TL;DR#
Current video techniques fall short in immersive experiences. Traditional methods produce unrealistic results, require multi-view videos which are inconvenient. Recent advancements leverage image and video diffusion models, but struggle with dynamic videos from static methods, and implicit pose embeddings. This paper introduces methods with fixed poses and synthetic multi-view datasets, but performance suffers from domain gaps between real & synthetic videos.
This paper introduces a new framework that generates high-fidelity videos with user-defined camera trajectories from monocular inputs. The proposed method, TrajectoryCrafter, disentangles deterministic view transformations from stochastic content generation, and leverages monocular reconstruction to model 3D transformations via point cloud renders. A dual-stream diffusion model combines point cloud renders and source videos for 4D consistency and broadens generalization. The method uses a hybrid training dataset of static multi-view and web-scale monocular videos.
Key Takeaways#
Why does it matter?#
This paper introduces a novel method for redirecting camera trajectories in monocular videos, offering precise control and broad generalization, potentially impacting virtual content creation and video editing. It opens new research avenues in 4D content generation and video manipulation, relevant to current trends in AI-driven video processing.
Visual Insights#

🔼 This figure showcases TrajectoryCrafter, a new method for altering the camera path in monocular videos. It demonstrates the system’s ability to precisely control the camera’s viewpoint and simultaneously generate consistent and coherent 4D content, ensuring smooth and realistic-looking video transitions and scene changes. The results shown are still images; to view the full video results, please refer to the project’s supplementary materials.
read the caption
Figure 1: We present TrajectoryCrafter, a novel approach to redirect camera trajectories for monocular videos, achieving precise control over the view transformations and coherent 4D content generation. Please refer to the supplementary project page for video results.
| PSNR | SSIM | LPIPS | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Apple | Block | Paper | Spin | Teddy | Mean | Apple | Block | Paper | Spin | Teddy | Mean | Apple | Block | Paper | Spin | Teddy | Mean |
