TL;DR#
The integration of AI into Software Engineering (AI4SE) has led to numerous benchmarks for tasks like code generation. However, this surge presents challenges such as scattered benchmark knowledge, difficulty in selecting relevant benchmarks, absence of a uniform standard for benchmark development, and limitations of existing benchmarks. Addressing these issues is critical for accurate evaluation and comparison of AI models in software engineering.
This paper introduces BenchScout, a semantic search tool, to find relevant benchmarks and BenchFrame, a unified method to enhance benchmark quality. BenchFrame is applied to the HumanEval benchmark, leading to HumanEvalNext, featuring corrected errors, improved language conversion, expanded test coverage, and increased difficulty. The paper then evaluates ten state-of-the-art code language models on HumanEvalNext.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it addresses critical gaps in AI4SE benchmark quality and accessibility. The BenchFrame and BenchScout tools offers an approach to enhance existing benchmarks and streamline benchmark selection which ensures more reliable and relevant evaluations of AI models.
Visual Insights#
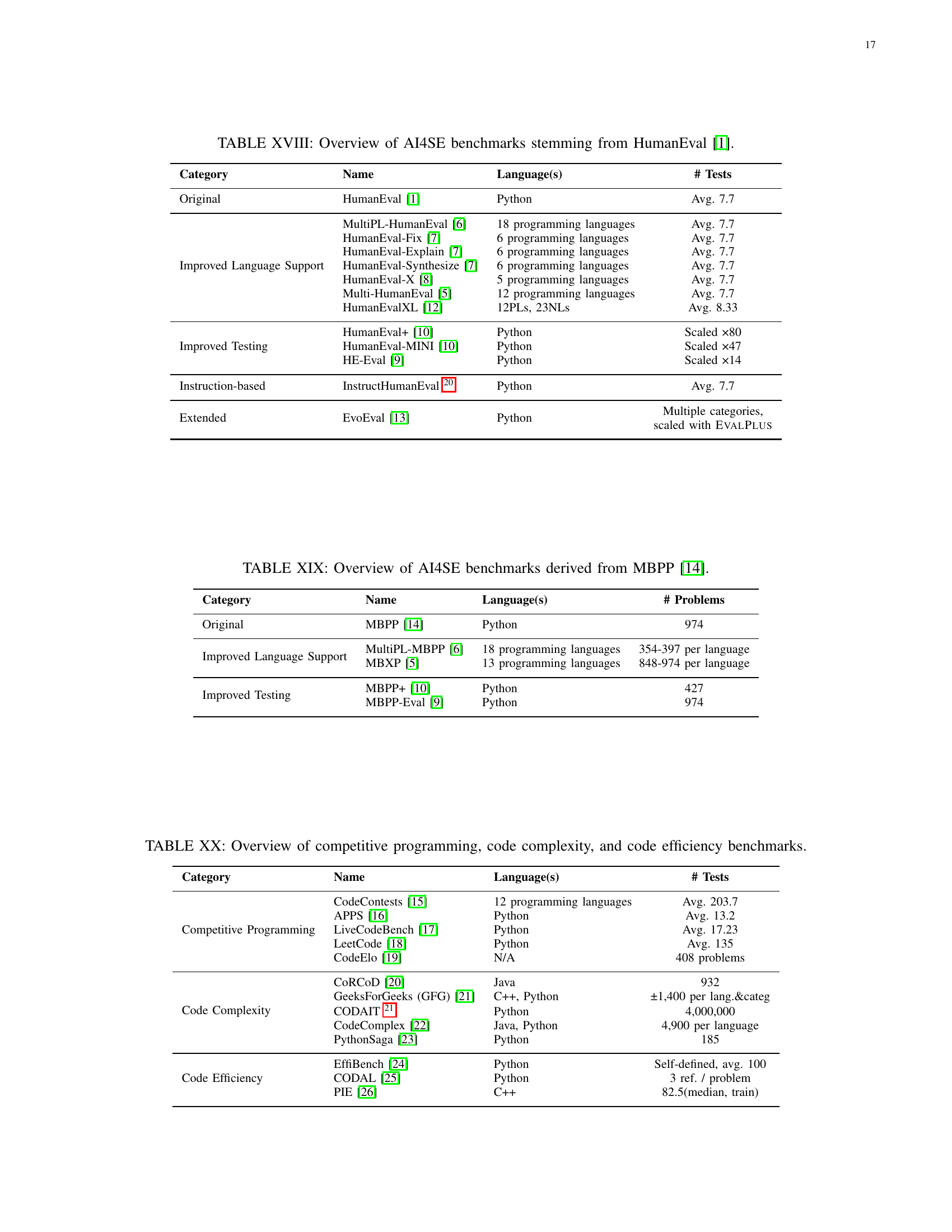
| Category | Name | Language(s) | # Tests |
| Original | HumanEval [HumanEval-2021] | Python | Avg. 7.7 |
| Improved Language Support | MultiPL-HumanEval [MultiPL-E-2022] | 18 programming languages | Avg. 7.7 |
| HumanEval-Fix [HumanEvalPack-2023] | 6 programming languages | Avg. 7.7 | |
| HumanEval-Explain [HumanEvalPack-2023] | 6 programming languages | Avg. 7.7 | |
| HumanEval-Synthesize [HumanEvalPack-2023] | 6 programming languages | Avg. 7.7 | |
| HumanEval-X [HumanEval-X-2023] | 5 programming languages | Avg. 7.7 | |
| Multi-HumanEval [MultiEval-HumanEval-MBXP-MathQA-X-2022] | 12 programming languages | Avg. 7.7 | |
| HumanEvalXL [peng_humaneval-xl_2024] | 12PLs, 23NLs | Avg. 8.33 | |
| Improved Testing | HumanEval+ [HumanEvalPlus-Mini-MBPP+-2023] | Python | Scaled ×80 |
| HumanEval-MINI [HumanEvalPlus-Mini-MBPP+-2023] | Python | Scaled ×47 | |
| HE-Eval [CodeScore-HE-APPS-MBPP-Eval-2023] | Python | Scaled ×14 | |
| Instruction-based | InstructHumanEval 111https://huggingface.co/datasets/codeparrot/instructhumaneval | Python | Avg. 7.7 |
| Extended | EvoEval [EvoEval-2024] | Python | Multiple categories, |
| scaled with EvalPlus |
🔼 This table presents an overview of various AI4SE (Artificial Intelligence in Software Engineering) benchmarks that originated from the HumanEval benchmark. It categorizes these benchmarks based on modifications made to the original HumanEval, such as improvements to language support, testing methodologies, and overall expansion of the benchmark. For each benchmark, the table lists its name, the programming languages it supports, and the number of tests or problems it contains.
read the caption
TABLE I: Overview of AI4SE benchmarks stemming from HumanEval [HumanEval-2021].
