TL;DR#
Large language models (LLMs) have shown that even a simple question-answering task can improve reasoning. However, single-turn tasks may be inefficient due to sparse rewards, and they do not require the LLM to learn how to respond to user feedback. This paper addresses the limitations of single-turn tasks by introducing a multi-attempt task framework. The model is given multiple attempts to answer a question, with feedback provided after incorrect responses. This encourages the model to refine its attempts and improve search efficiency.
The paper presents a simple yet effective multi-attempt task that enables LLMs to learn through reinforcement learning. A standard RL is applied to the multi-attempt task on a math problem dataset. The results show that LLMs trained on this achieves higher accuracy when evaluated with more attempts on a math benchmark. This demonstrates the potential of multi-attempt tasks for improving LLM reasoning and self-correction abilities. The paper also shows the multi-attempt LLM outperforms its single-turn counterpart.
Key Takeaways#
Why does it matter?#
This work introduces a simple yet effective multi-attempt task for RL training of LLMs. It shows enhanced self-correction and reasoning with potential for complex code generation. The novel approach opens new avenues for more effective learning in LLMs, such as incorporating detailed feedback.
Visual Insights#

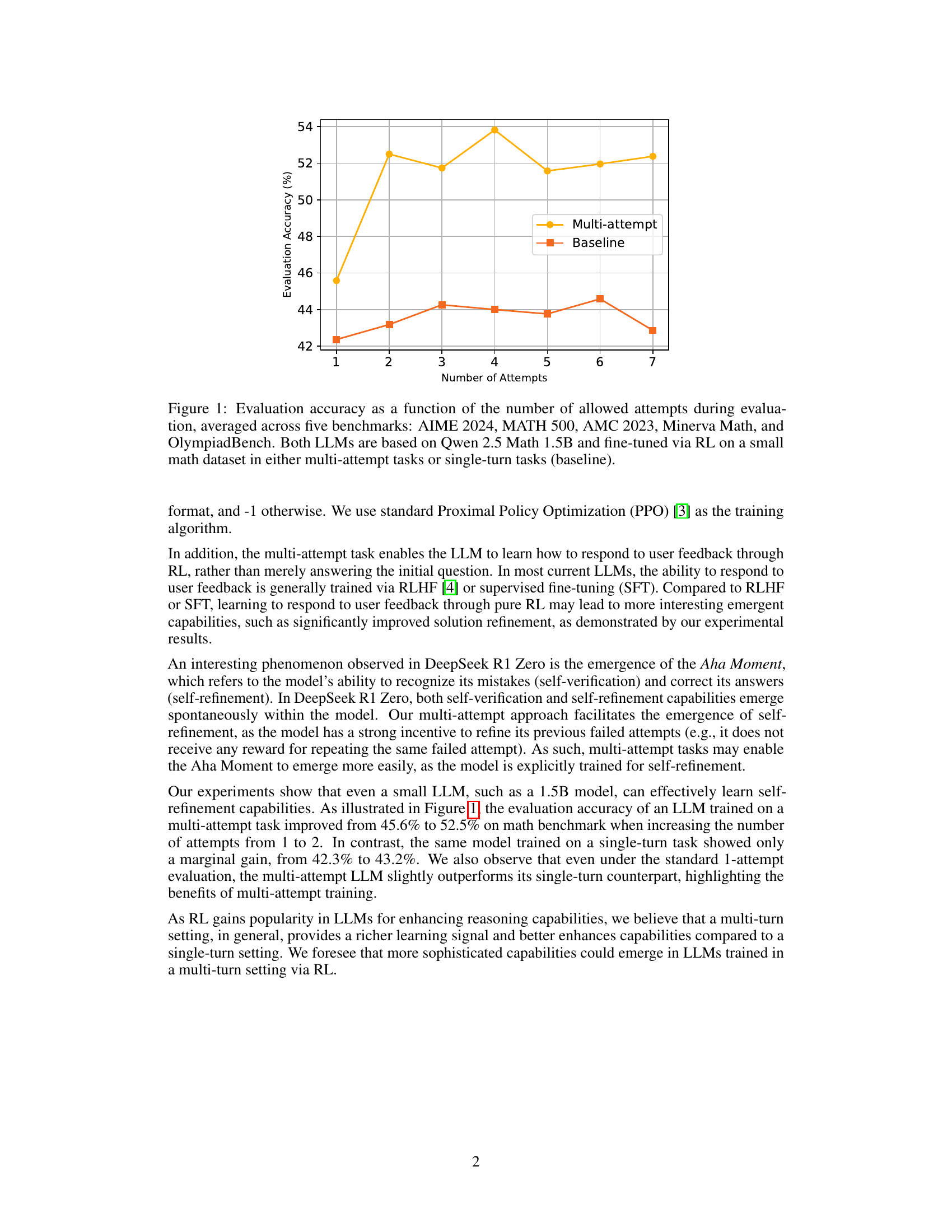
🔼 This figure displays the evaluation accuracy of two large language models (LLMs) across five different math benchmarks (AIME 2024, MATH 500, AMC 2023, Minerva Math, and OlympiadBench). The accuracy is shown as a function of the number of attempts allowed during evaluation. Both LLMs are based on the same foundation model (Qwen 2.5 Math 1.5B) but are trained differently: one using a multi-attempt reinforcement learning (RL) approach and the other using a standard single-turn RL approach (the baseline). The graph allows for a direct comparison of how the models perform with an increasing number of attempts, highlighting the impact of the multi-attempt training strategy.
read the caption
Figure 1: Evaluation accuracy as a function of the number of allowed attempts during evaluation, averaged across five benchmarks: AIME 2024, MATH 500, AMC 2023, Minerva Math, and OlympiadBench. Both LLMs are based on Qwen 2.5 Math 1.5B and fine-tuned via RL on a small math dataset in either multi-attempt tasks or single-turn tasks (baseline).
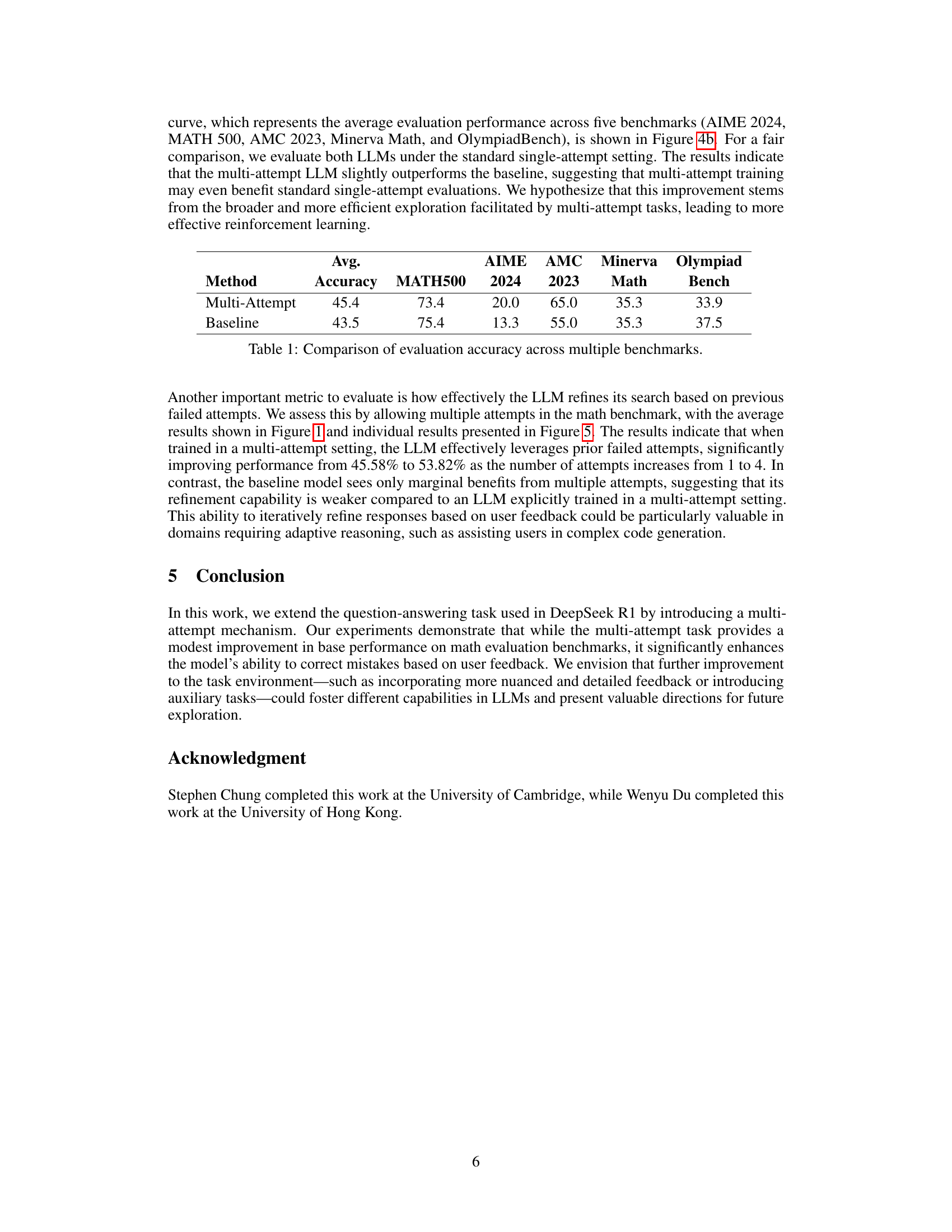
| Avg. | AIME | AMC | Minerva | Olympiad | ||
