TL;DR#
Large language models (LLMs) can be enhanced by adding external knowledge. Retrieval-Augmented Generation (RAG) and long-context models are methods for achieving that. However, RAG may miss key information, and long-context models are computationally expensive. Thus, there are limitations that restrict the effectiveness of LLMs.
To address the problem, this paper proposes task-aware key-value (KV) cache compression, which compresses external knowledge in a zero- or few-shot setup. This allows LLMs to reason effectively with compressed information, outperforming RAG and task-agnostic compression methods. The method improves accuracy while reducing inference latency.
Key Takeaways#
Why does it matter?#
This paper introduces a task-aware KV cache compression, offering a method for scaling LLM reasoning beyond retrieval-based methods. It provides new methods for corpus-level reasoning, which can provide new insights and potentially inspire new work.
Visual Insights#
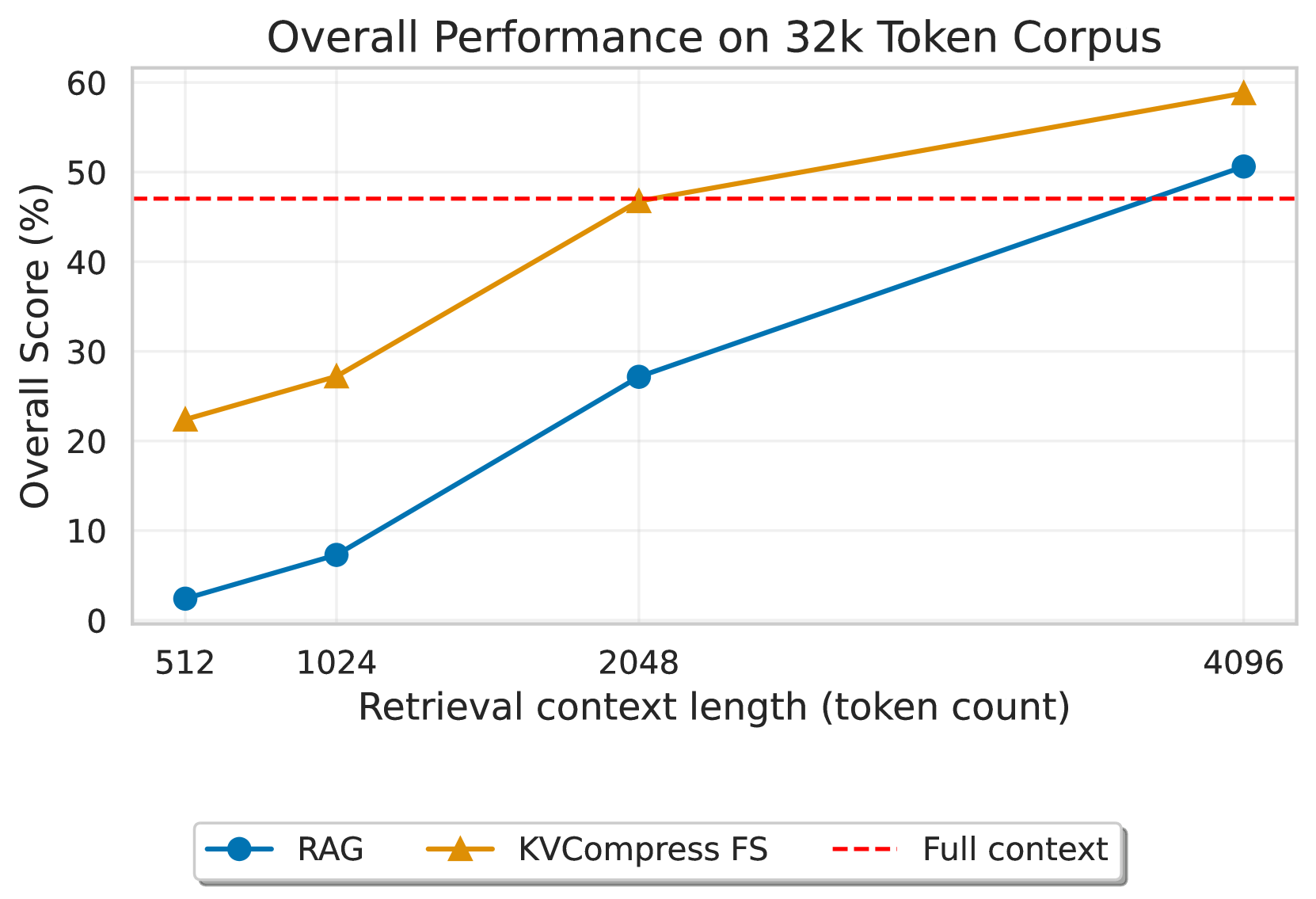
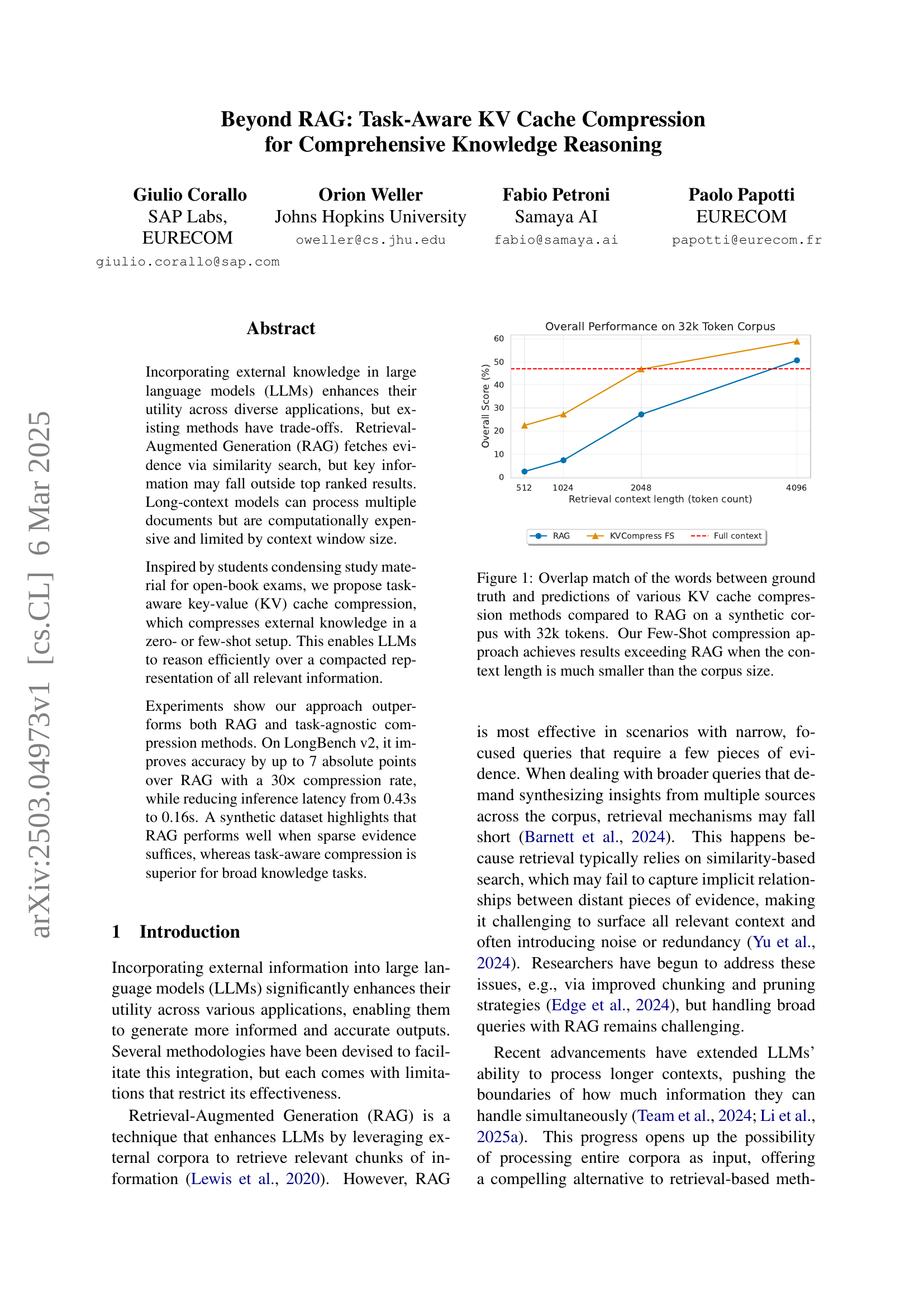
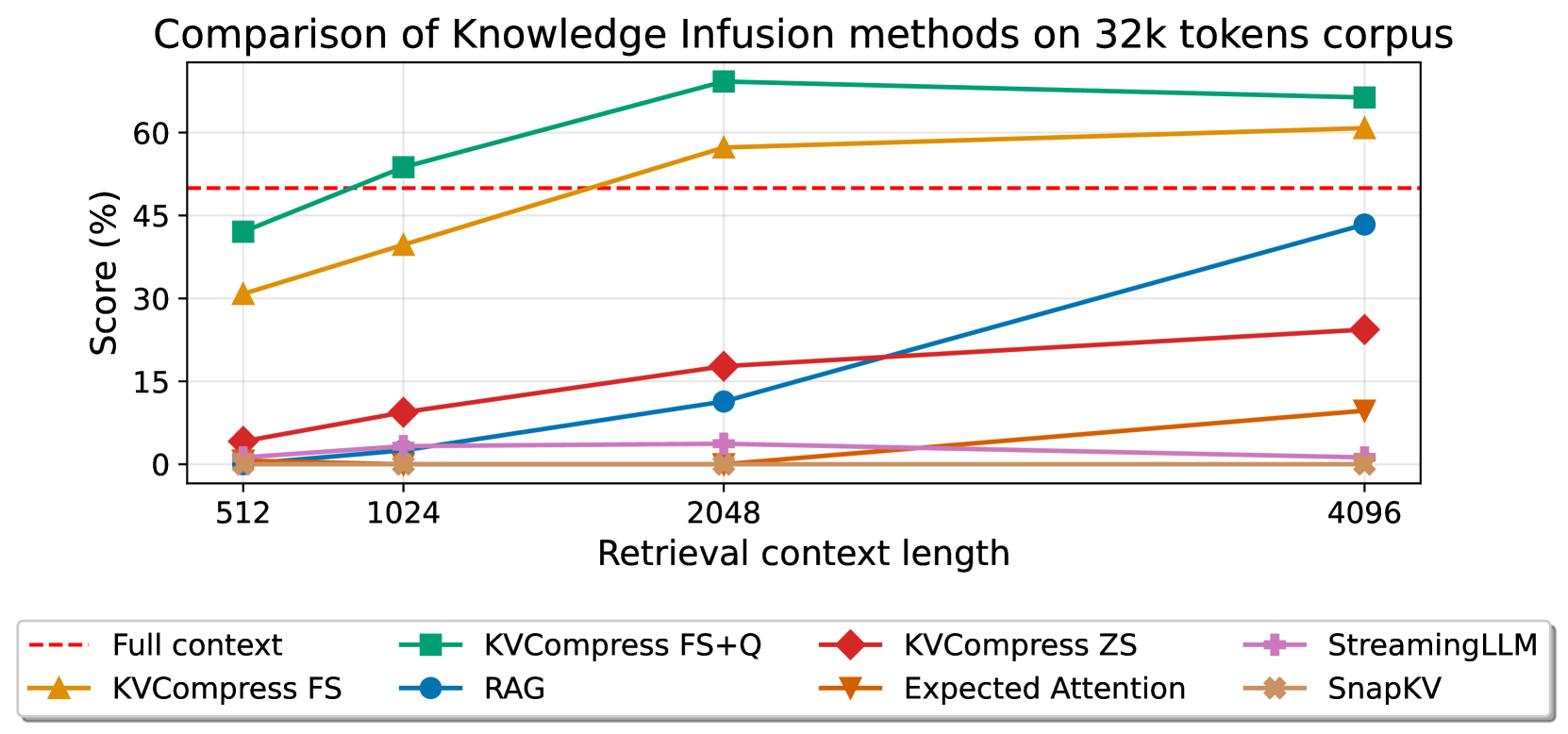
🔼 Figure 1 presents a comparison of different knowledge integration methods for LLMs on a synthetic dataset. The methods compared include Retrieval Augmented Generation (RAG) and several key-value (KV) cache compression techniques, both with and without few-shot examples. The x-axis represents the retrieval context length (in tokens), showing how much of the 32,000 token corpus was used. The y-axis displays the overall accuracy score. The figure demonstrates that the few-shot KV compression approach outperforms RAG, especially when the context length is significantly smaller than the full corpus size. This suggests that for tasks requiring comprehensive knowledge reasoning, compression methods are more effective than retrieval-based methods, particularly when the evidence is broadly distributed across the knowledge base, rather than concentrated in a few retrievable chunks.
