TL;DR#
Code embeddings are essential for semantic code search, but current approaches face scalability and efficiency challenges. Open-source models have limitations, while high-performing proprietary systems are computationally expensive. To address this, this paper introduces a parameter-efficient fine-tuning method based on Low-Rank Adaptation (LoRA) that constructs task-specific adapters.
Dubbed LoRACode, the approach reduces trainable parameters to less than 2% of the base model, enabling rapid fine-tuning on large code datasets. Experiments demonstrate significant improvements such as up to 9.1% in Mean Reciprocal Rank (MRR) for Code2Code search, and up to 86.69% for Text2Code search tasks. It also explores language-wise adaptation and highlights the sensitivity of code retrieval to syntactic and linguistic variations.
Key Takeaways#
Why does it matter?#
This paper introduces LoRACode, a parameter-efficient method using LoRA adapters for code embeddings. It achieves state-of-the-art performance with significantly reduced computational costs. This opens new avenues for multilingual code search and adaptation and sets a baseline for future research in PEFT for code.
Visual Insights#

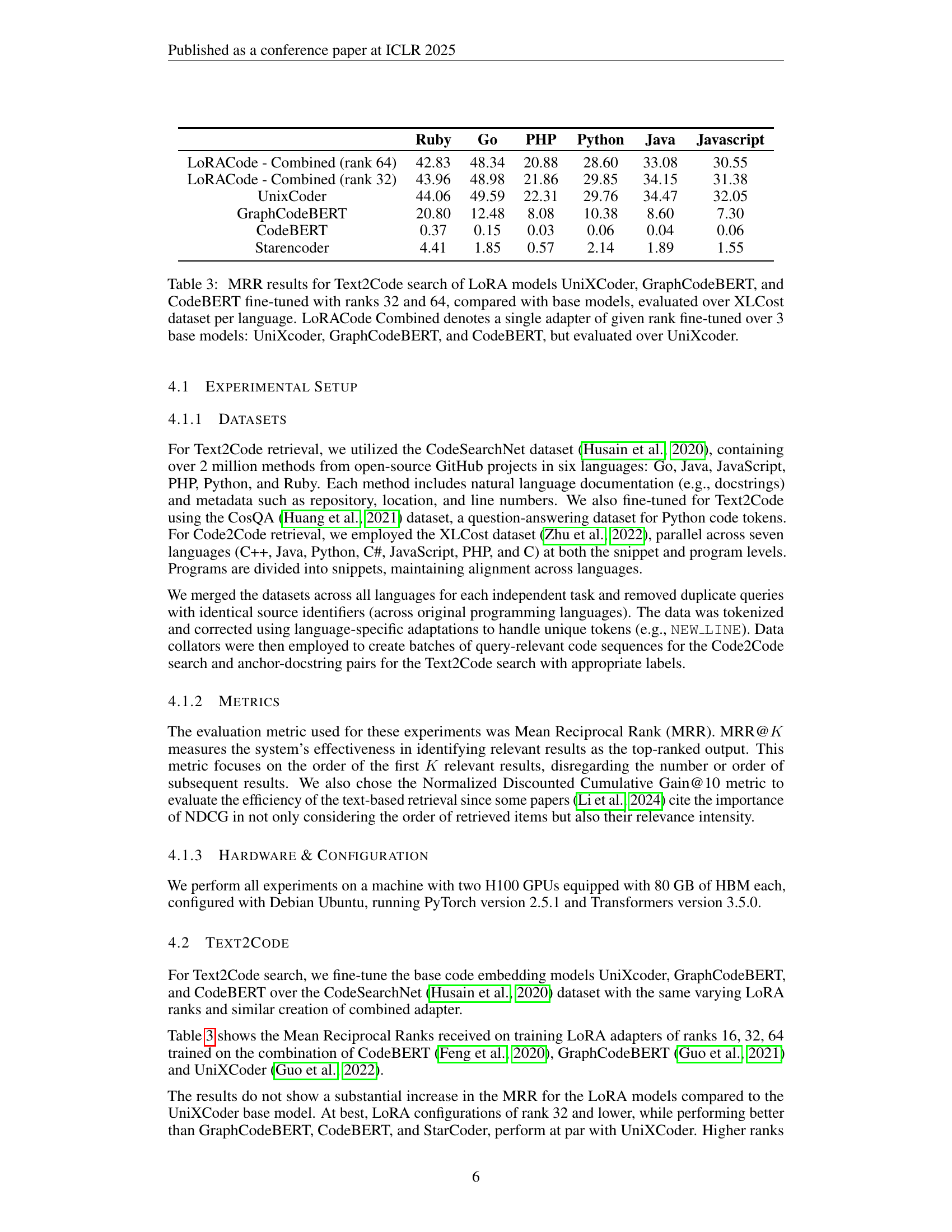
🔼 The LoRACode architecture uses either code-code or text-code pairs as input. These inputs are fed into a base model (CodeBERT, GraphCodeBERT, or UniXcoder). LoRA (Low-Rank Adaptation) layers are added to the base model to enhance it. These layers produce pooled embeddings which are then optimized by a Contrastive Trainer to boost retrieval accuracy. The final evaluation metric used is Mean Reciprocal Rank (MRR), which assesses the quality of the ranked retrieval results.
