TL;DR#
Emotion recognition is crucial, needing visual & audio understanding. Models lacked reasoning, generalization & accuracy with complex data. This paper tackles these issues by pioneering Reinforcement Learning with Verifiable Reward (RLVR) for video-based multimodal models. By applying RLVR, this work optimizes the model in crucial areas like reasoning, accuracy and generalization.
The authors introduce R1-Omni, applying RLVR to HumanOmni, enhancing performance in emotion recognition with superior reasoning, understanding and generalization. The study shows R1-Omni’s enhanced reasoning through interpretable explanations. It also addresses limitations like hallucination, subtitle & audio cue processing, guiding further research in multimodal AI.
Key Takeaways#
Why does it matter?#
This paper is important for researchers in multimodal learning & emotion recognition. It pioneers RLVR for video+audio, enhancing model reasoning, accuracy, & generalization. It highlights challenges like subtitle recognition & audio cue integration, guiding future research for more robust, human-like AI systems.
Visual Insights#

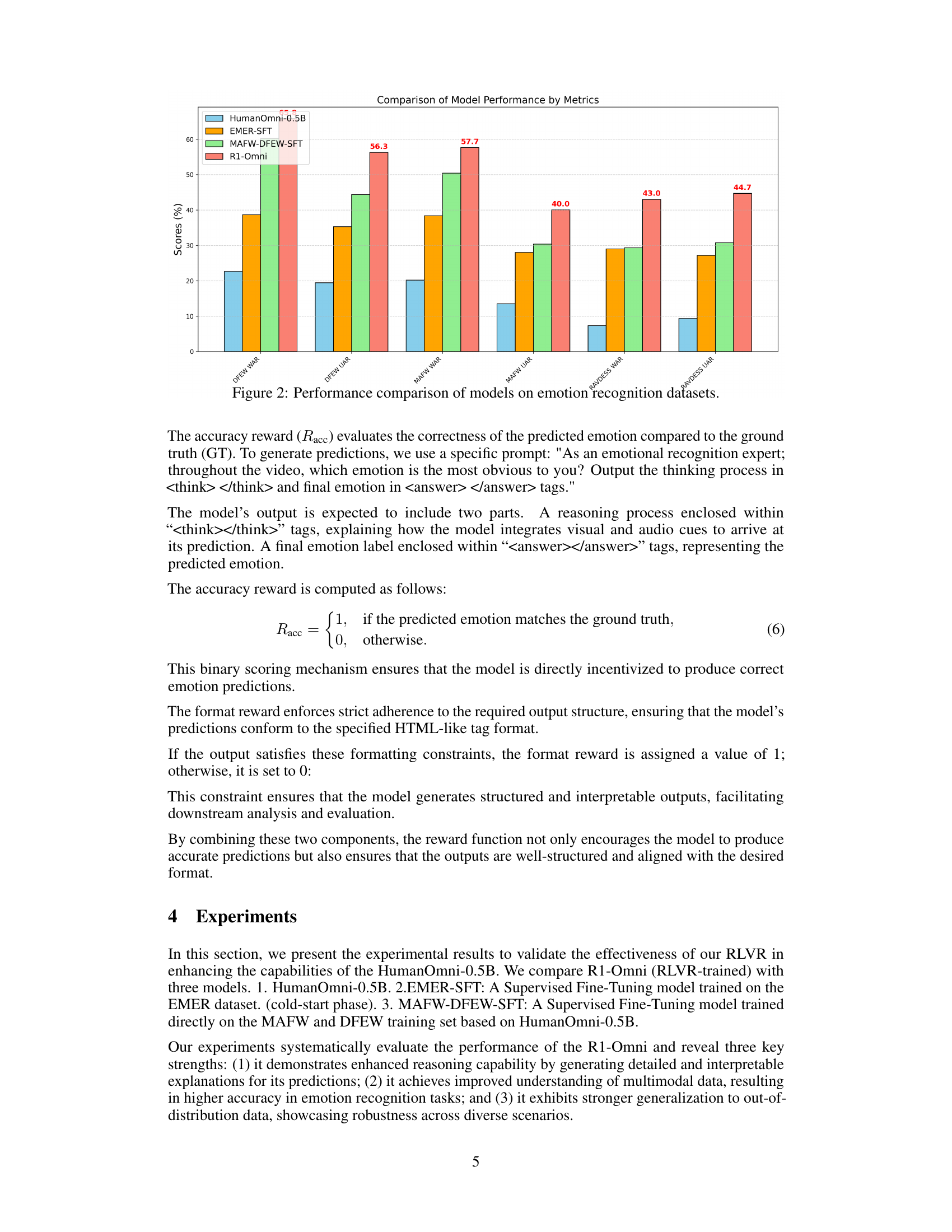
🔼 This figure compares the outputs of four different models (HumanOmni-0.5B, EMER-SFT, MAFW-DFEW-SFT, and R1-Omni) on two example video clips from the EMER dataset. Each model’s output includes a textual explanation of its reasoning process, followed by its predicted emotion. The ground truth emotion is also provided for comparison, enabling a visual assessment of the models’ reasoning capabilities, emotion recognition accuracy, and overall performance. The goal is to showcase how the R1-Omni model, using the RLVR framework, provides more coherent and accurate reasoning compared to the other models.
read the caption
Figure 1: Visualization comparison.