read the caption
Figure 1: Overlap match of the words between ground truth and predictions of various KV cache compression methods compared to RAG on a synthetic corpus with 32k tokens. Our Few-Shot compression approach achieves results exceeding RAG when the context length is much smaller than the corpus size.
In-depth insights#
Task-Aware Comp#
Task-aware compression represents a strategic approach to condense information, specifically tailoring the compression process to the demands of a given task. Unlike generic compression methods, task-aware techniques leverage knowledge about the task’s objectives, constraints, and typical data patterns. This allows them to prioritize the preservation of information most relevant to the task, potentially sacrificing less important data to achieve higher compression ratios. Such methods are useful for optimizing performance in scenarios where computational resources are limited, or data transmission costs are high, while still maintaining acceptable levels of accuracy or utility for the target task. The design and implementation of effective task-aware compression algorithms require a deep understanding of both the compression domain and the specific requirements of the application.
RAG vs. KV Cache#
RAG (Retrieval-Augmented Generation) fetches evidence, but info may fall outside top ranks. It excels with focused queries, needing few evidence pieces. KV cache compression compacts all relevant info, enabling reasoning over it efficiently. It is effective for broad queries demanding synthesis, outperforming RAG. Task-aware methods compress in zero/few-shot setups, reasoning efficiently over compacted representations. KV cache reduces memory load, compressing matrices while preserving essential information. RAG’s retrieval relies on similarity search, missing implicit relationships and introducing noise. KV cache compression mitigates memory load, retaining essential info. The paper introduces task-aware compression, balancing efficiency and relevance for superior results, with performance surpassing query-agnostic compression and approaching query-aware compression.
Long Context LLMs#
Long context LLMs face significant challenges in effectively utilizing extended input sequences. While increasing the context window allows processing more information, models often struggle to identify and synthesize relevant pieces from the entire context. Retrieval-Augmented Generation (RAG) offers a solution by fetching external knowledge, but its effectiveness depends on the accuracy of the retrieval mechanism. The paper introduces task-aware KV cache compression as an alternative, aiming to condense relevant information into a compact representation. This approach can potentially outperform RAG in scenarios requiring the synthesis of information from multiple sources, addressing a key limitation of existing methods. The method boosts perforce especially in multifaceted or broad queries.
Synthetic Dataset#
The paper introduces a custom synthetic dataset designed for controlled experiments in question answering (QA). This dataset allows for precise manipulation of interconnectivity between text chunks, enabling thorough evaluation of KV-cache compression and retrieval methods. It uses two query types: direct retrieval (localized information) and join-like (requiring synthesis across chunks). The synthetic datasets will give researchers full control over the complexity level of the dataset by varying inter-chunk connectivity which facilitates the identification of optimal scenarios for each technique by adjusting the connectivity levels. Using synthetic data and query types offer a robust framework for evaluating knowledge reasoning capabilities. This dataset is expected to be publicly released to support future research.
Multi-Hop Fails#
RAG’s reliance on similarity-based retrieval limits its ability to effectively synthesize information from multiple, disparate sources, resulting in significant performance degradation when answering questions that require integrating information from multiple chunks. In high-connectivity scenarios, the performance gap widens further, as relevant information is scattered across numerous chunks. Additionally, RAG struggles with entity disambiguation, particularly when dealing with similar entity names. Embedding-based retrieval often misidentifies relevant passages, retrieving irrelevant chunks due to embedding proximity, hindering accurate reasoning. These limitations highlight the need for alternative approaches that can effectively handle multi-hop reasoning and entity disambiguation in long-context scenarios. The authors’ proposed approach addresses these challenges by precomputing a unified, task-aware compressed cache, enabling more robust coverage of multi-hop or broad queries compared to RAG’s similarity-based lookups. The key insight is that the model can better prioritize critical information through explicit query cues during compression, improving accuracy and reducing the need for extensive retrieval during inference.
