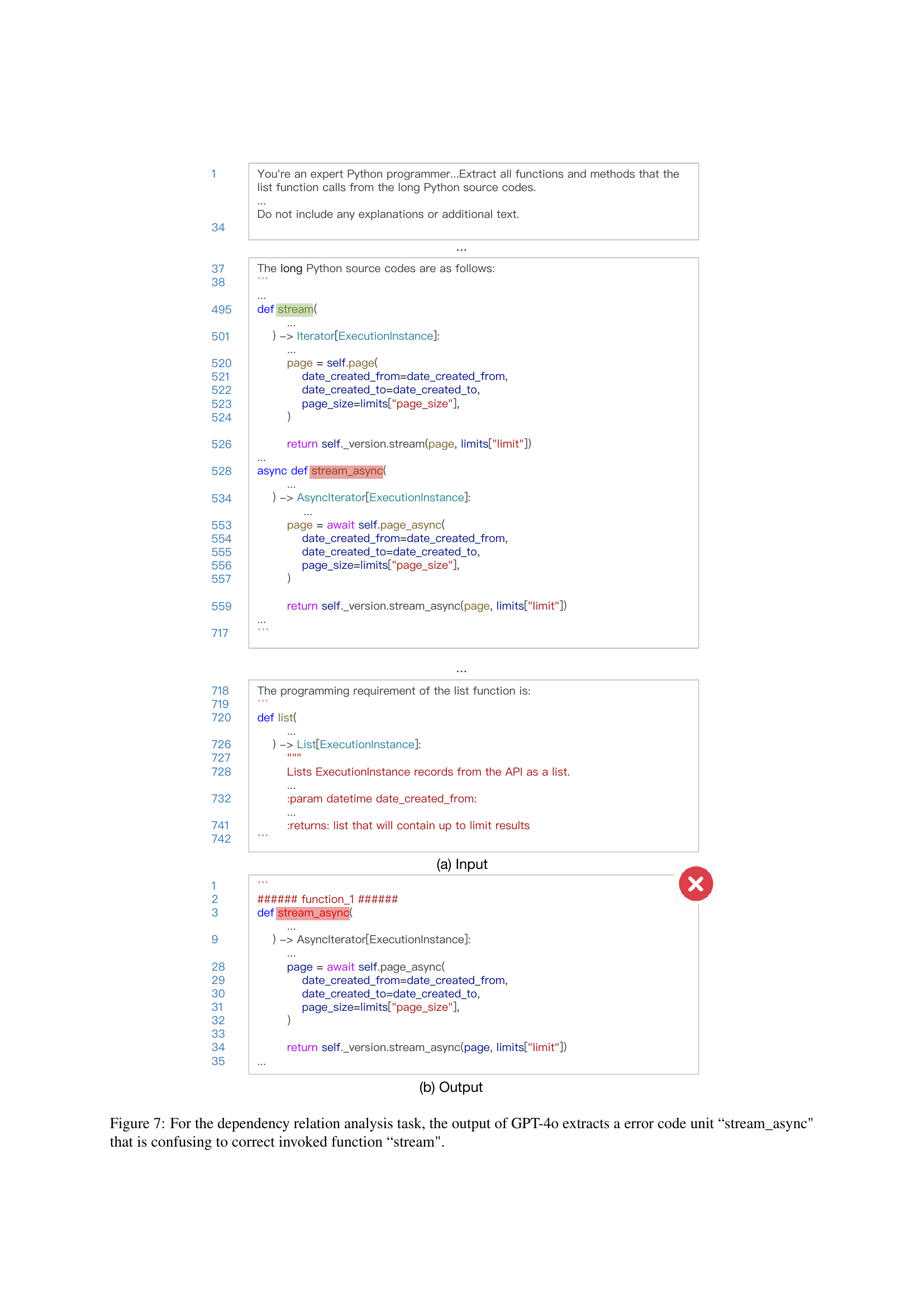
🔼 Figure 7 demonstrates a failure case in the dependency relation analysis task within the LONGCODEU benchmark. Specifically, when using GPT-4, the model incorrectly identifies the
stream_asyncfunction as related to thestreamfunction. This highlights a limitation of current LCLMs: they may extract code units based on superficial similarities (like similar names) rather than a true understanding of the code’s functional relationships and dependencies. This type of error emphasizes the difficulty in accurately identifying relationships between code units within a larger codebase.read the caption
Figure 7: For the dependency relation analysis task, the output of GPT-4o extracts a error code unit “stream_async' that is confusing to correct invoked function “stream'.