In-depth insights#
AI4SE Review#
Based on the review, AI4SE benchmarks exhibit a growing trend, highlighting the increasing integration of AI in software engineering. The review identifies key limitations, including scattered benchmark knowledge, difficulty in selection, absence of uniform standards, and inherent flaws. The review process involved a systematic search, credibility verification, and taxonomy development to categorize benchmarks, extract metadata, and address the challenges in evaluating AI models for code generation, repair, and understanding. BenchFrame introduces a unified approach for benchmark enhancement, as demonstrated through the HUMANEVALNEXT case study, addressing issues like incorrect tests and insufficient test coverage. This framework serves as a guiding light for improving the methodology and shedding light on limitations in existing AI4SE benchmarks, paving the way for better evaluation and advancement of AI in software engineering practices.
BenchScout Tool#
BenchScout is a tool designed to address the challenge of locating relevant AI4SE benchmarks. Given the abundance of these benchmarks, finding the most suitable one for a specific software engineering task can be difficult. BenchScout aims to systematically and semantically search existing benchmarks and their corresponding use cases. It seeks to visually evaluate the closeness and similarity of benchmark groups. It finds the relations between citing bodies to identify patterns relevant to different use cases. The tool aims to map unstructured textual content of papers to a semistructured domain using pre-trained text embedding models. It applies dimensionality reduction to create a 2D representation that’s easy to interpret and uses clustering techniques to assess similarity. The interactive interface is to allow users to explore clusters. BenchScout enhances search through features like text-based search and a paper content tooltip. A user study indicates high usability.
BenchFrame Qlty#
BenchFrame aims to improve benchmark quality for AI in Software Engineering (AI4SE). It likely addresses crucial aspects like correcting errors, improving language conversion, and expanding test coverage. The lack of standardization in benchmark development can lead to inconsistent evaluations and hinder progress. BenchFrame probably provides a structured methodology for refining benchmarks, ensuring they are robust and reliable. This is essential for accurately assessing model performance, preventing data leakage, and promoting fair comparisons across different approaches. By focusing on the practical aspects of enhancing benchmark quality, BenchFrame likely serves as a valuable tool for researchers and practitioners in the AI4SE field.
HumanEvalNext#
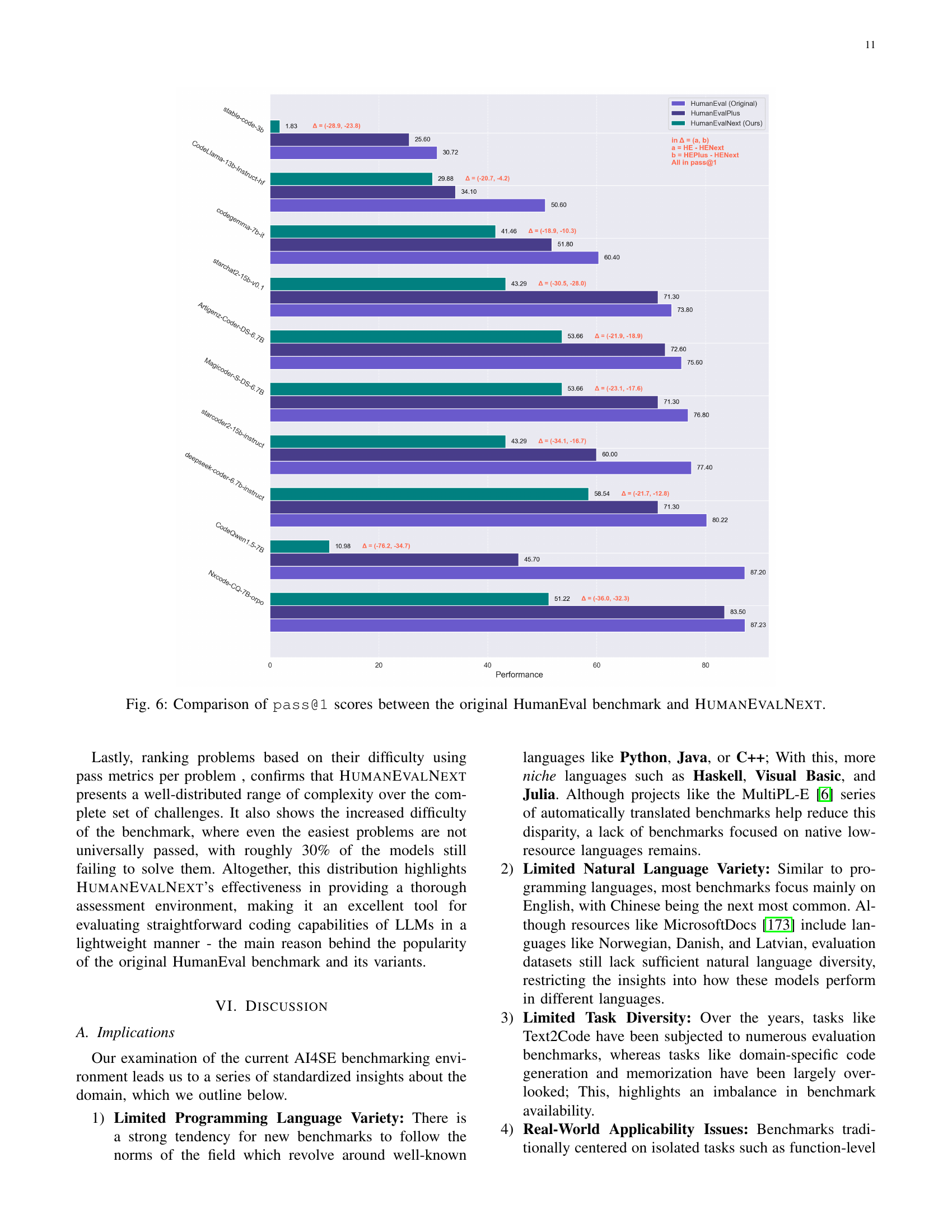
HumanEvalNext is presented as an enhanced version of the original HumanEval benchmark, addressing limitations such as incorrect tests and suboptimal solutions. Modifications include fixing canonical solutions, adding type annotations for improved language conversion support, and incorporating challenging scenarios (negative values, edge cases) to prevent overfitting. Assertions are implemented within the code to prevent models from ignoring crucial details. Test examples are refined, and spelling errors corrected. The independent peer review confirms the enhancements’ robustness while refining its quality.