More visual insights#
More on figures

🔼 This figure illustrates the task-aware key-value (KV) cache compression technique. It starts with a large KV cache (128k tokens) containing the original context (C) for a given task. This context is then compressed to a much smaller size (16k tokens) using task instructions (T) and a few-shot examples (FS). The compression process focuses on retaining only the essential information needed to answer factual questions related to the task. The resulting compressed cache can then be used by a large language model (LLM) at inference time to answer multiple questions efficiently, as if it had access to the entire, uncompressed original context.
read the caption
Figure 2: An illustration of our compression strategy that reduces the original context (C) from a KV cache of 128k tokens to 16k. This process is guided by task instructions (T) and few-shot examples (FS), condensing the essential information needed for factual QA on the corpus documents. At inference time, the LLM can answer multiple questions as if it had access to the entire (uncompressed) corpus.

🔼 This figure displays the model’s attention mechanism, visualized by the cross-attention scores between the prompt and the context tokens, under four different prompting conditions: (a) only the last token as prompt, (b) a task description as prompt, (c) a task description plus few-shot examples, and (d) a task description, few-shot examples, and a question. The visualization shows how the attention focuses on increasingly relevant context tokens as more information is included in the prompt. The perplexity values, representing the model’s uncertainty in predicting the answer, are also shown, decreasing as the prompt becomes more informative, indicating improved ability to select relevant context tokens.
read the caption
Figure 3: We examine how the model attends to context tokens when conditioned on the last token, a task description, a description with few-shot examples, and a description with both few-shot examples and a question. As we increase the information in the prompt, the cross attention between the prompt and the context better discriminates the context tokens that are relevant for decoding the answer. The perplexity is calculated on the loss for the answer.

🔼 The figure illustrates the structure of a synthetic dataset designed for evaluating the performance of different methods in handling varying levels of complexity in long-context reasoning. The dataset is structured around three entity types: People, Projects, and Memberships. Each entity type is represented by multiple chunks of text, each with a standardized length of 256 tokens. The connectivity level parameter controls the relationships between these entities. In the depicted example, where the connectivity level is set to 2, each person is connected to exactly two projects. This creates different levels of complexity for queries, enabling a comprehensive evaluation of model performance on varying levels of knowledge synthesis and information retrieval.
read the caption
Figure 4: Overview of our synthetic dataset. In this example, the connectivity level is set to 2.

🔼 This figure illustrates the two types of questions used in the synthetic dataset experiments: direct retrieval and join-like questions. Direct retrieval questions can be answered using information from a single text chunk (e.g., ‘Which projects does {pname1} belong to?’). Join-like questions require synthesizing information across multiple chunks (e.g., ‘What are {pname1}’s project domains?’). The example shown has a connectivity level of 2, meaning each person is connected to exactly two projects. This level of connectivity increases dataset complexity, as information is distributed across more chunks, making it more challenging for models to answer.
read the caption
Figure 5: Overview of our questions. In this example, the connectivity level is set to 2.

🔼 Figure 6 illustrates the performance of different methods on join-like questions within a synthetic dataset, as the target context length and connectivity level vary. Join-like questions necessitate synthesizing information from multiple parts of the dataset. The graph displays the performance of RAG (Retrieval-Augmented Generation) and different variants of KV cache compression (KVCompress FS, KVCompress FS+Q). The x-axis represents connectivity level (1-8), indicating the level of interconnectivity between different information chunks. The y-axis indicates the overall performance score (%). Different lines represent different target context lengths, showing how much information is given to the LLM. The dashed lines demonstrate the connectivity level where RAG starts to receive the necessary chunks for processing, highlighting the threshold beyond which RAG starts to underperform. This figure showcases the strength of the KV compression approach over RAG when more intricate inter-connectivity is present in the dataset and limited context is available.
read the caption
Figure 6: Performance by increasing target context length (64x to 8x compression rate) and connectivity level for Join-like questions in the synthetic dataset. The dashed line indicates for which connectivity level RAG gets the needed chunk for a given context length.