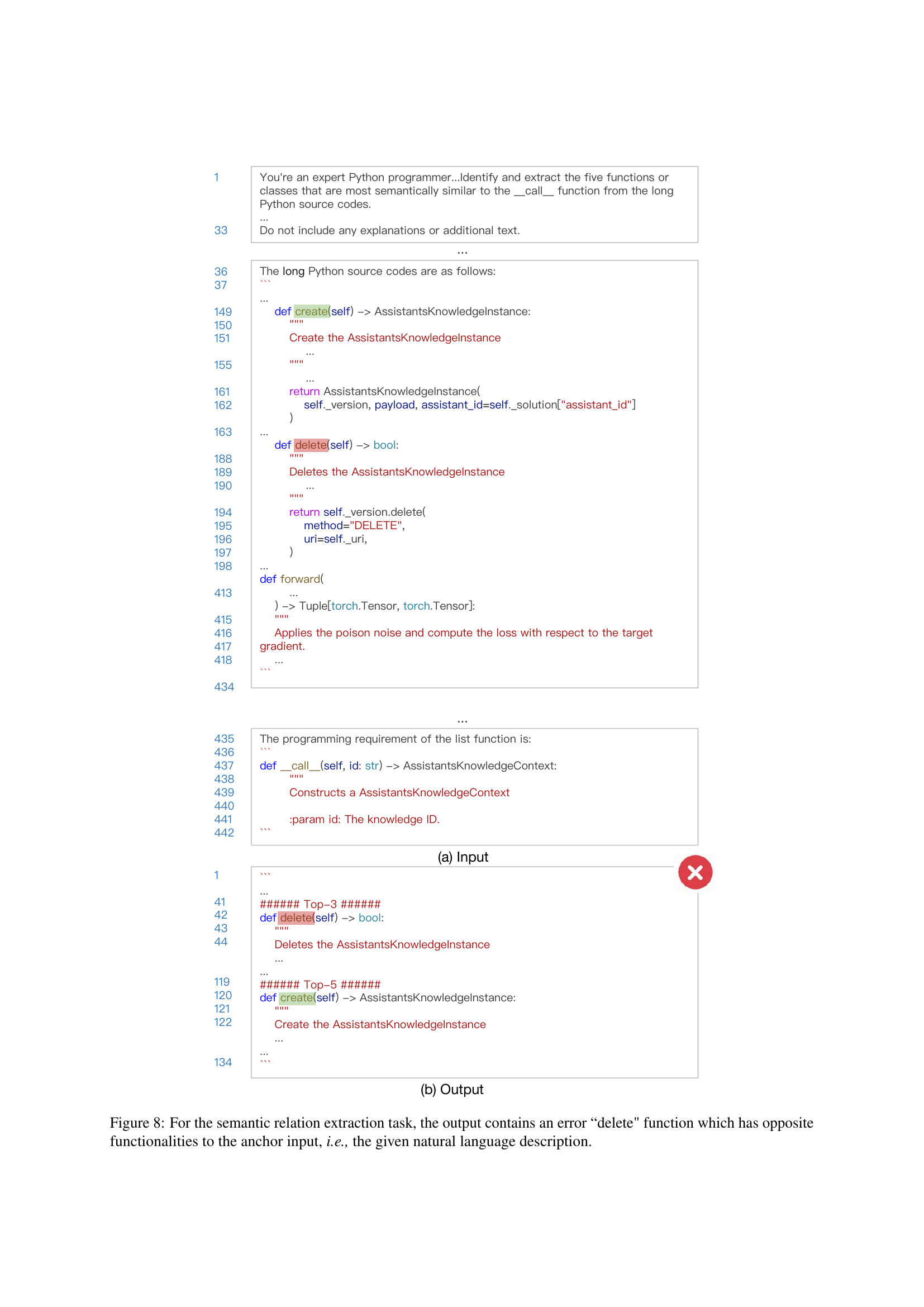
🔼 The figure displays an example from the Semantic Relation Extraction task within the LONGCODEU benchmark. The task requires the model to identify code units semantically similar to a given input. The model incorrectly identifies the
deletefunction as semantically similar to the anchor input, which is described in natural language. The error highlights the challenge of accurately capturing semantic similarity in code, even for advanced models. The opposite functionalities of thedeletefunction and the anchor input underscore the model’s failure to correctly understand the semantic relationship between code units.read the caption
Figure 8: For the semantic relation extraction task, the output contains an error “delete' function which has opposite functionalities to the anchor input, i.e., the given natural language description.
