TL;DR#
Household robots face challenges in dexterity, navigation, and environment interaction. Existing benchmarks highlight the need for enhanced bimanual coordination, precise navigation, and extensive reach. Everyday tasks involve articulated/deformable objects and confined spaces, requiring robots to effectively use their whole bodies. Current systems struggle with data collection, coordinated movements, and real-world complexity. Success requires careful hardware design and effective visuomotor policy learning.
This paper introduces the Behavior Robot Suite (BRS), a framework for whole-body manipulation in diverse household activities. BRS uses a wheeled, dual-arm robot with a 4-DoF torso, integrating JoyLo (a teleoperation interface) and WB-VIMA (a learning algorithm). JoyLo eases data collection through intuitive control, while WB-VIMA leverages robot’s kinematic hierarchy for synchronized movements. BRS excels in navigation, object manipulation, and complex tasks, marking a step toward real-world household assistance.
Key Takeaways#
Why does it matter?#
This paper introduces the Behavior Robot Suite (BRS), paving the way for more capable household robots. BRS integrates a novel hardware design and whole-body learning methods, which will enable robots to navigate complex environments, handle objects, and perform everyday tasks with greater dexterity and reliability.
Visual Insights#

🔼 Figure 2 shows the distribution of household objects’ locations based on the BEHAVIOR-1K dataset. The left graph displays the horizontal distances of objects from the robot’s reachable space, following a long-tail distribution (most objects are close, few are far). The right graph shows the vertical distances (heights) of the objects, revealing multiple peaks at 1.43m, 0.94m, 0.49m, and 0.09m. This indicates that objects are commonly found at these specific heights within a house (e.g., countertops, tables, floors).
read the caption
Figure 2: Ecological distributions of task-relevant objects involved in daily household activities. Left: The horizontal distance distribution follows a long-tail distribution. Right: The vertical distance distribution exhibits multiple distinct modes, located at 1.43 mtimes1.43meter1.43\text{\,}\mathrm{m}start_ARG 1.43 end_ARG start_ARG times end_ARG start_ARG roman_m end_ARG, 0.94 mtimes0.94meter0.94\text{\,}\mathrm{m}start_ARG 0.94 end_ARG start_ARG times end_ARG start_ARG roman_m end_ARG, 0.49 mtimes0.49meter0.49\text{\,}\mathrm{m}start_ARG 0.49 end_ARG start_ARG times end_ARG start_ARG roman_m end_ARG, and 0.09 mtimes0.09meter0.09\text{\,}\mathrm{m}start_ARG 0.09 end_ARG start_ARG times end_ARG start_ARG roman_m end_ARG, representing heights at which household objects are typically found.
|
|
|
|
| |||||||||||
| WB-VIMA (ours) | 0 | 0 | 1 | 0 | 0 | ||||||||||
| DP3 [70] | 13 | 0 | 9 | 0 | 7 | ||||||||||
| RGB-DP [66] | 2 | 2 | 3 | 0 | 3 |
🔼 This table presents a quantitative overview of safety incidents during the evaluation of the Whole-Body VisuoMotor Attention (WB-VIMA) model and baseline models. It shows the number of collisions with environmental objects and instances of motor power loss due to excessive force, highlighting WB-VIMA’s enhanced safety performance compared to the baselines. The minimal number of safety incidents for WB-VIMA suggests that its whole-body motion planning and control are robust and safe, especially when compared to the higher number of incidents recorded for DP3 and RGB-DP.
read the caption
TABLE I: Safety violations during evaluation. WB-VIMA exhibits minimal collisions with environmental objects and rarely causes motor power loss due to excessive force.
In-depth insights#
WB-VIMA Policy#
The paper introduces a Whole-Body VisuoMotor Attention (WB-VIMA) policy for robot manipulation. It leverages a transformer-based model for learning coordinated actions in mobile manipulation tasks. WB-VIMA autoregressively denoises whole-body actions, considering the robot’s embodiment and multi-modal observations. A key aspect is conditioning upper-body actions on lower-body actions, improving coordination and reducing error propagation. WB-VIMA uses visuomotor self-attention to fuse visual (point clouds) and proprioceptive data, avoiding overfitting. The model predicts actions sequentially within the robot’s kinematic structure, enhancing its ability to execute complex tasks with greater accuracy and stability.
JoyLo Interface#
JoyLo seems to be a key innovation, a low-cost, whole-body teleoperation interface. Its design prioritizes efficient control, intuitive feedback via bilateral teleoperation, and data quality for policy learning. The use of kinematic-twin arms and Nintendo Joy-Cons is interesting, potentially balancing intuitiveness with precision. A key aspect is its ability to prevent singularities and ensure smooth control, crucial for replay success and mitigating embodiment mismatches. It enables faster data collection, enhanced safety, and better coordination.
Real World Tests#
Although there’s no explicit section titled “Real World Tests,” the paper describes comprehensive experiments in real-world, unmodified household environments. This is crucial because it moves beyond simulated or lab settings, highlighting the robot’s ability to handle the complexities and unpredictability inherent in human living spaces. The five chosen tasks—cleaning after a party, cleaning a toilet, taking out the trash, putting items on shelves, and laying out clothes—are representative of everyday activities and demand a combination of navigation, manipulation, and interaction with articulated objects. The evaluation methodology, including success rates for the entire task and sub-tasks, provides valuable insights into the robot’s strengths and weaknesses. Addressing these challenges is vital for developing truly useful assistive robots.
Robotics: Hardware#
Robotics hardware is the foundation for bringing AI algorithms into the physical world. Advancements in actuators, sensors, and materials directly influence a robot’s capabilities. High-performance motors, coupled with precise encoders, enable accurate movements, while robust force sensors provide the ability to interact safely. Lightweight yet strong materials allow for energy-efficient designs. The rise of modular robotics is also a key area, allowing easier customization and repair. Furthermore, effective integration of these hardware components is necessary to perform complex tasks in unstructured environments.
Action Denoising#
Action denoising appears to be a critical component for enabling effective control of complex robotic systems, especially those with multiple articulated parts. The core idea is to leverage the robot’s inherent kinematic hierarchy to improve coordination and reduce error propagation. By conditioning the action predictions of downstream joints on the predicted actions of upstream joints (e.g., conditioning arm movements on torso and base movements), the policy can better account for the interdependencies between different body parts. This approach leads to more coordinated and accurate whole-body movements, and minimizes the accumulation of errors that can arise from independent joint control. Moreover, this could lead to greater robustness and safety, preventing the robot from entering out-of-distribution states or experiencing collisions. The autoregressive nature of the action decoding process ensures that movements are sequentially predicted within the robot’s embodiment, resulting in a more coherent and stable behavior.
More visual insights#
More on figures