| Method | Accuracy | MATH500 | 2024 | 2023 | Math | Bench |
| Multi-Attempt | 45.4 | 73.4 | 20.0 | 65.0 | 35.3 | 33.9 |
| Baseline | 43.5 | 75.4 | 13.3 | 55.0 | 35.3 | 37.5 |
🔼 This table presents a comparison of the average evaluation accuracy achieved by two different LLMs across five distinct benchmarks: AIME 2024, MATH 500, AMC 2023, Minerva Math, and OlympiadBench. The two models are differentiated by their training methodology: one model was trained using a multi-attempt approach, while the other used a standard baseline method (single-turn). The accuracy for each benchmark is shown for both models, allowing for a direct comparison of their performance based on different training strategies.
read the caption
Table 1: Comparison of evaluation accuracy across multiple benchmarks.
In-depth insights#
Multi-Attempt RL#
Multi-Attempt Reinforcement Learning (RL) is a paradigm shift in how we train Large Language Models (LLMs). Instead of the conventional single-turn approach, models are given multiple attempts to solve a task, receiving feedback after each incorrect try. This encourages exploration and refinement of solutions. The core idea is to leverage the feedback signal to guide the model towards better reasoning. The multi-attempt setting enhances the model’s ability to correct mistakes, refine its approach, and ultimately, improve its problem-solving skills. This approach fosters a more robust and adaptable model, capable of handling complex and nuanced tasks. Additionally, the multi-attempt approach facilitates a richer exploration of the solution space. By allowing the model to experiment with different strategies and learn from its failures, it can discover more effective and efficient solutions than it would in a single-turn setting. The method mimics a more natural learning process, akin to how humans learn through trial and error.
Refinement via RL#
Reinforcement Learning (RL) can be employed for refinement in language models, particularly in multi-attempt scenarios. This approach contrasts with traditional single-turn tasks, which often suffer from sparse rewards and lack the opportunity for iterative improvement based on feedback. By allowing the model to generate multiple responses, RL enables the model to learn how to better respond to feedback, potentially leading to emergent capabilities. Furthermore, RL can be used to directly refine a previous unsuccessful attempts, as evidenced by improved performance of LLMs trained on multi-attempt tasks. This type of training may lead to broader and more efficient exploration, ultimately enhancing reinforcement learning.
