TL;DR#
Retrieval-augmented generation (RAG) enhances LLMs with relevant documents, but previous work has shown that performance can degrade when retrieving many documents. However, it was unclear whether this degradation was due to the increased number of documents itself or the longer context length associated with more documents. To address this, the paper investigates how the number of retrieved documents affects LLM performance while controlling for context length using a multi-hop QA task.
The authors evaluate various language models on custom datasets derived from MuSiQue, keeping the context length and position of relevant information constant while varying the number of documents. The results show that increasing the number of documents in RAG settings poses significant challenges for LLMs and that processing multiple documents is a separate challenge from handling long contexts. The authors make their datasets and code available to facilitate further research in multi-document retrieval, and highlights the need for retrieval systems to balance relevance.
Key Takeaways#
Why does it matter?#
This paper is important because it reveals that simply increasing the number of documents in RAG systems can hurt performance, even with a fixed context length. This finding challenges the common assumption that more context is always better and highlights the need for new techniques to manage multiple documents effectively. It opens new research avenues to minimize conflicts.
Visual Insights#

🔼 Figure 1 illustrates how the researchers created datasets for their experiment. They started with multi-hop questions and 20 related documents for each question. Some documents contained information needed to answer the question (supporting documents, shown in pink), while others were distractors (shown in blue). To isolate the effect of document number on model performance, they kept the total context length constant across different datasets. They varied the number of distractor documents, extending the remaining documents when they reduced the distractor count to maintain a constant overall length. This ensured that the length of the context didn’t affect the results, only the number of documents.
read the caption
Figure 1: More Documents, Same Length. We create various sets containing the same questions but differing in the number of distractor documents. Each set includes a multi-hop question, all of the supporting documents that contain the information to answer the question (pink), and varying distractor documents (blue). We begin with a 20-document version (left) and then reduce the number of documents while maintaining a fixed context size. When fewer documents are used, the remaining documents are extended (blue without text) so that concatenating them yields the same total length.
| Model | Supporting documents only | No documents |
| Qwen-2 72B | 0.61 | 0.01 |
| Qwen-2 7B | 0.25 | 0.04 |
| Llama-3.1 70B | 0.44 | 0.02 |
| Llama-3.1 8B | 0.19 | 0.02 |
| Gemma-2 27B | 0.52 | 0.02 |
| Gemma-2 9B | 0.50 | 0.05 |
🔼 This table presents the F1 scores achieved by large and small versions of several language models across two different scenarios. The first scenario evaluates the models’ performance when only the supporting documents necessary to answer a question are provided, without any additional context. The second scenario tests the models’ performance when only the question is given, with no supporting documents whatsoever. This comparison helps isolate the impact of providing relevant versus irrelevant information on the models’ ability to generate accurate answers.
read the caption
Table 1: F1 scores for the large and small versions of each model in two scenarios. In the first scenario, only the supporting documents are provided (without expanding the context). In the second scenario, only the question is provided (without any supporting documents).
In-depth insights#
RAG: Doc Count#
RAG’s effectiveness is significantly influenced by the number of documents used. Increasing document count doesn’t always improve performance; it can introduce noise, redundancy, and conflicting information, hindering the model’s ability to pinpoint relevant data. Managing document diversity and relevance becomes crucial. The study suggests a ‘sweet spot’ in document count, balancing comprehensive coverage and minimizing distraction. RAG systems need to be designed to weigh the value of each additional document against the potential for increased complexity and confusion. The optimal document count can vary depending on task complexity and model capabilities. As the findings indicates, LLMs need mechanism to discard conflicting information and identify.
Fixed Context Hurt#
While the provided paper doesn’t explicitly have a section titled “Fixed Context Hurt”, the findings suggest that providing more documents, even with a fixed context length, can negatively impact LLM performance. This implies that the mere presence of additional, potentially irrelevant, documents within the same context window introduces complexity that hinders the model’s ability to extract and utilize the relevant information effectively. This could be due to several factors, such as increased difficulty in identifying key details amidst a larger pool of information, confusion arising from redundant or conflicting data points across multiple sources, or the model struggling to weigh the relative importance of different documents. Conversely, performance improvements observed when reducing the number of documents suggest that LLMs are more efficient when focusing on a smaller set of highly relevant sources, even if it means processing slightly longer individual documents. Further investigation is needed to fully understand the specific mechanisms behind this phenomenon and to develop strategies for mitigating the negative impact of multiple documents in RAG settings, such as better relevance filtering or more sophisticated document weighting techniques. Thus, the central finding is that a fixed context does not necessarily guarantee improved results, and careful consideration must be given to the information’s distribution and organization within the context.