| GCD | 9.823 | 12.30 | 9.75 | 10.37 | 11.61 | 10.77 | 0.215 | 0.458 | 0.398 | 0.324 | 0.385 | 0.356 | 0.738 | 0.590 | 0.535 | 0.576 | 0.629 | 0.614 |
| ViewCrafter | 10.19 | 10.28 | 10.63 | 11.15 | 11.50 | 10.75 | 0.245 | 0.427 | 0.344 | 0.308 | 0.372 | 0.339 | 0.750 | 0.615 | 0.521 | 0.533 | 0.606 | 0.605 |
| Shape-of-motion | 11.06 | 11.72 | 11.93 | 11.28 | 10.42 | 11.28 | 0.197 | 0.446 | 0.425 | 0.319 | 0.357 | 0.349 | 0.879 | 0.601 | 0.486 | 0.560 | 0.650 | 0.635 |
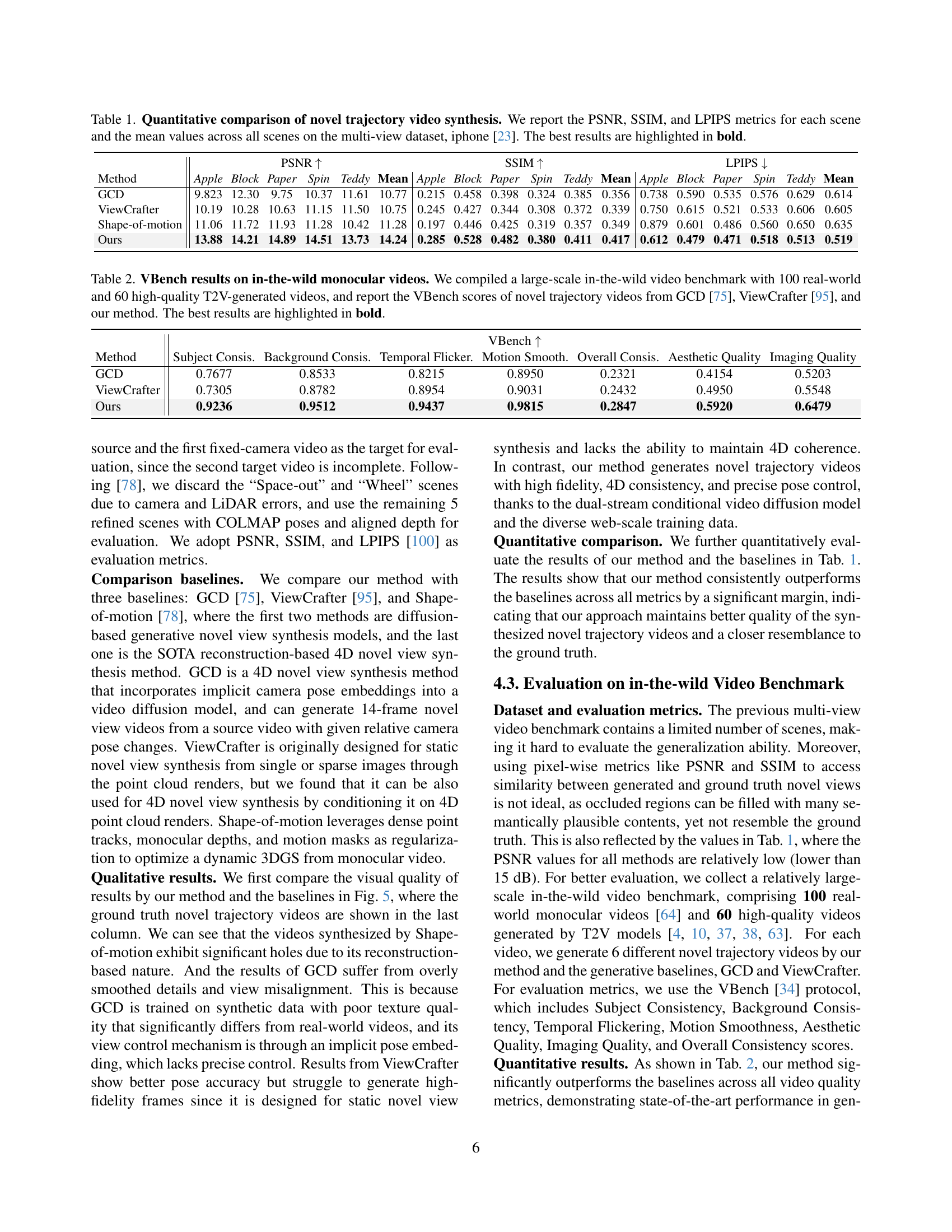
| Ours | 13.88 | 14.21 | 14.89 | 14.51 | 13.73 | 14.24 | 0.285 | 0.528 | 0.482 | 0.380 | 0.411 | 0.417 | 0.612 | 0.479 | 0.471 | 0.518 | 0.513 | 0.519 |
🔼 This table presents a quantitative comparison of different methods for novel trajectory video synthesis using the iPhone dataset [23]. The performance of four methods (GCD, ViewCrafter, Shape-of-Motion, and the proposed method, Ours) is evaluated based on three metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). Each metric is calculated for individual scenes within the dataset, and the average across all scenes is also reported. Higher PSNR and SSIM values, along with lower LPIPS values, indicate better visual quality. The best results for each metric and scene are highlighted in bold.
read the caption
Table 1: Quantitative comparison of novel trajectory video synthesis. We report the PSNR, SSIM, and LPIPS metrics for each scene and the mean values across all scenes on the multi-view dataset, iphone [23]. The best results are highlighted in bold.
In-depth insights#
Precise Trajectory#
Generating precise trajectories in videos is a challenging task, as it requires careful control over camera movements and 4D content. The paper addresses this by disentangling deterministic view transformations from stochastic content generation, enabling accurate 3D modeling using point cloud renders. They also propose a dual-stream diffusion model that leverages point cloud renders and source videos to ensure accurate view transformations and coherent 4D content generation. The hybrid training dataset, combining web-scale monocular videos and static multi-view datasets, further enhances generalization across diverse scenes, ultimately leading to high-fidelity video generation with user-defined trajectories.