🔼 This figure displays the performance of different methods on Direct Retrieval questions from a synthetic dataset, focusing on scenarios with highly similar entity names. The x-axis represents the retrieval context length, reflecting varying levels of compression (from 128x to 16x). The y-axis shows the performance (likely accuracy or a similar metric). By comparing the performance across different retrieval context lengths, the figure illustrates how well each method handles these specific types of questions under different compression ratios, and potentially highlights limitations of certain approaches when faced with similar entity names.
read the caption
Figure 7: Performance by retrieval context length size (128x to 16x compression rate) for Direct Retrieval questions with highly similar entity names in the synthetic dataset.

🔼 Figure 8 illustrates the performance of different methods on the ‘Hard Questions’ subset of the LongBench v2 benchmark as the retrieval context length varies. The x-axis represents the retrieval context length, which is manipulated by applying compression techniques (at rates ranging from 8x to 64x compression). The y-axis shows the accuracy (Exact Match) achieved by the different methods. The figure compares the performance of RAG (Retrieval Augmented Generation), KVCompress FS (Few-Shot Key-Value compression), KVCompress FS+Q (Few-Shot Key-Value compression with added queries), and a full-context baseline. The results demonstrate how the different compression approaches affect accuracy compared to RAG and the full context model when tackling challenging, long-context questions.
read the caption
Figure 8: Performance by retrieval context length size (64x to 8x compression rate) for the Hard Questions in LongBench v2.

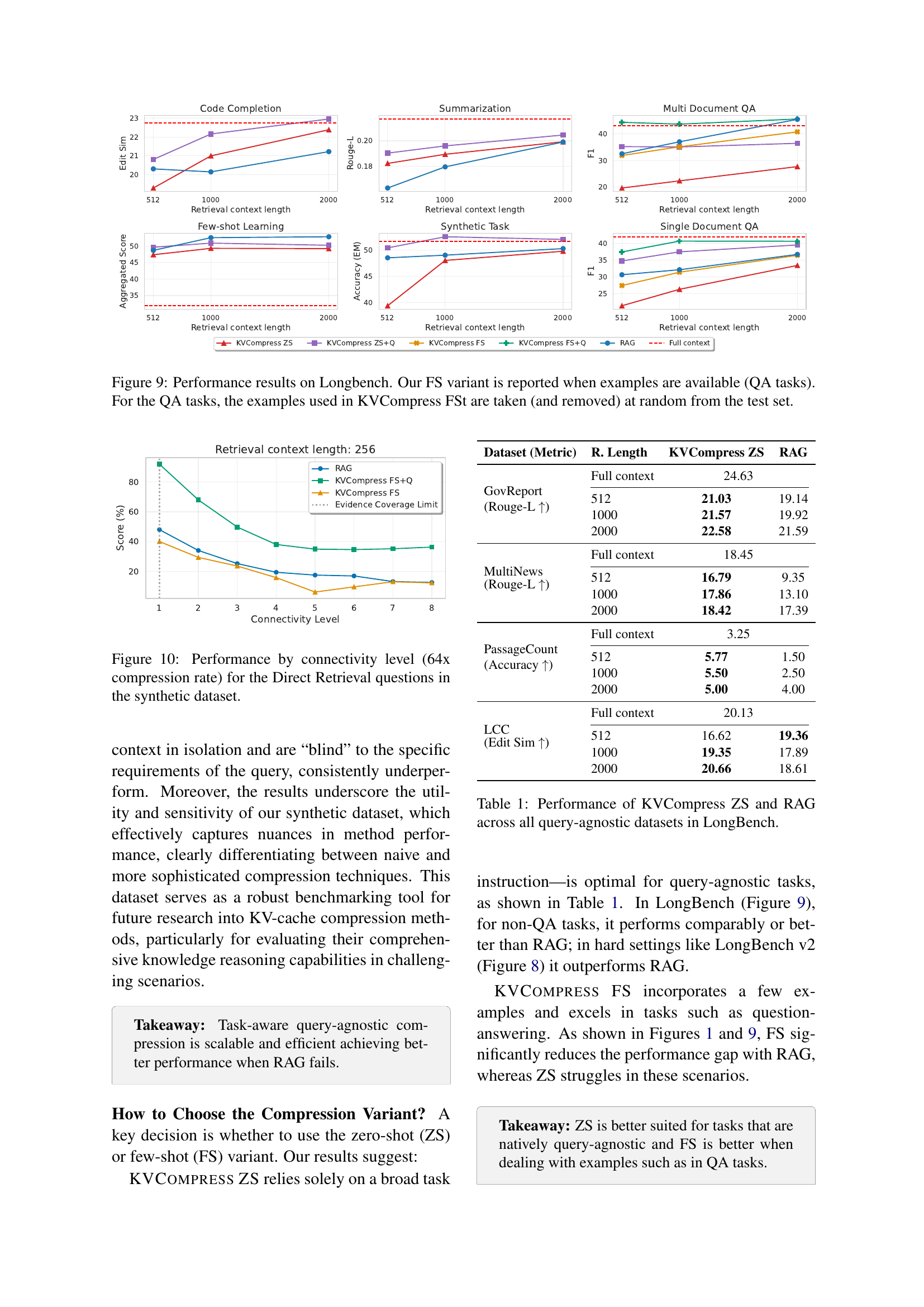