MuSiQue is Key#
While the research paper doesn’t explicitly have a heading called ‘MuSiQue is Key’, the paper leverages the MuSiQue dataset as a central tool for their investigation. MuSiQue, a multi-hop QA dataset, provides a controlled environment to study the impact of multiple documents on LLM performance. Its structure allows the researchers to systematically vary the number of documents while maintaining a consistent context length, a crucial aspect of their experimental design. By using MuSiQue, the paper aims to disentangle the challenges of long-context processing from the specific difficulties introduced by multiple documents, such as redundancy or conflicting information. The dataset’s realistic distractors, derived from related Wikipedia articles, make it well-suited for simulating real-world RAG scenarios, where LLMs often encounter irrelevant information alongside relevant content. MuSiQue’s pre-existing QA structure allows for objective evaluation of model performance, enabling the researchers to quantify the impact of document count on answer accuracy and efficiency. Custom sets are constructed from MuSiQue. The choice of MuSiQue is key to isolating and studying the research question.
Qwen2: Exception?#
The paper suggests that Qwen2 exhibits a distinct behavior compared to other models like Llama-3.1 and Gemma-2. While the latter tend to suffer performance degradation with an increased number of documents, Qwen2 appears to be more resilient, possibly indicating better handling of multi-document collections. This observation implies potential architectural or training-related advantages in Qwen2’s ability to process and integrate information from multiple sources, showcasing its capacity to effectively navigate the challenges associated with processing extensive data and a larger context size. Further investigation into Qwen2’s design and training methodologies is warranted to understand the underlying mechanisms contributing to its superior performance in multi-document RAG scenarios. This capability may be attributed to how the LLM deals with redundant, conflicting or implicit inter-document relations, as Qwen2 is able to perform consistently well when presented with distracting documents within a larger prompt.
RAG Balance Needed#
The paper underscores the crucial need for a balanced approach in Retrieval-Augmented Generation (RAG) systems, indicating that simply increasing the number of retrieved documents does not automatically lead to improved performance; in fact, it can hinder it. This suggests a trade-off between breadth and depth in information retrieval for RAG. The study reveals that LLMs struggle when presented with an excessive number of documents, even when the context length is controlled, highlighting that the challenge is not solely about processing long contexts but also about managing multiple, potentially conflicting or redundant, pieces of information. This finding emphasizes the importance of developing mechanisms to identify and filter out irrelevant or conflicting information from the retrieved documents to improve the accuracy and reliability of RAG systems. Future RAG systems must balance relevance and diversity to minimize conflicts.
