TL;DR#
Recent progress in Large Language Models (LLMs) has largely concentrated on processing extended input contexts, enhancing long-context comprehension. However, the generation of long-form outputs has been comparatively overlooked. This creates a critical gap, as many real-world applications, such as novel writing and complex reasoning, demand models capable of producing coherent, contextually rich, and logically consistent extended text. Current instruction-following datasets are dominated by short input-output pairs, limiting both research and application. Additionally, generating long-form content adds task execution complexities that are not present in shorter tasks. Computational costs also increase linearly, placing a substantial burden on researchers.
This paper advocates for a paradigm shift in NLP research, urging researchers to prioritize the challenges of long-output generation. It defines models optimized for long-output tasks as long-output LLMs and underscores the need for innovation in this under-explored domain. The study analyzes real-world user requests and paper publication trends, revealing a significant imbalance between demand for and research focus on long-output capabilities. It emphasizes the need for new datasets, benchmarks, and evaluation techniques tailored for long-output LLMs to unlock their potential in various domains.
Key Takeaways#
Why does it matter?#
This paper is important for researchers as it highlights the need to shift focus in LLM research from input processing to long-form output generation, paving the way for advancements in creative writing, complex reasoning, and real-world applications. It calls for new benchmarks, models, and evaluation techniques tailored for long-output LLMs, offering new research directions and potential for collaboration between academia and industry.
Visual Insights#

🔼 This figure illustrates the key distinction between traditional long-input LLMs and the emerging long-output LLMs. Long-input LLMs excel at processing extensive input contexts, as shown in the left panel, enabling tasks like question answering and document summarization that yield relatively short responses. Conversely, the right panel showcases long-output LLMs designed to generate extended, coherent, and contextually rich outputs. These models are crucial for applications requiring longer-form content generation such as creative writing, lesson planning, and dialogue systems.
read the caption
Figure 1: Difference between long-input and long-output LLMs.
| Dataset | Input Length | Output Length |
| LongAlpaca-12k | 5,945 | 218 |
| LongAlign-10k | 12,134 | 169 |
| \hdashlineSuri | 347 | 4,371 |
| LongWriter-6k | 262 | 5,333 |
🔼 This table presents a comparison of the average input and output lengths, measured in words, across four different long-context supervised fine-tuning (SFT) datasets. It highlights the disparity between the lengths of input prompts and the corresponding generated outputs in these datasets, which are frequently used in training long-context large language models (LLMs). This disparity is relevant to understanding the current challenges in training models capable of producing long-form text outputs.
read the caption
Table 1: Comparison of Average Input and Output Lengths (words) for Long-Context SFT Datasets.
In-depth insights#
Output, Not Input#
Shifting the focus from input to output in LLMs is crucial. Current research heavily emphasizes processing long input contexts. A shift is needed to address challenges in long-form output generation. Tasks like novel writing, long-term planning, and complex reasoning require coherent and logically consistent extended text. This highlights a gap in LLM capabilities, necessitating research focused on generating high-quality, long-form outputs. This shift holds immense potential for real-world applications. Current LLMs are more optimized for understanding and processing information than they are for generating extensive, detailed, and logical content. Focusing on output could improve the quality of generated content.
Demand > Research#
Demand exceeding research implies a critical gap. Real-world needs for complex problem-solving and long-form content are not met by current research focus, which may prioritize short input or task. This discrepancy hints at a potential misallocation of resources or perhaps methodological issues in addressing real-world complexities. Ignoring user needs in real tasks can hinder genuine progress in AI’s applicability.
Beyond 4K Tokens#
The pursuit of LLMs excelling beyond 4K tokens marks a critical shift in AI. Current benchmarks reveal performance dips beyond this threshold, signaling a need for architectural innovation. Addressing this requires novel training methodologies, enhanced memory management, and scalable architectures. Overcoming this limitation opens doors to applications demanding extensive context, like generating long-form content and long chain-of-thought reasoning, enabling richer, more coherent interactions and unlocking new frontiers in AI capabilities for solving complex real-world problems.
LLM Eval Bottleneck#
The LLM evaluation bottleneck highlights the difficulties in assessing the quality of long-form text, especially for coherence and consistency. Existing metrics are either rule-based, focusing on specific aspects like token count, or LLM-based, which are computationally expensive and less interpretable. A key challenge is the lack of reliable ground truth for subjective qualities like creativity. The high cost of API and the absence of effective evaluation frameworks hinders the accurate analysis of long-output LLMs.
Scaling is Key#
Scaling is undoubtedly crucial in advancing any AI model. The ability to handle larger datasets and longer contexts directly impacts performance. Scaling compute allows for training larger models, capturing intricate patterns. This is particularly relevant to long-output LLMs, where generating coherent and consistent text requires understanding extensive contexts. Scalability also plays a pivotal role in enabling real-time applications and handling increased user demand. Therefore, efficient scaling strategies are vital for broader adoption and impact.
More visual insights#
More on figures

