TL;DR#
Recent LLMs show great text generation, but evaluating their writing is tough. Current benchmarks focus on generic tasks and miss the details needed for high-quality writing in different areas. To fix this, the paper creates a comprehensive benchmark to assess LLMs across creative, persuasive, informative, and technical writing.
The paper introduces a query-dependent evaluation, where LLMs create criteria for each instance. A tuned critic model scores based on these criteria, evaluating style, format, and length. They show this framework is valid, enabling 7B models to approach SOTA performance. Releasing the benchmark and tools helps advance LLMs in writing.
Key Takeaways#
Why does it matter?#
WritingBench offers a comprehensive benchmark to evaluate LLMs in generative writing, enabling nuanced assessment and data curation. This advances creative AI and inspires improvements in model capabilities across diverse tasks. The resources helps refine writing models and create new, high-quality datasets.
Visual Insights#

🔼 This figure shows an example of a query from the WritingBench benchmark. The query is for a video script for a film review, written in the style of past commentary videos. The query’s requirements are color-coded to indicate different categories such as Personalization, Stylistic Adjustments, Format Specifications, Content Specificity, and Length Constraints. Three main requirement categories are highlighted with black borders, signifying their importance in the evaluation process. Red phrases indicate the additional materials provided to support the writing task. The color-coding and materials highlight the complexity WritingBench aims to address, moving beyond simple single-sentence prompts to simulate real-world writing scenarios.
read the caption
Figure 1: WritingBench query example with color-coded requirements. The three black-bordered categories highlight essential requirements analyzed in follow-up assessments. Red phrases correlate with gray-shaded writing support materials.
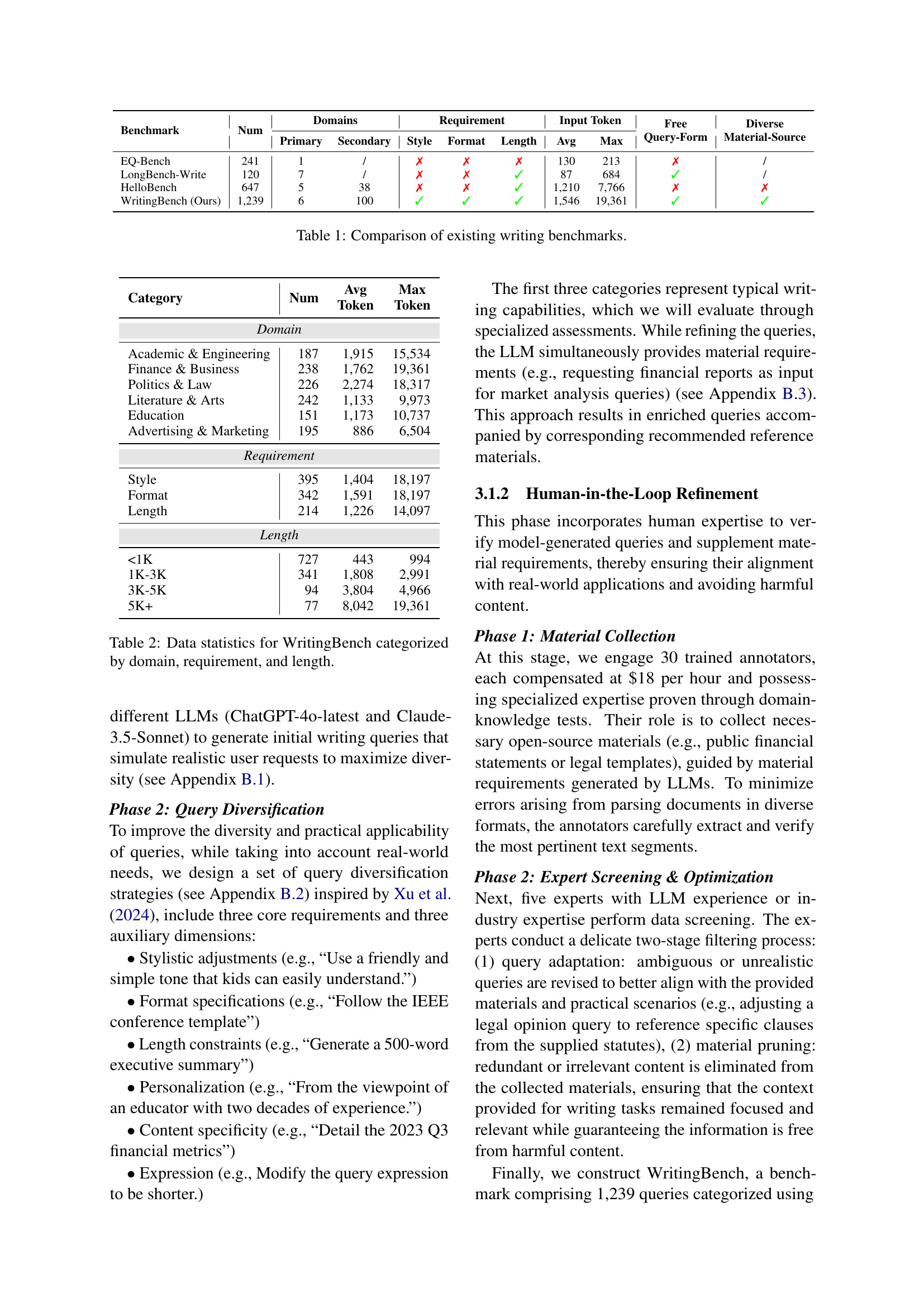
| Benchmark | Num | Domains | Requirement | Input Token | Free Query-Form | Diverse Material-Source | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Primary | Secondary | Style | Format | Length | Avg | Max | ||||
| EQ-Bench | 241 | 1 | / | ✗ | ✗ | ✗ | 130 | 213 | ✗ | / |
| LongBench-Write | 120 | 7 | / | ✗ | ✗ | ✓ | 87 | 684 | ✓ | / |
| HelloBench | 647 | 5 | 38 | ✗ | ✗ | ✓ | 1,210 | 7,766 | ✗ | ✗ |
| WritingBench (Ours) | 1,239 | 6 | 100 | ✓ | ✓ | ✓ | 1,546 | 19,361 | ✓ | ✓ |
🔼 This table compares several existing writing benchmarks, highlighting key differences in their capabilities. It shows the number of primary and secondary domains covered by each benchmark, as well as whether or not they include requirements for style, format, and length of the generated text. The table also indicates the average and maximum number of input tokens, the format of the queries, and the diversity of data sources used.
read the caption
Table 1: Comparison of existing writing benchmarks.