🔼 Figure 9 presents the performance comparison of different knowledge infusion methods on the LongBench benchmark. It shows the performance across various tasks including single-document QA, multi-document QA, code completion, summarization, few-shot learning, and synthetic tasks. The results display the performance of the proposed KVCompress method (both zero-shot and few-shot versions), RAG (Retrieval Augmented Generation), and a full context model as a baseline. For QA tasks within LongBench, the few-shot variant of KVCompress uses examples randomly selected and removed from the test set to ensure fair evaluation. The figure visually represents the performance differences of these methods, allowing for a direct comparison of their effectiveness in various long-context tasks.
read the caption
Figure 9: Performance results on Longbench. Our FS variant is reported when examples are available (QA tasks). For the QA tasks, the examples used in KVCompress FSt are taken (and removed) at random from the test set.

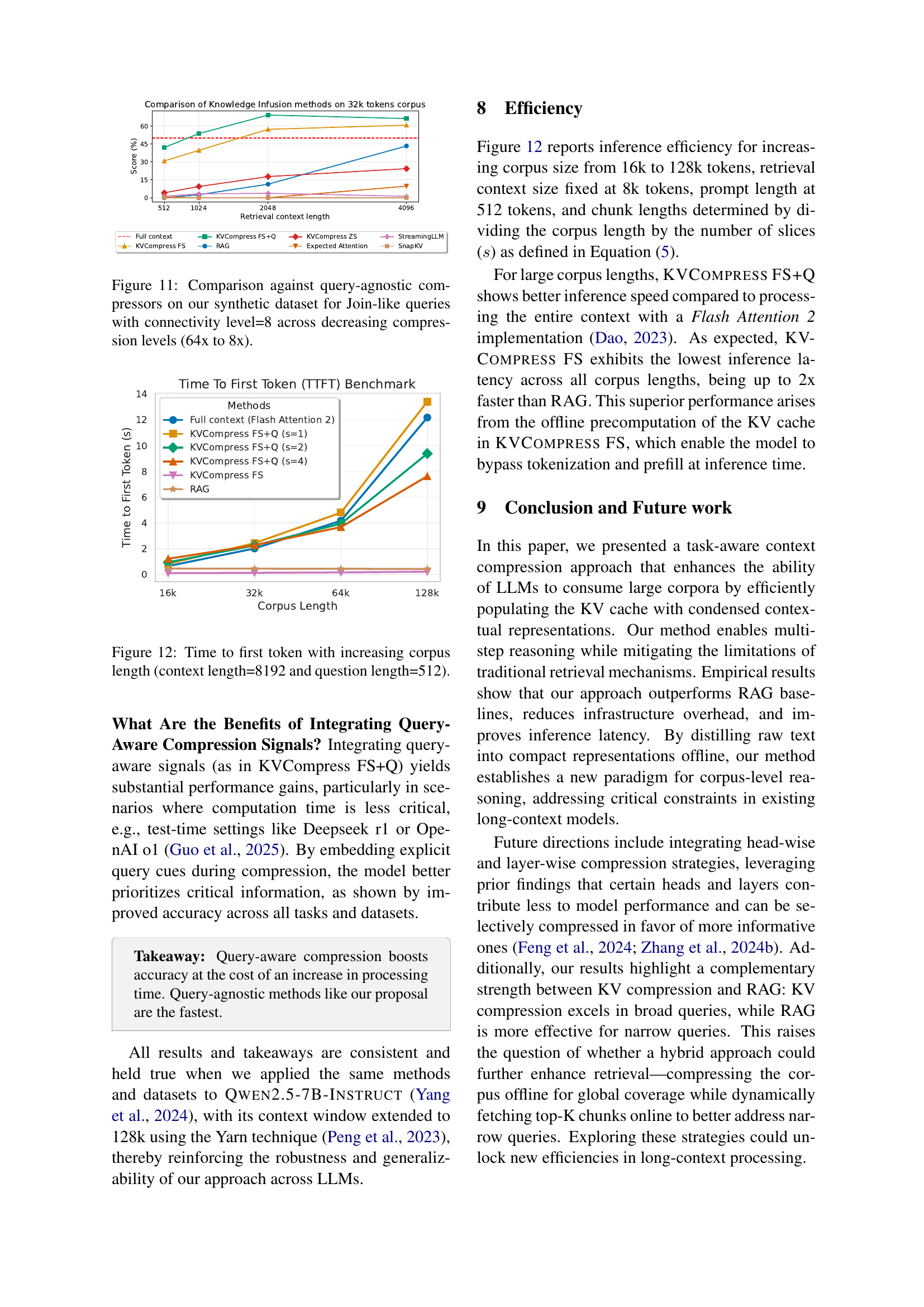
🔼 This figure displays the performance of different methods on direct retrieval questions within a synthetic dataset. The x-axis represents the connectivity level of the dataset, ranging from 1 to 8. Higher connectivity indicates a more complex data structure where relevant information is distributed across multiple chunks of text. The y-axis represents the performance score (%). The graph compares the performance of RAG (Retrieval Augmented Generation) and three variations of KVCompress (a task-aware key-value cache compression method) at a 64x compression rate. The KVCompress variants use zero-shot, few-shot, and few-shot with query approaches. The figure demonstrates how RAG performance degrades with increasing connectivity, highlighting the limitation of similarity-based retrieval in complex scenarios. In contrast, KVCompress methods show greater robustness against increasing complexity.