Emergent Abilities#
Emergent abilities in large language models refer to capabilities that arise unexpectedly as models scale in size and complexity, often without explicit training for those specific skills. This can include advanced reasoning, problem-solving, and even aspects of self-correction, as observed in models like DeepSeek R1 Zero with its ‘Aha Moment’ phenomenon. These abilities are crucial because they highlight the potential for LLMs to surpass simple pattern-matching and develop more general intelligence. Multi-attempt RL appears as a promising way to enhance these behaviors. It allows models not only to give answers but also learn from their mistakes.
Task Augmentation#
Task augmentation is a crucial element in reinforcement learning. Modifying the original task can significantly improve the learning process of LLMs. Strategies involve modifying the task to a multi-attempt setting, enabling models to refine responses based on feedback. This involves incorporating auxiliary tasks, such as rewarding the model for attempting the problem and penalizing if the answer is wrong.
Beyond Single-Turn#
Moving beyond single-turn interactions in language models signifies a shift towards more complex, multi-faceted dialogues, mirroring real-world conversations. This necessitates models capable of maintaining context, understanding user intent across multiple turns, and adapting their responses accordingly. Multi-turn interactions enhance user experience by allowing for clarification, negotiation, and iterative problem-solving. Reinforcement learning in such settings becomes more intricate, as the reward function must account for the long-term consequences of each response. Models must learn to balance immediate rewards with the potential for future success, requiring a more sophisticated understanding of dialogue strategy. Evaluation metrics also need to evolve, focusing on coherence, consistency, and the overall quality of the interaction rather than just single-turn accuracy. Exploration becomes even more critical, as the model must discover effective dialogue paths through trial and error. Techniques such as hierarchical reinforcement learning or imitation learning from human conversations may prove valuable in guiding exploration and improving the efficiency of learning. The ability to handle multi-turn interactions is crucial for deploying language models in real-world applications such as customer service, education, and personal assistance.
More visual insights#
More on figures