Dual-Stream Fusion#
While the term “Dual-Stream Fusion” isn’t explicitly mentioned as a heading in the provided paper, the core concept is heavily utilized within the TrajectoryCrafter framework. The essence of such an approach lies in processing information through two distinct pathways and subsequently integrating them to achieve a more comprehensive understanding or, in this case, a superior output. In the TrajectoryCrafter context, this manifests as a dual-stream conditional video diffusion model. One stream processes point cloud renders, enabling precise view transformations and geometric control based on user-specified camera trajectories. The other stream incorporates the source video, preserving rich appearance details and compensating for potential artifacts or inconsistencies arising from the point cloud reconstruction. The strength of the dual-stream approach lies in its ability to decouple deterministic view transformation from stochastic content generation, allowing for more robust and high-fidelity video synthesis. The fusion of these streams counters occlusions and geometric distortions. This fusion strategy effectively combines the strengths of both geometric precision and visual detail, leading to the generation of novel view videos with enhanced accuracy, consistency, and realism, showing state-of-the-art performance.
Hybrid Data Curation#
Hybrid data curation is a practical approach to gather data for training complex models. As multi-view data can be limited, a hybrid strategy is important to expand the datasets and foster high-quality video generation. Gathering data from monocular videos using strategies like double re-projection and web-scale datasets with static multi-view resources enhances the generalization. Hybrid approach can improve the generalization across diverse scenes because models benefit from large and varied dataset. By consolidating different data, we enhance model’s robustness for the complex task of generating high-fidelity videos.
4D Consistency#
The notion of ‘4D Consistency’ is crucial in the context of video generation and novel view synthesis. It refers to the temporal coherence and spatial accuracy of generated content across time, ensuring that the generated video maintains a realistic and stable representation of the scene. Achieving 4D consistency involves several challenges, including preventing flickering artifacts, maintaining consistent object identities and shapes, and ensuring that the generated content aligns with the underlying 3D geometry of the scene. Methods that explicitly model 3D structure or use temporal information effectively are better positioned to achieve high 4D consistency. The lack of 4D consistency can lead to visually jarring and unrealistic videos, undermining the overall quality and believability of the generated content. Therefore, innovations in video generation and novel view synthesis often prioritize enhancing 4D consistency through various techniques, such as incorporating geometric priors, using recurrent networks, or employing adversarial training strategies, Ultimately, 4D consistency is paramount for creating immersive and visually compelling video experiences.
Depth Inaccuracy#
The research paper acknowledges that depth estimation from monocular videos is inherently prone to inaccuracies. This is a critical limitation, as the entire pipeline relies on the quality of the reconstructed 3D point cloud. Errors in depth propagate through the system, affecting view transformation and content consistency. The paper discusses that while methods like DepthCrafter are employed to generate consistent depth sequences, these are not always perfect. Failures in depth estimation can lead to physically implausible behaviors in the generated novel views, and therefore future research is needed in improving depth estimation.
More visual insights#
More on figures

🔼 TrajectoryCrafter processes a source video (either recorded or AI-generated) by first converting it into a dynamic point cloud using depth estimation. This point cloud allows users to interactively define new camera trajectories. The system then uses a dual-stream conditional video diffusion model that combines the point cloud renderings with the original video to create a high-fidelity output video. This output video precisely matches the specified camera path while maintaining temporal consistency (4D consistency) with the source video.
read the caption
Figure 2: Overview of TrajectoryCrafter. Starting with a source video, whether casually captured or AI-generated, we first lift it into a dynamic point cloud via depth estimation. Users can then interactively render the point cloud with desired camera trajectories. Finally, the point cloud renders and the source video are jointly processed by our dual-stream conditional video diffusion model, yielding a high-fidelity video that precisely aligns with the specified trajectory and remains 4D consistent with the source video.