More visual insights#
More on figures

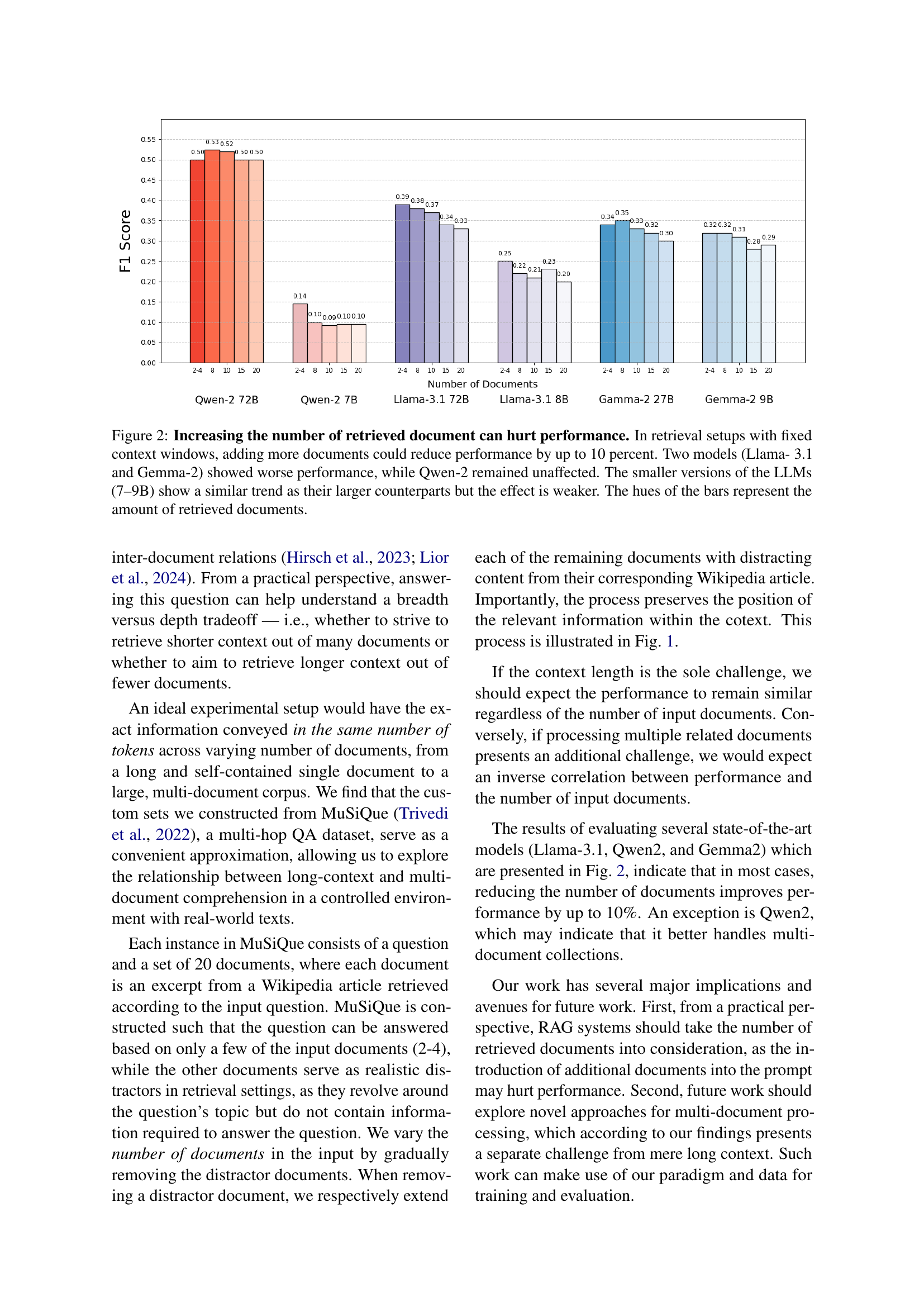
🔼 This figure displays the results of an experiment evaluating the effect of the number of retrieved documents on the performance of various Large Language Models (LLMs) in a retrieval-augmented generation (RAG) task. The x-axis represents different numbers of retrieved documents, while the y-axis shows the F1 score, a measure of model performance. Six LLMs of varying sizes (7B, 8B, 9B, 27B, 70B, and 72B parameters) are evaluated. The results show that for most LLMs, increasing the number of documents generally leads to a decrease in performance (up to 10% reduction in F1 score) when the total context length is kept constant. The exception is the Qwen-2 model, which shows relatively stable performance regardless of the document count. Smaller versions of the models exhibit similar trends, but the effect is less pronounced.
read the caption
Figure 2: Increasing the number of retrieved document can hurt performance. In retrieval setups with fixed context windows, adding more documents could reduce performance by up to 10 percent. Two models (Llama- 3.1 and Gemma-2) showed worse performance, while Qwen-2 remained unaffected. The smaller versions of the LLMs (7–9B) show a similar trend as their larger counterparts but the effect is weaker. The hues of the bars represent the amount of retrieved documents.