In-depth insights#
LLM Writ’g Gaps#
LLMs show promise in writing, but challenges remain in evaluation. Current benchmarks often focus on generic text or have limited writing tasks, failing to capture the diversity and complexity of high-quality written content. Existing metrics are inadequate for assessing creativity, logical reasoning, and stylistic precision required for generative writing. A need for query-dependent evaluation that can capture the nuances of specific tasks, styles, formats and lengths is required. Static metrics also lack the robustness and multi dimensional nature needed for writing, it’s important to improve in areas of integration with material and depth.
Query-Dep Eval#
A query-dependent evaluation framework dynamically assesses generative writing, addressing the limitations of static criteria. It uses LLMs to generate instance-specific evaluation criteria, considering style, format, and material usage, fostering nuanced assessments. This is in contrast to traditional metrics. A critic model scores responses against generated criteria, enhancing evaluation accuracy and human alignment. This adaptability allows it to evaluate tasks, and helps identify areas where AI models can improve in various writing dimensions.
Data-centric SFT#
While not explicitly mentioned, a ‘Data-centric SFT’ approach would emphasize the crucial role of data quality and relevance in supervised fine-tuning (SFT). This means prioritizing data curation, potentially involving techniques like filtering, augmentation, or re-weighting to improve model performance. It would likely involve rigorous data analysis to identify biases, gaps, and areas where the model struggles. The goal is to optimize the training data to maximize the learning efficiency and effectiveness of SFT, leading to improved generation quality, style consistency, and adherence to specific requirements, ultimately resulting in better writing capabilites.
CoT Benifits#
Chain-of-Thought (CoT) prompting significantly enhances creative content generation in LLMs. Models leveraging CoT outperform their non-CoT counterparts, showing its impact. This is seen from improvement in knowledge distillation experiments using DeepSeek-R1. Evaluating across benchmarks that CoT’s capacity in storytelling. These findings points out the fact that it is important for LLMs to incorporate CoT when dealing with creative tasks. Models with CoT consistently surpass those without, highlighting CoT reasoning can empower language models.
Long Output Lag#
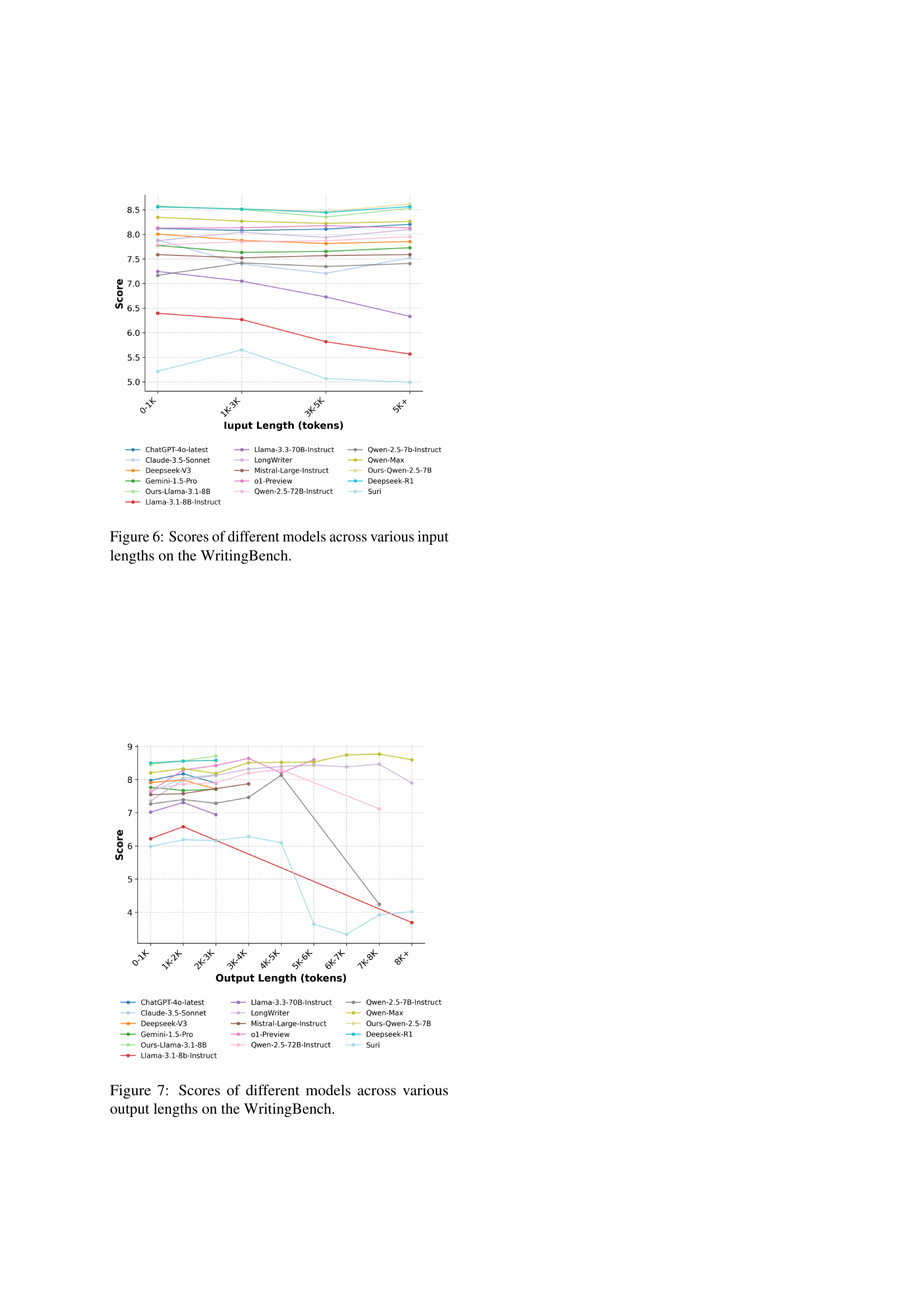
Writing quality tends to remain stable within a certain generation length, while length is the determining factor for overall output quality. Most models have limitations in response generation, and generally produce outputs that are approximately constrained to 3,000 tokens, so output quality tends to be stable below this range. However, there are smaller models that suffer more severe performance degradation when the constraint reaches a certain threshold, with the performance degradation characterized by repetitive outputs. LongWriter and Qwen-Max both show effective support for extended response lengths due to optimization in long-form generation, which shows the importance of improvement capabilities.