read the caption
Figure 1: LoRACode Architecture: The input consists of code-code or text-code pairs. The base models are enhanced with LoRA layers, that output pooled embeddings, optimized using the Contrastive Trainer to improve retrieval accuracy. Finally, Mean Reciprocal Rank (MRR) measures the quality of ranked retrieval results.
| Hyperparameter | Value |
|---|---|
| Batch Size | 16 per device |
| Epochs | 1 (rapid evaluation) |
| Learning Rate Scheduler | 1000 warmup steps |
| Logging | Every 200 steps |
| Save Strategy | End of each epoch |
| Evaluation Strategy | No intermediate eval |
🔼 This table presents the Mean Reciprocal Rank (MRR) scores for Text-to-Code search using various models. It compares the performance of three base models (UniXcoder, GraphCodeBERT, and CodeBERT) with their LoRA-adapted versions (using ranks 32 and 64). The results are broken down by programming language (Ruby, Go, PHP, Python, Java, Javascript) and show the improvement achieved by using LoRA adapters. A ‘LoRACode Combined’ model, which combines the adapters from all three base models and is evaluated on UniXcoder, is also included for comparison. This helps assess the effectiveness of the LoRA fine-tuning technique and its impact on cross-lingual code retrieval.
read the caption
Table 3: MRR results for Text2Code search of LoRA models UniXCoder, GraphCodeBERT, and CodeBERT fine-tuned with ranks 32 and 64, compared with base models, evaluated over XLCost dataset per language. LoRACode Combined denotes a single adapter of given rank fine-tuned over 3 base models: UniXcoder, GraphCodeBERT, and CodeBERT, but evaluated over UniXcoder.
In-depth insights#
LoRA for Search#
LoRA (Low-Rank Adaptation) offers a promising avenue for enhancing search systems by enabling parameter-efficient fine-tuning of large pre-trained models. It’s particularly attractive where computational resources are limited or task-specific adaptation is needed. The core idea involves freezing the pre-trained model’s weights and introducing a small set of trainable low-rank matrices to adapt the model to the search task. This approach could be used to optimize code search systems where capturing the nuances of syntax is important. LoRA can be used to customize the embedding space of code snippets or documents, improving the accuracy of retrieval. The adaptability of LoRA also makes it useful for scenarios that need a language model specifically built for the code search task, such as documentation searches.
Efficient Tuning#
Efficient tuning is crucial for code embeddings, balancing performance and computational cost. The paper likely explores parameter-efficient techniques like LoRA, minimizing trainable parameters while maximizing retrieval accuracy. Task-specific adapters tailored to Code2Code or Text2Code search are vital, along with language-specific adaptations to capture syntax nuances. Contrastive learning and optimized pooling strategies enhance embeddings. Success depends on dataset size, data quality, and model architecture.
Task & Lang Adap#
Task adaptation focuses on optimizing models for specific code-related tasks such as code-to-code search or text-to-code retrieval. Different tasks require different architectural considerations or loss functions during training. Language adaptation, on the other hand, fine-tunes a model to better understand a specific programming language’s syntax and semantics. Models for individual languages will have superior performance than a generalized, language-agnostic model. Combining task and language adaptation allows for a nuanced approach, where a model is optimized for both the type of task and the characteristics of the language being used.
Code2Code gains#
Code2Code gain analysis reveals LoRA adapters consistently outperform models like GraphCodeBERT and CodeBERT, proving their efficacy in low-rank adaptation for code retrieval. MRR increases significantly across languages: 9.1% in C, 7.47% in C++, 6.54% in Java, 5.82% in C#, 4.43% in JavaScript, 3.40% in Python, and 3.8% in PHP. Using rank 32 substantially boosts MRR over UniXcoder. LoRA’s low-rank decomposition improves retrieval accuracy for multilingual code search using 1.83%-1.85% trainable parameters with faster fine tuning.