More on tables
| Task | Input | Output | |||
| #Num | Format | #C-File | #Avg-L | #Gran | |
| CU_P | 487 | Code | ✗ | 0.4K | Name |
| CU_SA | 500 | Code | ✗ | 0.2K | Function |
| CU_DFA | 500 | Code | ✗ | 0.03K | Line |
| DRA_T1 | 500 | Code | ✓ | 0.3K | Function |
| DRA_T2 | 500 | Code | ✓ | 0.3K | Function |
| SRE_T1 | 500 | Code | ✓ | 1.0K | Function |
| SRE_T2 | 500 | Code | ✓ | 1.1K | Function |
| LDU | 500 | Document | ✗ | 0.7K | NL |
🔼 Table 2 presents a statistical overview of the LONGCODEU benchmark dataset. It details the number of examples (#Num) for each of the eight tasks. The ‘#C-File’ column indicates whether the task’s output can be generated by combining information across multiple files within a codebase. ‘#Avg-L’ shows the average length of the output for each task, and ‘#Gran’ specifies the level of detail in the output (e.g., function name, code line). This table provides essential information about the size, nature, and complexity of the data used in the LONGCODEU benchmark.
read the caption
Table 2: Statistics of LongCodeU. #Num means the number of examples in each task. #C-File represents whether the output can be obtained by aggregating cross-file content. #Avg-L is the average length of the output. #Gran means the granularity of the output.
| #Param | Context Size | Task | |||||||||
| CU_P | CU_SA | CU_DFA | DRA_T1 | DRA_T2 | SRE_T1 | SRE_T2 | LDU | #Avg | |||
| Code Models | Open-Source LCLMs | ||||||||||
| Qwen2.5-Coder | 7.6B | 128K | 43.47 | 71.06 | 74.01 | 30.38 | 9.59 | 24.34 | 21.81 | 21.83 | 37.06 |
| DeepSeek-Coder-V2 | 15.7B | 128K | 38.67 | 65.21 | 48.42 | 47.26 | 22.92 | 24.61 | 26.21 | 50.69 | 40.49 |
| CodeLlama | 33.7B | 16K | 68.57 | 62.41 | 79.87 | 68.82 | 34.94 | 44.48 | 36.34 | 46.92 | 55.29 |
| General Models | Open-Source LCLMs | ||||||||||
| Phi-3.5 | 3.8B | 128K | 39.92 | 46.75 | 49.52 | 30.76 | 9.66 | 18.99 | 14.48 | 34.14 | 30.53 |
| Mistral-v0.3 | 7.3B | 32K | 57.42 | 63.90 | 58.00 | 46.66 | 18.92 | 33.91 | 32.50 | 58.64 | 46.24 |
| DeepSeek-V2.5 | 236B | 128K | 70.58 | 82.11 | 77.47 | 72.25 | 56.80 | 49.08 | 47.42 | 85.85 | 67.70 |
| Proprietary Source LCLMs | |||||||||||
| Claude-3.5-Sonnet | – | 200K | 43.82 | 40.60 | 45.65 | 29.37 | 28.70 | 26.55 | 27.77 | 41.81 | 35.53 |
| Gemini-1.5-Flash | – | 1000K | 58.45 | 83.46 | 80.37 | 72.51 | 46.42 | 39.84 | 38.69 | 81.43 | 61.39 |
| GPT-4o | – | 128K | 56.42 | 86.76 | 87.87 | 71.58 | 48.88 | 44.45 | 43.14 | 87.54 | 65.83 |
🔼 This table presents the performance of various Long Context Language Models (LCLMs) on the Long Code Understanding benchmark (LongCodeU). Due to space constraints in the paper, only recall-based metrics (EM-R, LCS-R, and CB-R) are shown; precision-based metrics are available in Appendix A. The table shows the performance across different LCLMs, categorized as code models and general models. For each LCLM, parameter count, context window size, and the recall for each of the eight LongCodeU tasks are reported, along with an average recall across all tasks.
read the caption
Table 3: The performance of LCLMs on LongCodeU. We only report recall-based results (EM-R, LCS-R, and CB-R) due to page limitation. The precision-based results (EM-P, LCS-P, and CB-P) can be found in Appendix A.
Full paper#