🔼 The figure showcases the hardware components of the BEHAVIOR ROBOT SUITE (BRS). On the left, it displays the R1 robot, highlighting its dimensions (2066mm x 1746mm x 863mm), range of motion (two 6-DoF arms with parallel jaw grippers, and a 4-DoF torso mounted on an omnidirectional mobile base with three wheel and three steering motors), and its array of sensors (ZED-Mini, ZED 2, and RealSense T265 cameras). The right side of the figure details the JoyLo teleoperation interface, which uses two 3D-printed, kinematic-twin arms with Dynamixel motors and Nintendo Joy-Con controllers for intuitive whole-body control of the R1 robot. Two Dynamixel motors are coupled together on each JoyLo arm to ensure sufficient torque at the shoulder joint.
read the caption
Figure 3: BRS hardware system. Left: The R1 robot’s dimensions, range of motion, and onboard sensors. The robot features two 6-DoF arms, each equipped with a parallel jaw gripper, and a 4-DoF torso. The torso is mounted on an omnidirectional mobile base with three wheel motors and three steering motors. Right: The JoyLo system, consisting of two kinematic-twin arms constructed using 3D-printed components and low-cost Dynamixel motors. Compact, off-the-shelf Nintendo Joy-Con controllers are mounted at the one end of the arms, serving as the interface for controlling the grippers, torso, and mobile base. To ensure sufficient stall torque for the shoulder joints, two Dynamixel motors are coupled together.

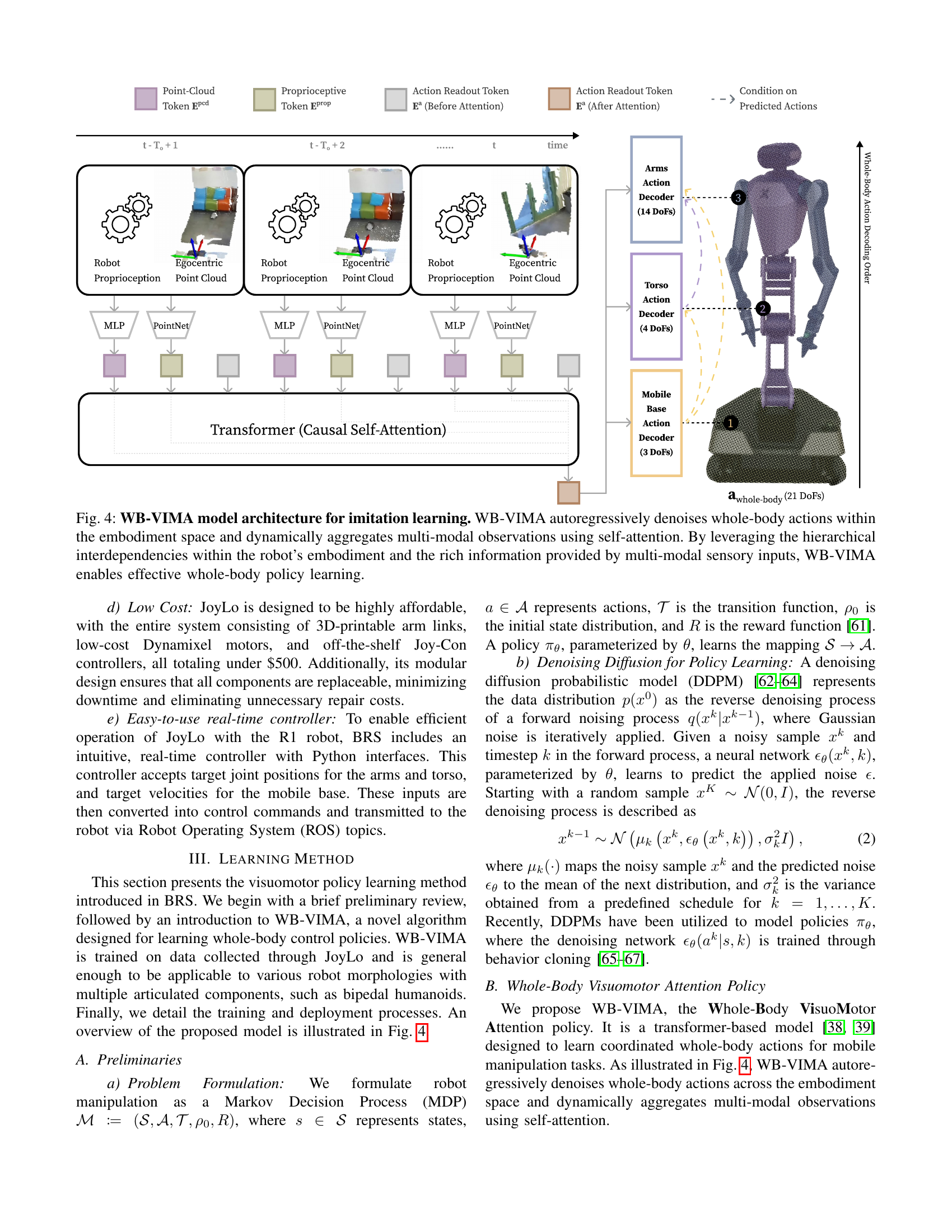
🔼 The figure illustrates the architecture of the WB-VIMA model, an imitation learning algorithm used for whole-body control. The model processes multi-modal sensory data (point cloud and proprioception) using self-attention to capture interdependencies between different parts of the robot’s body (arms, torso, base). The autoregressive denoising process predicts actions sequentially from the base to the end-effectors, ensuring coordinated whole-body movements. This hierarchical approach enables effective learning of complex whole-body policies.
read the caption
Figure 4: WB-VIMA model architecture for imitation learning. WB-VIMA autoregressively denoises whole-body actions within the embodiment space and dynamically aggregates multi-modal observations using self-attention. By leveraging the hierarchical interdependencies within the robot’s embodiment and the rich information provided by multi-modal sensory inputs, WB-VIMA enables effective whole-body policy learning.