Dataset Impact#
Dataset quality and size are crucial for code retrieval. Smaller, high-quality datasets yield better results than larger, noisy ones. Language-specific datasets improve performance by capturing nuances. Multilingual datasets can dilute results due to syntactic diversity. It will be interesting to see how this holds when the model is scaled up further.
More visual insights#
More on tables
| Hyperparameter | Value |
|---|---|
| Ranks | 16, 32, 64 |
| LoRA Alpha | 32, 64, 128 |
| Target Modules | Query and Value |
| Dropout | 10% |
🔼 This table presents a comparison of the performance of the UniXCoder base model and the LoRACode model (with a combined adapter of rank 64) on the CosQA dataset. The LoRACode model uses a parameter-efficient fine-tuning technique called Low-Rank Adaptation (LoRA) and incorporates adapters trained on the UniXcoder, GraphCodeBERT, and CodeBERT base models. The table shows the improvement in Mean Reciprocal Rank (MRR) and Normalized Discounted Cumulative Gain (NDCG@10) achieved by LoRACode compared to the UniXCoder base model, indicating the effectiveness of the LoRA approach. The key metric is the percentage increase for both MRR and NDCG@10.
read the caption
Table 4: Increase in Mean Reciprocal Rank and Normalized Discounted Cumulative Gain @ k=10 for LoRACode combined adapter (rank 64) trained on CosQA dataset (Huang et al., 2021), compared to the UniXCoder base model. LoRACode Combined denotes a single adapter fine-tuned over the 3 base models (UniXcoder, GraphCodeBERT, and CodeBERT), but evaluated on UniXcoder.