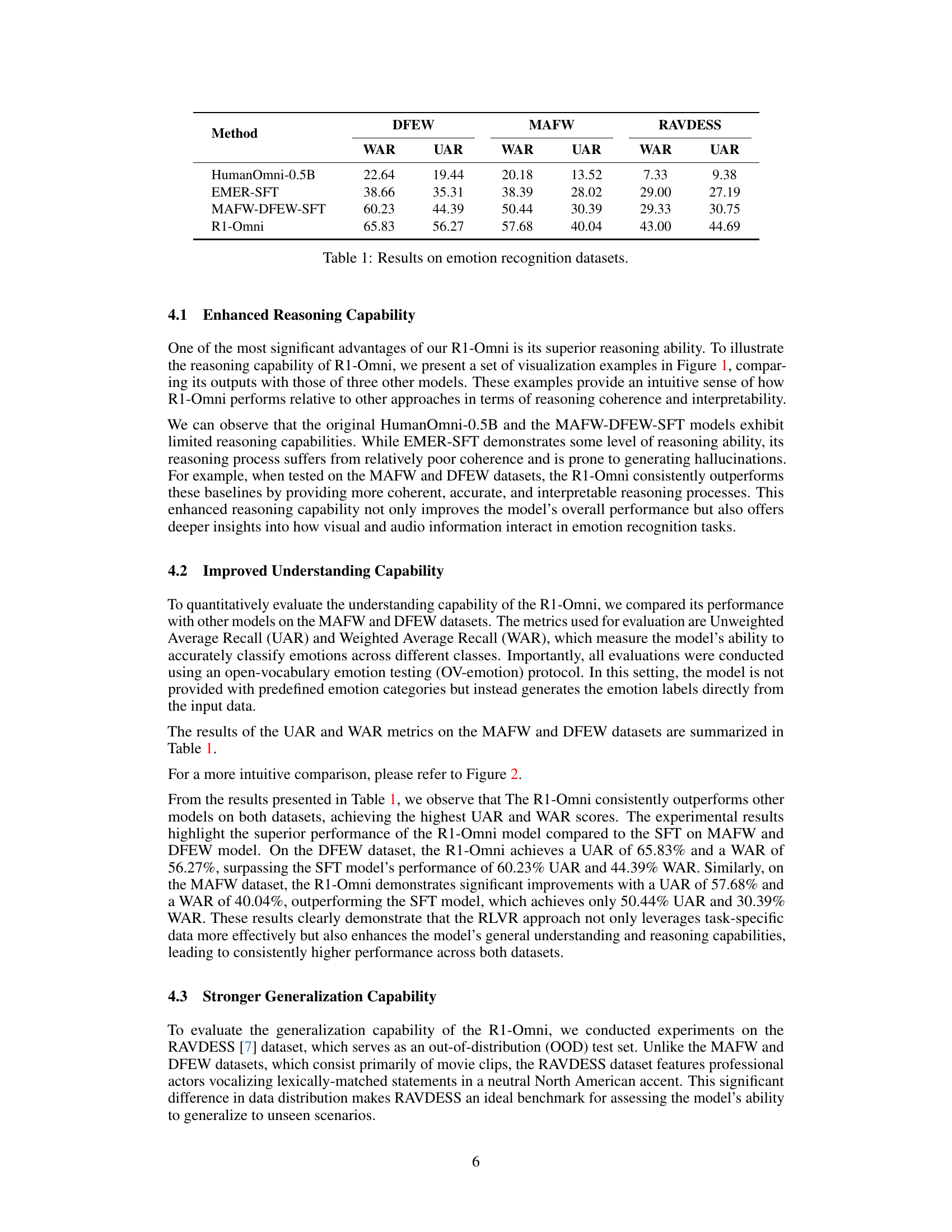
| Method | DFEW | MAFW | RAVDESS | |||
| WAR | UAR | WAR | UAR | WAR | UAR | |
| HumanOmni-0.5B | 22.64 | 19.44 | 20.18 | 13.52 | 7.33 | 9.38 |
| EMER-SFT | 38.66 | 35.31 | 38.39 | 28.02 | 29.00 | 27.19 |
| MAFW-DFEW-SFT | 60.23 | 44.39 | 50.44 | 30.39 | 29.33 | 30.75 |
| R1-Omni | 65.83 | 56.27 | 57.68 | 40.04 | 43.00 | 44.69 |
🔼 This table presents the performance of four different models on three emotion recognition datasets: DFEW, MAFW, and RAVDESS. For each dataset and model, it shows the Weighted Average Recall (WAR) and Unweighted Average Recall (UAR) scores, which are common metrics for evaluating the accuracy of emotion classification models. The models compared are: the HumanOmni-0.5B base model, a model fine-tuned on the EMER dataset (EMER-SFT), a model fine-tuned on the MAFW and DFEW datasets (MAFW-DFEW-SFT), and the R1-Omni model, which uses Reinforcement Learning with Verifiable Rewards (RLVR). The table allows for a comparison of the effectiveness of different training methods on various datasets, highlighting the impact of RLVR on improving the overall performance of the emotion recognition model.
read the caption
Table 1: Results on emotion recognition datasets.