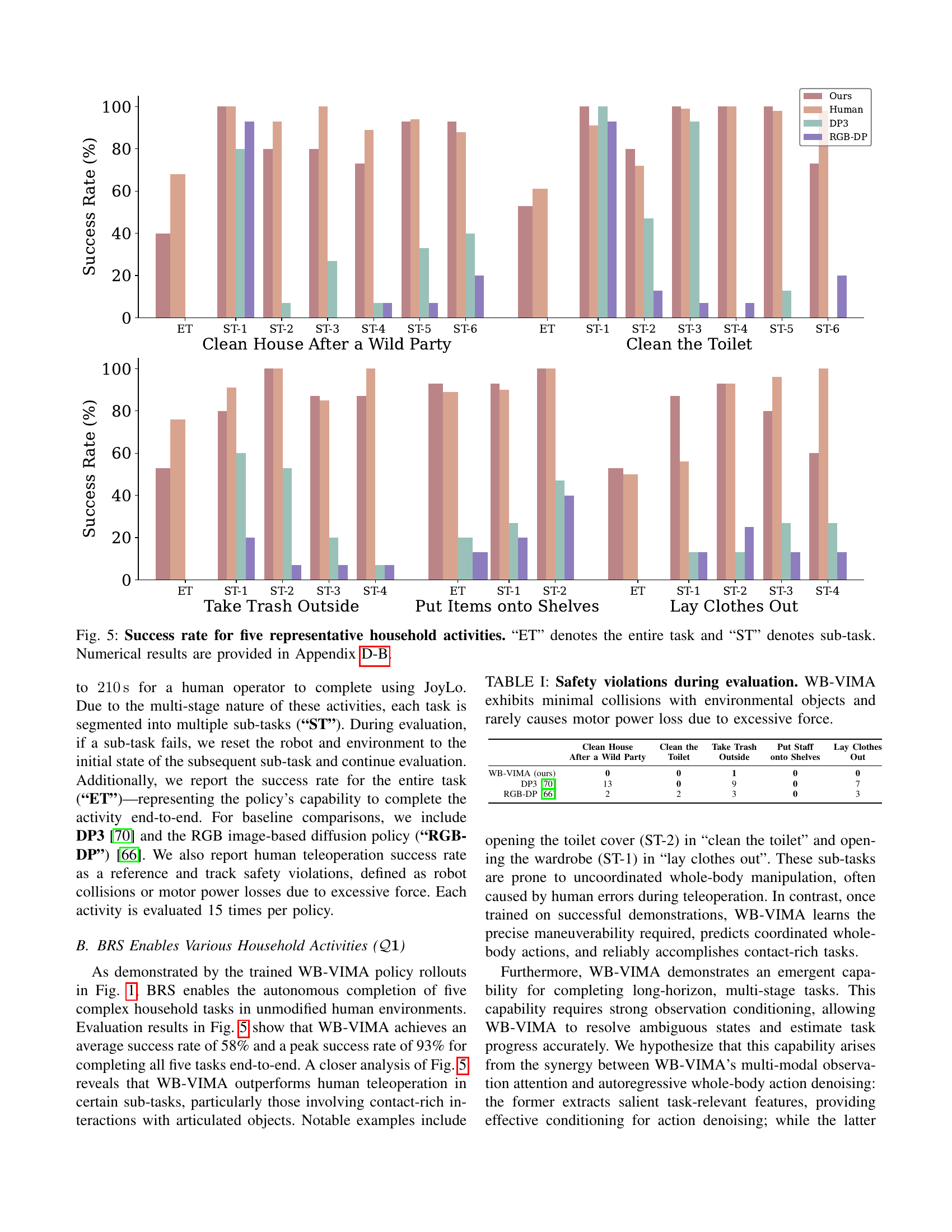
🔼 This figure presents the success rates achieved by different methods on five representative household tasks. The success rates are shown for both the entire task (‘ET’) and individual sub-tasks (‘ST’). ‘ET’ represents the percentage of times the robot successfully completed the entire task from start to finish. ‘ST’ shows the success rate for each individual step or sub-goal within a task. The methods compared include a trained WB-VIMA policy, a human operator using the JoyLo interface, DP3 (a baseline diffusion model), and RGB-DP (another baseline diffusion model that uses RGB images as input). The data visualization allows for a comparison of the overall effectiveness of each method on these tasks, as well as their relative strengths and weaknesses on the individual sub-tasks. Detailed numerical results are available in Appendix D-B.
read the caption
Figure 5: Success rate for five representative household activities. “ET” denotes the entire task and “ST” denotes sub-task. Numerical results are provided in Appendix D-B.