Bench AI Limit#
The concept of ‘Bench AI Limit’ likely refers to the inherent constraints and shortcomings of using AI-driven benchmarks in fields like software engineering (AI4SE). This includes limitations in scope, where benchmarks may not fully capture the complexity of real-world tasks, leading to an overestimation of AI capabilities. Another aspect is data contamination, where training datasets inadvertently include benchmark data, artificially inflating performance scores and hindering accurate evaluation. Benchmark saturation is also a concern, as models become increasingly adept at solving existing benchmarks, necessitating continuous development of more challenging and diverse benchmarks to truly reflect AI progress. The absence of standardized benchmark development practices is another factor. Addressing these limits is essential for ensuring benchmarks effectively guide innovation and provide reliable assessments of AI systems.
More visual insights#
More on tables
| Category | Name | Language(s) | # Problems |
| Original | MBPP [MBPP-MathQA-2021] | Python | 974 |
| Improved Language Support | MultiPL-MBPP [MultiPL-E-2022] | 18 programming languages | 354-397 per language |
| MBXP [MultiEval-HumanEval-MBXP-MathQA-X-2022] | 13 programming languages | 848-974 per language | |
| Improved Testing | MBPP+ [HumanEvalPlus-Mini-MBPP+-2023] | Python | 427 |
| MBPP-Eval [CodeScore-HE-APPS-MBPP-Eval-2023] | Python | 974 |
🔼 This table presents a comprehensive overview of AI4SE (Artificial Intelligence in Software Engineering) benchmarks derived from the MBPP (Mostly Basic Python Problems) benchmark. It categorizes these benchmarks based on their origin (original, improved language support, or improved testing) and provides the name of each benchmark along with the programming language(s) it supports and the number of problems included.
read the caption
TABLE II: Overview of AI4SE benchmarks derived from MBPP [MBPP-MathQA-2021].
| Category | Name | Language(s) | # Tests |
| Competitive Programming | CodeContests [CodeContests-AlphaCode-2022] | 12 programming languages | Avg. 203.7 |
| APPS [APPS-2021] | Python | Avg. 13.2 | |
| LiveCodeBench [jain_livecodebench_2024] | Python | Avg. 17.23 | |
| LeetCode [tian_is_2023] | Python | Avg. 135 | |
| CodeElo [quan_codeelo_2025] | N/A | 408 problems | |
| Code Complexity | CoRCoD [CoRCoD-2019] | Java | 932 |
| GeeksForGeeks (GFG) [GFG-2023] | C++, Python | ±1,400 per lang.&categ | |
| CODAIT 222CODAIT-2021 https://ibm.co/4emPBIa | Python | 4,000,000 | |
| CodeComplex [CodeComplex-2022] | Java, Python | 4,900 per language | |
| PythonSaga [PythonSaga-HumanEval-MBPP-Evaluation-Difficulty-2024] | Python | 185 | |
| Code Efficiency | EffiBench [EffiBench-2024] | Python | Self-defined, avg. 100 |
| CODAL [m_weyssow_codeultrafeedback_2024] | Python | 3 ref. / problem | |
| PIE [shypula_learning_2024] | C++ | 82.5(median, train) |
🔼 This table presents a collection of benchmarks categorized into three groups based on their focus: competitive programming, code complexity, and code efficiency. Each benchmark includes the name, primary programming language(s) used, and the number of tests or problems included. This allows readers to quickly compare the characteristics of different benchmarking tools and select the most appropriate one for evaluating specific aspects of code quality and performance.