read the caption
Figure 10: Performance by connectivity level (64x compression rate) for the Direct Retrieval questions in the synthetic dataset.
🔼 Figure 11 presents a comparison of the performance of different query-agnostic compression methods on a synthetic dataset designed to evaluate multi-hop reasoning. Specifically, it focuses on join-like queries (queries requiring the synthesis of information from multiple parts of the corpus) and uses a high connectivity level (level 8, indicating many connections between different parts of the data). The comparison is done across various compression levels, from 64x to 8x compression, to show how performance changes with decreasing compression. The graph helps understand the trade-off between compression rate and model accuracy.
read the caption
Figure 11: Comparison against query-agnostic compressors on our synthetic dataset for Join-like queries with connectivity level=8 across decreasing compression levels (64x to 8x).

🔼 Figure 12 illustrates the impact of increasing corpus size on the time taken to generate the first token in a language model. The experiment holds the context length constant at 8192 tokens and the question length at 512 tokens, while varying the overall corpus size. Different methods for knowledge infusion (including RAG and the proposed KVCompress method) are compared to show their relative efficiency in processing varied corpus sizes. The x-axis represents corpus length, and the y-axis shows the time to first token (TTFT) in seconds.
read the caption
Figure 12: Time to first token with increasing corpus length (context length=8192 and question length=512).
Full paper#