| Ruby | Go | PHP | Python | Java | Javascript | |
|---|---|---|---|---|---|---|
| LoRACode - Combined (rank 64) | 42.83 | 48.34 | 20.88 | 28.60 | 33.08 | 30.55 |
| LoRACode - Combined (rank 32) | 43.96 | 48.98 | 21.86 | 29.85 | 34.15 | 31.38 |
| UnixCoder | 44.06 | 49.59 | 22.31 | 29.76 | 34.47 | 32.05 |
| GraphCodeBERT | 20.80 | 12.48 | 8.08 | 10.38 | 8.60 | 7.30 |
| CodeBERT | 0.37 | 0.15 | 0.03 | 0.06 | 0.04 | 0.06 |
| Starencoder | 4.41 | 1.85 | 0.57 | 2.14 | 1.89 | 1.55 |
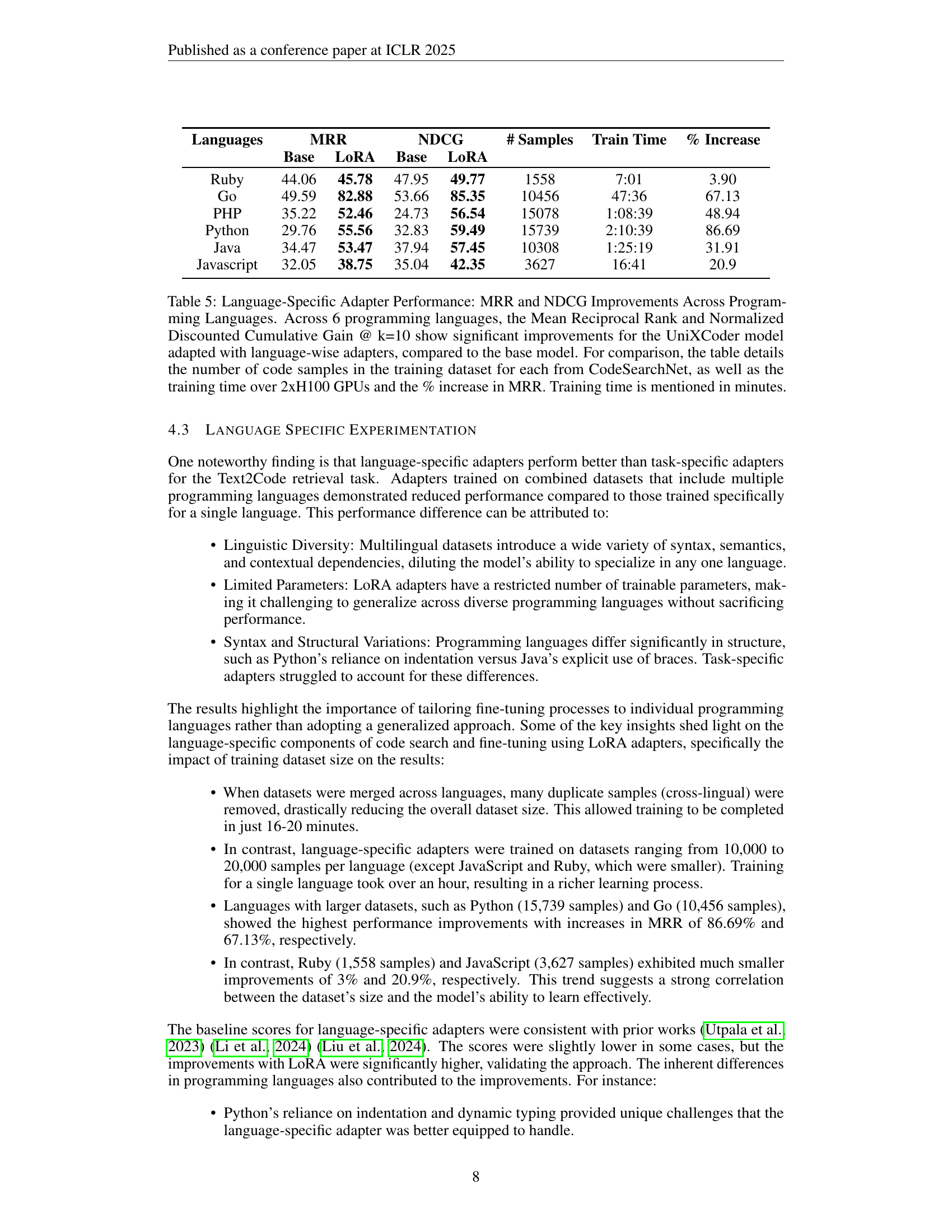
🔼 This table presents the performance of the LoRACode model with language-specific adapters on six programming languages (Ruby, Go, PHP, Python, Java, Javascript). It shows the improvements in Mean Reciprocal Rank (MRR) and Normalized Discounted Cumulative Gain (NDCG@10) achieved by using language-specific adapters compared to the baseline UniXCoder model. The table also provides details on the number of code samples used for training in each language, the training time on 2xH100 GPUs, and the percentage increase in MRR.
read the caption