read the caption
TABLE III: Overview of competitive programming, code complexity, and code efficiency benchmarks.
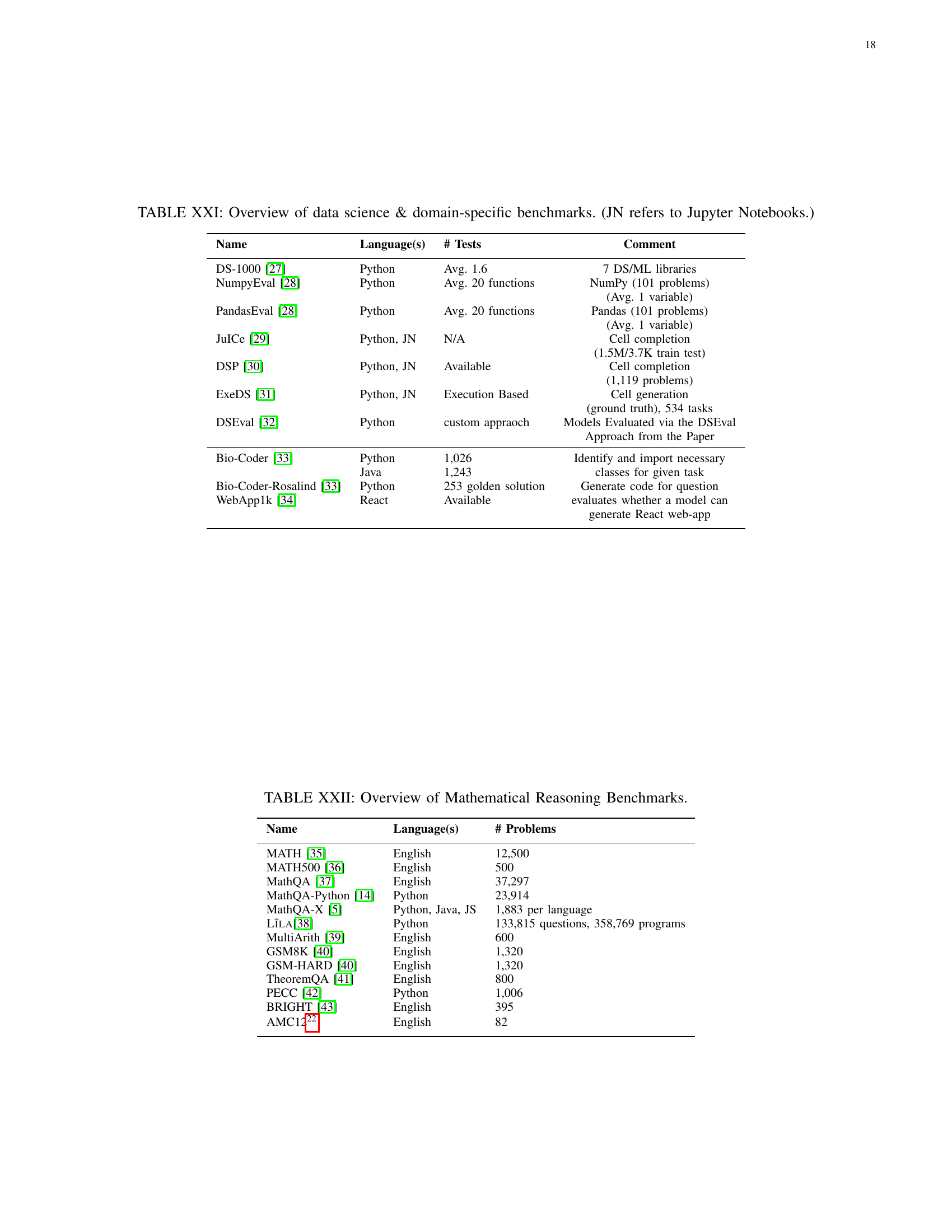
| Name | Language(s) | # Tests | Comment |
| DS-1000 [DS-1000-2022] | Python | Avg. 1.6 | 7 DS/ML libraries |
| NumpyEval [NumpyEval-PandasEval-PyCodeGPT-2022] | Python | Avg. 20 functions | NumPy (101 problems) |
| (Avg. 1 variable) | |||
| PandasEval [NumpyEval-PandasEval-PyCodeGPT-2022] | Python | Avg. 20 functions | Pandas (101 problems) |
| (Avg. 1 variable) | |||
| JuICe [JuICe-2019] | Python, JN | N/A | Cell completion |
| (1.5M/3.7K train test) | |||
| DSP [DSP-2022] | Python, JN | Available | Cell completion |
| (1,119 problems) | |||
| ExeDS [huang_junjie_execution-based_2022] | Python, JN | Execution Based | Cell generation |
| (ground truth), 534 tasks | |||
| DSEval [zhang_benchmarking_2024] | Python | custom appraoch | Models Evaluated via the DSEval |
| Approach from the Paper | |||
| Bio-Coder [xiangru_tang_biocoder_2024] | Python | 1,026 | Identify and import necessary |
| Java | 1,243 | classes for given task | |
| Bio-Coder-Rosalind [xiangru_tang_biocoder_2024] | Python | 253 golden solution | Generate code for question |
| WebApp1k [cui2024webapp1kpracticalcodegenerationbenchmark] | React | Available | evaluates whether a model can |
| generate React web-app |
🔼 This table presents a compilation of benchmarks specifically designed for evaluating the performance of AI models in data science tasks and other domain-specific software engineering problems. It details each benchmark’s name, the programming languages involved, the number of tests or problems included, and additional comments to clarify specific aspects or limitations. The ‘JN’ notation indicates the use of Jupyter Notebooks within the benchmark.
read the caption
TABLE IV: Overview of data science & domain-specific benchmarks. (JN refers to Jupyter Notebooks.)
| Name | Language(s) | # Problems |
| MATH [dan_hendrycks_measuring_2021] | English | 12,500 |
| MATH500 [lightman_lets_2023] | English | 500 |
| MathQA [MathQA-2019] | English | 37,297 |
| MathQA-Python [MBPP-MathQA-2021] | Python | 23,914 |
| MathQA-X [MultiEval-HumanEval-MBXP-MathQA-X-2022] | Python, Java, JS | 1,883 per language |
| Līla[Lila-BHASKARA-2022] | Python | 133,815 questions, 358,769 programs |
| MultiArith [MultiArith-2015] | English | 600 |
| GSM8K [PAL-GSM-Math-2022] | English | 1,320 |
| GSM-HARD [PAL-GSM-Math-2022] | English | 1,320 |
| TheoremQA [TheoremQA-2023] | English | 800 |
| PECC [patrick_haller_pecc_2024] | Python | 1,006 |
| BRIGHT [hongjin_su_bright_2024] | English | 395 |
| AMC12333https://huggingface.co/datasets/AI-MO/aimo-validation-amc | English | 82 |
🔼 This table presents a list of various benchmarks used for evaluating the mathematical reasoning capabilities of AI models in the context of software engineering. For each benchmark, it lists the name, the languages it supports, the number of problems it contains, and additional notes or specifics. This provides a comprehensive overview of available resources for assessing AI’s mathematical reasoning skills within AI4SE.
read the caption
TABLE V: Overview of Mathematical Reasoning Benchmarks.