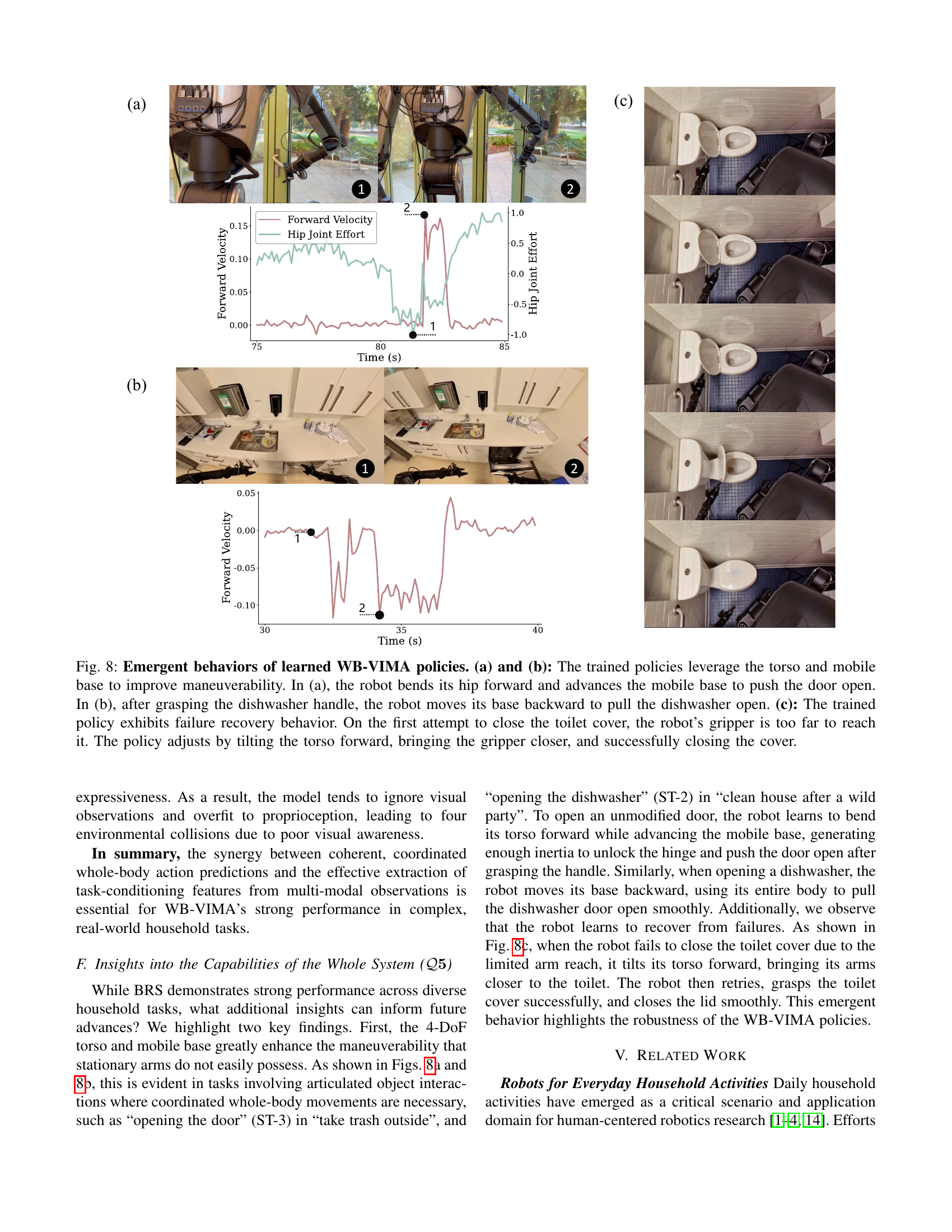
🔼 The figure shows emergent behaviors of learned WB-VIMA policies. The robot uses its torso and mobile base to improve maneuverability. In (a), the robot leans forward and moves its base to push a door open. In (b), after grasping a dishwasher handle, it moves its base backward to pull the dishwasher open. In (c), the robot demonstrates failure recovery; it adjusts its torso to reach the toilet cover when its gripper is initially too far.
read the caption
(a)

🔼 The image shows the robot successfully completing a subtask of the ‘Clean House After a Wild Party’ task. It demonstrates the robot’s ability to recover from a failed attempt to open the dishwasher. Initially, the robot’s gripper is too far from the dishwasher handle. The robot adjusts by moving its base backward, tilting its torso forward, and bringing its gripper closer to successfully close the dishwasher.
read the caption
(b)

🔼 A user study compared three interfaces for robot teleoperation: JoyLo, VR controllers, and Apple Vision Pro. The results, shown in two subfigures, demonstrate that JoyLo is the most efficient, producing the highest-quality data for robot learning. Figure 6a shows success rates and task completion times, highlighting JoyLo’s superior performance. Figure 6b presents survey results indicating JoyLo’s superior user-friendliness, especially in terms of ease of use and effectiveness for whole-body control.
read the caption
Figure 6: User study results with 10 participants. (a): JoyLo is the most efficient interface and produces the highest-quality data. “S.R.” denotes success rate. “ET Comp. Time” (“ST Comp. Time”) refers to entire task (sub-task) completion time. (b): Survey results show that JoyLo is unanimously rated as the most user-friendly interface by both robot learning practitioners and novices (“past data collection experience”). Nearly all participants find the Joy-Con helpful for whole-body control (“helpfulness of Joy-Con”).