Table 5: Language-Specific Adapter Performance: MRR and NDCG Improvements Across Programming Languages. Across 6 programming languages, the Mean Reciprocal Rank and Normalized Discounted Cumulative Gain @ k=10 show significant improvements for the UniXCoder model adapted with language-wise adapters, compared to the base model. For comparison, the table details the number of code samples in the training dataset for each from CodeSearchNet, as well as the training time over 2xH100 GPUs and the % increase in MRR. Training time is mentioned in minutes.
| UniXCoder | LoRACode - Combined (=64) | |
|---|---|---|
| MRR | 31.36 | 36.02 |
| NDCG@10 | 35.64 | 40.44 |
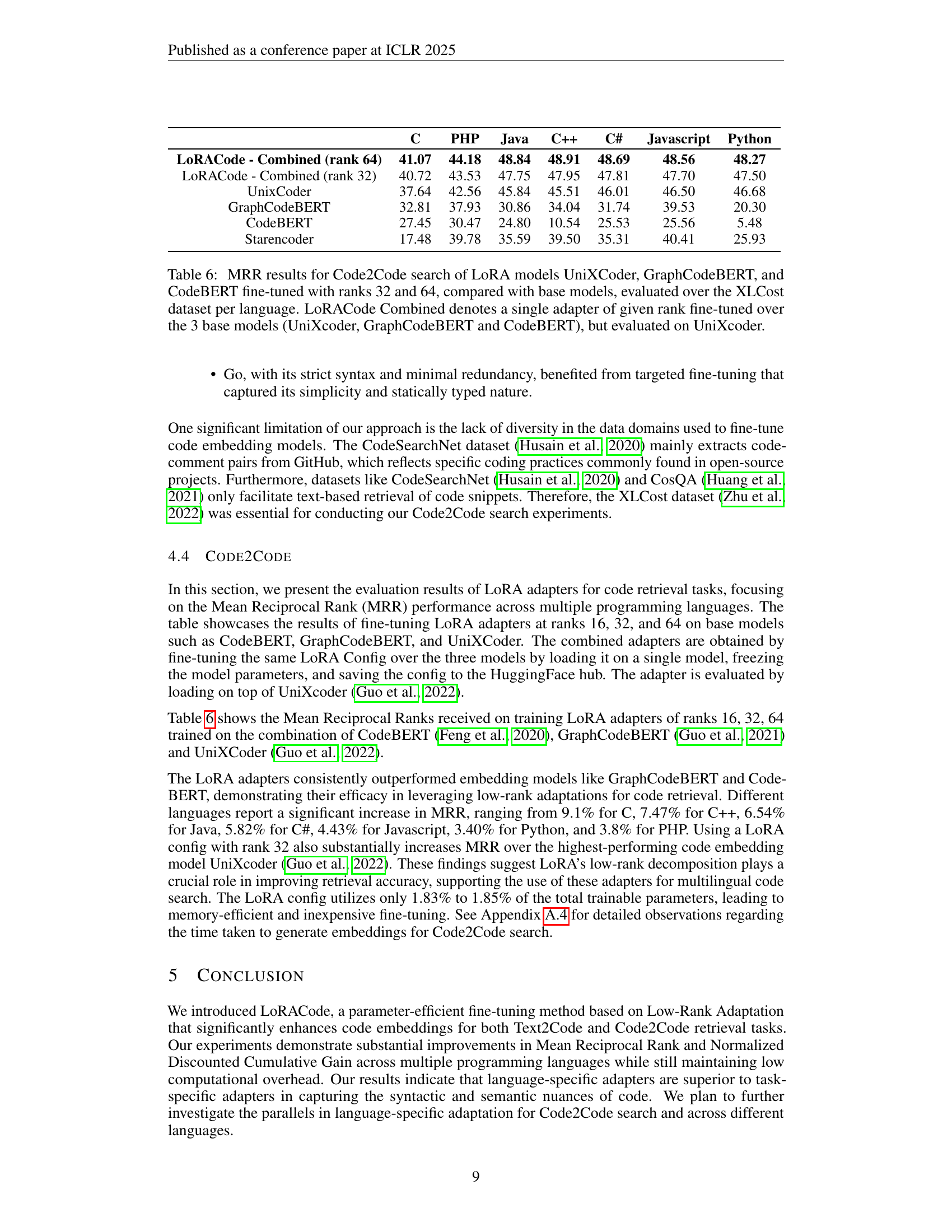
🔼 This table presents the Mean Reciprocal Rank (MRR) scores for Code-to-Code (Code2Code) search using different models. It compares the performance of three base models (UniXcoder, GraphCodeBERT, and CodeBERT) with LoRA-adapted versions of these models using two different rank settings (32 and 64). The ‘LoRACode Combined’ results represent a single adapter trained across all three base models and evaluated using UniXcoder as a baseline. The evaluation is performed per programming language using the XLCost dataset.
read the caption
Table 6: MRR results for Code2Code search of LoRA models UniXCoder, GraphCodeBERT, and CodeBERT fine-tuned with ranks 32 and 64, compared with base models, evaluated over the XLCost dataset per language. LoRACode Combined denotes a single adapter of given rank fine-tuned over the 3 base models (UniXcoder, GraphCodeBERT and CodeBERT), but evaluated on UniXcoder.