🔼 This figure illustrates the core concept of the paper: a multi-attempt question answering task. It contrasts this approach with the traditional single-turn question-answering task. The diagram shows how, in the multi-attempt scenario, the model receives feedback (whether its answer is correct or incorrect) after each attempt. If the answer is incorrect, the model is given another chance to refine its response. This process of iterative feedback and refinement is the key innovation of the paper, enabling the model to learn and improve reasoning capabilities through reinforcement learning. The single-turn task, in comparison, offers only one opportunity for the model to answer and receive feedback.
read the caption
Figure 2: Illustration of the multi-attempt question-answer task. We extend the single-turn question-answer task from DeepSeek R1 to a multi-attempt setting, enabling iterative refinement.

🔼 This figure displays a dialogue between a user and a large language model (LLM) fine-tuned for a multi-attempt question-answering task. The task involves answering a math problem. The LLM is given two attempts (N=2). In the first attempt, it provides an incorrect answer. The user provides feedback, indicating the answer is wrong. In the second attempt, guided by this feedback, the LLM correctly solves the problem. The dialogue shows the LLM’s thought process and highlights its ability to learn from its mistakes and refine its answer through multiple attempts.
read the caption
Figure 3: An example of a multi-attempt dialogue (N=2𝑁2N=2italic_N = 2) from a fine-tuned LLM, where the LLM makes a mistake on the first attempt but learns to correct it in the second attempt.

🔼 This figure shows the training reward over training steps for both the multi-attempt and baseline LLMs. The y-axis represents the average reward received per training step. The x-axis represents the number of training steps completed. The plot visualizes the learning progress of both models, demonstrating the difference in reward accumulation between the multi-attempt model (which receives feedback and can refine its response) and the baseline single-attempt model. The multi-attempt LLM consistently achieves higher rewards, indicating more effective learning.
read the caption
(a) Training Reward

🔼 This figure shows the average evaluation accuracy across five benchmarks (AIME 2024, MATH 500, AMC 2023, Minerva Math, and OlympiadBench) as a function of training steps. It compares the performance of two LLMs: one trained on a multi-attempt task and a baseline LLM trained on a standard single-turn task. The plot helps visualize how the accuracy of each model improves (or doesn’t improve) over the course of training. This is important for assessing the effectiveness of the multi-attempt training approach.
read the caption
(b) Average Evaluation Accuracy

🔼 This figure displays the training and evaluation results for two LLMs: one trained with a multi-attempt reinforcement learning (RL) approach and a baseline model trained with a standard single-attempt RL approach. Subfigure (a) shows the training reward over training steps, demonstrating that the multi-attempt LLM consistently receives higher rewards. Subfigure (b) presents the average evaluation accuracy across five different math benchmarks as a function of training steps, all evaluated using a single-attempt setting. This part highlights that even under the standard single-attempt evaluation protocol, the multi-attempt LLM achieves slightly better performance than the baseline model.
read the caption
Figure 4: Training and evaluation performance of the LLMs. (a) Training reward as a function of training steps. (b) Average evaluation accuracy across five benchmarks as a function of training steps, evaluated under the standard single-attempt setting.