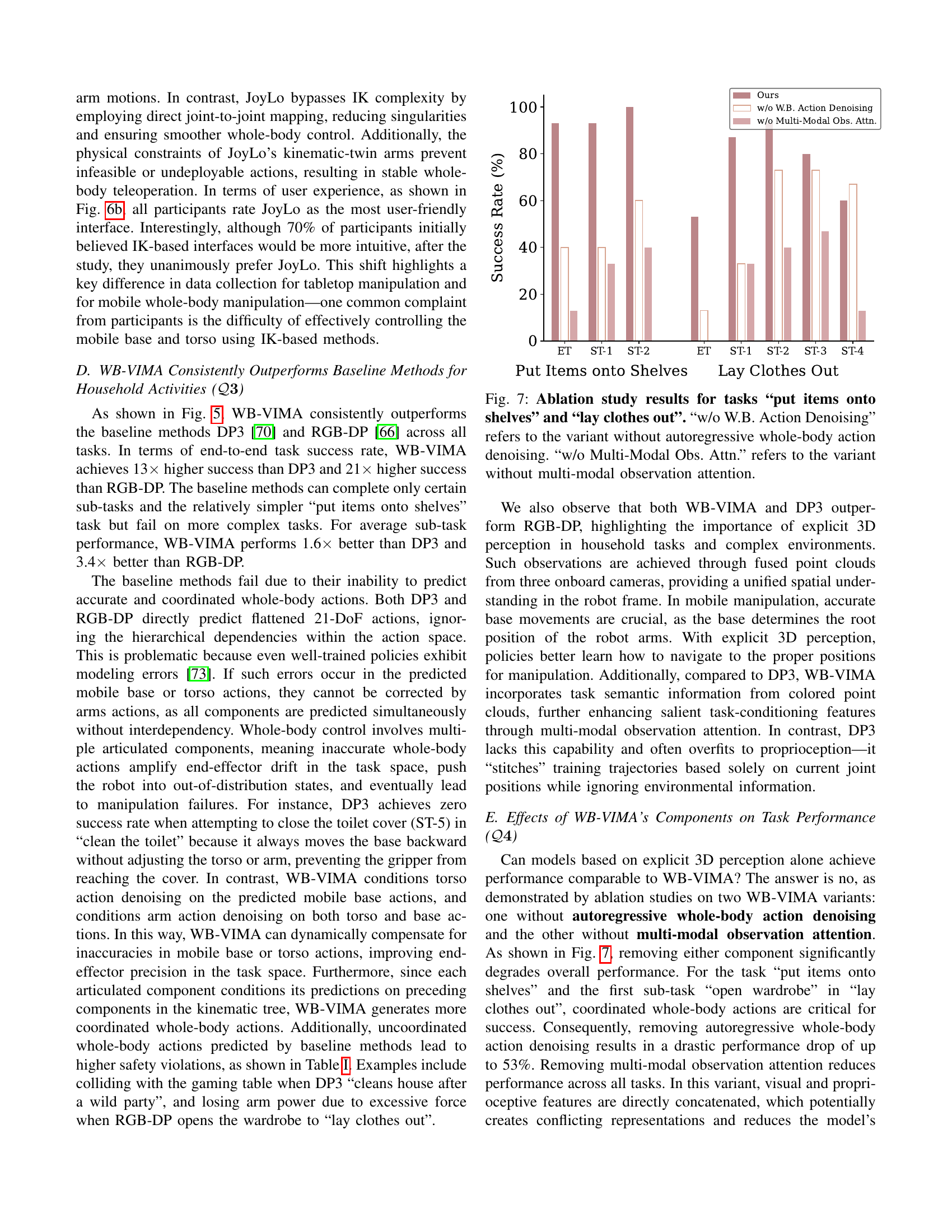
🔼 This ablation study analyzes the impact of two key components of the WB-VIMA model on task performance: autoregressive whole-body action denoising and multi-modal observation attention. The figure presents success rates for two representative household tasks, ‘Put Items onto Shelves’ and ‘Lay Clothes Out,’ comparing the full WB-VIMA model against variants where each of these components is removed. This visualization allows for a quantitative assessment of the individual contribution of each component to the model’s overall effectiveness and robustness in performing complex whole-body manipulation tasks. The results show that both components significantly contribute to the superior performance of WB-VIMA.
read the caption
Figure 7: Ablation study results for tasks “put items onto shelves” and “lay clothes out”. “w/o W.B. Action Denoising” refers to the variant without autoregressive whole-body action denoising. “w/o Multi-Modal Obs. Attn.” refers to the variant without multi-modal observation attention.