🔼 This figure shows the proportion of real user demand for both input and output text lengths in four different ranges: [2K, 4K), [4K, 8K), [8K, 16K), and [16K, ∞). The x-axis represents the word count ranges, and the y-axis represents the percentage of user requests falling within each range. The bars are segmented into input (solid color) and output (slash fill) showing that demand for longer outputs significantly exceeds that for longer inputs. The data highlights a significant discrepancy between the available resources focused on processing long inputs and the actual demand for generating long-form outputs.
read the caption
Figure 2: Proportion of real-user demand: The aforementioned 2K (words) range refers to the interval [2K, 4K), and similarly for the other ranges. Solid color fill for input demand, slash fill for output.

🔼 This figure shows the number of research papers on long-context LLMs published in major ML and NLP conferences in 2024, categorized by whether the papers focused on long input or long output. The x-axis represents the conference, sorted chronologically. The y-axis shows the count of papers. Solid bars represent papers focusing on long input processing while slashed bars represent papers focusing on long output generation. The figure visually demonstrates the significant research emphasis on long input processing compared to the relatively limited research on long output generation.
read the caption
Figure 3: ML and NLP Conf Long-context Research Trends Statistics (sorted by conference date). Solid color fill for Input-paper, slash fill for Output-paper.

🔼 This UMAP visualization displays the relationships between different supervised fine-tuning (SFT) datasets used for training long-output LLMs. Each point represents a dataset, and the proximity of points indicates their similarity in terms of input-output characteristics. The dataset ‘WildChat’, which is distinct and represented separately, is derived from actual user requests for long-form outputs. The clustering suggests varying degrees of overlap between the SFT datasets, highlighting potential differences in their ability to effectively capture and represent real-world long-output task requirements. The unique positioning of WildChat illustrates the potential gap between the datasets typically used for training and the actual demands of real-world applications.
read the caption
Figure 4: UMAP visualization results for different SFT datasets. WildChat is derived from the long output demands of real users, filtered and referenced in Section 2.1.

🔼 This UMAP visualization compares various long-output benchmarks against real-world user demands for long-form text generation. It shows how well each benchmark captures the diversity of length and complexity in actual user requests. Benchmarks closely clustered with the real-world data points indicate a good representation of real-world long-output needs, while benchmarks far from the real-world cluster suggest a limited scope and potentially poor generalizability. The visualization helps assess the extent to which different benchmarks effectively evaluate the generation of long-form outputs.
read the caption
Figure 5: UMAP visualization results for different benchmark. We use the instructions from the benchmark to evaluate whether the benchmark assesses a wide range of long-output demand.

🔼 This figure illustrates the impact of increasing the proportion of output tokens within a fixed total context length of 12,000 tokens on the decoding duration (time taken for model to generate text). It shows that the longer the output sequence the longer the decoding time. The experiment uses several different LLMs (Large Language Models) to demonstrate this trend, showing that decoding time increases linearly with the number of output tokens.
read the caption
Figure 6: We set the total context length to 12,000 and gradually increased the proportion of output tokens.

🔼 Figure 7 illustrates the disproportionate demand for long-form outputs compared to long inputs in real-world scenarios. The data comes from analyzing 100,000 user requests in the WildChat dataset. The x-axis categorizes requests by input and output length (in word count), grouped into ranges: [2K, 4K), [4K, 8K), [8K, 16K), and [16K+). The y-axis shows the frequency (count) of requests in each range. Solid bars represent the number of requests with long inputs, while hatched bars represent the number of requests with long outputs of corresponding lengths. The figure visually emphasizes the significantly higher demand for long outputs across all length categories, especially pronounced in the [4k, 8k) word range, indicating a critical need for improved long-form text generation capabilities in LLMs.
read the caption
Figure 7: Proportion of real-user demand: The aforementioned 2K range refers to the interval [2K, 4K), and similarly for the other ranges. Solid color fill for input demand, slash fill for output demand in the Wildchat dataset.