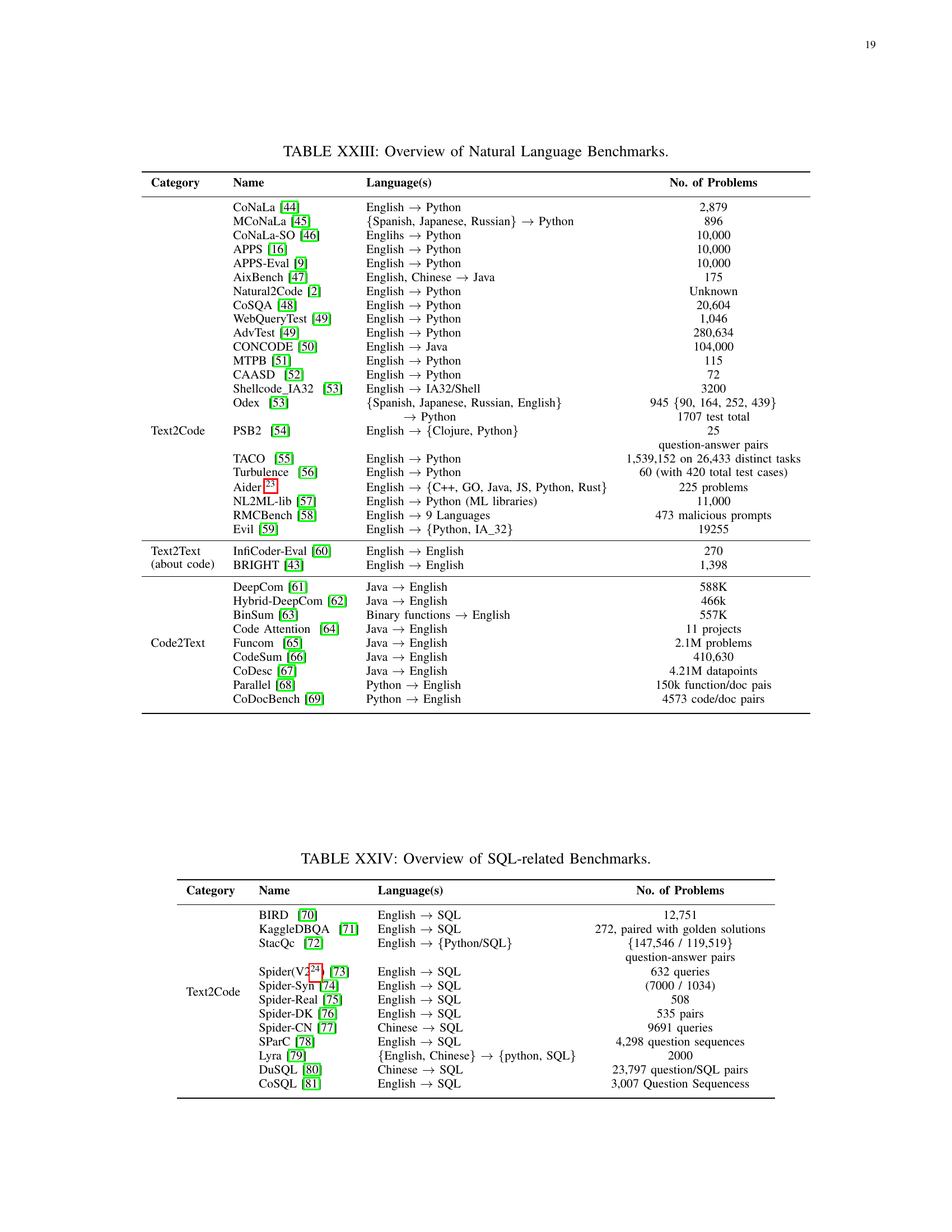
| Category | Name | Language(s) | No. of Problems |
| Text2Code | CoNaLa [CoNaLa-2018] | English Python | 2,879 |
| MCoNaLa [MCoNaLa-2022] | {Spanish, Japanese, Russian} Python | 896 | |
| CoNaLa-SO [orlanski_reading_2021] | Englihs Python | 10,000 | |
| APPS [APPS-2021] | English Python | 10,000 | |
| APPS-Eval [CodeScore-HE-APPS-MBPP-Eval-2023] | English Python | 10,000 | |
| AixBench [AixBench-2022] | English, Chinese Java | 175 | |
| Natural2Code [Gemini-Natural2Code-2023] | English Python | Unknown | |
| CoSQA [CoSQA-2021] | English Python | 20,604 | |
| WebQueryTest [CodeXGLUE-2021] | English Python | 1,046 | |
| AdvTest [CodeXGLUE-2021] | English Python | 280,634 | |
| CONCODE [Concode-2018] | English Java | 104,000 | |
| MTPB [MTPB-CodeGen-2022] | English Python | 115 | |
| CAASD [simiao_zhang_experimenting_2024] | English Python | 72 | |
| Shellcode_IA32 [liguori_can_2022] | English IA32/Shell | 3200 | |
| Odex [liguori_can_2022] | {Spanish, Japanese, Russian, English} | 945 {90, 164, 252, 439} | |
| Python | 1707 test total | ||
| PSB2 [thomas_helmuth_psb2_2021] | English {Clojure, Python} | 25 | |
| question-answer pairs | |||
| TACO [rongao_li_taco_2023] | English Python | 1,539,152 on 26,433 distinct tasks | |
| Turbulence [shahin_honarvar_turbulence_2023] | English Python | 60 (with 420 total test cases) | |
| Aider 444https://github.com/Aider-AI/aider/blob/main/benchmark/README.md | English {C++, GO, Java, JS, Python, Rust} | 225 problems | |
| NL2ML-lib [shin_good_2024] | English Python (ML libraries) | 11,000 | |
| RMCBench [chen_rmcbench_2024] | English 9 Languages | 473 malicious prompts | |
| Evil [liguori_evil_2021] | English {Python, IA_32} | 19255 | |
| Text2Text (about code) | InfiCoder-Eval [InfiCoder-Eval-2023] | English English | 270 |
| BRIGHT [hongjin_su_bright_2024] | English English | 1,398 | |
| Code2Text | DeepCom [DeepCom-2018] | Java English | 588K |
| Hybrid-DeepCom [hu_deep_2020] | Java English | 466k | |
| BinSum [BinSum-2023] | Binary functions English | 557K | |
| Code Attention [miltiadis_allamanis_convolutional_2016] | Java English | 11 projects | |
| Funcom [alexander_leclair_neural_2019] | Java English | 2.1M problems | |
| CodeSum [hu_summarizing_nodate] | Java English | 410,630 | |
| CoDesc [hasan_codesc_2021] | Java English | 4.21M datapoints | |
| Parallel [barone_parallel_nodate] | Python English | 150k function/doc pais | |
| CoDocBench [pai2025codocbenchdatasetcodedocumentationalignment] | Python English | 4573 code/doc pairs |
🔼 This table presents a comprehensive overview of benchmarks used for evaluating natural language processing (NLP) capabilities within the context of software engineering. It categorizes benchmarks by task type (Text2Code, Text2Text, Code2Text), listing the benchmark name, supported languages, and the number of problems or samples included in each benchmark. This detailed breakdown helps researchers select appropriate benchmarks based on their specific needs and research focus.