🔼 Figure 8 showcases emergent behaviors of the WB-VIMA policies in handling real-world manipulation challenges. The robot utilizes its torso and mobile base for enhanced maneuverability. In (a), the robot leans forward, using its hip and base to push a door open. In (b), the robot strategically reverses its mobile base to pull open a dishwasher after grasping the handle. Notably, (c) demonstrates a failure recovery mechanism; when unable to reach the toilet cover with its arm extended, the robot adjusts its torso position to bring the gripper within reach and successfully completes the task.
read the caption
Figure 8: Emergent behaviors of learned WB-VIMA policies. (a) and (b): The trained policies leverage the torso and mobile base to improve maneuverability. In (a), the robot bends its hip forward and advances the mobile base to push the door open. In (b), after grasping the dishwasher handle, the robot moves its base backward to pull the dishwasher open. (c): The trained policy exhibits failure recovery behavior. On the first attempt to close the toilet cover, the robot’s gripper is too far to reach it. The policy adjusts by tilting the torso forward, bringing the gripper closer, and successfully closing the cover.

🔼 The figure shows emergent behaviors of the trained WB-VIMA policies. In (a), the robot uses its hip to push the door open, demonstrating maneuverability. In (b), the robot uses its base to pull open a dishwasher. In (c), the robot recovers from a failure to close the toilet cover by adjusting its torso.
read the caption
(a)

🔼 The trained policies leverage the torso and mobile base to improve maneuverability. In (a), the robot bends its hip forward and advances the mobile base to push the door open. In (b), after grasping the dishwasher handle, the robot moves its base backward to pull the dishwasher open. In (c), the trained policy exhibits failure recovery behavior. On the first attempt to close the toilet cover, the robot’s gripper is too far to reach it. The policy adjusts by tilting the torso forward, bringing the gripper closer, and successfully closing the cover.
read the caption
(b)

🔼 The image showcases an example of the trained WB-VIMA policy’s failure recovery behavior. Initially, the robot attempts to close the toilet cover but its gripper is too far to reach. The policy then smartly adjusts by tilting the torso forward, bringing the gripper closer, and successfully completes the action of closing the toilet cover.
read the caption
(c)

🔼 The figure shows three diagrams of the robot’s hardware components. Diagram (a) illustrates the robot’s dual arms, each having six degrees of freedom (DoFs) and a parallel jaw gripper. Diagram (b) depicts the robot’s four-DoF torso which allows for waist rotation, hip bending, and knee-like motions. Lastly, Diagram (c) presents the omnidirectional mobile base that uses three steering motors and three wheel motors enabling versatile movement.
read the caption
Figure A.1: Robot diagrams. (a): Each arm has six DoFs and a parallel jaw gripper. (b): The torso features four revolute joints for waist rotation, hip bending, and knee-like motions. (c): The wheeled, omnidirectional mobile base is equipped with three steering motors and three wheel motors.

🔼 Figure A.2 presents a visualization of the processed point cloud data used by the robot. The left panel shows the colored point cloud data from all three cameras (head, left and right arms) fused into a single egocentric view aligned with the robot’s coordinate frame. This provides a comprehensive 3D view of the robot’s surroundings. The right panel shows the robot’s orientation within its environment, illustrating how the robot perceives and understands its spatial location relative to surrounding objects.
read the caption
Figure A.2: Visualization of the fused, ego-centric colored point clouds. Left: The colored point cloud observation, aligned with the robot’s coordinate frame. Right: The robot’s orientation and its surrounding environment.

🔼 The figure shows the individual links of a single JoyLo arm. Each arm consists of multiple 3D-printed links and low-cost Dynamixel motors. The JoyLo system uses two of these arms for intuitive whole-body teleoperation.
read the caption
Figure A.3: Individual JoyLo arm links.

🔼 Figure A.4 shows the generalization capabilities tested for the task of cleaning up after a party. The left panel displays variations of bowls used in the experiment, categorized as ‘seen’ (bowls that were included during training) and ‘unseen’ (bowls not seen during training). This tests the model’s ability to generalize to new, unseen objects. The middle panel illustrates the designated starting region for the robot. The right panel showcases various initial placements of objects (bowls in this case) on the gaming table. These different starting configurations and object arrangements demonstrate the robustness and adaptability of the robot’s learned policy.
read the caption
Figure A.4: Generalization settings for the task “clean house after a wild party”. From left to right: seen and unseen bowl variations, robot’s starting region, and initial object placements on the gaming table.

🔼 Figure A.5 shows various aspects of the experimental setup for the ‘clean the toilet’ task. The image shows three key elements. First, it illustrates the robot’s designated starting location within the restroom environment. Second, it displays a range of different sponge types used during the experiment to assess the robot’s adaptability to varying object characteristics. Third, it shows different initial positions or placements of the toilet cleaning objects before the robot begins the task. These variations help ensure the robustness of the experimental design by testing the robot’s ability to complete the task in a variety of realistic scenarios.
read the caption
Figure A.5: Generalization settings for the task “clean the toilet”. From left to right: robot’s starting region, sponge variations, and initial placements.

🔼 The figure displays the generalization settings used for the ‘Take Trash Outside’ task within the BEHAVIOR ROBOT SUITE (BRS) experiment. It showcases two key aspects: the possible starting locations of the robot, indicated by a designated ‘Starting Region’, and the various possible initial locations of the trash bag, illustrated as an ‘Initial Placement Region’. This variation in starting configurations and object placement ensures the robustness and generalizability of the learned robot policy by testing its ability to complete the task across a range of realistic scenarios.
read the caption
Figure A.6: Generalization settings for the task “take trash outside”. From left to right: initial placement region of the trash bag and robot’s starting region.