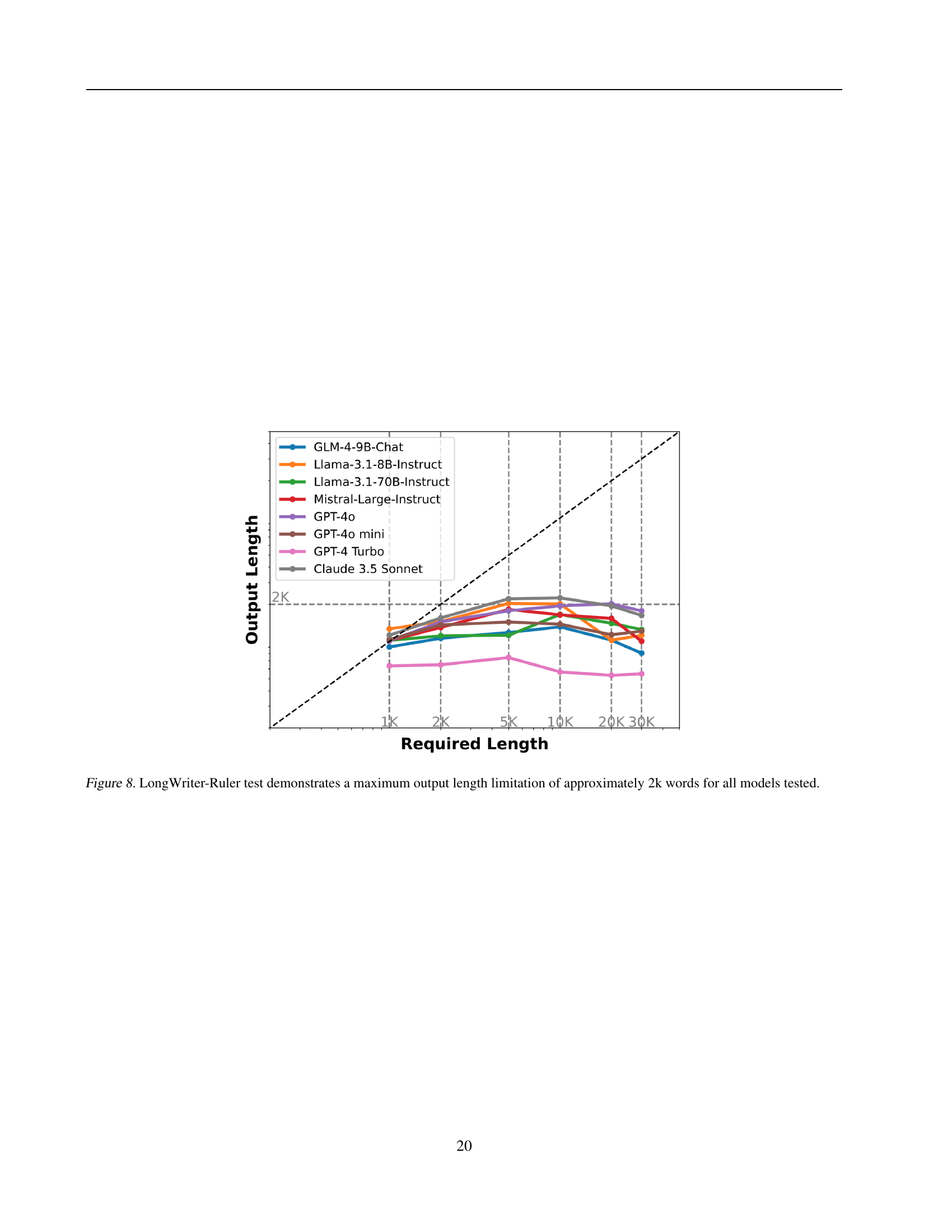
🔼 The LongWriter-Ruler test evaluates the maximum output length various large language models can generate. The results show that across different models, including GLM-4, Llama 2, Mistral, GPT-4, and Claude, there’s a consistent limitation: none of the models could reliably generate text exceeding approximately 2,000 words. This suggests a significant constraint on current LLMs’ ability to produce truly long-form outputs.
read the caption
Figure 8: LongWriter-Ruler test demonstrates a maximum output length limitation of approximately 2k words for all models tested.
Full paper#