read the caption
TABLE VI: Overview of Natural Language Benchmarks.
| Category | Name | Language(s) | No. of Problems |
| Text2Code | BIRD [jinyang_li_can_2023] | English SQL | 12,751 |
| KaggleDBQA [chia-hsuan_lee_kaggledbqa_2021] | English SQL | 272, paired with golden solutions | |
| StacQc [zhiliang_yao_staqc_2018] | English {Python/SQL} | {147,546 / 119,519} | |
| question-answer pairs | |||
| Spider(V2555see Table XII) [lei2024spider20evaluatinglanguage] | English SQL | 632 queries | |
| Spider-Syn [gan_towards_2021] | English SQL | (7000 / 1034) | |
| Spider-Real [deng_structure-grounded_2021] | English SQL | 508 | |
| Spider-DK [gan_exploring_2021] | English SQL | 535 pairs | |
| Spider-CN [min_pilot_2019] | Chinese SQL | 9691 queries | |
| SParC [yu_sparc_2019] | English SQL | 4,298 question sequences | |
| Lyra [liang_lyra_2022] | {English, Chinese} {python, SQL} | 2000 | |
| DuSQL [wang_dusql_2020] | Chinese SQL | 23,797 question/SQL pairs | |
| CoSQL [yu_cosql_2019] | English SQL | 3,007 Question Sequencess |
🔼 This table presents a curated list of benchmarks specifically designed for evaluating the performance of AI models on SQL-related tasks. It includes benchmarks categorized by the type of task (such as text-to-SQL code generation) and provides details on the programming language(s) involved and the number of problems or queries in each benchmark.
read the caption
TABLE VII: Overview of SQL-related Benchmarks.
| Category | Name | Language(s) | No. of Samples |
| Programming Languages | CodeTrans [CodeXGLUE-2021] | C#, Java | 11,800 |
| TransCoder-ST [TransCoderST-2022] | C++, Java, Python | 437,030 | |
| CoST [CoST-2022] | 7 programming languages | 16,738 | |
| AVATAR [AVATAR-2023] | Java, Python | 7,133 / 476 / 1,906 | |
| Multilingual-Trans [CodeTransOcean-MultilingualTrans-NicheTrans-LLMTrans-DLTrans-2023] | 8 programming languages | 30,419 total | |
| NicheTrans [CodeTransOcean-MultilingualTrans-NicheTrans-LLMTrans-DLTrans-2023] | Various niche languages | 236,468 total | |
| LLMTrans [CodeTransOcean-MultilingualTrans-NicheTrans-LLMTrans-DLTrans-2023] | 8 programming languages | 350 | |
| G-TransEva [jiao_evaluation_2023] | 5 programming languages | 400 total | |
| CODEDITOR [zhang_multilingual_2023] | C# & Java | 6613 | |
| Libraries | DLTrans [CodeTransOcean-MultilingualTrans-NicheTrans-LLMTrans-DLTrans-2023] | PyTorch, TensorFlow, | |
| MXNet, Paddle | 408 total | ||
| Intermediate Representation | SLTrans [paul_ircoder_2024] | 14 Languages LLVM-IR | 4M |
| Language Conversion Frameworks | MultiPL-E [MultiPL-E-2022] | 19 programming languages | - |
| MultiEval [MultiEval-HumanEval-MBXP-MathQA-X-2022] | 13 programming languages | - |
🔼 This table presents a comprehensive overview of existing benchmarks for evaluating programming language translation models. It categorizes benchmarks by the type of programming languages involved (e.g., specific languages or multiple languages), intermediate representations used, and associated frameworks. The ‘No. of Samples’ column indicates the number of training, development, and test samples available in each benchmark dataset, clearly highlighting the scale and scope of each benchmark. This detailed breakdown helps researchers choose the most appropriate benchmark based on the languages and methods they are working with.
read the caption
TABLE VIII: Overview of Programming Language Translation Benchmarks (Note: X/Y/Z denotes Train/Dev/Test).
| Category | Benchmark | Language(s) | No. of Problems |
| Software Development & Agent Benchmarks | DevBench [devbench-2024] | Python, C/C++, Java, JavaScript | 22 repositories |
| DevEval [DevEval-2024] | Python | 1,874 | |
| CoderUJB [CoderUJB-2024] | Java | 2,239 | |
| CODAL [m_weyssow_codeultrafeedback_2024] | Python | 500 | |
| ToolQA [zhuang_toolqa_2023] | Python, Math, English | 800(Easy)/730(Hard) | |
| MIT [wang_mint_2024] | Python, English | 586 Problems | |
| SAFIM [gong_evaluation_2024] | Python, Java, C++, C# | 17720 | |
| AgentBench [liu_agentbench_2023] | N/A | 1360 prompts | |
| Class Level | ClassEval [ClassEval-2023] | Python | 100 |
| CONCODE [Concode-2018] | English, Java | 104,000 | |
| BigCodeBench [BigCodeBench-2024] | Python | 1,140 | |
| Project & Cross-file | SWE-bench [SWE-bench-2023] | Python | 19,008 (Train), 225 (Dev), |
| 2,294 (Test) | |||
| 144 (Small) | |||
| CrossCodeEval [CrossCodeEval-2023] | C#, TypeScript, Java, Python | 2,665 (Python), 2,139 (Java), | |
| 3,356 (TypeScript), 1,768 (C#) | |||
| CoderEval [CoderEval-2023] | Java, Python | 230 | |
| DotPrompts [agrawal_guiding_2023] | Java | 105538 problems (1420 methods) | |
| BigCloneBench [svajlenko_evaluating_2015] | Java | 25,000 Java Systms | |
| DI-Bench [zhang2025dibenchbenchmarkinglargelanguage] | Python, C#, Rust, JS | 581 repositories (w/ dependencies) | |
| DyPyBench [Bouzenia_2024] | Python | 50 repositories | |
| Repository Level | RepoBench [RepoBench-2023] | Python, Java | Cross-file: 8,033, In-file: 7,910 |
| RepoEval [RepoEval-2023] | Python | 1,600 (line), | |
| 1,600 (API), 373 (function) | |||
| EvoCodeBench [EvoCodeBench-2024] | Python | 275 | |
| SketchEval [daoguang_zan_codes_2024] | Python | 19 repositories | |
| (5 easy, 8 medium, 6 hard) | |||
| Stack Repo [daoguang_zan_codes_2024] | Python | (435,890 / 220,615 / 159,822) | |
| answer pairs | |||
| ML-BENCH [tang_ml-bench_2024] | Python & Bash | 9641 problems | |
| CodeGen4Libs [liu_codegen4libs_2023] | Java | 403,780 prompts |
🔼 This table presents a collection of real-world software engineering benchmarks. It categorizes benchmarks by their focus area (Software Development & Agent Benchmarks, Class Level, Project & Cross-file, and Repository Level), lists the programming languages used in each benchmark, and indicates the number of problems or samples available for each benchmark. The notation X/Y/Z represents the number of training, development, and testing samples, respectively. This table is designed to provide a comprehensive overview of benchmarks used in evaluating AI models on practical software engineering tasks, offering a variety of complexities and scopes.