More visual insights#
More on figures
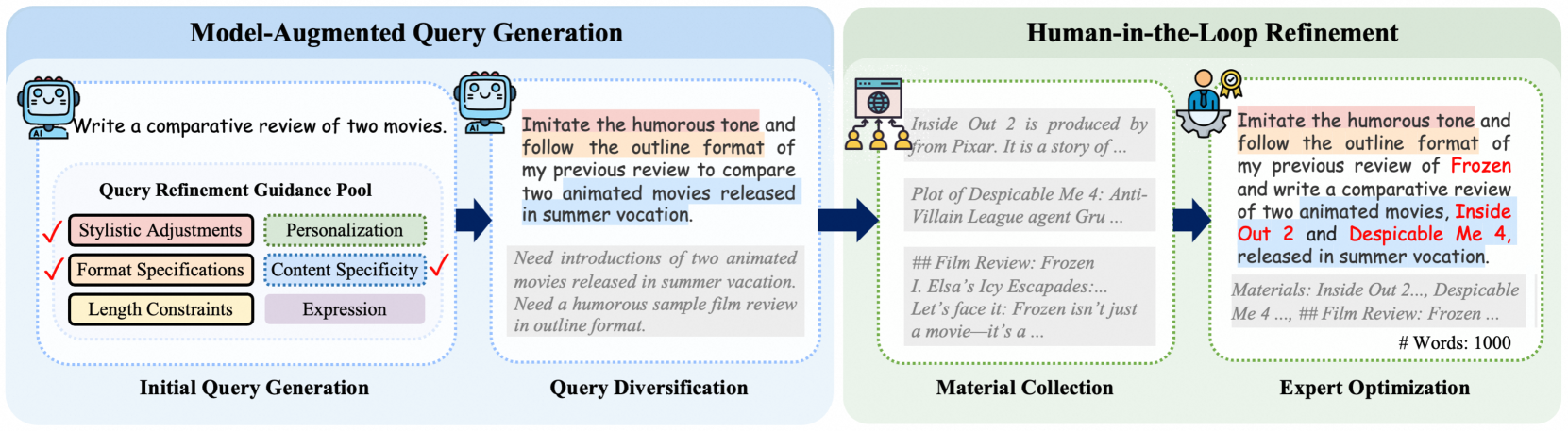
🔼 This figure illustrates the four-stage query construction pipeline used to create WritingBench queries. It starts with initial query generation using LLMs, then uses a refinement pool containing five writing requirements (three core competencies—personalization, stylistic adjustments, and format specifications—highlighted with black borders) and an expression type (purple). Checked strategies, refining the initial queries, are applied to produce multi-requirement prompts (color-coded text), with red phrases referencing gray-shaded writing support materials provided in the initial query. The process ensures diverse writing tasks covering various domains and includes integrating heterogeneous sources of materials. The implementation details are described in Section 3.1 of the paper.
read the caption
Figure 2: Construction pipeline of WritingBench queries. The refinement pool contains five writing requirements (three core competencies with black borders) and one expression type (purple). Checked strategies refine initial queries into multi-requirement prompts (color-coded text) with red phrases referencing gray materials. Implementation details in Section 3.1.

🔼 This figure shows a donut chart illustrating the distribution of WritingBench’s 1239 queries across six primary domains and their corresponding 100 secondary subdomains. Each primary domain is represented by a segment of the donut chart and its size corresponds to the number of queries in that domain. The secondary subdomains are further broken down within each primary domain, and the number of queries (Num) and the number of subdomains (Sub) are indicated for each primary domain. The chart visually represents the breadth and depth of WritingBench’s coverage of various writing tasks.
read the caption
Figure 3: Domain categories in WritingBench. Inner represents the 6 primary domains and outer depicts 100 secondary subdomains (Sub = subdomains per category, Num = dataset entries).

🔼 This figure showcases the dynamic criteria generation process within WritingBench. A writing query is provided as input, and the system automatically generates five evaluation criteria, each with a detailed description and a 10-point scoring rubric. The diverse background colors highlight the different types of requirements (e.g., formatting, style, content). This illustrates how WritingBench adapts its evaluation to each writing task, providing a more nuanced and comprehensive assessment compared to traditional static evaluation methods.
read the caption
Figure 4: Example of dynamically generating criteria for a writing query in WritingBench. Different background colors represent various types of requirements.