In-depth insights#
RLVR for Emotion#
Applying Reinforcement Learning with Verifiable Rewards (RLVR) to emotion recognition presents a novel approach to enhance multimodal models. By leveraging RLVR, the system can optimize its performance in understanding and classifying emotions based on both visual and auditory cues. This method allows for a more nuanced analysis of emotional expressions, potentially leading to improvements in accuracy and generalization. The verifiable reward aspect ensures that the model’s decisions are grounded in objective criteria, reducing the risk of subjective biases. RLVR’s capability to provide insights into how different modalities contribute to emotion recognition can further refine the model’s architecture and training process. Moreover, this approach enables robust performance on out-of-distribution datasets, proving its effectiveness across diverse scenarios.
R1-Omni insights#
The R1-Omni model showcases enhanced reasoning, enabling a clearer understanding of how visual and audio information contribute to emotion recognition. It significantly boosts performance in emotion recognition tasks compared to SFT models. R1-Omni exhibits markedly better generalization capabilities, excelling in out-of-distribution scenarios, suggesting its potential for real-world application.
GRPO+RLVR details#
The paper combines Group Relative Policy Optimization (GRPO) with Reinforcement Learning with Verifiable Rewards (RLVR). This integration allows the model to achieve superior reasoning, generalization, and emotion recognition capabilities. GRPO eliminates the need for a critic model by directly comparing groups of generated responses, streamlining the training process. RLVR simplifies the reward mechanism, ensuring alignment with correctness standards. This combination leverages the strengths of both methods, reducing dependency on external critic models and enhancing the model’s ability to differentiate between high-quality and low-quality outputs effectively. This integration shows promise for enhancing the model’s performance, particularly in tasks requiring complex reasoning and generalization, such as emotion recognition.
Limits of R1-Omni#
R1-Omni, despite its advancements, faces limitations that need addressing. Inaccurate subtitle recognition can hinder performance as neither the base model nor training explicitly improves this. Hallucination in reasoning occurs when outputs aren’t grounded in the video’s content, leading to incorrect emotion predictions, stemming from weaker causal links in multimodal data compared to text. Also, the model has an underutilization of audio cues, such as tone, crucial for accurate recognition, thus the model is less efficient when using audio features compared to visual ones. It focuses primarily on directly observable features and needs deeper insights into motivations and internal states. Future research must tackle these issues to enhance R1-Omni’s performance and reliability by improving subtitle processing, detecting and mitigating hallucinations, enhancing audio cue utilization, and promoting deeper reasoning and emotional intelligence for real-world applications.
Future of RLVR#
The future of Reinforcement Learning with Verifiable Rewards (RLVR) in multimodal emotion recognition is promising. Enhancements to foundation models will drive the success of RLVR-based methods. Addressing hallucinations in reasoning outputs is crucial due to weaker causal relationships in multimodal data and lack of supervision for reasoning content. Detecting and mitigating these inaccuracies will improve reliability. Enhancing the utilization of audio cues, such as tone and intonation, represents a limitation to explore for more accurate emotion recognition. Current reasoning is mechanistic, focusing on directly observable features. Future research should focus on deeper psychological insights, such as understanding motivations, intentions, or internal states of individuals, improving the model’s emotional intelligence. The goal is to better simulate human-like empathy and reasoning in real-world scenarios, capturing complex emotional dynamics. This evolution of RLVR promises more nuanced and accurate emotion recognition capabilities.
More visual insights#
More on figures

🔼 This figure presents a bar chart comparing the performance of four different models on two emotion recognition datasets: DFEW and MAFW. The models compared are HumanOmni-0.5B (a baseline model), EMER-SFT (Supervised Fine-Tuning on the EMER dataset), MAFW-DFEW-SFT (Supervised Fine-Tuning on the MAFW and DFEW datasets), and R1-Omni (the proposed model using Reinforcement Learning with Verifiable Rewards). The chart displays the Weighted Average Recall (WAR) and Unweighted Average Recall (UAR) for each model on each dataset, providing a quantitative assessment of their accuracy in recognizing emotions.
read the caption
Figure 2: Performance comparison of models on emotion recognition datasets.

🔼 Figure 3 showcases three challenging examples where the R1-Omni model faces difficulties. These examples highlight limitations such as inaccurate subtitle recognition, hallucination in reasoning (generating outputs not grounded in the video content), and the underutilization of audio cues for emotion recognition. The examples show model outputs and ground truth, illustrating where the model’s predictions are incorrect and the reasons for such failures.
read the caption
Figure 3: Challenging Cases.
Full paper#