TL;DR#
Large Language Models (LLMs) often struggle with size reduction without sacrificing accuracy. Existing methods like model distillation and transfer learning have limitations in achieving high accuracy and require careful data/domain selection, which is time-consuming and can lead to conflicting gradients during training, hindering overall learning progress.
To tackle these issues, this paper introduces the Branch-Merge distillation approach, which enhances model compression through two phases: the Branch Phase, where knowledge from a large teacher model is selectively distilled into specialized student models; and the Merge Phase, where these student models are merged to enable cross-domain knowledge transfer and improve generalization. The resulting TinyR1-32B-Preview model outperforms existing models in various benchmarks and provides a scalable solution for creating smaller, high-performing LLMs with reduced computational cost and time.
Key Takeaways#
Why does it matter?#
This paper is important for researchers due to its novel approach to efficiently compressing LLMs while maintaining high accuracy. The Branch-Merge distillation method offers a scalable solution that reduces computational costs and time, making it highly relevant to the current research trends in LLM optimization and deployment.
Visual Insights#

🔼 Figure 1(A) illustrates the two-phase Branch-Merge distillation method. First, the ‘Branch Phase’ involves creating specialized student models by fine-tuning a base model on different domains (math, coding, science). Then, the ‘Merge Phase’ combines these specialized models into a single unified model using Arcee Fusion. Figure 1(B) shows a performance comparison of various LLMs, demonstrating that TinyR1-32B-Preview (the result of the Branch-Merge method) surpasses other distilled models of similar size in math, coding, and science benchmarks, while achieving performance comparable to DeepSeek R1.
read the caption
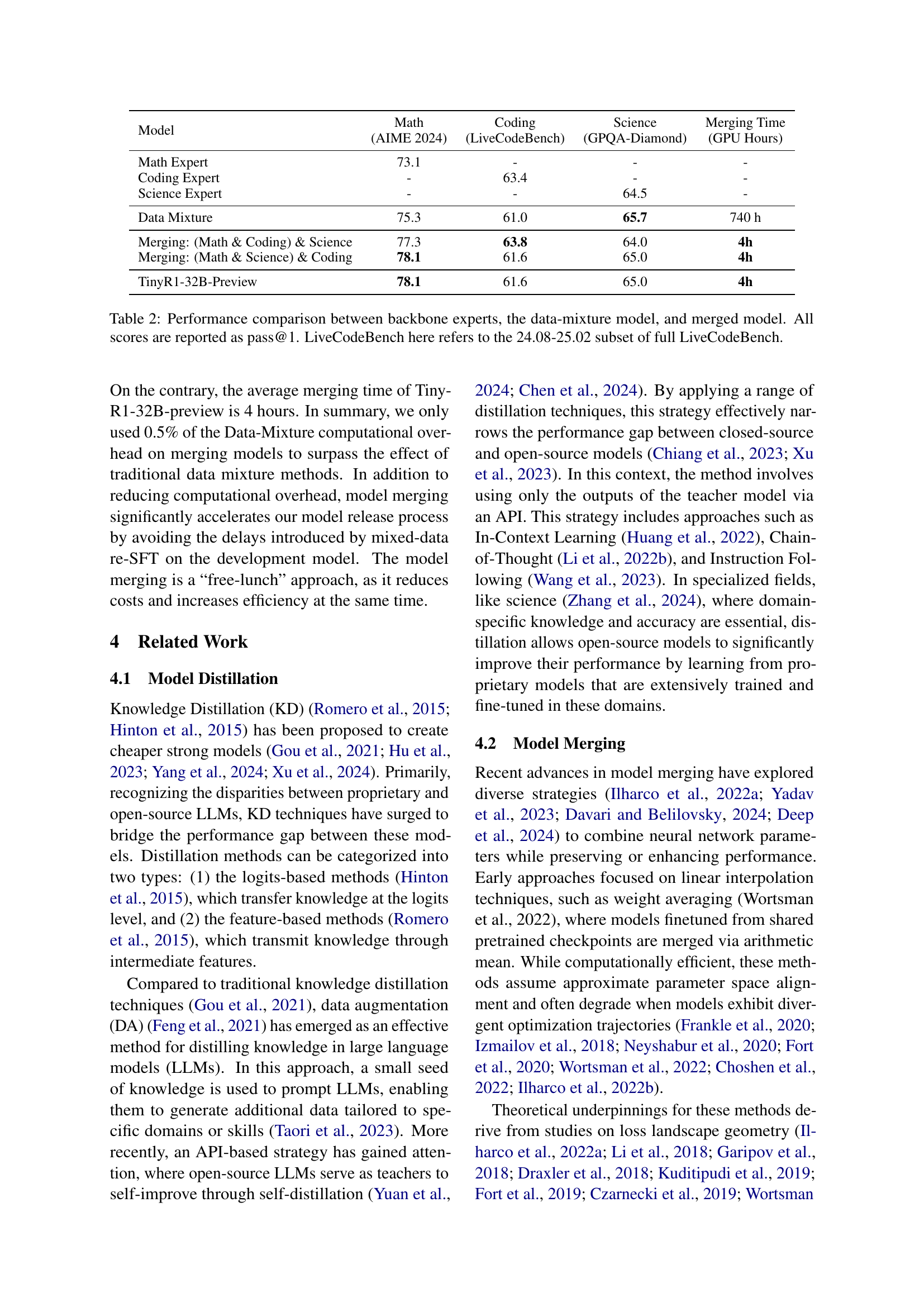
Figure 1: (A) A simplified diagram of our Branch-Merge distillation approach. (1) In the Branch phase, each copy of the Initial Model (backbone) is trained on knowledge from a different domain; (2) In the Merge phase, models are merged based on Arcee Fusion rules. (B) Performance Comparison of different LLM models Mustar (2025). TinyR1-32B-Preview outperforms distilled models of the same size in science, math, and coding and achieves comparable results to Deepseek R1. LiveCodeBench here refers to the 24.08-25.02 subset of full LiveCodeBench.
| Model | Math | Coding | Science |
| (AIME 2024) | (LiveCodeBench 24.08-25.02) | (GPQA-Diamond) | |
| DeepSeek-R1-Distill-Qwen-32B† | 72.6 (9.6k Tokens) | 57.2 (10.1k Tokens) | 62.1 (5.3k Tokens) |
| DeepSeek-R1-Distill-Llama-70B† | 70.0 | 57.5 | 65.2 |
| DeepSeek-R1† | 79.8 (9.6k Tokens) | 65.9 (10.4k Tokens) | 71.5 (5.3k Tokens) |
| TinyR1-32B-Preview (Ours) | 78.1 (11.8k Tokens) | 61.6 (12.4k Tokens) | 65.0 (8.6k Tokens) |
🔼 This table compares the performance of different large language models (LLMs) on three benchmark datasets: AIME 2024 (Mathematics), LiveCodeBench (Coding), and GPQA-Diamond (Science). The models compared include DeepSeek-R1 and its distilled versions (DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Llama-70B), along with the authors’ new model, TinyR1-32B-Preview. Performance is measured by pass@1 (the percentage of correct answers for each dataset). The table also shows the average output token length (including chain-of-thought reasoning) produced by each model, giving an indication of computational cost. Scores from the DeepSeek-R1 paper are marked with a †.
read the caption
Table 1: Performance comparison on benchmark datasets. All scores are reported as pass@1. Scores reported from DeepSeek-R1 paper DeepSeek-AI (2025) are noted with †. The number in parentheses represents the average output token length (including the chain of thought), obtained from our testing.
Full paper#