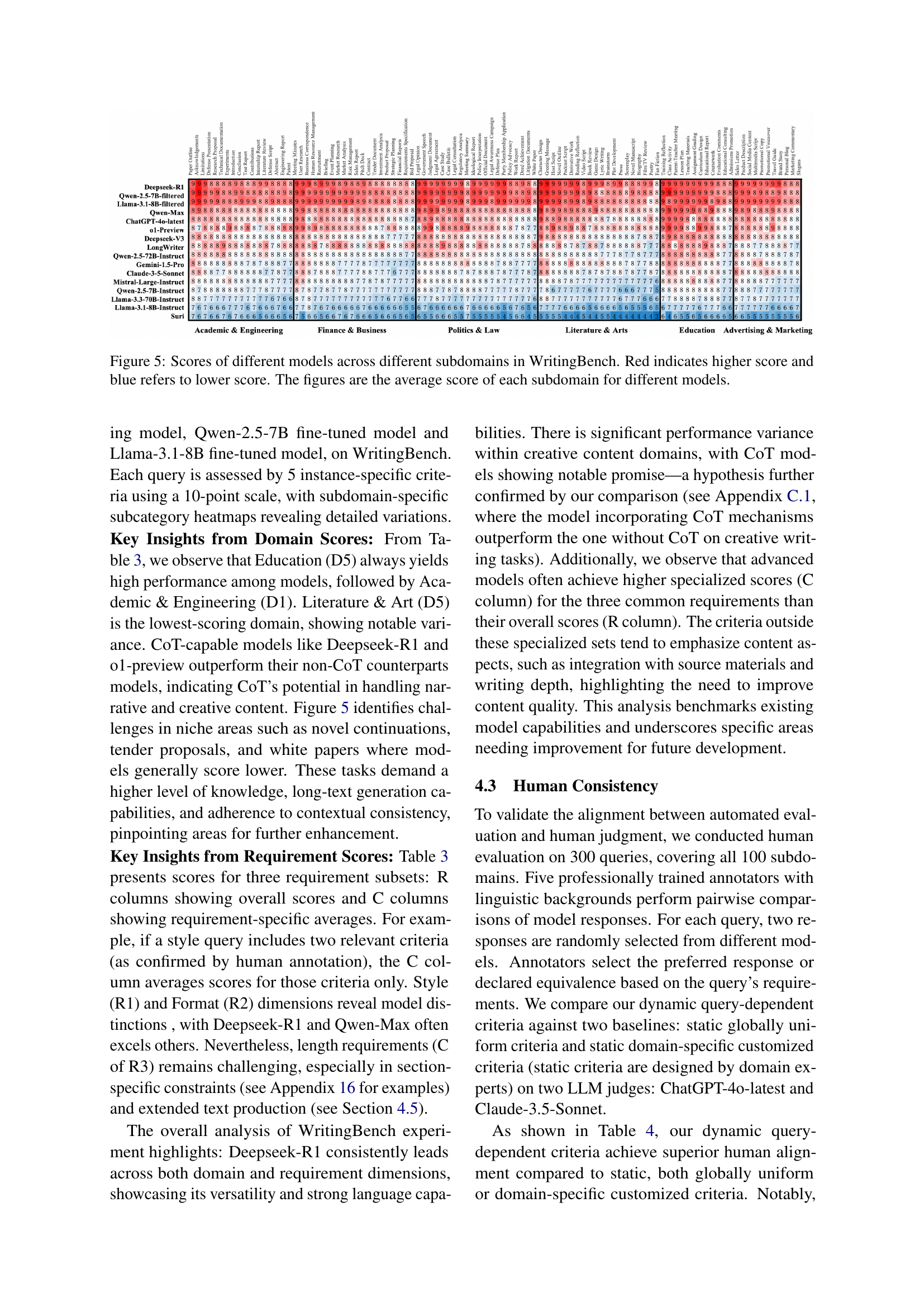
🔼 Figure 5 is a heatmap visualization showing the performance of various LLMs (large language models) across 100 subdomains within six primary domains of the WritingBench benchmark. Each subdomain represents a specific type of writing task (e.g., writing a scientific paper, a legal document, a poem etc.). The color intensity represents the average score achieved by each model on each subdomain, with red indicating higher scores and blue representing lower scores. This figure allows for a detailed comparison of the strengths and weaknesses of different LLMs in various writing scenarios.
read the caption
Figure 5: Scores of different models across different subdomains in WritingBench. Red indicates higher score and blue refers to lower score. The figures are the average score of each subdomain for different models.

🔼 This figure presents a performance comparison of various large language models (LLMs) on the WritingBench benchmark across different input lengths. The x-axis represents the range of input lengths (in tokens), and the y-axis shows the corresponding average scores achieved by each LLM. The different colored lines represent different LLMs, allowing for a visual comparison of how their performance varies with input length. This illustrates the impact of input length on the ability of each model to generate high-quality writing.
read the caption
Figure 6: Scores of different models across various input lengths on the WritingBench.

🔼 This figure shows the performance of various LLMs (large language models) on the WritingBench benchmark across different output lengths. The x-axis represents output length in tokens, and the y-axis represents the average score achieved by each model. Each line represents a different LLM, illustrating how well each model performs at generating text of varying lengths. The plot helps to identify strengths and weaknesses of the LLMs in producing longer or shorter responses, highlighting models better suited for generating longer-form content. The scores likely reflect a composite of quality metrics such as fluency, coherence, and relevance.
read the caption
Figure 7: Scores of different models across various output lengths on the WritingBench.
More on tables
| Category | Num |
|
| ||||
|---|---|---|---|---|---|---|---|
| Domain | |||||||
| Academic & Engineering | 187 | 1,915 | 15,534 | ||||
| Finance & Business | 238 | 1,762 | 19,361 | ||||
| Politics & Law | 226 | 2,274 | 18,317 | ||||
| Literature & Arts | 242 | 1,133 | 9,973 | ||||
| Education | 151 | 1,173 | 10,737 | ||||
| Advertising & Marketing | 195 | 886 | 6,504 | ||||
| Requirement | |||||||
| Style | 395 | 1,404 | 18,197 | ||||
| Format | 342 | 1,591 | 18,197 | ||||
| Length | 214 | 1,226 | 14,097 | ||||
| Length | |||||||
| <1K | 727 | 443 | 994 | ||||
| 1K-3K | 341 | 1,808 | 2,991 | ||||
| 3K-5K | 94 | 3,804 | 4,966 | ||||
| 5K+ | 77 | 8,042 | 19,361 | ||||
🔼 This table presents a statistical overview of the WritingBench dataset, categorized by six primary domains and 100 subdomains. It shows the number of queries, average and maximum token counts for inputs and outputs, and the distribution of queries across different length categories (less than 1k tokens, 1k-3k tokens, 3k-5k tokens, and more than 5k tokens). The table also details the distribution of queries based on three key writing requirements: style, format, and length.
read the caption
Table 2: Data statistics for WritingBench categorized by domain, requirement, and length.