| Languages | MRR | NDCG | # Samples | Train Time | % Increase | ||
|---|---|---|---|---|---|---|---|
| Base | LoRA | Base | LoRA | ||||
| Ruby | 44.06 | 45.78 | 47.95 | 49.77 | 1558 | 7:01 | 3.90 |
| Go | 49.59 | 82.88 | 53.66 | 85.35 | 10456 | 47:36 | 67.13 |
| PHP | 35.22 | 52.46 | 24.73 | 56.54 | 15078 | 1:08:39 | 48.94 |
| Python | 29.76 | 55.56 | 32.83 | 59.49 | 15739 | 2:10:39 | 86.69 |
| Java | 34.47 | 53.47 | 37.94 | 57.45 | 10308 | 1:25:19 | 31.91 |
| Javascript | 32.05 | 38.75 | 35.04 | 42.35 | 3627 | 16:41 | 20.9 |
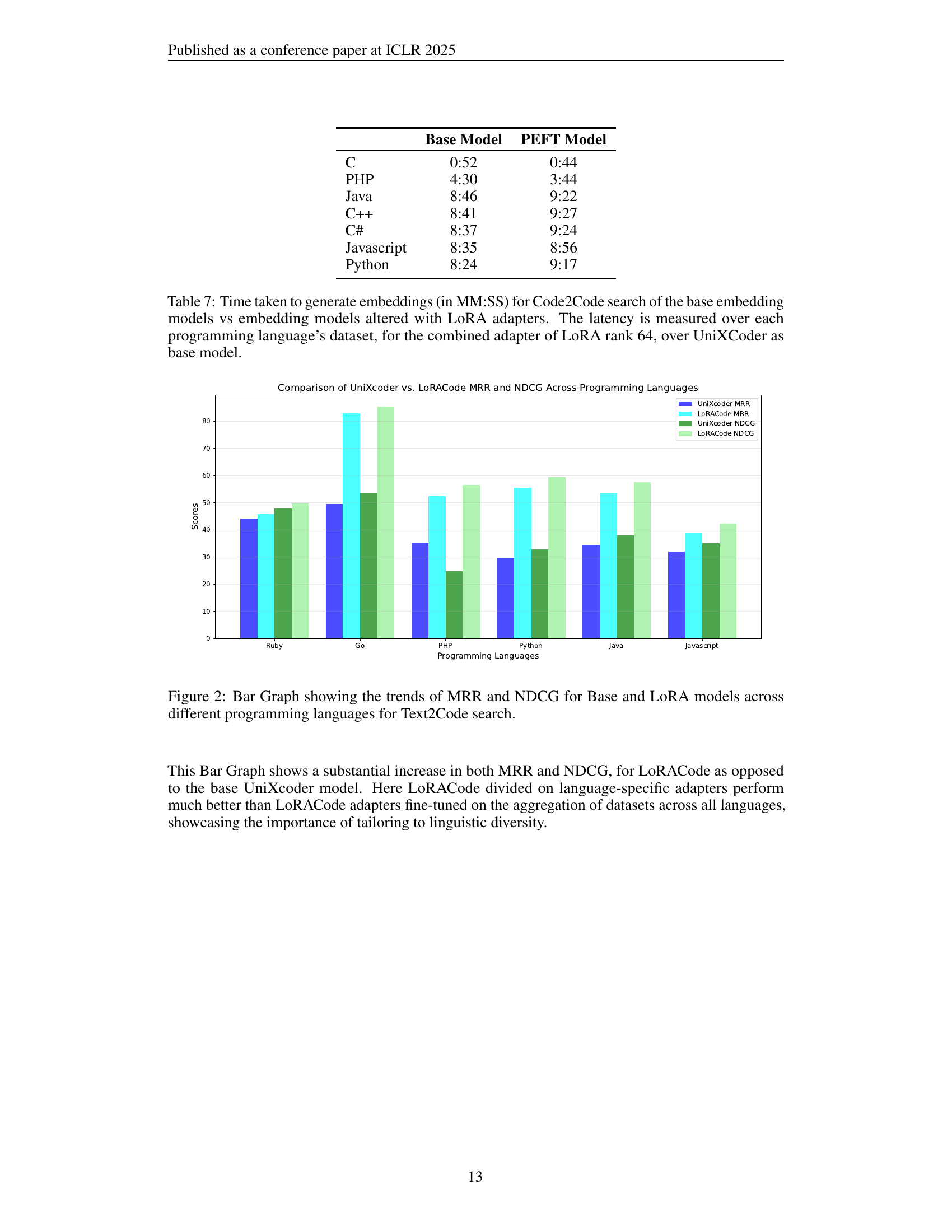
🔼 This table presents a comparison of the time taken to generate code embeddings using the base embedding models (UniXcoder, CodeBERT, GraphCodeBERT) versus those enhanced with LoRA adapters. The measurements are reported in minutes and seconds (MM:SS), and are broken down by programming language (Ruby, Go, PHP, Java, C++, Javascript, Python). For the LoRA-adapted models, the results reflect the use of a combined adapter with a rank of 64, using UniXcoder as the base model. This comparison highlights the impact of the LoRA adapters on the efficiency of the embedding generation process for different languages.
read the caption
Table 7: Time taken to generate embeddings (in MM:SS) for Code2Code search of the base embedding models vs embedding models altered with LoRA adapters. The latency is measured over each programming language’s dataset, for the combined adapter of LoRA rank 64, over UniXCoder as base model.
Full paper#