read the caption
TABLE IX: Overview of Selected Real-to-Life SE Benchmarks. (Note: X/Y/Z denotes Train/Dev/Test)
| Category | Benchmark | Sources/API(s) | No. of Problems |
| API Prediction | RestBench [RestBench-RestGPT-2023] | Spotify, TMDB | 57, 100 |
| APIBench-Q [APIBENCH-Q-2021] | StackOverflow, Tutorial Websites | 6,563 (Java), | |
| 4,309 (Python) | |||
| BIKER [BIKER-Dataset-2018] | StackOverflow | 33,000 | |
| Gorilla APIBench [Gorilla-APIBench-APIZoo-2023] | HuggingFace, TensorHub, TorchHub | 925, 696, 94 | |
| Gorilla APIZoo [Gorilla-APIBench-APIZoo-2023] | Open submissions | – | |
| (Google, YouTube, Zoom, etc.) | |||
| Retrieval & Planning | API-Bank [API-Bank-2023] | 73 commonly used APIs | 753 |
| CodeRAG-Bench [CodeRAG-Bench-2024] | Competition solutions, tutorials, | 25,859 | |
| documentation, StackOverflow, GitHub | |||
| Search4Code [rao_search4code_2021] | Bing | 6596(java)/4974(c#) | |
| CoIR [li_coir_2024] | GitHub, StackOverflow, and | 2.38M (corpus) | |
| Various Benchmarks | 3.37(queries) | ||
| Memorization | SATML-ext [al-kaswan_traces_2024] | GitHub | 1,000 samples |
🔼 This table presents a categorized overview of selected AI4SE (Artificial Intelligence in Software Engineering) benchmarks focusing on API prediction, retrieval and planning, and memorization tasks. For each benchmark, it lists the name, the data sources or APIs utilized, and the number of problems or samples included. This provides a concise summary of resources available for evaluating AI models in these specific SE sub-domains.
read the caption
TABLE X: Overview of Selected API and Retrieval Benchmarks by Category.
| Category | Benchmark | Language(s) | No. of Problems | Crowdsourced |
| Pseudocode to Code | SPoC [SPoC-2019] | C++ | 18,356 | Yes |
| NAPS [NAPS-2018] | Java/UAST | 17,477 | No | |
| Code to Pseudocode | Django [Django-2015] | Python, English | 18,805 (Train), 1,000 (Dev), | No |
| & Japanese | 1,805 (Test) |
🔼 This table provides an overview of the AI4SE (Artificial Intelligence for Software Engineering) benchmarks that specifically focus on pseudocode. It details the benchmark’s name, the programming languages involved, the number of problems or samples within each benchmark, and whether the benchmark is crowdsourced.
read the caption
TABLE XI: Overview of AI4SE Benchmarks Related to Pseudocode.
| Benchmark | Language(s) | No. of Problems | Source |
| WikiSQL [WikiSQL-2017] | Natural language SQL query | 80,654 | Amazon MTurk (deprecated - 2017) |
| Spider [Spider-2018] | Natural language SQL query | 10,181 | 11 Yale students (2018) |
| NL2Bash [xi_victoria_lin_nl2bash_2018] | Natural language Bash | 9,305 | Upwork (2018) |
| NAPS [NAPS-2018] | Java/UAST Pseudocode | 17,477 | Self-hosted crowdsourcing, |
| competitive programming community (2018) | |||
| SPoC [SPoC-2019] | C++ | 18,356 | Competitive programming websites (2019) |
| MBPP [MBPP-MathQA-2021] | Python | 974 | Google Research, |
| internal crowdworkers (2021) |
🔼 This table presents a collection of AI4SE (Artificial Intelligence for Software Engineering) benchmarks that were developed through crowdsourcing. It details the programming languages used, the number of problems included, and the original source of the benchmark data. Crowdsourced benchmarks are datasets created through community contributions and often represent real-world scenarios or problems.
read the caption
TABLE XII: Overview of Selected Crowd-sourced Benchmarks.