| Avg |
| Token |
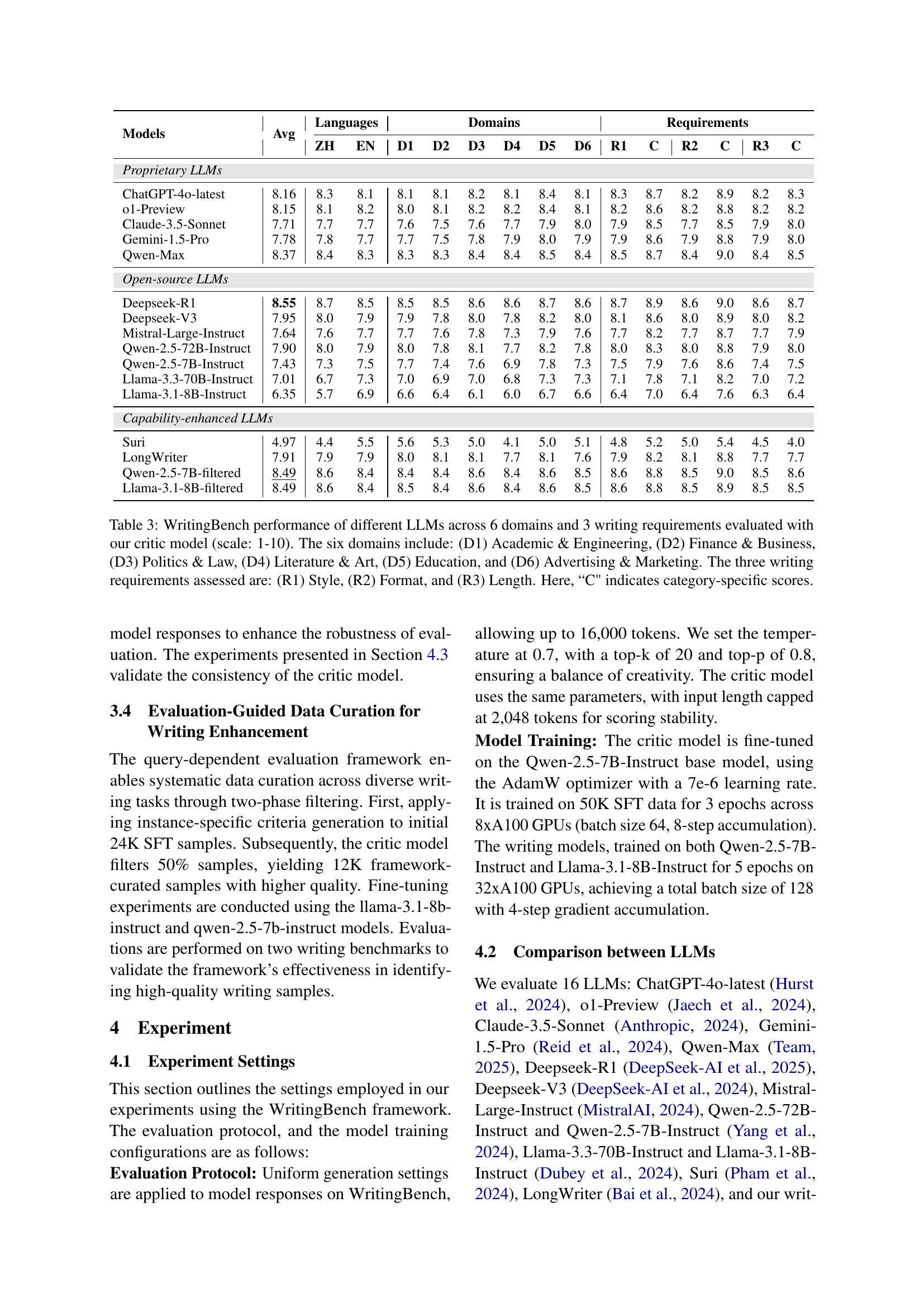
🔼 This table presents the WritingBench performance evaluation results for various Large Language Models (LLMs). The evaluation was conducted using a critic model and focuses on six writing domains (Academic & Engineering, Finance & Business, Politics & Law, Literature & Art, Education, and Advertising & Marketing) across three writing requirements (Style, Format, and Length). Scores range from 1 to 10, reflecting the quality of LLM writing in each domain and requirement. The ‘C’ column signifies the category-specific scores, providing a more granular view of LLM performance on particular aspects within each domain.
read the caption
Table 3: WritingBench performance of different LLMs across 6 domains and 3 writing requirements evaluated with our critic model (scale: 1-10). The six domains include: (D1) Academic & Engineering, (D2) Finance & Business, (D3) Politics & Law, (D4) Literature & Art, (D5) Education, and (D6) Advertising & Marketing. The three writing requirements assessed are: (R1) Style, (R2) Format, and (R3) Length. Here, “C' indicates category-specific scores.
| Max |
| Token |
🔼 This table presents the results of a human evaluation experiment comparing different methods for generating evaluation criteria in a writing benchmark. Specifically, it examines the agreement between human judges and three different approaches: using static, globally uniform criteria; static, domain-specific criteria; and dynamic, query-dependent criteria. The experiment uses two LLMs, ChatGPT-4 (referred to as ChatGPT) and Claude-3.5-Sonnet (referred to as Claude), as judges to assess the consistency of each criteria generation method. The scores represent the percentage of agreement between the human judges and the respective LLM judge.
read the caption
Table 4: Comparison of human consistency scores across different criteria generation methods. ChatGPT corresponds to ChatGPT-4o-latest, Claude corresponds to Claude-3.5-Sonnet.