🔼 The Ref-DiT (Reference-conditioned Diffusion Transformer) block refines view tokens by incorporating information from reference tokens. The process begins with 3D attention applied to both text and view tokens, capturing contextual relationships within the video data and text descriptions. Then, a cross-attention mechanism injects detailed information from the reference tokens (encoding the source video) into the view tokens. Because the source video and rendered views aren’t perfectly aligned spatially, the cross-attention selectively integrates relevant details, improving the accuracy and coherence of the view tokens for subsequent processing steps in the video generation model. This refined information ensures that the generated novel view is both geometrically accurate and visually consistent with the source video.
read the caption
Figure 3: Ref-DiT Block. The text and view tokens are first processed through 3D attention, followed by a cross-attention that injects the detailed, yet mis-aligned, reference information into the view tokens, yielding refined view tokens for subsequent layers.

🔼 The figure illustrates the double-reprojection technique used to create training data. A target video is first converted into a dynamic point cloud representation. A novel view (I’) is then rendered from this point cloud using a random view transformation. This novel view is then reprojected back to the original camera’s perspective, resulting in a new image (I’’) that includes occlusions and aligns with the target video. This I’’ image serves as a simulated point cloud render, mimicking the effects of occlusions and view transformations that occur in real-world scenarios.
read the caption
Figure 4: Double-reprojection. Given a target video, we lift it into a dynamic point cloud to render a novel view 𝑰′superscript𝑰′\bm{I}^{\prime}bold_italic_I start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT via a random view transformation. Then 𝑰′superscript𝑰′\bm{I}^{\prime}bold_italic_I start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT is reprojected to the original camera pose, yielding 𝑰′′superscript𝑰′′\bm{I}^{\prime\prime}bold_italic_I start_POSTSUPERSCRIPT ′ ′ end_POSTSUPERSCRIPT through the inverse view transformation. 𝑰′′superscript𝑰′′\bm{I}^{\prime\prime}bold_italic_I start_POSTSUPERSCRIPT ′ ′ end_POSTSUPERSCRIPT contains occlusions and aligns with the target video, simulating the point cloud renders.

🔼 Figure 5 presents a qualitative comparison of novel trajectory video synthesis methods. It showcases the results of four different approaches applied to the same video sequence from the iPhone [23] multi-view dataset. These methods include our proposed TrajectoryCrafter, the reconstruction-based method Shape-of-motion [78], and the generative methods GCD [75] and ViewCrafter [95]. The figure allows for visual comparison of the generated videos’ quality, accuracy in portraying camera movements, and overall visual fidelity to the source video, highlighting the strengths and weaknesses of each approach.
read the caption
Figure 5: Qualitative comparison of novel trajectory video synthesis. We compare our method with both reconstruction-based method, Shape-of-motion [78], and generative methods, GCD [75] and ViewCrafter [95] on the multi-view dataset, iphone [23].

🔼 Figure 6 presents a qualitative comparison of novel trajectory video synthesis results on real-world monocular videos. The experiment focuses on the specific camera trajectory of ‘zooming in and orbiting to the right’. The figure displays the input video and the output videos generated by three different methods: the authors’ proposed TrajectoryCrafter, GCD [75], and ViewCrafter [95]. This allows for a visual comparison of the quality and accuracy of the trajectory redirection achieved by each method, highlighting strengths and weaknesses in generating realistic and coherent videos with novel camera paths.
read the caption
Figure 6: Qualitative comparison on in-the-wild monocular videos. We show results of redirecting the camera trajectory as “zoom-in and orbit to the right” from the input videos, produced by our method and the generative baselines, GCD [75] and ViewCrafter [95].