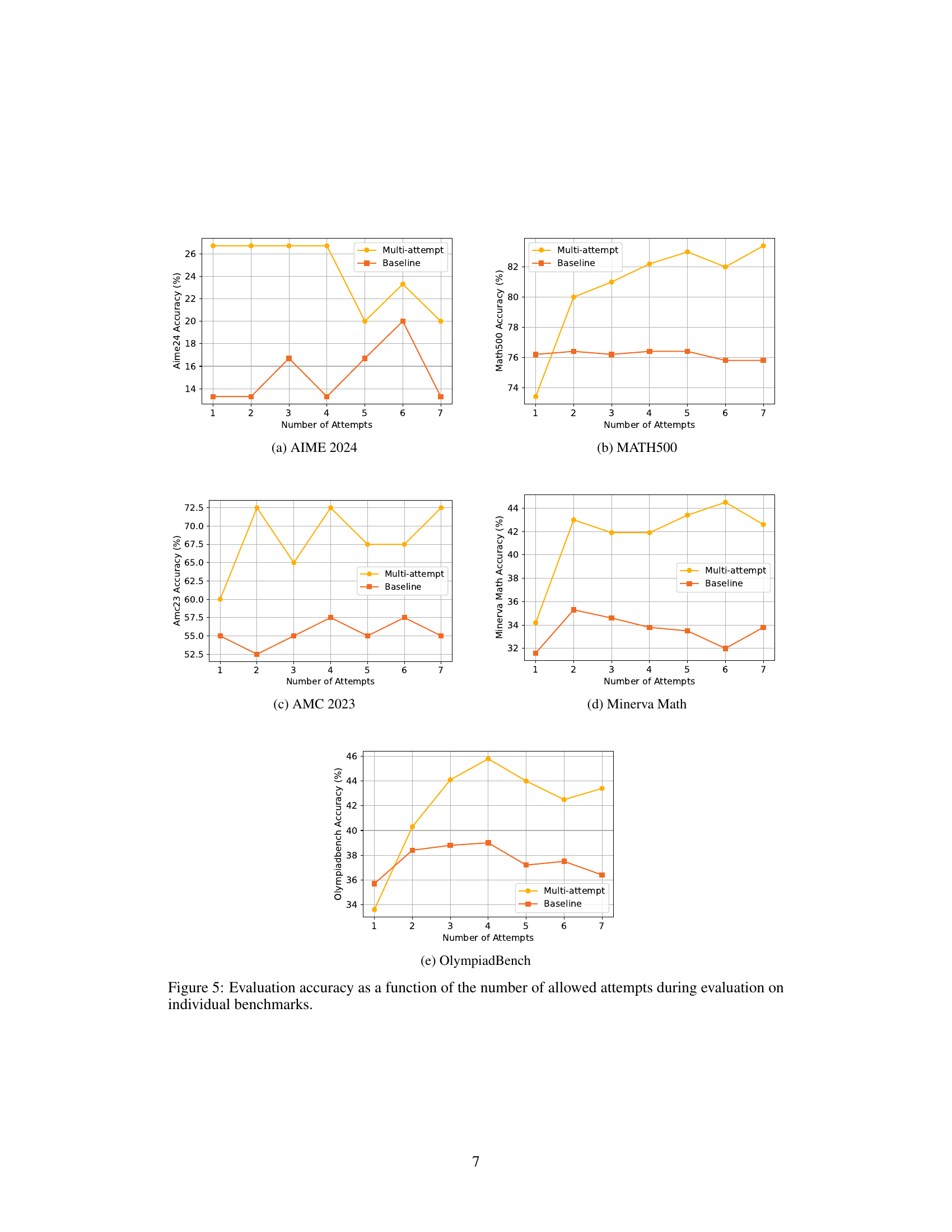
🔼 This figure shows the evaluation accuracy for the AIME 2024 benchmark as a function of the number of allowed attempts during evaluation. The accuracy is compared between a model trained with a multi-attempt approach and a baseline model trained on a standard single-turn task. The x-axis represents the number of attempts allowed, and the y-axis represents the accuracy. The graph shows that the multi-attempt model consistently outperforms the baseline model, demonstrating the effectiveness of the multi-attempt training.
read the caption
(a) AIME 2024

🔼 The figure shows the evaluation accuracy of two different LLMs on the MATH500 benchmark as a function of the number of allowed attempts. One LLM was trained on a multi-attempt task, allowing it to refine responses based on feedback, and the other LLM was trained on a standard single-turn task. The graph compares their performance across different numbers of attempts during evaluation.
read the caption
(b) MATH500

🔼 The figure shows the evaluation accuracy on the AMC 2023 benchmark as a function of the number of allowed attempts during evaluation. It compares the performance of a model trained with a multi-attempt approach to a baseline model trained with a standard single-attempt approach. The x-axis represents the number of attempts, and the y-axis represents the accuracy. The plot visually demonstrates the improvement in accuracy gained by allowing multiple attempts, especially for the multi-attempt trained model.
read the caption
(c) AMC 2023
Full paper#