| Models | Avg | Languages | Domains | Requirements | |||||||||||
| ZH | EN | D1 | D2 | D3 | D4 | D5 | D6 | R1 | C | R2 | C | R3 | C | ||
| Proprietary LLMs | |||||||||||||||
| ChatGPT-4o-latest | 8.16 | 8.3 | 8.1 | 8.1 | 8.1 | 8.2 | 8.1 | 8.4 | 8.1 | 8.3 | 8.7 | 8.2 | 8.9 | 8.2 | 8.3 |
| o1-Preview | 8.15 | 8.1 | 8.2 | 8.0 | 8.1 | 8.2 | 8.2 | 8.4 | 8.1 | 8.2 | 8.6 | 8.2 | 8.8 | 8.2 | 8.2 |
| Claude-3.5-Sonnet | 7.71 | 7.7 | 7.7 | 7.6 | 7.5 | 7.6 | 7.7 | 7.9 | 8.0 | 7.9 | 8.5 | 7.7 | 8.5 | 7.9 | 8.0 |
| Gemini-1.5-Pro | 7.78 | 7.8 | 7.7 | 7.7 | 7.5 | 7.8 | 7.9 | 8.0 | 7.9 | 7.9 | 8.6 | 7.9 | 8.8 | 7.9 | 8.0 |
| Qwen-Max | 8.37 | 8.4 | 8.3 | 8.3 | 8.3 | 8.4 | 8.4 | 8.5 | 8.4 | 8.5 | 8.7 | 8.4 | 9.0 | 8.4 | 8.5 |
| Open-source LLMs | |||||||||||||||
| Deepseek-R1 | 8.55 | 8.7 | 8.5 | 8.5 | 8.5 | 8.6 | 8.6 | 8.7 | 8.6 | 8.7 | 8.9 | 8.6 | 9.0 | 8.6 | 8.7 |
| Deepseek-V3 | 7.95 | 8.0 | 7.9 | 7.9 | 7.8 | 8.0 | 7.8 | 8.2 | 8.0 | 8.1 | 8.6 | 8.0 | 8.9 | 8.0 | 8.2 |
| Mistral-Large-Instruct | 7.64 | 7.6 | 7.7 | 7.7 | 7.6 | 7.8 | 7.3 | 7.9 | 7.6 | 7.7 | 8.2 | 7.7 | 8.7 | 7.7 | 7.9 |
| Qwen-2.5-72B-Instruct | 7.90 | 8.0 | 7.9 | 8.0 | 7.8 | 8.1 | 7.7 | 8.2 | 7.8 | 8.0 | 8.3 | 8.0 | 8.8 | 7.9 | 8.0 |
| Qwen-2.5-7B-Instruct | 7.43 | 7.3 | 7.5 | 7.7 | 7.4 | 7.6 | 6.9 | 7.8 | 7.3 | 7.5 | 7.9 | 7.6 | 8.6 | 7.4 | 7.5 |
| Llama-3.3-70B-Instruct | 7.01 | 6.7 | 7.3 | 7.0 | 6.9 | 7.0 | 6.8 | 7.3 | 7.3 | 7.1 | 7.8 | 7.1 | 8.2 | 7.0 | 7.2 |
| Llama-3.1-8B-Instruct | 6.35 | 5.7 | 6.9 | 6.6 | 6.4 | 6.1 | 6.0 | 6.7 | 6.6 | 6.4 | 7.0 | 6.4 | 7.6 | 6.3 | 6.4 |
| Capability-enhanced LLMs | |||||||||||||||
| Suri | 4.97 | 4.4 | 5.5 | 5.6 | 5.3 | 5.0 | 4.1 | 5.0 | 5.1 | 4.8 | 5.2 | 5.0 | 5.4 | 4.5 | 4.0 |
| LongWriter | 7.91 | 7.9 | 7.9 | 8.0 | 8.1 | 8.1 | 7.7 | 8.1 | 7.6 | 7.9 | 8.2 | 8.1 | 8.8 | 7.7 | 7.7 |
| Qwen-2.5-7B-filtered | 8.49 | 8.6 | 8.4 | 8.4 | 8.4 | 8.6 | 8.4 | 8.6 | 8.5 | 8.6 | 8.8 | 8.5 | 9.0 | 8.5 | 8.6 |
| Llama-3.1-8B-filtered | 8.49 | 8.6 | 8.4 | 8.5 | 8.4 | 8.6 | 8.4 | 8.6 | 8.5 | 8.6 | 8.8 | 8.5 | 8.9 | 8.5 | 8.5 |
🔼 This table presents the performance evaluation results of writing models on two benchmarks: WritingBench and EQBench. The models are categorized as either trained on the full dataset (’-all’) or a filtered subset (’-filtered’) of high-quality data curated using the WritingBench framework. The scores provide a quantitative comparison of the models’ writing capabilities, highlighting the impact of data filtering on model performance.
read the caption
Table 5: Performance evaluation of our writing models on two benchmarks.’-filtered’ indicates models trained with filtered data, while ’-all’ refers to those trained with the full dataset.
| Evaluation Metric | Judge | Score |
| Static Global | ChatGPT | 69% |
| Static Domain-Specific | ChatGPT | 40% |
| Dynamic Query-Dependent | ChatGPTt | 79% |
| Static Global | Claude | 65% |
| Static Domain-Specific | Claude | 59% |
| Dynamic Query-Dependent | Claude | 87% |
| Dynamic Query-Dependent | Critic Model | 83% |
🔼 This table presents the prompt used to initiate the generation of writing queries in the WritingBench benchmark. The prompt instructs a language model to produce 10 distinct writing requests under a specified secondary domain, while remaining within the context of a primary domain. It emphasizes the need for detailed and specific requests that reflect realistic user needs and tone, and specifies the desired JSON format for the output.
read the caption
Table 6: Initial query generation prompt introduced in Section 3.1.1.