🔼 Figure A.7 shows different aspects of the experimental setup for the ‘put items onto shelves’ task. It illustrates the variability introduced to test the robustness of the robot’s ability to generalize its actions across different scenarios. The image displays three key elements: the robot’s starting position (showing the range of potential starting locations), the arrangement of boxes to be placed onto the shelves (including various placements to increase variability), and finally, several configurations of shelves (demonstrating the different shelf setups the robot was tested on). Each of these variable elements is designed to challenge the robot’s ability to perform the task consistently and successfully despite changes in the environment.
read the caption
Figure A.7: Generalization settings for the task “put items onto shelves”. From left to right: robot’s starting region, box placements, and shelf configurations.

🔼 Figure A.8 shows various scenarios for the task of laying out clothes. It illustrates the generalization capabilities of the system by showcasing different starting positions for the robot, various arrangements of clothes, and different types of clothing items (e.g., different colors and styles). This demonstrates the robustness of the learned policy and its ability to handle the variability inherent in real-world environments.
read the caption
Figure A.8: Generalization settings for the task “lay clothes out”. From left to right: robot’s starting region, clothing placements, and clothing variations.
More on tables
| Clean House |
| After a Wild Party |
🔼 Table A.I provides detailed specifications for the motors that control the robot’s torso. It lists the range of motion (in radians and degrees) for each of the four torso joints: waist (yaw), hip (pitch), and two knee-like joints. It also gives the rated and maximum motor torque for these joints in Newton-meters (Nm). This table is essential for understanding the physical capabilities and limitations of the robot’s torso.
read the caption
TABLE A.I: Torso motor specifications.
| Clean the |
| Toilet |
🔼 This table lists the specifications of the mobile base of the R1 robot, including its velocity limits, acceleration limits, and onboard sensors.
read the caption
TABLE A.II: Mobile base specifications.
| Take Trash |
| Outside |
🔼 Table A.III presents the configurations used for the ZED stereo RGB-D cameras (both the main head camera and the two wrist cameras) and the RealSense T265 tracking camera. It details the frequency of data acquisition, image resolution, depth mode for the ZED cameras, and minimum and maximum depth ranges for each camera setup. This information is crucial for understanding the quality and characteristics of the visual data collected by the robot for the tasks in the BEHAVIOR ROBOT SUITE.
read the caption
TABLE A.III: Configurations for the ZED RGB-D cameras and RealSense T265 tracking camera.
| Put Staff |
| onto Shelves |
🔼 Table A.IV provides a detailed breakdown of the costs associated with building the JoyLo teleoperation interface. It lists each component, its quantity, unit price, total price, and supplier. This table is valuable for understanding the affordability and accessibility of the JoyLo system, as it demonstrates the low cost of the materials used in its construction.
read the caption
TABLE A.IV: JoyLo bill of materials.
| Lay Clothes |
| Out |
🔼 Table A.V presents the hyperparameters used for both the PointNet and the proprioception MLP. PointNet is a deep learning architecture used for processing point cloud data, while the proprioception MLP processes proprioceptive data (information about the robot’s own state, such as joint angles and velocities). The table lists specific values used in the model’s configuration, such as the number of hidden dimensions in each network, their depth (number of layers), and the activation functions used. These hyperparameters are critical for the performance of the model and tuning them appropriately is an essential part of training.
read the caption
TABLE A.V: Hyperparameters for PointNet and the proprioception MLP.
| Parameter | Value |
|---|---|
| Waist Joint Range (Yaw) | () |
| Hip Joint Range (Pitch) | () () |
| Knee Joint 1 Range | () () |
| Knee Joint 2 Range | () () |
| Rated Motor Torque | |
| Maximum Motor Torque |
🔼 This table lists the hyperparameters used for configuring the transformer decoder within the WB-VIMA model. The transformer decoder is a key component of the model responsible for processing and integrating information from multiple sensory modalities (vision and proprioception) before generating predictions for the robot’s actions. The hyperparameters control various aspects of the transformer’s architecture and training process, influencing its ability to learn effective and coordinated whole-body movements.
read the caption
TABLE A.VI: Hyperparameters for the transformer decoder used in multi-modal observation attention.
| Parameter | Value |
|---|---|
| Forward Velocity Limit | |
| Lateral Velocity Limit | |
| Yaw Rotation Velocity Limit | |
| Forward Acceleration Limit | |
| Lateral Acceleration Limit | |
| Yaw Rotation Acceleration Limit |
🔼 This table lists the hyperparameters used for training the UNet models within the WB-VIMA architecture. These UNet models are responsible for the autoregressive denoising of the whole-body actions (mobile base, torso, and arms) during the policy learning process. The hyperparameters specified include the number of hidden dimensions, kernel size, group normalization settings, and embedding dimensions for the diffusion steps. This table is crucial for understanding the configuration of the model’s denoising components and how they impact the quality and efficiency of whole-body action prediction.
read the caption
TABLE A.VII: Hyperparameters for the UNet models used for denoising.
| Parameter | Value |
|---|---|
| RGB-D Cameras | |
| Frequency | |
| Image Resolution | 1344376 |
| ZED Depth Mode | PERFORMANCE |
| Head Camera Min Depth | 0.2 |
| Head Camera Max Depth | 3 |
| Wrist Camera Min Depth | 0.1 |
| Wrist Camera Max Depth | 1 |
| Tracking Camera | |
| Odometry Frequency | |