| Category | Benchmark | Language(s) | No. of Samples |
| Automated Program Repair & Fault Localization | Defects4J [Defects4J-2014] | Java | 835 |
| GitBug-Java [GitBug-Java-2024] | Java | 199 | |
| EvalGPTFix [quanjun_zhang_critical_2023] | Java | 4530 | |
| TutorCode [boyang_yang_cref_2024] | C++ | 1239 | |
| GHRB [jae_yong_lee_github_2023] | Java | 107 | |
| IntroClass [claire_le_goues_manybugs_2015] | C | 998 | |
| ManyBugs [claire_le_goues_manybugs_2015] | 7 Languages | 185 | |
| DebugBench [runchu_tian_debugbench_2024] | C++, Java, Python | 1,438 & 1,401 & 1,414 | |
| QuixBugs [derrick_lin_quixbugs_2017] | Java | 40 (locations of bugs) | |
| RES-Q [beck_labash_res-q_2024] | Python, JS | 100 hand-crafted questions | |
| + test scripts | |||
| StudentEval [hannah_mclean_babe_studenteval_2023] | Python | 1,749 buggy programs on | |
| 48 distinct tasks | |||
| (3 test cases per problem) | |||
| Re-Factory [Hu_refactory_2019] | Python | 1783(buggy)/2442(correct) | |
| ConDefects [wu_condefects_2023] | Python, Java | 526(Python), Java(477) | |
| Cerberus [shariffdeen_cerberus_2023] | C, C++, Java | 2242 (across 4 task types) | |
| Vulnerability Detection | CVEFixes [guru_prasad_bhandari_cvefixes_2021] | Various Languages | 5,365 |
| LLMSecEval [catherine_tony_llmseceval_2023] | C | 150 (on 25 distinct vulnerabilities) | |
| SecurityEval [mohammed_latif_siddiq_securityeval_2022] | 6 languages | 130 (on 75 common vulnerabilities) | |
| Vul4J [bui_vul4j_2022] | Java | 79 vulnerabilities | |
| FormAI [tihanyi_formai_2023] | C | 112,000 labeled instances | |
| VJBbench [wu_how_2023] | Java | 42 vulnerabilities | |
| SmartBugs [durieux_empirical_2020] | Solidity | 69 Vulnerable Smart Contracts | |
| Devign [zhou_devign_2019] | C | 4 large-scale software repositories | |
| D2A [zheng_d2a_2021] | C/C++ | 6 OSS Programs | |
| BigVul [10.1145/3379597.3387501] | C/C++ | 348 Projects | |
| SARD 666https://samate.nist.gov/SARD/ | Java, C, C++, C#, PHP | 32k777As of 4th Feb 2025 | |
| Juliet 1.3 888https://samate.nist.gov/SARD/test-suites/112 | C/C++ | 64k999As of 4th Feb 2025 | |
| NVD 101010https://nvd.nist.gov/developers/data-sources | Various Languages | 265k111111As of 4th Feb 2025 | |
| Software Testing | CoverageEval [michele_tufano_predicting_2023] | Python | 1160 |
| ATLAS [watson_learning_2020] | Java | 9,275 projects | |
| HITS [wang_hits_2024] | Java | 10 projects | |
| MeMo [bareis_code_2022] | Java | 9 projects | |
| MLAPIs [wan_automated_2022] | Python | 63 applications |
🔼 This table provides a comprehensive overview of existing benchmarks used for evaluating automated program repair, fault localization, and vulnerability detection techniques. It details each benchmark’s name, programming language(s) it supports, and the number of samples or datasets it includes. This information is crucial for researchers to select appropriate benchmarks based on their specific needs and research focus.
read the caption
TABLE XIII: Overview of Automated Program Repair, Fault Localization, and Vulenrability Detection Benchmarks.
| Category | Benchmark | Language(s) | No. of Samples |
| Code Synthesis & Understanding | Methods2Test [Methods2Test-2020] | Java | 780,944 |
| CRUXEval [CRUXEval-2024] | Python | 800 | |
| CRQBench [elizabeth_dinella_crqbench_2024] | C++ | 100 | |
| CriticBench [lin_criticbench_2024] | Python | 3,825(across 5 tasks) | |
| CodeScope [yan_codescope_2024] | 8 Programming Langauges | 13,390 (across 8 tasks) | |
| Merge Conflict Repair | ConflictBench [ConflictBench-2024] | Java | 180 |
| Type Inference | TypeEvalPy [ashwin_prasad_shivarpatna_venkatesh_typeevalpy_2023] | Python | 845 (annotated labels) |
| TypeEvalPy AutoGen [ashwin_prasad_shivarpatna_venkatesh_typeevalpy_2023] | Python | 78373 (annotated labels) | |
| Automatic Code Quality Review | CodeReview [zhiyu_li_automating_2022] | 8 languages | 7.9M pull requests |
| Software Maintainability [markus_schnappinger_defining_2020] | Java | 519 projects | |
| (evaluations of quality) | |||
| Hallucination Detection | HALLUCODE [fang_liu_exploring_2024] | Python | 5,663 |
🔼 This table presents a collection of benchmarks focusing on various software engineering workflows. It details the specific tasks covered by each benchmark, the programming languages involved, and the number of samples or problems included. These benchmarks are used to evaluate AI models’ performance in these specific SE workflows.
read the caption
TABLE XIV: Overview of Selected SE-Workflow Benchmarks.
| Name | Language(s) | Tasks | Information |
| Big-Bench [BIG-Bench-2022] | Python, Numeric, JSON, English | Functions over numbers, Mathematical Reasoning, Text2Code, Code2Text, Code explanation, Debugging, Turing Complete Concept Learning, amongst other tasks | 250, several per category, 42, 60, 66, 34, 6,390 |
| XLCoST [XLCoST-2022] | C, C++, C#, Java, JavaScript, Kotlin, PHP, Python, Ruby, Rust | Text2Code (program synthesis, code search), Code Summarization, Code Translation | 567K (509k, 58k), 567K, 122K |
| CrossCodeBench [changan_niu_crosscodebench_2023] | Java, C#, Python, C++, JS, PHP, Go, Ruby, TS, C, Bash, Shell | Classification, In-Filling, Translation, Generation, Summarization, Type Prediction, Question Answering | 6.6M, 13.4M, 2.4M, 19.5M, 11.2M, 773K, 190K |
| Long Code Arena [long-code-arena-2024] | English, Python, Java, Kotlin | Commit Message Generation, Module Summarization, Library-Based Code Generation, Project-Level Code Completion, Bug Localization, CI Builds Repair | 163, 216, 150, 908 (varying sizes), 14.96K, 78 |
| CodeXGLUE [long-code-arena-2024] MicrosoftDocs121212https://github.com/MicrosoftDocs/ CodeSearchNet [CodeSearchNet-Challenge-2019] | English, Chinese, Norwegian, Danish, Latvian Go, Java, JavaScript, PHP, Python, Ruby | Code Documentation Translation, Code Documentation (Code Summarization, Comment Generation) | (CN: 52K, NOR: 26K, DK: 45K, LT: 21K), 621870 |
🔼 This table presents a list of benchmarks that evaluate multiple aspects of AI models in software engineering tasks. Unlike single-task benchmarks, these multi-category benchmarks assess a wide range of capabilities, providing a more holistic evaluation of the AI model’s overall performance.
read the caption
TABLE XV: Overview of Multi-Category Benchmarks, Covering Various Tasks.
Full paper#