| Models | WritingBench | Benchmark2 |
|---|---|---|
| Deepseek-R1 | 8.55 | 4.79 |
| Qwen-2.5-7B-Instruct | 7.43 | 4.39 |
| Llama-3.1-8B-Instruct | 6.35 | 3.12 |
| Qwen-2.5-7B-all | 8.46 | 4.69 |
| Qwen-2.5-7B-filtered | 8.49 | 4.70 |
| Llama-3.1-8B-all | 8.45 | 4.65 |
| Llama-3.1-8B-filtered | 8.49 | 4.65 |
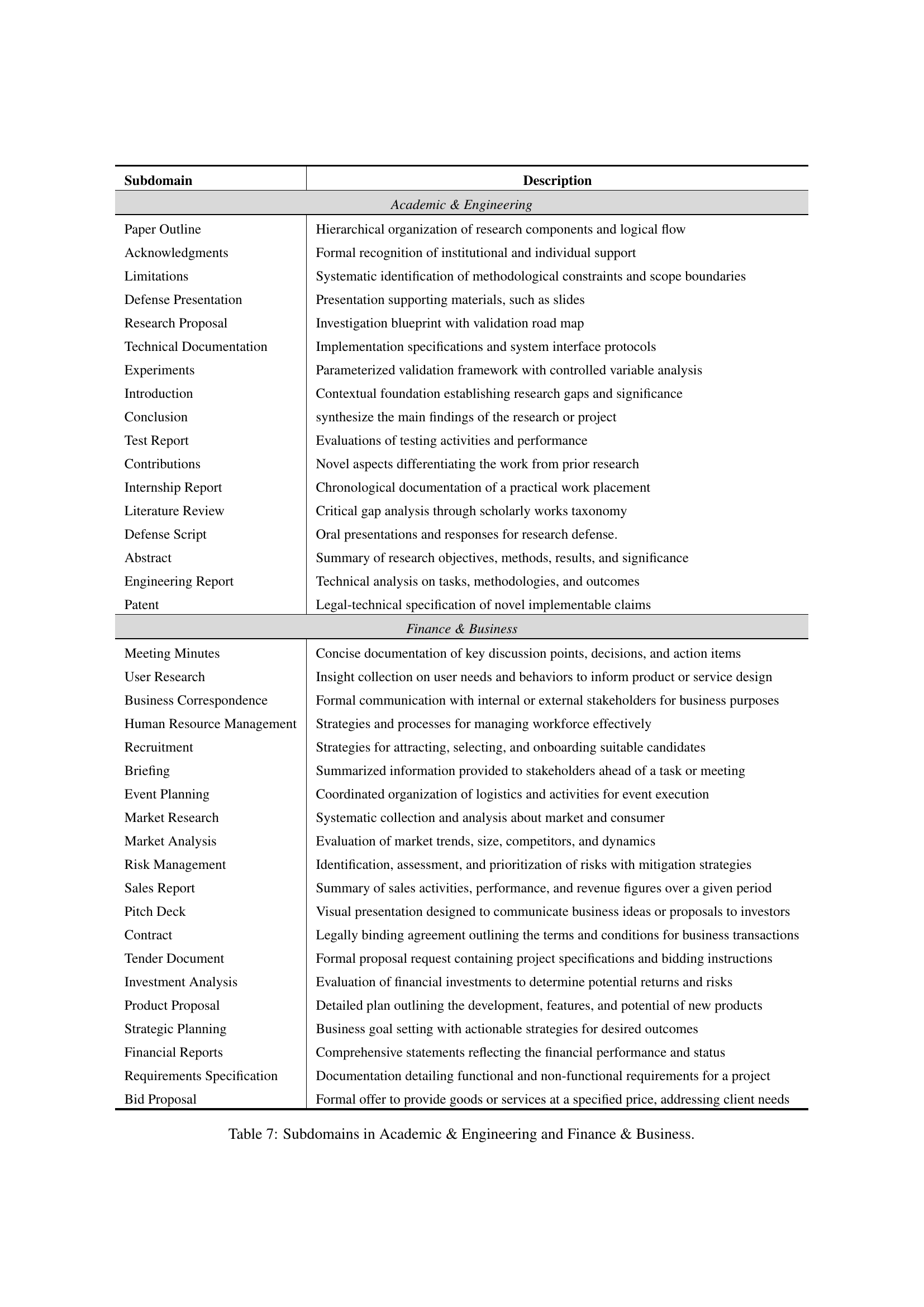
🔼 This table lists the 20 subdomains categorized under Academic & Engineering and Finance & Business domains in the WritingBench benchmark. For each subdomain, a brief description of the type of writing task it represents is provided. This helps clarify the range of writing tasks covered within these two broad domains.
read the caption
Table 7: Subdomains in Academic & Engineering and Finance & Business.
| Subdomain | Description |
| Academic & Engineering | |
| Paper Outline | Hierarchical organization of research components and logical flow |
| Acknowledgments | Formal recognition of institutional and individual support |
| Limitations | Systematic identification of methodological constraints and scope boundaries |
| Defense Presentation | Presentation supporting materials, such as slides |
| Research Proposal | Investigation blueprint with validation road map |
| Technical Documentation | Implementation specifications and system interface protocols |
| Experiments | Parameterized validation framework with controlled variable analysis |
| Introduction | Contextual foundation establishing research gaps and significance |
| Conclusion | synthesize the main findings of the research or project |
| Test Report | Evaluations of testing activities and performance |
| Contributions | Novel aspects differentiating the work from prior research |
| Internship Report | Chronological documentation of a practical work placement |
| Literature Review | Critical gap analysis through scholarly works taxonomy |
| Defense Script | Oral presentations and responses for research defense. |
| Abstract | Summary of research objectives, methods, results, and significance |
| Engineering Report | Technical analysis on tasks, methodologies, and outcomes |
| Patent | Legal-technical specification of novel implementable claims |
| Finance & Business | |
| Meeting Minutes | Concise documentation of key discussion points, decisions, and action items |
| User Research | Insight collection on user needs and behaviors to inform product or service design |
| Business Correspondence | Formal communication with internal or external stakeholders for business purposes |
| Human Resource Management | Strategies and processes for managing workforce effectively |
| Recruitment | Strategies for attracting, selecting, and onboarding suitable candidates |
| Briefing | Summarized information provided to stakeholders ahead of a task or meeting |
| Event Planning | Coordinated organization of logistics and activities for event execution |
| Market Research | Systematic collection and analysis about market and consumer |
| Market Analysis | Evaluation of market trends, size, competitors, and dynamics |
| Risk Management | Identification, assessment, and prioritization of risks with mitigation strategies |
| Sales Report | Summary of sales activities, performance, and revenue figures over a given period |
| Pitch Deck | Visual presentation designed to communicate business ideas or proposals to investors |
| Contract | Legally binding agreement outlining the terms and conditions for business transactions |
| Tender Document | Formal proposal request containing project specifications and bidding instructions |
| Investment Analysis | Evaluation of financial investments to determine potential returns and risks |
| Product Proposal | Detailed plan outlining the development, features, and potential of new products |
| Strategic Planning | Business goal setting with actionable strategies for desired outcomes |
| Financial Reports | Comprehensive statements reflecting the financial performance and status |
| Requirements Specification | Documentation detailing functional and non-functional requirements for a project |
| Bid Proposal | Formal offer to provide goods or services at a specified price, addressing client needs |
🔼 This table lists the 100 secondary subdomains included in the WritingBench benchmark, categorized under the primary domains of Politics & Law and Literature & Art. For each subdomain, a concise description is provided to clarify the type of writing task involved.