🔼 This table lists the hyperparameters used for training the WB-VIMA model. It includes settings for the optimizer (AdamW), such as learning rate, weight decay, learning rate warmup steps, learning rate cosine decay steps, and minimal learning rate. These values are crucial for controlling the training process and achieving optimal model performance.
read the caption
TABLE A.VIII: Training hyperparameters.
| Item No. | Part Name | Description | Quantity | Unit Price ($) | Total Price ($) | Supplier |
| 1 | Dynamixel XL330-M288-T | JoyLo arm joint motors | 16 | 23.90 | 382.40 | Dynamixel |
| 2 | Nintendo Joy-Con | JoyLo hand-held controllers | 1 | 70 | 70 | Nintendo |
| 3 | Dynamixel U2D2 | USB communication converter for controlling Dynamixel motors | 1 | 32.10 | 32.10 | Dynamixel |
| 4 | 5V DC Power Supply | Power supply for Dynamixel motors | 1 | <10 | <10 | Various |
| 5 | 3D Printer PLA Filament | PLA filament for 3D printing JoyLo arm links | 1 | 5 | 5 | Various |
| Total Cost: $499.5 | ||||||
🔼 Table A.IX presents a detailed breakdown of the success rates achieved by different methods (Human, Ours, DP3, and RGB-DP) across various sub-tasks involved in the ‘Clean House After a Wild Party’ task. The success rates are expressed as percentages, with the number of successful trials out of the total trials provided in parentheses. This allows for a granular understanding of performance at each stage of the task, revealing where certain approaches may struggle and highlighting the overall effectiveness of different methods. The table also notes any safety violations (collisions or motor power loss) that occurred during the task execution.
read the caption
TABLE A.IX: Numerical evaluation results for the task “clean house after a wild party”. Success rates are shown as percentages. Values in parentheses indicate the number of successful trials out of the total trials.
| Hyperparameter | Value | Hyperparameter | Value |
|---|---|---|---|
| PointNet | Prop. MLP | ||
| 4096 | Input Dim | 21 | |
| Hidden Dim | 256 | Hidden Dim | 256 |
| Hidden Depth | 2 | Hidden Depth | 3 |
| Output Dim | 256 | Output Dim | 256 |
| Activation | GELU | Activation | ReLU |
🔼 Table A.X presents a detailed breakdown of the success rates achieved by different methods (Human, Ours, DP3 [70], and RGB-DP [66]) on the ‘Clean the Toilet’ task. Success is measured for the entire task (ET) as well as individual sub-tasks (ST1-ST6), providing a granular view of performance at each stage of the process. The success rates are expressed as percentages, with the raw numbers of successful and total trials included in parentheses for complete transparency and reproducibility of the results. Additionally, safety violations (collisions or motor power loss) are recorded for each method, offering further insights into the robustness and safety of each approach during task execution.
read the caption
TABLE A.X: Numerical evaluation results for the task “clean the toilet”. Success rates are shown as percentages. Values in parentheses indicate the number of successful trials out of the total trials.
| Hyperparameter | Value |
|---|---|
| Embed Size | 256 |
| Num Layers | 2 |
| Num Heads | 8 |
| Dropout Rate | 0.1 |
| Activation | GEGLU [171] |
🔼 This table presents a detailed breakdown of the success rates achieved by different methods (human, Ours, DP3, and RGB-DP) on the sub-tasks involved in the ‘Take Trash Outside’ task. Success rates are represented as percentages, and the raw numbers of successful trials versus total trials for each method and subtask are given in parentheses. Additionally, the number of safety violations (collisions or excessive force leading to motor power loss) is recorded for each method. This allows for a granular analysis of performance and safety across various approaches and task stages.
read the caption
TABLE A.XI: Numerical evaluation results for the task “take trash outside”. Success rates are shown as percentages. Values in parentheses indicate the number of successful trials out of the total trials.
| Hyperparameter | Value |
|---|---|
| Hidden Dim | [64,128] |
| Kernel Size | 2 |
| GroupNorm Num Groups | 5 |
| Diffusion Step Embd Dim | 8 |
🔼 Table A.XII presents a detailed breakdown of the success rates achieved by different methods (Human, Ours, DP3 [70], RGB-DP [66], Ours w/o W.B. Action Denoising, Ours w/o Multi-Modal Obs. Attn.) on the ‘Put Items onto Shelves’ task. The success rates are expressed as percentages, with the raw numbers of successful and total trials given in parentheses. This granular data allows for a precise comparison of performance across various methods and helps to understand the impact of specific model components on overall success in completing this household task. The table also shows the number of safety violations (collisions or motor power losses) encountered during each method’s trials.
read the caption
TABLE A.XII: Numerical evaluation results for the task “put items onto shelf”. Success rates are shown as percentages. Values in parentheses indicate the number of successful trials out of the total trials.
| Hyperparameter | Value |
|---|---|
| Learning Rate | |
| Weight Decay | 0.1 |
| Learning Rate Warm Up Steps | 1000 |
| Learning Rate Cosine Decay Steps | 300,000 |
| Minimal Learning Rate |
🔼 Table A.XIII presents a detailed breakdown of the success rates achieved by different methods (Human, Ours, DP3, RGB-DP, and two ablation variants of Ours) on the ‘Lay Clothes Out’ task. Success is measured across the entire task (ET) and its four sub-tasks (ST1-ST4). The success rates are represented as percentages, with the number of successful trials out of the total trials indicated in parentheses for each method and subtask. Additionally, the table includes a count of safety violations (collisions, motor power loss) for each approach. This granular level of detail enables a thorough comparison of the performance and safety profiles of various methods on this complex household task.
read the caption
TABLE A.XIII: Numerical evaluation results for the task “lay clothes out”. Success rates are shown as percentages. Values in parentheses indicate the number of successful trials out of the total trials.
Full paper#