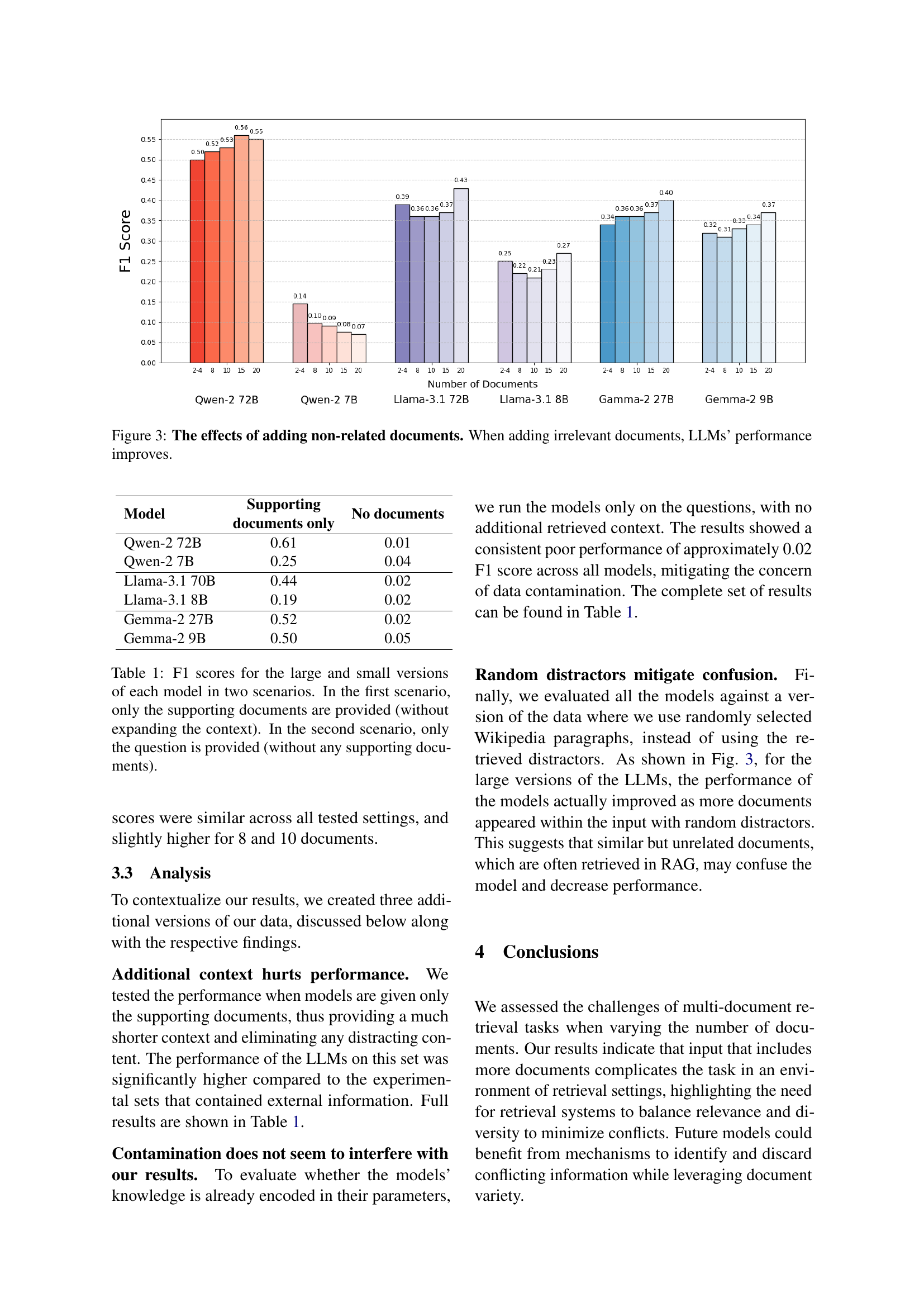
🔼 Figure 3 presents the results of an experiment assessing the impact of adding irrelevant documents to the input on the performance of Large Language Models (LLMs). The experiment shows that contrary to the negative effect of adding relevant but distracting documents, adding completely unrelated documents improved the performance of the LLMs. This suggests that the presence of some unrelated documents may not significantly hinder the ability of LLMs to identify and utilize the relevant information to answer questions, or may even mitigate the confusion caused by many related but irrelevant pieces of information.
read the caption
Figure 3: The effects of adding non-related documents. When adding irrelevant documents, LLMs’ performance improves.
Full paper#