read the caption
Table 8: Subdomains in Politics & Law and Literature & Art.
| Domain | Description |
| Politics & Law | |
| Legal Opinion | Authoritative assessment and guidance on legal matters or questions |
| Government Speech | Formal address delivered by government officials outlining policies or positions |
| Judgment Document | Official written decision or order issued by a court |
| Legal Agreement | Binding contract setting out terms and obligations between parties |
| Case Study | In-depth analysis of a legal case for educational or professional purposes |
| Case Bulletin | Summary and update on ongoing or concluded legal cases |
| Legal Consultation | Professional advice provided on legal rights, responsibilities, or strategies |
| Regulatory Analysis | Examination of rules and regulations affecting compliance and enforcement |
| Meeting Summary | Brief overview of discussions, decisions, and outcomes from a meeting |
| Ideological Report | Analysis or commentary on political or ideological trends and perspectives |
| Policy Interpretation | Explanation or clarification for public or organizational guidance |
| Official Document | Formal written record issued by government entities or officials |
| Legal Awareness Campaign | Initiative to educate the public on legal rights and responsibilities |
| Defense Plea | Formal written argument submitted by the defense in a legal proceeding |
| Party Membership Application | Form and process for joining a political party |
| Policy Advocacy | Efforts to influence or promote specific policy changes or implementations |
| Work Report | Detailed account of activities, achievements, and challenges within a specific period |
| Deed Achievement | Record highlighting significant accomplishments and contributions |
| Litigation Documents | Legal filings and paperwork submitted in the course of a lawsuit |
| White Paper | Authoritative report providing information or proposals on an issue |
| Literature & Art | |
| Character Design | Creation and development of detailed characters for stories or visual media |
| Greeting Message | Friendly or formal introductory statement used for various occasions |
| Host Script | Guided narration and dialogue for a presenter during an event or show |
| Novel Outline | Structured plan for the plot, characters, and settings of a novel |
| Podcast Script | Written content outlining the dialogue and segments for podcast episodes |
| Derivative Work | Creative work based on or inspired by an existing piece |
| Reading Reflection | Personal thoughts and analysis on a piece of literature |
| Video Script | Script detailing dialogue and action for video content creation |
| Book Review | Critical evaluation and summary of a book’s content and impact |
| Game Design | Creation of game mechanics, stories, and interfaces for interactive entertainment |
| Lyric Writing | Crafting of words for songs with rhyme and meter considerations |
| Brainstorm | Rough ideas and notes generated during a creative thinking session |
| Plot Development | Process of mapping out the storyline and narrative structure |
| Prose | Written or spoken language in its ordinary form, without metrical structure |
| Screenplay | Scripted blueprint for film or television with dialogue and directions |
| Novel Manuscript | Complete text of a novel prepared for publication |
| Biography | Detailed account of a person’s life experiences and achievements |
| Film/TV Review | Analytical critique of a film or television show’s content and effectiveness |
| Poetry | Artistic composition using rhythmic and metaphorical language |
| Fan Fiction | Amateur stories written by enthusiasts featuring characters from existing media |
🔼 Table 9 lists the 100 secondary subdomains categorized under the primary domains of Education and Advertising & Marketing in the WritingBench benchmark. For each subdomain, a brief description is provided, explaining the type of writing task involved. This table provides a comprehensive overview of the diverse writing tasks included within the benchmark.
read the caption
Table 9: Subdomains in Education and Advertising & Marketing.
| Domain | Description |
| Education | |
| Training Reflection | Personal assessment of training experiences and learned insights |
| Class Activity | Planned exercises or tasks designed to engage students in learning |
| Parent-Teacher Meeting | Formal discussion between educators and parents about student progress |
| Lesson Plan | Structured outline of educational objectives and teaching methods for a class |
| Teaching Materials | Resources used to aid in presenting information to students |
| Assignment Grading | Evaluation and scoring of student work based on specific criteria |
| Curriculum Design | Development of educational content, structure, and delivery methods |
| Educational Report | Analysis or summary of educational outcomes and performance |
| Coursework | Academic work assigned to students as part of a course |
| Evaluation Comments | Feedback provided on student performance and areas of improvement |
| Educational Consulting | Professional guidance on educational strategies and systems |
| Admissions Promotion | Strategies and activities aimed at encouraging enrollment in educational institutions |
| Advertising & Marketing | |
| Sales Letter | Persuasive written communication intended to motivate potential buyers |
| Product Description | Detailed overview of a product’s features, benefits, and uses |
| Social Media Content | Engaging text, images, or videos crafted for online platforms |
| Multimedia Script | Planned screenplay integrating various forms of media for marketing |
| Promotional Copy | Compelling text written to boost interest and sales of products |
| Promotional Voiceover | Recorded narration to accompany marketing visuals or ads |
| Travel Guide | Informative content offering insights and tips for travelers |
| Brand Story | Narrative that outlines the history, values, and mission of a brand |
| Personal Blog | Individual commentary or stories shared in an informal online format |
| Marketing Commentary | Analytical thoughts on marketing trends and strategies |
| Slogans | Catchy and memorable phrases designed to convey brand identity |
🔼 This table presents a set of guidelines used to refine and enhance the initial writing queries generated by the model. These guidelines aim to increase the diversity and practical applicability of the queries by incorporating specific requirements for length, format, style, personalization, and content. The guidelines are designed to create writing tasks that better represent real-world scenarios.
read the caption
Table 10: Query refinement guidance pool introduced in Section B.5.
| Models | WritingBench-D4 | EQBench |
|---|---|---|
| Deepseek-R1 | 8.55 | 84.99 |
| Qwen-2.5-32B-Instruct | 7.34 | 48.17 |
| Qwen-2.5-32B-CoT | 8.66 | 82.48 |
| -w/o CoT | 8.49 | 79.43 |
🔼 This table describes the prompt used in the query refinement stage of the WritingBench construction. The prompt guides the refinement of initial writing queries generated by LLMs, incorporating specific requirements and considering factors like length, format, style, and content. The prompt is structured to ensure consistency and to guide the annotators to generate high-quality writing queries that align with real-world writing scenarios.
read the caption
Table 11: Query refinement prompt introduced in Section 3.1.1.
Full paper#