🔼 Figure 7 demonstrates the impact of the Ref-DiT (Reference-conditioned Diffusion Transformer) block on video generation quality within the TrajectoryCrafter model. Three versions of the model are compared: the complete model with Ref-DiT blocks, a model without Ref-DiT blocks, and a model where the source video is directly concatenated with point cloud renders instead of using Ref-DiT. A yellow box highlights key visual differences between the outputs, showing how the Ref-DiT block improves the coherence and fidelity of the generated video by effectively integrating information from both the point cloud renders and the source video.
read the caption
Figure 7: Effectiveness of Ref-DiT blocks. We compare our full model (w/ Ref-DiT) to two alternatives: a baseline without Ref-DiT (w/o Ref-DiT), and a variant that directly concatenates the source video with the point cloud renders (w/ Concat Condition). The yellow box highlights the most prominent differences.

🔼 Figure 8 demonstrates the impact of different training data on the model’s performance. It compares the model trained on a combination of static multi-view and dynamic monocular videos (mixed data) against two alternatives: a model trained only on static multi-view data, and a model trained only on dynamic monocular data. The yellow boxes highlight key differences in the results, particularly demonstrating how using both static multi-view and dynamic monocular data improves the model’s ability to handle occlusions, geometric distortions, and maintain motion consistency in the generated videos.
read the caption
Figure 8: Ablation on the training data. We compare our model trained with mixed data to two alternatives: training without multi-view data and training without dynamic data. The yellow box highlights the most prominent differences of occulusions, geometric distortions, and motion consistency.
More on tables
| VBench | |||||||
|---|---|---|---|---|---|---|---|
| Method | Subject Consis. | Background Consis. | Temporal Flicker. | Motion Smooth. | Overall Consis. | Aesthetic Quality | Imaging Quality |
| GCD | 0.7677 | 0.8533 | 0.8215 | 0.8950 | 0.2321 | 0.4154 | 0.5203 |
| ViewCrafter | 0.7305 | 0.8782 | 0.8954 | 0.9031 | 0.2432 | 0.4950 | 0.5548 |
| Ours | 0.9236 | 0.9512 | 0.9437 | 0.9815 | 0.2847 | 0.5920 | 0.6479 |
🔼 This table presents a quantitative comparison of novel trajectory video synthesis methods on a large-scale, in-the-wild video benchmark dataset. The dataset consists of 100 real-world videos and 60 high-quality videos generated by text-to-video (T2V) models. The table reports VBench scores, which are a set of metrics evaluating video quality and consistency across several aspects, for novel trajectory videos generated by three different methods: GCD [75], ViewCrafter [95], and the proposed method (TrajectoryCrafter). The best results for each metric are highlighted in bold.
read the caption
Table 2: VBench results on in-the-wild monocular videos. We compiled a large-scale in-the-wild video benchmark with 100 real-world and 60 high-quality T2V-generated videos, and report the VBench scores of novel trajectory videos from GCD [75], ViewCrafter [95], and our method. The best results are highlighted in bold.
| Method | PSNR | SSIM | LPIPS |
|---|---|---|---|
| Ours w/o Ref-DiT | 11.63 | 0.341 | 0.612 |
| Ours w/ concat. condition | 11.05 | 0.352 | 0.627 |
| Ours w/o dynamic data | 10.93 | 0.348 | 0.621 |
| Ours w/o mv data | 12.35 | 0.361 | 0.588 |
| Ours full | 14.24 | 0.417 | 0.519 |
🔼 This ablation study investigates the impact of different components of the TrajectoryCrafter model on its performance. Specifically, it compares the full model against versions where key components have been removed. These components include the Reference-conditioned Diffusion Transformer (Ref-DiT) blocks, the dual-stream conditioning (concat. condition), the dynamic data, and the multi-view (mv) data. The comparison is done using three metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). The results are presented for each scene in the iPhone [23] dataset, with the best performance in each metric bolded. This table helps to understand the contribution of each component to the model’s overall performance and identify areas for potential improvement.
read the caption
Table 3: Ablation study. We report the PSNR, SSIM, and LPIPS metrics for the full model and its ablated versions on the multi-view dataset, iphone [23]. The best results are highlighted in bold.
Full paper#